
融合FCM和TFNs的协同过滤推荐算法
2023-03-27 02:19:22徐新卫邓佳佳
计算机技术与发展 2023年3期
徐新卫,陶 飞,邓佳佳,周 俊
(1.安徽工业大学 管理科学与工程学院,安徽 马鞍山 243032;2.广东科技学院,广东 东莞 523073)
0 引 言
伴随信息技术和互联网的高速发展,数据量表现出几何级稳定增长。而推荐系统(Recommendation Systems,RSs)是有效的信息处理手段之一。为了解决信息过载的问题,RSs主要采用信息过滤的技术,通过用户的历史行为信息提取出用户偏好,减少用户查找信息的时间,并将用户与商品相互联。协同过滤(Collaborative Filtering,CF)是推荐最成功的技术之一,根据相似度指数发现与当前用户相似的用户,然后利用这些相似用户对产品进行评估。基于用户的CF算法(User-Based CF,UBCF)和基于项目的CF算法(Item-Based CF,IBCF)是协同过滤推荐算法(Recommendation Algorithms,RAs)的两种基本形式。算法主要是研究用户行为定位相似的用户。IBCF是利用项目间的相似性来提出与附近用户感兴趣的事物相似的东西。CF算法可以帮助客户找到合适的物品或服务,但它们被诸如冷启动、数据稀少和可扩展性等问题所困扰。
近年来,学者们利用聚类方法[1]来解决CF算法中数据系数以及推荐精度低等问题。贾俊杰等[2]利用了信任的传递性,先计算出显隐式信任获得综合直接信任值,然后再获得Jaccard全局信任值,最后将综合直接信任值和Jaccard全局信任值结合得到综合信任值,将其融入FCM中实现推荐;Tran C等[3]提出了一种新的基于聚类的CF方法,仅仅使用激励/惩罚用户模型(Incentivized/Penalized User,IPU),只由用户给出评级来对用户进行聚类,无需进一步的事先信息从而进行推荐;张建华等[4]针对知识RAs的语义缺失和精准性低的问题,提出一种基于改进的LDA-FCM的知识RAs,利用LDA模型挖掘用户知识模型并用FCM聚类用户,再结合JS散度代替欧氏距离以提高推荐精度;王永贵等[5]提出一种优化聚类的CF算法,根据评分差异对原始评分矩阵进行预处理得到用户项目评分矩阵及项目类型矩阵,构建用户类型偏好矩阵,缓解了数据的稀疏性;赵学健等[6]利用遗传算法(Genetic Algorithm,GA)改进FCM,同时考虑用户特征偏好矩阵和用户项目评分矩阵计算相似度实现推荐;郑鑫等[7]采用FCM筛选最近邻居,结合奇异值分将用户评分分解为不同特征以实现推荐。
通过上述分析,可以发现利用聚类方法对用户进行聚类时,一方面容易受到异常值和噪声的干扰。另一方面,FCM算法的结果并不是很稳定,因为它的起始质心是随意创建的。需要注意的是,基于协同过滤推荐算法(Collaborative Filtering Recommendation Algorithms,CFRAs)进行相似性度量是至关重要的。UBCF和IBCF算法中最常用的相似度量是余弦(Cosine)、余弦修正(Adjusted Cosine,AC)和皮尔逊相关系数(Pearson Correlation Coefficient,PCC)。但在用户行为复杂的情况下,PCC、AC和余弦作为相似度度量的基于CFRAs的性能上无法得到保证。因此,学者们在设计更全面的相似度方面做出了巨大的努力,将用户评分的信息量及模糊性考虑其中以计算相似度,提升推荐精度。
