
基于Sophon SC5+芯片构架的行人搜索算法与优化
2023-03-24 13:24孙杰吴绍鑫王学军华璟
计算机应用 2023年3期
孙杰,吴绍鑫,王学军,华璟*
(1.浙江工商大学 计算机与信息工程学院,杭州 310018;2.深圳市星火电子工程公司,广东 深圳 518001)
0 引言
行人重识别算法通过标注监控视频图像的行人来获取图像,但是预处理工作繁琐,不适用于现实场景;并且一个单独的行人重识别算法也不能满足实际应用需求,可以通过行人搜索的思想解决该问题。行人搜索分为行人检测与行人重识别两个模块。行人检测任务从图像集合或视频集合中找到所有出现的行人,并分别对他们的位置进行定位和标注;行人重识别任务通过计算机视觉技术判断目标行人是否存在于某段视频或图片中,主要解决跨摄像头跨场景下行人的识别与检索问题[1]。给定现实场景中的原始监控视频或图像,行人检测技术完成每帧图像的行人定位,生成候选行人图像数据库;再将目标行人图像和候选行人图像输入行人重识别模块进行特征提取与比对,完成相似度度量,最终获取目标行人在原始监控视频中存在的信息。
基于深度学习的检测算法能学习到更有效的行人特征表示和相似度度量,相较于传统算法,此类算法过程简便,鲁棒性和准确性较高。目前已经有越来越多的目标检测技术用于行人检测,Redmon等[2]提出的YOLOv3(You Only Look Once version 3)里程碑式地增加了多尺度检测,提高了网络对小物体的检测准确率。Wang等[3]提出了引入神经网络隐式知识学习的YOLOR(You Only Learn One Representation),该算法具备捕获不同任务的物理意义的能力。Ge等[4]提出YOLOX,将解耦头、数据增强、无锚点以及标签分类等目标检测领域的优秀进展与YOLO 进行巧妙的集成组合。
近年来,从有监督学习到半监督学习,以及面对复杂多变的场景,数据跨模态和端到端的行人重识别算法也开始成为研究关注的对象。Zeng等[5]提出分类聚层和难样本挖掘三元组损失(Hard-batch Triplet Loss)相结合的伪标签聚类算法,通过层次聚类,充分利用目标数据集中样本间的相似性产生高质量的伪标签,并提高了算法性能。He等[6]采用了Vison Transformer 作为骨干网络提取特征,将图像块打乱后重组形成不同的局部表示,每个部分都包含多个随机的图像块嵌入,并在网络中嵌入了非视觉信息以学习更多不变的特征。Zhang等[7]提出多分辨率表征联合学习(Multi-resolution Representations Joint Learning,MRJL)算法,充分利用高分辨率行人图像中的细节信息和低分辨率图像中的全局信息。
虽然当前的算法都具有较好的检测效果和重识别能力,但也需要更多的计算需求和耗时,难以在确保准确性和实时性的同时将算法部署在硬件资源有限且功率预算紧张的设备上。降低模型计算强度、参数大小和内存消耗,并高效地部署于AI 芯片,是将行人搜索算法应用于生产中的必备环节,设计一个符合应用需求的行人搜索系统值得深入研究。为解决上述问题,本文围绕提高行人检测速度和行人重识别精度两个方面展开理论研究和实验证明,并基于Sophon SC5+人工智能芯片,对改进后的算法进行量化,将高性能行人搜索系统部署于实际场景中。本文主要工作如下。
1)在行人检测算法上,使用GhostNet[8]优化YOLOv5 的主干网络结构,替换原有的部分CBS 和C3 模块,大幅度减少了模型的参数量;同时在主干网络和颈部网络中加入CBAM(Convolutional Block Attention Module)[9]增强网络对行人重要信息的提取能力,在保证检测精度的同时提升检测速度。
2)在行人重识别算法上,使用一个负样本对和两个正样本对缓解难样本挖掘三元组损失[10]优化模糊的问题,并加入中心损失约束,进一步压缩类内特征;再使用附加间隔交叉熵损失[11]进行组合,有效地使用融合损失优化网络,以提高网络的特征提取能力,加快网络训练。
