
结合多解码器与两阶段通道选择的异常检测方法
2023-03-16 10:20王禹博陈利锋许卫霞
计算机工程 2023年3期
王禹博,陈利锋,许卫霞
(复旦大学 计算机科学技术学院,上海 200433)
0 概述
异常检测作为机器学习的一个重要研究课题,在各领域有着广泛的应用。例如,在工业领域中,异常检测常被用于检测传感器的异常数据,并起到实时监控报警的作用。在学术领域中,异常检测被用来检测大规模深度学习数据集中标注错误的异常样本。在异常检测问题中,正常的数据样本被称为合群点(Inliers),异常的数据样本则被称为离群点(Outliers),数据样本类别被划分为正常类(正类)和异常类(负类)。由于训练数据中缺乏有标记的异常类样本,传统的多分类模型往往效果较差。因此,在异常检测中,常对正常类的数据分布进行单分类建模[1],从而把异常类数据区分出来。
目前,研究人员已提出大量关于异常检测的方法,这些方法使用的典型策略有如下3 种:建立一个参数化的合群点模型,并从正样本训练数据中学习到适当的参数,如Robust Covariance[2]、One-Class SVM[3]等;为合群点设置判别规则,并根据该规则识别和剔除离群点,如Isolation Forest[4]等;利用离群点的几何分布特性对其进行分离,如Local Outlier Factor[5]等。随着各应用领域中深度学习方法的快速发展,出现了许多基于神经网络的异常检测方法。这些方法大多属于上述3 类策略中的第1 类,但存在3 个主要问题。问题1:没有利用到实际场景中的无标注数据。实际工业领域中的数据往往有大量无标注数据,目前许多方法仅使用正样本训练数据对模型进行训练,导致模型对训练数据过拟合。同时,无标记数据中含有丰富的负类信息,这些信息也被完全忽略了。问题2:需要人为设定异常阈值。绝大多数方法只设计一种正常性度量方式对样本进行打分和排序,进而确定哪些样本被归为异常样本。然而,这种方法必须依赖人为的经验和技巧确定分数阈值来分离合群点和离群点。一方面,这种行为可能引发相当程度的人为误差;另一方面,阈值作为超参数,对数据集较为敏感,需要针对不同的数据集和应用场景来进行调节,导致工作量和计算开销增加。问题3:对等地处理合群点和离群点。有些方法对等地处理合群点和离群点,暗含了“合群点和离群点拥有相似的模式”这一假设,与异常检测场景下的数据性质不相符。这是因为在异常检测中,合群点和离群点由不同的生成机制产生,从而使数据分布间存在较大差异。
本文提出一种基于多解码器与两阶段通道选择的异常检测方法,使用一个包含编码器、多通道解码器、两阶段通道选择器的重构-选择模型代替传统方法中的重构-排序-拒绝模型,通过使用多个通道对输入样本进行重构,采用通道选择器选出更适合的通道,并根据通道的属性确定样本的异常性,从而完成异常检测任务。设计一种新的免阈值多维度度量方法,直接评估样本相对于各潜在类的归属度,并据此建立免阈值的选择器,以判断输入样本是否异常,从而减少确定阈值过程中产生的人为误差和计算开销。此外,使用无标记数据对离群点进行建模及增强正样本训练数据,以更好地训练合群点通道。最后,充分注意合群点与离群点之间的生成机制和数据分布的差异性,采用不对等的方式进行建模,为离群点分配更多通道以有效表示其相对复杂的分布。
1 相关研究
深度异常检测方法一般可归纳为3 种范式:在第1 种范式下,深度学习和异常检测作为2 个独立模块,其中深度学习模块仅作为用于特征工程的独立特征提取器;在第2 种范式下,深度学习和异常检测有一定程度的耦合,致力于学习对正常性有效特征的表示;在第3 种范式下,深度学习和异常检测被高度整合,直接以端到端的方式通过神经网络学习异常分数。下面分别介绍基于这3 种范式的方法。
基于第1 种范式的方法使用深度学习技术从高维度数据或线性不可分数据中抽取适用于下游异常检测任务的低维度特征。在这类方法中,特征提取模块和异常性评估模块完全分离且互相独立。其中,基于深度学习的特征提取模块的唯一目的是对原始输入数据进行降维。相较于传统机器学习方法中常用的降维措施如主成分分析[6]、随机映射[7]等,深度学习方法往往在捕捉复杂语义和非线性关系上表现更好[8]。这类方法通常假定通过深度学习方法获取特征中存在可以区分正常样本和异常样本的有效信息。一些研究者直接使用大规模预训练模型如AlexNet、VGG、ResNet 等提取低维特征,从而在复杂、高维的结构化数据如图像数据和视频数据上进行异常检测。去掩蔽在线异常检测框架[9]采用在ImageNet 数据集上预训练的VGG 模型为下游视频异常检测任务提取特征。ANDREWS 等[10]使用类似的VGG 模型对单类支持向量机(Support Vector Machine,SVM)进行预训练,并在MNIST 数据集上微调以进行异常检测。
