
基于Transformer模型的手势脑电信号分类识别
2023-03-27 12:04李赵春周永照冯卫奔王玉成
科学技术与工程 2023年5期
李赵春,周永照,冯卫奔,王玉成
(1.南京林业大学机械电子工程学院,南京 210037; 2.中国科学院合肥物质科学研究院智能机械研究所,常州 213000)
调查显示,脑卒中已成为导致中国居民的第一位死亡原因,也是中国成年人残疾的首要原因。脑卒中后的患者大多会发生手功能障碍,手功能的恢复既是治疗重点也是难点[1]。因此,及时有效的康复训练对重塑患者大脑功能进而改善运动能力至关重要。基于头皮脑电信号的精细手势动作识别是脑卒中患者运动功能康复的重要技术手段。
脑电信号(electroencephalogram,EEG)作为一种电生理信号,反映了最简单、直接的大脑活动状态。它可以以非常高的时间分辨率、非侵入式方式和较低的成本在头皮表面获取,采集方法简单安全。脑机接口(brain-computer Interface,BCI)是大脑与外界的通信通道,通过EEG可以清楚看到大脑中各种各样的思维活动[2]。BCI的关键是从大脑活动中解释运动意图。高效的神经解码算法可以提高解码的精度,但是EEG信号低信噪比导致EEG信号分类精度较低。因此,如何设计更好的实验范式并设计更符合EEG信号数据结构特征的分类识别方法至关重要。
对于精细的手势动作来说,单靠运动想象获取的脑电信号无法获得较高的分类准确率。为了得到更好的脑电信号,通常是采用实际手势动作,而不是运动想象,因为它更直观,从而提高了BCI的性能。
EEG信号相对于其他生理信号更为微弱,一般在微伏数量级,并且由于导联方式,更容易受到干扰。常见的伪迹干扰来自外部电子设备或受试者本身的出汗、肌肉活动、眼动、心电等。在对EEG信号分析前,通常需要对EEG信号进行预处理,最小化伪迹干扰,可以提高EEG信号的信噪比和分类精度。常见的去伪迹方法包括盲源分离(blind source separation,BSS)[3],小波变换(wavelet transform,WT)[4]和经验模态分解(empirical mode decomposition,EMD)[5]。
