
分布式存储中基于局部修复码的负载均衡方法
2023-03-24 13:25龙运波唐聃
计算机应用 2023年3期
龙运波,唐聃
(1.中国科学院 成都计算机应用研究所,成都 610041;2.中国科学院大学 计算机科学与技术学院,北京 100049;3.成都信息工程大学 软件工程学院,成都 610225)
0 引言
随着信息产业的迅猛发展和普及,数据存储量呈爆炸式增长,国际数据公司预测到2025 年全球数据将增至175 ZB[1]。数据作为生产要素之一,已经被正式纳入国家所定义的要素市场化配置中,保障数据的可靠性和可用性具有重要意义,因此数据存储技术已成为现代信息产业架构中不可或缺的底层基座。在新兴技术的驱动下,存储主要面对的应用已经从数据库、文件、流媒体等传统应用转向云计算、大数据和人工智能等大规模数据应用场景,因此在存储效率、容错能力之外也给存储系统的即时访问性能提出了新的挑战。面对众多复杂的应用场景,大型分布式存储的访问效率至关重要。存储系统的访问效率受诸多因素影响,最重要的原因在于负载不均导致的资源竞争[2]。例如互联网中资源分布和访问呈现Zipf 定律,即少数流行度比较高的数据资源常常占据大部分的访问量,造成相应存储服务器的工作负荷远高于其他节点。另一方面,由于应急突发性事件而引发的系统大量并发访问,也会造成某些数据访问量剧增,使存储系统中访问热度偏移,从而严重影响存储系统的访问性能。因此如何高效地避免因节点的集中访问造成的负载不均,是分布式存储亟待解决的问题。
分布式存储中传统的负载均衡方法主要分为静态负载均衡和动态负载均衡。静态负载均衡指在系统设计之初对数据的访问规律进行先验分析,预先设定负载策略,避免出现负载不均的问题,主要方法有节点空间划分法[3]、多Hash法[4-5]。但由于数据应用场景的日益丰富,动态变化的访问负载难以预见,因此复杂场景需要动态地均衡系统负载。动态负载均衡指在系统运行过程中,通过实时收集数据的访问特征和节点信息,动态调控出现的各种负载不均问题,其中应用最广泛的有动态副本法[6-7]和虚拟节点算法[8-9]。动态副本法主要针对存储系统中冷热数据资源访问不均的问题,通过增加热数据的副本数量,将数据的访问请求分散到多个节点,实现热点降温。不同动态副本算法之间的主要区别在于副本放置节点的选择不同。文献[6]中提出了一种树型副本放置策略,过热节点利用相邻节点建立一棵虚拟平衡树,树的同一层节点共同存储一个完整的数据副本。通过这种分散的副本放置策略,利用最少的副本数量实现负载均衡。虚拟节点算法主要针对因服务器配置不同而引起的存储负载不均问题,将物理服务器虚拟为多个相同配置的虚拟节点,并将它随机分布避免因资源分布不均导致的存储负载失衡问题,同时可以灵活删除和添加虚拟节点以实现存储系统的负载转移。文献[10]中基于虚拟节点的一致性哈希提出了一种动态负载均衡方法,通过动态收集和分析数据访问情况以均衡调度节点间的负载。无论是上述的静态负载均衡还是动态负载均衡,通常基于多副本冗余技术,针对数据的访问负载,预先或实时设置数据资源的副本数量和放置规则来提供多种访问方式,以实现负载均衡。然而这种方式在均衡负载的同时,存储系统的空间利用率大打折扣,同时频繁地创建、迁移、删除数据副本也会给网络带宽带来巨大压力。
纠删码的出现为分布式存储的负载均衡提供了更多可能。纠删码主要用于存储容错,以基于最大距离可分(Maximum-Distance-Separable,MDS)码的分布式存储系统为例,(n,k)-MDS 码将一份源文件切分成k个源数据块,编码成n个存储数据块(当中有n-k个冗余的校验数据块),然后将这n个存储数据块分别存放于n个节点中,于是其中任意k个数据块可以通过译码恢复得到源文件。文献[11]中注意到纠删码除了容错能力,还能以更小的代价代替多副本策略来高效地提高存储系统访问性能。文献[12]中结合队列理论和纠删码,利用(n,2)-MDS 码对数据进行编码,并结合Bloking-one Scheduling 算法均衡节点访问负载,以提高数据的访问效率。文献[13]中将随机线性网络编码应用于存储系统,通过阻塞算法均衡访问负载,降低数据的访问延时。文献[14]中基于(n,k)-MDS 码提出了(n,k)-fork-join 模型,将访问请求分为n份发给n个服务器,取任意k个服务器的响应数据即可完成访问,以此提高网络分布式存储中的文件下载速度。此后,许多研究致力于通过纠删码提高存储系统的访问效率[15-19],但由于编码后的数据被分为n个数据块,通常需要至少k个数据块才能获取一份文件的完整数据,当多任务访问一个数据时还须合理使用队列理论或调度策略处理访问请求的排队,计算量和通信带宽的代价高昂。
