
LSTM预测驱动的软件系统主动自适应方法
2023-03-29 12:31谢生龙刘瑞佳
应用科学学报 2023年1期
谢生龙,王 璐,刘瑞佳,溥 颖,刘 潇
1.延安大学数学与计算机科学学院,陕西 延安 716000
2.西安电子科技大学计算机科学与技术学院,陕西 西安 710071
随着互联网技术的快速发展以及分布式计算、网格计算、云计算等基于互联网应用模式的不断涌现,软件系统的异构性、交互性、分布性和动态性等特点越来越明显。在复杂软件需求的驱动下,软件系统的规模也在逐渐扩大,尤其是与环境交互复杂的面向服务系统(service-oriented systems,SOS)更是如此。由于SOS 无法准确地预知交互环境和需求的变化,于是形成了许多潜在的不确定性。不确定性的概念已在其他学科领域得到广泛探索,如经济学[1]、物理学[2]和心理学[3]等。对于软件系统来讲,不确定性是指与确定性知识的偏差[4]。SOS 暴露在来自系统环境、资源可用性以及用户目标等各种潜在的不确定性风险下,这降低了SOS 对这些不确定性进行响应的可信度,最终会影响SOS 的服务质量。从软件系统的生命周期角度来看,处理这些不确定性是系统管理员的任务。然而,这种管理任务繁多庞杂,容易出错且费时费力,仅靠系统管理员通过诸如穷举测试等方法去解决执行时遇到的所有不确性问题是不现实的。因此,不确定性使得软件系统变得难以维护。现代SOS 只有具备在24/7 全天候运行过程中解决各种不确定性问题的能力,才能在不断变化的环境下满足特定的服务级别协议(service level agreement,SLA)需求[4]。用户的这一期望对SOS 的自主处理能力提出了更高的要求,于是有学者从静态分析、运行时验证及机器学习等方面入手,开展了相关的研究工作。
静态分析以系统性的方式检查软件系统运行的逻辑过程,推断某些属性可能存在的不确定性。众所周知,尽管用户需求和运行环境都会发生变化,但仍有一些固有的属性保持不变[5]。这些属性可以表征为对未来系统状态特征量化的近似值,而这些值可用来分析与计算不变属性的范围,如上界和下界;也可以向SOS 推荐服务组合策略的方案。在一般情况下,开发人员可以手动将静态分析置于软件最优配置中[6],如基于规则的建模和图变换对自适应系统进行静态分析[7-8],通过规则实现一致性操作属性的校验,使处于适应状态中的系统以系统演化的方式再次适应新的变化以达到稳定的状态。此外,也允许系统通过自动静态分析进行自演化,如以系统代码静态分析的方法捕获运行时的参数和执行路径,并基于调整后的程序建立稳定的执行模型,进而匹配不稳定的执行场景[9]。很显然,这类分析往往不是为了分析程序代码,而是为了分析系统本身行为。文献[10]建议将静态分析与实时优化技术相结合,首次引入可管理且固有的自适应静态分析技术,通过自我分析与自动调整实现了相对于软件系统和分析本身而言是最优功能或非功能的服务质量(quality of service,QoS)权衡。
运行时验证是一种比较正式的分析技术,可用于验证软件系统在运行时是否满足某些预定义的属性。目前,许多软件工程方法采用运行时架构模型来简化这些自适应系统中自主控制回路的设计。虽然这种技术在响应各种环境变化时表现良好,但实现自适应问题预测的能力有限,甚至可能出现系统短暂不能使用、适应代价高或资源浪费等问题。基于运行时验证的解决方案通常使用服务组合的运行时模型进行检查,以确定能否成功地适应SOS,于是文献[11]在运行时使用模型检查和定量验证技术来保障自适应系统的可靠性。文献[12]遵循简单的静态监控规则,并添加二级运行时验证或反馈循环验证模块,提高了自适应系统的性能。这些方法可以看作是一种典型的运行时定量验证(runtime quantitative verification,RQV)技术,主要依赖自适应系统的监测能力,先将系统监测到的信息用于核心模型的参数更新,再用于检测或预测需求规则的违反情况,一旦监测到违规情况就可以使用相同的定量验证技术选择合适的自适应参数。文献[13]研究了在运行时如何使用模型检查器并结合缓存、适应目标和配置策略来减少运行时验证时间的开销,这是一种使用自适应系统的模型检查器解决不确定性选择的典型思路,可以从时间维度累积效用,使之达到最大化。文献[6]提出了一种在不确定性下的主动延迟感知适应方法,采用概率模型进行适应决策检查。此外,目前流行的机器学习技术也可以帮助系统在运行时有效地选择自适应模式。然而,这类方法可能存在学习偏差,在某些情况下导致次优甚至不可行的适应过程,以致引发新的不确定性问题。为了突破这一限制,文献[14]提出了一种结合机器学习和形式化定量验证的主动自适应方法。在该方法中,机器学习的任务是为给定场景选择最佳适应模式,定量验证自适应决策的可行性,防止执行不可行的自适应,并向机器学习引擎提供反馈,促使模型更快地收敛到最优决策。从宏观来看,以上提到的RQV 与概率模型的检验有两个主要区别:1)对于一般的自适应决策,RQV 通常用于一次量化或验证每个可能配置的属性,以便选择模型检查过程之外的目标配置。2)RQV 通常只在环境状态实时运行的上下文中验证单个配置,而不是在自适应全过程中验证自适应序列。
