
基于HBase的工业时序大数据分布式存储性能优化策略
2023-03-24 13:25杨力陈建廷向阳
计算机应用 2023年3期
杨力,陈建廷,向阳
(同济大学 电子与信息工程学院,上海 201804)
0 引言
随着信息技术飞速发展,大数据正在成为各大产业领域的重要资产,并且物联网、5G 等技术的高速发展也导致大数据的范围扩大化和来源多样化[1]。随着全球工业水平提升,工业大数据已成为大数据家族的重要成员,其中时序数据就是重要且典型的工业大数据类型。在各大智能工业场景中,大量不同来源的异构时序性日志数据量呈爆炸式增长,在时序数据规模越来越大的情况下,海量工业时序数据的存储与管理成为了大数据领域的研究焦点[2]。
广义的时序数据,即带有时间信息的数据记录,通常可以通过结构化方式表示。时序数据具有时间序列化、时段密集化、单条数据高权重、数据产生高并发、数据总量巨大的特点[3]。在工业场景下,工业时序数据通常由上百台工业设备的上万个传感器产生,各传感器采样周期堆叠,并且各数据之间可能存在复杂的依赖关系,因此工业时序数据具有采样周期密集和强关联的特点[4]。工业时序数据主要包含设备参数、设备运行状况、设备负载程度等,反映了各设备在不同单位时间内的工作情况,对分析设备故障、提升设备工作效率进而优化整个工业场景整体管控都具有重要的意义[5]。
因此,工业系统对时序数据具有较高的数据访问需求。现有数据存储系统在面对该需求时极易发生负载不均衡现象,导致系统访问效率低下。在一些典型业务场景,如超大型自动化码头系统中,数以万计的码头设备传感器在极短的时间内产生大量设备工作状态时序数据,对于相同传感器或相近时间段数据的写入与读取,通常发生在同一存储节点上,极易造成存储节点因访问数据流量不均衡而引发的负载倾斜问题;且数据高维索引查询的效率较低,很容易出现数据访问速度慢,甚至服务器宕机的情况,这会严重影响业务流程的运行。因此,工业时序数据存储系统需要具备平衡数据访问负载的能力,实现多维度查询,从而支持对工业时序数据的高密度并发访问。
HBase 作为一种具有良好可扩展性的分布式列族数据库,常作为一种通用存储技术用于海量数据存储场景[6]。对于数据负载倾斜问题,目前主要基于HBase 的多存储服务器节点分散分布的特点,通过添加必要的系统模块以达到优化目的,主要分为预分区与被动分区两类。预分区方法在数据到来之前将Region 按照行键RowKey 进行分区,将后续写入的数据按不同策略写入特定分区[7-12];被动分区方法对数据进行监控,根据数据量、数据访问频率等数据变化特性进行动态分区[13-18]。但由于工业时序数据采样周期密集、强关联以及访问需求高的特点,现存的负载均衡方法没有考虑到特定业务场景中数据与访问行为特征的关联,无法满足特定场景下的数据访问需求,因此,在工业场景下,面向海量工业时序数据的分布式存储负载均衡策略值得进一步研究和探索。
本文基于分布式存储系统HBase 提出面向海量工业时序数据的分布式存储性能优化策略。针对工业时序数据的负载倾斜问题,本文发现工业系统具有相对固定的时序数据访问模式,通过对用户历史访问行为模式与数据特征的分析,提出基于冷热数据分区及访问行为分类的负载均衡优化策略。将待存储数据进行冷热分类并写入对应分区,进而缓解负载倾斜,提升后续数据读取效率;同时,为降低存储集群中跨节点通信开销以提升工业时序数据高维索引的查询效率,提出了索引主数据同Region 化策略。在真实工业时序数据上进行了对比实验,验证了本文策略能提升工业时序数据的存储性能,可满足工业场景下对时序数据的访问需求。
1 相关工作
针对时序数据特点所引发的负载倾斜问题,目前的主流方法是向HBase 引入必要的系统模块以达到优化目的,主要分为预分区和被动分区两类方法。