近年来局部修复码(Local Repair Code,LRC)、再生码(Regenerating Code,RC)的研究颇受关注,它们主要针对存储系统中局部零星节点数据失效频率较高的情况,以提升传统纠删码的修复效率[20-21]。其中局部修复码的突出优点是只需要较少节点就能恢复某个失效数据块,很大程度上降低了修复开销,所以近年来在存储容错的应用中备受关注。例如文献[22-23]中利用有理函数域和椭圆曲线构造了一类码长与运算域大小呈线性关系的局部修复码;文献[24-27]中提出能够纠正多个删除错的一类(r,δ)局部修复码。研究码长扩展更自由、局部修复能力更强的局部修复码是国内外学者们进一步追求的目标。除了应用于存储系统的高效容灾,一类特殊的局部修复码还可以在存储系统的负载均衡上发挥有效作用,本文将它称为具有(r,t)-并行访问性能的LRC。该码类的一个非常重要的特性是具有(r,t)-availability 性能,即n个编码数据块中的任一个数据块都能由t组不相交的修复集重构,且每组集合至多有r个码符,r≪k。局部修复码的方法为每个数据块提供了t种平行的访问方式供选择,每种访问方式相较于传统纠删码都大幅节省了计算成本和修复带宽。该特性来源于文献[28],需要将局部修复码的码率和最小汉明距离适当折中。然而,并非所有的局部修复码都适用于负载均衡的应用场景,只有如文献[28-34]的(r,t)局部修复码,才能在负载均衡的应用上表现出更加高效的性能。在这些理论研究中,Wang等[28]首次为局部修复码引入了(r,t)-availability 的概念,Rawat等[29]在此基础上取得了较大突破,将具有(r,t)-availability 性质的局部修复码定义为(n,k,r,t)-LRC,同时将它的性能参数t由2 推广到了t≥2 的一般情形,使局部修复码具有更灵活的并行局部修复能力,也正是这项工作使该类局部修复码能够成为本文实现负载均衡的核心与关键。Hao等[31]利用低密度校验码在二元域上构造了该类局部修复码,Balaji等[32]也基于二元域给出了码长为(r+1)g的(n,k,r,t)-LRC,Zhang等[33]将它推广为更一般的情况,使码长不再局限于r+1 的指数倍,但参数t≤r,限制较为严重。还有一些理论研究[35-36]关注于该码类的码距、码率及码长上界。事实上,(n,k,r,t)-LRC 只是局部修复码的一小类分支,且大多仍是在存储容错的应用场景下进行理论研究,关注存储系统中负载均衡的侧面应用尚不多,只有一些研究[37-42]利用局部修复码来提高存储系统中的文件下载速度。文献[41-42]中提出局部修复码在应用于高频访问场景下的存储系统时,它的访问效率相较于纠删码和多副本策略提升较大。但这些研究主要依赖队列理论实现,局限于队列中任务分配等技术细节问题,较少关注到(n,k,r,t)-LRC本身在访问负载均衡应用中的巨大潜力。
本文利用局部修复码中(r,t)-availability 性能所带来的(r,t)-并行访问性能为分布式存储系统的文件(数据)访问提供一种负载均衡的方法。主要包括:1)数据块之间访问热度的负载均衡以应对因数据热点偏移造成的负载不均;2)各存储节点间的负载均衡以提升系统的整体性能。本文给出了局部修复码(n,k,r,t)-LRC 的三种针对性的(显式)构造,该负载均衡方法相较于其他基于纠删码或多副本的方法能够以更小的代价达到了更好的负载均衡效果。
1 预备知识
本文的 负载均 衡方法 主要基 于(n,k,r,t)-LRC 的(r,t)-availability 性能进行设计,因此本章首先对背景知识及所需的方法工具进行介绍。
1.1 (n,k,r,t)-LRC的概念及性质