虽然上述两类软件主动自适应研究已经在许多领域取得了较好的成果,但SOS 仍可能受到各种来源的不确定性影响,如服务调用失败、不确定服务响应延时或新服务的注册等。事实上,在SOS 出现上述类似问题之前,一切都是未知的。因此,基于静态分析或模型验证的自适应保障方法只能是短期的判断,不一定有足够的时间给出最优的自适应决策来应对系统可能发生的所有变化。现代SOS 运行环境的开放性和软件运行环境的动态性体现在系统参数和QoS 指标之间的重要关系中,仅仅依靠静态分析和运行时验证使SOS 主动自适应显得力不从心,尤其是对于具有刚性目标的SOS 来说,软件需要更积极、更主动、更精确的自适应以应对用户QoS 开放性造成的问题。因此,及时获取环境信息并根据这些信息预测可能发生的服务故障,是SOS 主动自适应调整的关键[15]。鉴于此,为了更好地保障SOS 运行时的质量可靠性,在自适应过程中逐渐采用了机器学习或数据挖掘技术[16]。文献[17]基于动态贝叶斯网络模型执行一步时间序列预测,并用基于主题的动态贝叶斯网络模型进一步修正未来可靠性预测模型,最后根据可靠性预测结果实现了主动适应策略的生成。文献[18]结合序列模式挖掘算法和贝叶斯网络等技术抽取并建模事件因果关系,保障事件关系识别质量,支持软件系统的自适应。与贝叶斯网络这类相关的方法确实可以保障用户QoS,但不太适合高度动态环境中大规模自适应服务组合系统。有部分学者还指出:基于在线测试框架和正式的测试生成方法可以提高服务的正确性,如文献[19]就描述了一种主动方法,支持由不同类型问题触发的服务组合。该方法允许将一个或一组服务操作替换为动态组合的操作来改变组合工作流。为了应对在线用户需求多变的实际情况,文献[20]结合Web 服务与自适应软件系统,提出了一个基于工作流监控和预测系统模型,支持用户更灵活地表达在模型水平上的需求,在实现动态QoS 计算和预测的同时还可以实时监控系统的运行状态和运行上下文,从而使软件系统能更好地满足用户不断变化的需求,并适应运行过程中动态的环境。然而,这类针对QoS 定量分析的方法大多通过QoS 预测技术指导单一的服务来支持适应过程,缺少对服务操作之间的依赖关系和服务操作的时间序列特性分析。此外,深度学习方法作为一种新兴的机器学习方法,能凭借其本身强大的功能映射能力以多层信息处理和特征提取方式逼近小误差的复杂非线性函数,因此已经应用到引发系统自适应现象的故障预测中,如文献[21]利用卷积神经网络预测轴承的剩余使用寿命,文献[22]提出了一种利用深度卷积神经网络的新数据驱动预测方法,并通过实验证明了该方法的有效性。在众多的深度学习方法中,LSTM 网络善于处理系统运行数据的时间序列,并在各方面都获得了良好的效果。例如:文献[23]验证了一种基于LSTM 网络的航空发动机剩余寿命估计的方法;文献[24]研究了一种基于双向LSTM 网络的故障预测方法;文献[25]设计了一种基于LSTM 网络的新型动态预测维护框架;文献[26]结合双向长短期记忆网络和粒子滤波器方法,构造了一种新的深度学习方法用于工程系统的剩余使用寿命预测。在这些研究中,LSTM 只停留在单级引发可能的自适应现象故障预测,而缺少对软件系统领域的主动自适应的应用研究。
本文受到预测控制模型(model predictive control,MPC)的启发[27],旨在提出一种积极主动的自适应方法,基于历史与运行时的数据特征并采用预测技术让SOS 给出预见性的判断,从而有效弥补反应式自适应被动性的缺陷。
1 模型构建
MAPE-K 模型包含一般自适应控制回路执行过程的关键活动[28],该模型主要由托管系统和自适应引擎两个部分构成。在自适应引擎中,监测器负责感知系统的状态,分析器分析感知到的信息并决定是否需要自适应调整,规划器决策如何适应当前的系统状态,执行器执行适应策略。本文方法适用于基于MAPE-K 显式闭环控制的一般自适应场景,并突出了环境、系统服务质量、自适应目标及自适应策略等关键要素。本节将介绍与这些要素有关的基本模型,并根据这些基本要素构建基于MAPE-K 的主动自适应控制模型,旨在提高SOS 的适应主动性。
1.1 基本模型
1.1.1 环境模型
