
基于词向量与TextRank的政策文本关键词汇抽取方法研究
2023-03-30 08:52赵燕清于俊凤张铭君DMYTROLANDE
现代计算机 2023年2期
李 晨,赵燕清,于俊凤,张铭君,DMYTRO LANDE,2
(1.齐鲁工业大学(山东省科学院)情报研究所,济南 250014;2.乌克兰国立技术大学信息与计算机科学学院,基辅 03056)
0 引言
政策通常是指政府、机构、组织为实现目标而订立的计划。政策文献是政策的物化载体,是政府处理公共事务的真实反映和行为印迹,是对政策系统与政策过程客观的、可获取的、可追溯的文字记录[1]。关键词是对文本的高度概括和抽象,能够帮助人们快速了解政策全文信息。因为政策本身的特殊性,原文中并不会设置关键词字段,如果可以采用自动的方式提取出与主题相关的词语或短语,则可以更好地辅助政策解读。
目前政策文本关键词提取算法大都以开源分词工具为基础,结合词频统计和人工辅助来实现。如吴宾等[2]利用开源工具人工提取海洋工程装备制造业政策主题词;吴爱萍等[3]运用扎根理论从政策样本中提取高频关键词。如果可以利用机器学习的方式自动抽取政策关键词,那么就可以进一步提高政策分析效率。现有的基于机器学习的关键词提取算法大体可以分为两类,分别是有监督提取方法和无监督提取方法。有监督的提取方法是一种分类方法,需要人工提前设置好训练集,然后训练出分类模型,最后通过分类模型完成关键词提取。如果训练集质量较高,用此方法可以得到比较好的结果,但是这种方式需要人工的参与,总体来说效率低、代价大。无监督的关键词抽取方式目前主要有三种:基于统计方法(TF‑IDF)的抽取方式、基于主题模型(LDA[4])的抽取方式和基于图模型(TextRank)的抽取方式。
1 相关工作
基于TF‑IDF 的抽取算法是较为简单的一种实现。该方法以词频统计为基础,按照某个词在单篇文档中出现的次数和在所有文档中出现的文档频率进行计算。该方法可以过滤一些常见的无关紧要的词语,同时还能保留区分度较高的重要词语。张骁等[5]就利用TF-IDF 算法结合实际对科技服务业政策文本的关键词进行了提取。方法虽然易于实现但是缺点也很明显,单纯以词频衡量词的重要性,不够全面,同时也不能反映词的位置信息。为了克服这些缺点,很多人对TF‑IDF 算法进行了改进。张瑾[6]在原有的算法基础上加入位置权值及词跨度权值,避免了单纯采用TF‑IDF 算法产生的偏差。
LDA 模型在自然语言领域被大规模应用,该技术同样也适用于文本关键词抽取。基于LDA 的实现方式需要对数据集进行训练得到主题模型,选取能够反映主题的词语作为候选关键词,这种方式抽取的关键词很大程度上依赖训练数据的主题分布情况。