3)将改进后的行人检测和行人重识别算法在AI 芯片Sophon SC5+上进行量化和部署实验,实现行人搜索系统。
1 行人检测算法
1.1 基于Ghost模块的重构模型网络结构
YOLOv5 中使用了较多的CBS 和C3 模块提取输入图像的特征,它们的结构如图1 所示。其中,C3 模块使用了多个残差组件会导致特征冗余的问题产生。
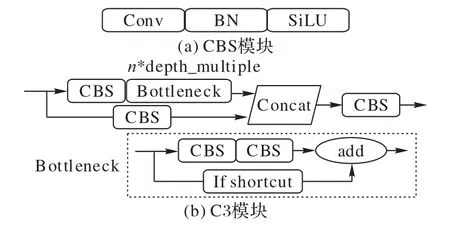
图1 YOLOv5中的CBS和C3模块结构Fig.1 CBS and C3 module structure in YOLOv5
为了减少模型的计算量和参数量,使网络更轻量化,使用Ghost 模块替换YOLOv5 主干网络中的部分CBS 和C3 模块。目前大部分卷积操作都使用1×1 的逐点卷积方式降低维度,再通过深度卷积提取特征,而Ghost 模块采用线性变换的方式生成特征图,可以更有效地减少网络的计算量,传统卷积与Ghost 模块的结构示意如图2 所示。
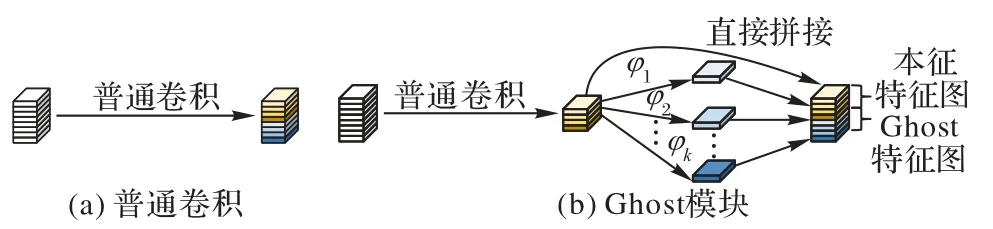
图2 传统卷积生成特征图和Ghost模块生成特征图Fig.2 Traditional convolution to generate feature maps and Ghost module to generate feature maps
普通卷积层生成n个特征图,可以表示为如下形式:
其中:卷积输入X∈Rc×h×w,c、h、w分别为输入特征图的通道、高度与宽度;f∈Rc×k×k×n代表n个大小为k×k×c的卷积核;b是偏置项。输出特征图Y∈Rn×k′×w′,n为输出特征图的通道数。整个卷积过程运算所需要的浮点运算量为n×h′×w′×c×k×k。在YOLOv5s 中,n和c通常为512 或1 024,导致计算量非常大。
Ghost 模块的计算如式(2)所示:
其中:卷积输入Y′∈Rm×h′×w′;m是经过普通卷积后得到的特征图个数,由于m≤n,所以省略了偏置项;Yi′是Y′的第i个特征图;φij是第i个特征图生成第j个Ghost 特征映射的线性操作。此处普通卷积的浮点运算量为m×h′×w′×c×k×k。为保证空间尺度相同,通过式(2)生成n-m个特征图。假设每个线性运算核为d×d,可以用理论加速比衡量Ghost的提升程度,如式(3)所示:
其中:d×d与k×k的大小相同,且s≪c。最终Ghost 模块的计算量是普通卷积的,且参数计算量也相似,可以从理论上证明Ghost 模块的优越性。因此将YOLOv5 的主干网络中的C3 和CBS 模块替换为步长分别为1、2 的GhostBottleneck。
1.2 添加CBAM
CBAM 是高效的注意力机制,可无缝嵌入各种CNN,经过CBAM 之后生成的特征图,可以提高特征在通道和空间上的联系,有利于提取目标的有效特征。CBAM 主要由通道注意力模块(Channel Attention Module,CAM)与空间注意力模块(Spartial Attention Module,SAM)组成,在这两个维度上对特征进行调整,以加强网络的特征提取能力。如图3 所示。

图3 CBAM结构Fig.3 Stucture of CBAM
输入的特征图首先经过CAM,如图3(a)所示,基于特征图的宽高分别进行最大池化(MaxPool)和平均池化(AvgPool);两个池化操作共享一个多层感知机(MultiLayer Perceptron,MLP),经过MLP 后分别输出两个特征向量进行相加;最后经过Sigmoid 激活函数δ得到通道权重,将权重与输入特征图相乘得到新的加权特征图,完成通道注意力对原始特征的重新标定。计算如式(4)所示:
其中:W0和W1是MLP 中的两层全连接层的权重参数。