环境是SOS 外部及内部存在交互的实体,可以是用户元素、物理元素或虚拟元素等之间的交互。SOS 与环境通过一定的自适应控制机制建立交互关系,支持自适应引擎对SOS 内、外部环境进行观察和评估,以实现对SOS 运行状态的判断。环境对应的模型可以表示为托管系统中带有属性的运行环境元素模型,能表征与SOS 实现自适应相关的部分。在通常情况下,环境可以被特定的监测器和分析器监测并响应。本文首先对SOS 运行所依赖的环境实体进行归纳;然后将SOS 运行过程中的每个环境实体(environmental entity,EE)划分为固定的、取值变化的及状态变化的3 类;最后识别出运行过程中各类环境实体的属性状态(attribute state,AS)和属性变量(attribute variable,AV)。环境建模的具体步骤如下:
步骤1根据识别出的AS 和AV,将得到的环境变量定义为集合E={e1,e2,···,en}。由于AS 可看作是AV 在离散域中的个例,因此AV 和AS 可以统一描述为四元组
式中:ve为环境变量的度量值;dome为该变量的取值范围;LVe为刻画该变量程度的语言变量集合,如LVe={低、中、高};MFe为隶属函数集合。
步骤2以笛卡儿积的形式定义AV 的取值空间为
式(2) 描述了SOS 运行过程中环境实体及其分类和属性的取值空间关系。式(2) 中ei的取值范围是一个区间,表示这些环境变量不确定的客观事实,区间的范围可以综合历史经验值和专家知识得到。以e3为例,当电流环境变量取值用语言变量集合{低,中,高} 刻画时,可将e3描述为
步骤3采用区间数的方法构建环境变量隶属函数集合MFe[29]。
1.1.2 质量模型
质量是软件系统服务效能的关键指标,尤其是当自适应引擎运行时,质量又是自适应需求分析的依据。运行时质量模型是SOS 自适应的关键要素,早期ISO9126/25010 标准将质量模型定义为一组特征以及特征之间的关系,这为用户制定软件质量需求提供了基础[30]。按此定义,质量模型既要表征系统的重要属性,如可靠性等相关的性能约束,还要体现这些属性特征的关系。本文定义了一个通用的QoS 模型,度量SOS 服务质量,并将第t个采样间隔处的质量模型表示为
式中:QoSikj(t)表示第i个实体的第j个服务Sij在t时刻第k个服务属性对应的QoS值,在建模中所用的值以t时刻监测到的对应度量值如平均响应时间来表示;fkij表示Sij在环境e中第k个属性的质量函数;δ表示其他的任意输入,如历史时间序列的QoS调优参数;Mkij(t)表示Sij第k个质量的属性矩阵,包括服务成本c、服务可靠性r及系统性能p这3 个属性,其基本形式为
本文将此质量模型用于分析最新知识的可选适应动作,并基于此分析和自适应目标实现了自适应引擎对适应需求的分析[31]。
1.1.3 适应目标
适应目标代表自适应引擎对托管系统的期望。由于SOS 在运行过程中需要自适应目标推动自身演化,因此自适应目标必须能够引导SOS 对不确定性问题进行具体处理。本文按照自主管理系统对高级目标4 种类型的划分,根据一个或多个非功能需求的属性定义自适应目标[32],如服务的可靠性、响应时间及成本等,以此推动SOS 向自适应目标方向调整;同时用时间概率对服务质量目标进行规范,以模糊约束表示模糊目标的规范需求,且允许适应目标根据自身状态的改变而变化,在操作期间也可以通过自适应引擎更新探针以及对执行器实施删除或添加的操作实现新的目标。具体来说,本文将目标最大收益Max(U) 作为自适应驱动目标,对持续时间L求取最大化收益与成本之间的差值,并将这一差值用函数表示为
式中:U表示系统的效用,RC表示仅包含约束条件下的响应收益,xC表示在时间窗口内提供的响应数量,RO表示可选内容的响应收益,xO表示及时响应的数量,K为常系数,s(t) 表示t时刻的服务数量。
1.1.4 自适应策略
适应策略是高度领域化的,定义了需要在自适应引擎上实施的活动规则。一般来说,一个自适应策略可以定义为能够被自适应引擎理解、执行和适应的任何动作序列。参考dTAS 中自适应策略的定义方式[33],本文也设计了如表1所示的自适应策略。

表1 不确定场景的自适应策略示例Table 1 Examples of self-adaptive strategies for uncertain scenarios
1.1.5 托管系统
托管系统是向用户提供服务的SOS,是自适应的主体。因此,托管系统的关注点在于领域知识,即系统的环境。为了支持自适应,自适应引擎需要为监测器和执行器设计可执行的自适应策略用于SOS 的操作。实现自适应的一个常见方法是:只有当一个系统或服务处于静止状态时,才会执行自适应策略。这里的静止状态是指托管系统及其准备适应的服务未处于活动的状态,这种状态能够保障系统安全地调整和演化。当然,这类方法还需要一个组件来处理适应过程中的通信消息和适应状态,以确保在适应前后的一致性。针对这一问题,通常可以采用开放服务网关协议(open service gateway initiative,OSGi)实现,该协议支持动态地安装、启动、停止和更新任意组件。
1.1.6 反馈回路