预分区方法在存储数据前就设定HBase 中不同数据分区的StartRowKey 和EndRowKey,进行预分区。Van Le等[7]基于Hbase 提出一种针对时序数据的智能存储策略,在HBase建表之前,根据要存储的时序数据的特征设计每个分区Region 的StartRowKey 和EndRowKey,然后设计表的预分区,以保证后来的时序数据均匀地分散在不同的Region 中,进而缓解用户密集访问高频时序数据所产生的负载不均衡问题。但随着时序数据量的指数级增长,单个Region 在很短的时间内就会达到Split 阈值,HBase 为保证数据安全会自动将超过阈值的Region 进行Split 操作,增大了HBase 的系统开销。王远等[8]提出在欲插入数据的RowKey 中添加随机字符串前缀,打乱时序数据插入的顺序,以避免将多条连续时序数据写入同一个Region,巧妙地避免了写热点问题;但该方式会同时降低数据查询的效率,并且忽略了读热点问题。Azqueta-Alzúqeta等[9]提出基于MapReduce 并行处理技术预先对写入的时序数据并行计算RowKey 值,然后根据HBase中各存储节点HRegionServer 的属性和数目特征,对数据表进行预分区;通过分布式计算框架MapReduce 并行处理确实加快了对高频时序数据的准备与存储过程,但并没有解决HBase Region 自动Split 而导致HBase 系统开销增大的问题。雷鸣等[10]提出面向海量气象半结构化与非结构化数据的HBase 负载均衡策略,通过修改HBase 内置数据分区模块,改变HBase 的分区规则,以达到负载均衡的目的;但这只是改变了Region 的大小,并没有考虑不同Region 内存储的数据被访问的频次差别。王璐[11]提出将分表存储与预分区相结合的策略,在数据写入前对数据表与预分区进行设计,缓解了HBase 的负载倾斜问题;但该方法并没有考虑在特定业务场景下不同表处理的数据访问请求数量的差异。张周[12]提出基于用户访问行为预测的HBase 分布式数据存储系统(HBase data storage system based on User access Behavior Prediction,PUB-HBase),该系统面向网络安全实验数据集,对HBase 的数据区进行冷热分类,对网络安全日志数据访问模式进行模型描述,并设计RowKey 字段实现索引与主数据的一致性,缓解负载倾斜问题;但该系统将热数据区(Hot Data Area)存放在集群磁盘中,降低了热数据读取效率,并且对数据读请求与索引查询请求字段的额外解析增大了系统处理数据访问请求的系统开销。
被动分区方法在系统运行中,通过监控数据存储量与数据被访问频率构建分区并设定分区的分布。Sun等[13]引入数据流块的概念并对负载进行预测和数据迁移,实现了系统的动态负载均衡,但还需优化数据迁移带来的系统与网络开销。Chen等[14]提出针对HBase 动态负载与数据热点问题的负载均衡策略,该策略动态考虑数据负载分布的变化,对数据进行动态存储,在一定程度上缓解了HBase 的负载倾斜问题,但没有考虑由于收集并处理节点实时负载分布信息而带来的系统额外开销。Xiong等[15]提出针对HBase 的负载均衡问题的策略,可分为全局计划、随机分配计划与批量启动分配计划,这些计划对Region 的个数进行管理和分配,改善了负载均衡问题,但并没有考虑到数据写热点问题,因为Region 数目均衡并不能保证实际负载均衡[16]。Ghandour等[17]向HBase 引入负载均衡器,均衡器通过监控热点访问数据动态地分割和移动访问频率更高的“热数据”,以提升对特定热点数据的访问负载均衡效果;但该策略只是被动地根据用户访问行为改变冷热数据的分布,必然会导致系统在执行负载均衡过程中对一些突发访问行为改变应对不及时,从而增大HBase 的额外开销。祝烨[18]提出一种通过搜集集群整体状态信息对热点数据进行动态管理的策略,但该策略并未考虑集群状态信息获取与汇聚时所产生的额外系统开销。
