
基于时间序列的民用运输航空器碳排放预测研究
2023-03-30 08:52向小军杨志晗赵赶超
现代计算机 2023年2期
向小军,杨志晗,赵赶超
(1.中国民用航空飞行学院科研处,广汉 618300;2.中国民用航空飞行学院飞行技术学院,广汉 618300)
0 引言
近年来,我国民航业得到巨大发展,虽受到“新冠”疫情的影响,2021 年民航运输总周转量仍相较于十年前增长48%,机队规模扩大近1.3 倍,在《“十四五”民用航空发展规划》的指导下,民航业还将继续朝着民航强国的目标飞速发展。与此同时,随着民航业发展,航空燃油消耗量每年也呈增长态势,由燃油消耗带来的碳排放与日俱增。据统计,我国民航业碳排放约占全国碳排放的1.6%,可以预见,未来民航业将成为主要的能源消费和碳排放来源之一。中国已正式宣布将力争在2030 年前实现碳达峰、2060 年前实现碳中和[1],由于航空业研发投入大、周期长、难度高等特点,很难像其他产业一样在短时间内完成低碳转型,因此,民航业减排将成为我国完成“双碳”目标的重要挑战。在这样的背景下,预测我国民航业碳排放量并分析减排措施对于早日完成行业内“双碳”目标有一定参考意义。
目前,对于碳排放预测的研究主要分为三个方面。一是结合历史数据,建立回归预测模型,通过若干易统计数据来推测碳排放量。Wei等[2]通过相关性分析,分析了二氧化碳排放与影响因素之间的关系,然后使用优化后的最小二乘支持向量机预测了碳排放量,该方法有效提高了碳排放的预测精度。Faruque 等[3]建立了二氧化碳排放受电能消耗和国内生产总值(GDP)影响的预测模型,对比分析了卷积神经网络(CNN)、卷积神经网络-长短期记忆(CNN‑LSTM)、LSTM 和密集神经网络(DNN)四种深度学习方法的预测精度。陈文婕等[4]基于私家车轨迹数据,通过逆地理编码与人工神经网络对各区域私家车碳排放量进行预测,并从效率、效果和公平三个角度评估各区域减排潜力,对我国道路交通领域制定减排策略提供了参考。高金贺等[5]在STIRPAT 模型的基础上,建立了由遗传算法优化的支持向量机(GA‑SVR)预测模型,选取人口总量、人均GDP、机动车保有量、旅客周转量、货物周转量、城镇化率和碳排放强度作为影响指标,对北京市1995—2019 年期间数据进行分析,结果表明该模型具有良好的拟合回归效果。