自适应引擎需要接收来自托管系统的自适应反馈,实现对SOS 的适应。本文根据MAPEK 反馈回路,并借鉴MPC 思想对变化环境和托管系统进行监控[27],在必要时对后者状态进行预测,主动地、预见性地判断自适应需求,支持托管系统从容地调整到符合适应目标的系统配置,从而降低因反应式自适应缺陷带来的服务质量低的风险。
1.2 主动自适应过程模型
基于SOS 的主动适应过程涉及了几个关键问题。首先,SOS 的主动适应过程需要根据系统的可用性指定功能配置,包括如端口访问量的环境条件以及环境中的服务等。其次,SOS 的主动适应过程必须了解其运行上下文将在何时发生怎样的变化。只有基于这些信息,自适应引擎才能确定可能违反其活动配置的具体情况。如果SOS 的主动配置失效,自适应引擎就会主动寻找至少一种可能的适应策略。本文把这种自适应限定于通过分析器来分析是否需要主动自适应的情况。在理想情况下,这种自适应是针对一系列即将发生的上下文事件进行的优化,因此自适应引擎应该满足分析所有可能变化的需求,并为这些事件决策所有可能的自适应方案。目前,已经存在不少成熟的自适应系统的控制模型[4],本文则基于流行的MAPE-K控制回路,并结合1.1 小节介绍的基本概念模型,构建了如图1所示的主动自适应过程模型。
在图1中,自适应引擎实现的自适应过程如下:监测器通过特定probe 从托管系统和运行环境中获取质量与环境数据,然后处理这些数据同时更新相应的环境模型和质量模型;分析器根据已有知识并用预测手段分析系统是否需要自适应,若需要,则分析器将结合自适应目标通过一定的预测模型来分析自适应的策略;规划器会根据预测结果选择自适应动作,最后形成一个或由多个适应动作组成的最佳自适应策略;执行器按照策略执行,此时系统将从当前配置适应到新的配置,如此便完成了一次自适应过程。
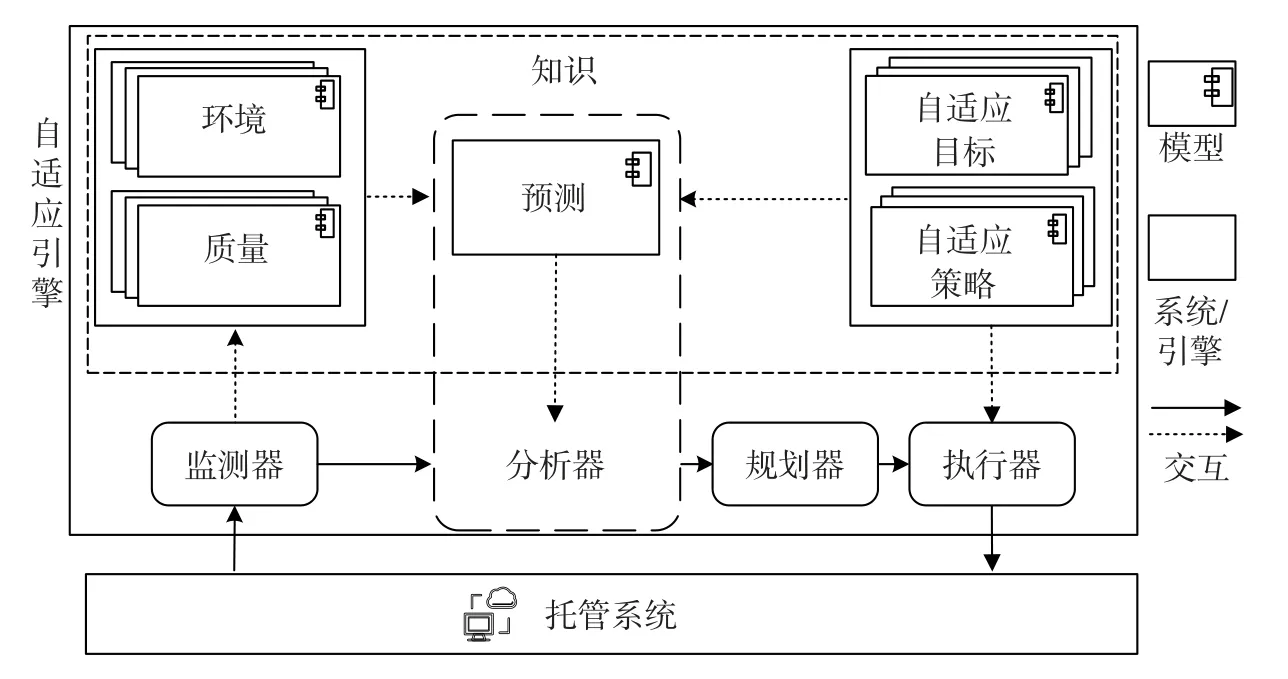
图1 预测驱动的主动自适应过程模型Figure 1 Prediction driven proactive self-adaptive process model
本文提出的模型包含两个关键部分:一是基于预测技术的分析模块,二是基于环境、质量及自适应目标与策略形成的各个知识更新模块,该模型能提供一个简单但功能强大的自适应过程指导框架。基于预测的分析器会评估下一个时刻的SOS 状态,并将评估结果与预定义的约束条件进行比较。若预测的QoS 属性值不符合所考虑的某个质量指标要求的约束条件,分析器就会提示服务违规,并在任何异常发生之前执行适当的适应动作。如果25%的响应延迟率高于用户可接受的阈值,分析器就可以采用可预测托管系统状态的LSTM 预测模型判断有无自适应需求,这有力地提高了系统的预见性。
2 预测驱动的自适应方法
2.1 驱动流程
SOS 主动自适应的目的是避免出现违反SLA 的情况,使系统有预见性地采取一定的自适应策略去保障QoS 不受影响,实现系统效用最大化。本文希望具有灵活和健壮特点的SOS 能够自适应各种不确定的变化,这不仅需要不同的控制行为共同作用于系统,而且要求SOS 不受系统故障或负载等不确定性因素的影响。庆幸的是,作为面向服务的系统在一定时间窗口中具有明显的时序特征,这样就能学习历史数据,并挖掘出这些控制行为对系统状态作用的规律。如果使用过去监测到的系统参数预测在不久的将来会发生什么,并根据预期的目标进行监督,就能生成新的训练示例。如此,系统便能对每一次自适应主动地进行自适应判断,以保持一定水平的服务性能。鉴于此,图2中给出了本文采取的预测思路,可以作为图1所示过程模型的一个组成部分。
图2所示的预测是基于实时与非实时数据结合的过程[34]。一方面,基于离线的历史数据进行训练,同时从托管系统中监测系统参数和环境属性,如交易服务中订单请求的当前位置或顺序。另一方面,通过分类器实时反映托管系统的状态。在系统参数存在更新滞后的情况下,分析器可以促使历史数据重新生成训练模型,但这要求分类器在系统参数发生变化时拥有相关的知识。如果观察到系统平均负载逐渐增加,那么在几周内可能需要一种不同的自适应策略调整系统。本文为了从大量数据中自动提取隐藏于其中且具有特殊关系的状态特征,选择了基于LSTM 神经网络模型进行训练,并利用实时数据对当前系统状态进行实时的知识分类,以促进SOS 快速自适应调整,此时自适应引擎通过监测托管系统的变化将当前的系统参数输入模型,从而在动态情况下生成新的训练实例,同时分析器对托管系统的历史数据进行训练并产生新的离线训练样本。正是因为这种方法只允许对监测到的变化进行后验适应,所以才可能使分析器提前生成预测模型。当这些变化发生时,系统已经拥有主动自适应判断的经验知识。由于训练实例与系统实际情况存在高度相似性,因此可以持续保持SOS 高质量的服务目标。
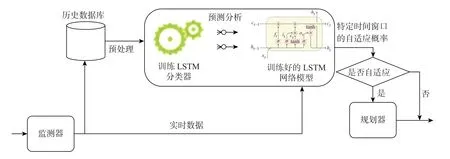
