
基于Transformer的时序数据异常检测方法
2023-03-27 02:04:18徐丽燕黄兴挺李熠轩季学纯
计算机技术与发展 2023年3期
徐丽燕,徐 康,黄兴挺,李熠轩,季学纯,叶 宁
(1.智能电网保护和运行控制国家重点实验室,江苏 南京 211106;2.南瑞集团(国网电力科学研究院)有限公司,江苏 南京 211106;3.南京邮电大学 计算机学院、软件学院、网络空间安全学院,江苏 南京 210003;4.南京邮电大学 贝尔英才学院,江苏 南京 210003)
0 引 言
为保障网络系统的正常运行,运维人员需要时刻监控海量的数据。其中,关键性能指标(Key Performance Indicator,KPI)异常检测是一个底层核心任务[1],其目标是根据KPI变化曲线,从大量数据中找出与预期不符的离群点,也就是系统软硬件服务的异常。随着服务系统的大型化与复杂化,需要监控的关键性能指标呈现多样化、规模化的趋势。利用人工智能技术和机器学习算法对大型网络系统进行异常检测成为智能运维技术发展的必然趋势[2]。深度学习算法利用神经网络自动学习特征,凭借强学习能力与高适应力的优势在异常检测领域变得越来越流行,并已应用于各种任务。研究表明,在异常检测领域,深度学习[3]方法已经完全超越传统方法[4]。
传统深度异常检测方法通过搭建神经网络自动化地完成特征提取并对异常进行量化评估。例如,基于自编码器的方法[5]通过自编码器重构原始数据的误差,评估异常值;基于对抗生成网络的方法[6]根据生成器模拟原始数据,通过原始数据与模拟数据的误差以及判别器的值协同评估数据的异常值。而各种神经网络框架如循环神经网络[7](Recurrent Neural Network,RNN)、长短期记忆网络[8](Long Short-Term Memory,LSTM)在异常检测中的应用,一定程度解决了异常检测时间序列在时间上的相关性问题。
更复杂的组合模型也被应用于时序数据异常检测领域。基于RNN、LSTM等循环神经网络和编码-解码框架的网络能捕获长短期的时间序列的趋势[9-10],但RNN、LSTM等方法仍然难以很好地捕获时序中的长距离依赖,并且难以并行计算[11]。Li等人提出了基于生成对抗网络(Generative Adversarial Networks,GAN)的MAD-GAN模型[12],这类基于GAN重构数据的模型相较于自编码器具有更好的生成能力,但对抗生成网络存在着模式崩溃等问题。最近,图神经网络(Graph Neural Network,GNN)也被应用于多元时间序列[13],通过图结构建模变量之间的关系来预测某个节点的值[14],但这类方法过于依赖于单个时间点之间的关联,而没有有效利用序列的上下文信息。
尽管已经提出了很多基于深度学习的异常检测方法,但现有的方法仍有两点不足:
(1)现有的深度学习方法建模序列数据时因其长期依赖性导致模型性能下降。
(2)现有的时序深度学习模型中因其包含递归运算导致模型难以并行计算。
针对以上两点不足,提出一种基于Transformer[15]的时序数据异常检测方法(Devformer)。利用多头自注意力机制[16]并行化地处理当前上下文环境中的全部数据,自动化地提取每个时间节点数据的长距离依赖特征;利用编码-解码框架[17],建立一个端到端的异常得分模型,得到每个时刻异常倾向的量化评估。
相较已有方法,这篇文章的主要贡献有:
(1)将Transformer引入异常检测领域,有效解决异常检测时间序列上下文依赖与神经网络并行化运算问题。
(2)在WADI、SWaT、KDDCUP99与AIOPS18数据集上的异常检测实验中,Devformer表现优于现有的时序数据异常检测的对比方法。
1 相关工作
这部分将主要介绍时序数据的异常检测与Transformer。
1.1 时序数据的异常检测
异常监测是对数据集中不匹配预期模式的离群点进行识别,属于不均衡数据的分类问题[18]。异常检测的核心就在于建立一个合适的模型,自动学习数据的深层次特征,得到正常和异常的决策边界,以区分正常和异常样本。
时序数据指以一定的时间间隔持续捕获的一系列指标数据。网络系统的流量变化,银行的量化交易,工业物联网的环境监控都具体表现为时间序列数据,是系统正常工作与性能变化的最直观反映。因此,通过监测时序数据的变化,实现异常检测是智能运维领域的重要内容。基于时序数据普遍表现出数据量大、监测指标多、异常种类多样的特点,更适合使用学习能力强的深度学习方法实现时序数据的异常检测。
