
基于改进YOLOv5的人脸检测算法
2023-03-23 07:44孙孚斌朱兆优陈思超陈弘扬
机电工程技术 2023年2期
孙孚斌,朱兆优,陈思超,陈弘扬
(东华理工大学机械与电子工程学院,南昌 330013)
0 引言
目标检测算法是目标识别的基础,随着机器视觉行业及相关产业的蓬勃发展,各种检测算法也得到了不同程度的优化和性能提升。
目前比较常见的目标检测算法可以分出两种类型,Two-stage 方 法 和One-stage 方 法。Two-stage 算 法 就 是 把检测问题分成两个阶段来处理,在第一个阶段中划出包含目标大致位置信息的候选区域(Region Proposals),然后在第二阶段对候选区域作分类以及位置细修处理。目前比较常用的Two-stage 类型的方法有卷积神经网络(R-CNN);由Ren 等[1]提出的基于卷积神经网络改进的FasterR-CNN 算法,该算法结合特征图共享和边框回归的思想,利用RPN 网络提取目标的深层网络特征,运用非极大值抑制(NMS)的方法实现了在GPU 上的目标实时检测;通过多次迭代寻找最优分类器的Adaboost人脸检测算法。One-stage 目标检测算法,该类算法除去了划分候选区域的步骤,可以通过一个stage 直接找出目标的类别和坐标值,目前常见的one-stage 算法有SSD,由俞伟聪[2]在ECCV2016 提出的一种检测速度比FasterR-CNN 快的检测算法;还有Redmon[3]提出的YOLO检测算法。
YOLO 检测算法具有泛用性高,检测失误率低且检测速度快等优点,被广泛应用于人脸检测中。初代的YOLO 检测算法运用于人脸检测方面由于其单一尺度的网格划分导致对于多尺度的人脸检测实际效果达不到预期,召回率不高。蒋纪威等[4]提出修改内部参数改变神经网络结构的方法,提高了检测的实时性,但是没有改善训练的精度。朱超平等[5]针对卷积层进行改进,在卷积层的后面增加批量归一化的操作,提升了训练速度,但是仍然没有提升训练的精度。本文提出一种改进的YOLOv5检测模型,并应用于人脸检测。首先YOLO的版本选择YOLOv5,较之前的版本增添了许多有效的数据处理方式以达到提高训练模型的精度且减少训练时间的目的,比如用于数据扩增的Mosaic、Cutout,还有改变亮度、图像扰动、加噪声、翻转、随机擦除等方式[6]。但是YOLOv5使用的边界框回归损失函数GIOU 存在当检测框与真实框呈现为包含关系时会退化为IOU,无法对其相对位置关系进行区分的问题[7]。在此之上替换YOLOv5的边界框回归损失函数为EIOUloss,即通过预测框与真实框的中心点间标准化距离加速损失的收敛,并分别考虑边界框的纵横比,把纵横比拆开,分别计算真实框和预测框的长和框,进一步提升回归精度。
1 YOLOv5算法
YOLOv5 是一种单阶段目标检测算法,其网络结构如图1所示。

