
融合ELECTRA 和文本局部信息的中文语法错误检测方法
2023-03-16 10:21陈柏霖王天极任丽娜黄瑞章
计算机工程 2023年3期
陈柏霖,王天极,任丽娜,3,黄瑞章
(1.贵州大学 公共大数据国家重点实验室,贵阳 550025;2.贵州大学 计算机科学与技术学院,贵阳 550025;3.贵州轻工职业技术学院,贵阳 550025)
0 概述
随着互联网的普及,中文电子文本的数量呈爆炸式增长趋势。文本质量参差不齐,语法错误会严重影响人们的阅读效率。在中文辅助写作中,一个完善的中文语法错误检测工具可以帮助学习者快速定位错误点和错误类型并对文章进行修改,从而提高写作效率。此外,借助中文语法错误检测工具可以让审校人员节省大量时间,提高出版业校对过程中的工作效率。然而,面对海量的中文文本,如何快速高效地自动检测中文语法错误成为一个亟需解决的问题。
中文语法错误检测(Chinese Grammar Error Detection,CGED)的目标是自动检测文本中存在的错别字、语法和语序错误等。对于给定的文本,CGED 的检测对象包括是否有语法错误、错误的类型以及错误的发生位置。传统的语法错误检测研究主要集中于英文,大多从全局语义出发,采用机器翻译等生成式方法对语法错误进行检测和纠正。与英文相比,中文不存在显著词边界,也没有时态、单数、复数等识别元素,语法复杂度高且蕴含的语义信息丰富,因此,中文语法错误检测更加依赖于文本局部信息,如短语在句子中的语义和位置等。目前,许多研究人员参考了英文语法纠错方法,使用生成式方法直接进行改错,跳过了错误检测环节,只有少量研究采用序列标注方法进行中文语法错误检测。然而,生成式方法往往从全局语义出发,忽略了中文文本局部信息对语法检错的作用,并存在所需数据量大、难以训练、可靠性差等问题,使其不能很好地适用于中文语法错误检测任务。因此,如何在数据有限的情况下充分利用文本局部信息提高中文语法错误检测的效果,是该领域的一个重点研究方向。
本文提出应用于中文语法错误检测任务的ELECTRA-GCNN-CRF 模型。不同于生成式方法,本文将语法检错任务视为序列标注问题,使得所需数据量和训练难度降低。在ELECTRA 预训练语言模型的基础上,通过门控卷积网络捕捉文本局部信息,缓解错误语义传播问题,并加入残差机制避免梯度消失现象,最后通过条件随机场(Conditional Random Field,CRF)层解码获取每个字符的语法错误标签。
1 相关工作
语法错误检测研究可以追溯到20 世纪80 年代,早期大都基于经验和规则来检查和纠正语法错误。为了识别和处理更复杂的语法错误,基于机器翻译的方法被用于语法错误检测中[1-3],该类方法将文本纠错视为从错误句子到正确句子的“翻译”问题。在英文文本纠错中,FU 等[4]将简单的拼写错误通过规则进行改正,对于改正后的文本,利用Transformer 模型对较复杂的语法错误进行修改。ZHAO 等[5]将复制机制集成到机器翻译模型中,利用输入句和生成句之间存在大量重叠单词的特点,将简单的词复制任务交给复制机制,使用注意力机制学习难度较大的新词生成任务。在中文领域,机器翻译方法大多只研究针对错别字的纠错,也被称为中文拼写检查(Chinese Spelling Check)。现有方法主要从以下3 个方面进行研究:
1)使用不同方法对汉字音形混淆集进行建模[6-7],学习错误字和正确字之间的映射关系。
2)将汉字的音形特征通过特征嵌入的方式注入模型底层[8-10],使得模型能够动态学习每个字的特征。
3)使用不同策略对模型产生的候选字进行后处理[11-13],从而提升输出精度。
由于中文语法错误检测起步较晚,缺乏高质量的大规模训练语料,使得机器翻译方法在包含多种语法错误的文本中检测效果不佳。部分研究使用数据增强方法[14-15],通过人工构造中文语法错误数据来对现有数据集进行扩充。然而,现有方法模拟出的伪数据的语法错误分布往往与真实分布并不十分一致,不能对模型起到很好的训练作用。因此,有研究人员将中文文本纠错分解为先检错后纠错的二阶段任务,并将中文语法错误检测视为序列标注任务。目前,中文语法错误检测相关研究大都集中在NLPTEA 的CGED 评测任务中。FU 等[16]在BiLSTM+CRF 序列标注模型上添加分词、高斯ePMI、PMI 得分等先验知识,并通过不同的初始化策略训练多个BiLSTM 模型,对其加权融合后通过CRF 层输出最终结果。2020 年,在NLPTEA 的CGED 评测任务[17]中,WANG 等[18]在Transformer 语言模型的基础上融入残差网络,增强输出层中每个输入字的信息,使得模型可以更好地检测语法错误位置。CAO 等[19]在BERT 模型的基础上加入一种集成基于分数的特征的门控机制,融合了语义特征、输入序列的位置特征和基于评分的特征。LUO 等[20]使用基于BERT 模型和图卷积网络的方法提高基线模型对句法依赖的理解,并在多任务学习框架下结合序列标注和端到端模型来提高原始序列标注任务的效果。
综上,现有的中文语法错误检测方法通常从全局语义出发,使用生成式方法直接生成正确语句或是在模型中添加人工句法特征,均未有效利用文本局部信息。针对这一问题,本文使用ELECTRA 预训练模型表征文本信息,在此基础上,使用门控卷积神经网络(Gated Convolution Neural Network,GCNN)网络捕捉文本的局部语义和位置信息,最后使用CRF 进行解码,不需要额外添加句法特征,从而缓解梯度消失和错误语义传播问题。
2 模型结构
本文提出的ELECTRA-GCNN-CRF 模型整体架构如图1 所示,该模型自底向上由输入层、GCNN 层、CRF 层和输出层组成,其中,GCNN 层的作用是提取文本的局部信息。ELECTRA-GCNN-CRF 模型将中文语法纠错视为序列标注任务,为文本中的每个字预测对应的语法错误标签,并对文本采用BIO 的标注方式,即字符位于语法错误部分开头时标注为B,位于语法错误部分内部时标注为I,非语法错误部分的字符标注为O。