二是进行情景分析或建立碳达峰预测模型,对各行业碳达峰情况进行预测。李宝成等[6]先是利用排放系数法对河南省交通运输领域碳排放进行测算,分析能耗与碳排放量、碳排放强度等方面的关系;之后结合情景分析法预测碳达峰时间和碳排放峰值,最后提出一系列节能减排措施。韩博等[7]构建了一套符合民航特征的碳排放综合预测模型,对2019—2050 年民航碳排放量开展预测分析,结果表明,民航业很难实现2030 年碳达峰愿景,预测民航业将于2045 年实现碳达峰,在此基础上,可持续性航空燃料等新技术的发展将会使民航碳达峰时间提前4—7 年。胡荣等[8]运用情景分析和蒙特卡洛模拟方法预测了厦门机场航空器碳排放达峰的可能性、峰值与影响因素,结果表明,在基准情景下未来15年内碳排放年均增长率为3.1%,期间没有达峰可能性。许继辉等[9]基于LEAP 构建自上而下的中国民航业能源系统模型,探讨民航业中长期低碳发展的技术路径,预计2060年左右中国人均乘机次数翻两番,现有政策情景下,民航业碳排放有望在2046年左右达峰,峰值水平约为3.5亿吨。李心怡等[10]首先采用Kaya恒等式和对数平均迪氏指数分解法(LMDI)分解中国民航运输碳排放的影响因素,其次建立Tapio 解耦模型分析民航运输碳排放量与各影响因素的关联强度,最后运用改进可拓展的STIRPAT模型实现中国民航运输碳排放预测,预计基准情景下2050年之前未有碳排放峰值出现。
三是借助计算机深度学习等方法建立时间序列预测模型,对碳排放进行短期或中长期预测。张金良等[11]首先根据Kaya 恒等式的扩展,分析出影响碳排放的主要因素为人口、经济、产业结构、能源消费强度以及消费结构;然后分别建立线性回归、径向基函数神经网络、ARIMA 以及BP神经网络模型,对比得到最优模型;最后基于最优模型在基准发展、产业优化、技术突破、低碳发展这4 个情景下对未来30 年碳排放进行预测。徐丽等[12]对1997—2015 年中国居民能源消费碳排放现状进行分析,基于ARIMA 模型对2016—2025 年居民能源消费碳排放进行预测研究,该模型预计,到2025 年居民能源消费碳排放将达7.87 亿吨。张昱等[13]设计并实现了一种基于Attention 机制的CNN-LSTM时序预测方法,将此方法应用于某大型园区八个组团的建筑热负荷多步预测中,结果表明此方法有较高的精确度。魏光普等[14]对内蒙古包头市2002—2020 年城区三种建筑类型能源消耗量进行分析,以循环神经网络模型为基础构建LSTM预测模型,并对2021—2030年的包头市建筑碳排放量进行预测,结果表明包头市建筑行业碳排放将于2022 年达峰。胡剑波等[15]基于LSTM 神经网络模型预测出我国碳排放强度变化趋势,同时,建立ARIMA‑BP 神经网络模型作为验证模型对碳排放强度进行直接预测,两模型对比后预测结果相差2.03 个百分点。