(n,k,r,t)-LRC 是一类特殊的局部修复码,最早由Rawat等[29]给出。假设有信息向量m=(m1,m2,…,mk),利用(n,k,r,t)-LRC 对它编码,得到编码向量c=(c1,c2,…,cn)。本文称c(ii∈[n])为码字符号,其中:ci∈m为信息符号;[n]代表{1,2,…,n}的整数集合,全文的[t]、[k]、[t]、[b]、[c]等都表示为对应的整数集合。(n,k,r,t)-LRC 应满足以下性质:
1)对于每个信息符号ci∈m,都存在t个不相交的子集Г1(i),Г2(i),…,Гt(i) ⊂[n]{i},以Гj(i)为索引的码符cГj(i)可以构成ci的函数式。
2)每个子集的元素个数|Гj(i)|≤r,j∈[t],i∈[k]。
3)任意两个子集的元素都不相交,即对于任意i∈[k],j≠l∈[k],都有Гj(i) ∩Гl(i)=∅。
基于以上定义的(n,k,r,t)-LRC 具有(r,t)-availability 性能,本文称之为(r,t)-并行访问性能:对于任意信息符号,都存在t个不相交的集合可以分别构成函数式进行重构,且每个集合至多包含r个其他码符。将函数式用于分布式存储,能够为编码后的每一个数据块提供t+1 种访问方式,以实现分布式存储中数据块之间访问热度的负载均衡。
1.2 平衡不完全区组设计
本文基于平衡不完全区组设计(Balanced Incomplete Block Design,BIBD)给出了三个(n,k,r,t)-LRC 的构造方法。其中BIBD 是组合数学中一类特殊的区组设计。
定义1设X=(x1,x2,…,xk)是一个包含k个元素的有限集合;ℬ=(B1,B2,…,Bb)是X的一族子集,称Bi为区组(blocks)。当满足以下两个条件时,称(X,ℬ)为一个(k,b,r,c,λ)-BIBD。
1)|X|=k,|ℬ |=b,且对于所有的i∈[b],|Bi|=r。
2)每一对(x,y) ⊂X恰好包含于λ个区组中。
当ℬ 可以被划分为c个平行类(parallel classes),则称(X,ℬ)是可解的,其中一个平行类指ℬ 中多个不相交的区组构成的子集,且这些区组的并集为X。
定义2定义一个可解平衡不完全区组设计(Resolvable Balanced Incomplete Block Design,RBIBD)(X,ℬ)为(k,b,r,c,λ)-RBIBD,ℬ 可以被划分为c个平行类ε1,ε2,…,εc⊂ℬ。其中:i∈[c];j∈[k];|B∈ε∶ixj∈B|=1,即在一个平行类中,所有元素是唯一的。在RBIBD 中,参数需要满足r|k。
可以用一个k×b维的关联矩阵M表示一个区组设计(X,ℬ),M的行对应元素x1,x2,…,xk的索引,M的列对应区组B1,B2,…,Bb的索引,则M中的元素mij定义如下:
根据关联矩阵的定义以及BIBD 的构造属性可知,(k,b,r,c,λ)-BIBD 的关联矩阵M的行重为c,列重为r,且任意两列中对应行索引相同的1 的个数至多是1 个。
一个(k,b,r,c,λ)-RBIBD 的关联矩阵M包含c组列向量集合M1,M2,…,Mc,它们的支撑构成集合[k]的t个不同划分,每组包含个列向量。显然M1,M2,…,Mc可以表示该RBIBD的c个平行类。
1.3 GF(2)上的随机矩阵及其性质
本文编码的构造需要使用GF(2)上的随机矩阵以及它的重要性质。
定义3设GF(2)上的矩阵Rn×k,n>k>0,若其中各元素取值相互独立,且满足取“0”的概率为p,取“1”的概率为1 -p。当p∈(0,1) 时,称它为随机矩阵;当p=0.5 时,称它为均匀随机矩阵。
文献[43]给出了定理1、2,并证明了它们的正确性。
定理1GF(2)上的随 机矩阵Rn×k列满秩 的概率 如式(2)所示,其中δ=n-k。
定理2设有GF(2)上列满秩的生成矩阵Gn×(kn>k>0)和校验矩阵Hn×n(m=n-k)。若Gn×k中删除任意t(t<min{k,m})行仍然列满秩,则Hn×n中对应t行线性无关。
推论1 根据定理1 和定理2,给定一个二元域上的随机矩阵Rn×k,可以构造一个具有高概率容错能力的纠删码,以P的概率容n-k-δ个删除错,本文称它为近似δ-MDS 码。