EEG信号模式识别一直是个具有挑战性的问题,早期的机器方法依赖于过多的预处理和已经确定的信号特征,最佳特征子集和算法没有明确规定。但在近几年里,用于EEG信号分类的深度学习模型已被成功地提出,卷积神经网络(convolutional neural networks,CNN)和循环神经网络(recurrent neural network,RNN)广泛应用于EEG分类中,但它们各有弊病。CNN可以捕捉到局部的接收域信息,但忽略了全局信息。RNN网络无法捕捉空间信息,并行计算效率较低。
近年来,受Transformer在自然语言处理和机器视觉等领域的成功启发,许多研究人员开始探索其在EEG信号分类中的应用。Sun等[6]设计了5种新的基于变压器的脑电信号分类模型,取得了良好的性能。 Liu等[7]提出了一种新的基于自我注意的脑电情绪识别框架。该方法考虑了脑电样本中不同脑区和时间段的不同贡献,以及脑电信号固有的时空特征。 Lee等[8]提出了一种基于变压器结构的注意模块来解码脑电信号中的想象语音,证明了用注意力模块解码想象语音的技术有潜力作为真实世界的通信系统。 Tao等[9]为了捕获长 EEG 序列中编码的时间信息,在 EEG 信号上使用 Transformer 的增强版本,即门控Transformer,沿着EEG序列学习特征表示,实现了新的最先进的性能。Transformer模型在EEG信号分类取得了良好的效果,与CNN和RNN相比,Transformer在处理长距离依赖关系方面表现更为出色,是一个很好的长序列数据识别模型。在长时间序列中,注意力机制可以确定最相关的信息,了解哪些数据部分与最终输出有关。
为增强大脑感觉运动功能皮层EEG信号强度、降低脑机交互过程中的大脑负荷,现设计4种实际手势动作并同步采集EEG信号作为数据处理对象,有效提高EEG信号与手势动作的信号关联度;同时设计一种基于MEMD-CCA的混合去伪影方法,在消除肌电伪影和眼电伪影方面效果良好。为了得到更好的脑电分类结果,结合脑电信号的时间特征和空间特征,考虑多通道脑电采集时体积传导和受试者反应速度的不同,改进一种基于自注意力的Transformer模型:在经典Transformer模型中添加top-k选择,构建top-k稀疏Transformer模型并选择信号特征明显的k个数据段以期提高分类准确率。最后,通过重构脑电信号数据结构,对比分析时间、空间、top-k时间和top-k空间4个变体Transformer模型的分类识别性能效果。
1 脑电信号采集