基于第2种范式的方法将基于深度学习的特征工程和异常性评估相结合,获得样本的正常性相关特征表示。不同于上一类方法,此类方法在进行特征提取时往往考虑到一些符合异常检测问题背景的数据约束,从而使生成特征可从异常检测的角度加以解释。这其中较有代表性的是使用自动编码器的方法,这类方法通过自动编码器及其变形学习数据的低维特征,通过该特征可以对训练数据(即正常点数据)进行良好重构。复制神经网络[11]是第1 个使用基于自动编码器的数据重构进行异常检测的网络,通过在中间层施加离散性约束,将数据分入数个不同的组,从而能够检测异常簇(Clustered Anomalies)。鉴于生成对抗网络(Generative Adversarial Network,GAN)在多个应用领域展现出良好性能,一些研究人员试图以生成-对抗的范式构建异常检测方法。基于生成对抗网络的方法一般假定生成网络G的特征空间生成正常样本的能力强于生成异常样本的能力,因而特征空间可以较好地捕捉到训练数据中的正常性样本。AnoGAN 方法[12]对于任意给定的数据样本x,都能够在其特征空间中映射出特征z,并使根据z生成的样本G(z)与原始样本x尽可能相似。通过在正常样本训练数据上训练AnoGAN,异常样本被生成高度相似样本的概率将低于正常样本。SABOKROU 等[13]以一自动编码器和一辨别器构建模型,并用标准的生成对抗机制训练自动编码器,使其尽可能好地重构合群点。
基于第3 种范式的方法直接以端到端的模式为异常检测任务学习异常分数。这类方法并不依赖已有的度量手段进行异常性评估,而是直接构建神经网络模块以生成异常分数。通过学习给定的异常性得分序列,排序模型可以对样本点按异常性进行排序。PANG 等[14]提出一深度序数回归模型(Deep Ordinal Regression Model)以直接优化无监督视频异常检测的异常分数。Softmax 似然模型(Softmax Likelihood Model)通过定义一个基于异常分数的数据分布,最大化训练数据在该分布下的似然来学习异常分数。由于异常样本和正常样本分别代表稀有样本和频繁样本,因此,从概率角度看,正常样本应以较高概率出现,异常样本则反之。CHEN 等[15]设计了一种带有参数的异常打分函数,并通过该函数对数据分布进行建模,利用训练数据对该分布的参数进行噪声对比估计(Noise Contrastive Estimation,NCE)[16]后,即获得优化好的异常打分函数。ZHAI等[17]提出一种基于能量的神经网络进行异常检测,该方法的要点在于使用能量而非重构误差(Reconstruction Error,RE)作为异常分数,从而提供了一种新的度量异常性方法。
为更直观地说明本文工作对现有相关研究的改进,在图1 中可视化地展示了流行深度异常检测方法中的问题和本文方法的对应解决方案。图1(a)中的圆弧线是异常检测方法对正常/异常样本的分界,图1(b)中的圆弧线是本文方法对各数据类的分界。图1(a)中①所示方法只利用正样本数据训练,导致遗漏部分无标签合群点。图1(a)中②所示方法很难确定最优异常分数阈值。图1(a)中③所示方法对等地处理合群点和离群点,对离群点的描述能力较差。作为对比,本文方法充分利用无标签合群点提高泛化性能,综合比较样本对各类的归属度而非使用阈值,为离群点构造容量更高的模型。

图1 流行方法存在的问题和本文的解决方案Fig.1 Problems of popular methods and solutions in this paper
2 本文模型与方法
本节详细描述了本文所提方法的工作原理,包括模型结构、优化目标、训练策略和推断流程。
2.1 问题描述
为便于讨论,定义目标任务如下:给定数据集X=Xpos∪Xun,其中:子集Xpos中的数据均为标注数据,且均为具有标签l的数据(即合群点);子集Xun中的数据为未标注数据,尚待确认其标签。本文所讨论的异常检测任务是指确定Xun中数据的标签是l(即合群点)还是非l(即离群点)。
