
面向自然语言处理领域的对抗样本生成方法
2023-03-27 02:04:14方贤进杨高明
计算机技术与发展 2023年3期
张 影,方贤进,杨高明
(安徽理工大学 计算机科学与工程学院,安徽 淮南 232001)
0 引 言
在大数据的时代和人工智能不断突破新进展、新理论的背景下,深度学习(Deep Learning)[1]早已被广泛应用于计算机视觉[2]、语音识别[3]和自然语言处理(Natural Language Processing,NLP)[4]等热门领域,并且取得了令人瞩目的成就。然而研究表明,深度学习模型容易遭到对抗样本的破坏,这引起了人们对其应用程序中重大安全问题的关注。
对抗样本首先是在图像领域被发现的,而后研究人员在NLP任务中(例如虚假新闻检测、情感分析、文本分类等)也发现了对抗样本。与图像对抗攻击[5]类似,文本对抗攻击[6]的全称为文本对抗样本的生成过程,是指对原始输入中的文本添加微小的且难以察觉的扰动。这种被扰动后的文本依旧会使人类观察者正确分类,却导致了目标模型分类错误。除了达到愚弄目标模型的目的,一个有效的对抗样本还应该满足效能保持的要求。效能保持意味着对抗样本与原始样本相比应在语义上保持不变且语法上保持正确。
虽然文本对抗样本是由图像领域发展而来,但经实验证实图像领域的算法基本上不可直接运用到文本领域,因为图像数据和文本数据有着本质差别。具体来说,图像是像素集合的表示,是连续的;文本是符号化的表示,是离散的。对于人类而言,图像中像素的微小变化不会被感知,表达的含义也没有改变,但对于文本的变化可轻易地察觉。在过去十几年的研究工作中,很多学者提出了大量优秀的对抗文本生成方法,范围从字符级翻转[7]扩展到句子级转述[8],也都取得了良好的效果。相比之下,以单词替换为主的词级生成方法在对抗样本的流畅性和有效性等方面表现的更加突出,因此也成为了NLP任务的主要手段。虽然作为主流技术,遗憾的是,关键词的查找和单词排序机制等方面还没有达到理想状态,很难生成质量较高且有效的对抗样本。
1 相关工作
迄今为止,针对NLP任务中对抗样本攻击的研究已有了相应重大进展,以下简要介绍此研究的相关工作。
关于字符级的生成方法,Gao等人[9]设计了特殊的评分函数判断影响分类类别的关键词,并对前K个关键词进行随机插入、删除、替换等操作以扰动原始样本。由于扰动是随机的,生成正确单词的概率较低且对抗样本的可用性不高。在文献[10]中细化了Gao等人[9]设计的评分函数,在情感分析数据集上验证了改进的有效性。Ebrahimi等人[11]通过使用热输入向量的梯度在输入中操纵字符级的插入、交换和删除以构建对抗样本。然而字符级别的扰动通常只会改变字符,这会导致语法错误和文本阅读不流畅。关于句子级的生成方法,Jia等人[12]通过在原始样本末端插入不相关的句子来生成对抗样本;Iyyer等人[13]利用一种回译数据的神经转述模型将原始句子进行复述,经复述输出的句子作为对抗样本。由于句子级别的扰动颗粒较大,对抗样本与原始样本之间的差别也较大。
相对而言,单词级的扰动在对抗样本的质量及攻击成功率方面表现的更加优异。Papernot等人[14]随机地替换输入样本中的单词,这种替换方式无疑会破坏原始样本的含义和语法的正确性。Alzantot等人[15]利用遗传算法(Genetic Algorithm,GA)中的交叉和变异操作生成扰动,减少了对抗样本的替换词数。随后,Wang等人[16]改进了GA,它在可以随机剪切单词的基础之上,还可以随机剪切文本片段,攻击效果也有了一定程度的提升。Ren等人[17]提出了一种基于概率加权词显著性(Probability Weighted Word Saliency,PWWS)的方法,利用同义词替换原始词构造了质量良好的对抗样本,但是生成效率十分低下。Jin等人[18]提出的TextFooler生成算法也利用了同义词作替换词,并且采用了重要单词替换选择机制。虽比PWWS的生成效率有所提高,但仍不理想。Wang等人[19]借助图像领域的梯度攻击提出了快速梯度投影法(Fast Gradient Projection Method,FGPM)应用在NLP任务中,虽然对抗样本能够使目标模型判断错误,但这种直接使用在文本上的方法造成对抗样本可读性差。
尽管单词级生成方法更为有效,但是就目前的研究进展来看,在对抗样本的分类准确率和单词扰动百分比方面还有很大的进步空间。针对此现象,该文提出了一种单词级的对抗样本生成方法,对生成过程进行优化以生成质量较高的对抗样本,并通过实验证明了该方法的有效性。
2 研究方法
2.1 问题定义
文本对抗样本是对原始输入文本进行小的修改而形成的,可以改变文本分类器的判断。给定一个包括一切可能的输入文本的特征空间X={x1,x2,…,xN}和输出空间Y={y1,y2,…,yK},原始输入文本可以表示为x=[w1,w2,…,wi,…]。其中xN表示第N个样本,yK表示样本对应的类别标签,wi表示样本中第i个单词。一个预训练过的分类器f:X→Y,它把输入的文本空间X映射到标签空间Y,将原始样本x分类到正确标签。对于输入文本x∈X,通过添加不可感知的扰动Δx生成对抗样本。一个成功的对抗样本xadv应该符合以下约束条件:
f(x)≠f(xadv)
(1)
其中,xadv=x+Δx,扰动Δx要求足够小且有效。
2.2 生成文本对抗样本
针对文本对抗样本的约束条件,提出的基于单词重要性联合分类概率生成对抗样本的方法能够满足上述约束。
如图1所示,该方法主要分为三个模块:文本表示与预处理模块、生成样本扰动模块和目标模型预测标签模块。接下来将详细介绍这三个模块,完成整个生成过程。
2.2.1 文本表示与预处理模块
在NLP中,将“自然语言”转化为“符号语言”是其本质和核心,所以文本预处理的重要性不言而喻。在此模块中,首先,采用NLTK[20]自然语言处理工具包对原始输入文本进行分词处理。由于英文文本的独特性,可直接根据单词间的空格分割开。因此对于每一个样本x,其分词结果为x=[w1,…,wi-1,wi,…]。其次,利用NLTK的词性标注器对单词进行词性标注。最后,运用预先训练的100维GloVe词嵌入[21]将文本转化为向量。该过程如图2所示。