1.1 脑电信号通道选择
研究表明,人脑对手势动作的控制神经均位于大脑中央前回区域[10]。因此所选16导电极均围绕此区域分布,根据10-20国际标准电极放置法,选择如下16导电极位置:Fz、FC3、FC1、FCz、FC2、FC4、C5、C3、C1、Cz、C2、C4、C6、CP3、CPz、CP4,如图1所示。
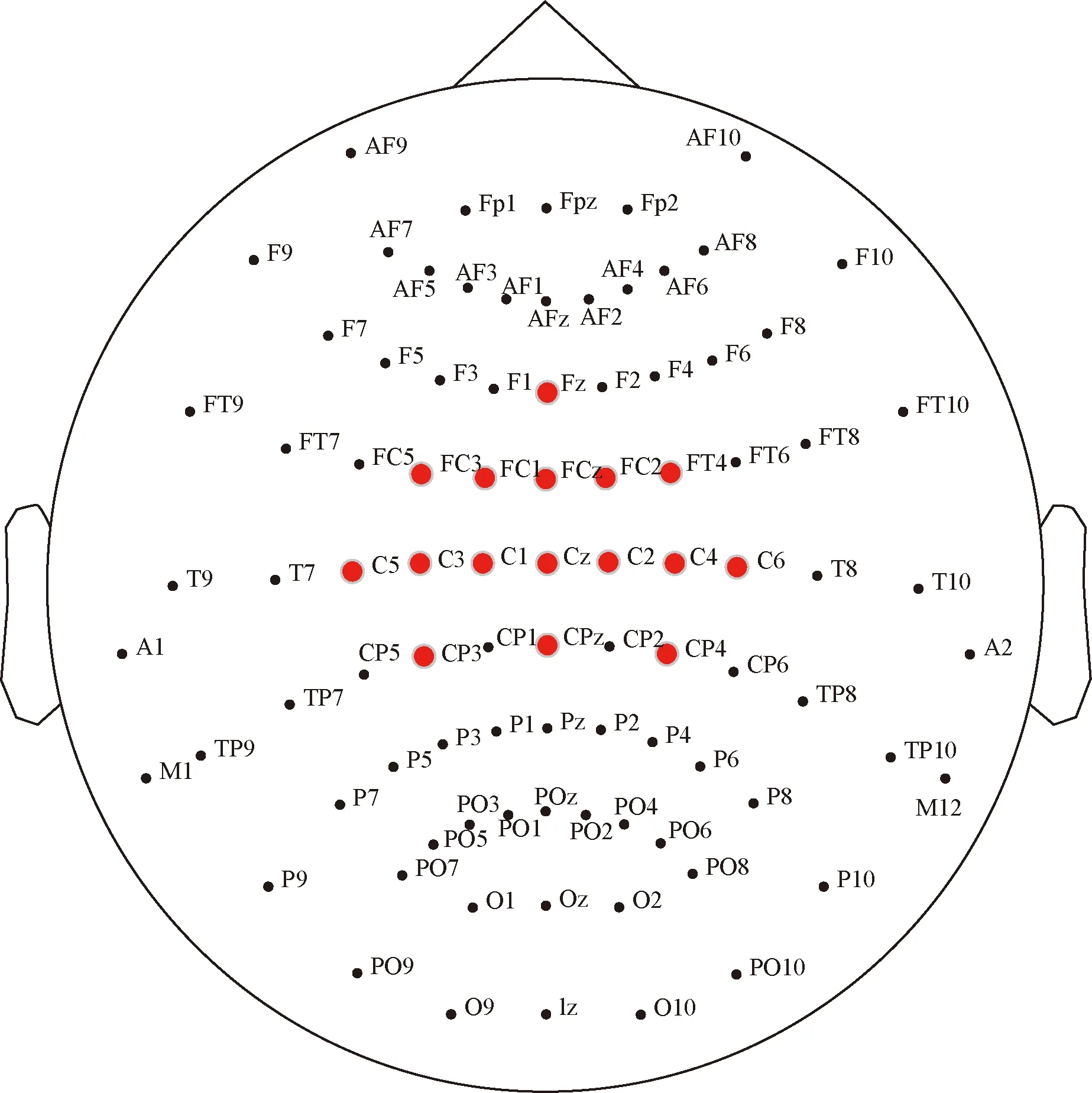
图1 10-20国际电极放置标准16通道电极位置分布图Fig.1 Distribution of 16-channel electrode position 10-20 international standard electrode placement method
1.2 脑电信号采集
设计手势动作共4种,如图2所示,依次为握拳、伸掌、数字2和数字3。实验范式如图3所示,单次试验时长共7 s,脑电设备采样频率设为1 000 Hz,分为4个阶段。
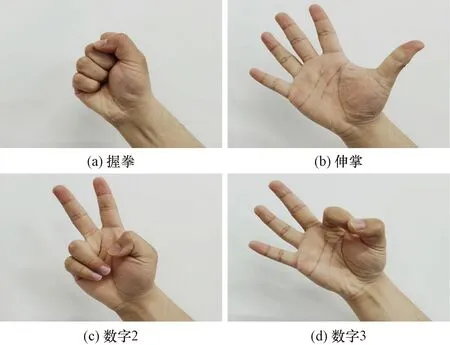
图2 手势动作Fig.2 Gesture action

图3 实验范式Fig.3 Experimental paradigm
(1)准备阶段。0~2 s,该阶段内受试者保持放松状态。
(2)提示阶段。2~3 s,第二秒开始时,扬声器会发出“嘀”的一声提示音,持续大约0.5 s,提醒受试者做好准备。
(3)反馈阶段。3~5 s,第3秒开始时,显示器上会出现动作提示,受试者根据出现的图片做出相应的动作。
(4)休息阶段。5~7 s,受试者重新回到放松状态,等待下一次提示。
实验对象共3名,均为健康的男性青年,年龄在23~35岁,均为右利手。实验前受试者均已熟悉实验步骤和流程,且都为自愿参加。
2 脑电信号预处理
EEG信号频率主要集中在0.1~40 Hz,在上位机先对EEG信号进行50 Hz陷波和0.1~40 Hz带通滤波。伪影一般仅使用传统BSS技术是难以去除的,因为它们要求可用通道的数量应等于或大于未知源的数量。因此,在通道数量有限的情况下,仅使用独立成分分析(independent component analysis,ICA)或典型相关分析(canonical correlation analysis,CCA)都无法完全恢复脑源和非脑源。