
融合注意力的轻量型垃圾分类研究
2023-03-27 02:04:12张国有
计算机技术与发展 2023年3期
张国有,高 希
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
随着中国经济的高速发展,城市生活垃圾产量逐年升高。根据国内统计年鉴数据,城市生活垃圾清运量从2003年的14 856.5万吨[1]增加到2021年的23 511.7万吨[2],平均每年相较2003年增长3.64%。垃圾分类已在国内全面展开,目前需要解决的主要问题是人们生产和生活中产生各种各样的垃圾,人们有时候是很难准确判断出其所属的种类。按照2017年发布的《生活垃圾分类制度方案》,垃圾主要分为“以塑料、金属制品为主的可回收垃圾;以瓜果蔬菜食物为主的厨余垃圾;以过期药品和废弃电子产品为主的有害垃圾;以建筑垃圾为主的其他垃圾”四大类,此分类标准符合中国国情,能够切实地落地实施。
相较于传统的图像分类任务,以落地于实际工程应用为目的的垃圾分类,不仅需要达到高准确率、实时性快的特点,而且还需要具备从多种多样的垃圾图像中提取显著语义特征,以应对生活场景中多种的垃圾类别。近年来,多位研究学者对垃圾分类的细粒度图像分类问题展开了研究,并提供了新思路。赵冬娥等[3]利用SAM判别方法在可回收垃圾的高光谱图像中实现检测与分类,取得了更高的分类准确度,可达到99.33%。高明等[4]针对垃圾分类中类别易混淆、背景干扰等挑战,提出一种新型的像素级空间注意力机制PSATT(pixel-level spatial attention)。薛丽霞等[5]提出一种基于卷积神经网络并融合注意力机制和语义关联性的多标签图像分类方法,可以有效地学习标签之间语义关联性,并提升多标签图像分类效果。马雯等[6]针对人工分拣垃圾环境差、任务繁重且分拣效率低的问题 ,基于现有深度卷积神经网络模型,提出改进的Faster R-CNN目标检测模型与VGG16及ResNet50卷积神经网络相结合的方法,与传统Faster R-CNN算法相比,该方法平均精确度提高8.26百分点,综合识别率达到81.77%,且能够减少图像处理时间。Seredkin等[7]开发了一种基于Fast R-CNN[8]在传送带上检测和分类废物的方法,使得神经网络模型的平均精度为64%。Yang M等[9]使用具有尺度不变特征变换的支持向量机和卷积神经网络。实验表明:支持向量机的性能优于CNN,由于难以找到最佳超参数,CNN并未得到充分训练。
现有的垃圾图像分类方法,其运算准确度能达到90%以上,但在实际应用环境中,模型往往不能直接搭建在现有设备,例如:树莓派开发板、单片机等。造成的主要原因有:模型在算力较好的GPU等设备中训练,与实际应用环境计算能力相差甚远,增加模型参数量虽然能够提升准确率,但是其模型大小远超应用设备可用内存。针对以上问题,该文以ShuffleNet V2[10]网络为基础进行改进,引入SE模块和最大公约数分组卷机方法,从而减少算法运行时间,提升算法性能。主要贡献有:
(1)在ShuffleNet V2网络的基础上,重新设计网络单元结构,以适应网络能够在树莓派等算力小的开发板上低延时运行。
(2)在网络中引入SE模块[11](Squeeze-and-Excitation),通过自适应评估网络单元处理后的每个通道信息,获取相应通道的相应权重因子,从而强化重要特征层的信息。
(3)针对多级分类问题,一方面在网络末端连续拼接214、4个节点的全连接层。另一方面,在损失计算和准确率计算中针对多级分类,引入损失权重和准确率权重,提升模型对多级分类任务的适应能力。