证明 定理2 指出,若生成矩阵Gn×k删除任意t=n-k-δ行仍列满秩,则校验矩阵Hn×n中对应t行线性无关,即译码矩阵存在唯一解。因此,校验矩阵成功译码的概率等于生成矩阵的满秩概率。而根据定理1,利用GF(2)上的随机高矩阵作为生成矩阵,它满秩的概率如式(2)所示,当随机矩阵的分布概率p=0.5 时,满秩概率;当δ>20时,随机矩阵的满秩概率P>1 -10-7。这意味着该编码的高概率译码能力可用于分布式存储系统对数据进行编码。
文献[43]中基于二元域上随机矩阵的优良性质提出了随机阵列码。本文将用它给出(n,k,r,t)-LRC 的一种构造方案,选择随机阵列码作为构造基础,主要考虑到以下优势:1)随机阵列码的参数不受有限域规模的限制,为存储系统提供的容错能力也可根据容错需求扩展。2)随机阵列码的编译码基于二元域的异或运算,文献[43]中通过实验证明了它相较于里所(Reed Solomon,RS)码、柯西里所(Cauchy Reed Solomon,CRS)码等MDS 码具有更高的编译码速率,尤其是在大规模构造中表现良好。其中CRS 码的编译码虽然也可以采用异或运算,但由于它的本质是将GF(2w)域中的元素映射为二元域中的比特矩阵,在编码过程中,生成矩阵的规模相较于随机阵列码增大了w2倍,相应的异或运算次数也会成倍增加,导致编译码效率降低,且效率差距在大规模编码中会愈加明显。3)根据推论1,随着规模的增长,随机阵列码的存储效率趋近于MDS 码,有较高的存储空间利用率。
2 构造(n,k,r,t)-LRC
本章给出了(n,k,r,t)-LRC 的显式构造方法,其中使用了前面介绍的(k,b,c,r,λ)-RBIBD和GF(2)上的随机矩阵。
早在文献[29,34]中就曾利用(k,b,c,r,λ)-RBIBD 构造局部修复码的局部修复组,但没有提到(k,b,c,r,λ)-RBIBD的显式构造方法。而在一些专门针对BIBD 的研究[44]中,大多采用 正交拉丁方(Multiple Orthogonal Latin Squares,MOLS)或有限射影平面进行构造,这些方法复杂且没有程序化的实现方法。因此本文提出一种RBIBD 的显式构造算法。
2.1 (k,b,c,r,λ)-RBIBD的构造算法
根据(k,b,c,r,λ)-RBIBD 的定义及性质,可以采用向量筛选的办法在列重为r的k维列向量全集Ω中筛选向量,使筛选得到的向量集合满足以下条件:
1)任意两个向量至多有一个1 的位置相同;
2)向量集合可以划分为c个不相交的子集,子集中所有向量的并恰好是一个元素全1 的向量。
根据以上分析,给出(k,b,c,r,λ)-RBIBD 的构造算法。

算法1 能够显式地构造一个(k,b,c,r,λ)-RBIBD,虽然参数c的取值有限,但本文的目的是将它应用于局部修复码构造局部校验列,为数据块提供(r,t)-并行访问性能,一般只需要少量平行类就能满足数据块对并行读取能力的要求。
例1设X={1,2,…,15},利用算 法1 可以构 造一个(15,15,3,3,1)-RBIBD 的关联矩阵M如式(3)所示,对应的RBIBD 如表1 所示,其中:b=15 个不同的三元组集合表示区组,任意两个元素恰好只出现在λ=1 个区组中,这些区组可以分为3 个平行类ε1、ε、ε3,每个平行类中的区组都是集合X的划分。

表1 一个(15,15,3,3,1)-RBIBD的例子Tab.1 An example of(15,15,3,3,1)-RBIBD
2.2 (n,k,r,t)-LRC的构造方法
基于算法1 给出的(k,b,c,r,λ)-RBIBD,本文面向分布式存储数据块访问负载均衡给出了三个(n,k,r,t)-LRC 的构造方法。
2.2.1 构造方法1
通过算法1 构造一个(k,b,c,r,λ)-RBIBD 的关联矩阵M,设M1,M2,…,Mt为M的t组列向量集合,表示RBIBD的t个平行类。可以通过如下方式构造一个
-LRC 的生成矩阵G。
1)生成矩阵G的前k列由单位矩阵Ik×k构成;
2)在(k,b,c,r,λ)-RBIBD 的关联矩阵M中选取t组向量集合M1,M2,…,Mt,每组列向量集合包含个列向量。G的后列由M1,M2,…,Mt构成,使G=[Ik×k|M1,M2,…,Mt]。