现有负载均衡方法没有考虑特定业务场景中数据与访问行为特征的关联性。本文结合预分区与被动分区的思想,考虑了工业系统中时序数据与访问行为特征的关联性,在用户访问行为到来前,在集群中预先分区为若干冷数据区(Cold Data Area);在接收到一定数量的用户访问请求后,根据用户访问行为将写入的数据进行冷热分类预测,将预测的热数据分散存放在不同节点的热数据分区中,缓解用户对热数据高频密集访问而导致的负载倾斜问题,并将主数据与多维索引规划存放在相同Region 中,以提高工业时序数据的多维索引查询效率。
2 本文方法
2.1 问题描述
在通用分布式集群中,负载均衡让多个存储或计算节点在中央处理器(Central Processing Unit,CPU)、网络流量、内存、磁盘输入输出(Input and Output,IO)等资源中分配负载,以达到优化存储与计算资源的使用、最大化数据吞吐率、最小化请求响应时间的同时避免单一节点过载的目的[19]。负载倾斜,即负载均衡的相反效果,由于单一节点的存储与计算资源过载,造成CPU 负荷过大、网络拥塞、磁盘IO 任务队列过长,导致集群资源无法最大化利用、集群工作效率显著下降,并影响业务层的运行。
负载倾斜产生的根本原因是在特定业务场景下数据访问模式的不平衡问题。海量工业时序数据业务场景具有数据采样周期密集、强关联以及访问需求高的特点,现存的负载均衡方法并没有考虑工业场景中数据与访问行为特征的关联,因此对海量工业时序数据的高并发密集访问会导致请求在集群中单一节点或少数节点上堆积,进而引发CPU、网络流量、内存、磁盘IO 等资源的不均衡使用,导致系统响应时间增长,访问失败率与机器宕机几率增高,并由于更多数据访问请求的堆积而进一步加重负载倾斜程度,引发恶性循环,最终影响业务流程的运行。
图1 描述了在工业时序数据存储场景下,HBase 集群中由数据的高并发访问引发的负载倾斜现象。多个用户并发访问海量时序数据,造成数据访问请求在集群中单一节点HRegionServer2 上堆积,此节点承受了超出资源支持限度的请求,而其他2 个节点的资源并没有充分利用,处于闲置状态,造成了负载倾斜问题。

图1 HBase集群负载倾斜Fig.1 HBase cluster load tilt
2.2 优化系统整体架构
对多种具体工业场景下系统时序数据访问日志进行分析,本文发现在不同的业务场景下,工业系统具有相对固定的时序数据访问模式,体现为对一些特定特征的数据访问较频繁。因此根据用户访问请求特征对要写入系统的数据进行冷热分类,将常被访问的热数据存放在热数据区,将不常被访问的冷数据存放在冷数据区。热数据分散存储在多个节点中,用户群后续对热数据进行高频访问时,数据访问请求能够较均匀地分散在不同存储节点上,达到负载均衡。
基于上述思想,本文的系统架构如图2 所示,由4 个优化模块和1 个历史访问行为数据库组成,优化模块包括:数据请求处理模块、预测分类模块、索引构建/RowKey 拼接模块、数据整理模块。
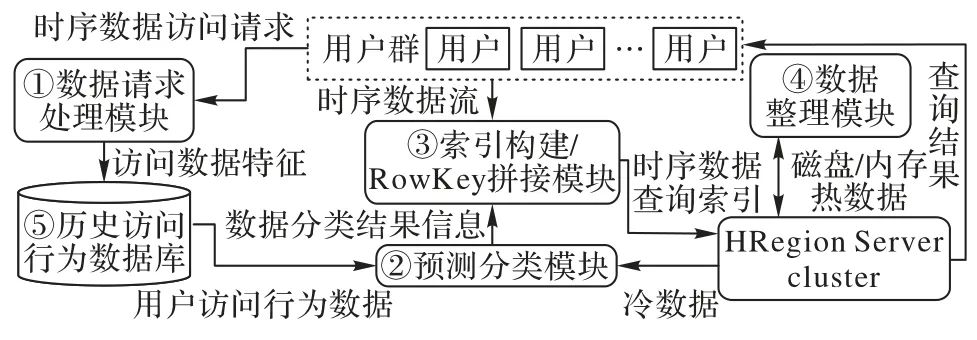
图2 引入优化策略后的系统架构Fig.2 System architecture after introducing optimization strategy
1)数据请求处理模块接收用户群的时序数据访问请求,提取用户所访问数据的特征,即用户访问行为。
2)预测分类模块根据数据特征对用户要访问的数据进行分类,如果判定为热数据,则将要写入的数据标记为热数据,如果判定为冷数据,则将要写入的数据标记为冷数据。