Yang等[16]先是使用自上而下的方法对往返上海的所有客运航班进行碳排放估算,后建立ARIMA 模型对途中碳排放进行5年预测,最终得到最佳的ARIMA 模型阶数。柴建等[17]基于单变量(ETS、ARIMA 模型)和多变量(Bayes 多元回归)两个维度对航空燃油效率及航空运输总周转量进行分析和预测,最终综合以上两种模型结果得出航空燃油效率、航空总周转量与人均GDP、城镇化率之间的关系。
综上可以看出,国内外学者对碳排放的回归、达峰等预测已相当成熟,该类研究主要集中在综合碳排放、高耗能产业碳排放等方面。对于交通运输业的碳排放预测主要集中在公路运输上,而民航业碳排放研究相对较少。本文基于时间序列预测的方法建立ARIMA 模型以及WOA‑LSTM 组合模型,对我国民航业航空器碳排放量、碳排放强度等数据预测至2035 年并对比结果,最终根据预测数据提出合理减排措施。
1 模型与方法
1.1 差分整合移动平均自回归模型
差分整合移动平均自回归模型通常被称为ARIMA(autoregressive integrated moxving average)模型,是由Box 和Jenkins 于20 世纪70 年代初提出的一种时间序列预测分析方法[18]。在描述ARIMA 模型时,首先要了解AR 模型、MA 模型和ARMA模型。
AR(autoregressive)模型是自回归模型的简称,数学模型表达式如公式(1):
其中:Xt是当前值;c是常数项;p是阶数;φi是自相关系数;εt被假设为平均数等于0,标准差等于δ的随机误差值;δ被假设为对于任何的t时刻都不变。该模型反映了在t时刻的目标值与前t-1至t-q时刻的目标值之间存在线性关系。
MA(moving average)模型是移动平均模型的简称,数学模型表达式如公式(2):
该模型反映了在t时刻的目标值与前t-1至t-q时刻的误差值之间存在线性关系。
ARMA(autoregressive moving average)模型是自回归移动平均模型的简称,描述的是AR 模型与MA 模型的结合,具体数学模型表达式如公式(3):
ARIMA 模型则是在ARMA 模型的基础上,将数据通过差分转化为平稳数据,再将因变量仅对它的滞后值以及随机误差项的现值和滞后值进行回归所建立的模型。
模型参数包括p—趋势自回归阶数;d—趋势差分阶数;q—趋势移动平均阶数。其中p和q由表1确定。

表1 ARIMA(p,d,q)阶数确定
1.2 长短期记忆人工神经网络算法
长短期记忆网络(long short term memory,LSTM)是在循环神经网络(recurrent neural net‑work,RNN)的基础上进行改进的一种算法,由Seep Hochreiter 等学者于1997 年提出,该算法可以在一定程度上解决RNN 算法的梯度消失和梯度爆炸问题[19]。