例2 根据方法1,可以构造一个(25,15,3,2)-LRC,码字的生成矩阵G=[I15×15|M1,M2],M1、M2取例1中M的前10列。设信息向量m=(m1,m2,…,m15),则码字c=(m1,m2,…,m15,l1,l2,…,l10)=mG,其中:(l1,l2,…,l10)为t·k/r=2×15/3=10个局部校验符号,给信息向量m中的每个符号提供(3,2)-并行访问性能。例如m1可以直接获取,也可以选择{m4,m11,l1}或{m3,m6,l7}两组码符组成的函数式通过计算进行访问。
显然方法1 给出的(n,k,r,t)-LRC 具有(r,t)-并行访问性能,但由于大规模分布式存储需要一定的容错能力保证数据可靠性,本文在方法1 的基础上给出方法2 及方法3。
2.2.2 构造方法2
给定一个(k,b,c,r,λ)-RBIBD 的关联矩阵M,给定一个(N+t,k)-RS 码的生成矩阵,可以通过如下方式构造一个(n=N+t·k/r,k,r,t)-LRC 的生成矩阵G。
1)生成矩阵G的前N列由的前N列构成;
2)根据Mi的支撑,将的第N+i列划分成k/r列,使每一个列向量的列重为r,其中:i∈[t]。将划分所得的向量作为G的后t·k/r列。
在方法2 的生成矩阵G中,前k列对应码字的信息符号,第k+1~N列对应码字的全局校验,最后k·t/r列对应码字的局部校验。方法2 借鉴了文献[29]中Construction1 的构造思路,不同之处在于本文给出了其中(k,b,c,r,λ)-RBIBD 的详细构造方法。
例3 基于GF(26)给定一个(22,15)-RS 码的生成矩阵如式(4)所示,其中的前15 列为单位矩阵,第16~22 列为范德蒙矩阵。根据方法2,将的最后t=2 列如图1 所示划分成t·k/r=2×15/3=10 列作为 局部校验列,得到一 个(30,15,3,2)-LRC 的生成矩阵G。这些局部校验列为编码后的每个信息符号提供了(3,2)-并行访问性能。
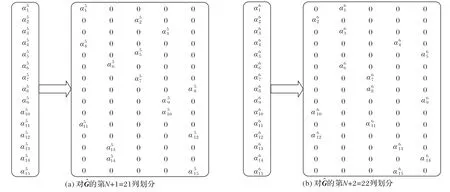
图1 例3中生成矩阵G的构造过程Fig.1 Construction procedure for generated matrix G in example 3
方法2 给出的(n,k,r,t)-LRC 仍然具有(r,t)-并行访问性能,相较于方法1,它的优势在于拥有一定的容错能力。
定理3当r|t,且存在一个(k,b,c,r,λ)-RBIBD,其中:c≥t,它的关联矩阵M可由算法1 给出,那么方法2 给出的(n=N+t·k/r,k,r,t)-LRC 能够修复个删除错。最小汉明距离为:
证明 对于(N+t,k)-RS 码,它的最小汉明距离满足dmin(c)=N-k+t+1,在方法2 中,G的后t·k/r列向量总是能够通过线性变换重构中的t列,与前N列一起构成RS 码的生成矩阵,因此方法2 给出的(n=N+t·k/r,k,r,t)-LRC 满足,即式(5)。
方法2 给出的(n,k,r,t)-LRC 具有(r,t)-并行访问性能,同时达到了(n,k,r,t)-LRC 的最小汉明距离上界,但由于方法2 基于RS 码构造,因此需要与RS 码保持同一有限域大小。事实上,方法2 的(n,k,r,t)-LRC 只适用于中小规模的存储系统,因为随着码长n的增大,有限域将线性增长,在大规模有限域上的矩阵运算效率低下。针对这个问题,本文提出了方法3 以适用大规模存储系统的负载均衡。
2.2.3 构造方法3
根据定义3 构造一个GF(2)上的满秩随机矩阵RN×k,利用初等行变换将RN×k变换为上单位阵的形式,使:
给定一个(N,k,δ)-随机编 码的生成矩阵=RT=[Ik×k|Dk×m],以及(k,b,c,r,λ)-RBIBD 的关联矩阵M,可以通过如下方式构造一个(n=N+k·t/r,k,r,t)-LRC 的生成矩阵G。
1)生成矩阵G的前N列由的前N列构成;
2)选取(k,b,c,r,λ)-RBIBD的t个平行类,即在关联矩阵M中选取t组列向量集合M1,M2,…,Mt,每组列向量集合包含k/r个列向量。G的后t·k/r列由M1,M2,…,Mt构成,使G=[Ik×k|Dk×m|M1,M2,…,Mt]。
同方法2 一样,在方法3 的生成矩阵G中,前k列对应码字的信息符号,第k+1 到第N列对应码字的全局校验,最后t·k/r列对应码字的局部校验。显然这些局部校验列为码字中的每个信息符号提供了(r,t)-并行访问性能,同时方法3 继承了GF(2)上随机阵列码的容错能力及高效的编译码速率。