1 网络结构与算法原理
1.1 深度可分离卷积、分组卷积、通道混洗
深度可分离卷积,是将传统的三维卷积核分解为一个逐通道处理的二维卷积(Depthwise Convolution)完成空间相关性的映射操作,和一个跨通道的1×1大小的三维普通卷积核,即逐点卷积(Pointwise Convolution)来增强特征提取,完成跨通道相关性的映射操作。逐通道卷积是完全在二维平面内进行的卷积操作,那么就必须要保证卷积核的数量和输入特征矩阵的通道数相同,如此能够完成映射跨通道相关性任务。而普通1×1大小的三维卷积的卷积核和输入特征图具有相同的通道数,既保证了不同通道之间的跨通道映射,还能够以增加卷积核个数的方式为不同通道增加跨通道映射的可能性。
假设,输入特征图分辨率为Ii×Ii,卷积核尺寸为Ck×Ck,k为卷积核在宽、高维度包含的权值数量,输入通道为P,输出通道为Q。普通的三维卷积经过一次卷积操作后,产生的参数量为W1,计算量为WFLOPs1,如式(1)、(2)所示:
W1=Ck×Ck×P×Q
(1)
WFLOPs1=Ck×Ck×P×Q×Ii×Ii
(2)
深度可分离卷积产生的参数量为W2,计算量为WFLOPs2,如式(3)、(4)所示:
W2=Ck×Ck×1×P+1×1×P×Q
(3)
WFLOPs2=Ck×Ck×1×P×Ii×Ii+1×1×P×Q×Ii×Ii
(4)
相同大小卷积核的深度可分离卷积和普通卷积,在参数量方面的比值为W,在计算量方面的比值为WFLOPs,其计算如式(5)所示:
(5)
当卷积核为3×3×64时,输入特征图通道和输出特征图通道均为64,则传统普通的三维卷积的参数量为36 864,而深度可分离卷积的参数量为4 672,在不考虑偏置的情况下同比缩减为原来的12.7%。经过分析对比可知,采用深度可分离卷积,在轻量化网络方面相较于传统卷积网络能够大幅降低运算复杂度。
深度可分离卷积中的Depthwise Convolution是一种特殊的分组卷积,即:输入特征矩阵通道数、卷积核个数、输出特征矩阵通道数相等的分组卷积。
分组卷积最早出现在AlexNet[12]中,分组卷积和普通卷积过程的不同在于:分组卷积对输入特征矩阵和卷积核进行了分组,卷积核只与相同分组的输入特征矩阵进行卷积操作,不同组之间不进行信息融合。相较于普通卷积在所有的输入特征图上做卷积运算,属于通道密集连接方式(channel dense connection),而组卷积则是一种通道稀疏连接方式(channel sparse connection),类似于全连接层之后的随机失活(dropout)。使用分组卷积的网络如Xception[13]、MobileNet V3[14]、ResNeXt[15]等。其中,Xception和MobileNet采用了深度可分离卷积。在卷积操作过程中,分组卷积和普通卷积参数量WGC、WCC,如式(6)、(7)所示:
(6)
WCC=Ck×Ck×P×Q
(7)
其中,Q表示分组卷积和普通卷积生成相同尺寸特征矩阵的深度,G表示输入特征在分组卷积运算的channel维度的分组数量,且其值必为输入特征和输出特征的公约数。
通过对比公式(6)、(7),分组卷积在参数量方面仅仅是普通卷积的1/G,在计算量方面大幅降低,AlexNet指出在网络结构中用分组的卷积操作,增加filter之间的对角相关性,降低过拟合的风险,具有正则化的效果。但是,分组卷积相对于普通卷积还存在一定的不足:大量的分组卷积在网络中叠加,受限于分组方式,只有属于相同组的特征层才能进行“信息交流”,不同组之间的特征层在网络传递过程中始终保持闭塞状态,降低了网络结果在最终输出方面涵盖不同特征层之间信息表达的可能性。