作为一种神经网络模型,LSTM 拥有三种类型的门结构:遗忘门、输入门和输出门,这些特殊的“门”结构可以在细胞状态中增加或丢弃信息。LSTM处理信息的流程如下:
首先通过“遗忘门”决定从细胞状态中丢弃的信息。该遗忘门读取前序输出与当前输入,再通过sigmoid 函数做非线性映射,之后输出一个维度在[0,1]之间的向量ft,最后与细胞状态相乘,表达式如公式(4):
其中:Wf为权值;ht-1为前序输出;xt为当前输入;Ct-1为细胞状态;bf为偏置向量。
其次通过“输入门”确定何种新信息被存放在细胞状态中。输入门包含了决定和值被更新的sigmoid 层和创建新候选向量的tanh 层,数学表达式如公式(5)和(6):
再次,经过上两步骤后,对细胞状态进行更新。过去的状态与遗忘门输出的向量ft相乘以及输入门中的相加后得到新的候选值,数学表达式如公式(7):
最后通过输出门确定需要的输出值。数学表达式如公式(8)和(9):
整个流程如图1所示。
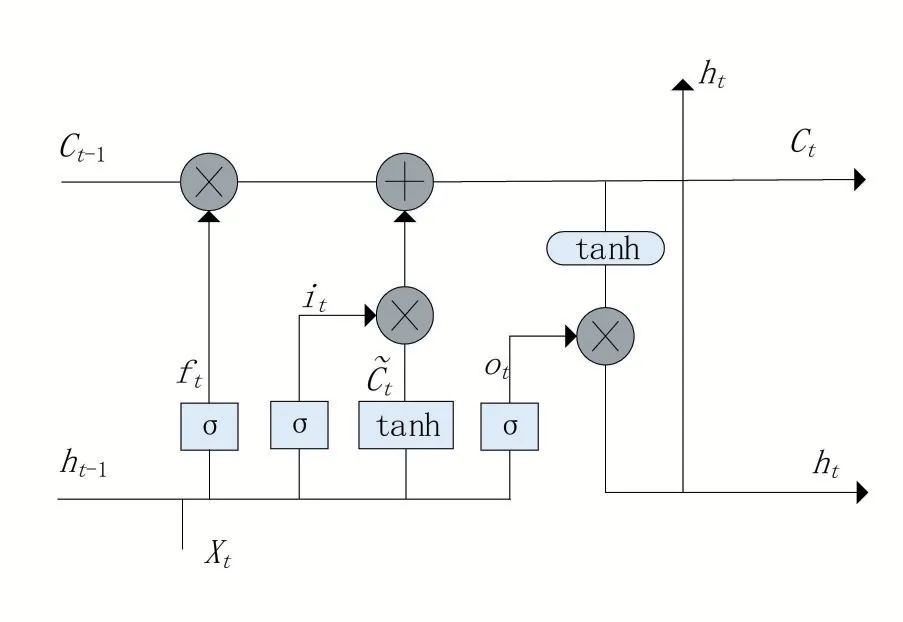
图1 LSTM神经网络原理图
1.3 鲸鱼优化算法
鲸鱼优化算法(WOA)是2016 年由澳大利亚格菲斯大学的Mirjalili 等学者提出的一种模拟座头鲸狩猎行为的元启发式优化算法,该算法采用随机或最佳搜索代理来模拟捕猎行为,并使用螺旋模拟座头鲸的气泡网攻击机制,具有机制简单、参数少、寻优能力强等特点[20]。
标准WOA 模拟了座头鲸特有的搜索方法和围捕机制,主要包括:围捕猎物、气泡网捕食和搜索猎物三个重要阶段。WOA 中每个座头鲸的位置代表一个潜在解,通过在解空间中不断更新鲸鱼位置,最终获得全局最优解。
1.3.1 围捕猎物
座头鲸的搜索范围是全局解空间,需要先确定猎物的位置以便包围。由于最优设计在搜索速度中的位置不是先验已知的,因此WOA 算法假定当前的最佳候选解是目标猎物或接近最优解。在定义了最佳搜索代理之后,其他搜索代理将尝试向最佳搜索代理更新它们的位置。这一行为由公式(10)和(11)表示:
其中:t表示当前迭代次数;A和C是系数向量;X*(t)是目前得到的最佳解的位置向量;X(t)向量是位置向量。
如果存在更好的解决方案,那么应该在每次迭代中更新X*(t),其中向量A和C的计算方式如公式(12)和(13):
在整个迭代过程中a由2线性降到0,r1和r2是[0,1]中的随机向量。
1.3.2 气泡网捕食