图2 基于LSTM 预测驱动的自适应流程Figure 2 Self-adaptive process based on LSTM predictive drive
2.2 基于预测驱动的主动自适应算法
在主动自适应过程中,工作流是由一组自主运行的任务组成的。SOS 执行这些任务,自适应引擎协调各种资源以保证工作流能在不违反SLA 目标的情况下高质量运行。
基于LSTM 预测驱动的主动自适应算法将工作流建模为一组任务构成的工作流WF={t1,t2,···,tn},其中n表示工作流中的任务数量。将每个任务都表示为一个元组ti=〈C,E,Q〉,其中C表示任务类别或类型,如alarm service、medical service、drug service、assistance service 等[33]。E参考式(3) 确定,表示一组环境量化的水平;任务质量约束表示为Q={q1,q2,···,qj},其中j表示描述任务性能的QoS 属性数量。每个质量属性都是一个元组qj


本文算法首先检索工作流中的任务列表,以及每个任务的相关QoS 自适应目标列表,并基于LSTM 神经网络模型预测每个任务的服务异常行为,最终推荐适当的自适应动作,以维护整个工作流所需的自适应目标。对于每项任务,自适应引擎监测器将提供QoS 的实时记录和历史记录作为训练样本输入LSTM 模型,并通过测试样本测试后用于预测未来的任务执行过程中是否有违反QoS 的情况。当预测值超出某个质量指标指定的SLA 阈值范围时,便会检测到违规的情况,此时该算法根据多个性能指标如平均绝对百分比误差(mean absolute percentage error,MAPE)、均方根误差(root mean square error,RMSE)来评估预测结果,选择自适应目标达成度最高的策略。一旦选择了自适应动作,将根据QoS 指标和性能冲突进行评估。
3 实验评估
dTAS 是一个远程辅助系统[33],集成了嵌入在可穿戴设备中的传感器紧急求助服务和来自医疗保健、药房和提供商的远程服务,可以为身在家中的慢性病患者远程提供健康服务。dTAS 工作流程会周期性测量患者的重要参数,并通过第三方医疗服务机构进行参数分析。分析结果可以触发药房服务,向患者提供新药物或改变患者的药物剂量,也可以调用报警求助服务。如果患者使用可穿戴设备上的紧急按钮,就可以直接调用救助服务;工作人员接收到服务请求后将患者送往救护车并进行及时的诊疗[35]。dTAS 一个典型的服务场景S 如下:

dTAS 为系统实体(system entity,SE)设计了一个MAPE-K 循环,能够在系统适应阶段为下一个工作流的执行选择所需的服务。这些服务具有某些属性,如成本和故障率,而SE 有自己的属性阈值,例如服务组合的成本需要小于20.0 (cost lower_than 20.0),SE 可以通过注册各种服务处理规定的工作流任务。Knowledge 保存了一个负载故障表,其中包含关于每个已注册服务给定负载的故障率变化信息。开始时此表只保存每个已使用服务的默认故障率,每次调整后将根据最后一次工作流运行后新收集的数据更新Knowledge。Planner 按照特定的协议,通过直接消息传递与其他服务进行通信,可以在执行期间调用Analyzer 重新评估服务组合。实验时可以访问每个实体的服务注册表,允许为工作流选择需要的各种服务,从而创建一个服务组合,但实体之间并不知道彼此的目标和可用服务注册表,且一个服务可以注册两个不同的实体。由于服务的故障率随着使用量的增加而变化,因此实体根据消息通信掌握彼此使用哪些服务,并通过改变它们所选择的服务组合来提高满足目标要求的数量。
3.1 数据收集
实验采用图1所示的过程模型重新配置dTAS,在Algorithm 1 的指导下执行场景S 所示的工作流。采用3 个SE 同时运行的工作模式;设置第1 个SE 自适应目标为min(cost),第2 个SE 自适应目标为max(reliability),第3 个SE 的自适应目标为min(cost)和max(reliability);protocol type 为默认,rating type 为class,max protocol messages 为40,protocol data usage 为100%;执行4 770 次自适应循环,且每次自适应执行2 000 次指定的工作流;最终将实体满足的自适应目标率、系统满足的自适应目标率、实体组合的理论故障率、系统组合的实际故障率及实体组合的理论故障率与实际故障率之差依次记为ER、SR、EFR、SFR、FRE,并将服务在运行时段内累积的调用成本记为cost,最终整理得到如表2所示的大量QoS 数据。

表2 数据集结构Table 2 Data set structure
3.2 实验过程
3.2.1 主动性分析