为提高不同特征层之间信息交流的目的,ShuffleNetV1中使用通道混洗的方式,能够在不增加网络参数量的情况下完成不同特征层之间的信息交流。通道混洗能够完成不同特征层之间的信息交流,且相较于使用逐点卷积,具有不增加网络参数量的优点。其操作流程是在组卷积运算完成之后,将不同分组特征层内部重新分组成与组卷积相同分组数的内部分组,将不同分组特征层中的内部分组特征层按照顺序依次抽取,即可获得通道混洗后的特征矩阵。
1.2 ShuffleNet单元
图1(a)、(b)是ShuffleNet V1网络的两个主要基本单元。在ShuffleNet V1单元(a)中,输入特征经过两条支路,其中右侧分支进行了2次1×1逐点卷积、1次3×3深度可分离卷积以及以此通道混洗操作。而左侧支路则不对输入特征进行任何操作,最终两条支路特征相加、激活,得到最终的输出特征。单元(a)针对输入特征和输出特征维度相同的情况,而单元(b)的右侧支路采用了和单元(a)基本相同的操作,左侧采用了3×3大小、步距为2的平均池化操作。最终,将两侧支路的输出特征在channel维度拼接在一起,得到宽高减半、深度加倍的特征矩阵。

图1 ShuffleNet单元
ShuffleNet V2网络则主要由两个单多次叠加完成,如图1(c)、(d)。在ShuffleNet V2单元(c)中,输入特征首先按照通道数一分为二,相当于对输入特征在channel维度进行了二分组操作,每一组之间有各自的分支结构,左侧进行不采取任何操作的同等映射,右侧进行2次1×1逐点卷积和1次3×3深度可分离卷积,两侧的输入和输出通道数相同。两侧输出特征在channel维度完成拼接融合,并使用通道混洗以保证两侧特征充分融合。单元(d)在维度方面,主要完成通道加倍、宽高减半操作,属于下采样模块。单元(d)右侧相对于(c)的右侧采用步距为2的深度可分离卷积,完成特征的2倍下采样。左侧支路进行1次步距为2的3×3深度可分离卷积和1次1×1逐点卷积。两侧支路通过channel维度的拼接,完成特征的通道加倍。在ShuffleNet V2相较于V1,将通道混洗操作从右侧支路中迁移到主路上,不仅在很大程度上解决了分组卷积阻碍不同特征层“信息交流“的问题,而且能够加强两侧支路输出特征的信息融合。
1.3 ShuffleNet-SENet单元与网络结构
在实际的模型搭建和测试环节中发现,直接使用ShuffleNet V2网络,模型参数量依旧很大,不能部署在树莓派开发板。
为了进一步降低模型参数量,且最大范围保证准确度,秉承以下原则重新设计网络模型:(1)在计算量相同的卷积运算下,输入特征与输出特征具有相同通道数时,参数量最小;(2)在组卷积运算时,参数量随组卷积分组个数呈正相关;(3)网络设计的分支程度越高,耗时越长的分支对网络的运行效率将起到决定作用。
Shuffle-SENet单元如图2所示。

图2 Shuffle-SENet单元
Shuffle-SENet网络对ShuffleNet V2网络的改进主要体现在以下3点:
(1)将ShuffleNet V2单元中多次出现的1×1逐点卷积,替换为1×1最大公约数分组卷积。其中为了尽可能减少分组数量且保证程序能够稳定运行,每次组卷积的分组数是输入特征通道和输出特征通道的最大因数gcd。分组数gcd在网络的不同阶段都是非固定、动态的,例如:输入通道为24,输出通道为54,那么gcd值为6。