座头鲸捕食主要有收缩包围和气泡网捕食两种机制。采用气泡网捕食时,座头鲸与猎物的位置更新用对数螺旋方程表达式如公式(14)和(15)表示:
其中:D′是当前搜索个体与当前最优解的距离;b是螺旋形状参数;l是值域为[-1,1]均匀分布的随机数。
由于靠近猎物过程中有两种捕食行为,因此WOA 根据概率来选择气泡网捕食或者收缩包围,位置更新如公式(16)所示:
其中,p为捕食机制选择概率,值域为[0,1]的随机数。
随着迭代次数t的增加,参数A和收敛因子a逐渐减小,若 |A| <1,则各座头鲸逐渐包围当前最优解,在WOA中属于局部寻优阶段。
1.3.3 搜索猎物
为保证所有座头鲸能在解空间中充分搜索,WOA 根据座头鲸彼此之间的距离来更新位置,达到随机搜索的目的。因此,当 |A|≥1时,搜索个体会游向随机座头鲸,如公式(17)和(18)表示:
其中:D′′为当前搜索个体与随机个体的距离;Xrand(t)为当前随机个体的位置。
1.4 WOA⁃LSTM时间序列模型
LSTM 的训练效果以及训练过程中的拟合速度与初始参数的设置密切相关,其中学习率和隐藏节点数直接影响了神经网络的训练精度和收敛速度。对于学习率来说,若初始学习率设置过大,会导致偏离值较大且后期无法拟合,反之收敛速度会很慢。对于隐藏节点数来说,设置过少会欠拟合,过多会导致过拟合[21]。通过鲸鱼优化算法,全局向局部搜索寻优,确定最佳学习率和隐藏节点个数,从而优化神经网络。
统计产品与服务解决方案(SPSS)是世界领先的统计分析软件之一,广泛应用于自然科学、技术科学、社会科学等各个领域,具有操作简单、编程简单、功能强大等特点,世界上许多有影响的报刊杂志纷纷就SPSS 的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价。矩阵实验室(Matlab)是一款商用数学软件,常用于数据分析、无线通信、深度学习、图像处理、信号处理等领域,具有高效的数值计算功能以及丰富的应用工具箱,为用户提供了大量方便实用的处理工具。
本文将基于SPSS建立ARIMA 时间序列预测模型,同时基于MATLAB 建立WOA‑LSTM 时间序列预测模型,采用均方根误差(RMSE)、平均绝对误差(MAE)以及平均绝对误差百分比(MAPE)作为评估指标来对比分析两种模型的预测结果。
2 实例分析
本文涉及的中国民航运输业交通与经济数据主要来源于中国民用航空局发展计划司编著的1992—2020《从统计看民航》,其收录了1991—2019年中国民航业发展的统计数据。
2.1 数据预处理
由于不同指标量纲不同,不存在可比性,故需要将原始数据标准化,以消除量纲的影响。标准化表达式如公式(19):