定理4当r|t,且存在一个(k,b,c,r,λ)-RBIBD,其中:c≥t。它的关联矩阵M可由算法1 给出,那么方法3 给出的(n=N+k·t/r,k,r,t)-LRC 能够以的概率修复n-k-k·t/r+t-δ个删除错。
3 基于(n,k,r,t)-LRC的负载均衡方法
第2 章给出了三个(n,k,r,t)-LRC 的构造方法,本章将它们应用于分布式存储,以实现数据块间访问热度及存储节点间的负载均衡。
3.1 数据块间访问热度的负载均衡
在分布式存储中,一个完整数据将被划分为k个数据块进行存储。针对不规模的存储系统,本文选取相应的(n,k,r,t)-LRC 对数据块进行编码,编码过程可以表示为:m1×k×Gk×n=c1×n。其中:信息向量m1×k表示原始数据块向量;码字c1×n表示编码数据块向量。由于复杂的数据应用场景,数据块之间的访问热度负载不均成为常态,某些数据块过高的访问热度成为访问效率的瓶颈。因此,本文首先基于(n,k,r,t)-LRC 的(r,t)-并行访问性能给出了一个热数据访问算法以降低热数据的访问压力。


例4 设数据块m=(m1,m2,…,m15),利用方法1 给出的(25,15,3,2)-LRC 进行编 码,得到编 码数据 块向量c=(m1,m2,…,m15,l1,l2,…,l10)。其中l1,l2,…,l10为局部校验块,根据生成矩阵G可得局部校验块的生成式如表2 所示,构成两组不相交的修复集。假设数据块m1的访问热度过高,根据算法2,可以得到t=2 组索引集合Г1={4,11,16},Г2={3,6,22},对应的两组编码块向量为mГ1=(m4,m11,l1),mГ2=(m3,m6,l7)。由生成矩阵G进行译码可得m1的两个译码公式如式(7)、(8)所示,根据算法2 的步骤6),动态选择其中之一作为m1的访问方式,即可分散多个请求对于m1的访问负载,实现数据块间的负载均衡。

表2 例4中局部校验块的生成式Tab.2 Generation formulas of local parity blocks in example 4
3.2 分布式存储节点间的负载均衡
分布式存储中节点间的负载不均也是影响性能的重要因素,通常可以使用合理的数据布局及迁移策略来均衡节点负载。为了避免频繁的数据迁移影响存储系统的整体性能,本文结合热数据访问算法,通过合理的数据布局达到更优的负载均衡效果。
小规模分布式存储可以采用方法1 的(n,k,r,t)-LRC 对数据编码,为了在均衡节点负载的同时也能发挥存储系统的局部修复性能,将编码数据块如图2 所示布局于存储系统中,称其为纵式布局:
1)首先在编码数据块中任选一个修复集,将数据块及局部校验块按照修复集中的分组方式纵式存储于各节点中,如例4 中,选择修复集1,则原始数据块将按照该修复集分组存储于各存储节点,对应的局部校验块l1,l2,…,l5负责各自节点内的局部修复。
2)为实现节点间的负载均衡,将其余修复集的局部校验块与关联数据块错位存储。如例4,修复集2 中,局部校验块l6与数据块m2、m10、m12相关联,它们分别存储于D3、D4、D5,那么l6要与它们错位存储,就只能存储在D1或D2中。于是按照这个规则,l6,l7,…,l10的存储布局如图2 所示。

图2 一个(25,15,3,2)-LRC的编码数据布局Fig.2 Encoded data layout of a(25,15,3,2)-LRC
纵式存储布局有以下两点优势:
1)实现存储节点间的负载均衡。在例4 中,假设数据块m1的访问热度过高,可以选择式(7)或式(8)两种方式对m1进行访问。而结合图2 可以看出,利用式(8)进行访问,访问请求可以被分散到D2~D4节点,使节点之间负载均衡。
2)当节点内数据块发生删除错时,可以利用某一修复集在节点内进行修复,节省了跨节点修复的数据访问开销,进一步提升系统性能。
对于中大规模的存储系统,可以使用方法2 或方法3 给出的(n,k,r,t)-LRC 对数据进行编码,提供负载均衡、局部修复,及较好的容错能力,对其编码数据使用横纵联合布局:
1)首先仍然对局部校验块采用纵式布局方案,最大化节点间的负载均衡效果和存储系统的局部修复性能,如例5中,给出l1,l2,…,l10的存储布局如图3 所示。