通过SAM 对输入的特征图每个位置的所有通道进行最大池化和平均池化,得到两个h×w×1 的特征图并按照通道拼接。再使用7×7 的卷积核和Sigmoid 激活函数生成空间权重,然后与通道特征图相乘,得到经过CBAM 后的最终特征,从通道和空间两个维度上完成对特征图的重标定:
因此基于上述思想,结合了Ghost 模块的YOLOv5 虽然降低了模型的参数和计算量,但也会导致检测精度降低。通过添加CBAM 可以在少量增加模型计算量和参数的基础上,提高检测效果,缓解精度下降问题。
本文在YOLOv5 中使用步长为2 的GhostBottleneck 替换原始主干网络中的4 个C3 模块,使用步长(Stride)为1 的GhostBottleneck 替换主干网络中的部分CBS 模块,并在主干网络的末端和颈部网络的3 个尺度特征模块后面嵌入CBAM,总计5 个注意力机制模块,并保留YOLOv5 中的其他结构,最终得到轻量级YOLOv5-GC 行人检测模型如图4 所示。新的网络结构通过替换原来Bottleneck 中较多的3×3 标准卷积,降低了网络的计算量,并提高了模型检测速度;再通过添加CBAM 提高对行人检测任务的准确率。
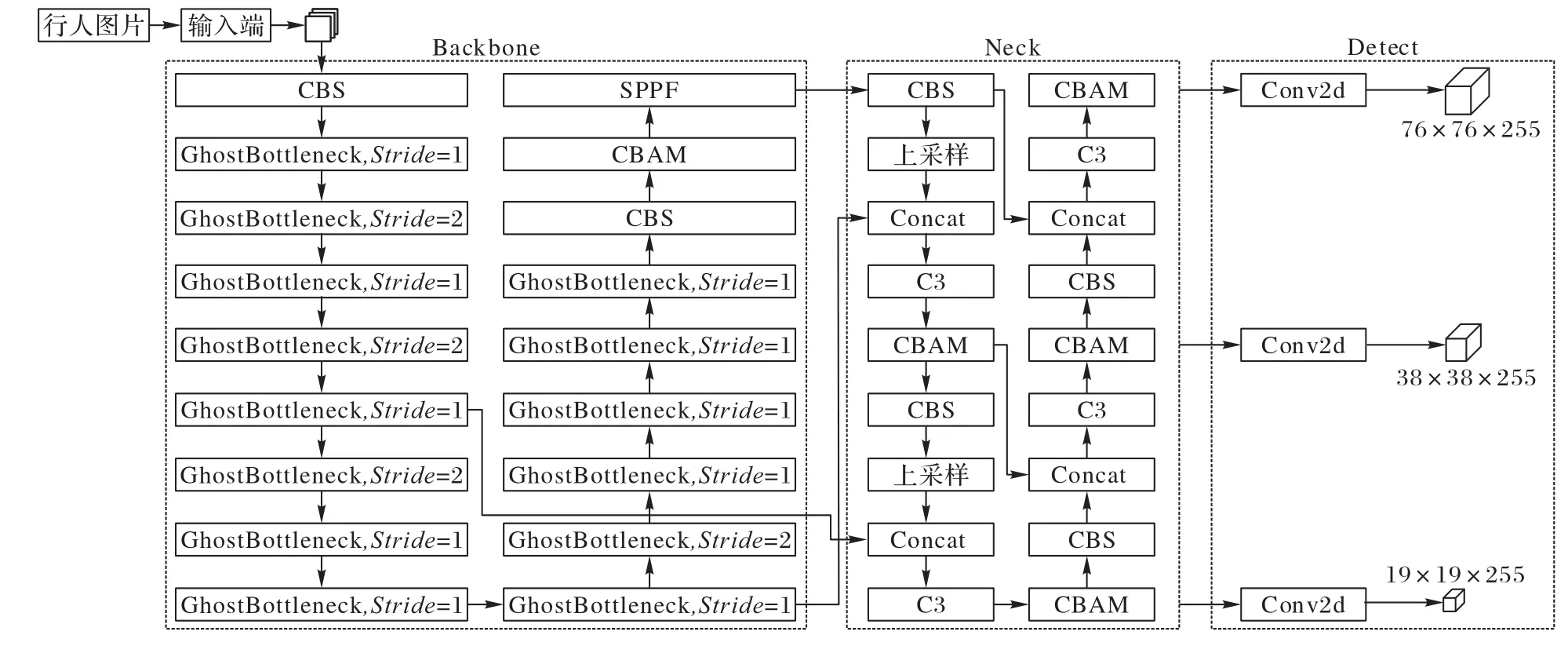
图4 YOLOv5-GC网络结构Fig.4 YOLOv5-GC network structure
2 行人重识别算法
2.1 改进的中心三元组损失约束
三元组损失[12]函数是行人重识别中常用的损失函数之一,其中的三元组由目标、正样本、负样本图片组成。损失函数的目的是网络训练学习后使正样本和目标图片的特征表达距离更近,负样本和目标图片的特征表达距离更远。
难样本挖掘三元组损失[13]是三元组损失的改进版本,传统的三元组损失是从训练数据中随机抽取三张图片,虽然该方法比较简单,但抽取的图片大部分都是容易区分的样本对,不利于网络学习到更好的表征,因此最相似的负样本和最不相似的正样本是所需要的难样本。对于每个输入图像,选取与它距离最远的正样本和距离最接近的负样本构成三元组,并计算三元组距离,如式(6)所示:
其中:一个批次中的图片数量N=M×K,M是从每个批量训练组中挑选出的查询行人数,每个行人对应有K张图片;分别代表目标图片、正样本、负样本的特征向量;α是正负样本之间的阈值,控制不同行人ID 图像之间的特征向量接近程度。
难样本三元组损失在优化时可能会存在优化目标模糊的情况,如图5 所示。图5(a)是样本在特征空间中的一种表示情况,Hard Negative 是距离最近的负样本,Hard Positive 是距离最远的正样本,Nearest Positive 是距离最近的正样本。经过难样本三元组损失后,可能会出现图5(b)所示的结果,属于同一个行人的anchor 和最近正样本之间的距离大于同一行人的Anchor 和最近负样本之间的距离。

图5 图片在特征空间上的距离Fig.5 Distance of image in feature space
因此为了较好地缓解优化目标模糊的问题,在原有难样本挖掘三元组损失的基础上,使用一个负样本对和两个正样本对进行改进,使图片在特征空间上,anchor 最近正样本和最远正样本的距离都小于最近负样本的距离。此外,考虑到会有少量样本特征没有归属到本类中心,和其他类别特征重叠,这样对行人重识别任务十分不利。因此在上述改进的基础上,增加中心损失[13]约束项,驱使相同类别向各自类内中心聚集,使特征分布更加紧凑,以提高类内相似度。改进后的中心约束三元组损失计算如式(7)所示:
其中:α和β控制样本对之间的相对距离;Cyi是第i个样本所属类别的中心特征;γ是平衡改进难样本挖掘损失和中心损失的权重。
2.2 融合损失函数设计
网络模型在同时训练分类模型和验证模型时,可以采用不同的损失函数。不同的损失函数虽然针对不同任务,但最终对样本特征分布的约束相似,因此起到互补的作用。有效利用这种互补性可以对网络产生较强约束,帮助网络学习到鲁棒性更强的行人特征,从而改善网络的性能。
