
全局时空特征耦合的多景深三维形貌重建
2023-03-24 13:25张江峰闫涛陈斌钱宇华宋艳涛
计算机应用 2023年3期
张江峰,闫涛,3,4*,陈斌,钱宇华,宋艳涛,3
(1.山西大学 计算机与信息技术学院,太原 030006;2.山西大学 大数据科学与产业研究院,太原 030006;3.山西省机器视觉与数据挖掘工程研究中心(山西大学),太原 030006;4.哈尔滨工业大学 重庆研究院,重庆 401151;5.哈尔滨工业大学(深圳)国际人工智能研究院,广东深圳 518055)
0 引言
三维形貌重建作为计算机视觉的前沿课题之一,在增强现实、精密制造和无人驾驶等领域[1]应用广泛。现阶段,三维形貌重建不仅需要满足高精度与高效率的测量需求,也要满足跨场景应用的快速部署要求[2]。三维形貌重建过程中需要探究深度线索或立体匹配,从而辅助构建立体形貌,如多景深重建[3]、相机自运动[4]、点云配准[5]和光场重建[6]等。相机自运动需要图像采集设备在宏观的定位系统下搭建庞杂的照片集,受限于数据信息的噪声和立体匹配信息的稀疏性,此类方法不易跨场景应用。点云和光场均通过专用信息采集设备记录场景的深度线索,它们的重建精度依赖信息采集设备的精度,因此硬件成本较高。而基于多景深图像序列的三维形貌重建方法即聚焦形貌恢复(Shape From Focus,SFF)则利用图像含有的场景信息和图像序列间含有的景深关系共同推导深度线索,重建效率高且硬件成本低,易于实现多场景应用[7]。
基于多景深图像序列的三维形貌重建主要包含以下步骤:首先,相机等图像采集设备在它们的聚焦范围内快速扫描焦平面,产生一系列不同景深(聚焦)的图像集即聚焦栈(Focus Stack,FS);其次,对聚焦栈中的图像序列采用统一的聚焦评价算子FM(Focus Measure)构成聚焦体积(Focus Volume,FV),在FV 中评选最佳聚焦值所在序列信息,从而构成初始形貌结构;最后,采用深度图修复等图像后处理算法得到最终的三维形貌图即深度图。
为实现场景中的高精度三维形貌重建,聚焦评价算法至关重要。传统基于多景深的三维形貌重建[8-9]提出了多种聚焦评价算子,大致可分为空间域和频率域。传统方法通过图像像素信息推导深度信息,而固定的模型参数难以对多场景进行自适应式的高精度三维形貌重建。随着多景深数据集的生成和开源,一系列算法[10-13]利用深度学习替代传统聚焦评价算子,从大规模多景深图像数据中学习区分聚焦和离焦,并创建场景语义级的三维形貌。然而,基于深度学习的三维形貌重建仅通过二维或三维卷积简单地拼接局部聚焦信息,无法很好地挖掘全局场景信息。
基于多景深图像序列的三维形貌重建目前仍面临三个主要挑战[13]:聚焦测量、弱纹理场景和采样频率。聚焦测量过程中聚焦评价算子直接作用于多景深图像序列,不仅需要判断聚焦与离焦的分界线,而且需要以场景信息为引导有效分离场景中的异质区域;聚焦测量算子无法对弱纹理场景进行有效聚焦评价,极易导致错误深度信息蔓延;采样频率宏观上决定了场景的层次结构,为确保前景和背景落入景深范围内,需要对待测场景密集采样。
综上所述,如何构建聚焦测量精准、纹理场景自适应的多场景三维形貌重建是目前亟需解决的问题。本文提出全局时空特征耦合(Global Spatio-Temporal Feature Coupling,GSTFC)模型,在重建多景深三维形貌的同时建模聚焦区域特征的时序关系和空间关系,并通过自适应参数有效耦合这两种关系,从而增强模型的特征表示能力。
本文的主要工作如下:1)提出基于3D-ConvNeXt 的U 型网络主干,可以在有效提取局部聚焦序列信息的同时,减少网络参数量,降低模型成本;2)利用3D-SwinTransformer 模块[14]通过局部聚焦序列信息构建全局关系,在此基础上选择自适应网络参数平衡局部和全局特征并有效耦合;3)利用神经网络构建聚焦体积,代替原有手工计算聚焦最大值或神经网络直接拟合深度图的方式,通过分析聚焦体积中每个点的深度置信度保留聚焦和离焦的过渡信息。
1 相关工作
基于多景深图像序列的三维形貌重建根据是否利用深度学习抽取聚焦特征,大体可分为传统聚焦建模和神经网络拟合两类。
