
结合贡献度与时间权重的协同过滤推荐算法
2023-03-27 02:04:18贾俊康李玲娟
计算机技术与发展 2023年3期
贾俊康,李玲娟
(南京邮电大学 计算机学院,江苏 南京 210023)
0 引 言
随着互联网和信息技术的普及,人类全面进入web2.0时代以后,就面临着“信息超载”[1]问题,用户想要从海量数据中筛选出满意的结果变得愈加艰难。因此,作为信息过滤工具的推荐系统应运而生,它能够根据用户的需求,快速、准确地向用户进行有效推荐。推荐算法作为推荐系统的核心[2],直接决定了推荐效果。主流推荐算法包括基于内容的推荐、协同过滤推荐和混合推荐三类传统的推荐算法,以及各种与深度学习结合的推荐算法[3-4]。其中,协同过滤推荐算法是应用最为成功的推荐算法之一[5]。它又分为两类,一类是基于模型的协同过滤,另一类是基于内存的协同过滤。后者又有基于用户的协同过滤UserCF和基于项目的协同过滤ItemCF之分[3]。UserCF源于生活中的经验假设:兴趣爱好类似的用户,他们对同一项目可能有着相似的喜好程度[6],这种算法不是分析用户之间潜在的某种关系,而是从用户历史行为数据信息中计算用户相似度,从中寻找相似用户进行推荐,思路简单,易于实现[7]。但是这种算法至少存在三方面的问题:①未考虑时间因素,没有将用户不同时间的评分区别对待;②未考虑跟风用户带来的影响;③未考虑不同用户对同一个项目评分差异过大带来的影响。
由于存在以上问题,传统的UserCF算法的推荐精度仍有待提高。为此,该文设计了一种结合贡献度与时间权重的协同过滤推荐算法(collaborative filtering recommendation algorithm combining contribution and time weight),命名为CTCF。该算法通过定义可信误差阈值与贡献度来减少不同用户对同一项目评分差异过大对推荐结果产生的负面影响;通过在用户相似度计算中引入拟合时间因子与贡献度的时间权重来动态模拟用户兴趣随时间的变化;既充分利用了传统的UserCF算法的优势,又避免其存在的问题,进一步提高了基于用户的协同过滤推荐算法的精度。
1 相关技术
1.1 UserCF算法推荐过程
UserCF的推荐过程如图1所示。

图1 UserCF算法推荐过程
主要步骤为[8]:
①利用用户的历史行为数据构建用户-项目评分矩阵;
②使用用户相似度计算方法计算用户相似度,并找出目标用户的最近邻;
③选择最近邻喜欢而目标用户未评分的项目;
④预测目标用户对第③步中得到的项目的评分,并将预测评分高(即喜欢程度高)的项目推荐给目标用户。
1.2 评分矩阵
假设U={u1,u2,…,um}表示m个用户,I={i1,i2,…,in}表示n个项目。用户-项目评分矩阵可表示为Rm,n={Ru,i},Ru,i是用户u对项目i的评分。表1是5个用户对6个项目的评分示例,其中“/”表示该用户没有对项目进行过评分,评分值为1至5的整数,数值越大表示用户对这个项目喜好程度越高。

表1 用户对项目的评分示例
与之对应的评分矩阵如下:

1.3 相似度计算方法
相似度的计算方法主要有余弦相似性[9]、欧几里得相似度[10]、皮尔逊相关系数[11]等。余弦相似度是两个评分向量夹角的余弦值。欧几里得相似度指的是两个点之间的真实距离。皮尔逊相关系数广泛用于度量两个变量之间的相关性,其计算公式如下:
sim(a,b)=
(1)