因此本文尝试将附加间隔交叉熵损失[11]和改进后的中心约束三元组损失共同组合对模型进行监督优化。附加间隔交叉熵损失中引入了角间距,对类间距离的优化效果明显,但由于类内约束不足,同类行人的特征分布仍比较分散。而中心约束三元组损失对有较强的类内约束能力,聚集相同类别的样本,但由于每次仅可以利用一个batch 中的信息,神经网络会随着训练、迭代,遗忘掉之前的信息,存在收敛困难的情况。融合附加间隔交叉熵损失后不仅可以加快收敛,在训练时会同时考虑难样本对和简单样本对,完全利用训练集中所有行人图片的标注信息。综上所述,融合损失函数可以让两种损失之间优势互补,提高网络的特征提取能力,加快网络训练。融合损失函数如式(8)所示:
其中:cos(θyi)是计算样本在类别yi中的区域;cos(θyi)-m表示要求不同类的行人区域之间至少有m的间隔。s(c os(θyi)-m)将cos(θyi)增大s-1 倍,由于cos (θyi)的取值范围为[0,1],数值较小,无法有效区分不同类的差异,增大s倍之后,再通过Softmax 可以提高分布差异性,产生明显的马太效应,使收敛速度提升。
2.3 网络结构
图6 给出了本文行人重识别算法ReID(Person Re-IDentification)的网络结构,将ResNet50 作为ReID 网络中的基础提取网络,引入BNNeck(Batch Normalization Neck)[14]网络结构的思想,经过批标准化(Batch Normalization,BN)层得到归一化后的特征,在各个维度上获得平衡,近似于在超球面附近分布,使分类损失更易收敛,从而缓解融合损失优化目标特征所在的空间差异导致损失优化方向不同的问题。并在ResNet50 中引入Non-local[15]注意力机制,通过加权得到非局部的响应值,构造了和特征图尺寸一样大小的卷积核,进而保留更多的行人特征。
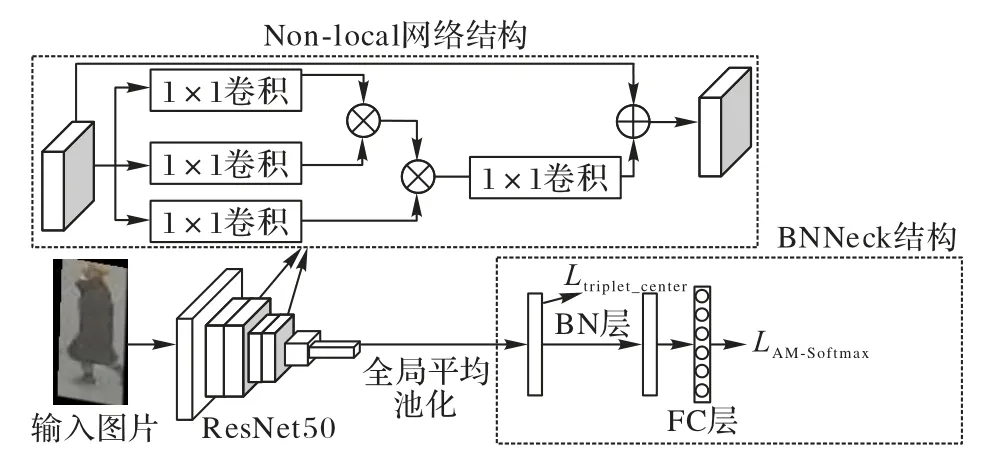
图6 ReID网络结构Fig.6 Structure of ReID network
3 基于Sophon SC5+的模型部署
本文的行人检测与行人重识别算法基于Pytorch 深度学习框架实现,为了将模型移植到SC5+上,需要把基于开源框架的模型转换为BITMAIN TPU 平台特有的bmodel 格式。bmodel 是面向比特大陆张量处理器((Tensor Processing Unit,TPU)的深度神经网络模型文件格式,包括目标网络的权重、TPU 指令流、输入输出等信息。因此首先需要将本文算法在图形处理器(Graphics Processing Unit,GPU)的环境中训练后,得到文件后缀为.pt 的模型,完成模型转换后,以fp32 模型和int8 模型两种格式部署到SC5+中。
现有的行人检测和行人重识别算法,在训练时往往都会使用fp32 的数据精度表示权值、偏置、激活值。如果使用深层次的网络,参数和计算量就会大幅度增加,用于实际的视频监控系统会面临性能较差的问题。因此采用模型量化的方法,在保证一定精度的情况下,对模型的大小进行压缩,以减少内存占用,加速前向推理。本文通过比特大陆自主开发的网络模型量化工具Quantization-Tools 对fp32 模型进行量化。在Sophon SC5+运算平台上,网络各层输入、输出、系数都用8 bit 表示,在保证网络精度的基础上,大幅减少功耗、内存、传输延迟,提高运算速度。模型的量化步骤如图7 所示。