例如,王森等[8]利用梯形模糊数(Trapezoidal Fuzzy Numbers,TFNs)表示评分与满意度的映射关系,融合基于模糊评分的项目相似性和基于标签隶属度的相似性形成项目相似度,从而进行推荐;Zhang等[9]为确定用户的相似度,根据三角模糊数的相似度,将三角形面积和中点用来表达用户对项目的整体评价,从而使相似度计算的准确性得到提高;Yager[10]针对用户分数潜在的信息,采用模糊理论中的模糊子集并结合PCC算出评分的相似度,其后对两部分加权获得最终相似度;吴毅涛[11]考虑多数推荐系统使用离散评分,用户只能在评分级别{1,2,3,4,5}中选择相应的分数,提出了梯形模糊评分模型,将评分模糊化并考虑评分信息量和模糊性,用梯形模糊数来计算相似度以提高推荐质量,并证明模糊相似度(Fuzzy Similarity,FS)是余弦在模糊域上的扩展。
因此,该文提出了一种融合FCM和TFNs的协同过滤推荐算法(Genetic Algorithm Improved Fuzzy C-means And Trapezoidal Fuzzy Number Collaborative Filtering Algorithm,GAFCM-TFNCF)。首先,使FCM与GA相结合,然后,对用户进行聚类,最后,根据FS将离散分数转换成梯形模糊数用来计算用户相似度,从而利用模糊分数预测评分。此方法的优点如下:
(1)将GA的搜索结果作为FCM的初始聚类中心,可以有效避免FCM在迭代过程中陷入局部最小值点;
(2)现有RSs下的评分只能片面地表达用户的偏好,该文通过引入TFNs将评分模糊化,从而计算用户的相似度,这样更能合理表达用户的观点。
1 相关工作
1.1 FCM算法
在实际应用中,基于FCM方法是使用最广泛的模糊聚类技术。它允许数据项属于隶属度从0到1不等的集合,通过优化目标函数来定义样本点的类别,以获得每个样本点对所有类中心的隶属度,从而达到样本数据自动分类的目的。基本如公式(1)所示:
(1)
其中,m是给定数据集中的数据向量总数;c为聚类数目;V={v1,v2,…,vi,…,vc}表示聚类中心;μik(μik∈[0,1])是用户uk对聚类中心vi(i=1,2,…,c)的隶属度;Hm×c=(μik)是一个模糊分区矩阵,也为聚类的结果;M是JFCM(H,V)中的一个参数,一般M∈[1.25,2.5],通常称为模糊器,用来控制成员等级影响的实数。
聚类中心vi和隶属度矩阵H根据以下的公式来计算,使得JFCM(H,V)最小化。
dik=‖uk-vi‖2
(2)
(3)
(4)
(5)
式(2)中,dik(uk,vi)是数据对象uk和簇vi之间的距离值,欧几里得度量来衡量距离值是常用方法之一。FCM算法旨在将方程中的准则函数最小化,距离值dik是通过迭代更新式(3)中的聚类中心vi和式(4)中的隶属度μik,迭代更新重复过程,直到达到条件即终止。
FCM算法流程可以如下表示[6]:
(1)输入聚类数目c,模糊器M和距离函数‖·‖;
(2)初始化聚类中心vi(i=1,2,…,c);
(3)根据公式(2)、(3)和(5),计算uki(k=1,2,…,m;i=1,2,…,c);
(7)停止。
1.2 模糊集和梯形模糊数的运算
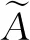
(6)
(7)
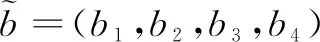
(8)
(9)
(10)
(11)
该文将利用上述公式改进目前CFRAs中模糊相似度的计算,从而进行评分预测。
2 基于改进FCM和TFNs的协同过滤算法
针对模糊相似度的计算,目前CF算法仅采用常规距离和重心距离,存在一定的误差。因此,该文考虑Ahmad S[13]提出的一种新的梯形相似性度量,它结合了几何距离(Geometric Distance,GD)、重心距离(Center Of Gravity,COG)、Dice相似性系数(Dice Similarity Coefficient,DSC)和Hausdorff距离(Hausdorff Distance,HD)。CF算法常用的是PCC、Cosine等计算相似度,但未能考虑评分信息量,并不适用于模糊评分的相似度计算,所以本节采用梯形相似度结合评分信息来进行推荐。