2 CTCF算法设计
该文所设计的CTCF算法的核心内容包括:可信误差阈值与贡献度的计算、拟合贡献度与时间因子的时间权重的计算、用户相似度的计算、评分的预测。
2.1 可信误差阈值与贡献度的计算方法设计
如前所述,传统的UserCF算法,在计算用户相似度时,可能会遇到不同用户对同一项目评分差异较大的情况,例如表1中user1和user2虽然共同评分的项目占比为67.7%,但其中至少有75%的项目评分差异较大。这种不同用户对共同项目的评分差异从一定程度上能够反映出用户兴趣的差异,因此,在判断当前用户对目标用户的价值时,应该充分考虑这种差异。该文分别定义了可信误差阈值与贡献度,用可信误差阈值来计算贡献度,依据贡献度来评定当前用户对目标用户的价值大小,从而为进一步计算用户相似度提供权重。
定义1 可信误差阈值:是不同用户对同一项目的评分差异的度量,计算方法如公式(2)所示:
(2)
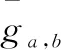
(3)
定义2 贡献度:是用户间的参考价值度量,反映不同用户的共同喜好程度高低,计算方法如公式(4)所示:
(4)
其中,t为|ga,i-gb,i|<χ的数目,|I(a)∪I(b)|为用户a和用户b评分项目的总数量。可以看出sup∈[0,1],且评分相近的项目越多(即共同喜好程度越高),贡献度sup就越大,彼此的参考价值越高。
2.2 拟合贡献度与时间因子的时间权重计算方法设计
如前文所述,传统的UserCF算法忽略了用户兴趣爱好会随时间变化这一事实[12],由此得出的最近邻可能并不准确。一般来讲用户近期的行为更能充分说明其目前的兴趣爱好。随着时间推移,用户会逐渐减弱对某个项目的喜好,这种趋势呈现出先快后慢、最后趋于稳定的特点,这与艾宾浩斯曲线[13]很相似。因此,该文进一步将贡献度与时间因子相结合来对艾宾浩斯曲线加以改进,设计了拟合贡献度与时间因子的时间权重,计算方法如公式(5)所示。
(5)

不难看出,该时间权重既考虑了不同用户对同一项目评分差异过大对推荐结果的影响,又动态模拟了用户兴趣随时间的变化。
2.3 改进的用户相似度计算方法设计
在计算用户相似度时,该文对皮尔逊相关系数加以改进,引入公式(5)的拟合贡献度与时间因子的时间权重,同时考虑目标用户a评价过的项目可能包含某用户b评价过的全部项目(即前者是后者的超集,如表1中user2与user4)的情况,因后者不能为目标用户提供有用的信息,将其视为跟风用户[14],并将目标用户与跟风用户的相似度置零。改进后的相似度计算方法如公式(6)所示:
sim(a,b)=
(6)