图7 中的int8_umodel 是通过量化生成的int8 格式的网络系数文件,是作为临时中间存在的文件形式。需要将该文件进一步转换成可以在SC5+中执行的int8_bmodel 文件。经过int8 量化后的算法与原本在GPU 下的算法精度存在一定误差。因此还需要对网络的精度进行预检测,比特大陆平台提供了可视化分析工具calibration 来初步查看网络的误差,该工具使用平均绝对百分比误差(Mean Absolute Percentage Error,MAPE)、余弦相似度(COsine Similarity,COS)和欧氏距离(DIST)作为误差评价的标准,具体如式(9)~(11)所示:
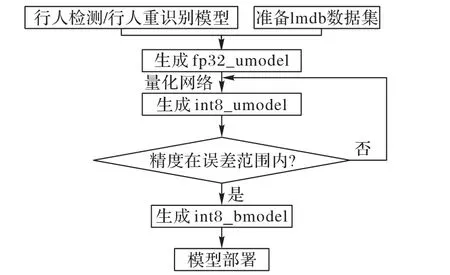
图7 模型量化为int8_bmodelFig.7 Quantizing model as int8_bmodel
其中:At代表实际值;Ft代表预测值;xi、yi分别表示特征向量。本文以YOLOv5-GC 算法为例,通过calibration 可视化分析工具生成如图8 所示的量化误差分析图。
参考COS 曲线,在图8(a)中,在模型最后输出阶段,曲线下滑得较为明显,说明经过直接量化的int8 模型误差较大。而图8(b)中的混合量化执行在部分层使用定点计算,部分层使用浮点计算,有效提高了网络的整体量化精度,因此COS 曲线较为平稳,近似于1,是本文所需要的量化模型。两个量化后的int8 模型误差较大,因为基于Pytroch 框架的网络转换之后的模型可能包含前处理和后处理相关的算子,对这些算子进行量化在很大程度上会影响网络的量化精度,Sophon SC5+内部集成了浮点计算单元,因此可以高效地利用浮点计算,根据这个特点,在转换int8_umodel 文件的命令行中,提供了标记前处理、后处理相关的层,并允许这些层以浮点形式计算,有效提高网络的整体量化精度,使转换后的模型精度与原有算法不会产生较大误差。

图8 量化误差分析图Fig.8 Quantitative error analysis diagram
4 实验与结果分析
4.1 实验设置
为验证本文行人重识别和行人检测算法的有效性,采用COCO[16]、Market-1501[17]、DukeMTMC-ReID[18]数据集进行实验。COCO 数据集进行了预处理,只提取行人图片,训练集包含行人图片64 115 张,行人数量为257 252;测试集包含图片数量2 693 张,行人数量11 004。Market-1501 数据集共收集了1 501 个行人的32 688 张身份标注的行人图片。DukeMTMC-ReID 包含来自不同视角的行人1 812 个。实验运行环境为Ubuntu18.04 和Pytorch1.8,硬件平台使用的GPU 为2080Ti,AI 芯片为Sophon SC5+,内存为64 GB。
行人检测部分设置图片的输入分辨率为640×640,Batchsize 为64,共训练300 个epoch。行人重识别部分设置图片的输入分辨率为256×128,Batchsize 为64,共训练120 个epoch。
4.2 实验评价指标
为了保证对比实验的客观性,采用平均精度均值(mean Average Precision,mAP)、帧率、Rank-k指标进行评价。mAP 用于评价检测模型的平均准确率均值:
其中:M为图像总数;P为精度;IAP表示平均检测精度(Average Precision,AP),mAP 是所有类别的平均精度。由于本文行人检测中只有行人这一类目标,所以AP 值与mAP 值相等。一般来说行人检测模型的性能越好,mAP 值越大,模型精度越高。
Rank-k表示在算法测试阶段,对于查询目标行人query,在候选集(gallery)中对图片提取特征后根据相似度高低进行排序,若最靠前的k张图片中包含query 行人,则正确匹配的概率。k一般取值为1、5 或者10。以Rank-1 为例,表示在提取的query 特征和gallery 特征计算特征距离后,正确的目标行人排在首位的准确率,如式(13)所示:
其中:n是待查询行人图像的总数;i是第i个查询对象,Si表示若第i个查询行人对应的首位排序是同一个行人的话,则识别成功Si=1;否则Si=0。