基于图模型的关键词提取算法近年来研究较多,借鉴PageRank[7]算法思想进行改进与扩展。该方法是将文本转化为相关词的词语网络图,该图的节点是词,边是词语之间的共现关系,该类算法无需引入外部语料进行训练,只需对图进行随机游走即可实现词语排序和关键词抽取。TextRank[8]借鉴了PageRank 算法思想,首次实现了对词图上的关键词评分并根据评分结果完成关键词提取,成为了无监督关键词抽取方法的典型代表。为了进一步改进TextRank算法的提取效果,很多人对该算法进行了改进。夏天[9]以TextRank 为基础,引入词语位置信息加权计算邻接词语的影响力转移矩阵,有效提高了抽取效果;李航等[10]提出一种综合考虑词性、词语位置信息、词语对文档集重要程度的改进TextRank 方法;刘啸剑等[11]利用LDA 构建主题模型,计算词语相似度并以此相似度为权重构建图的边,以短语作为图的节点,选择top-k个词作为文章的关键词。
随着词向量技术的产生,越来越多的人开始研究将词向量与TextRank 结合进行关键词提取。词向量技术可以挖掘出词与词之间的语义关系,然后将这种语义关系引入到TextRank 算法的计算过程当中,从而解决TextRank 只考虑词共现的缺陷。周锦章等[12]通过构建词向量,基于隐含主题分布思想和词汇的语义差异构建转移矩阵,将词向量与TextRank融合。
本文在已有研究基础之上以维基百科作为外部知识库结合互联网获取的政策文本构建词向量,根据《国务院公文主题词表》为词语初始化权重,再利用词向量计算词语之间语义相似度,结合政策文本位置权重共同构建TextRank转移矩阵,最终选择K个关键词。
2 方法实现
2.1 基于fastText的词向量构建
词向量是指用来表示词语的向量,如比较简单的One‑hot representation。由Mikolov 提出的word2vec 是至今比较有名的词向量表示方式。word2vec 的出现解决了传统词袋模型的缺点,而word2vec 再生成词向量的时候会把每个词当成原子,忽略词内部的形态特征。相对于word2vec,fastText 添加 了subwords 特 性,使 用字符级的n‑grams 来表示单词,这样每个单词除保留了本身外还被表示成多个n‑grams。对于每一个单词,fastText 在拆分成n‑grams 表示的时候,还在单词前后端加入“<”和“>”,用于区分前缀和后缀,如单词hello采用3‑grams可以表示为:
本文利用开源的fastText 工具,将维基百科和政策内容融合共同构建词向量。
2.2 TextRank转移矩阵构建