1.1 传统多景深三维形貌重建
传统多景深三维形貌重建模型通过前后图像的差异信息判别聚焦和离焦,并对深度信息进行置信度评价以确定聚焦与离焦的边界线。根据图像处理方式的不同可大致分为空间域和频率域两部分。在空间域类中,改进图像算子的聚焦特征提取能力可以提高重建结果的精度,如Sum-modified-Laplacian[15]、TENV(TENengrad Variance)[16]和Laplacian in 3D window[17]等;图像区域的梯度[18-20]波动同样也可作为聚焦的线索,如空间频率(Spatial Frequency,SF)算子。为贴合待测场景中不同物体的表面,学者通过构建物体表面和聚焦形貌的一一对应关系[21]将深度信息区域化,后续使用拉格朗日多项式估计分段曲面[22];也有学者探讨聚焦评价窗口对聚焦信息的影响,并提出自适应改变窗口大小来提高聚焦评价的准确度[23-24],如DLAP(Diagonal LAPlacian)算子通过收集邻域内梯度值变化自适应改变聚焦评价窗口;还有学者提出环形差分滤波器(Ring Difference Filter,RDF)[9]统筹局部区域内非相邻环形区域对聚焦中心的影响。这类方法主要对局部像素信息进行聚焦测量,无法对非连通的聚焦区域进行有效鉴别,难以拟合聚焦区域边界。由于图像时频的变换过程可有效分离图像的高、低频信息,进而有助于保留图像的相对聚焦区域,陆续有学者从图像频域角度分析并解构聚焦栈,如快速离散曲波(Fast Discrete Curvelet,FDC)[25]可检测聚焦栈中的高频分量;非降采样小波变换[7]将聚焦栈分离为不同尺度的高频信息;非降采样剪切波[26]可得到深度信息的最优尺度表达等。频率域类方法改善了空间域类方法仅在局部评价聚焦的问题,但仍需辅以场景结构的先验信息来完善并修复深度图像的边界及噪点。
现阶段,传统的多景深三维形貌重建力求改进聚焦测量算子以产生精细的聚焦体积[8]。同时,为防止重建结果将噪点等错误信息引入深度图修复算法。深度图修复算法采用梯度或场景结构约束来改善初始深度图的稀疏性,如引导滤波[27]、图像分割(Graph Cut,GC)算法[28]、鲁棒聚焦体积正则化的聚焦形貌恢复(Robust Focus Volume Regularization in Shape From Focus,RFVR-SFF)模型[8]。而深度修复算法在鉴定深度异常值的过程会影响原有深度正确值,造成重建算法精准度的退化。综上所述,传统多景深三维形貌模型单一的评价参数无法适应多领域三维形貌重建[29]。
1.2 基于深度学习的多景深三维形貌重建
深度学习类方法构建多层卷积神经网络(Convolutional Neural Network,CNN)学习多景深图像序列中隐含的内部关系,由此得到的深度信息具有更强的表征和泛化能力。目前已公布的基于深度学习的三维形貌重建模型将特定场景下的多景深图像集和深度图经过神经网络抽象学习聚焦特征并自动拟合聚焦区域,相较于传统方法更加精准高效。
基于焦点深度的深度(Deep Depth From Focus,DDFF)[10]模型作为首个端到端可训练的CNN,为解决三维形貌重建的不适定性给出示范,说明利用卷积关联像素信息可以抽取场景中抽象的聚焦特征。然而,仅使用单一卷积核逐层抽取特征无法关联景深的前后关系,导致多景深数据利用率较低。离焦网络(Defocus Net,DefocusNet)模型[11]利用域信息不变的散焦模糊作为直接监督数据,通过融合分支和深度分支分别生成全聚焦图像和深度图像,该模型利用散焦信息监督网络可以有效分离前景和背景,但无法拟合相邻深度下同质区域的过渡。上述方法将简单堆叠的多景深图像集直接输入网络,仅通过二维卷积操作无法有效利用多景深图像之间的序列关系。
