
基于YOLOv5s 算法的汽车零件防错装检测系统
2023-03-23 07:44李武波
机电工程技术 2023年2期
李武波,黄 利,刘 兴,郭 峰
(一汽-大众汽车有限公司佛山分公司,广东佛山 528000)
0 引言
随着汽车行业发展及大众对汽车产品认识的提升,汽车的配置越来越丰富。为了避免在汽车生产时发生零件错漏装,以往总装车间采用加强出厂前人员检测来解决这一难题。从实际运行效果来看,人工的检测可靠性低,尤其是对于涉及多车型多配置零件,人工存在识别疲劳造成检测错误,导致的汽车配置错误,进而产生一系列售后问题,甚至导致经济损失。例如,一汽-大众佛山工厂总装车间总共有16 种汽车轮毂零件,为确定4个轮毂是否异常,终检人员需绕车一圈检测。不仅存在人员识别错误风险,而且需要花费大量检查的时间。采用计算机视觉开展目标检测势在必行。
本文使用的技术是计算机视觉中的目标检测(object detection)[1]方向,是计算机视觉识别的重要研究方向,在工业检测/机器人/智能视频监控等方面的应用特别广泛,具有重要的现实意义[2]。2016-2018 年期间,国内外的专家学者相继提出基于深度学习的单阶段目标检测的算法YOLO[3-4]系列和SDD[5]系列。2021 年,Ultralytics LLC公司提出了YOLOv5 算法,YOLOv5 是现今较先进的目标检测算法,在计算速度上表现非常出色。YOLOv5根据网络模型宽度和深度的差别,从小到大依次递增分别共有4 种版本,它们是YOLOv5s、YOLOv5m、YOLOv5l 以及YOLOv5x[6]。其中,YOLOv5s 是其中的网络深度和特征图宽度最小的,识别运行速率也最快。
在汽车机器视觉检测应用中,2020 年,张丽秀等通过采用改进的YOLOv3 算法实现汽车零件配置的识别,解决传统的终检人工作业检测的弊端[7]。为进一步提高识别速度和检测质量,基于YOLO 系列中YOLOv5s 具有体积小、速度快和易开发等优势,本文采用YOLOv5s算法,研发零件防错装检测系统,通过对汽车生产线过程中轮毂、前后杠、尾标等零件进行配置识别,取代了传统汽车零件装配后依靠人工检测。
1 YOLOv5s目标检测算法
YOLOv5s 网络由输入端(Input)、骨干网络(Backbone)、Neck层、输出层(Prediction)4 个部分组成。其网络模型结构如图1 所示。

图1 YOLOv5s网络结构模型
1.1 输入端(Input)
相对其他版本,输入端在Mosaic数据增强、自适应锚框计算、自适应图片缩放3 方面做了优化提升,Mosaic数据增强通过4 张图片的随机排布、绽放、裁剪的方式拼接形成一张新图片,然后将该张图片传入神经网络学习;自适应锚框是指针对不同的数据集,都需要设定特定长宽的锚点框;自适应图片缩放将自适应地添加最少的黑边到图片中,从而减少了计算量,提升了YOLOv5 的推理速度。
1.2 骨干网络(Backbone)
YOLOv5s 的骨干网络(Backbone)结构由Focus 结构、CSP结构[8]组成。Focus 对图片做切片操作,从一张高分辨率的图片中周期性的取出像素点到低分辨率的图片中,图片的相邻位置进行了堆叠,提高了每个像素点的视野。新的图片再经过卷积运算,最终得到没有丢失信息的二倍下采样特征图。CSP 主要将feature map 拆成两部分,一部分做卷积运算,另一部分和上一部分卷积运算结果进行连接。通过以上步骤,可以降低模型的计算量,提升运算速率。
1.3 Neck层
Neck层是指一系统混合和组合图像特征的网络层,并将图像特征传递到预测层。YOLOv4 的Neck 层采用FPN+PAN结构,其中FPN 层是自顶向下传达强语义特征,PAN是自底向上传达定位特征。YOLOv5 仍采用的是这种结构,与YOLOv4 不同的是,采用CSPNet 设计的CSP2结构,增强了网络特征融合的能力,而YOLOv4 的Neck只是进行普通卷积运算。
1.4 输出层
YOLOv5s使用GIOU Loss[11]作为损失函数,通过多轮次运算,不断地调整相应参数,使运算的锚框与实际锚框的误差值最小,最终得到最优的模型。
2 汽车零件防错装检测系统
本文检测系统可用于摄像头拍摄下的汽车外饰零件检测,以汽车轮毂零件为例,系统整体流程图如图2 所示。摄像头安装在轮毂零件装配后的工位,实时拍摄零件;检测系统设定每2 s 读取一次控制生产线的PLC 信号(获得实时的生产线上的每辆车的位置信息);当车辆到达指定拍摄位置,系统多摄像头获取并保存1 张视频帧图像,并调用YOLOv5s程序对保存图片计算,自动识别出零件配置信息(PR号),并输出标注的检测框图片;识别出的PR号与实际的生产需求PR 号进行比对,如果PR号相同,则实际安装的轮毂零件正确,PR 号不同,则实际安装轮毂零件配置错误,需要更换正确零件。系统保存识别的PR号,实际计划PR号,检测结果等检测信息,便于后续查询及问题追溯。