(2)在ShuffleNet V2单元末端加入通道注意力机制(Squeeze-and-Excitation)。SE模块通过自适应评估ShuffleNet V2单元处理后的每个通道信息,获取相应通道的权重因子,从而强化重要特征层的信息,忽略其他特征层信息。
(3)为了适应具有多级分类任务的垃圾分类需求,在ShuffleNet V2网络末端加入了两个全连接层。第一个全连接层共214个节点,分别对应214个细分类别。第二个全连接层共4个节点,分别对应4个标准垃圾类别。
Shuffle-SENet网络结构如图3所示。

图3 Shuffle-SENet网络结构
首先,对尺寸不同的图像进行等比例水平反转和224×224的随机中心裁剪,完成数据的预处理操作,将预处理后的图像经过Shuffle-SENet网络第一阶段的卷积层和池化层获得64×56×56大小的特征图;然后,按照Shuffle-SENet网络的二、三、四阶段指定的网络单元重复次数获得192×7×7大小的特征图;最后,网络串联卷积层和全局最大池化层分别将特征图深度提升到1 024、尺寸缩小为1。为了适应具有多级分类任务的垃圾分类需求,在ShuffleNet V2网络末端加入了两个全连接层。第一个全连接层共214个节点,分别对应214个细分类别。第二个全连接层共4个节点,分别对应4个标准垃圾类别。
2 训练优化策略
2.1 数据集与数据预处理
依照国内2017年发布的《生活垃圾分类制度方案》,包括:4个标准类别、214个细分类别,共计58 061张图片,每个标准类别约包含14 515张,每个细分类别约包含270张。标准类别包括:有害垃圾、可回收垃圾、厨余垃圾以及其他垃圾。
在进行深度学习模型训练之前需要将数据集图像进行预处理,根据计算的可靠性和算力支持,首先将所有图像随机裁剪到224×224的统一像素大小,然后按照1∶1的比例对图像进行水平反转。参考Pytorch官网公布的归一化标准,将每张图像的RGB三通道像素值分别调整到均值为0.485、0.456、0.406,方差为0.229、0.224、0.225的正态分布。归一化将数据映射到指定的范围内进行处理,降低计算量,使训练过程更加便捷快速。其计算如公式(8)所示:
(8)
其中,μ为数据均值(mean),σ为标准差(std)。
2.2 损失函数
实验采用交叉熵损失函数(Cross-Entropy Loss Function)来衡量模型预测值和真实值之间的差距。其计算如式(9)所示:
(9)
其中,Closs表示预测值和真实值之间的损失值,m表示训练样本数量,n表示预测类别数量,q(xij)表示样本xi为类别j的真实概率,p(xij)表示模型预测样本xi为类别j的概率。
对于多级分类问题,4个标准类别和214个细分类别的损失值都应该全部列入衡量范围。因此,在公式(9)的基础上加入权重类别损失函数,其计算如式(10)所示:
Cavg=0.9Closs_major+0.1Closs_minor
(10)
其中,Cavg表示权重类别损失值,Closs_major表示模型预测细分类别的损失值,Closs_minor表示模型预测标准类别的损失值。
为了提升网络对标准类别的分类能力,且在实际垃圾分类中对标准类别存在较高的分类能力,对标准类别和细分类别的损失值赋予不同的权重0.9、0.1。本研究针对多级多类别分类问题,使用交叉熵损失函数求导更为简单,能在模型训练过程中加快模型损失计算和更新梯度的速度。