2.4 评分预测方法
计算得到目标用户与其他用户的相似度后,按照相似度降序排列,取前K个作为目标用户的近邻集,产生近邻评价过的项目集,并用公式(7)[15]对其中目标用户未评价的项目进行评分预测。
(7)
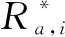
最后,按照目标用户a的预测评分的降序对项目排序,取Top-N个加以推荐。
2.5 CTCF算法流程
CTCF算法的总体流程如图2所示。
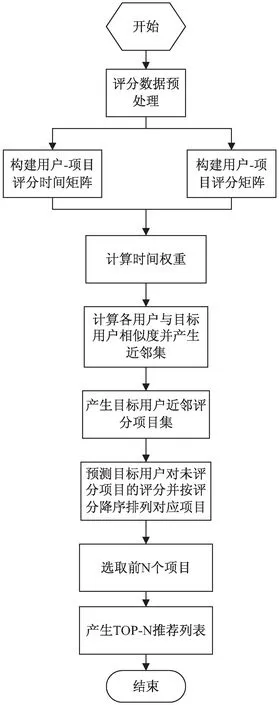
图2 CTCF算法流程
具体步骤可描述如下:
算法:结合贡献度与时间权重的协同过滤推荐算法。
输入:用户评分信息,目标用户a,推荐结果个数N;
输出:推荐给目标用户a的项目列表。
Step1:首先,对用户评分信息做预处理,用公式(8)将时间戳归一化;其中,ti为当前时间戳,tmin为最小时间戳,tmax为最大时间戳。
(8)
然后,构建出用户-项目评分矩阵与用户-项目评分时间矩阵。
Step2:用公式(4)计算贡献度sup,用公式(5)计算时间权重。
Step3:用公式(6)计算相似度矩阵,并产生目标用户a的近邻集以及该近邻集已评价的项目集I,在I中去除用户a已评价过的项目,构成I'。
Step4:用公式(7)预测目标用户a对I'中各个项目的评分。
Step5:将预测得到的评分由高到低排序,并将前N个项目作为目标用户a的推荐集。
3 实验及结果分析
为了测试CTCF算法的性能,做了相关实验。
3.1 实验数据及环境
实验所用的数据是MovieLens ml-100K数据集中u.data文件的数据,有943个用户、1 652部电影、100 000个评分[16]。随机选取其中的75%用作训练集,剩余的25%用作测试集,用户的评分范围为1~5,数值越大表示用户兴趣越大。
实验环境:CPU为Intel Core i7,主频为2.2 GHz,内存为16 GB;操作系统是macOS 10.13;编程语言是Python3.7。
3.2 评价指标
该文采取目前比较主流的推荐算法评价指标召回率(recall)和精度(precision)来评估算法。分别用公式(9)和公式(10)进行计算。
(9)
(10)
其中,R(a)表示算法推荐给用户a的项目集合,I'(a)表示用户a实际喜欢的项目集合,U表示测试集中所有用户的集合。
为了比较全面地评价算法,还采用F-Measure作为评价指标,F-Measure公式如下:
(11)
当参数α=1时,就是最常用的F1值,即:
(12)
F1的值越大表示算法的综合表现越好。
3.3 实验结果分析
(1)可信误差阈值(χ)的有效性实验。
为验证定义的可信误差阈值(χ)的有效性,在χ取常数(0、1、2、3、4)以及用公式(2)进行动态计算的情况下,测试CTCF算法的F1值,结果如图3所示。

图3 不同可信误差阈值对F1值的影响
从图3可以看出,随着近邻数的增加,F1值不断增大,然后趋于稳定,而且采用该文定义的可信误差阈值时,F1明显高于其他几种情况。
(2)CTCF算法总体性能实验。
为验证CTCF算法能有效提升推荐质量,将其与采用皮尔逊相似度的UserCF、使用了改进皮尔逊相似度的文献[17]的算法作对比,统计三种算法的precision、recall和F1值,结果如图4至图6所示。