3)索引构建/RowKey 拼接模块为冷热数据构建对应分区的RowKey,并进一步根据主数据的特征,采用索引主数据同Region 化策略,以构建主数据的二级索引。
4)数据整理模块在集群负载较小时,扫描已经写入集群的数据,将因用户访问行为变动而改变冷热性质的数据重新筛选分类,让冷热数据分类与用户总体访问行为更加契合,并将热数据更新至内存中。
5)历史访问行为数据库存放用户访问数据的特征,对数据进行分类判定。
在该系统架构中,时序数据的存储与查询流程如下:
1)用户群向数据请求处理模块发送时序数据访问请求,若是存储数据,则向索引构建/RowKey 拼接模块传输欲存储的时序数据流。
2)数据请求处理模块接收读取、查询的请求,并提取要读取数据的特征,传入历史访问行为数据库中。
3)在负载均衡优化策略指导下,预测分类模块从历史访问行为数据库读取用户的访问行为数据,利用访问行为数据进行训练,并根据用户访问信息预测欲查询或写入的数据,输出数据分类结果信息至索引构建/RowKey 拼接模块。
4)索引构建/RowKey 拼接模块根据数据冷热分类结果信息,利用索引主数据同Region 化策略生成主数据的RowKey,发送给HRegionServer 集群,若是存储数据,集群将数据写入对应数据分区中;若是查询数据,则集群将接收到的RowKey 对应数据进行查询并返回结果至用户群。
5)在集群负载较小时,数据整理模块调用预测分类模块,将冷热数据区中的数据按照最新分类模型进行分类,筛选出新的冷热数据,并将这些数据标为对应的冷热数据类型,传给索引构建/RowKey 拼接模块,构建对应的RowKey,分散放置到集群各节点的冷热数据区中。
2.3 负载均衡优化策略
为了满足工业时序数据业务场景下的用户访问模式,在如图2 所示架构下,根据用户访问请求的数据特征对要写入系统的数据进行冷热分类,将后续用户对热数据的高频访问请求较均匀地分散在不同节点上,达到负载均衡。冷数据即用户访问频率较低且不足以引发负载倾斜的数据,存放在冷数据区;热数据即用户访问频率较高且容易引发负载倾斜的数据,存放在热数据区。热数据区与冷数据区均匀设置于多个HRegionServer 节点中,以保证用户对冷热数据的访问请求负载的均衡。
该策略首先根据具体业务场景制定行键RowKey 连接与命名规则,并根据RowKey 规则进行预分区,例如本文策略的默认数据分区RowKey 字段的连接规则为:0 号字节表示节点编号;1 号字节为索引标记位;(0000 0010)2、(0000 0011)2、(0000 0001)2 分别表示热索引、热主数据、冷主数据;其余字节为对应分区下具体数据的标识字段。在预测分类模型训练成功之前,所有数据存放在冷数据区中。
考虑到分类预测模型的模型规模、分类准确率、计算速度等因素,本文使用逻辑回归(Logistic Regression,LR)模型,输入用户读取数据的特征,并计算出该数据在每分钟内被访问的次数,对LR 模型进行训练,以根据用户访问行为对数据进行冷热分类。
以自动化码头上自动引导车(Automated Guided Vehicle,AGV)的可编程逻辑控制器(Programmable Logic Controller,PLC)数据存储为例,每辆AGV 上都有多个传感器在特定时刻产生设备状态数据。将数据特征输入训练好的LR 模型,对数据进行冷热分类,然后输出数据的冷热分类结果。在自动化码头业务场景,不同生产项目类别的业务自主性、装卸工艺业务流程、集装箱运输路线等特征,都具有特定的运行模式,导致设备状态时序数据的产生与读取模式具有相对固定的特点,因此工业时序数据与访问行为特征存在关联性。
冷热数据分类标准为:若数据每分钟被访问的次数超过20,归类为热数据;否则,归为冷数据。