图2 文本表示与预处理过程
2.2.2 生成样本扰动模块
对抗样本质量的好坏与添加的扰动密不可分。为了生成质量良好的对抗样本,在此模块中主要是生成扰动并对添加的扰动进行约束,利用决策机制在每一步骤中都采用最佳选择。在这项工作中,采用的是基于单词重要性分数联合分类概率选择最佳同义替换词和确定替换顺序。首先,计算单词的重要性分数并过滤停用词,再为其建立同义词集合,根据分类概率从中选择最佳同义词;而替换顺序由单词的重要性分数和最佳同义词的替换效果共同决定。因此,解决问题的关键在于选择最佳候选同义词和确定替换词的顺序。图3为生成样本扰动示意图。
(1)计算单词的重要性得分。
在NLP的文本分类任务中,不同的单词对分类结果产生不同程度的影响,需要对文本中的单词进行重要性分数计算。将输入文本删除单词wi后的文本表示为xwi=[w1,…,wi-1,wi+1,…],oy(x)表示目标分类模型为正确标签y输出的逻辑值,并使用f(·)表示标签y的预测分数。单词重要性分数的计算方式如公式(2)所示:
(2)
根据公式(2)可看出,若删除单词wi前后分类结果不变,则I1(wi)为分类模型预测的差值;若删除wi前后分类结果改变,则I1(wi)为删除wi前后文本被预测为不同类别的差值之和。
一般来说,一段文本语句往往含有不必要的噪声和特征,并不能够对分类器的判定结果起到重要作用,且在不同的文本中,同一单词起到的作用也会有所不同。因此,根据文本特点创建不同的停用词集,过滤“the”、“in”等没有实际意义的单词,可以达到减轻生成扰动的负担的目的。
(2)寻找同义候选词。
为了保证生成对抗样本的单词正确性和语义相似度,即添加扰动后的样本能够使人类尽量无法感知,从而不影响人类的阅读和理解,该文采用与单词的同义词进行替换方式产生扰动,因此对于本方法而言,扰动的最初状态是对输入单词所查找的同义词。

(3)
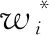
(4)
与此同时,得到新的扰动文本:
(5)
(6)
(3)确定最佳替换顺序。