全聚焦深度网络(All-in-Focus Depth Net,AiFDepthNet)模型[12]利用全聚焦图像监督或全聚焦图像和深度图共同监督训练网络得到深度信息,以降低数据集对深度监督信息的依赖并改用全聚焦信息监督。然而,全聚焦图像与深度图对聚焦信息的敏感度不同,使用全聚焦图像作为监督信息极度依赖图像采集频率,采样频率降低会导致最终深度图像的噪点增多、边界信息模糊。后续也有研究通过差分聚焦体积网络(Differential Focus Volume Net,DFV-Net)模型和聚焦体积网络(Focus Volume Net,FV-Net)模型[13]结合焦点和上下文进行深度估计,但在初始特征提取中未综合考量聚焦体积中的聚焦过渡关系。全局时空聚焦特征耦合模型[30]加入注意力机制并利用局部时空聚焦信息构建全局联系,从而依据多景深图像序列推导焦平面矩阵,指导三维形貌重建。但是简单的焦平面矩阵无法直接适应不同数据集的深度范围,后续需要根据场景深度范围重新调整深度值,易引起精度丢失。而且推导的焦平面矩阵有固定的分层数,不利于网络模型精细化理解待测场景中的前后图像序列的过渡关系。综上所述,现有的三维形貌重建方法在聚焦特征的高效提取、弱纹理区域的聚焦鉴定和多频率景深的泛化性上仍有上升空间。
2 本文模型
2.1 问题描述
多景深三维形貌重建利用相机的光学成像原理还原待测场景的三维形貌信息,它的核心思想是利用相机的景深限制来推导深度信息。大多数相机只能在称为景深(Depth of Field,DoF)的范围内捕捉部分场景的清晰图像,而范围外会模糊形成弥散圆(Circle of Confusion,CoC)。三维形貌重建算法利用透镜成像公式[31]的基本原理,通过调节相机与待测场景的距离,等间隔采集场景图像,得到可以覆盖待测场景全部景深的图像栈。在捕捉的图像栈中使用聚焦测量算子进行聚焦水平评价,选择所有聚焦水平最大值所在序列位置作为待测场景的初始深度[32],可表示为:
其中:N为聚焦栈大小;图像大小为H×W;FMi[x,y]表示聚焦栈中第i张图像中[x,y]位置的聚焦水平;D[x,y]表示深度图。最后,采用图像后处理算法对初始深度图进行修复。
2.2 网络结构
本文提出全局时空特征耦合(GSTFC)模型是一个端到端的深度卷积网络,输入为多景深图像序列,输出为相应场景的深度信息即深度图。GSTFC 模型由收缩路径、瓶颈模块、扩张路径及特征处理组成,如图1 所示。

图1 GSTFC模型的整体结构Fig.1 Overall structure of GSTFC model
本文采用U 型主干网络,在收缩路径和扩张路径的编解码过程中跳跃连接各个尺度特征,以实现底层纹理特征与高层聚焦特征的充分融合,同时兼顾精准定位和轻量化应用[33]。该主干网络的优点使它在图像生成等任务中有明显优势[34]。为确保训练过程中卷积操作和注意力操作在宏观结构层次下网络特征归纳的统一性和微观层次下特征维度的兼容性,使用ConvNeXt 模块[35]代替原有的全卷积网络(Fully Convolutional Network,FCN)等结构。但为引入同一区域内不同景深序列的聚焦信息,将ConvNeXt 模块的特征提取维度由二维变为三维,由此获得局部时空聚焦特征。3D-SwinTransformer 模块对于时序关系的全局建模能力有利于将前者获得的局部聚焦特征进行信息整合,从而获得全局时空聚焦特征。后续,灵活的特征处理模块对不同焦距数据进行分类处理从而得到最终的深度图。
2.2.1 收缩路径和扩张路径
收缩路径中主要包含三个子模块,每个子模块中包含3D 卷积层(Conv 3D)、正则激活层和3D-ConvNeXt 模块。每个子模块针对局部聚焦区域的时空特征进行多尺度提取,以探索多景深图像序列的局部时空聚焦特征。第一个子模块整体的特征频道设为48,3D 卷积层通过大小为(3,7,7)的卷积核对原始多景深图像序列进行特征抽取,随后通过层归一化(LayerNorm)和高斯误差线性单元(Gaussian Error Linear Unit,GELU)增益特征,最后堆叠3 层3D-ConvNeXt 模块以探索该尺度下的局部时空特征。第二和第三个子模块整体的特征频道分别为96 和192,使用卷积核大小为(1,2,2)的3D卷积层代替最大池化或平均池化层,堆叠的3D-ConvNeXt 模块层数分别为3 和9。