引入基于冷热数据分区及访问行为分类的负载均衡优化策略后,Hbase 的写数据流程与负载分布如图3 所示。

图3 优化策略的写数据流程Fig.3 Writing process of optimization strategy
可以看到,相较于原Hbase 的写数据流程,该系统的写数据流程中,写数据请求负载根据预测分类结果均匀存放在相应数据分区中,很好地改善了数据写负载的倾斜问题。优化策略的写数据步骤如下:
1)用户群与本地元数据缓存Meta Cache 交互,读取meta表所在HRegionServer 节点信息,若Meta Cache 未命中,则连接Zookeeper,获取meta 表所在HRegionServer 信息。
2)用户群得到meta 表具体位置,定位它所在HRegionServer 节点,与此节点通信,获取meta 表,将新的meta 元数据对应信息通过最近最少使用(Least Recently Used,LRU)写入元数据缓存Meta Cache,根据meta 表访问要写入的数据表table 所在的HRegionServer,并建立连接。
3)用户群获得HRegionServer 节点许可后,以数据流的形式将要写入的时序数据特征传入预测分类模块。
4)预测分类模块根据传入的数据特征,根据所训练的分类模型对写入的时序数据进行冷热分类,并将分类结果输出至索引构建/RowKey 拼接模块。
5)索引构建/RowKey 拼接模块根据接收的数据冷热分类结果,将数据冷热性按上文所述字段规则耦合至对应数据的RowKey,并将耦合冷热性后的数据以数据流的形式写入不同节点中对应的冷热数据区。
6)在集群负载较小时,数据整理模块调用预测分类模块,将冷热数据区中的数据按照最新分类模型分类,筛选出新的冷热数据,并将这些数据标为对应的冷热数据类型,传给索引构建/RowKey 拼接模块,构建对应的RowKey,并分散放置到集群各节点的冷热数据区中,此步骤未在图中给出。
引入基于冷热数据分区及访问行为分类的负载均衡优化策略后,Hbase 的读数据流程与负载分布如图4 所示。在引入了数据请求处理模块后,用户读取数据的特征被提取并保存至历史访问行为数据库,用于训练预测分类模块,并对写入数据进行冷热分类。优化策略的读数据步骤如下。

图4 优化策略的读数据流程Fig.4 Reading process of optimization strategy
1)用户群与本地元数据缓存Meta Cache 交互,读取meta表所在HRegionServer 节点信息,若Meta Cache 未命中,则连接Zookeeper,获取meta 表所在HRegionServer 信息。
2)用户群得到meta 表具体位置,定位它所在HRegionServer 节点,与此节点通信,获取meta 表,将此新的meta 元数据对应信息通过LRU 写入元数据缓存Meta Cache,并根据meta 表访问要读取的数据表table 所在的HRegionServer,建立连接。
3)数据请求处理模块接收用户群的访问数据请求,并将访问请求通过用户群与节点之间的连接发送至对应数据所在的HregionServer。
4)数据请求处理模块提取用户群要读取数据的特征,以数据流的形式传入历史访问行为数据库中。
5)系统根据RowKey 同时访问读数据缓存Block Cache、数据内存副本MemStore 和已写入磁盘的文件StoreFile,将提取的数据进行合并比较,系统将同一索引下时间戳最大的数据返回给用户群。
2.4 索引主数据同Region化策略