利用TextRank 进行关键词抽取的思想比较简单:首先根据词共现关系构建无向带权图,然后利用PageRank 循环迭代计算节点权值,排序权值即可得到最终关键词。TextRank 算法的核心计算公式如式(2)所示:
其中:WS(Vi)表示节点Vi的权值;ln(Vi)表示指向Vi的节点集合;Out(Vj)表示节点Vj指向的节点集合;wji表示两个节点之间边的权重;WS(Vj)表示节点Vj的权值;d为阻尼系数,一般取值0.85。基于TextRank的关键词抽取步骤如下:
(1)文本预处理。包括按句子进行文本分割、分词、词性标注、去停用词。
(2)构建词图。文本预处理之后的词语构成节点集合,根据词语的共现关系构建边集。边的构建采用滑动窗口机制,即当两个节点在长度为K的窗口中共现,它们之间才会存在边。
(3)根据公式(2)迭代各节点的权重,直到结果收敛。
(4)对结果进行排序,得到top‑k关键词。
(5)对所得到的关键词进行组合,如果组合的词汇在政策全文中出现,则选择该组合词作为一个关键短语。
本文通过引入词向量等方式对上述步骤进行修改,从而达到面向政策文献的关键词抽取。
对于步骤(1),在进行分词的时候引入《国务院公文主题词表》作为词库,同时剔除此表中无区分度的词语,如:章程、条例、办法、细则、规定、命令、决定、决议、公告、通告、通知、通报、报告、请示、批复、函、会议纪要、答复等。
当关键词出现在词表中的时候,在原有权重的基础上再乘1.5。
对于步骤(2),在构建此图边集的时候综合考虑词语的位置信息和词语之间的语义相似度,共同构建转移矩阵。图中任意两个节点vi和vj之间的权重转移是通过边wij来完成的,wij的构建如公式(3)所示:
其中,ft(i,j)计算方式如下:
vsim(i,j)表示vi和vj的的语义相似度,将两者的词向量取出,按照余弦相似度进行计算,coc(i,j)表示二者共现次数。pos(i,j)表示政策文本位置信息的重要影响程度,其计算方式如下所示,pj表示词语出现的位置权重:
3 结果分析
本文以我国“双创”政策为例,验证提出方法的有效性和实用性。首先从互联网相关网站搜索以国务院以及各部委为发文主体,以“双创”为内容的政策文件共计163 篇(如表1 所示)。
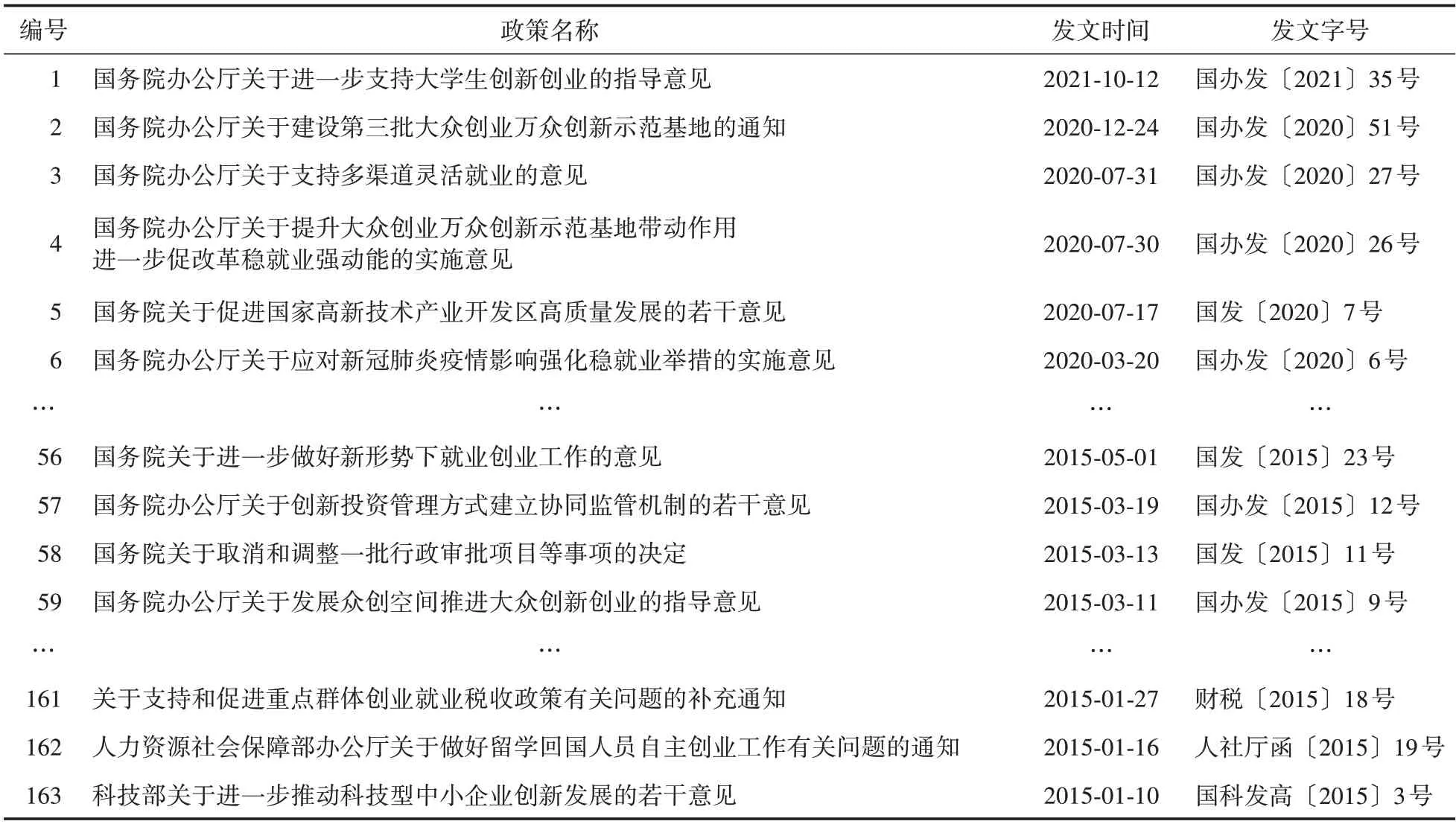
表1 “双创”政策(部分)
根据本文提出的算法,对上述政策列表进行关键词提取,剔除权重小于1.0 的关键词,最终得到关键词192 个(见表2)。从关键词列表和词云可以看出,国家以创新创业为核心制定多项保障措施,如政府工作改革、提供支持政策、加强科技支持、培养创新孵化企业、优化税收政策、提供贷款资金支持等。