其中:Xi为原始数据,Zi为标准化后的数据。
2.2 数据选择
根据中国民用航空局发布的年度《民航行业发展统计公报》,可以得出航空燃油消耗量与航空器碳排放之间的关系为1∶3.15,即平均每消耗1吨燃油产生3.15吨二氧化碳排放。本文结合1991—2019 年中国民航统计数据,选取航空器产生的总碳排放、碳排放强度(单位GDP所排放二氧化碳)、吨公里碳排放作为分析预测目标,并将1991—2014 年24 组数据作为训练集,2015—2019 年5 组数据作为测试集,其中训练集相关数据如表2 所示,测试集相关数据如表3所示。
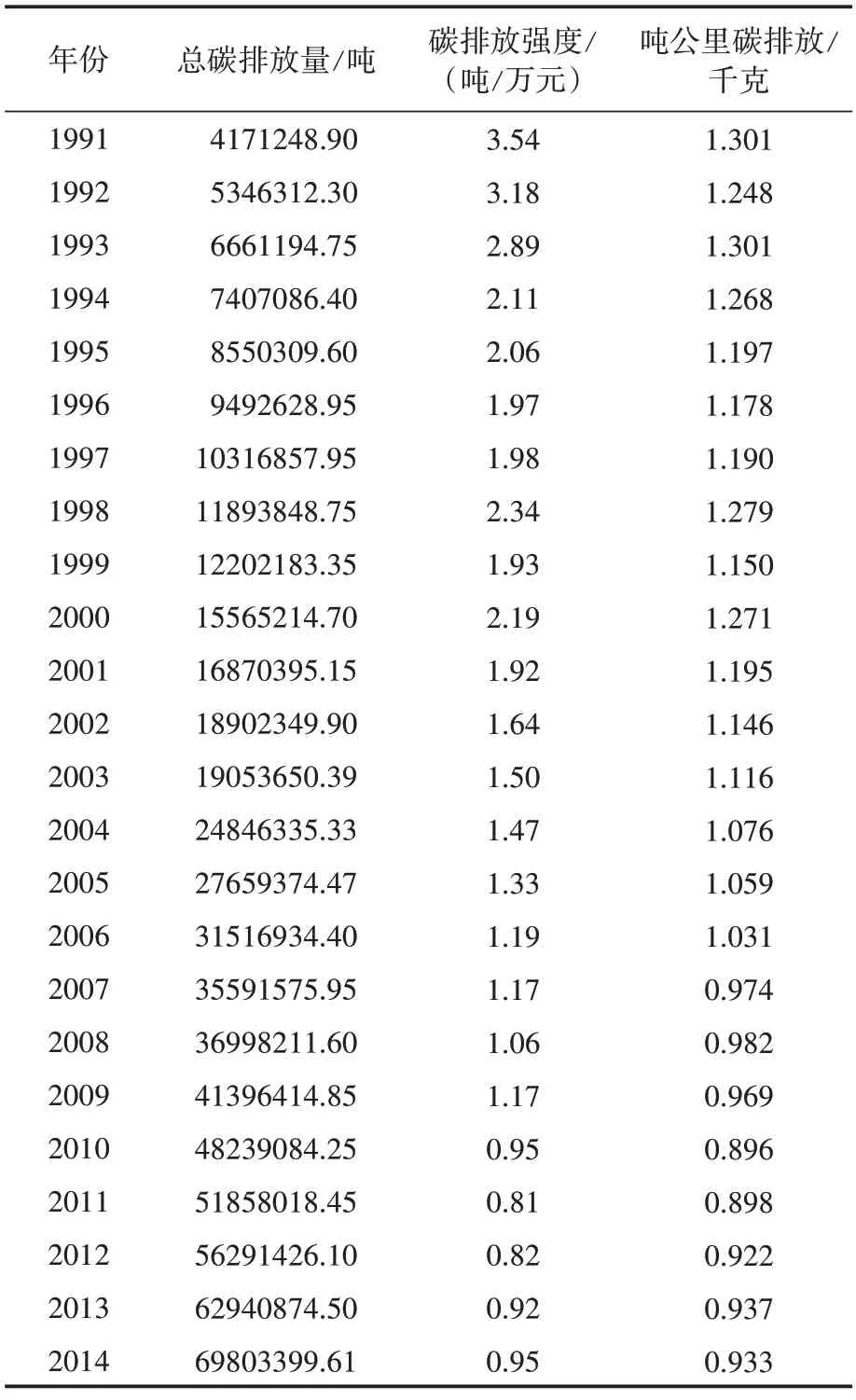
表2 1991—2014年中国民航碳排放相关数据
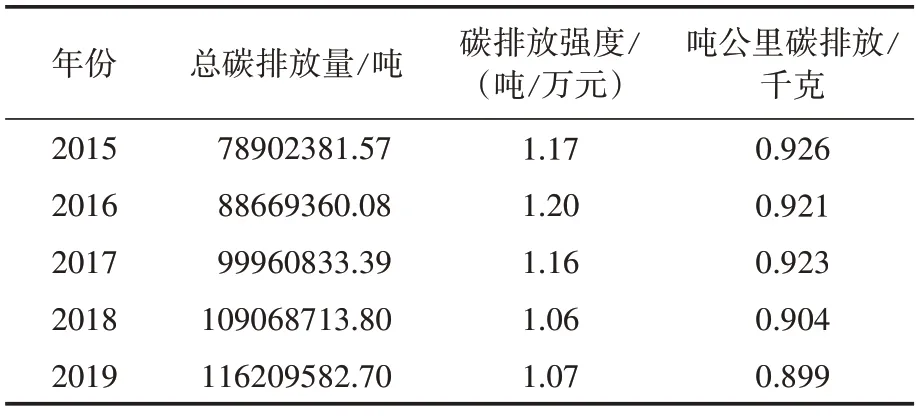
表3 2015—2019年中国民航碳排放相关数据
将中国民航1991—2019 年航空器产生的碳排放量、碳排放强度、吨公里碳排放变化趋势用折线图表示,依次如图2~图4所示。
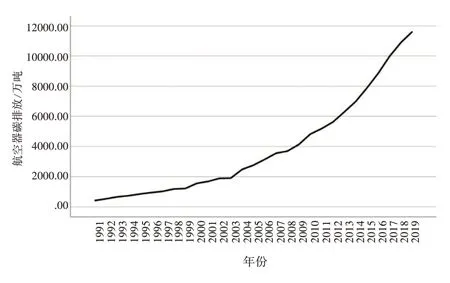
图2 1991—2019年航空器产生的碳排放量趋势图
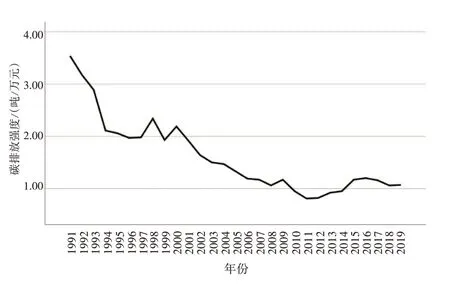
图3 1991—2019年碳排放强度趋势图
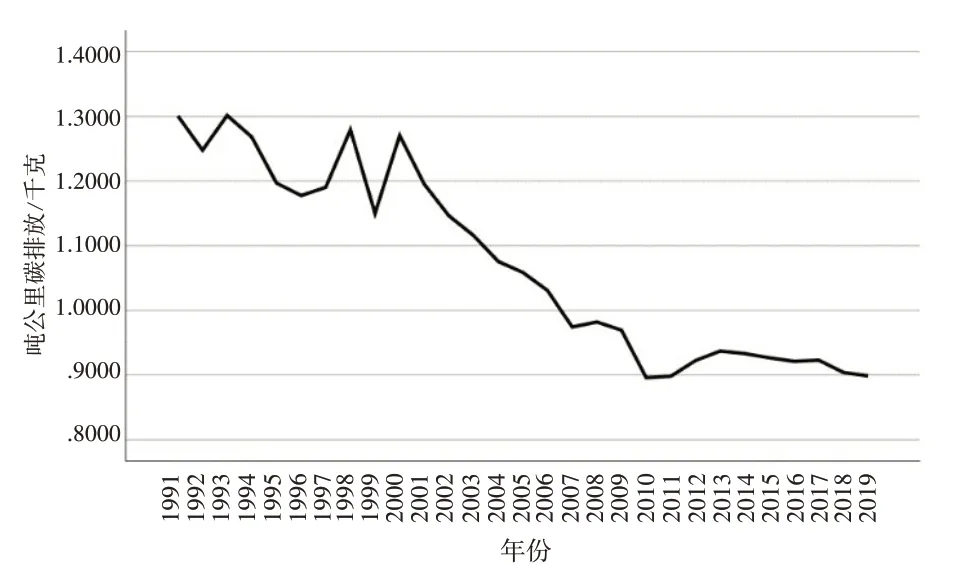
图4 1991—2019年吨公里碳排放趋势图
可以看出,1991—2019 年航空器产生的碳排放呈逐年增加的趋势,且过去十年为快速增长期;而碳排放强度和吨公里碳排放整体处于下降趋势,碳排放强度相较于吨公里碳排放过去三十年变化幅度较大,且近十年稍有起伏,吨公里碳排放近年处于稳中带降的趋势。以上三项数据与我国大力发展民航业和民航业技术变革等因素密切相关,民航业的飞速发展带来航班量与飞行小时数的增加,从而航空燃油消耗量增加,进一步导致碳排放量增加;民航业新技术的应用使燃油效率提高,因此吨公里碳排放量整体处于下降态势。
3 预测结果与讨论
3.1 基于ARIMA模型预测结果
首先对1991—2019 年航空器碳排放量进行自相关(ACF)、偏自相关(PACF)分析,如图5所示,ACF 出现拖尾,即相关数据不具备平稳性,对其进行二阶差分后,ACF 与PACF 均出现截尾,如图6所示,此时数据具有平稳性,可进行预测分析,此时模型为ARIMA(1,2,1)。同理,对碳排放强度、吨公里碳排放分析后模型分别为ARIMA(0,1,0)与ARIMA(1,1,1)。