在工业时序大数据场景下,若想要查询某个时间段中某设备在某地的状态数据,需要多次访问该数据所在表,因此需要二级甚至多级索引以优化查询性能。虽然HBase 提供二级索引构建功能,但HBase 默认二级索引RowKey 没有适应主数据分区的构建策略,导致在存储的数据规模逐渐增大的情况下,二级索引与主数据不在同一个Region 甚至不处于同一个HRegionServer 中,在高频查询过程中,导致HRegionServer 之间的跨节点通信、数据查询所需的系统开销增加,数据查询效率降低。
面向时序数据的索引主数据同Region 化策略通过用户历史访问行为统计汇总用户最常访问的数据列特征,并构建二级索引,将索引与对应主数据存放在同一Region 中。在发生Region 迁移时,索引与主数据同时迁移,无需对索引进行额外维护,避免了索引跨节点查询导致对应主数据及索引迁移维护带来的系统开销。在索引构建的主要流程中,同Region 化策略与原系统索引并无差别,不会产生额外的性能和内存开销。
二级索引与普通数据类似,通过RowKey 唯一确定。二级索引的数据值value 对应主数据的RowKey。二级索引与主数据的行键RowKey 由4 个字段组成,二级索引的RowKey字段设计如图5 所示。
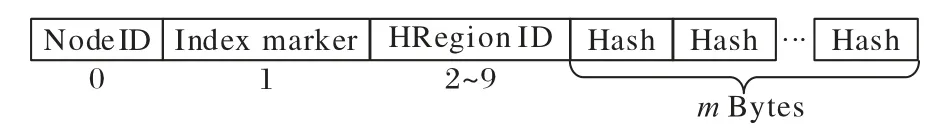
图5 二级索引的RowKey字段设计Fig.5 Secondary index RowKey field design
RowKey 首字节(0 号字节)为集群中服务器的节点编号,假设集群中服务器节点数为n,则RowKey 首字节范围取[0,n),表示该条数据所在服务器节点。1 号字节最低位用于区分索引与主数据,0 代表索引,1 代表主数据;次低位用于区分数据冷热类别,0 为冷数据,1 为热数据。2~9 号字节为RegionID,唯一标识一个节点中的Region。10~(9+m)号字节为根据主数据各列族特征进行哈希变换的字段,m为保证特定场景下数据存储规模与RowKey 唯一性所需最小字节数。
引入索引主数据同Region 化策略后,系统查询数据流程如图6 所示,索引构建/RowKey 拼接模块对具有多级索引查询需求的部分热数据构建对应的索引。优化策略的索引查询数据步骤如下:
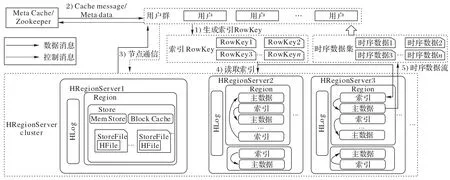
图6 优化策略的索引查询流程Fig.6 Index query process of optimization strategy
1)用户群将时序数据索引发送至索引构建/RowKey 拼接模块,模块按策略返回索引RowKey。
2)用户群与本地元数据缓存Meta Cache 交互,读取meta表所在HRegionServer 节点信息,若Meta Cache 未命中,则连接Zookeeper,获取meta 表所在HRegionServer 信息。
3)用户群得到meta 表具体位置,定位它所在HRegionServer 节点,与此节点通信,获取meta 表,将此新的meta 元数据对应信息通过LRU 的方式写入元数据缓存Meta Cache,并根据meta 表访问要读取的数据表table 所在的HRegionServer,建立连接。
4)用户群获得HRegionServer 许可后,系统按索引RowKey 进行主数据搜索。
5)系统将与索引对应的主数据返回给用户群。
3 实验与结果分析
3.1 实验环境
1)硬件环境。实验所用HBase 集群由1 个master 节点与3 个HRegionServer 节点组成。服务器节点型号均为Dell PowerEdge R720,采用Intel Cascade Lake 3.0 GHz 处理器,24 GB 内存,14 TB 硬盘。
2)软件环境。实验所用操作系统为CentOS 7.6 64 bit;Hadoop 版本为2.7.6;HBase 版本为1.4.13;JDK 版本为1.8。