图4 不同近邻数N对应的precision

图5 不同近邻数N对应的recall
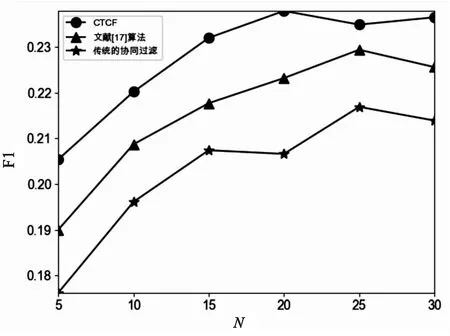
图6 不同近邻数N对应的F1
从图4和图5可以看出,不同近邻数下,CTCF算法对recall和precision有了明显的提升。从图6可以看出,CTCF算法的F1值始终高于另外两种算法。
时间复杂度也是评价一个算法优劣的重要指标,CTCF算法与UserCF类似,最耗时的阶段是用户相似度计算,时间复杂度是O(n2),n为用户数;文献[17]算法的时间复杂度是O(n3)。为对比三种算法的时间开销,进行了相关实验,结果如图7所示。
由图7可知,CTCF算法与传统的协同过滤算法耗时相近,远远小于文献[17]算法。综上,CTCF算法在不增加时间复杂度的前提下,提升了推荐精度。
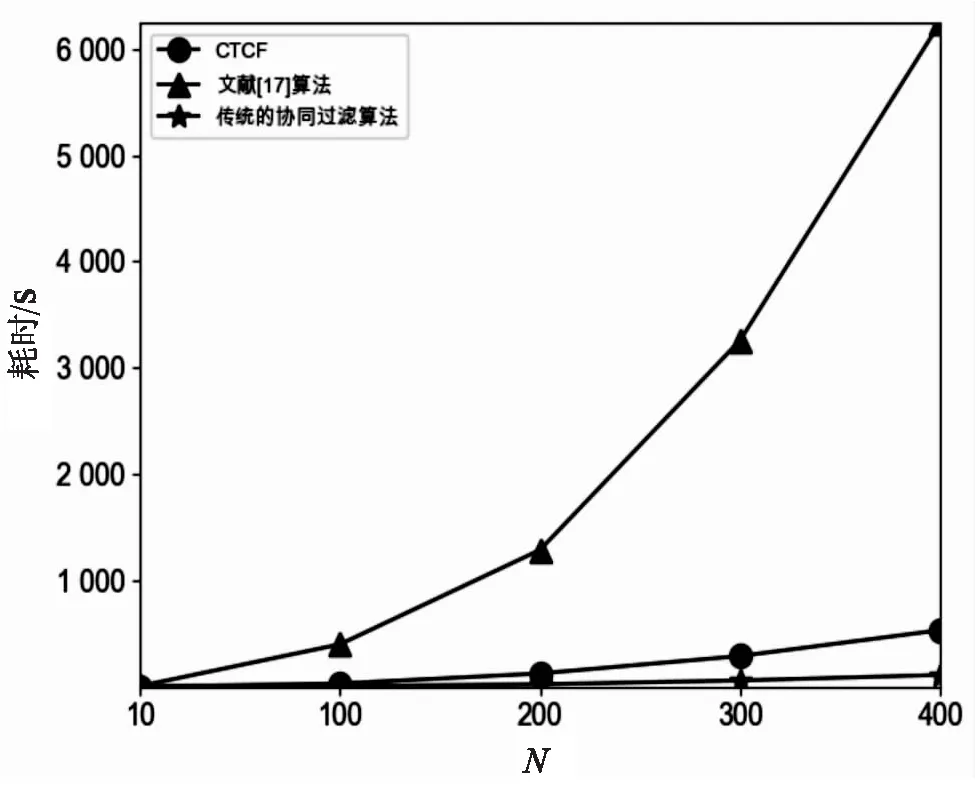
图7 三种算法对应不同近邻数N的时间开销
4 结束语
以提高推荐精度为目标,该文设计了一种结合贡献度与时间权重的协同过滤算法CTCF,该算法对传统的基于用户的协同过滤推荐算法做了改进,在用户相似度计算中引入贡献度与时间因子,降低了不同用户对相同项目评分差异过大带来的影响,同时在一定程度上增大了用户近期反馈行为的权重,对用户早期的行为信息权重进行了衰减,客观地反映了用户兴趣随时间的动态变化。在MovieLens数据集上与类似算法的对比实验结果表明,设计的CTCF算法能有效提高推荐质量。
猜你喜欢
当代陕西(2020年17期)2020-10-28 08:18:18
制造技术与机床(2019年9期)2019-09-10 07:36:54
石河子大学学报(哲学社会科学版)(2019年3期)2019-07-27 01:33:48
中国生物医学工程学报(2019年4期)2019-07-16 08:04:10
西南交通大学学报(2018年6期)2018-12-18 02:22:28
人大建设(2018年5期)2018-08-16 07:09:00
河北遥感(2017年2期)2017-08-07 14:49:00
电信科学(2017年6期)2017-07-01 15:44:57
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
电力自动化设备(2015年4期)2015-09-28 02:42:54