传统的统计学方法通过移动差分自回归[19]等模型分解并平稳化时间序列,异常检测具有明显季节性与趋势性的非平稳时间序列,但由于数据维度灾难的原因,难以捕捉高维或非线性关系,对异常与正常分界模糊的数据分类困难。支持向量机[20]、决策树和随机森林[21]的分类方法与XGBoost[22]等回归算法解决了上述问题,较快且较好地拟合非线性或高维数据,一定程度避免了过拟合的问题,提高了模型的泛化能力。但传统的关键性能指标异常检测方法并没有充分考虑时间序列的上下文信息,难以捕获异常对全文信息的依赖。
在基于机器学习的异常检测方法中,需要对原始数据进行特征工程,提取样本特征。特征的选取决定了异常检测的效果,但却取决于相关领域的专家经验,导致检测效果并不稳定。同时,异常检测时间序列数据量大且异常种类多的特点,决定了机器学习算法在异常检测领域的局限性。因此,引入对大规模高维数据、非线性参数学习能力更强的深度学习异常检测方法。
1.2 Transformer
Transformer作为一种新型的神经网络框架,利用自注意力机制学习数据的长距离依赖关系,利用编码-解码框架实现输入与输出的端到端运算。
注意力是有限的,并且数据中总有冗余信息。Transformer的自注意力机制解决了如何将有限的注意力聚焦在有效信息。自注意力机制捕获数据的长距离依赖关系,以并行运算模式使数据对不同距离数据的依赖关系学习能力相同,解决了LSTM等方法因包含递归运算而导致模型难以并行计算,同时长期依赖性会导致模型性能下降的问题。
Transformer最初被应用于机器翻译[15],用于学习句内单词的相关性。Transformer框架凭借学习长距离依赖关系的优势,较好地适应了时间序列中当前数据值依赖于历史数据的特征。同时,Dai等人引入段级递归机制,有效地解决了Transformer并行运算机制中分批次投入导致的上下文碎片问题[23]。各项研究表明,Transformer在序列数据处理任务表现出较优的性能。Wu等人通过改变编码器的输入与解码器的输入、输出模式将Transformer用于时序数据的预测[24];Bryan Lim等人在时序预测任务中,将LSTM应用于Transformer的编码器并结合门限机制提高了时序预测的精度[25]。
而近年来,Transformer也被应用于时序数据异常检测的任务中。Chen等人在构建的模型中使用Transformer架构建模时序数据的依赖关系[26];Li等人提出的基于生成对抗网络的模型也使用了Transformer组件构成GAN模型的生成器,来挖掘时序数据的深层信息[27];Wang等人将Transformer与变分自编码器(Variational Auto-Encoder,VAE)结合起来,在多元时序数据上进行异常检测[28];Xu等人同样通过Transformer对每个时间点计算自注意力权重来得到点与序列之间的关系[29];这些工作展现了Transformer在时序数据处理上的优秀性能。
2 基于Transformer的异常检测方法
时序型的多维KPI数据及其对应的异常标签为本模型的输入和输出。该文使用滑动窗口方法处理原始时序数据获取窗口数据。
本模型输入的时间序列数据处理为T个长度为m的滑动窗口,每个滑动窗口数据记作Seriest,为模型输入的基本单位。以图1为例,模型将5条数据处理为3个长度为3的滑动窗口。本模型的编码器将输入的Series1…T编码为中间表示C1…T,Ct=fe(xt1,xt2,…,xtm),其中xt1,xt2,…,xtm为Seriest的每个时间点的多维KPI向量数据,fe(…)为Transformer编码器[15]。接着,使用解码器φt=fd(Ct,Seriest),将中间表示Ct和Seriest作为Transformer解码器fd(…)的输入,输出为异常得分Φt。使用分数生成器生成规范化的异常得分dev(Φt),模型假设Seriest的异常得分满足高斯分布,其中Margin为正常值和异常值的阈值,μ和σ为高斯分布的均值和标准差。Seriest中的异常得分表示时间窗口内最后一个时间点数据的异常得分。
本模型训练基于Transformer的异常检测模型,主要分为三个模块:(1)编码器模块,输入为预处理后的窗口数据,输出数据的中间表示;(2)解码器模块,输入为预处理后的窗口数据和编码器的中间表示,输出窗口数据的初始异常分数;(3)分数生成器,将初始异常分数通过分数生成器生成规范化的异常得分,最后通过阈值判别数据中的异常,通过该异常得分模型,当滑动窗口的异常得分Φt>Margin时,判断滑动窗口的最后一条数据为异常。具体流程如图2所示。