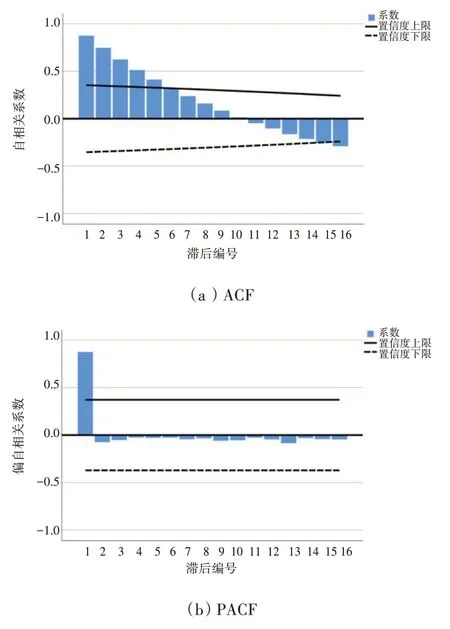
图5 差分前航空器碳排放ACF与PACF分析
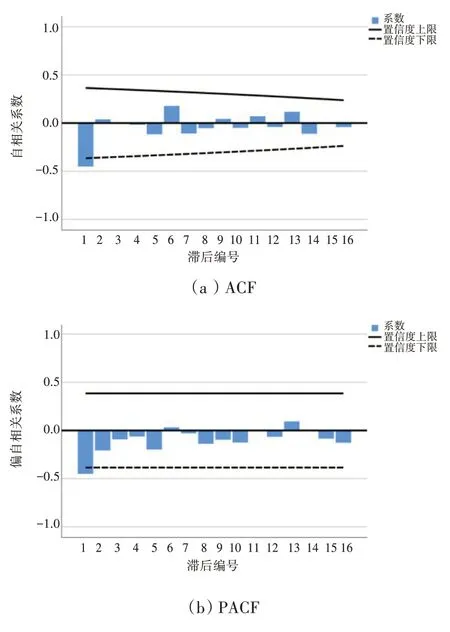
图6 二阶差分后航空器碳排放ACF与PACF分析
其次对三项数据预测至2035 年,依次如图7—图9所示。经过ARIMA 模型预测,航空器碳排放在未来十六年一直保持增长态势,2035 年碳排放将达到3.88 亿吨,未见“达峰”出现;碳排放强度于2020 年后持续上升,2035 年将上升至与1991 年持平水平;吨公里碳排放则出现稳定下降趋势,至2035 年吨公里碳排放仅为0.804千克。
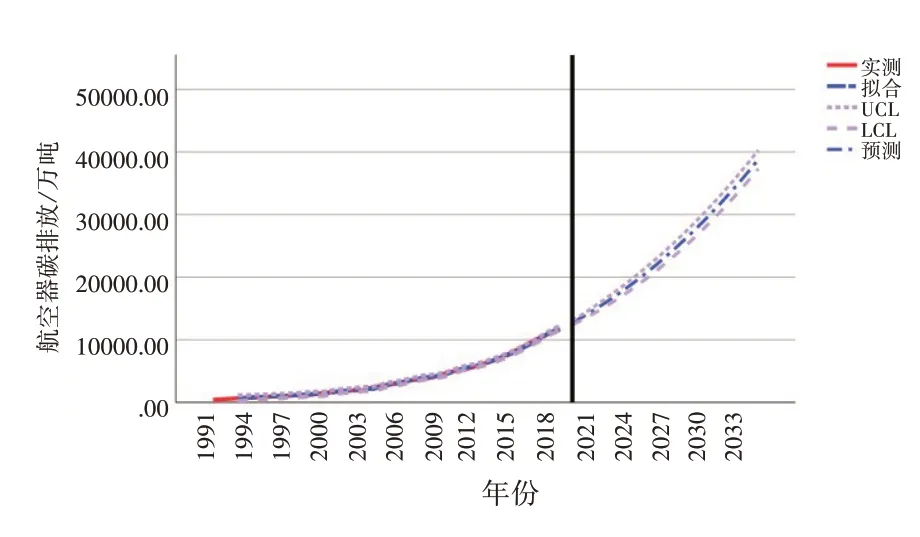
图7 ARIMA模型航空器碳排放演化趋势图(1991—2035年)

图8 ARIMA模型碳排放强度演化趋势图(1991—2035年)
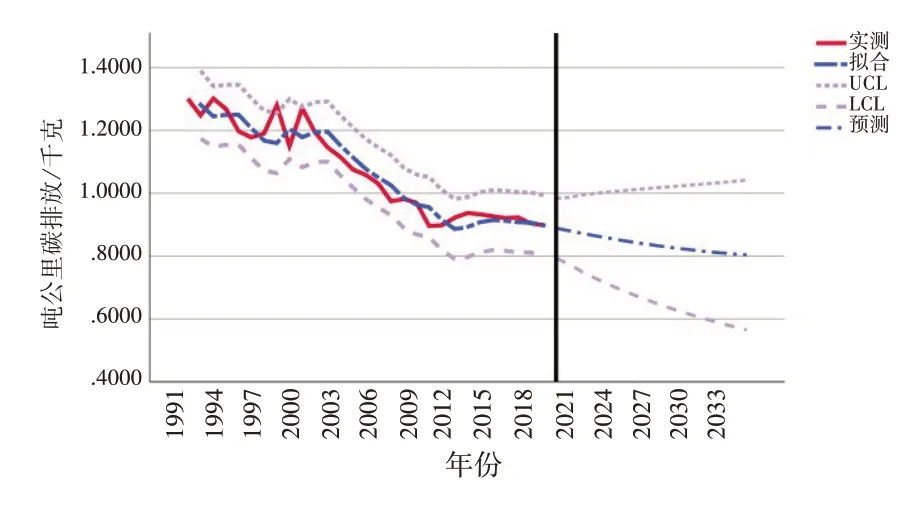
图9 ARIMA模型吨公里碳排放演化趋势图(1991—2035年)
最后模型对应RMSE、MAE以及MAPE如表4所示。
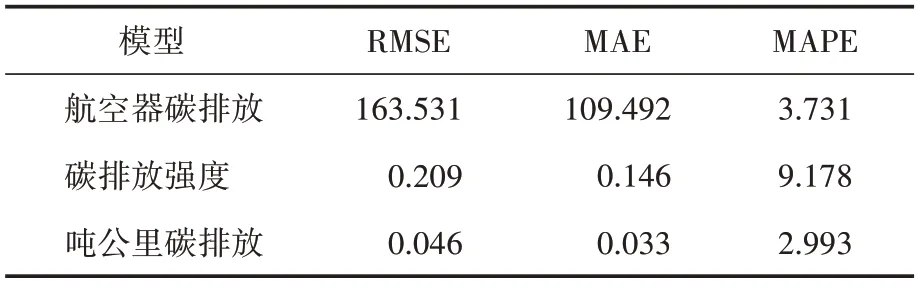
表4 ARIMA模型RMSE、MAE、MAPE统计
3.2 基于WOA⁃LSTM模型预测结果
设置WOA 算法中种群个数为20,迭代10步后得到最优的LSTM 学习率与隐藏节点数,不仅提高了参数选择与调整的效率,同时提高了预测模型的准确度。通过计算机深度学习的方法,基于WOA‑LSTM 建立的三项数据的模型测试集拟合效果如图10所示。
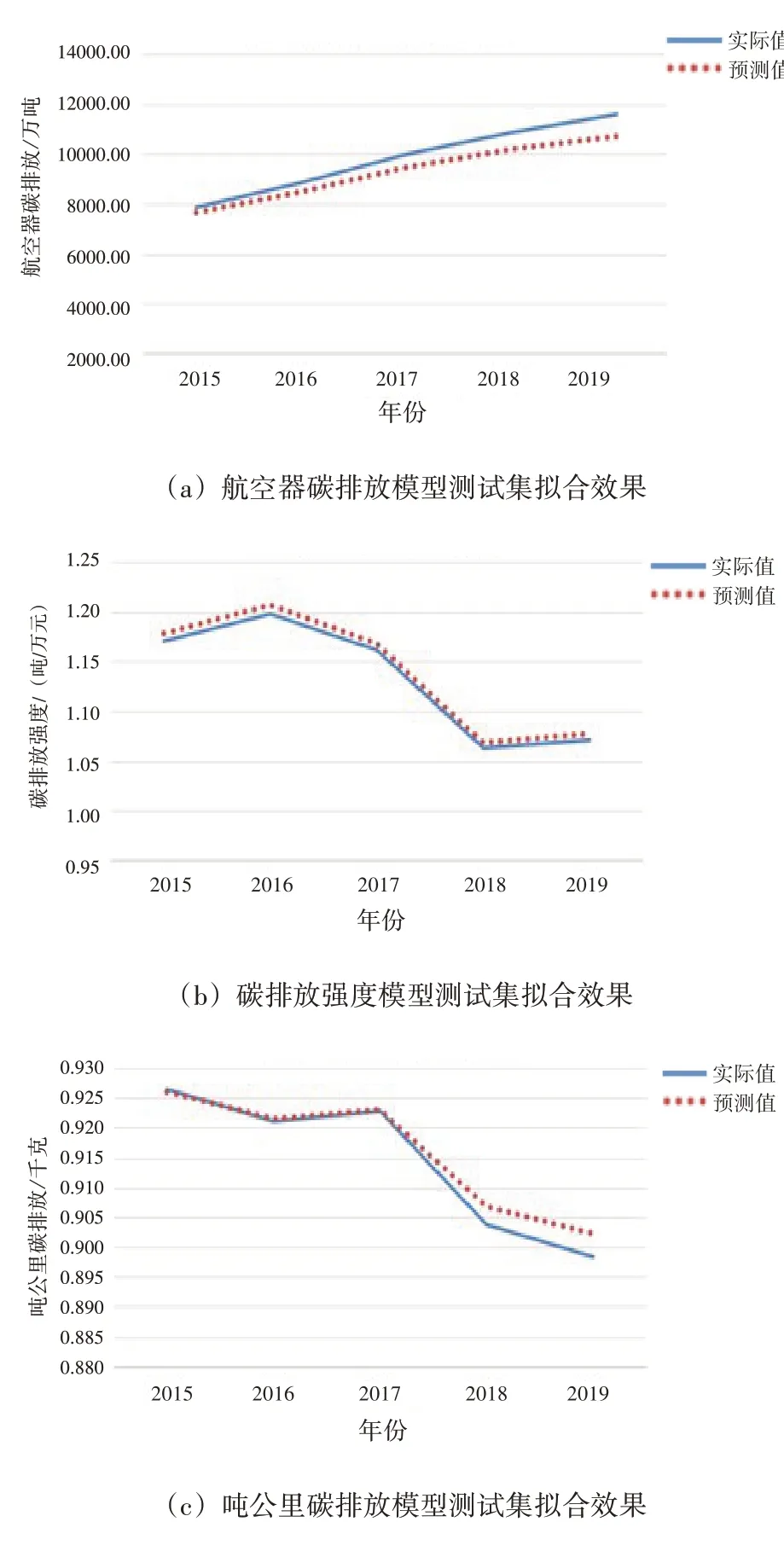
图10 测试集拟合效果图
由图10 可知,所建时间序列预测模型拟合度良好,使用该模型对2020—2035 年数据进行预测,演化趋势如图11~图13 所示。基于WOA‑LSTM 模型预测的航空器碳排放量虽同样为上升趋势,但增加较为平缓,甚至出现“达峰”趋势;碳排放强度与吨公里碳排放变化都较为平缓,吨公里碳排放在未来出现细小波动。
同样,计算基于WOA‑LSTM 所建立三种模型的RMSE、MAE以及MAPE值,如表5所示。
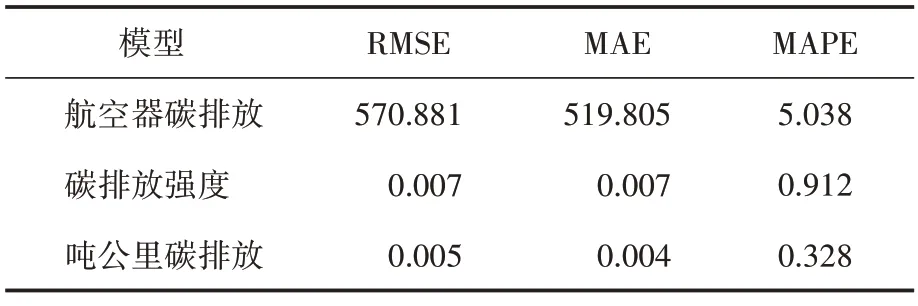
表5 WOA⁃LSTM 模型预测结果
3.3 模型对比分析