收缩路径中包含的下采样操作和3D 卷积层对输入的多景深图像序列进行由局部到整体的聚焦特征抽样,从而得到局部时空聚焦特征并保留各个尺度的聚焦特征。
扩张路径与收缩路径的维度一一对应,也包含三个子模块。每个子模块中包含3D 反卷积层(ConvTranspose 3D)、正则激活层和3D-ConvNeXt 模块。3D 反卷积层主要负责还原上一个子模块的特征矩阵尺度,并与相对收缩路径的浅层特征相融合。收缩路径和扩张路径中,3D-ConvNeXt 模块的堆叠次数与特征维度保持一致。
2.2.2 3D-ConvNeXt模块
CNN 在计算机视觉的应用最广泛且相对成熟[36],它特有的归纳偏置有利于处理图像数据。但Vision Transformer的引入改变了原有的网络架构,核心的多头注意力机制灵活关注一系列图像块,为特征编码提供全局线索[37]。二者并不是独立发展,如Transformer 变体中引入了卷积的“滑动窗口”策略。尽管Transformer 在计算机视觉领域通过借鉴卷积的独特优势提升效率,但在训练过程和架构设计中仍存在明显的差异[35]。本文提出的3D-ConvNeXt 模块的架构设计参照3D-Swin Transformer 结构,使它可灵活嵌入Transformer 模块,将二者提取特征相结合。ConvNeXt 模型[35]依照Swin Transformer[38]的结构进行调整改进,有效地弥合了纯卷积网络和Vision Transformers 之间的性能差距。该设计分为五部分:宏观设计、ResNeXt[39]、Inverted Bottleneck、大卷积核和逐层微观设计。在宏观设计中,ConvNeXt 模型将卷积模块的堆叠比例改为1∶1∶3∶1,并将stem 层中的卷积核设为4,步距设为4;在网络结构设计中,采用ResNeXt 模型的组卷积层,并将组卷积层中的组数设置为特征频道数;借鉴MobileNetV2[40]的Inverted Bottleneck 模仿Transformer block 中的多层感知机(Multi-Layer Perceptron,MLP)模块;增大原有的卷积核,将卷积核大小设为7;在逐层微观设计中,采用GELU 激活函数、更少的激活层和正则层,将Batch Normalization 改为Layer Normalization 和单独下采样层。在微观设计中,GELU 激活函数是一种高性能的非线性神经网络激活函数,可以采用随机正则化的方式有效提升网络的鲁棒性,因此可将它视为ReLU 激活函数更平滑的变体;Layer Normalization 相较于Batch Normalization 不会对小批量数据施加限制,可有效减少模型的显存消耗。
本文在ConvNeXt 模型的基础上进行改进,以满足多景深图像序列的三维形貌预测。首先,为探究多景深图像序列之间的聚焦离焦过渡关系,将原有的2D-ConvNeXt 模块整体升级为3D-ConvNeXt 模块,主要包含卷积层;其次,将原有的分类式网络中的线性分类层转换为3D-ConvNeXt 模块堆叠次数相对应的U 型主干网络结构[33],便于获得多景深图像序列的多尺度信息并保留浅层细节特征,有效降低了网络整体所需参数;最后,微调原有的stem 层,将它转换为卷积核为2、步距为2 的卷积层,最终将得到的下采样特征与3D-Swin Transformer 模块切分得到图像序列块的特征进行对齐,并添加自适应参数以平衡卷积特征和Transformer 特征。
收缩路径中每个子模块的特征维度设置、卷积模块堆叠次数均与Swin Transfromer 保持高度一致,便于提高局部特征与全局特征的融合性。其中3D-ConvNeXt 模块主要包含3D逐通道卷积层、LayerNorm 层、GELU 激活层和3D 逐点卷积层。3D-ConvNeXt 模块使用残差方式缓解网络增加深度时带来的梯度消失问题。该模块首先使用卷积核大小为(3,7,7)的3D 逐通道卷积层和LayerNorm 层获得初始特征;随后,使用卷积核大小为(1,1,1)的3D 逐点卷积层扩充原有维度并使用GELU 激活特征;最后,使用卷积核大小为(1,1,1)的3D 逐点卷积层降低特征到原有维度,添加随机的Drop Path层以有效提升模型的鲁棒性。该设计方法在牺牲部分准确度的前提下可大幅减小网络的参数规模,有助于平衡模型计算量和预测准确率。