在最近的调查中,研究人员反复建议,抑制EEG伪影的最佳方法可能包括通过组合多个算法的多个处理过程,而不是单独使用[11]。CCA使用了比ICA算法寻求的统计独立性更弱的条件,且具有自动化和计算效率更高的优点。MEMD算法是一种经验和数据驱动的方法,本质上是自适应的,不需要任何先验知识,特别适合处理非线性和非平稳神经信号,充分利用通道之间的信息。
设计了基于多变量经验模式分解(multivariate empirical mode decomposition,MEMD)和CCA的混合去除伪影方法(MEMD-CCA)。基于MEMD和CCA的混合去除伪影方法具体步骤如下。
步骤1输入数据是16通道脑电采集数据,依图3实验范式截取0.5~6.5 s数据,单个脑电数据的大小为16×6 000。
步骤2使用MEMD算法分解16通道脑电数据。IMF分量根据原始通道顺序被重组为一个IMF矩阵X(t)。
步骤3识别并去除与肌电伪影伪影相关的IMF,组成新的IMF数据集,定义为F(t)。肌电伪影一般杂乱无章,具有相对较低的自相关值,而眼电伪影则具有相对高的自相关值,计算IMF的自相关值并设置高低阈值来识别与伪影相关的IMF,并使用相对较高或较低的阈值来避免错漏EEG成分,那些从不同的脑电通道识别出的IMF实际上由于体积传导具有内在相似的振荡模式。这些跨信道信息可以在很大程度上促进后续BSS步骤。
步骤4基于二阶统计量(second order statistics,SOS)的CCA算法用于将分散在数据集F(t)的IMF分量中伪影信号集中到几个CCA组件(CCs)中。CCA使用重组的IMFs矩阵X(t)及其延时版本Y(t)=X(t-1)通过解决等式中的最大化问题,通过分解矩阵wx和wy得到源矩阵Sx和Sy。
步骤5计算源信号矩阵Sx的每个源信号的自相关系数r,若r小于所设阈值e时,将Sx中与伪影对应源信号设置为零,并定义新的数据集Snew。

步骤7MEMD信号重构。X(t)clean中的干净的IMFs对应代替数据集F中具有伪影成分的IMFs,得到无伪影的IMF数据集,将IMFs相加得到干净的脑电信号。
步骤8依实验范式,截取动作反馈的2~4 s的重构脑电数据,保存数据集。
3 模型构建
3.1 Tranformer模型