2.1 梯形模糊相似度

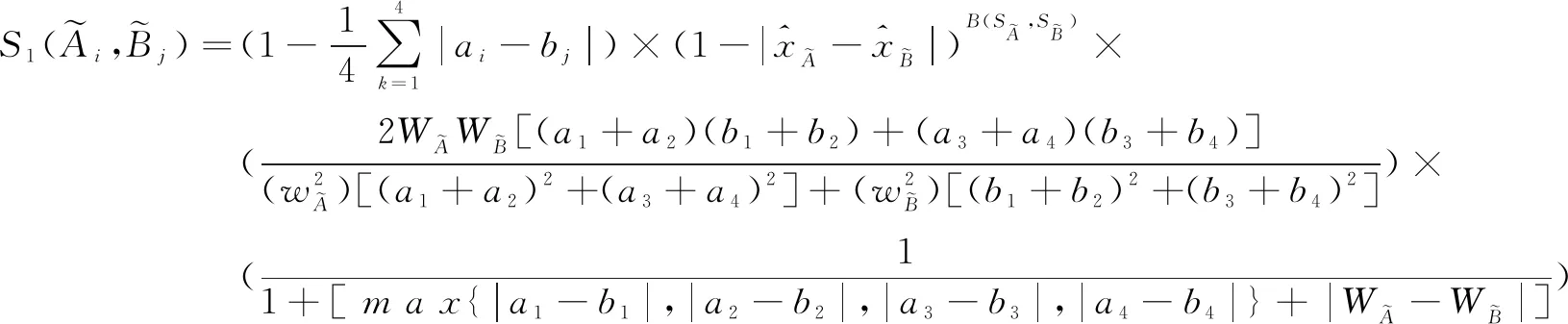
(12)
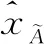
(13)

(14)
(15)
根据GD和COG可以看出两个用户对于一个项目的相似度,再通过加权所有项目相似度获得用户模糊相似度,公式如下:
(16)
由用户u和v共同评价的项目集表示为U,数量表示为n(U),项目i被用户u评价的分数为Ru,i,而用户u评价的项目数是n。
2.2 GAFCM-TFNCF算法流程
因为遗传算法[16-17]在生成优化和搜索问题方面有着较不错的解决方案,目前许多学者已将GA用于处理聚类问题或者将多种不同的方式用来集成GA和聚类方法[18-20],且使用GA优化初始聚类中心和聚类方法的参数[21-22]。所以在用FCM算法进行聚类之前,先利用遗传算法对其进行改进。所提出的模型步骤如下[23]:
(1)对原始数据集进行预处理,搭建出用户偏好矩阵,并将其进行归一化处理;
(2)将GAFCM算法的参数M(种群规模)、m(隶属度因子)、c(聚类的簇数)、pc(交叉率)、pm(变异率)、tmax(最大迭代次数)、ε(收敛的精度)进行初始化;
(3)将从数据集中随机选择初始染色体;
(4)更新最佳染色体;
(5)选择t染色体,利用轮盘赌选择放入选择池中,其轮盘赌是GA的一种选择机制,公式如下所示:
(17)
其中,Pi为染色体i(1≤i≤t)的选择概率,fi和fj分别是i和j的适应值。
(6)随机将两条染色体作为双亲并检查交叉概率,以用来核实是否进行交叉步骤,在交叉过程中生成新染色体的概率定义如下:
(18)
(19)

(7)核实突变pm的概率,以确定是否继续突变步骤,实施编码遗传突变概率定义如下:
(20)
ag=2-u·k
(21)
其中,sg和u为随机数,且sg∈{-1,1}和u∈[0,1],rg为变异的范围,rg∈[10-6,0.1];k∈{4,5,…,20}表示变异的精度。
(8)若满足终止条件则结束,否则转到步骤(3);
(9)将GA的输出结果作为FCM的初始聚类中心;
(10)利用(2)~(5)进行计算获得聚类中心和隶属度矩阵,从而实现用户聚类划分。
在经过上述操作后,利用梯形模糊评分来计算相似度并进行推荐。
(1)相似度计算流程如下:
输入:用户项目评分矩阵R,邻居数量k。
①根据(12)计算目标用户u和其他用户v在一个任务的共同评价方面的相似度S(Ru,i,Rv,i);
②利用式(16)计算模糊相似度sim(u,v)。
(2)产生推荐集。
①作为邻居集,选择相似度最高的k个用户;
②如式(22)所示,采用平均加权方法对预测评分进行加权。
(22)

输出:目标用户u对未知任务的预测评分,获得推荐结果。
3 实验结果分析
3.1 实验环境及实验数据
实验的操作系统为Windows10,CPU为Intel(R) Core(TM) i5-1035G1@ 1.00 GHz 1.19 GHz,实验内存为16 GB,主要实验平台是Python 3.7。为验证GAFCM-TFNCF算法的性能,利用常见的数据集Movielens进行实验,其数据集的描述如表1所示。

表1 实验数据集
3.2 评价指标实验数据设置
将平均绝对误差(Mean Absolute Error,MAE)、均方根误差(Root Mean Squared Error,RMSE)作为实验的度量标准;MAE和RMSE的值越小,预测的估计值就越接近真实值,推荐的准确性就越好。具体定义如公式(23)、(24)所示。
(23)