图1 ELECTRA-GCNN-CRF 模型架构Fig.1 ELECTRA-GCNN-CRF model architecture
2.1 输入层
文本输入模型前需要对其进行向量化处理,传统文本表示模型存在表征能力不足、无法处理一词多义等问题。预训练语言模型在大规模无监督语料中进行训练,通过Transformer 架构对输入序列进行建模,获取每个字的上下文语义知识,因此,其可以根据上下文语义动态生成字向量,有效解决一词多义问题,而且还能根据不同任务对预训练模型进行微调,从而获得针对性更强的字向量,适应特定任务的需求。
由于ELECTRA 预训练语言模型具有训练效率高、训练方式能够避免数据不匹配问题等优点,因此本文选用ELECTRA 预训练语言模型进行文本向量化。ELECTRA 模型是CLARK 等[21]借 鉴GAN 网络[22]的思想而设计的,该模型由生成器和判别器两部分组成,并使用RTD(Replace Token Detection)预训练方式。生成器是个小型掩码语言模型,负责对输入的Token 进行随机替换,然后让判别器判别生成器的输出是否发生了替换,取判别器作为最终的ELECTRA 预训练语言模型,其具体流程如图2 所示。这种预训练方式避免了因“[MASK]”标记导致的预训练阶段与微调阶段数据不匹配问题,并且大幅提高了训练效率,也使ELECTRA 预训练语言模型对文本中的语义变化特别敏感,适用于语法错误检测任务,其性能优于BERT 预训练语言模型。

图2 ELECTRA 预训练语言模型训练流程Fig.2 Training procedure of ELECTRA pre-training language model
设输入序列为X={x1,x2,…,xn},则生成的隐藏层向量Hc为:
2.2 残差门控卷积神经网络
为了充分利用文本局部信息进行语法错误检测,降低语法错误对上下文语义的影响,本文使用残差门控卷积神经网络提取文本的局部特征,此部分由两层卷积核长度分别为5 和3 的残差门控卷积层组成,整体模型和残差门控卷积神经网络结构如图3所示。