在研究中,多通道EEG数据具有空间信息和时间信息,每个采样通道下所有时间点的信息都是该通道的特征,每个采样时间点下所有通道的信息都是该时间点的特征。另外,根据对EEG信号的观察,一个时间片段比单个采样点更能反映信号趋势和特征。受vision transformer(ViT)模型启发[12],构建了时间Tranformer模型和空间Transformer模型,两模型分别计算了采样时间段间的相关性和采样通道间的相关性。
时间Tranformer模型和通道Transformer模型的区别在于输入,如图4所示。在时间Transformer模型中,模型输入按时间维度切割成k份不重叠的时间切片并展平成一维向量(k=通道数,确保注意力模块输入相同),通过线性映射到模型维数。在空间Transformer模型中,模型输入按电极通道分割数据,通过线性映射到模型维数。
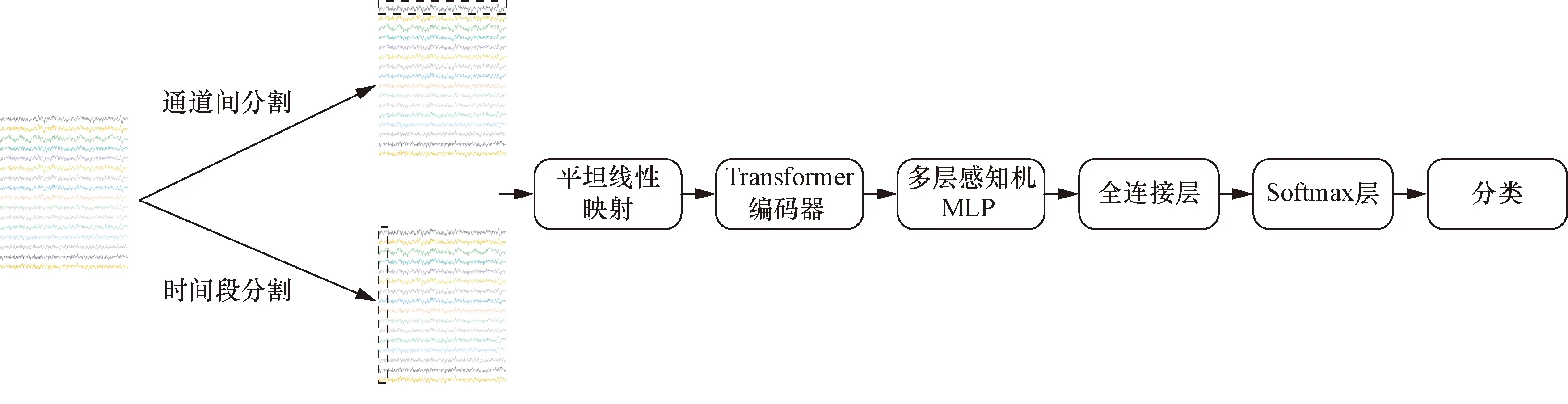
图4 时间Tranformer模型和通道Transformer模型Fig.4 Time Transformer model and spatial Transformer model
Transformer模型架构中自注意力模块采用查询-键-值(query-key-value,QKV)模式,其计算过程如图5所示。注意力模块用于映射一组查询和键值对,其中输出计算为值的加权和。自注意力模型使用缩放点积来作为注意力打分函数,输出向量序列可以简写为
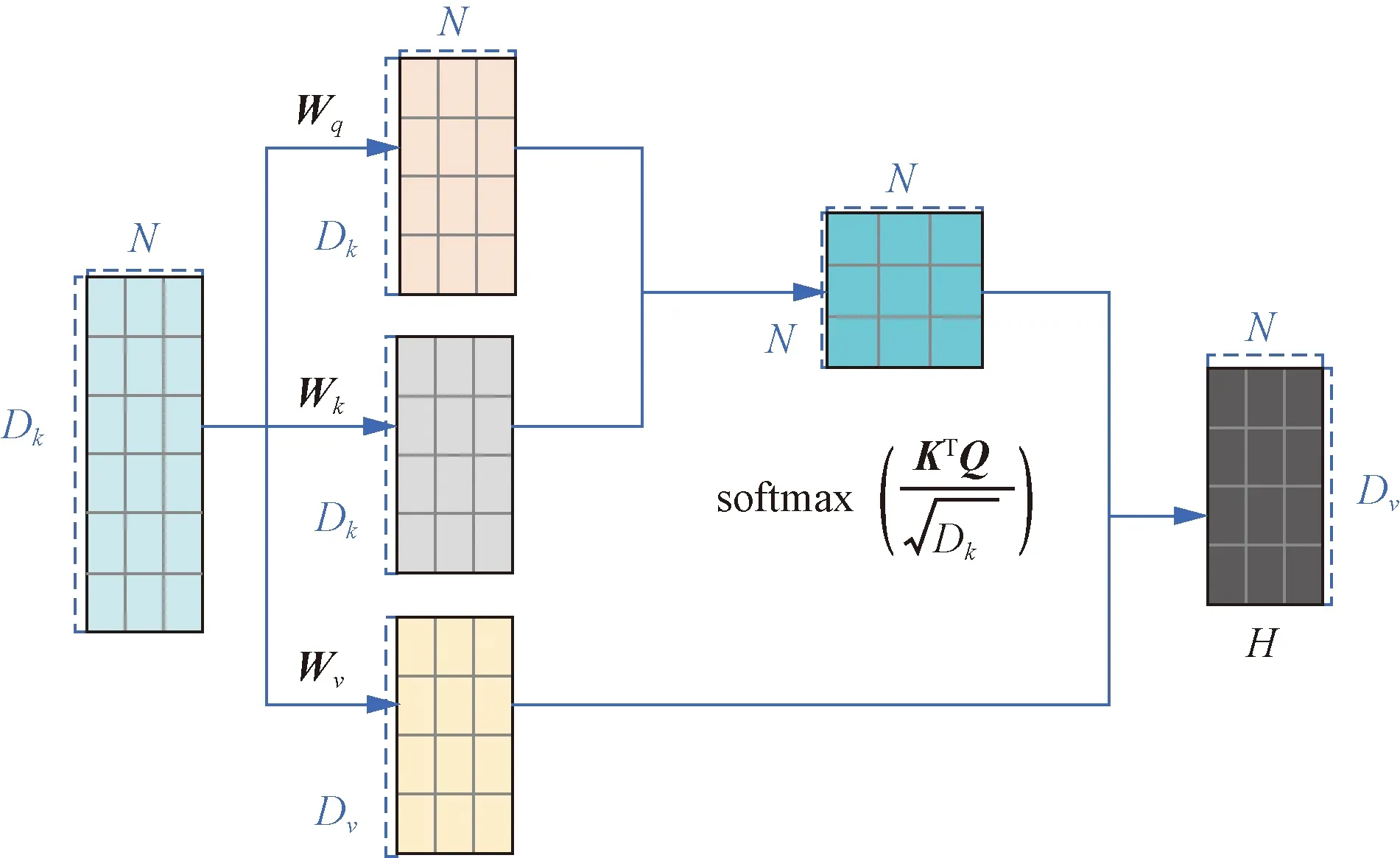
Dk、Dv为矩阵的行数;N为矩阵的列数;Wq、Wk、Wv为输入数据线性变化的矩阵图5 自注意力模型的计算过程Fig.5 The calculation process of the self-attention model

(1)

3.2 top-k稀疏Transformer模型
多通道EEG信号采集时,由于设备的传输速率和人的反应速度,脑电信号的采集有延迟性,另外,由于体积传导的缘故,EEG不同通道采集的信号存在共模冗余信号成分。自注意力能够为长距离依赖关系建模,但它可能会受到信号中不相关或冗余信息的影响。因此,为了提取脑电信号中特征更加明显的时空信息,使用了基于top-k选择的稀疏Transformer模型[13]。在Transformer Encoder层,通过top-k选择将注意退化为稀疏注意,这样有助于保留引起注意的部分信号,而其他无关信号就被删除了,这样能有效地保留重要的信息和去除噪声,注意力就可以集中在最具信息价值的数据上。