图1 YOLOv5网络结构
YOLOv5 目标检测算法由输入端、基准网络(Backbone)、Neck 网络以及Head 输出端四个部分组成[8]。首先是YOLOv5网络的输入端,输入图像大小为608×608×3(RGB3 通道)。该阶段存在一个图像预处理步骤,即将输入的图像放缩至输入网络的608×608 大小,并对输入的图像进行马赛克(Mosaic)数据增强,通过随机裁剪、随机排布和随机缩放的方式对输入图像进行拼接,不仅能提高对小目标的检测效果,还可以丰富检测目标的背景[9]。其次是基准网络部分主要采用的是Focus 结构和CSP(内含残差结构)以及SPP(空间金字塔池化)结构组成。Foucs 的主要作用就是切片功能,比如将原始的608×608×3的图像输入Focus 结构中,再经过切片的操作之后会得到304×304×12的特征图,接着通过一个32个通道数的Conv 层,输出大小为304×304×32 的特征映射[10]。图中C3 模块内含Bottleneck(瓶颈层),其中n代表模块中瓶颈层的个数,ture/flase代表着是否启用瓶颈层中的残差模块。提取的特征印象经过多重卷积之后送入SPP(空间金字塔池化)模块进行各种尺度的特征图的融合,先通过一个1*1的卷积使输入通道减半,之后做内核大小分别为5、9、13 的最大池化,再将最大池化结果与未进行池化的数据进行连接,最后合并[11]。之后送入Neck 网络,进一步提升特征的多样性和鲁棒性。最后采用3个尺度进行预测,每一个尺度都具有3 个BoundingBox(即界限值),最后根据与实际框的交并比(IOU)最大的界限值来进行物体预测[12]。图像可视化处理过程如图2所示。
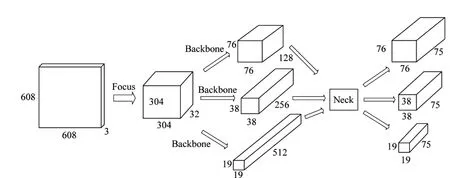
图2 图像可视化变化过程
2 改进的YOLOv5算法
2.1 基准网络结构改进
在传统的基准网络结构(Backbone)的最后一层添加一层残差注意力模块(SE-RsNet Module),改进后的基准结构网络如图3所示。
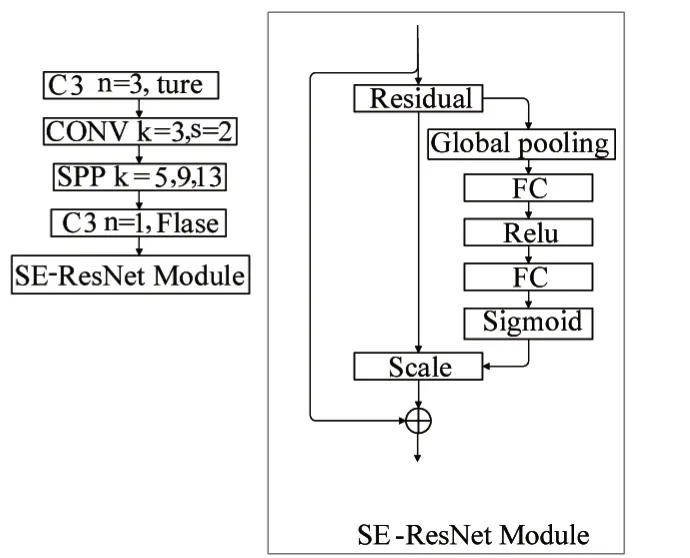
图3 残差注意力模块
该模块先将输入的特征图通过一次全局平均池化(Global pooling)进行压缩,经过压缩后输出一个1*1*512的特征向量,该特征向量通过激励后进行Scale操作,将1*1*512 的特征向量进行通道权重相乘,即将SE 模块计算出来的各通道权重值分别和原特征图对应通道的二维矩阵相乘,得到输出结果。该模块虽然加大了总计算量,但是提升了参数量,使检测模型更加关注识别物体,而且因为残差结构的存在,保证了改变后的模型不会相较原来的模型更差。
2.2 算法改进
2.2.1 YOLOv5算法存在的缺陷
目标检测任务的损失函数一般由Objectness score 损失(置信度损失)、class probability score 损失(分类损失)以及bounding box 损失(边界框回归损失)3 部分组成。YOLOv5 算法采用GIOU 作为边界框回归损失函数[13]。GIOU 损失函数克服了IOU 损失函数在预测框与真实框不相交时无法反馈两个框之间的距离远近的问题,并且同时继承了IOU的优点。计算损失公式如下:
其中,B是预测框,Bgt是真实框,C包含预测框和真实框的最小凸闭合框。从GIOU 的公式中可以看出GIOU 类似IOU 采用预测框与真实框之间的距离来度量损失函数,并且对尺度不够敏感IOU ∈[0,1],得到GIOU ∈[-1,1],所以GIOU 不仅仅关注预测框与真实框之间的重叠区域,还关注其他的非重叠区域,能更好地反映预测框与真实框的重合度,当完全重合时IOU=GIOU=1,当预测框与真实框不重合时,不重合的程度越高,GIOU的值则越接近-1。
但是根据式(7)可以看出,当预测框与真实框框呈包含状态时无法获得其相对位置关系。如图4所示。

图4 预测框与真实框呈包含状态
在这一情况下,3 张图的LGIOU是相等的,由于GIOU十分依赖IOU,所以在垂直方向上的误差很大,很难收敛,导致GIOU不够稳定[14]。
2.2.2 改进的YOLOv5损失函数
针对上述GIOU 存在的问题,提出使用EIOUloss 函数替代GIOU。EIOU通过将GIOU中引入最小外接框来最大化重叠面积的方法替换为两个框中心点的标准化距离,并添加一个影响因子和用边长作为惩罚项,该影响因子考虑了预测框纵横比拟合真实框的纵横比。损失公式如下:
该损失函数包含重叠损失LIOU,宽高损失Lasp以及中心距离Ldis损失3 个部分,其中bgt是真实框的中心点,b是预测框的中心点,ρ代表两个中心点之间的欧氏距离,c 代表包含真实框和预测框的最小闭合框的对角线距离,w和h分别是预测框的宽度和高度,wgt和hgt分别是真实框的宽度和高度,Cw和Ch分别是覆盖真实框和预测框的最小外接边框的宽度和高度。
3 实验与结果分析
3.1 实验平台
本文搭建的实验环境为:Intel core i7-115200 处理器,基准频率2.3 GHz,GPU 为RTX 2060,6 GB 显存,Windows操作系统。
3.2 结果分析
本文采用由香港大学发布的人脸数据集Wide Face,其中包含了各种不同的光照状态、运动状态、姿势、远近、肤色和不同程度遮挡的人脸,从61 种人脸分类中各取出20 张用作人脸数据集训练,迭代次数为默认的300次,训练集与验证集划分为80%和20%。训练获得的损失函数对比如图5~6 所示。通过对比可以看出,改进后的YOLOv5检测模型的损失低于未改进的YOLOv5检测模型,大概提升14.2%,说明改进后的YOLOv5检测模型具有更好的鲁棒性。