3)测试数据。本文采用自动化码头中AGV 产生的设备状态数据,包含了设备在某一时刻的运行状态、电量、运行速度、运转功率等信息,属于典型的工业时序数据,具有时间序列化、时段密集化、数据产生高并发、数据总量巨大的特点。实验数据由130 辆AGV 在2020 年7 月至2021 年1 月不间断运转所产生,共2.4× 108条。为了论证存储性能优化策略在数据规模越大的条件下,优势越明显,实验将该数据集进行数据规模递增的划分,共分出9 个子数据集。表1 列出了实验所用时序(Time Series,TS)数据集的相关信息。

表1 TS数据集Tab.1 Time series datasets
3.2 评价指标
采用节 点负载分布[20]和数据 查询时间[21]评价优 化策略。
1)节点负载分布。在不同数据规模与访问密集程度下,对优化前后的系统各节点负载进行统计,各节点上请求数越均衡,集群资源有效利用率越高,对高频时序数据访问产生的负载倾斜问题改善越成功。
2)数据查询时间。系统在不同数据集下对相同查询请求处理完成所需时间,数据查询时间越短,数据查询效率越高,优化越有效。
3.3 比较方法
将本文方法与预分区方法和被动分区方法中具有代表性的方法进行实验对比,包括:PUB-HBase[12]和分级负载均衡器(Hierarchical load Balancer,HBalancer)[14]。PUB-HBase面向网络安全实验数据集,对HBase 的数据区进行冷热分类,对网络安全日志数据访问模式进行模型描述,并预测用户读数据请求,通过RowKey 字段设计实现索引与数据的一致性,进而缓解负载倾斜,并提升数据查询效率。HBalancer动态收集并考虑数据负载分布的变化,对数据进行动态存储,从而在一定程度上缓解负载倾斜问题。
3.4 节点负载分布
在不同规模的数据集下,本文采用不同节点处理的请求数的标准差代表节点负载分布的倾斜程度,标准差越大,不同节点处理请求数量差别越大,负载倾斜程度越高。在不同数据量下,使用PUB-HBase、HBalancer、本文方法后,系统在工业场景访问模式下各HRegionServer 集群的负载倾斜程度如表2 所示。在不同数据规模下,相较于原系统、PUBHBase、Hbalancer,引入本文策略后系统的集群负载倾斜度明显降低,极大地改善了原系统存在的负载倾斜问题,且负载均衡效果优于另外两种方法。引入本文方法后系统的负载倾斜度相较于原系统、PUB-HBase、HBalancer 分别平均降低了28.5%、16.1%、12.5%。

表2 不同方法在不同数据量下的负载倾斜度Tab.2 Load tilts of different methods under different data volumes
表3 列出了预测分类模块的预测精度与训练数据量、训练时间之间的关系。在训练数据量为0.54 GB 时,模型精度较低,仅有76.36%。随着训练数据量的增大,模型训练时间和模型预测精度都随之上升。当训练数据量达到4.50 GB时,模型精度较高,为85.42%,模型预测精度的增长变缓,预测精度满足数据冷热分区策略的模型精度需求,且训练时间为3 048.49 s,满足系统的即时性访问需求。
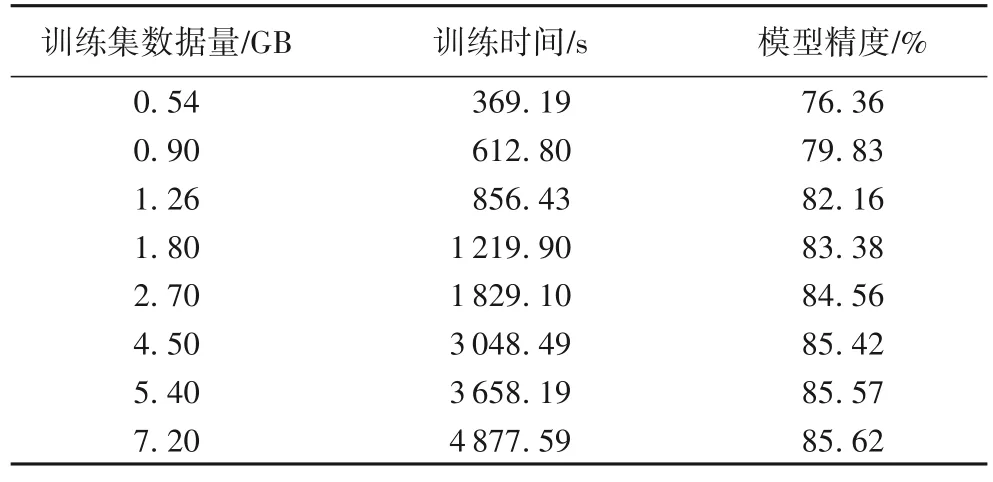
表3 在不同训练量下的训练时间和预测精度Tab.3 Train times and prediction accuracyies under different training volumes
3.5 数据查询时间