在稀疏Transformer模型注意力模块中,首先生成注意力分数P,表达式为
(2)
然后在假设得分越大、相关性越大的基础上,模型对注意力分数P进行评估,对P执行稀疏注意力掩蔽操作M(·),以选择top-k贡献元素。掩蔽函数M(·)为
(3)
式(3)中:ti为第i行中第k大的值。通过top-k选择高注意力分数,保证EEG信号重要成分的保留。输出向量序列可以简写为
H=Vsoftmax[M(P,k)]
(4)
结果表明,采用自注意力机制的最具贡献的数据上。top-k选择应用于时间Transformer模型,可以集中更多的注意力在更有价值的时间段;top-k选择应用于空间Transformer模型,可以集中更多的注意力在更有价值的通道上。
3.3 实验配置及参数设置
使用的实验环境为Windows10系统,处理器为AMD Ryzen 7 3700x 8-Core Processor,编程语言为python 3.8,改进的Transformer模型的构建使用pytorch1.10.1。在实验中,模型的自注意力模型均设置为3层,每层自注意头的个数为8,dropout为0.5,Mmodel为512,连接前馈层的参数设置为2 048,学习率为5×10-5。模型均使用的是交叉熵损失函数和Adam优化器。top-k稀疏Transformer模型中超参数k为8。为了保证模型的稳定性,使用了10折交叉验证的方法进行训练。将样本按个体的顺序随机打乱并平均分成10份,每次取不同的1份作为测试集对模型进行测试得到分类准确率,剩下的9份作为训练集进行训练,最后将得到的10个准确率取平均作为模型的分类结果。
4 结果与讨论
使用了准确率和混淆矩阵评价模型。在10折交叉验证中,准确率指10次训练准确率的平均值。时间Transformer模型、空间Transformer模型、top-k时间Transformer模型、top-k空间Transformer模型训练曲线、10折交叉验证准确率如图6和图7所示。表1为手势脑电信号Transformer模型10折交叉验证准确率。

表1 手势脑电信号Transformer模型10折交叉验证准确率平均值Table 1 Average accuracy of gesture EEG Transformer model 10-fold cross-validation