图3 残差门控卷积神经网络结构Fig.3 Structure of residual gated convolution neural network
GCNN 主要由卷积层和线性门控单元(Gate Linear Unit,GLU)组成。卷积层可以提取一定宽度内相邻词的局部语义和位置特征,并使由语法错误造成的错误语义控制在给定宽度内,能够有效缓解错误语义传播问题。GLU 是一种门控机制,使用Sigmoid 激活函数控制信息流通,能够保留有效信息,抑制无效信息带来的影响[23]。
GCNN 单元内的操作可用公式表示为:
其中:Hc表示由输入层得到的隐藏层向量;Conv 表示卷积操作;σ表示Sigmoid 激活函数;⊗表示向量的哈达玛积;C表示经过门控卷积单元的局部特征向量。
为了保留全局语义信息并改善梯度消失问题,本文在GCNN 单元的基础上引入残差机制,用公式表示为:
其中:LayerNorm 表示层归一化;⊕表示向量相加;Z表示经过GCNN 的特征向量。
2.3 CRF 层
CRF 可以解决输出序列与标注规则不符的问题,如“B-S”标签后不能接“B-W”标签等,只能接“I-S”或者“O”标签。CRF 模型通过特征转移函数计算概率分数,以判断当前位置与相邻位置标签的依赖关系。
设CRF的输入序列为Z,则输出序列的分数函数为:
其中:Tyi,yi+1表示标签yi到标签yi+1的 转移分数;Pi,yi表示第i个字到第yi个标签的分数。
然后通过条件概率公式计算预测序列Y,以此生成所有可能的标注序列YZ,最后使用维特比算法计算YZ中得分最高的Y:
其中:为真实的标注序列;Y为全局最优标注序列。
2.4 输出层
ELECTRA-GCNN-CRF 模型在输出层进行BIO解码,将语法错误标签转化为(起始位置,结束位置,语法错误类型)格式的三元组,输出语法错误检测结果。如图1 中输出(9,10,R),表明例句中起始位置为“9”、结束位置为“10”的“个月”这一段文本存在语法错误,错误类型为“成分冗余”。
3 实验结果与分析
3.1 数据集
为了验证本文方法的有效性,使用NLPTEA 中文语法错误检测数据集进行实验,其为一份人工标注过的语法错误检测数据集,语料来源是母语不为汉语的学习者在中文写作中产生的错误样例。数据集将语法错误分为4 种类型:Selection error(记为“S”,即用词不当);Redundant error(记为“R”,即成分冗余);Missing error(记为“M”,即成分缺失);Word ordering error(记为“W”,即词序不当)。对于每段语法错误,生成“起始位置,结束位置,语法错误类型”格式的三元组,如果语句中不存在语法错误,则输出“correct”。数据集中的语句可能没有语法错误,也可能包含一种或多种语法错误,数据样例如表1 所示。

表1 NLPTEA 中文语法错误检测数据集数据样例Table 1 Data sample of NLPTEA Chinese grammar error detection dataset
本文收集了NLPTEA 历年的CGED 任务评测数据集,去重之后对数据进行BIO 标注,将数据集给出的标签映射到每一个字符上,并按照8∶2 的比例划分训练集和验证集,最终在2020 年的NLPTEA CGED 任务的测试集上进行测试,数据集规模如表2所示。