图2 基于Transformer的时序数据异常检测框架
2.1 Devformer编码器
Devformer编码器主要分为多头自注意力机制,残差与归一化网络两个模块。
2.1.1 多头注意力机制

注意力机制有三个输入:Query,Key,Value。由Query索引键值Key,计算两者相关性,再加权Value得到注意力矩阵。
Attention(Query,Key,Value)=
(1)
定义三个矩阵WQ、WK、WV分别作为Query、Key、Value取相同值Seriest时的权重,注意力机制能够捕捉序列内部的依赖关系。
(2)
将多维的时序数据切片分别训练,并将多次注意力机制结果用前馈神经网络拼接。多头的机制能够提高模型的训练效率,有助于捕捉更丰富的特征。
Multihead(Q,K,V)=concat[head1,…,
headn]Wo
(3)
headi=Attention(Qi,Ki,Vi)
(4)
其中,n为头的数量,i为头的索引。
2.1.2 残差与归一化网络

(5)
归一化网络基于Seriest的均值与方差,不断调整神经网络中间输出,使编码器输出Ct更加稳定,起到正则化作用。
(6)
在前馈神经网络后添加残差与归一化网络有同样的效果。
2.2 Devformer解码器
Devformer解码器主要分为后遮挡的自注意力机制、残差与归一化网络、注意力解码机制三个模块。
MaskedAttention(Query,Key,Value)=
(7)

WVSeriest)
(8)
其中,mask为与Seriest相同维度的单位上三角矩阵,-inf的含义为负无穷。在进入激活函数前,Query和Key的点积结果需要先经过mask层。mask层将注意力矩阵的上三角置为负无穷,对应激活后的注意力系数趋于0,使当前时刻数据的异常得分与未来时刻无关。
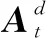
(9)
最后通过前馈神经网络进行降维处理,输出单维的Φt,作为Seriest最后一条数据xtm异常得分。
(3) 若Uα,取V=[α],则对任意的(x,z)V∘V,存在L,使得(x,y)V, (y,z)V。由[α]的定义知(x→y)⊗(y→z)≥α,同时(y→z)⊗(z→y)≥α。
(10)
解码器中的每个注意力网络与前馈神经网络都加入了残差与归一化网络。
2.3 Devformer分数生成器
Devformer以多头自注意力机制的编码-解码框架学习异常得分之后,假设所有数据的异常得分满足高斯分布,构造一个损失函数。基于异常检测时间序列异常数量少而种类多的特征,该文采用偏差网络框架[30],通过高斯分布获取参考分数,建立基于Z得分的损失函数。
Devformer由解码器获得异常得分fd(Ct,Seriest)后,采用先验驱动的方法,从标准高斯分布中随机抽取一定数量的样本,并取样本的平均值、标准差作为参考分数。
r1,r2,…,rm~N(μR,σR)
(11)
(12)
(13)
其中,ri(1≤i≤m)为随机选取的一组数据的异常得分,m为数据量,μR为先验数据集参考分数的数学期望,σR为参考分数的方差。
(14)
引入L(φt,μR,σR)作为损失函数:
L(φt,μR,σR)=(1-y)|dev(φt)|+ymax(0,a-dev(φt))
(15)
其中,y为Seriest最后一条数据的异常标记。
在基于Z得分建立的损失函数中,正常数据的异常得分会向0靠近,异常数据的异常得分会远离0,或保持大于a的值不变,以此实现了正常数据和异常数据异常得分的区分。在异常检测过程中,时序数据xt投入已训练的模型,将输出对应的异常得分Φt。将异常得分在[0,a]范围内的数据归为正常,否则为异常。
3 Devformer模型训练方法
算法1给出了基于偏差网络的Transformer算法的异常得分模型建立方法。
算法1:Devformer模型训练方法。
输入:n维的异常检测时间序列X∈Rn的集合;
输出:异常评分网络Φt∈R。
预处理数据集建立T个长度为m的滑动窗口集合{Seriest};/*m为滑动窗口长度*/
(1)随机初始化编码器向量{Ct};
(2)fori=1 to epochs do
(3)forj=1 to nb_batch do
(4)从训练集随机抽取batch_size个数据投入训练;
(5)将m维序列切成n片,每片m/n维,分别训练后将结果拼接;/*m为n的整数倍*/
(6)编码器编码所有的Seriest为中间向量Ct;
(7)解码器解码Seriest、Ct,获得异常得分Φt
(8)梯度下降最小化损失函数L(φt,μR,σR);
(9)end for
(10)end for
(11)return 0
在数据集中随机采集固定数量的正常数据和异常数据,保证模型单次投入的数据组中正常数据和异常数据数量相等,训练足够数量的异常数据,解决时序数据集异常类别不平衡的问题。
4 实验结果与分析
该文由Python3.8与Tensorflow2.3.0搭建了基于Transformer的时序数据异常检测模型,并利用SWaT、WADI和KDDCUP99、AIOPS18四个数据集评价该模型的性能。表1为数据集基本信息。