图5 改进的YOLOv5损失曲线
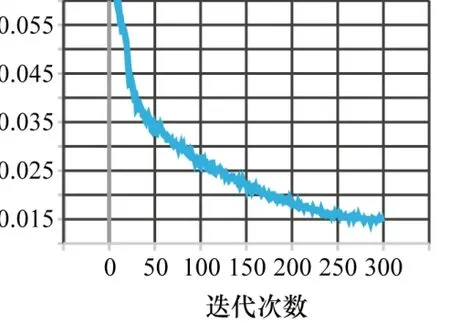
图6 YOLOv5损失曲线
改进YOLOv5 检测模型训练的PR 曲线如图7 所示。训练后的mAP@0.5(IOU 为0.5 时Precision 和Recall围成的面 积)和 mAP@0.5:0.95(IOU 从0.5 到0.95,步长为0.05,上的平均mAP)的值以及准确率比较如表1 所示。可以看到,改进后的YOLOv5目标检测算法较传统的YOLOv5检测算法拥有更高的准确率和精度。

图7 PR曲线

表1 实验数据对比
将训练获得的权重文件应用于人脸检测,每一帧图片的处理时间平均只需要0.03 s,实时视频流处理可以保持33 的FPS,保证经过算法检测后输出的视频图像的流畅性,效果如图8~10 所示。从图中可以看到,改进后的YOLOv5 检测算法训练获得的权值文件应用于实际的人脸检测中不仅保持了较高的检测速度,并且拥有较高的准确率,能够忽略小人脸检测、多目标检测和人脸肤色、表情差异产生的影响。
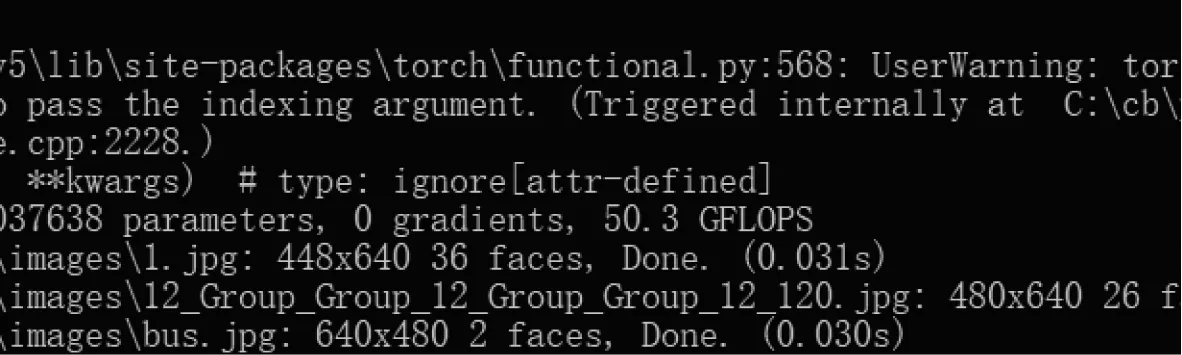
图8 程序运行

图9 人脸原图

图10 人脸检测效果
4 结束语
本文提出了改进YOLOv5 目标检测算法的具体方法,通过在损失函数中引入真实框与预测框中心点间的欧式距离和预测框与真实框的长比及宽比作为损失惩罚项以加快函数收敛速度和提高回归精度,另外在基准网络结构中的最后一层增加一残差注意力模块,提升参数量,使检测模型更加关注识别物体。实验表明改进的YOLOv5 目标检测算法在wideface 数据集上的训练准确率达到88.28%,较传统YOLOv5 准确率提升2.6%,训练过程中的损失为0.013,较传统YOLOv5 损失减小13.33%,拥有更好的鲁棒性。该目标检测算法解决了传统YOLOv5目标检测算法中当预测框和真实框呈包含状态时无法预测两框之间相对位置关系以及在垂直和水平方向上收敛速度慢的问题,提升了回归精度的同时保证了人脸检测过程中要求的实时性,能够较好地应用于实际人脸检测项目中。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
动漫星空(2018年9期)2018-10-26
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