2.3 优化方法
优化算法的选择也是一个模型的重中之重。即使在数据集和模型架构完全相同的情况下,采用不同的优化算法,也很可能导致截然不同的训练效果。如果损失函数是衡量模型预测结果和真实值的差距,那么优化方法就是指导模型在迭代过程中得到最优解。本试验采用SGDM[16](Stochastic Gradient Descent with Momentum)优化器,通过引入动量机制,抑制了SGD的震荡。其优化方法如式(11)、(12)所示:
νt=η×νt-1+α×g(wt)
(11)
wt+1=wt-νt
(12)
其中,α表示学习率,η表示动量系数,g(wt)表示在第t+1次优化时对参数wt的损失梯度,νt表示在第t+1次优化时权重wt+1对权重wt的差值,第一次的权重优化设置ν0为0。实验中设置学习率初始值α为0.01,动量系数η为0.9,在训练周期中学习率会根据优化策略不断调整,以避免网络的震荡难以收敛。
2.4 学习率优化策略
在深度学习传统的优化方法中,学习率α在优化器定义之后总是一成不变的。但是由于模型的权重在初始阶段是随机初始化的,学习率的大小会直接影响模型的稳定性,过大的学习率会使模型震荡难以收敛,过小的学习率则会减慢模型收敛速度。因此,该文提出了自定义学习率优化策略,其计算方法如式(13)所示:
lrf}
(13)
其中,αt代表迭代t次数据集的学习率,lrf代表学习率的迭代相关系数,lrf的值越大,学习率的变换就越稳定,且lrf的取值在0~1之间。
学习率初始值为0.01,经过200个epoch数据集迭代之后学习率下降到0.001,为初始值的10%。此方法通过在迭代数据集过程中动态调整学习率,避免了模型震荡难以收敛的缺点。
2.5 迁移学习
Yosinski等[17]通过大量实验评估了不同位置卷积层的迁移能力,实验发现:低层特征具有很强的迁移能力,而高层卷积层的特征都是和具体任务相关的抽象特征,不适合进行迁移,需要在新数据集上重新学习训练。基于此理论,为了提高模型提取底层特征的能力,实验采用载入底层网络权重并所有权重,重新训练的迁移学习方法。
3 实 验
3.1 实验环境和评价指标
实验中使用到的硬件设备和软件版本以及各种训练参数如表1所示。
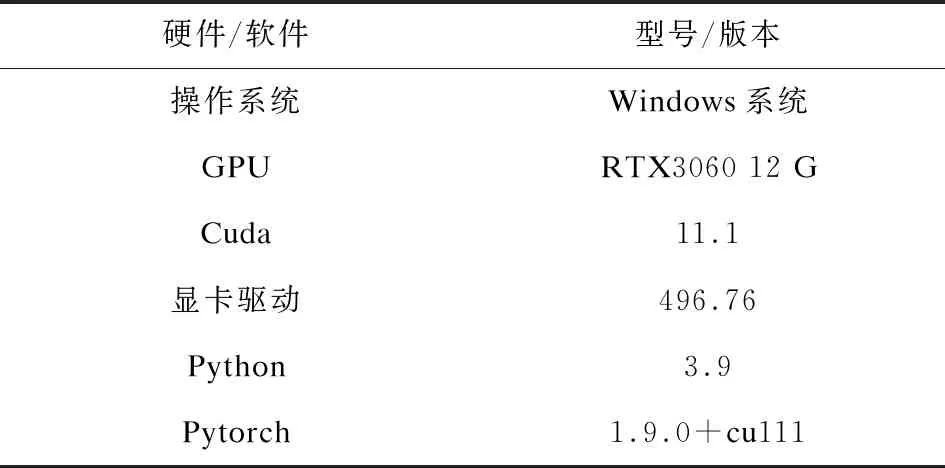
表1 实验配置
评价指标如下:
标准类别的Top1准确率为:
(14)

细分类别的Top5准确率为:
(15)
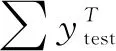
加权类别准确率为:
acc=0.1acctop1+0.9acctop5
(16)
3.2 实验设计和结果分析
本研究搭建了与ShufffleNet网络具有相同版本信息的模型(Shuffle-SENet),并将具有相同版本的不同模型分别完成损失、准确率、运行速度等方面的对比。为验证优化后的模型结构相比ShuffleNet V2原模型的有效性,在百度飞桨提供的垃圾分类数据集上,将数据集的80%划分为训练数据集,20%为测试数据集,进行了相关实验和模型预测。
3.2.1 训练损失值对比
ShuffleNet V2、ShuffleNet V1、MobilenNet与Shuffle-SENet的所有版本,遍历数据集200个周期,在训练集的损失值对比如图4所示。

图4 训练损失值