为了说明本文提出的预测驱动自适应过程模型能够支持SOS 主动自适应,本小节先只对预测驱动的主动性进行实验验证,评估在该模型指导下dTAS 是否具有自适应需求的预见能力。
3.2.1.1 数据准备
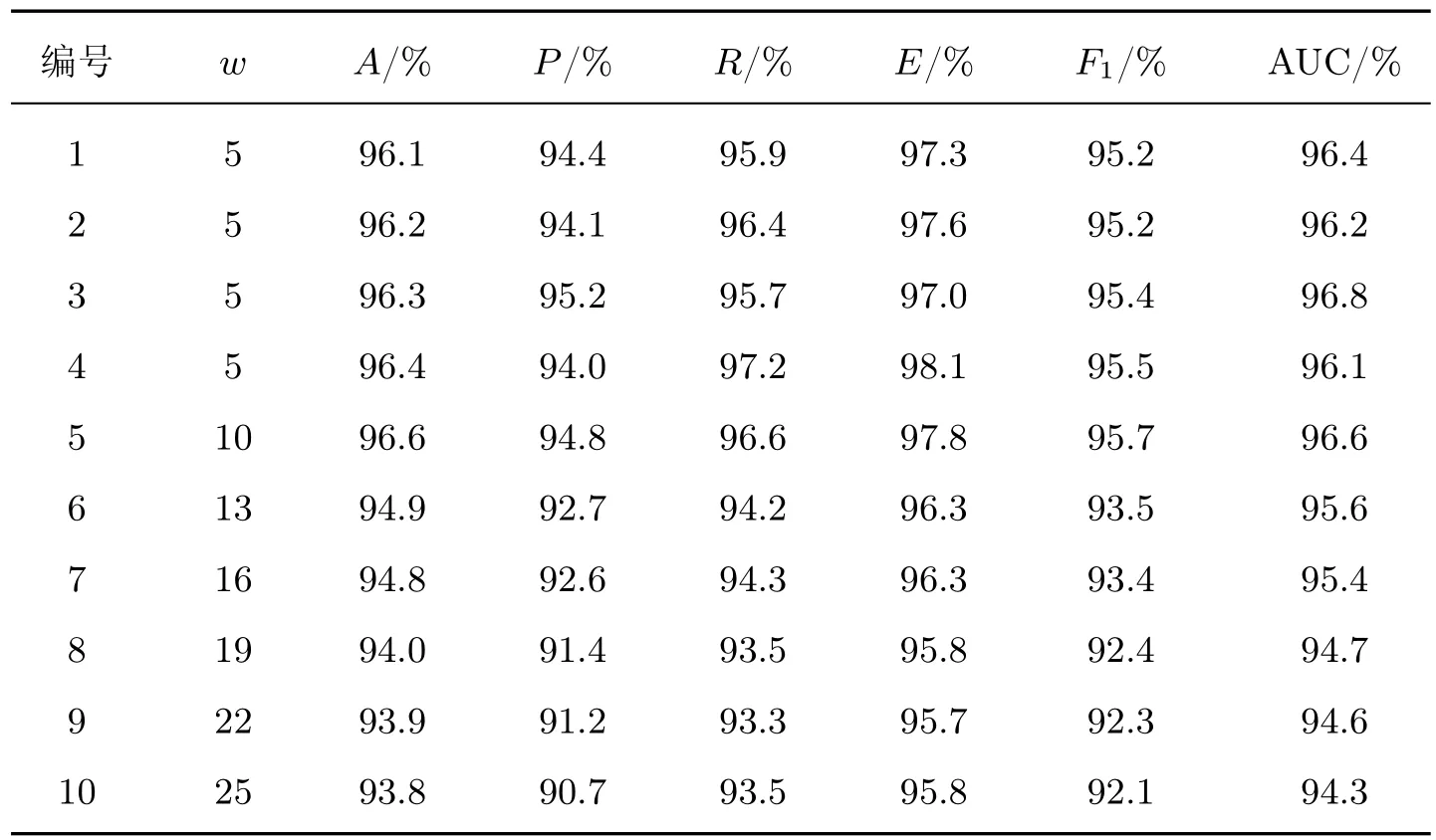
表2结构所示的数据是从不同的SE 中获得的,本文随机选取SE 2 作为分析对象。考虑到该实体注册的QoS 范围不同,为了消除这些数据的异构性,形成规范的数据集,这里采用最小-最大归一化的方法对收集到的数据进行预处理,使处理后的数据落在[0,1]范围内,从而确保所有指标在系统运行条件下贡献的平等性。实验采用Keras/Tensorflow 2.8.0 深度学习库构建深层的LSTM 分类模型,将自适应循环的次序作为时间序列,以时间滑动窗口模式进行预测[34],也就是根据前一个时间步长预测下一个时间步长,这样窗口滑动一个单位就形成一个预测结果。本文统一将70% 的数据集作为训练集,剩下的30% 作为测试集,并选取值为1 的自适应循环作为正样本,值为0 的自适应循环作为负样本,计算FRE。为了便于评估决策的质量,实验只对有无自适应需求进行分析,而不去识别和执行任何适应计划。当系统需要进行主动自适应预警时,根据时间窗口将数据标记为两个类别Cate0和Cate1。Cate0表示当前距离自适应需求到来的时长t大于w,Cate1表示当前距离自适应需求到来的时长t小于等于w,t由测试样本的中位数确定。图3显示了实验采用的深度LSTM 三层结构,包含输入层、隐含层和输出层。
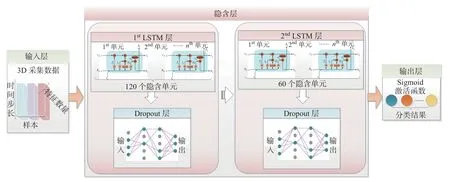
图3 LSTM 结构Figure 3 Structure of LSTM
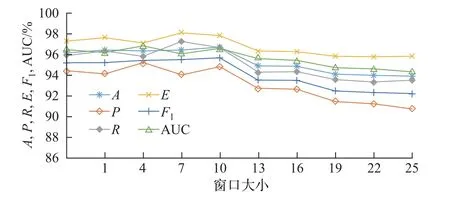
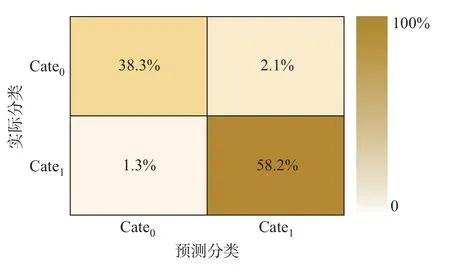
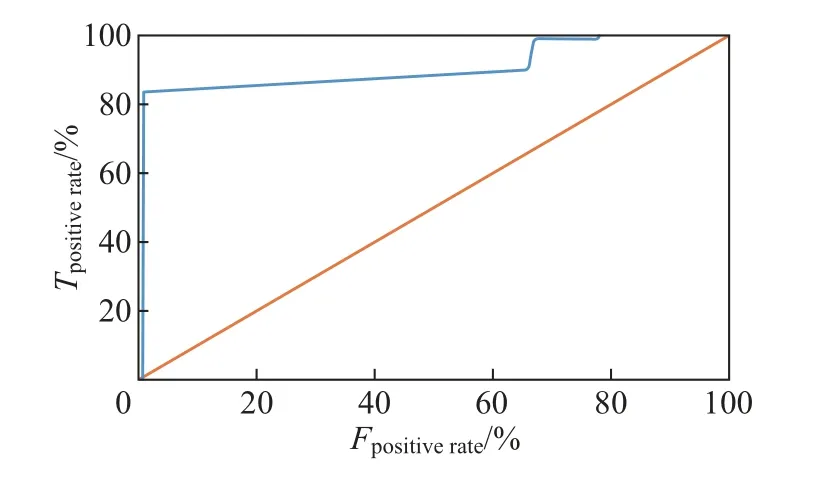
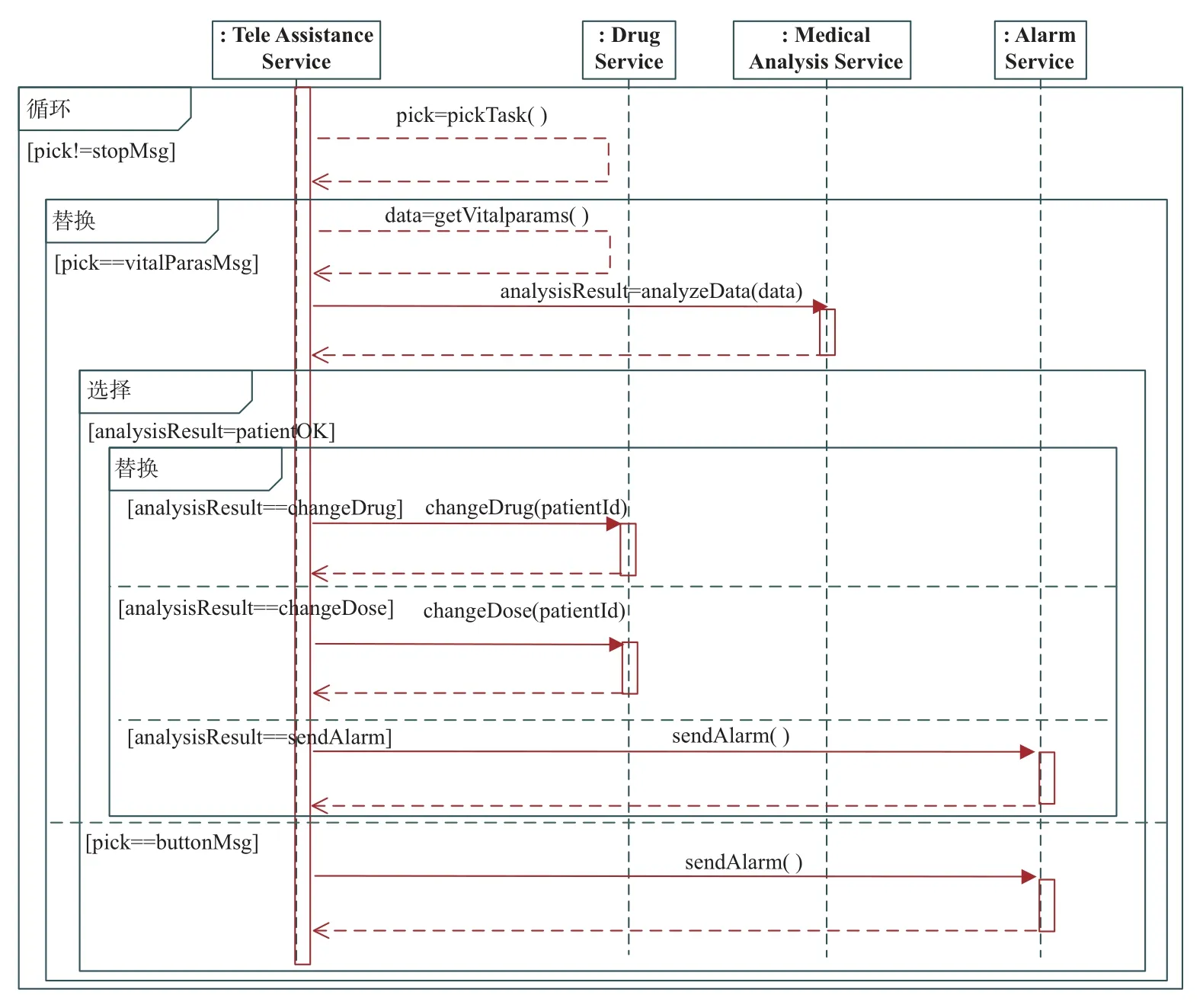
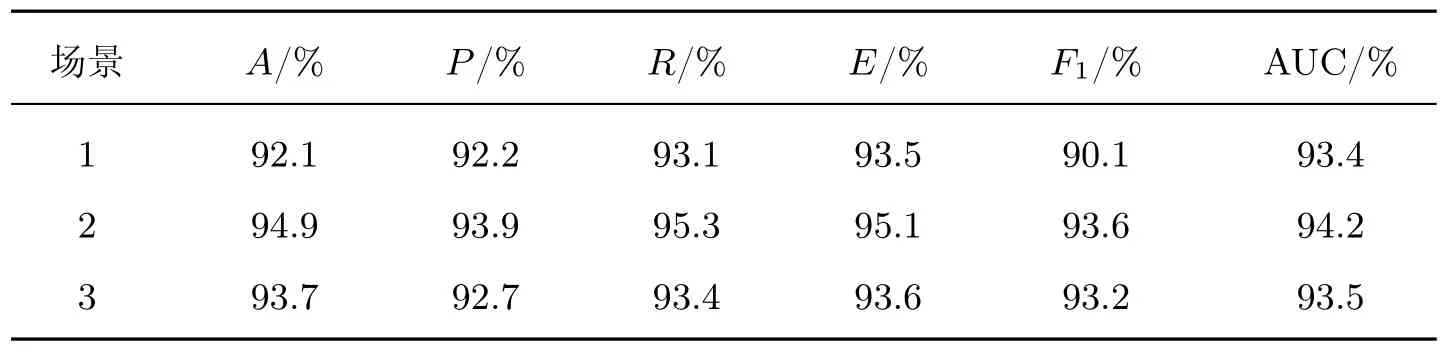
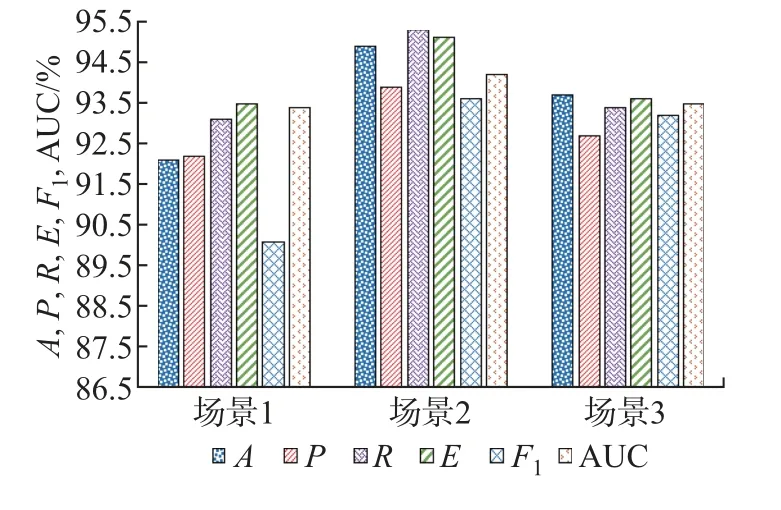
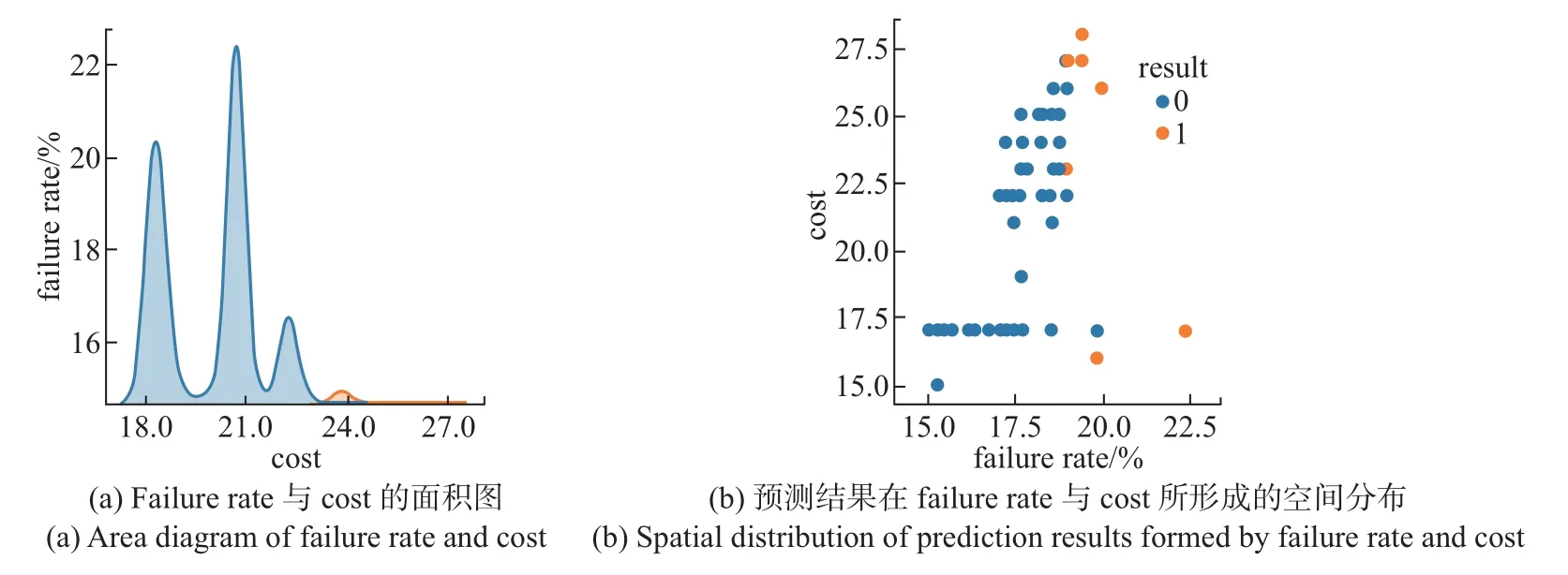
在输入层将QoS 数据代入LSTM 的网络层,并将输入数据重构为形如[样本,时间步长,特征]的LSTM 预期3D 结构。为了将全部服务系统决策结果预测值进行分类,应使时间步长满足测试集中记录数据的最小长度要求。隐含层介于输入层和输出层之间,该层是模型训练和测试的核心部分。这里采用双层结构,分别设置120 个和60 个单元。另外,为了避免神经网络训练数据的过拟合问题,实验时在每个LSTM 隐含层串联Dropout,并用正则化方法在正向传递和权值更新的过程中对LSTM 神经元的输入和递归连接进行概率性失活。输出层是包含Dense() 的全连接层,该层用作网络和输出之间的原型,允许将隐含层输出处的三维张量转换为分类器输出处的一维数组。本文将分类器输出定义为两个元素的向量,这些特征描述了观察结果属于两类的概率:Cate0(w 训练LSTM 分类器时,选用了专门用于解决二分类问题的binary_crossentropy 作为目标函数的损失函数loss,并采用了在深度学习模型中常用的Adam 优化算子。该算子是随机梯度下降算法的扩展式,具有计算效率高、内存需求小以及对大数据适用性高等优点。为了评估模型的性能,将度量功能定义为可提供平均预测准确率的binary_accuracy。 3.2.1.2 评价指标 实验根据列联表分析法,评价基于LSTM 预测驱动的自适应模型对自适应需求的预警效能。自适应预测能以两种可能的状态终止:警告或忽略。根据表3所示的列联表,将警告定义为一个积极的决策P,断言在不久的将来系统将违反适应目标;将忽略表示为消极决策N,表示在整个执行过程中将不需要自适应。对于一个积极的决策,若最终真的发生了违反适应目标的情况,则它是一个真阳性(true positive,TP);否则,它是一个假阳性(false positive,FP)。类似地,如果在执行结束时没有真正发生违反目标的情况,那么消极的决策可以是真阴性(true negative,TN),也可以是假阴性(false negative,FN)。对角线上是TP 和TN,即正确的分类,而不在对角线上的则是错误的分类。 表3 列联表结构Table 3 Structure of contingency table次 本文选用准确率A、精确率P、召回率R、效率E和F1值衡量实验中二分类模型的优劣,具体计算公式如下: 式中:A表示分类正确的样本数占总样本数的比例,P表示预测为正类的样本中真正类所占的比例,R表示在所有正类中被预测为正类的比例,E表示正确的忽略在所有忽略中所占的比例,F1为P与R的调和平均。 