2)将全局校验块单独存储于一个节点,称它为校验节点,如例5,校验节点D6存储了所有的全局校验块p1,p2,…,p5。
例5 假设数据块m=(m1,m2,…,m15),利用方法2 给出的(30,15,3,2)-LRC 进行编码,得到编码数据块向量c=(m1,m2,…,m15,p1,p2,…,p5,l1,l2,…,l10),其中:p1,p2,…,p5为全局校验块;l1,l2,…,l10为局部校验块,生成式如表3 所示,构成两个不相交的修复集。编码数据块的横纵联合布局如图3 所示,以发挥存储系统的负载均衡和局部修复性能。
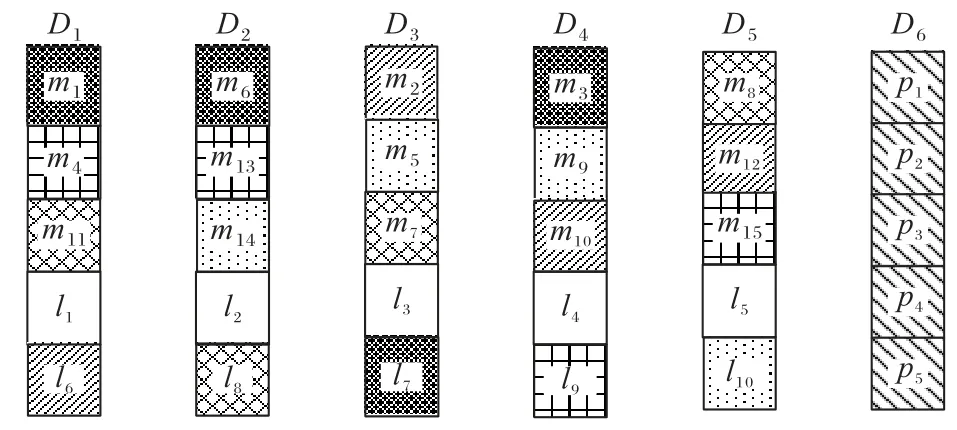
图3 一个(30,15,3,2)-LRC的编码数据布局Fig.3 Encoded data layout of a(30,15,3,2)-LRC

表3 例5中局部校验块的生成式Tab.3 Generation formulas of local parity blocks in example 5
该存储系统具有纵式布局的两个优势——节点间的负载均衡及节点内高效的局部修复性能。另外,全局校验块保障了存储系统不俗的容错能力,以采用方法2 中(n,k,r,t)-LRC 进行编码的存储系统为例,能够修复任意n-k-k·t/r+t个删除错,例5 中的存储系统可以容任意7 个数据块的删除错。
4 实验与结果分析
本文基于(n,k,r,t)-LRC 给出了一种适用于分布式存储的负载均衡方法,本章将展开具体实验。除此之外,还会从负载均衡代价、存储性能、扩展性能等多个维度与同类研究进行对比分析。
4.1 负载均衡能力分析
实验方案:本文生成k=30 个数据块,编号为(1,2,…,k),分别利用方法1 给出的(n=40,k=30,r=3,t=1)-LRC,(n=50,k=30,r=3,t=2)-LRC,(n=60,k=30,r=3,t=3)-LRC 进行编码,并模拟用户对这些数据块进行T次随机访问。以此设计两组对比实验,分别限定数据的随机访问范围为[ 1,k/2 ],模拟真实存储系统中数据块访问负载不均的情形。定义各数据块间访问次数的标准差S为负载均衡度,用于衡量负载均衡表现,标准差越小,负载均衡表现越佳。
实验假设数据块的访问次数为数据块热度,当数据块热度(访问次数)时,通过算法2 实现数据块间的访问负载均衡。
1)情形1,限定数据的随机访问范围为[ 1,k/2 ],它的数据块访问负载分布如图4(a)所示,访问负载集中在[ 1,k/2]这些数据块之间,负载均衡度S≈20.3。分别基于(n=40,k=30,r=3,t=1)-LRC、(n=50,k=30,r=3,t=2)-LRC 和(n=60,k=30,r=3,t=3)-LRC 使用算法2 均衡各数据块间的访问负载,得到访问负载分布如图4(b)~(d)所示。随着修复集数量t的增多,负载均衡度逐渐降低,分别为:S1≈14.1、S2≈10.4、S3≈5.2,可以看到算法2 表现出了优秀的负载均衡性能。
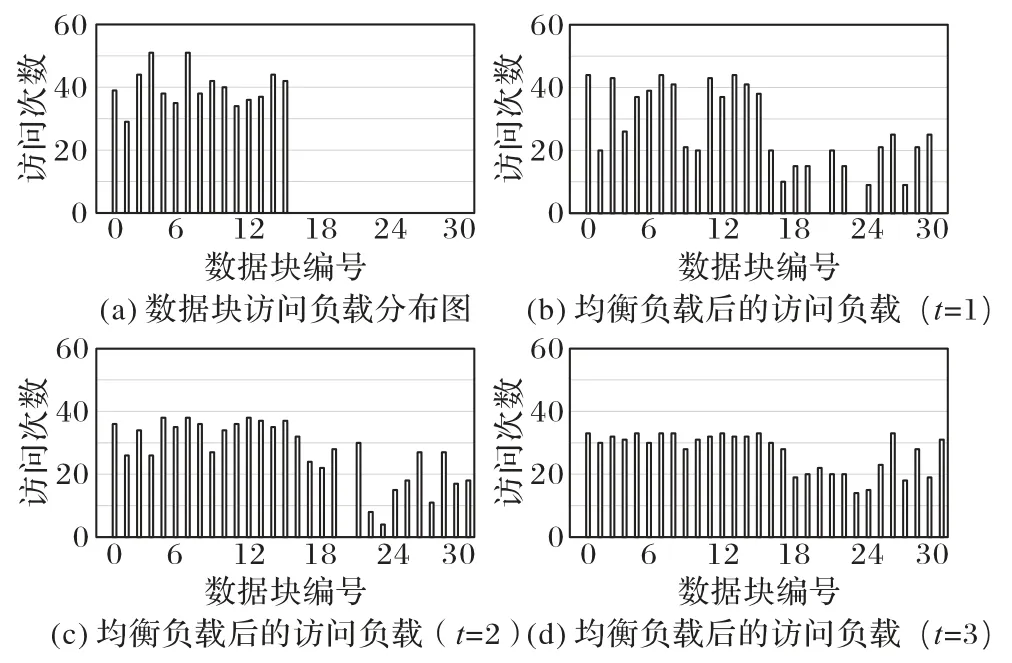
图4 情形1下的数据访问负载分布图Fig.4 Load distribution diagram of data blocks in case 1
2)情形2,更极端的情况,本文限定数据的随机访问范围为[ 1,],数据块访问负载分布如图5(a)所示,访问负载集中在[ 1,]这些数据块之间,此时的负载均衡度S≈36.5。分别基于方法1 给出的(n=40,k=30,r=3,t=1)-LRC、(n=50,k=30,r=3,t=2)-LRC、(n=60,k=30,r=3,t=3)-LRC 使用算法2 均衡各数据块间的访问负载,均衡后的访问负载分布如图5(b)~(d)所示,对应的负载均衡度分别为S1≈25.5、S2≈17.8、S3≈14.3。
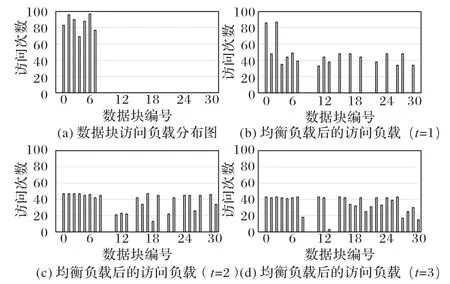
图5 情形2下的数据访问负载分布图Fig.5 Load distribution diagram of data blocks in case 2
4.2 对比分析