图2 检测系统流程图
2.1 系统环境及参数设置
本文中的汽车零件检测系统基于YOLOv5s算法,操作系统是Win10 系统。首先需要配置Python3.8.5 的虚拟环境。通过Anaconda3 完成,在系统控制台建立一个命名为“yolov5”的虚拟环境,然后激活yolov5 虚拟环境。YOLOv5s还依赖matplotlib,numpy,opencv,Pillow,tensorflow,pytorch 等库,具体依赖库都保存在YOLOv5的开源文件“requirements.txt”中。控制台输入“pip install-r requirements.txt”,打包安装所需的依赖库。
本系统的YOLOv5s 训练过程的一些关键参数设置为:图片尺寸为640 ×640,初始学习速率设置为0.001,权重衰减系数为0.000 5,网络优化方法选择为SGD,每次训练图片设置为64,训练轮数Epoch为300 轮。
2.2 数据集准备
汽车轮毂作为汽车轮胎必备零件,样式种类多。本文案例中的轮毂共有16 种,不同样式轮毂的PR 号也不一样。为了增加训练的模型的准确性,每种轮毂共收集200~300 张图片,分别在不同光线、分辨率、场景、位置条件下拍摄得到。数据集分为训练集和测试集,共包括5 202 张训练图片和572 张测试图片。人工对训练集和测试集的图片打标签,使用的标注软件为Labelimg,生成训练所需的“.txt”标注文件,标注后的部分图片见图3。