3.2.1.3 参数设置 定义LSTM 的相关参数如表4所示。在模型训练过程中,本文以Keras 中的callbacks回调机制加快训练过程并保存最佳分类模型。一旦损失值或准确率收敛、达到最优值就停止训练。 表4 LSTM 基本参数设置Table 4 Basic parameter settings for LSTM 3.2.1.4 结果分析 考虑到不同的测试因子对基于LSTM 预测的自适应模型扰动的影响,实验前4 次采用固定时间窗口滑动,后6 次采用变动的时间窗口滑动,得到如表5所示的预测分类结果。为了便于分析,进一步将表5可视化为图4。 表5 分类预测结果Table 5 Classification prediction results 根据表5和图4展示的实验结果可以看出:在第1~4 次测试中,当取同一时间窗口w=5 时,该模型在同一工作流场景下的自适应需求预警分类的效果较好,平均准确率约为96.3%。预警观测结果较为稳定,差值浮动约在0.3%以内,说明对于存在自适应需求的情况可以较好地预警,且对于没有自适应需求的情形也能恰当地忽略,这也说明本文提出的自适应过程模型能够充分赋予SOS 系统主动预测的能力。在第5~10 次测试中,随着w的增大,A有逐渐减小的趋势,最小的准确率为93.8%,与分类准确率最好的窗口w=10 相比,减幅为2.8%。当w >10 时,F1与w呈现反比例变化的趋势;当w=5 时,第3 次测试的曲线下面积(area under curve,AUC)值最大;w=10 次之。特别地,当w为10 时,F1值达到了最大值95.7%,说明这组实验分类器的性能表现最好,系统的主动适应性能最强。 图4 分类评价指标可视化Figure 4 Visualization of classification evaluation indicators 图5展示w=10 时测试集的概率混淆矩阵,结果表明:在1 424 次的测试中,有546 次自适应需求被成功预警,19 次自适应需求被错误忽略;829 次无自适应需求被正确忽略,而30 次无自适应需求被错误预警。A、P、R分别为96.6%、94.8%、96.6%,表现出了较好的预测性能。 图5 w=10 时的概率混淆矩阵Figure 5 Probability confusion matrix when w=10 为了进一步评价LSTM 分类器针对示例场景的性能,分别以假正例率Fpositiverate和真正例率Tpositiverate为横纵坐标轴,绘制了如图6所示的接收者操作特征曲线(receiver operating characteristic,ROC)曲线,同时以AUC 补充二分类评价指标。在图6中,ROC 曲线能够靠拢(0,1) 点且偏离45◦的对角线,使最终形成的AUC 相对较大,说明在自适应循环过程中LSTM 能恰当地判断预警。 图6 w=10 时的ROC 曲线Figure 6 ROC curve when w=10 3.2.2 鲁棒性分析 为了评估本文模型的鲁棒性,实验针对3 个虚拟的工作流场景依次采用工作流时序图(workflow sequence diagram,WSD)表示。场景1 是一个组合片段,包含dATS 典型的交互执行条件和方式、在任何场合下只发生一个序列alt、重复一定次数的loop 及一个可能发生的序列opt,形成了复杂执行路径的时间序列工作流;场景2 只包含换药及调整药品剂量这两种服务;场景3 在场景2 的基础上增加了主动报警和解除报警的服务,形成5 个可能执行路径的复杂工作流。图7给出了场景1 的时序图,另外两个场景也可按此形式绘制。 图7 场景1 的工作流时序图Figure 7 Workflow sequence diagram for scenario 1 为了在同一条件下比较与分析3 个工作流的执行结果,对于每个工作流,以数据收集过程中的设置启动系统并执行任务。采用图3所示的LSTM 网络模型,设定最佳的窗口w=10,并通过200 次迭代评估预测过程模型。表6给出了不同工作流场景下形成的自适应预警分析结果。 表6 场景1、2、3 自适应预警结果Table 6 Self-adaptive alert results for scenarios 1,2 and 3 表6对应的可视化结果如图8所示。 图8 场景1、2、3 的预警评价结果Figure 8 Early warning evaluation results for scenarios 1,2 and 3 LSTM 的预测分析是根据过去执行的知识给出的决策,即使用不同的工作流也可以获得较好的性能。