只引入本文同Region 化策略的系统与原系统、PUBHBase 通过索引搜索数据所用的时间如图7 所示。可以看出,单独引入本文同Region 化策略的系统通过索引查询数据所用时间短于原系统和PUB-Hbase。并且随着数据量增大,数据查询时间缩短效果更明显,说明同Region 化策略能够在索引查询数据过程中减少HRegionServer 之间额外的跨节点通信以及带来的系统开销,提升数据查询效率。

图7 数据查询时间对比Fig.7 Comparision of data query time
本文方法与原系统、PUB-HBase 在不同数据规模下对查询任务所需的综合查询时间如表4 所示。在引入数据冷热分区机制与索引主数据优化策略后,由于热数据区数据常驻内存,且索引与主数据处于相同Region 中,减少了系统跨节点通信带来的额外开销,提高了查询速度,查询时间变短。相同数据规模下,本文方法的数据查询时间小于原系统和PUB-HBase。相较于原系统与PUB-HBase,本文策略平均查询效率分别提升27.7%与13.8%。
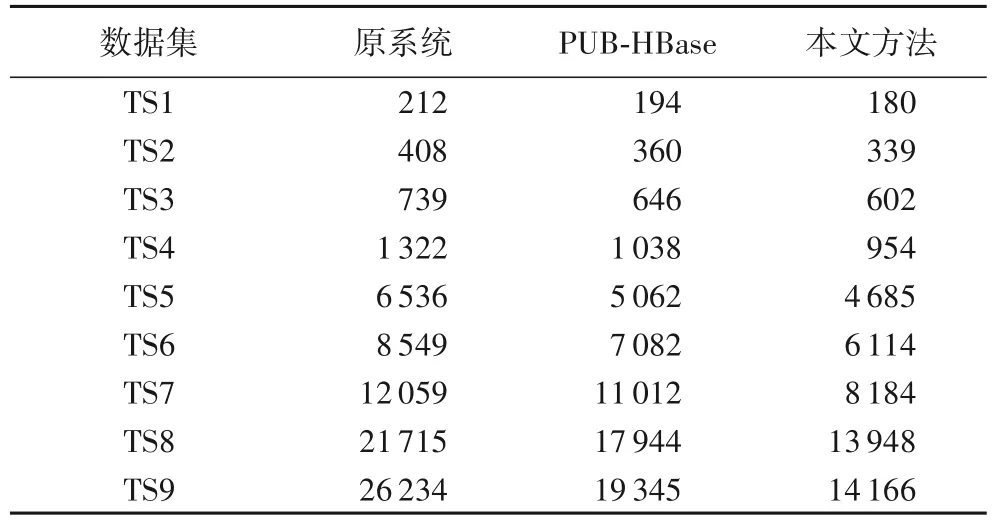
表4 综合数据查询时间对比 单位:ms Tab.4 Comparision of comprehensive data query time unit:ms
为进一步验证冷热数据分区对数据查询时间的优化作用,实验研究了热数据区命中率与数据查询时间的关系。在不同数据规模下,优化后的系统热数据区命中率与数据查询所需时间的关系如图8 所示。从图8 可以看出,热数据区命中率越高,查询所需时间越短,这是因为热数据常驻于内存中,而冷数据存储在磁盘中,当用户群的访问请求命中热数据区时,数据直接在内存中被访问,数据访问速度更快,访问时间更短。当数据规模达到TS7 至TS9 时,图像线条倾斜程度增大,这表明数据规模越大,热数据区命中率对数据查询时间缩短效果越明显。

图8 热数据区命中率与数据查询所需时间关系Fig.8 Relationship between hot data area hit rate and time required for data query
4 结语
本文基于HBase 提出了面向海量工业时序数据的分布式存储性能优化策略:基于冷热数据分区及访问行为分类的负载均衡优化策略;索引主数据同Region 化策略。基于冷热数据分区及访问行为分类的负载均衡优化策略,引入数据冷热分区的概念以及用户访问行为预测分类模型,根据用户访问请求特征对要写入系统的数据进行冷热分类并存放在相应数据区,将后续用户对热数据的高频访问请求均匀地分散在不同节点上,缓解了由工业时序数据特点引发的负载倾斜问题;索引主数据同Region 化策略,汇总用户最常访问的数据列特征,并设计索引RowKey 字段,提升了工业时序数据高维索引的查询效率。
通过与原Hbase 的实验对比表明,在工业时序数据存储场景下,本文的优化策略在两种指标上都取得了明显的提升。虽然本文策略被实验验证具有一定的有效性,但对数据访问模式的稳定性具有较高的要求,如果访问模式频繁改变,则难以有效划分冷热数据。在后续工作中,可以通过设置更灵活且更紧凑的分类模型训练时间来提升系统对访问模式改变的适应性,进而达到更好的性能。
猜你喜欢
环球时报(2022-03-29)2022-03-29
中国农业信息(2021年3期)2021-11-22
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
知识经济·中国直销(2018年7期)2018-07-27
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
电子制作(2017年13期)2017-12-15
初中生世界·七年级(2017年9期)2017-10-13
电子制作(2016年15期)2017-01-15
电测与仪表(2015年8期)2015-04-09