4.3 行人检测实验
4.3.1 消融实验
为了验证本文行人检测算法(YOLOv5-GC)的有效性,对不同模块在YOLOv5s 上的作用进行对比实验。为了验证改进效果对不同深度的YOLOv5 的影响,加入了原始YOlOv5l和YOLOv5l-Ghost 进行对比实验,结果如表1 所示。可以看出,将YOLOv5s 的网络主干替换为Ghost 模块时,使原先复杂的卷积操作更轻量化,YOLOv5s 的模型大小降低了3.9 MB,但由于包含重要信息的网络参数减少,也会使平均精度会下降。YOLOv5s 在添加CBAM 后,尽管模型参数量会增大,但检测速度变化较小,并且精度也有所提升,达到了82.9%。而同时添加两个模块的YOLOv5s-GC 网络,相较于初始的YOLOv5s,模型大小减少了3.7 MB,在GPU 上的推理时间也从5.3 ms 降低到了4.9 ms,并且相较于YOLOv5s-Ghost,mAP 也提升了1.1 个百分点。此外,YOLOv5l 在加入Ghost 模块后,模型大小相较于原始YOLOv5l 降低了47%。对加入CBAM 注意力机制的行人检测模型进行可视化分析,如图9 所示。

图9 检测结果示意图Fig.9 Schematic diagram of detection results
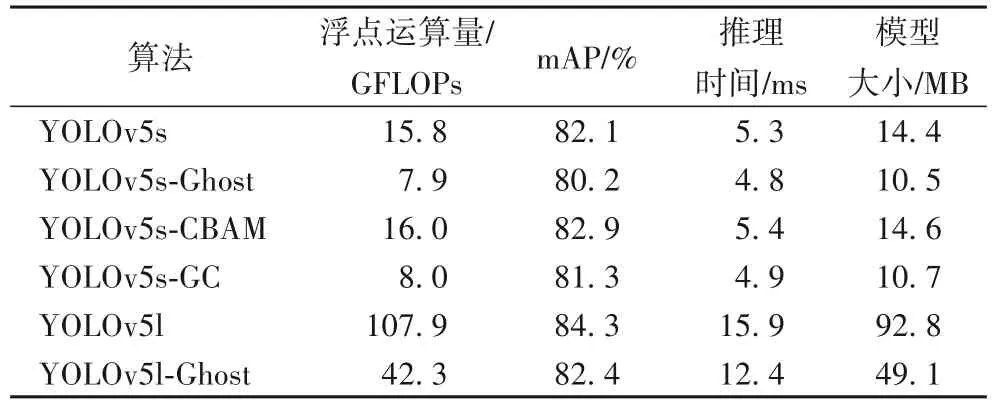
表1 各模块对行人检测算法的影响Tab.1 Influence of each module on person detection algorithm
可以看到YOLOv5s-ghost 在添加注意力模块之后,对图片中行人被干扰背景遮挡导致的漏检问题,有一定的改善。本文结合Ghost 模块和CBAM 模块构造的YOLOv5s-GC,在大幅度减少计算量、参数量和模型大小的情况下也保持了较高的mAP,并且随着网络的深度增加,轻量化效果也更明显。
4.3.2 与YOLO其他算法的对比实验
将YOLOv5s-GC 与其他主流检测算法进行比较,以进一步验证算法的可行性,结果如表2 所示。

表2 YOLOv5s-GC与其他YOLO算法对比实验结果Tab.2 Comparison of experimental results between YOLOv5s-GC and other YOLO algorithms
可以看出,在主流的行人检测算法中,虽然YOLOv4-tiny的帧率最高,但它的mAP 精度较低。本文的YOLOv5s-GC 的mAP 比YOLOv4-tiny 高出35.7 个百分点,并且模型大小减小了54.7%。YOLOv5s-GC 的mAP 相较于其他YOLO 算法最多提高了43.8 个百分点。实验结果表明,本文改进的行人检测算法可以应用到行人搜索任务的现实场景中,并且比原有的YOLOv5 更轻量化。
4.4 行人重识别实验
4.4.1 消融实验
表3 列出了在Market-1501 和DukeMTMC-reID 数据集上使用行人重识别算法(ReID)的消融实验结果,Baseline 为BagTricks[14]。可以看出,将Baseline 中的Softmax 替换为附加间隔交叉熵损失(LAMS),LAMS进一步增大类间距离,缩小类内距 离,在Market-1501 上Baseline+LAMS的mAP 和Rank-1分别提 高0.4 和0.1 个百分 点。在Market-1501 上,Baseline+L的mAP 和Rank-1 分别提高了0.6 和0.2 个百分点,说明联合两个损失函数训练有效。此外本文在Baseline 上加入Non-local注意力机制,可以看出在Market-1501 数据集上,mAP 和Rank-1 分别提升了1.1 和0.4 个百分点,说明Non-local 进一步提升了主干网络提取行人特征的能力。将所有方法整合后,在Market-1501 数据集上,ReID 的mAP 和Rank-1 相较于Baseline 分别提高了1.5 和0.6 个百分点,另外在DukeMTMC-ReID 数据集上,ReID 仍然有较好的效果。