表1 数据集基本信息
表1中,Train Rate表示训练集中异常数所占比例,Test Rate表示测试集中异常数所占比例。
SWaT与WADI数据集分别来自新加坡科技与设计大学网络安全中心的配水系统与水安全处理系统的攻击检测。SWaT数据集的KPI来自对应系统的网络流量与51个传感器与执行器的数据,WADI数据集的KPI来自配水系统123个传感器与执行器的数据。
KDDCUP 99数据集来自1999年KDDCUP竞赛的比赛数据,模拟了US空军局域网环境,并监控了34类关键性能指标,其异常来自局域网受到的模拟攻击;AIOPS18数据集来自2018年AIOPS挑战赛的比赛数据集,该数据集由时间戳、一维的关键性能指标与异常标记组成,体现了智能运维在时间序列异常检测领域的代表形式。
上述数据集,长时间、短间隔地记录多维的关键性能指标(如网络流量、传感器与执行器的所有值)与异常检测标签,符合模型异常检测的时序要求与深度学习的大数据量与高维数据的要求。
实验中,偏差网络损失函数的置信度边界值(confidence margin)设置为5.0,高斯分布数据量设置为5 000时,实验结果较优。
设置模型训练次数epochs为800,单次训练投入数据组批数nb_batch为10,一批数据组的数据量batch_size为30。
实验使用准确率(Precision)、召回率(Recall)和F1分数衡量模型异常检测的效果:
(16)
(17)
(18)
其中,TP为正确检测的异常数,FP为检测为异常的正常数,FN为检测为正常的异常数。
异常检测的目标是尽可能完全地检测出异常,在进行实验与模型评估时,更加重视模型在召回率指标上的表现。因此,在保证F1分数更高的同时,该文主要使用召回率作为模型的性能衡量指标。
4.1 异常检测结果分析
将基于偏差网络的Transformer异常检测方法分别与主成分分析异常检测方法(PCA)、随机森林异常检测方法(Random Forest)、基于偏差网络的长短期记忆(LSTM)异常检测方法、文献[12]中基于生成对抗网络的重构方法MAD-GAN、文献[30]中基于偏差网络的深度学习模型Devnet、文献[14]中基于图注意力网络的GDN模型进行比较。其中,MAD-GAN将数据映射到潜在空间,并通过潜在空间重构数据,计算重构损失得到异常得分;Devnet结合高斯先验分布计算偏差损失,通过端到端方式直接优化模型;GDN将数据的每个特征维度作为图神经网络的一个节点,通过节点相似度学习图结构,结合注意力机制计算每个节点的异常得分。
具体实验结果如表2所示,表2中加粗部分表示单个数据集中最优的性能。