图3 轮毂零件数据样本集
在系统控制台输入“pip install labelimg”,即可安装Labeling标注软件。使用Labeling 软件对5 202 张训练图片和672 张测试图片进行矩形框标注,标注文件包含5个数据,其中第1 个数据为标签物体的类别,后面4 个数据为标签物体在图片中的坐标信息。
2.3 模型训练及结果
本文的检测系统模型训练是在Featurize 上,基于云GPU(显卡)进行训练,GPU 型号为NVIDIA 的RTX3060,拥有12.6 G显存。
将标注好的训练与测试集,基于YOLOv5s算法进行模型训练,采用精确率(Precision)、召回率(Recall)指标作为评价指标,其值越大,说明训练得到的模型准准确度越高。精确率指模型对所有识别出的图片(包括正确识别和误识别为该PR号的图片),正确识别的图片所占的比例[12]。召回率指被正确识别的数量占总识别图片数量的比例[13]。经过训练得到的模型,设定IOU 阈值为0.5 时,结果为精确率为98.964%,召回率为97.863%,训练结果数据如图4 所示。本系统的训练模型只有14.2 MB,正是基于YOLOv5s的权重数据文件小,这样后续在实际检测中,单张图片识别的时间短,满足生产过程的检测实时性要求,实际运行中,该模型在识别时,CPU检测一张图片需要300 ms左右,GPU检测一张图片需要15~20 ms左右时间。
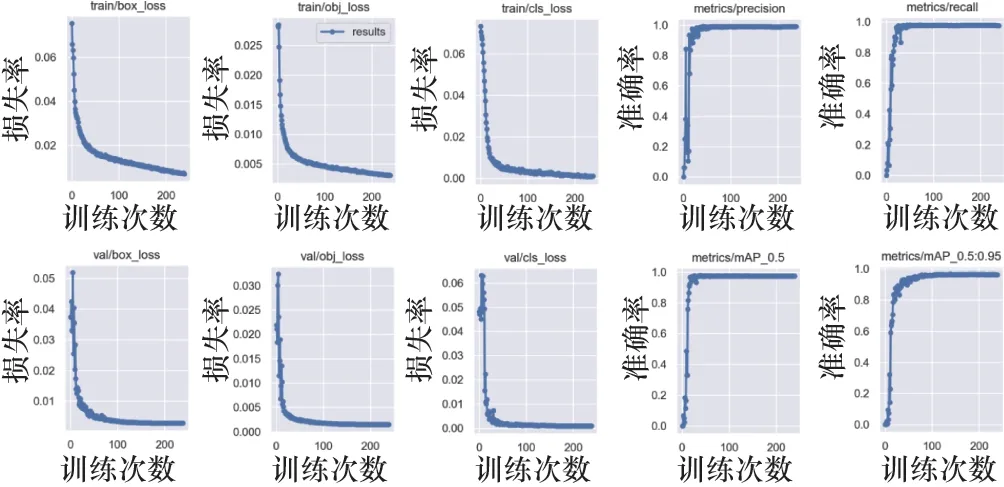
图4 模型训练结果
2.4 检测系统的设备投入
本轮毂检测系统的整体成本为摄像头2 台以及普通微型计算机1 台,其他都是人力投入。摄像头采用海康威视全彩POE摄像头,单价不到500 元,轮毂的检测需要在生产线左右两侧分别安装1 个摄像头。采用1 台微型计算机作为整个工厂所有的零件检测系统服务器,成本约5 000 元。综上,检测系统单次总投入在6 000 元左右。通过该项技术的运用不仅可靠性高,还可为每个零件的检测减少1 个人力投入。
3 检测效果与分析
图5 展示的是实际轮毂识别效果图,利用训练好的模型对摄像头拍摄的图片进行识别。图中的方框是通过模型训练后自动的描框,其中“G8-COX”指的是该轮毂的类别,即PR号,“0.84”是置信度(模型运算判断84%的概率是此PR号,系统设定0.5 即可接受)。

图5 实际识别图
根据实际生产线汽车轮毂零件检测结果,识别正确率在99%以上。本检测系统检测结果保存在一张数据库表中,如图6,便于后续问题追溯。图6 中记录的是图片识别的PR 号、判定结果、检测时间等信息。检测系统还有增加蜂鸣器及手机钉钉提醒功能,当检测到轮毂配置错误时,系统会让生产线的蜂鸣器响,并将错误信息实时发送到相应人的手机钉钉上。

图6 系统结果保存数据表
4 结束语
本文开发了基于YOLOv5s 算法的汽车零件防错装检测系统,以轮毂零件为对象开展验证,通过图片的收集制作了轮毂的训练与测试数据集,使用Labelimg软件完成所有图片的人工标注,为了节省成本,使用云GPU完成了模型的训练。结果表明模型训练精确率为98.964%,召回率为97.863%,系统实际检测结果可靠。
系统解决了汽车生产制造过程中,多配置零件易造成错装的问题。目前已经在一汽-大众佛山工厂完成开发应用,该设备的投入低,能够极大地降低人力成本投入,且检测准确度与效率高。根据实际运行效果表明:该系统优于人工检测,可以满足在生产节拍内零件检测要求,进而提升车辆生产的质量,避免出现错装零件的汽车流入客户中。计划下一步将此技术扩展到零件供应商的生产过程防错检测。
猜你喜欢
中国交通信息化(2022年9期)2022-10-28
汽车工程师(2021年12期)2022-01-18
上海涂料(2021年5期)2022-01-15
制造技术与机床(2017年10期)2017-11-28
环球市场信息导报(2016年22期)2017-07-31
环球时报(2017-07-18)2017-07-18
制造业自动化(2017年2期)2017-03-20
中国新技术新产品(2017年3期)2017-03-07
环球市场信息导报(2016年42期)2016-02-09
大型铸锻件(2015年1期)2016-01-12