(24)
其中,用户u对项目i的预测评分值为Pu,i;用户u对项目i的真实评分值是Ru,i;T为测试集;|T|为测试集的数量。
相关参数设置如下:种群规模M=50,迭代数t=50,变异概率pm=0.05,交叉概率pc=0.85,收敛的精度ε=0.000 1,隶属度因子m=2,聚类的簇数c=8。
3.3 算法对比
为了验证算法GAFCM-TFNCF的有效性,对比算法有UBCF、基于用户偏好和项目属性的协同过滤推荐算法UPPPCF[24]、传统基于FCM的协同过滤算法FCMCF[7]、基于项目模糊相似度的协同过滤推荐算法IFSCF[8]。
3.4 实验结果
将80%的数据集作为训练集,剩下的20%作为测试集。对比算法的参数均根据自身文献设置为最优并记录下结果以进行对比。使用MAE、RMSE来衡量预测评分的准确性。为减小由于分割数据集所带来的误差,将10次实验的平均值作为结果。以邻居数量当作变量,间隔为5,比较文中算法(GAFCM-TFNCF)与其它四种算法的预测精度,实验结果如图1所示。
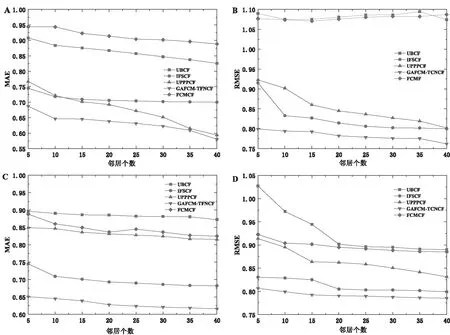
图1 五种算法在数据集100 K和1 M上的MAE和RMSE对比
由图1可以看出,GAFCM-TFNCF算法在所有的对比算法中表现最佳。GAFCM-TFNCF算法相比其余四种算法MAE值要小很多。这表明融合GA和FCM进行聚类,极大避免了在搜索过程中陷入极小值点,然后再将用户评分模糊化能够极大地提高推荐的精准度。对比UPPPCF算法,当邻居数量不断变大后,因为用户对相同项目的评分变得很少,但GAFCM-TFNCF算法的MAE曲线相较于UPPPCF算法更平稳,这表明文中算法在性能表现上更加稳定,不易受到数据集大小的影响,而UPPPCF算法下降幅度较大,说明容易受到数据集大小的影响。
为了比较数据稀疏性对算法精度的影响,实验在Movielens-100 K数据集中进行,核定用户数和项目数不变的前提下,将评分数逐步进行减少,比较五种算法的MAE值,实验结果如图2所示。

图2 不同数据稀疏度下的五种算法对比
通过图2发现,随着稀疏度的不断增加,可使用的数据不断减少,五种算法的MAE值都不断增长,稀疏度在大于95%后增长速度变快。GAFCM-TFNCF算法增长幅度较其余四种算法小,推荐精度更高,表明该算法可以在数据稀疏中完成推荐,其中UBCF算法预测最差,这表明该算法对于稀疏度高的数据集并不适用。
4 结束语
针对推荐系统存在数据稀疏性、未考虑用户评分信息量等问题,提出一种基于改进FCM的用户模糊相似度的协同过滤推荐算法。对于传统FCM聚类对异常值和噪声很敏感的问题,采用GA融合FCM,避免FCM在开始搜索时陷入局部最小值点。同时兼顾梯形模糊评分模型,将离散评分模糊化用来计算相似度,从而更合理地表达了用户对项目的偏好。在推荐算法中采用常见数据集进行实验对比,表明算法具有更优的推荐精准度。在未来工作中,考虑在保证推荐准确度的同时,如何同时保护用户的隐私,这是今后的一个研究方向。
猜你喜欢
幼儿100(2023年37期)2023-10-23 11:38:58
数学小灵通·3-4年级(2020年11期)2020-12-14 07:05:36
数学物理学报(2019年3期)2019-07-23 01:15:32
电子测试(2017年15期)2017-12-18 07:19:27
启蒙(3-7岁)(2017年6期)2017-11-27 09:34:55
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
智能系统学报(2015年4期)2015-12-27 09:38:39
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