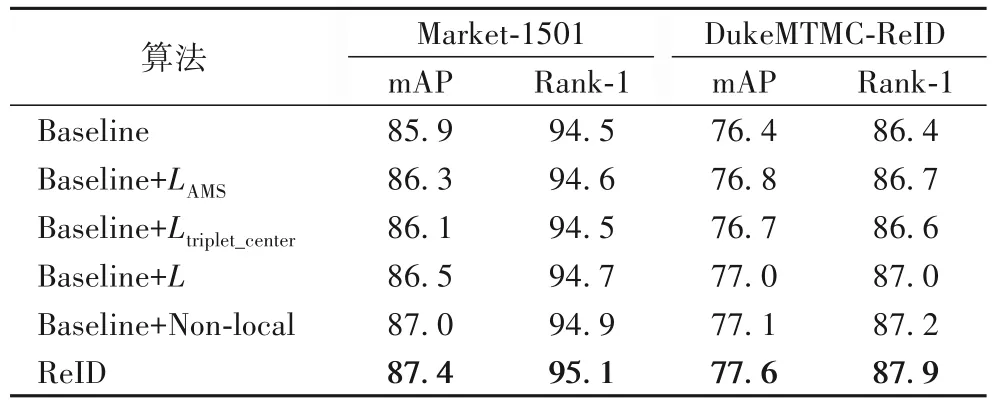
表3 消融实验结果 单位:%Tab.3 Results of ablation experiment unit:%
4.4.2 与其他算法的对比实验
表4 列出了ReID 和近几年主流的行人重识别算法在Market-1501 和DukeMTMC-ReID 数据集下的对比实验结果。对比算法包括:ACRN(Attribute-Complementary Re-ID Net)[22]、SVDNe(tSingular Vector Decomposition Net)[23]、MMT-500(Mutual Mean-Teaching)[24]、GPR(Generalizing Person Re-identification)[25]、ConsAtt[26]、PCB-RPP(Part-based Convolutional Baseline with Refined Part Pooling)[27]、PPS(Part Power Set)[28]与BagTricks。
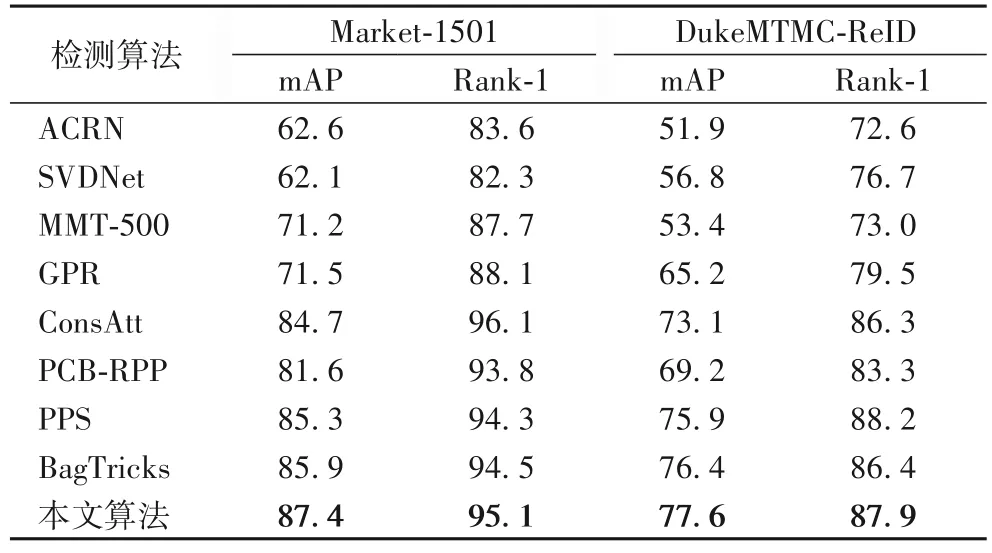
表4 不同行人重识别算法的对比实验结果 单位:%Tab.4 Comparison of experimental results of different person re-identification algorithms unit:%
与MMT-500 和GPR 这类无监督的行人重识别算法相比,基于监督学习的算法效果上会更好。在Market-1501 数据集上,虽然ReID 的Rank-1 相较于ConsAtt 算法降低了1 个百分点,但ReID 的mAP 提高了2.7 个百分点,说明ReID 对mAP 的影响更大。SVDNet 算法对全连接层进行奇异值分解,提高了检索性能,但需要人工操作的地方较多。PCBRPP 算法结合了分块特征,而ReID 在仅提取全局特征的情况下,在Market-1501 数据集上的mAP 与Rank-1 提高了5.8和1.3 个百分点。综上所述,在本文提出的融合损失函数的约束下,ReID 可以较好地压缩类内特征,在两个数据集上都表现出较好的性能,mAP 最多提高了25.7 个百分点。
4.4.3 超参数设置
本文提出的中心约束三元组损失有3 个超参数,分别是α、β与γ。文献[14-29]已经充分讨论了平衡权重,因此设置γ=5× 10-4。本文选取不同的α和β在两个数据集上进行实验,结果如表5 所示。从表5 中可以看出α和β的值对实验结果存在一定影响,设置α=0.3,β=0.7,对本文算法会有较好的效果。

表5 不同参数的性能对比 单位:%Tab.5 Performance comparison of different parameters unit:%
4.5 Sophon SC5+实验
在将模型量化后,还需要将量化后的模型加载到TPU 上执行。由于行人搜索算法涉及到两个不同模型的推理,预处理到后处理之间的步骤需要反复多次执行。在实际的应用开发中,只针对神经网络的运算进行加速,无法满足真实安防场景下的需求。因此比特平台提供了若干硬件加速模块以及相应的软件接口库,分别针对以上步骤进行加速,提高算法运行效率。不同算法量化后的模型结果比较如表6 所示,实验中设置推理的批处理大小为1,Sophon SC5+只使用一个BM1684 芯片,推理时间为平均推理时间。