表2 数据集规模Table 2 Dataset size 单位:个
3.2 评价指标
本文采用NLPTEA 的CGED 任务评价指标作为本次实验的评价标准。语法错误检测模型需要从以下3 个方面对语句进行检测:
1)Detection-level,即检测层,对于输入的语句,判断其是否包含语法错误。
2)Identification-level,即识别层,对于输入的语句,判断其包含哪几种语法错误。
3)Position-level,即定位层,对于输入的语句,判断每段语法错误的起始位置和类型。Position-level是语法错误检测最关键的部分。
对于上述3 个方面,模型使用以下指标进行评价:
3.3 参数设置
实验中模型参数设置如下:隐藏层维度为768;ELECTRA 预训练模型[24]的Transformer结构为12层;多头注意力机制的头数为12;每批次大小为240;优化器采用Adam;丢弃率为0.15;最大迭代次数为20;使用早停法缓解过拟合;CRF 层的学习率为10-3,其他层的学习率为10-5;GCNN 层卷积核宽度分别为5 和3。
3.4 对比实验结果分析
为了验证本文模型的有效性,将其与NLPTEA 2020的CGED 任务中表现优异的检测模型进行横向比较与分析,对比模型包括ResELECTRA_ensemble[18]、BSGED_ensemble[19]、StructBERT-GCN[20]和StructBERTGCN_ensemble[20]。4 种对比模型具体描述如下:
1)ResELECTRA_ensemble,该模型将残差网络与Transformer 结构进行融合,使用ELECTRA-large预训练语言模型参数进行初始化,最后使用80 个单一模型进行集成。
2)BSGED_ensemble,该模型在BERT 的输出中加入文本位置和PMI特征,并使用门控机制进行控制,通过BiLSTM 网络获取上下文信息,然后使用CRF 层进行解码,最后利用16 个单一模型进行集成。
3)StructBERT-GCN,该模型的训练方式比原版BERT 增加字序预测和句序预测2 个新的训练目标,同时将句法依存关系使用GCN 网络进行建模并融入训练过程。
4)StructBERT-GCN_ensemble,该模型是38 个StrcutBERT-GCN-CRF 模型和65 个多任务训练的StructBERT-CRF 模型的集成。
在NLPTEA 2020 的中文语法错误检测数据集上,本文模型与基线模型的对比结果如表3 所示,其中,ELECTRA-GCNN-CRF 和 ELECTRA-GCNNCRF_ensemble 为本文模型,后者是10 个单一模型的集成,最优结果加粗标注。从表3 可以看出,在单一模型中,本文模型较StructBERT-GCN 在3 个方面的F1 值均取得明显进步,在所有模型中,ELECTRAGCNN-CRF_ensemble 在Detection-level 中的F1 值接近最优性能,在Identification-level 和Position-level方面取得了最优的F1 值。

表3 本文模型与NLPTEA 2020 的CGED 任务评测模型性能对比Table 3 Performance comparison between this model and CGED task evaluation models of NLPTEA 2020 %
3.5 消融实验结果分析
为了验证本文模型各部分结构的有效性,采用以下模型进行消融实验:
1)ELECTRA-softmax,仅使用ELECTRA 预训练语言模型。
2)ELECTRA-CRF,使用ELECTRA 预训练模型和CRF 层。
3)BERT-GCNN-CRF,将本文的预训练语言模型替换为BERT-base 预训练模型[25],其余部分不变。
4)ELECTRA-BiLSTM-CRF,将本文模型的GCNN层替换为2 层BiLSTM 神经网络,其余部分不变。
5)ELECTRA-GCNN-CRF-RES,在本文模型的基础上去掉GCNN 层的残差机制,其余结构和参数不变。
6)ELECTRA-GCNN-CRF,本文提出的中文语法错误检测模型。
消融实验结果如表4 所示。从表4 可以看出:ELECTRA-softmax、ELECTRA-CRF 和ELECTRAGCNN-CRF 在3 个方面的F1 值均依次上升,证明了GCNN 层和CRF 层的有效性;ELECTRA-BiLSTMCRF 在Detection-level 中取得最高的F1 值,表明在判断语句是否有语法错误的任务中,使用BiLSTM网络捕捉上下文信息可以获得更好的效果;对比ELECTRA-GCNN-CRF 和BERT-GCNN-CRF 可以看出,在参数规模相同的情况下,使用ELECTRA 预训练模型性能远优于BERT 预训练模型,证明ELECTRA 生成的上下文语义特征向量更能反映语义变化情况,对错误语义更加敏感,能够获取基础的语法错误特征,结合后续的局部信息提取层能够获得语法错误的相对位置和局部语义信息,从而提升语法错误检测效果;ELECTRA-GCNN-CRF 对比ELECTRA-BiLSTM-CRF,在Position-level 的F1 值提升了1.37 个百分点,即使用GCNN 网络相较于BiLSTM 网络能够更好地提取文本特征,缓解语法错误对于上下文语义的影响;ELECTRA-GCNNCRF-RES 对 比ELECTRA-GCNN-CRF,在Positionlevel 的F1 值下降了3.97 个百分点,表明加入残差机制可以使模型更好地识别语法错误边界。