表2 不同方法的性能比较
实验结果表明,相较于其他方法,Devformer能够较好地分析出时间序列的长距离依赖关系,能够全面检测出存在的异常,在召回率方面有着显著的优势。
对于SWaT数据集,Devformer拥有最高的召回率,相较于召回率第二的主成分分析方法,提升了高达0.050 2的得分,提升率达6.275%;同样,在特征数量更多的WADI数据集上,Devformer的召回率依然最高,达到了0.982 4,相比于其他对比方法,召回率得分有着平均0.376 4的提升;对于KDDCUP99数据集,Devformer的召回率也超过了0.95,在保证可观的召回率的同时,还拥有出色的准确率(得分超过0.99),F1值也超过了0.97,相较于其他方法,三项指标均为最高水准,体现出了模型优秀的综合性能;同样,在AIOPS18数据集上,Devformer的三项指标均为最高,在Recall值上有着平均0.194 7的提升。
经分析发现,Devformer的性能在大规模数据集中更优。并且,Devformer在特征维度较高的WADI与仅包含六个特征的AIOPS18数据集上,都有着优秀的性能表现,说明了该模型对不同的特征维度均具有良好的适应性。Devformer在WADI数据集中准确率过低,在SWaT数据集中召回率不够高,主要因为训练数据量不足。各深度方法对于AIOPS18数据集的训练效果均不理想,是因为该数据集的关键性能指标维度过低导致的数据中包含的特征信息过少,可以通过抽样重复训练的方法提升训练效果。
4.2 不同窗口大小下Devformer性能分析
Devformer中窗口大小(即序列长度)通过影响模型捕获单个异常对其他数据依赖的最大距离,而对模型性能影响巨大。为了分析不同序列长度对模型准确率、召回率与F1的影响,本实验控制其他变量不变,通过设置不同的序列长度,分析序列长度对模型性能的影响。实验结果如图3所示。

图3 序列长度对模型性能的影响
4.3 Devformer的鲁棒性实验
在实际应用中,训练用数据集是有噪声的,即无法将所有的异常标注。Devformer的偏差网络更关注异常并重复训练阳性数据,减少了假阴型样本的干扰。为了证明Devformer对假阴型数据的抗干扰能力,在训练集中分别增加0%、2%、5%、10%、20%的假阴性样本,比较Devformer分别与主成分分析异常检测方法(PCA)、随机森林异常检测方法(Random Forest)、文献[12]的MAD-GAN、文献[30]中的Devnet、基于偏差网络的长短期记忆(LSTM)异常检测方法在有噪声的KDD训练集中的性能。实验结果如图4所示。

图4 污染训练集对模型性能的影响
实验证明,Devformer具有较好的鲁棒性,即使训练集中有较多的假阴型样本,对模型性能也不会有明显影响。这是因为Devformer采集大量正常数据的异常得分建立正态分布作为参考分数,即使数据中有少量假阴型样本作为异常数据,对模型学习到的分布影响不大。
4.4 不同Transformer层数下Devformer性能分析
在Devformer中设置了不同数量的Transformer层,模型表现出不同的性能,图5显示了三个数据集WADI、SWaT和KDDCUP99在不同Transformer层数的模型中的性能变化。

图5 Transformer层数对模型性能的影响
实验结果表明,该模型在SWaT数据集、KDDCUP99数据集以及WADI数据集Transformer层数分别设置为3层、5层和1层时表现最佳。
当Transformer层数过多时,神经网络过于复杂,会导致过拟合的问题;Transformer层数过少,可能导致简单的神经网络难以学习高维度数据中复杂的异常模式。
5 结束语
该文提出了一种用于时间序列的基于Devformer的深度异常检测方法。首先,通过基于时间窗口的方法预处理时序数据;其次,通过Transformer和基于Z得分的偏差网络建立异常得分模型。实验结果表明,相比于现有深度学习异常检测方法,该方法对于大规模时间序列的异常检测有更好的召回率、稳定性和抗干扰性。
由于Devformer的神经网络较为复杂,模型训练时间偏长,且若训练数据规模过小,模型效果偏差。Devformer中神经网络的简化与提优是很重要的研究课题,可以提高模型训练效率以及对小规模数据的适应能力。
猜你喜欢
《学习方法报》历史中考版(2024年8期)2024-12-31 00:00:00
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国农业信息(2021年3期)2021-11-22 06:44:48
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
传媒评论(2017年3期)2017-06-13 09:18:10
电子设计工程(2017年20期)2017-02-10 03:39:29
电子制作(2016年15期)2017-01-15 13:39:08
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
电子器件(2015年5期)2015-12-29 08:42:24
电测与仪表(2014年13期)2014-04-04 12:04:18