(7)
根据打分结果对单词倒序排序以获得最佳替换顺序worder。为确保生成质量更佳的对抗样本,再次为扰动添加约束。因为每个文本具有不同长度,所以设置替换上限为该文本单词数量的6%。
2.2.3 目标模型预测标签模块
目标模型预测标签模块是该算法的最后一步,旨在判别对抗样本的标签,它的作用是验证生成的对抗样本是否有效。此模块的具体流程如图4所示。先将生成的扰动根据顺序worder添加到原始样本生成扰动样本,再输入到目标分类模型中得到类别标签,由标签结果决定是否进行更多的替换。若标签改变即成功,否则继续进行替换直到文本分类的结果改变,或者替换单词数量达到上限即失败。

图4 目标模型预测标签流程
采用的主要算法过程如下所示:
算法:对抗样本生成过程。
输入:原始样本x=[w1,…,wi-1,wi,…],标签y,文本分类模型f,替换上限比例6% top;
输出:对抗样本xadv。
1:初始化:xadv←x
2:for eachwiinxdo:
3:根据等式(2)计算单词重要性分数I1(wi);
4:end for
5:建立停用词集stop_words set;
6:for wordwiinxdo:
7: ifwinot in stop_words set:
8: 为单词wi建立同义词集合Li;
9:end for
10:for wordwiinxdo:
11: for candidate wordwijinLido:
12: 根据等式(3)计算同义候选词的替换效果I2(wi)
13: end for
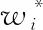
15:end for

17:for wordwiinworderdo:
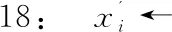
20: iff(x)≠f(xadv):
21: returnxadv
22: else if 单词替换数量达到上限top:
23: return none
24:end for.

3 实验设置与结果分析
计算机将文本数据信息映射到给定的某一类别或某几类别标签的过程称为文本分类(Text Classification)。它被广泛应用在新闻主题分类、情感分析、舆情分析及邮件过滤等场景中。在这一节中,分析了所提出的方法在文本分类任务上的性能。
3.1 数据集与目标分类模型
为了验证生成方法的有效性,在三个流行的数据集上对不同的深度神经网络模型进行分类预测,分别为IMDB数据集、AG's News数据集和Yahoo! Answers数据集。
IMDB数据集[23]:该数据集是用于情感分类任务,数据集中的每个样本都是一个电影评论,类别标签为积极或消极。
AG's News数据集[24]:该数据集是用于新闻文章分类,由世界新闻、体育新闻、商业新闻和科学新闻四个类别组成。
Yahoo! Answers数据集[25]:该数据集由十大类别主题组成,包含1 400 000个训练样本和5 000个测试样本,平均分布在不同的类别上。
目标模型选用卷积神经网络[26](Convolutional Neural Networks,CNN)、长短时记忆网络[27](Long Short-Term Memory,LSTM)和双向长短时记忆网络[28](Bi-directional Long Short-Term Memory,Bi-LSTM),并选用Random、FGPM[19]及PWWS[17]作为实验的对比方法评估文中方法的性能,且每组实验都是从数据集中随机抽取2 000个干净样本进行扰动。其中Random是指随机地选择样本中的单词进行替换,并没有预先计算替换顺序。
3.2 评估指标
为了评估对抗样本的质量,在实验中设置了两种评估指标,分别为分类正确率(Classification Accuracy,CA)和扰动率(Perturbation Rate,PR)。分类正确率是指对抗样本被模型分类准确的比例。它是衡量生成方法成功与否的核心指标,也表示着误导模型的能力。值越小,结果越有效。扰动率是指文本被扰动的比例,也是评估对抗样本质量的重要因素。一般而言,越少的扰动表示着语义一致性越高。两者的计算公式分别如下:
CA=success_count/sum_count
(8)
PR=substitute_count/len(doc)
(9)
其中,success_count表示对抗样本标签改变的个数,sum_count表示输入样本的总个数,substitute_count为被替换单词的数量;len(doc)为样本的长度。
3.3 评估结果分析
表1和表2分别展示了文中方法与其他方法在AG's News数据集和Yahoo!Answers数据集上三个模型的分类准确率对比。由对抗样本误导分类标签的性质可知,对抗样本的分类准确率越小越好。在每组实验中,文中的生成方法都能使得模型达到较低的分类准确率,证明它可以最大程度地欺骗模型并显著地降低性能。实验结果还表明,相比于其他分类模型,LSTM模型使得对抗样本的分类准确率下降的最为显著。
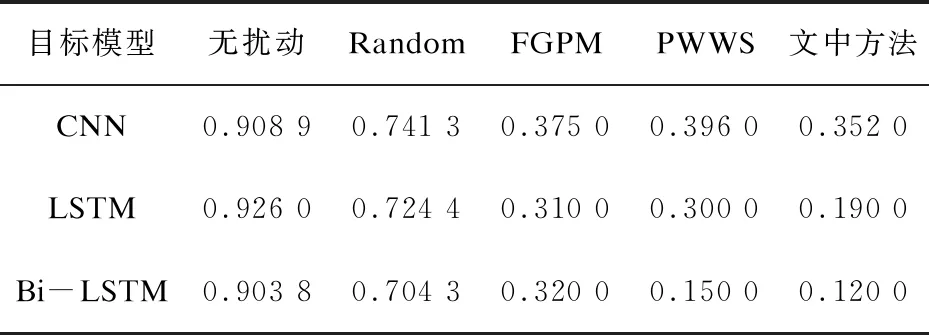
表1 AG's News数据集生成对抗样本的分类准确率(CA)
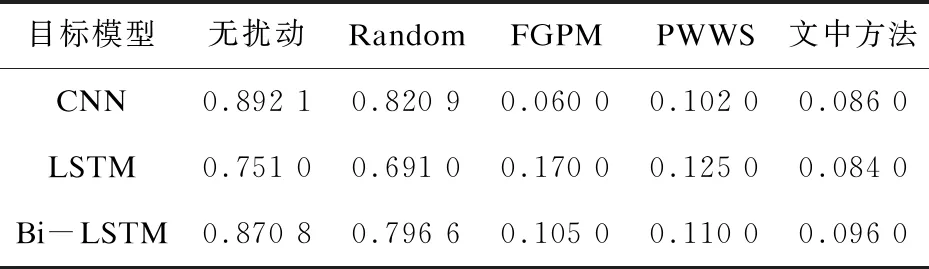
表2 Yahoo! Answers数据集生成对抗样本的分类准确率(CA)
此外如表3中第三列所示,在IMDB数据集上再次验证了该方法可降低对抗样本被模型分类正确的概率。如前所述,扰动率越小,对抗样本与原始样本越接近。在第四列中可清晰地观察到扰动率保持在较小值,亦即替换的单词数量较少,可获得较强的隐蔽性,从而使得对抗样本在语义和语法上与原始文本保持较大的一致性。