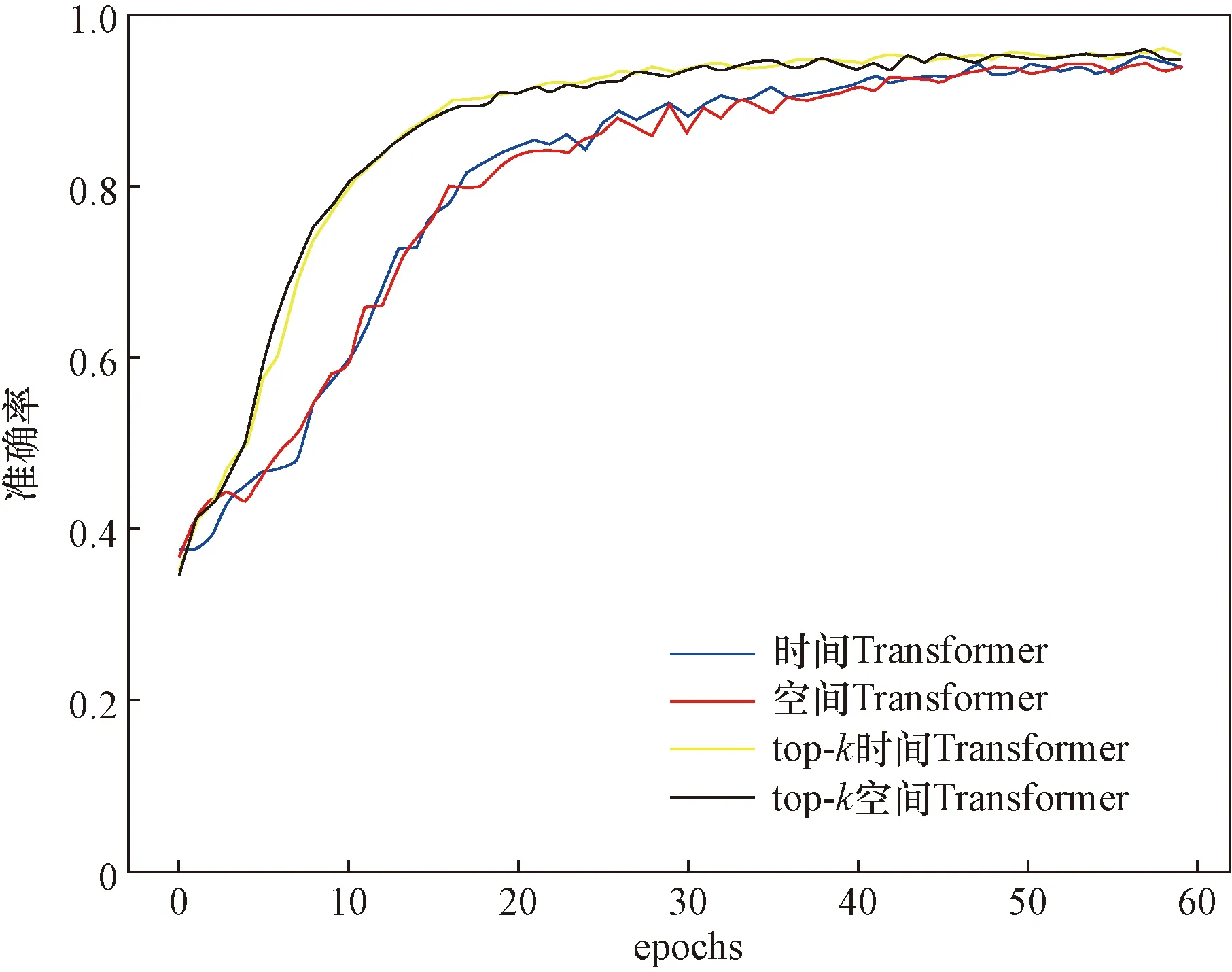
图6 手势脑电信号的Transformer分类模型训练曲线Fig.6 Transformer classification model training curve of gesture EEG signals
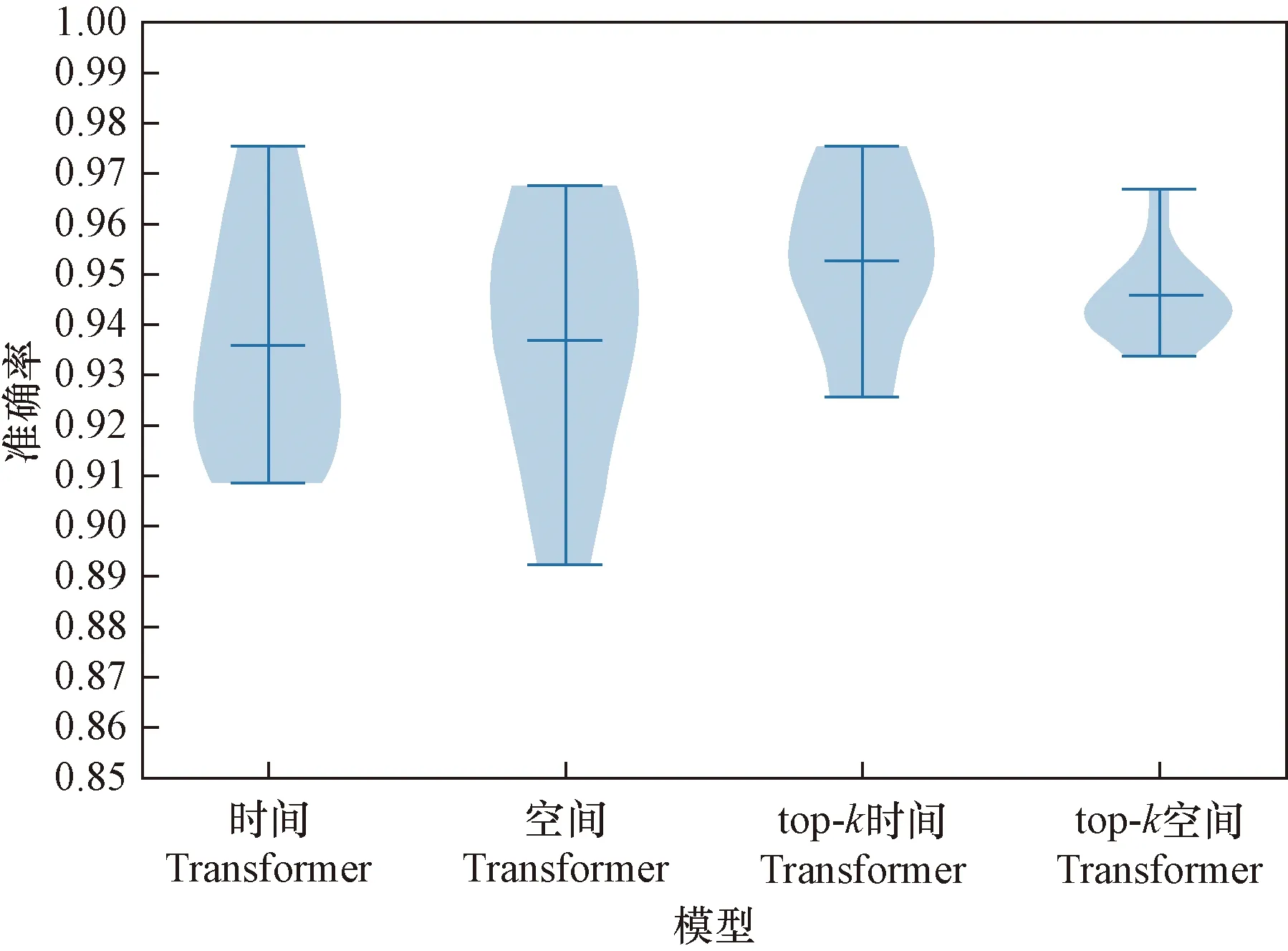
图7 手势脑电信号Transformer模型10折交叉验证准确率Fig.7 Gesture EEG Transformer model 10-fold cross-validation accuracy
混淆矩阵表现了每一种分类情况的具体数量。混淆矩阵用来观察每个类别的分类情况以及各类别错分的情况。混淆矩阵对角线上的数目代表了该类分类正确的数目。时间Transformer模型、空间Transformer模型、top-k时间Transformer模型、top-k空间Transformer模型10折交叉验证混淆矩阵如图8所示。
据图6~图8可知,4个Transformer模型都取得较好的分类结果。自注意力的优点是参数少、对算力要求少、可并行计算、对长期依赖关系有着更强的捕捉能力。结果表明,采用自注意力机制的Transformer模型具有较好的性能。由于数字2和数字3手势相关脑电信号相似性强,容易混淆识别。在添加了top-k选择后,注意力退化为稀疏注意力,将注意力都转移到最具信息价值的数据上,top-k时间Transformer模型和top-k空间Transformer模型准确率分别增加了0.017和0.008,手势数字2和数字3还存在互相识别错误,但是手势数字2和数字3识别率上升。从表1可知,增添了top-k选择的Transformer模型取得了更好的分类结果,top-k时间Transformer模型的结果优于top-k空间Transformer模型,因为top-k时间Transformer模型选取的是最具信息价值的时间片段,而top-k空间Transformer模型选取的是最具信息价值的通道信息,通道信息中含有无关信息。另外,绘制了同种手势EEG信号的各个Transformer模型最后一层的单个注意力头的注意力权重,可以看到,因为top-k选择,注意力权重主要集中在一小块区域,从而提高了分类的精度。如图9所示。