由训练损失值的结果分析,文中模型所有版本损失值的下降速度和收敛速度均略微优于ShuffleNet V2、ShuffleNet V1、MobilenNet。除却参数量较小的0.5版模型,其余所有模型的损失值皆达到0.1,但所有模型的损失值在180个迭代周期后达到收敛。
3.2.2 预测准确率对比
ShuffleNet V2、ShuffleNet V1、MobilenNet与Shuffle-SENet的所有版本,迭代200次数据集,在测试集的准确度对比如图5所示。
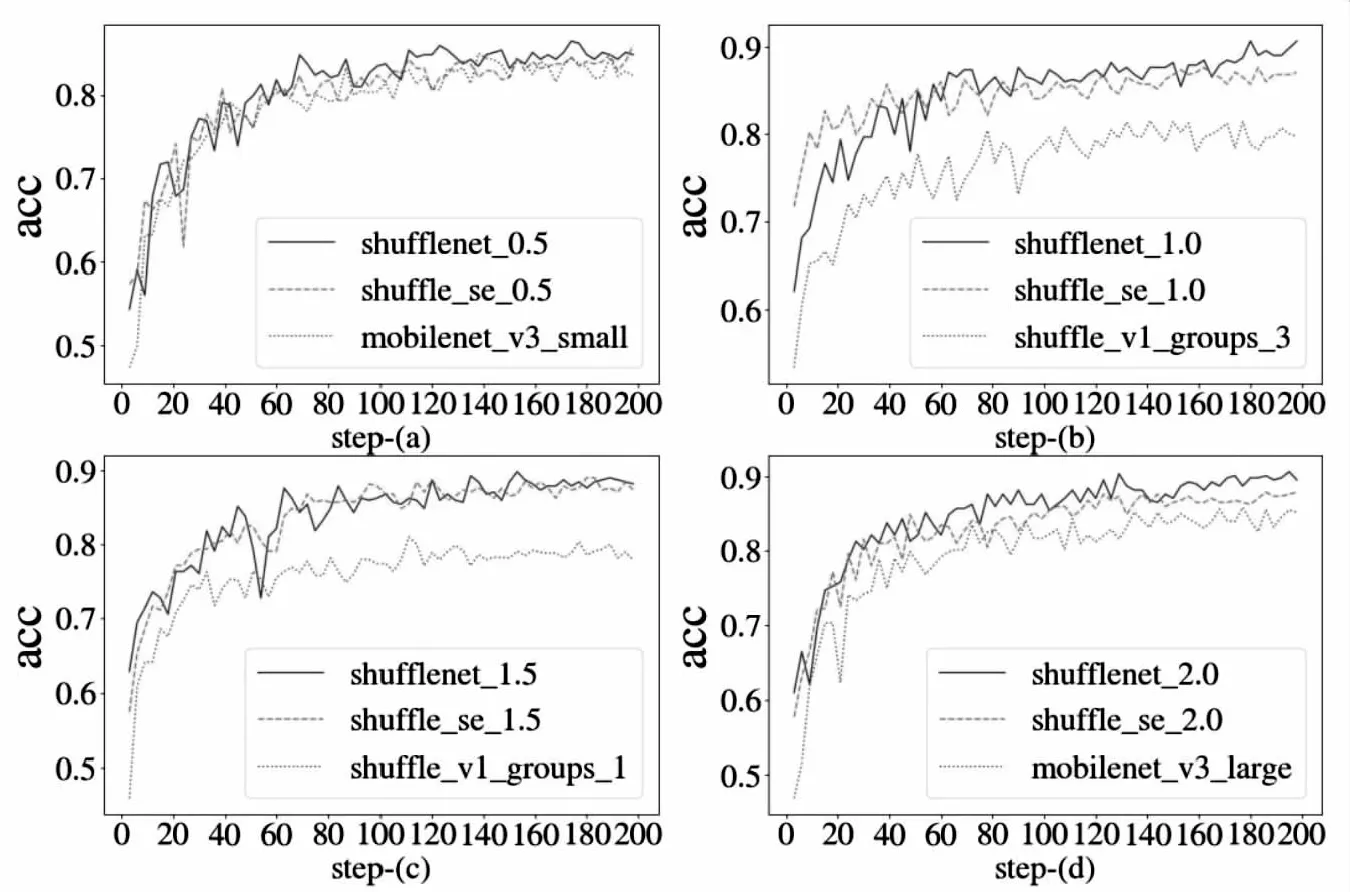
图5 测试准确度
由于文中模型训练采用迁移学习的方法,故模型训练前期存在较高的准确度。由测试准确度结果分析,文中模型的0.5版本相较于ShuffleNet V2、MobileNet即使在参数量大幅缩减的情况下,也能保持基本一致。文中模型的1.0、1.5版本相较于ShuffleNet V2准确率基本相同,还能大幅超出ShuffleNet V1平均0.1的准确率。在迭代数据集180个周期之后,文中模型的0.5版本预测准确度开始收敛,并达到90%左右。
3.2.3 与ShuffleNet V2的运行速率对比
在保证文中模型在准确度方面基本不变的情况下,为了验证采用最大公约数分组卷积的有效性,统计了所有模型分别在CPU、GPU的单帧图像预测时间(Time on CPU、GPU)、参数量(params)以及浮点运算(FLOPs)。如表2所示,文中模型在处理速度方面能够提升30 ms左右,在参数量方面最低降低10%,且特征深度越大参数量降低越明显,在浮点运算量方面能降低32.8%~61.7%。将文中所有版本模型搭载到Raspberry Pi 4B+发板中。模型的0.5版本单帧预测时间1.28 s,平均准确率在80%以上。

表2 不同模型的预测速率对比
4 结束语
在ShuffleNet V2网络的基础上,重新设计网络单元结构,以适应网络能够在树莓派等算力小的开发板上低延时运行。另外,在网络中引入SE模块,通过自适应评估网络单元处理后的每个通道信息,获取相应通道的权重因子,从而强化重要特征层的信息。针对多级分类问题,一方面在网络末端连续拼接214、4个节点的全连接层。另一方面,在损失计算和准确率计算中针对多级分类,引入损失权重和准确率权重,提升模型对多级分类任务的适应能力。综合以上策略,虽然Shuffle-SENet网络在准确率方面略有牺牲,但是在实际运行中基本满足了垃圾分类需求,且能够在树莓派开发板之类算力较弱的设备中低延时、高效运行。在后续的研究之中,可以尝试引入自注意力机制,进一步提升模型从全局信息中提取重要信息的能力和垃圾分类准确率。另外,为了提高模型的实时运行速率,一方面可以从轻量化网络结构设计方面构思,另一方面采用模型压缩的方法对模型进行一系列蒸馏、剪枝、量化等操作,将两种方法结合使用对于提升网络速率极有可能产生事半功倍的效果。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
小学生学习指导(低年级)(2019年3期)2019-04-22 03:34:48
今日农业(2019年15期)2019-01-03 12:11:33
小学生学习指导(低年级)(2018年9期)2018-09-26 05:59:42
小学生导刊(低年级)(2017年1期)2017-06-12 12:07:42
新校长(2016年8期)2016-01-10 06:43:59
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