由表6 中的数据可知,将NVIDIA 2080Ti 显卡下训练出的模型转换到fp32_bmodel,能有效地保证算法的精度不变。虽然转换成fp32 之后,部分模型的大小会有少量增加,但模型在Sophon SC5+下的推理时间更短。YOLOv5s-GC 在转换bmodel 中,需要将YOLOv5 算法export 成torchscript,才 能进行量化部署,所以相较于GPU 下训练的模型,初始的模型更大。YOLOv5s-GC 的fp32 模型的平均推理时间相较于在2080Ti 下训练的模型,缩短了0.8 ms;基于融合损失的ReID模型的平均推理时间比在2080Ti 下训练的模型少1.3 ms。
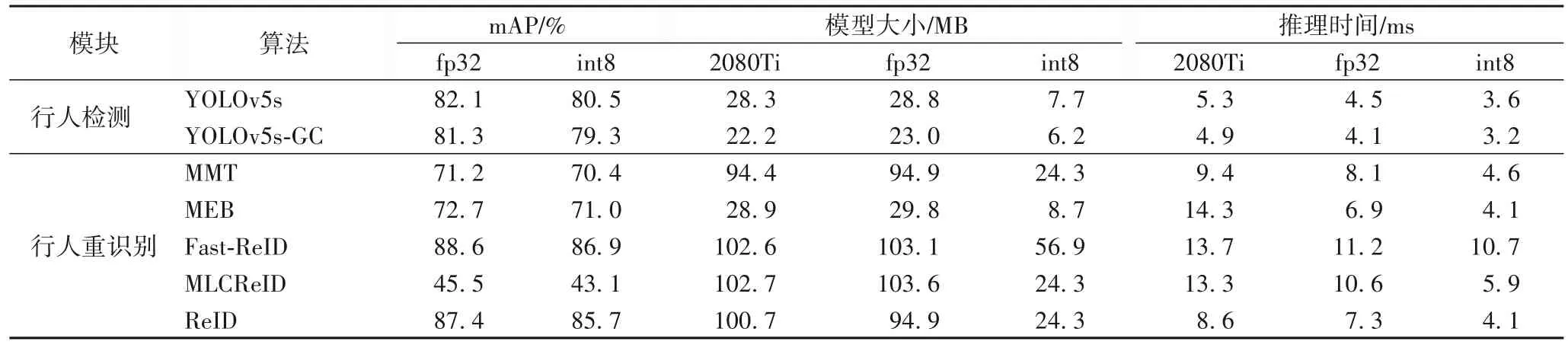
表6 不同算法量化后的结果比较Tab.6 Comparison of results after quantization by different algorithms
将模型进一步量化为int8_bmodel 后,只使用int8 量化的模型,如MMT 算法,相较于原始模型,模型大小减小了74.3%。此外,为了保证精度的误差范围,对于一些较为复杂的网络,需要采用混合执行的方式进行量化,如Fast-ReID算法,混合量化后Fast-ReID 的模型大小缩小了44.5%左右。且各个算法转换成int8_bmodel 之后的平均推理时间,也比在GPU 和fp32 下的平均推理时间更短,模型也更轻量化。
本文的融合损失的ReID 模型在int8 下的推理时间相较于2080Ti 训练的模型少4.5 ms。虽然相较于fp32 下的模型,mAP 下降了1.7 个百分点,但是模型容量减小了74.4%。且一张SC5+卡包含3 个BM1684 芯片,为算法现场场景应用提供了高计算、低成本的方案,由此可以证明AI 芯片Sophon SC5+对算法的现实应用有很高的价值。最后,本文将上述的改进方法,在Sophon SC5+上进行部署,完成行人搜索系统的实现,可视化的结果如图10 所示。图10(a)表示从监控摄像机中以目标对象的单张截图为查询条件,查找区域内所有视频中目标对象;图10(b)表示针对搜索的目标结果,点击任一结果图片,播放对应时间的监控视频。

图10 行人搜索结果示意图Fig.10 Schematic diagram of person search results
5 结语
本文首先分析了在智能视频监控下行人搜索算法存在的问题,并基于这些问题提出了使用Ghost 模块和CBAM,使算法模型的精度保持在一定范围内,而模型计算量大幅下降,速度更快。针对行人重识别中难样本挖掘三元组损失存在的目标模糊和聚类不足的问题,引入中心损失函数,并融合附加间隔交叉熵损失,使行人重识别算法在训练时,能较好地压缩类内特征。将改进模型部署在Sophon SC5+人工智能芯片上,验证量化后的模型的速度和大小都有较大优势。从算法到硬件,自上而下地优化深度学习的效率,符合行人搜索系统低成本高性能的需求。在下一步的研究中,可以从处理行人服装更换和室内外场景变化下的行人重识别入手,通过姿态估计或骨架关键点检测辅助提取行人可见信息,提高匹配的准确率;还可以建立基于端到端联合建模优化的行人搜索模型,并部署到Sophon 芯片上,以减轻两阶段模型对边界框生成这一额外步骤的依赖。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
山西大学学报(自然科学版)(2021年1期)2021-04-21
意林(2021年5期)2021-04-18
五邑大学学报(自然科学版)(2019年3期)2019-09-06
扬子江(2019年1期)2019-03-08
今日农业(2019年15期)2019-01-03
小天使·一年级语数英综合(2017年6期)2017-06-07
计算机工程与设计(2015年1期)2015-12-20
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
读者·校园版(2015年19期)2015-05-14