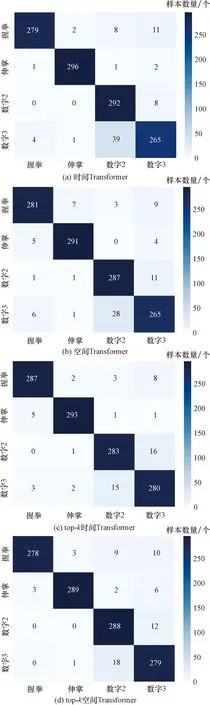
图8 手势脑电信号Transformer模型10折交叉验证混淆矩阵Fig.8 Gesture EEG Transformer model 10-fold cross-validation confusion matrix
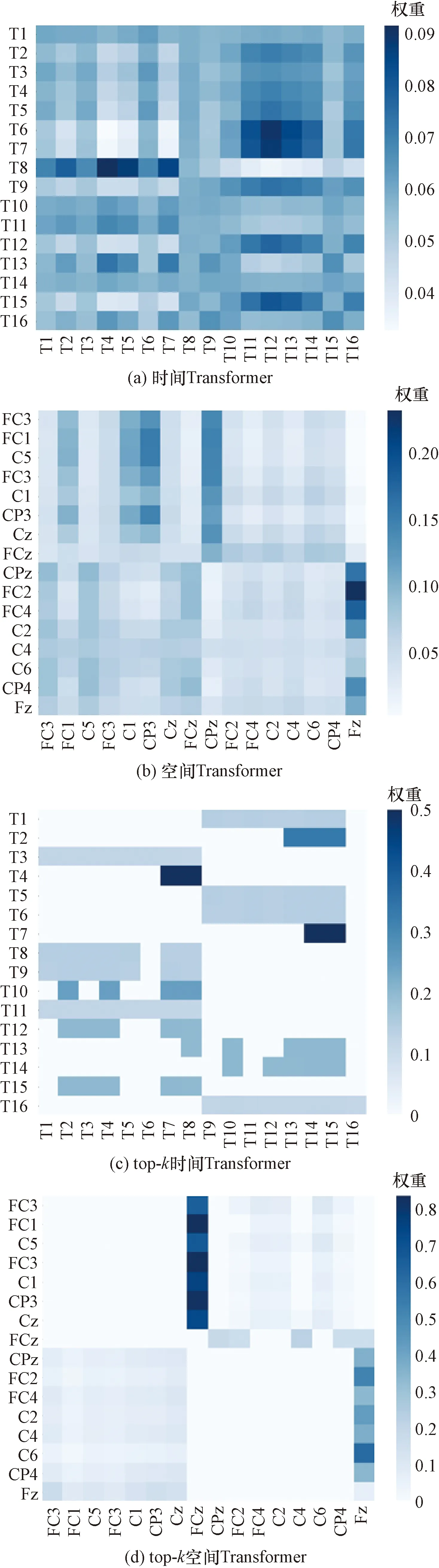
图9 手势脑电信号Transformer模型单个注意力头的注意力权重Fig.9 The attention weight of a single attention head in the gesture EEG Transformer model
5 结论
为提高脑电信号与手势动作的信号关联度,设计了4种实际手势动作,通过确定手势运动的脑电信号通道选择,设计脑电信号实验范式同步采集手势动作头皮脑电信号。
为了去除眼电和肌电等伪影,设计了一种基于MEMD-CCA的混合去伪影方法,对脑电信号进行二重分解、阈值处理和重构。结合脑电数据结构特点改进了一种基于自我注意的Transformer模型识别方法,分别从时间维度和空间维度构建了基于自我注意的Transformer模型及其变体top-k稀疏Transformer模型,改进的Transformer模型取得了优异的分类识别结果。
实验结果表明,Transformer模型适用于脑电信号分类识别,增添了top-k选择的Transformer模型取得了更好的分类结果,top-k时间Transformer模型识别率最高,达到95.2%。
猜你喜欢
成都信息工程大学学报(2021年4期)2021-11-22
科技传播(2019年24期)2019-06-15
中国医疗器械信息(2019年3期)2019-03-09
中国医学影像学杂志(2018年9期)2018-10-17
北京航空航天大学学报(2017年9期)2017-12-18
现代电生理学杂志(2016年3期)2016-07-10
现代电生理学杂志(2016年4期)2016-07-10
现代电生理学杂志(2016年1期)2016-07-10
中国卫生标准管理(2015年4期)2016-01-14
中国医学装备(2015年10期)2015-12-29