表4 消融实验结果Table 4 Ablation experimental results %
3.6 语法错误对比实验结果分析
为了进一步比较不同模型在不同类型语法错误中的识别效果,本文分别计算BERT-GCNN-CRF、ELECTRA-BiLSTM-CRF、ELECTRA-softmax、ELECTRACRF 和ELECTRA-GCNN-CRF 模型在4 种语法错误中Position-level 的精确率、召回率和F1 值,其中精确率如图4 所示。从图4 可以看出,本文模型在4 种语法错误中均能取得最高的精确率,这是由于语法错误通常出现在文本局部,本文模型通过GCNN 网络能够学习到每种语法错误的相对位置、局部语义信息等重要特征,因此,相比于其他模型,本文模型能够更加精准地识别语法错误的起止边界和类型,从而提升中文语法错误识别精度。在W 型错误中,ELECTRA-softmax 和ELECTRA-CRF 模型的对比结果表明CRF 层对于识别语序错误具有重要作用。

图4 5 种模型检测不同类型语法错误时的精确率对比Fig.4 Comparison of precision of five models in detecting different types of grammar errors
召回率对比情况如图5 所示,从图5 可以看出,和精确率情况类似,本文模型在S 型、R 型和W 型的语法错误中均能取得最高性能,然而,在M 型语法错误中,ELECTRA-BiLSTM-CRF 模型的召回率比本文模型高出3.02%,原因可能是成分缺失错误往往出现在句子的主语或谓语部分,识别此种类型的错误需要更大范围的上下文乃至全局语义信息,在全局语义特征提取方面GCNN 网络不如BiLSTM。
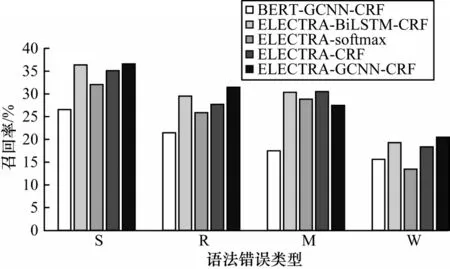
图5 5 种模型检测不同类型语法错误时的召回率对比Fig.5 Comparison of recall of five models in detecting different types of grammar errors
为了综合衡量模型性能,平衡精确率和召回率,本文对比不同模型的F1 值,结果如图6 所示。从图6可以看出:基于BERT 的中文语法错误检测模型的F1 值在3 种语法错误中逊于其他模型,仅在W 型错误中优于ELECTRA-softmax 模型,说明ELECTRA模型的预训练方式对中文语法错误检测任务有显著效果;在基于ELECTRA 的模型中,对于M 型语法错误的识别F1 值均相差无几,说明基于ELECTRA 的模型均对M 型语法错误较为敏感;在其他3 种类型的错误中,本文模型的F1 值相较对比模型均有不同程度的提升。以上结果表明本文模型在中文语法错误检测任务中具有有效性。

图6 5 种模型检测不同类型语法错误时的F1 值对比Fig.6 Comparison of F1 values of five models in detecting different types of grammar errors
4 结束语
针对现有中文语法错误检测模型无法充分利用文本局部信息导致语法错误检测效果较差的问题,本文提出一种中文语法错误检测模型ELECTRAGCNN-CRF。将中文语法错误检测视为序列标注问题,通过ELECTRA 语言模型获取文本的语义表征,结合残差门控卷积神经网络和CRF 识别语法错误。在NLPTEA CGED 2020 公开数据集上的实验结果表明,该模型对中文语法错误检测效果具有提升作用,消融实验结果也验证了模型各部分结构的有效性。
中文语法具有较高的复杂性,本文所提模型仍然存在很多不足,在错误类型和位置的识别检测方面有很大的提升空间。下一步将针对目前缺乏大规模中文语法错误数据集的问题,研究新的数据增强方法,使得构造的伪数据能够很好地模拟真实的语法错误,从而获得更优的语法错误检测效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
开放教育研究(2020年2期)2020-03-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
科技资讯(2016年25期)2016-12-27
青春岁月(2016年22期)2016-12-23
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
电视技术(2014年19期)2014-03-11
外语学刊(2011年1期)2011-01-22