然而从场景1 的结果可以看出:在多任务或多执行路径的情况下,SE 面临的各种不确定性增大,dTAS 的自适应需求也随之增加,这就增大了服务组合失败的可能性,以致在各类评价指标方面略低于工作流相对简单的场景2 和3,由此可见工作流的复杂度也会在一定程度上影响到LSTM 自适应预测分类器的性能。从表6或图8呈现的结果中还可以发现:F1指标绝对差值最大,但仅为3.5%,且对于该评价指标都有高于90.0% 的评估结果,也就是说3 个试验场景的测试结果浮动并不大,从而说明本文模型并非严格局限于特定的工作流场景,而是适用于不同任务工作流的自适应,总体而言具有较好的鲁棒性。 3.2.3 有效性分析 为验证本文中预测驱动主动自适应的效果,本小节在Keras2Java-LSTM1https://github.com/Rachnog/Keras2Java-LSTM的基础上进行实验,实现了图1所示的分析模块。LSTM 预测模型基本配置参数同3.2.1.3 中所述,自适应策略见表1。此外,本文对3.2.1 中实验结果进行观测后发现,系统测试样本中failure rate、cost 及预测结果都存在如图9所示的类似分布特征,即当存在自适应需求时,参数空间分布稳定,但存在大量重复点且重复点几乎均在SE 1 的failure rate 或cost 较大处。为了便于比较,实验时只考虑SE 1 的cost。若分类结果为1,则规定采取reliability−0.01n,n取非负整数的策略使系统实现自适应调整,并以MAPE 作为评价指标选取合适的n,优先保证调整策略满足SE 1 对cost 的自适应目标。对图7所示的场景进行5 次滑动自适应测试实验,并在同样的SE 和服务工作流配置下对未采用本文预测驱动方法的情形同样测试5 次,最后根据记录结果求取了两种情况下各实体EFR、SFR、FRE、cost 的平均值,得到最终结果如表7所示。 图9 SE 1 的3 个参数分布情况Figure 9 Distribution of three parameters for SE 1 表7 两种情况下的自适应效果对比Table 7 Comparison of self-adaptive effects in two cases 从表7的实验结果来看:一方面,有预测分析的自适应可以成功地防止几乎83.0%的自适应目标被违反的情况,这对于高度不确定环境下运行的SOS 系统来讲已是非常理想了。与无预测的第1 次测试相比,带预测的自适应开始时有较大的故障率,但随着时间推移SE 的故障有消除迹象,因为有预测时LSTM 模型在全连接网络的设计下将高维的初始数据转换为低维的中间特性,并使用预测分类将自适应需求映射到最终的自适应预警过程,能够增强系统自适应的主动性。另一方面,SE 1、SE 2 及SE 3 的EFR 均呈现有预测低于无预测的现象,即有预测驱动分析的自适应比没有预测分析的自适应有更好的整体效果。因此,带有预测分析的自适应存在前瞻性的分析,有助于提高系统的自适应准确性。 从SE 的cost 角度来讲,虽然平均只降低了2.5%,但带有预测的自适应过程整体上呈现下降趋势,尤其是SE 3、SE 2、SE 1 的EFR 下降明显,这说明SE 保证了稳定的自适应准确性,同时有效控制了自适应成本。与无预测技术的自适应相比,就SE 的EFR 而言,本文方法通过多维数据的特征提取,充分保障了预测输入的信息量,从而支持了前瞻性的自适应判断,使得dTAS 具有较好的主动自适应能力。 在SOS 运行环境中,SOS 希望通过上下文感知自身行为或改变服务结构,从而适应其所在物理环境、用户社会环境和技术环境等。以预测驱动的模型指导SOS 自适应过程,使得SOS 能够及时且正确地判断自身运行环境的变化,预见性地给出自适应需求判断,从而恰当应对不确定事件,在提高自适应系统主动自适应性的同时也赋予SOS 一定的主动演化能力。本文采用主动分析思路,在历史数据和实时数据的基础上用LSTM 的神经网络模型进行分类预测,使SOS 给出预见性的自适应判断,有效避免了被动自适应的滞后性影响。基于一系列的实验评估结果,本文方法至少表现出了3 个理想的特性:1)能够针对不同的工作流程给出较准确的适应需求预警;2)在不同的工作任务场景下均表现出较好的鲁棒性;3)使用预测技术帮助自适应系统进行前瞻性的适应决策,其自适应效果优于未使用预测技术的情形。

4 结 论
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·七年级数学人教版(2020年10期)2020-11-26
数学物理学报(2020年2期)2020-06-02
今日农业(2019年12期)2019-08-15
今日农业(2019年10期)2019-01-04
今日农业(2019年16期)2019-01-03
商周刊(2017年9期)2017-08-22
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