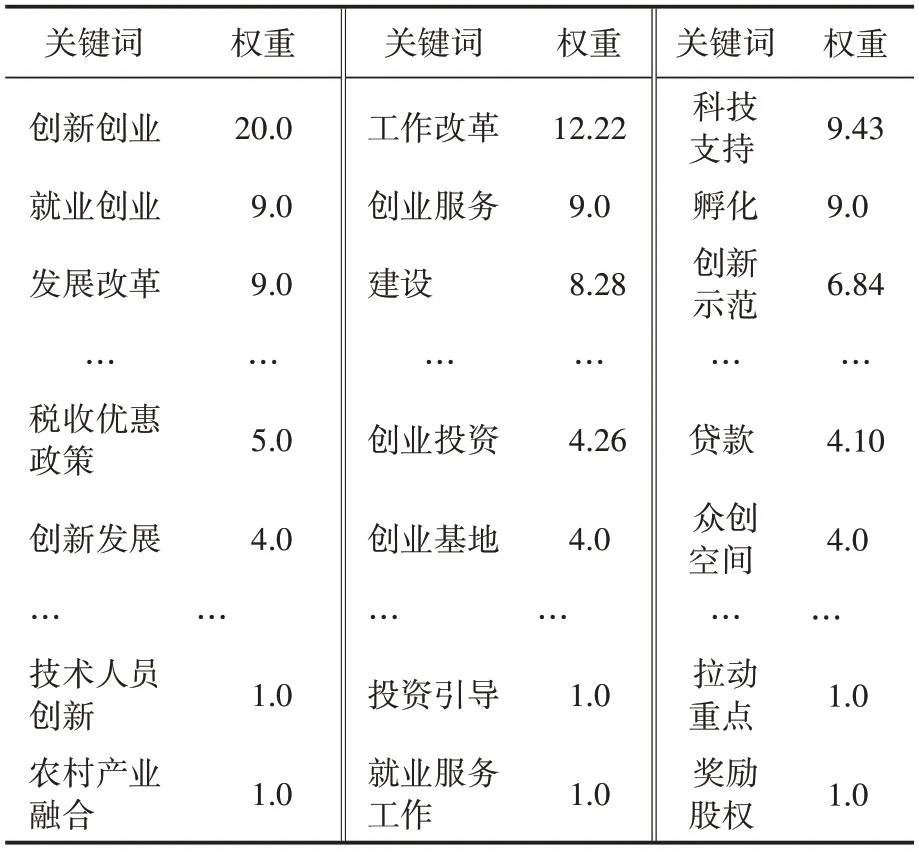
表2 “双创”政策关键词列表(部分)
精确率方面,本文使用维基百科中文语料和从互联网采集到的163篇“双创”政策作为词向量训练文本(参数维度设置为100,窗口大小为5),选择其中50 条政策作为测试集,采用多人交叉标注的方式为每篇政策选择10个关键词。实验指标采用精准率P、召回率R和F1 值进行评测,其中N1表示人工标注合集,N2表示算法抽取合集。
实验选择提取5、8、10 个关键词对不同的方法进行对比,结果如表3 所示。具体包括引入政策文本位置信息的TF‑IDF 方法(方法1)、TextRank 方法(方法2)、基于Word2Vector 的关键词抽取方法(方法3)。
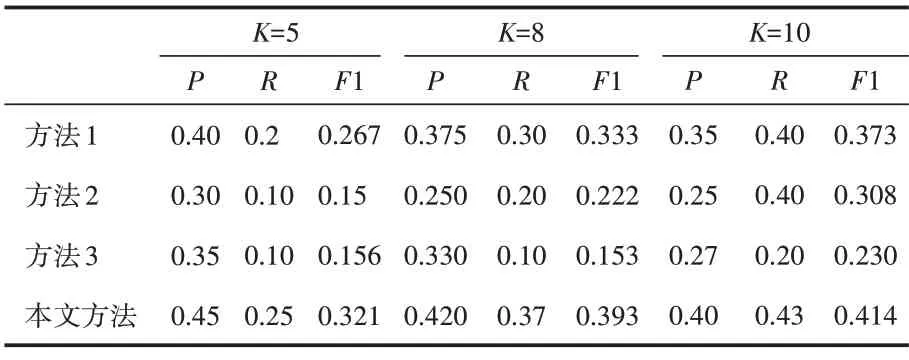
表3 不同提取方法的比较结果
为了能够更直观地查看对比结果,采用折线图的方式将准确率P、召回率R和F1 值进行展示,如图1所示。

图1 对比结果
从图1可以看出,实现方式最简单的是方法1,其实验结果要优于方法2 和方法3。对于方法2,它的实现虽然不依赖于语料环境,但是在没有任何改进的情况下也不能取得较好的结果。在未加入外部语料和只考虑词语相似度的情况下,方法3虽然引入了词向量技术,但是实验结果却是最差。本文提出的方法在关键词抽取个数不同的情况下相对其他几种算法效果都有明显的提升,准确率、召回率和F1 值均高于其他三种方法,验证了提出方法的有效性和实用性。
4 结语
当对政策文本进行主题分析时,往往需要提取政策文本的关键词汇,而由于其本身的特殊性,并不会直接提供关键词字段,所以就要对政策关键词进行提取。本文提出了一种将外部知识库和政策库融合共同构建词向量,利用《国务院公文主题词表》修改词语权重,综合考虑位置信息和词语相似度构建TextRank 转移矩阵的政策文本关键词抽取方法。以“双创”政策为例,提取政策关键词,结果表明本文提出的方法具有较好的效果,可用于政策文本主题分析,为政策研究人员提供辅助支持。
猜你喜欢
国际医药卫生导报(2022年18期)2022-09-29
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小天使·一年级语数英综合(2020年4期)2020-12-16
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
电信科学(2017年6期)2017-07-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
传奇故事(破茧成蝶)(2015年7期)2015-02-28