2.2.3 瓶颈模块
瓶颈模块主要分为两个子模块:3D 卷积模块和3D-SwinTransformer 模块。3D 卷积模块类似于收缩路径中的第二个子模块,具有相同的3D 卷积下采样和堆叠3 层的3D-ConvNeXt 模块。3D-SwinTransformer 模块包含3D Patch Embedding 和3D SwinTransformer Block。相较于直接从多景深图像序列中获取全局信息,3D Patch Embedding 预处理收缩路径中第一个子模块得到的特征,可以增益对特征的提取能力。3D SwinTransformer Block 在保留原有的滑窗设计和层级设计的同时,将图像之间的序列关系也引入对比。3D 卷积模块抽取局部时空聚焦特征,3D-SwinTransformer 模块构建全局时空聚焦特征,二者之间使用自适应参数进行耦合拼接。
2.3 特征处理
传统三维形貌重建模型根据输入的多景深图像序列确定聚焦体积的大小,通过聚焦测量算子评价单帧图像不同像素的聚焦置信度从而构建场景的三维形貌关系。传统模型仅提取最大聚焦值以确保深度信息的准确性,忽略了聚焦和离焦的过渡关系。当采样频率不足以覆盖整个场景时,深度图异质严重,会导致无法有效捕捉场景信息。而现有的深度学习的多景深三维形貌重建直接拟合多景深图像序列特征并输出深度图,未引导神经网络有效地学习聚焦过渡信息。
本文提出特有的深度聚焦体积(Depth Focus Volume,DFV)模块,利用神经网络引导构建聚焦体积并尽可能保存离焦和聚焦的过渡信息。首先,设立合适的场景预分层值,并确保该值大于等于多景深图像序列数;其次,对深度聚焦体积值沿序列维度计算深度置信度,根据深度置信度分配深度值;最后,将深度值等比例压缩至多景深图像序列范围。DFV 模块预先扩展场景中的深度层次,脱离了原有设定的深度范围,将场景中各个点的深度信息进行细化分层。另外,DFV 模块基于深度学习构建出三维形貌重建模型的深度决策信息,避免直接拟合深度值从而导致特征信息丢失。
各多景深三维形貌重建模型预测的三维形貌通过深度图表示,深度中各像素点的灰度值为待测场景的相对深度信息。三维形貌重建模型的预测精度依赖于对待测场景的密集采样,而稀疏采样会导致深度鉴别精度下降。因此可以通过观测各模型预测的深度图的灰度分布是否聚集以鉴定模型是否具有稀疏采样下的鲁棒性。图2 为各模型预测深度图的灰度直方图,横坐标为1~100 的灰度级(深度值),纵坐标为该灰度级出现的频数。实验场景设置为光场数据集SLFD 中的石狮子场景,该场景的深度层次过渡平滑,可有效对比各模型在稀疏采样下的鲁棒性。该场景的原采样频率为100,实验采样时将原有的图像序列等间隔采样以模拟稀疏采样,并设采样频率为10。图2 通过灰度直方图展示各模型对稀疏采样的敏感度,通过深度图像的深度值分布判定各个模型是否可以监测到聚焦和离焦的过渡信息。从图2(d)可以看出该场景的前景过渡较平滑且背景占比较大。对比的3 个模型的深度值都存在等间距分布,但与标准深度图的分布相似度不同。图2(a)和(b)中,RDF 和RFVR-SFF 仅判断出绝对聚焦关系,未能识别出场景的过渡关系;图2(c)中,GSTFC 的预测深度图与标准深度图的灰度分布最相似,不仅能尽可能保证聚焦区域的鉴别,而且对于离焦区域同样可以识别最佳的深度关系。
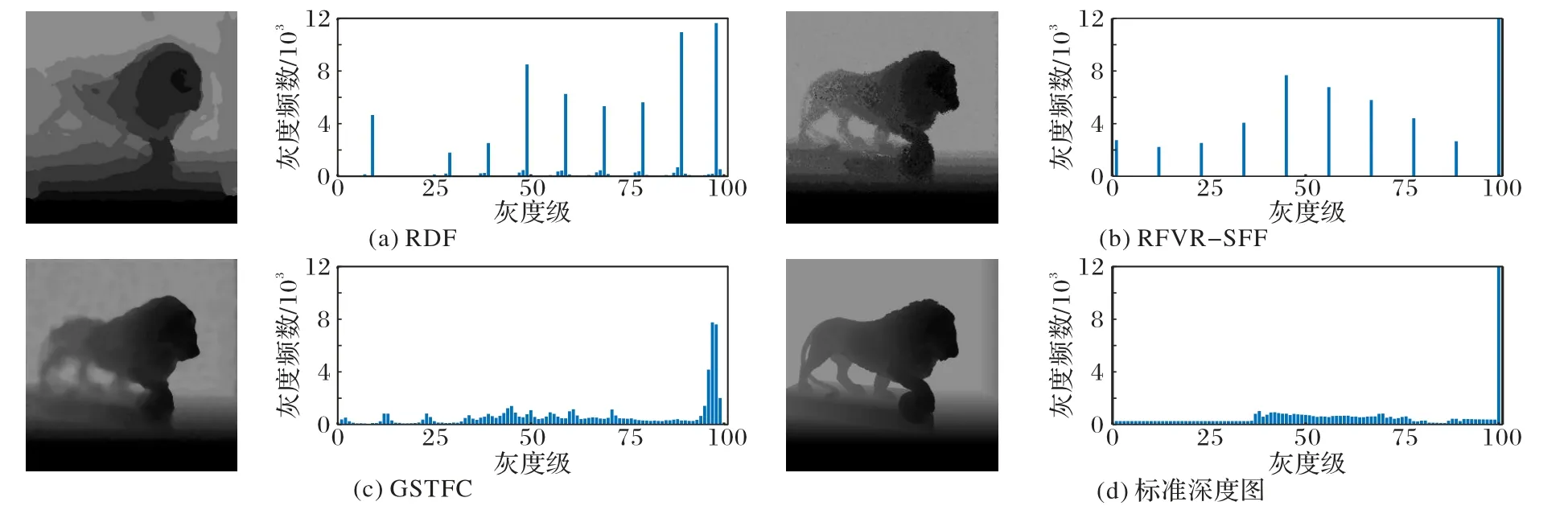
图2 各模型预测深度图及其灰度直方图Fig.2 Depth maps predicted by different models and corresponding grayscale histograms
3D-ConvNeXt 模块将扩张路径的输出特征聚焦为四维张量M∈R1×K×H×W,其中:K代表场景预分层值;图像大小为H×W。对于该特征使用DFV 模块统计场景中各点的深度值。具体操作如下:DFV 模块将特征张量M通过Softmax 归一化进行聚焦权重分配为深度注意力Mdepth:
其中:k、i和j表示张量M的位置信息。
由于Softmax 确保非负性的同时归一化有效的概率分布,深度注意力Mdepth等同于深度的概率分布[12]。随后,引入聚焦先验信息P∈R1×K×H×W,二者相结合得到每个像素的预期深度值:
其中:I表示三维形貌重建结果图,即深度图。
2.4 数据集介绍与实验设置
本文使用多景深图像数据集DFF[2]和FoD500[11]训练网络并对比模型效率。DFF 数据集共选用15 000 个场景图像和模拟深度图映射构建多景深图像序列,同时在该数据集中添加不同强度的高斯噪声并调整图像序列大小,以验证多景深三维形貌重建模型的鲁棒性。FoD500 数据集使用Blender渲染器构建数据集,包含400 个训练场景和100 个测试场景,每组数据包含5 张RGB 场景图和1 张深度图像。该数据集在构建过程中随机抽取400 组CAD 3D 模型,这些模型在每个场景随机大小、位置并旋转放置20~30 个随机材料。
DFF 数据集在模拟过程中将每个位置的模糊量结合全局深度信息加权控制,更突出测试模型对聚焦边界的鉴定;而FoD500 数据集注重刻画深度信息的过渡,精准的深度值可以有效衡量模型对聚焦范围的预测,同时该数据集提供物体之间相互遮挡的图像,可以有效测试模型对场景之间的间隔和弱纹理背景的区分能力。两个数据集采样频率相差巨大,DFF 数据集的采样频率为100,FoD500 数据集的采样频率为5,二者的采样范围可以涵盖目前已知测试数据集的采样频率。后续实验将在SLFD and DLFD(Sparse Light Field Dataset and Dense Light Field Dataset)[41]、Base-Line[42],4D Light Field[43]和POV-Ray[44]等数据集上测试各模型的优劣。
本文提出的GSTFC 模型在Ubuntu 平台上采用PyTorch工具实现,显卡型号为NVIDIA A100。多景深图像序列作为三维形貌重建模型的输入,相对应的深度图作为标签信息进行有监督训练,共进行200 次迭代训练。在训练过程中使用Adam 优化器,初始学习率设置为10-4,其余参数皆为PyTorch默认参数。训练过程中以0.5 的概率随机进行图像序列增强(整体翻转和图像序列倒转),批处理大小设置为2。
为更好地分析不同模型方法的客观评价结果,使用均方误差(Mean Square Error,MSE)、均方根误差(Root Mean Square Error,RMSE)、颠簸性(Bumpiness)、相对误差平方值(Square relative error,Sqr.rel)、峰值信噪比(Peak Signal to Noise Ratio,PSNR)、结构相似性(Structural SIMilarity,SSIM)、矩阵线性相关性(Correlation)定量评估GSTFC 模型与对比模型的性能[10]。后续将深度图通过ColorMap 映射到彩色空间,对不同模型预测的深度图进行主观评价。
2.5 消融实验
为进一步探究GSTFC 模型的合理性,本文在FoD500 数据集的训练集进行训练,并在测试集进行测试。消融实验将从MSE、模型参数量和模型计算量对模型进行评价。对比模型的计算量和推理时间时,采用多景深图像序列为5、图像大小为224×224 的RGB 图像。消融实验主要从主干网络、特征组件和特征处理三方面设置对比,如表1 所示。实验过程中,特征频道、堆叠次数、下采样和损失函数等保持一致,本文仅探讨3D-ConvNeXt 主干、3D-SwinTransformer 模块和DFV模块对网络模型的影响。