表3 在IMDB数据集生成对抗样本的分类准确率(CA)和扰动率(PR)
综上所述,所提出的方法能够在降低分类模型准确率的同时减小样本的扰动比例,使得生成的对抗样本与原始样本保持较高的一致性,不容易被人类察觉。
3.4 对抗训练及案例分析
对抗训练的目的是为了提高模型的鲁棒性。为了验证模型是否提高了正视对抗样本的能力,将IMDB数据集生成的对抗样本加入到其干净样本中,构造一个新的数据集来重新训练CNN模型。结果如图5所示,随着对抗样本数量的增加,目标模型能够更好地拟合这些数据,模型的分类准确率逐步上升。换句话说,对抗样本被经过对抗训练后的模型分类到错误类别的概率在减小,模型的脆弱性得到了保护,也就有了更强的鲁棒性。

图5 对抗训练
表4展示了在IMDB数据集上针对CNN模型生成文本对抗样本的示例。从表中可以看出,在该文本中仅替换1个单词,就实现了将原始标签“积极”错误地判别为“消极”。

表4 IMDB数据集上原始样本和对抗样本示例
4 结束语
在NLP文本分类任务中,针对目标分类模型的脆弱性,提出了一种单词级的对抗样本生成方法。该方法在单词重要性和分类概率的共同作用下生成微小的扰动。在三个文本分类数据集上的实验表明,对抗样本在保持较低的分类正确率的同时具有较低的扰动率,亦即对抗样本质量有所提高。进一步的实验表明,模型在对抗训练后提高了自身的鲁棒性。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:06:36
阅读(快乐英语高年级)(2020年8期)2020-01-08 02:21:16
数学物理学报(2019年4期)2019-10-10 02:38:56
车迷(2018年11期)2018-08-30 03:20:32
智慧少年·故事叮当(2018年11期)2018-05-14 11:48:18
海峡姐妹(2018年3期)2018-05-09 08:21:02
意林(绘英语)(2017年5期)2017-05-15 02:17:23
贵州师范学院学报(2016年3期)2016-12-01 03:53:52
公民与法治(2016年10期)2016-05-17 04:12:58
电源技术(2015年11期)2015-08-22 08:50:38