将ARIMA 模型与WOA‑LSTM 模型进行对比,可以看出ARIMA 模型对航空器碳排放的预测比WOA-LSTM 模型更加精准,而对于碳排放强度及吨公里碳排放的预测略逊于WOA‑LSTM模型,尤其是碳排放强度预测的MAPE 值为9.173,明显不如WOA‑LSTM 模型准确。综合来看,经过WOA 优化的LSTM 时间序列预测模型的预测效果好于传统ARIMA模型。
4 结语
本文使用SPSS与MATLAB建立了ARIMA及WOA‑LSTM 时间序列预测模型,用于对中国民航业航空器碳排放、碳排放强度等数据的未来预测,其中WOA‑LSTM 使用鲸鱼优化算法对LSTM 模型中的学习率和隐藏节点数进行优化,避免了人为确定参数的主观性和盲目性。通过对ARIMA 与WOA‑LSTM 模型 的 对 比,ARIMA模型在航空器碳排放以及吨公里碳排放预测中具有良好的效果,WOA‑LSTM 模型则在碳排放强度和吨公里碳排放的预测中有更为优越的拟合度和准确性。
根据预测结果可知,在当前政策没有较大变动的情况下,未来民航业碳排放将会持续上升,这将对我国在环境保护方面的总体规划造成较大冲击,为我国完成2030“碳达峰”目标造成一定的困难。同时,由于行业特殊性,民航业技术迭代周期长、新技术应用慢等特点,也给民航业的节能减排工作带来很大困难。基于本文预测结果与民航业特点,总结出以下几点民航业节能减排方面的建议:
(1)调整优化机队规模结构。从1991—2019年吨公里碳排放数据的演化可以看出,老旧机型相较于新机型在燃油效率方面有一定劣势,应加快撤下高排放老旧飞机。
(2)提升空管运行效率,优化航班航线。积极推进空管新技术研发应用以及飞行程序新标准的制定,全面提升航班整体运行效率。
中国是一个发展中的人口大国,根据《“十四五”民用航空发展规划》的部署,我国民航业未来还将继续高速发展,随之而来的二氧化碳排放问题值得特别关注。本文所建立的碳排放时间序列模型可以对相关研究提供一定的参考,同时我们将继续关注民航业绿色发展等问题,为后续研究做好准备。
猜你喜欢
煤气与热力(2021年6期)2021-07-28
高师理科学刊(2020年2期)2020-11-26
西南石油大学学报(社会科学版)(2016年1期)2016-12-01
太空探索(2016年3期)2016-07-12
太空探索(2016年8期)2016-07-10
工业设计(2016年6期)2016-04-17
中小企业管理与科技·中旬刊(2016年2期)2016-03-18
——《2013年中国机动车污染防治年报》(第Ⅱ部分)
环境与可持续发展(2014年1期)2014-08-14
电力工程技术(2014年1期)2014-03-20
首都经济贸易大学学报(2013年1期)2013-03-11