从表1 可以看出,本文模型在保证预测精度的同时更注重对模型参数的压缩。相较于U 模型,添加了全局注意力3D-SwinTransformer 模块的U+T 模型预测的准确率提高了,模型参数量和计算量也增加了。相较于U 模型,X 模型的参数量和计算量都大幅降低,而MSE 却小幅上升,因为ConvNeXt 模块使用深度可分离卷积等可有效降低参数量,但为了与3D-SwinTransformer 结合而设计的独有结构也提高了MSE。相较于U+T 模型,X+T 模型的MSE、参数量和计算量都明显降低,说明3D-ConvNeXt 模块更适配于3D-SwinTransformer 模块,二者结合取得了最优效果。相较于X+T 模型,X+T+DFV 模型的MSE 也明显降低,说明DFV 模块结合已有的聚焦先验信息能有效提升模型的深度图预测能力并减少参数量和计算量。由于3D-U 型主干网络与3D-SwinTransformer 模型的适配程度低,因此X+T+DFV 模型优于U+T+DFV 模型。综上所述,X+T+DFV 模型即本文最终选择的多景深三维形貌重建模型。

表1 消融实验的对比分析Tab.1 Comparison analysis of ablation experiments
2.6 对比实验
将GSTFC 与深度学习模型和传统方法进行对比。深度学习模型包括:DDFF[10]、DefocusNet[11]、AiFDepthNet[12]、FVNet[13]和DFV-Net[13];传统方法包括:RFVR-SFF[8]、RDF[9]、TENV[16]、SF[20]、DLAP[24]、FDC[25]和GC[28]。传统方法的选择依据文献[29]的分类标准。为平衡GSTFC 模型和传统方法是否使用场景先验信息的前置条件,GSTFC 模型仅使用DFF数据集训练以学习判定聚焦离焦的相对关系。
表2 为不同模型在FoD500 数据集上的对比结果,其中GSTFC 的MSE、RMSE 和Bumpiness 取得了最优。相较于最先进的AiFDepthNet,GSTFC 在FoD500 数据集上的RMSE 下降了12.5%。GSTFC 从全局时空视角对多景深图像序列进行聚焦提取,相较于之前的模型聚焦测量更加精准并且预测深度区域更平滑;但由于GSTFC 扩大了场景预分层数并保留离焦区域的深度信息,导致相对误差较大

表2 不同模型在FoD500数据集上的对比结果Tab.2 Comparison results of different models on FoD500 dataset
表3 为不同模型在传统验证数据集的客观对比结果,可以看出:相较于传统模型算法,GSTFC 模型对多景深图像序列的聚焦测量在客观指标对比中具有良好的表现。图3 则展示了不同模型的三维重建结果可视化对比。
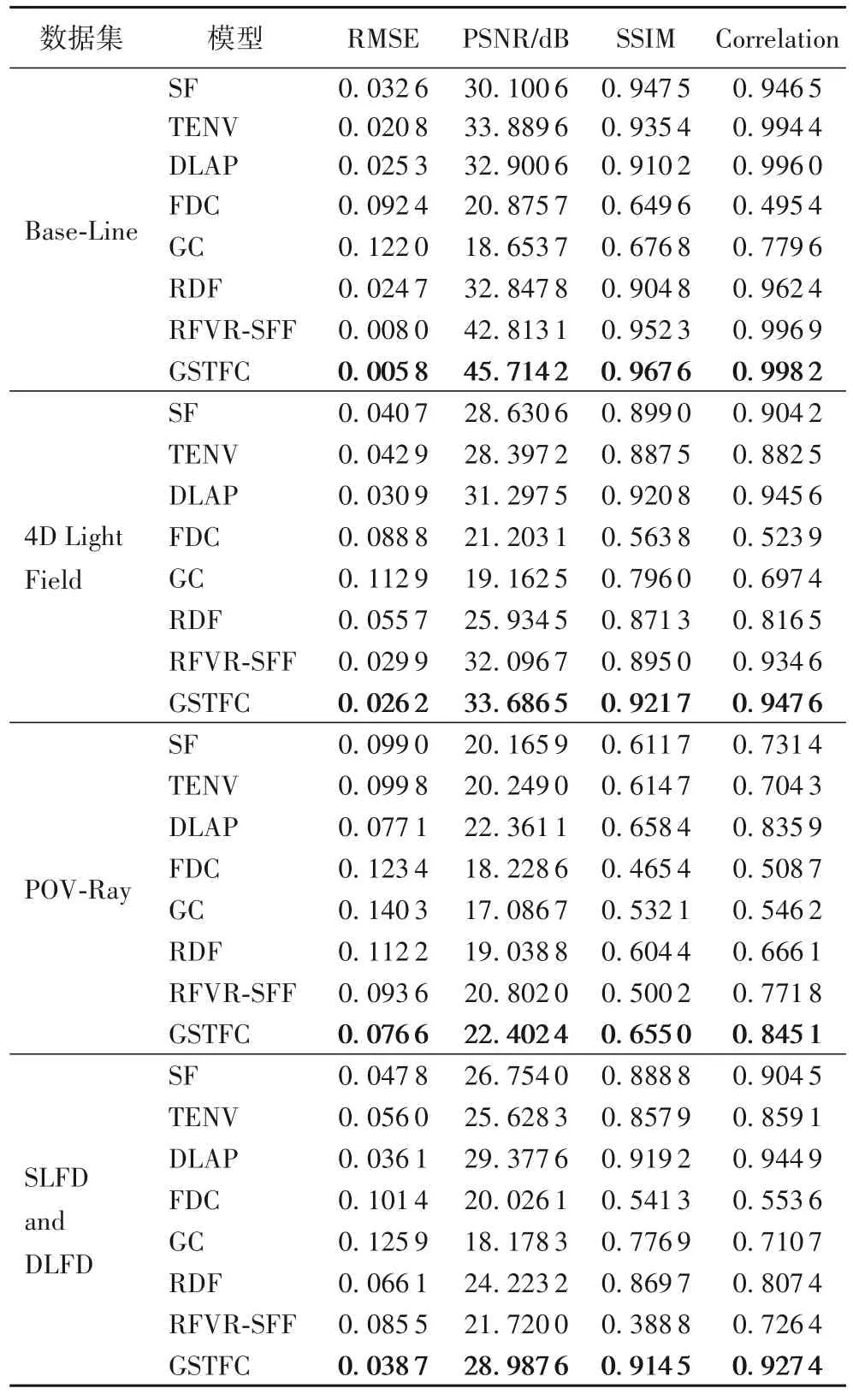
表3 不同模型在传统数据集上的对比结果Tab.3 Comparison results of different models on traditional datasets
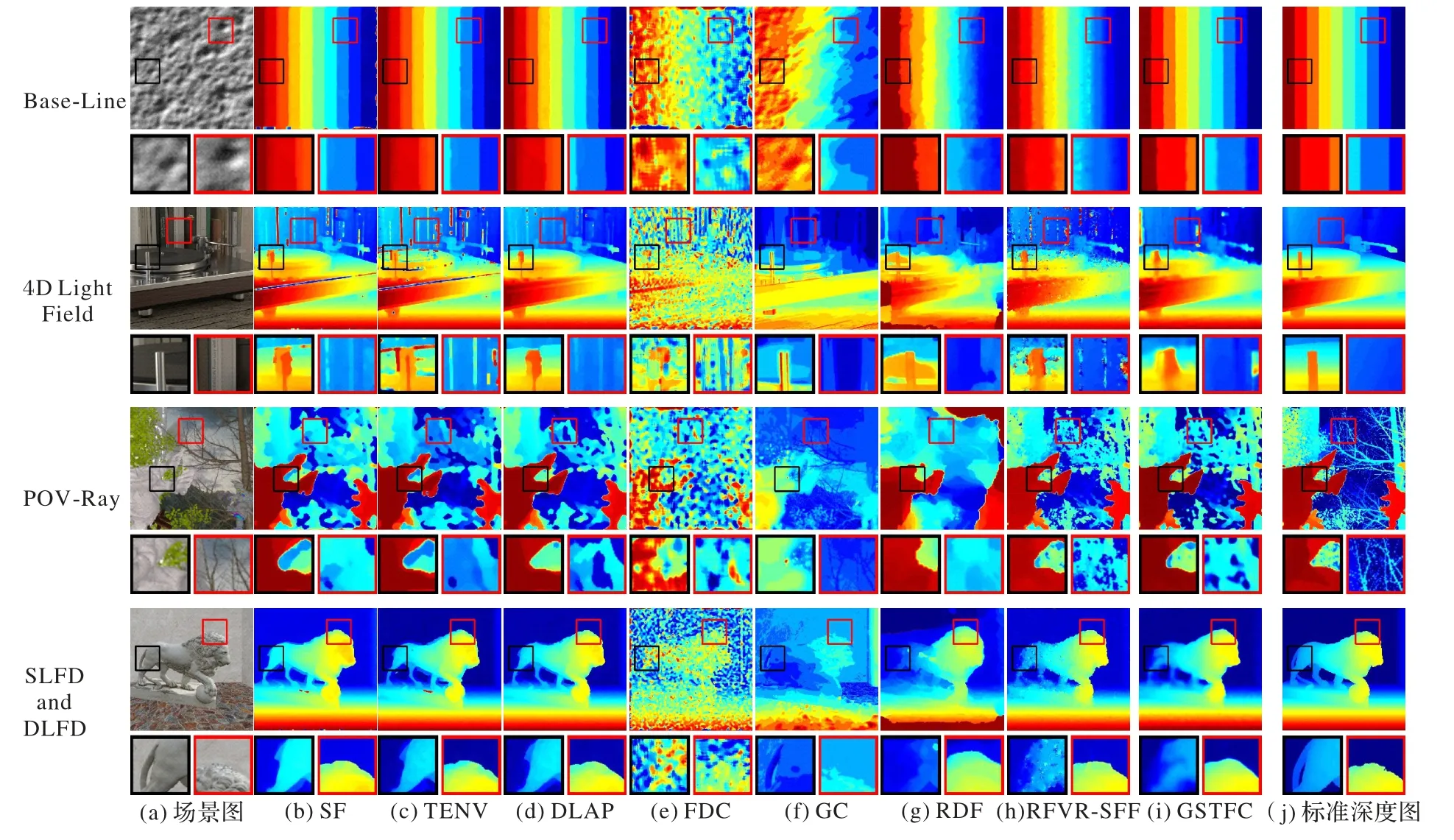
图3 不同模型的重建结果可视化对比Fig.3 Visualized comparison of reconstruction results of different models
Base-Line 数据集以富纹理场景为背景并使用常见的深度形状模拟生成,能考验各模型对聚焦区域的精准判断。GSTFC 相较于对比模型在4 个评价指标中均有优异表现;SF的深度边缘信息存在噪点;TENV 和DLAP 缓解了SF 的边缘噪声问题但聚焦测量仍存在不足;FDC 根据场景中的高低信息判断聚焦离焦,无法区分场景自身的高频和聚焦高频,在后续实验中同样表现较差。GC 主要根据场景信息辅助深度判断,对杂乱无章的背景无法鉴别导致它的表现结果差;RDF 和RFVR-SFF 在聚焦区域测量的表现相对表现良好。
4D Light Field 数据集进一步验证各模型对精细的场景结构的判断能力。GSTFC 的抗噪性优于RFVR-SFF,但在边缘保持方面稍有不足;SF、TENV 和DLAP 预测的深度图存在部分噪点;GC 可以表达精细的场景结构信息,但对多层深度嵌套表达不佳;RDF 对于聚焦测量不及RFVR-SFF。GSTFC模型对于场景的结构表达优于其他传统方法。