上述实验证明了本文基于(n,k,r,t)-LRC 的负载均衡方法可以有效地应用于存储系统均衡数据块间的访问负载,且随着t的增大,负载均衡能力逐渐增强。相较于同类研究,如基于多副本的负载均衡策略与基于纠删码的负载均衡策略,本文方法的代价更小、效率更高。
本文方法的核心思想是利用(n,k,r,t)-LRC 的(r,t)-并行访问性能为每个数据块提供t种不同的访问方式,以此均衡数据块间的访问负载,执行负载均衡方法仅仅会增加存储系统r-1 倍的访问量。而基于(n,k)-MDS 码的负载均衡方法,每次触发均衡方法都会激增k-1 倍的访问量。例如,文献[19]中提出了一种基于(2k,k)-MDS 码的负载均衡方法。在情形2 的实验基础上,基于(2k,k)-MDS 码使用算法2 均衡访问负载,得到实验结果如图6 所示,可以看到索引号为(k/4,k]的数据块之间增加了大量的访问请求,但原热点数据块的负载压力并没有明显减轻,这正是因为在该实验中每执行一次负载均衡都会激增k-1=29 倍的访问量,代价巨大。相比之下,图5(d)中的负载均衡效果显著,基于(n,k,r,t)-LRC 每执行一次负载均衡方法只增加r-1=2 倍的访问量。本文方法中的r远小于k,实际应用中将极大地节省网络带宽、减少访问负载。另一方面,基于(n,k)-MDS码的负载均衡方法,普遍存在的问题是基于有限域的运算复杂,它的规模难以扩展。针对这个问题,本文基于方法3 给出的(n,k,r,t)-LRC 结合了二元域上随机阵列码的优良性质,可以应用于大规模存储系统。

图6 使用MDS码进行实验的负载均衡效果Fig.6 Load balancing effect in experiment using MDS code
相较于多副本方式的负载均衡方法,本文方法更有优势。一方面数据以多副本方式存储于系统中,存储效率极低,以三副本为例,它的存储效率只有33%。另一方面,基于多副本的负载均衡会涉及频繁的数据迁移,降低存储节点的使用率。本文很好地解决了这些问题,利用(n,k,r,t)-LRC将数据编码后进行存储,存储效率k/n>50%是常态;利用局部修复码的(r,t)-并行访问性能以及合理的数据布局方案,本文的负载均衡方法有效避免了频繁的数据迁移。
5 结语
随着数据应用场景的日益丰富,面向热数据的分布式存储对访问效率提出了更高的要求。针对存储系统中热数据访问频率过高,导致冷热数据负载严重失衡的问题,本文基于(n,k,r,t)-LRC 提出了一种适用于分布式存储的负载均衡方法,以提高存储系统的访问性能。其中(n,k,r,t)-LRC 是存储编码新技术的前沿课题,本文给出了一种面向分布式存储负载均衡应用的显式构造方法,利用(n,k,r,t)-LRC 的(r,t)-availability 性质,不仅能快速响应丢失数据块的修复请求,进行局部修复,还能够为每个数据块提供t+1 种不同的访问方式,以均衡数据块间的访问负载。相较之下,现有的同类研究在实现负载均衡时会导致访问量激增,额外带来大量的网络带宽。而本文方法以更小的代价达到了较好的负载均衡效果,不仅考虑了数据块间的访问负载均衡,还通过合理的数据布局尽可能均衡了各节点间的访问负载。另外,本文方法也可以为后续更多数据存储应用提供思路,如适用于边缘计算的存储系统实质上与本文的核心思想有异曲同工之妙。
尽管如此,本文方法也存在一定的局限性。一方面,由于RBIBD 的生成算法和计算机的算力影响,在构造(n,k,r,t)-LRC 时,修复集的数量t受到限制,而它对负载均衡的效果影响重大,如何在理论范围内构造任意规模、任意参数的(n,k,r,t)-LRC 是一大挑战;另一方面,如何设置参数t,在负载均衡效果与存储效率之前寻找平衡,以最小的代价达到理想的效果,值得进一步研究。
猜你喜欢
哈尔滨轴承(2020年2期)2020-11-06
发明与创新·大科技(2019年12期)2019-03-17
中国铸造装备与技术(2017年6期)2018-01-22
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
雷达与对抗(2015年3期)2015-12-09
中国教育信息化(2015年12期)2015-08-24
电测与仪表(2015年1期)2015-04-09
电测与仪表(2015年10期)2015-04-09
电测与仪表(2015年19期)2015-04-09