POV-Ray 数据集关注场景中的物体遮挡。在该数据集中,GSTFC 相较于其他传统模型在部分区域表现良好;SF、TENV 和DLAP 在预测过程中无法区分场景的细节纹理;GC可以分辨场景中的细节信息但深度值不够精确;RFVR-SFF和RDF 对于前后背景的遮挡表现不佳。GSTFC 模型在整体结构表达上表现良好,但在细微结构的深度预测稍有不足。
SLFD and DLFD 数据集关注各模型对弱纹理背景的处理,GSTFC 模型引入多景深图像序列的全局时空特征,有助于提取场景中弱纹理区域之间的对比关系,同时降低了噪声对结果的影响。GSTFC 模型在该数据集的弱纹理区域预测优于对比的传统模型。
2.7 稀疏性实验
由于基于深度学习的三维形貌重建算法依赖数据集的可扩展性,本节中仅展示与传统模型的对比。为评估采样频率对各模型的影响,使用SLFD and DLFD 数据集展示不同采样频率下各模型的三维形貌重建能力。为保证实验对比的公平性,仅使用采样频率为100 的DFF 数据集训练,在测试过程中仅使用图像复制操作补齐。多景深三维形貌重建的最佳采样是针对待测场景的层次结构依次采样,以保证聚焦度量的唯一性并完整呈现待测场景的三维形貌。当对待测场景进行富采样时,多余的离焦图像会携带干扰聚焦算子,并影响最终的场景分层数;而稀疏采样时,不足的聚焦图像序列难以保证离焦区域的深度信息。由此可见,多景深三维形貌重建模型在同一场景不同采样频率的重建效果不一,并由于各模型的聚焦测量算子和深度修复算法不同,各模型的三维形貌重建效果峰值不一。图4 为随机场景下采样频率由10 到100 逐次递增10 时各模型的性能对比,可以看出GSTFC 在多数采样频率下优于RDF 和RFVR-SFF。图5 为采样频率r=2,5,…,100 时,各模型的三维重建效果。
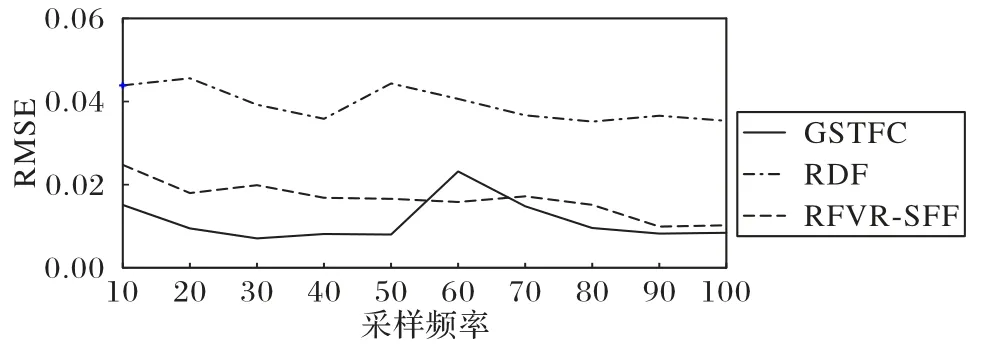
图4 不同采样频率下各模型性能对比Fig.4 Comparison of performance of different models at different sampling frequencies

图5 稀疏性对比实验结果Fig.5 Comparison experimental results of sparsity
当r=1 时,多景深三维形貌重建退化为单图像深度估计,无法利用现有的深度线索。当r=2 时,GSTFC 模型不仅可以辨别前景和背景的关系,还可以表达场景的部分过渡信息,而RDF 和RFVR-SFF 仅能观测到简单的前后关系,无法理解场景内容;当r=5 时,GSTFC 模型已经可以对场景中前后层次有良好的表达,而RDF 和RFVR-SFF 同样能表达层次关系,但由于无法提取序列关系并未显示出聚焦和离焦的过渡关系,还存在大量噪点无法处理;当r=10,30,50,100 可以逐渐覆盖整个场景时,GSTFC 模型有良好的场景细节刻画和前景背景分离能力,可以保留更多的景深过渡关系。
3 结语
相较于其他深度线索的三维形貌重建方法,基于多景深图像序列的三维形貌重建方法高效利用图像携带的场景信息和聚焦信息,较高的重建效率和较低的应用成本有利于该方法在更多的场景适用。本文提出全局时空特征耦合(GSTFC)模型注重提取多景深图像序列之间的聚焦与离焦的过渡信息和场景结构信息。相较于现有的深度学习模型和传统的三维形貌重建模型具有更加精准的聚焦测量,并在弱纹理场景中表现良好。未来研究主要聚焦于以下两方面:1)如何将场景结构信息注入神经网络中,使网络模型可以自适应多场景应用。2)如何对多景深图像序列提前作预处理操作,在保留关键信息的同时降低网络输入量,进一步降低成本量并提升网络效率。
猜你喜欢
成都信息工程大学学报(2021年4期)2021-11-22
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
材料科学与工程学报(2016年4期)2017-01-15
中国光学(2015年1期)2015-06-06
电视技术(2014年19期)2014-03-11
郑州大学学报(工学版)(2014年6期)2014-03-01
化工生产与技术(2014年6期)2014-02-27
数码摄影(2009年8期)2009-10-14