2.2 模型结构
如图2 所示,本文模型包含编码器E、多通道解码器D和两阶段通道选择器S共3 个模块。使用编码器E抽取输入样本的低维特征,多通道解码器D的各通道互相竞争,试图对编码器E抽取的特征h进行重构。根据合群点和离群点的生成机制和数据分布不同,将通道类型分为2 种,其中,合群点通道指的是指定其中一个通道重构合群点,离群点通道指的是指定其他通道重构离群点。两阶段通道选择器S以两阶段的方式将每一个样本点与其最适合的通道匹配。在第1 阶段,利用注意力选择器在所有离群点通道中选择一个最佳离群点通道来匹配样本点;在第2 阶段,构造竞争性选择器从合群点通道和最佳离群点通道中选择一个通道作为目标通道以完成样本点的最终匹配。
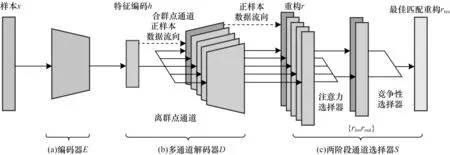
图2 本文模型结构Fig.2 Structure of model in this paper
在训练阶段,由于正样本训练数据都拥有已知的标签,因此直接将其送入合群点通道,无标记数据则被送入选择器S为其选择的通道中。选择器S持续更新其匹配结果,致力于得到样本-通道的最优匹配方案。模型得到充分训练后,在推断阶段,无标签样本的标记由样本被选择器S匹配的目标通道的异常属性决定,也就是说,如果目标通道为合群点通道,就判定该样本点的标签为l(即合群点),反之,则判定标签为非l(即离群点)。
2.3 编码-重构模块
在异常检测领域,自动编码器[18]的有效性已被广泛验证。具体来说,自动编码器可以从正样本数据中学习到和合群点高度相关的低维特征,从而更好地对合群点进行建模,相对地,对未见的离群点则给出较大的重构误差。由于数据集X包含多种类型的样本点,如已知目标类中产生的合群点、未见新类中产生的新颖点、无意义噪声等,因此较为合理的想法是构造多个自动编码器对不同类型的样本分别建模,然而多个自动编码器会大幅增加网络参数量,并增加过拟合的风险。因此,本文提出一种较为平衡的方式,即使用一个单通道编码器和一个多通道解码器来构建编码-重构模块。其中,编码器的形式如下:
多解码器的初步解码过程如式(2)所示:
然后,将k个解码器的结果输入到通道选择器中,并输出最后的结果,如式(3)所示:
其中:E和D分别表示编码器和多通道解码器;x∈X;h是样本x经编码器压缩编码提取的低维特征;r是特征h经多通道解码器重构的结果,其分量与x具有相同的尺寸。假设解码器的通道数为k,ri,i=1,2,…,k表示第i个通道的重构结果。注意,h的尺寸必须小于x以保证编码器E和多通道解码器D可以学习到与数据集X相关的信息,而非简单地执行无意义的恒等映射。在实现时,编码器和解码器的具体形式取决于数据的模态和形式。例如:对于固定维度的多维数据,可以采用多层感知机作为编码器和解码器;对于图像数据,则可以使用卷积神经网络。
通过构建重构模块,本文模型具备了对数据集中多个不同类型的数据分布同时进行建模的能力,并且每个数据类都通过多通道解码器的一个通道进行重构,在增加分布建模能力的同时,有效降低参数量,缓解过拟合的风险。
为此,本文需要将每个数据样本都准确高效地分配至其最适合的通道。本文模型使用两阶段通道选择器完成这一目标。选择器的两阶段结构设计使该模型消除了使用单阶段选择器所造成的诸多问题。
2.4 两阶段通道选择器
在异常检测场景中,合群点和离群点通常在数据分布上有所区别。一般而言,合群点倾向于以高度集中的方式分布,离群点则更多地表现为由多个单分布(或者说类)组成的混合分布。为适应这种数据环境,指定多通道解码器中的合群点通道来重构合群点,使用其他离群点通道来重构不同类的离群点。通过将各样本送入合适的通道,增强重构能力,并达到比单通道解码器更小的重构误差。
通道选择器以一种两阶段的方式将样本与通道进行匹配。对于每个样本,首先,选出与其最佳匹配的离群点通道,再将该离群点通道与合群点通道进行比较,选择出目标通道。在第1 阶段,使用注意力机制进行匹配操作。在第2 阶段,使用竞争性机制比较最佳离群点通道与合群点通道的重构结果。这种结构设计可以避免误导性的局部极值点,并直接利用引入的监督信息对选择结果进行修正。
2.4.1 第1 阶段的注意力选择器
在第1 阶段,模型的目标是为样本点选择最佳匹配的离群点通道。为此,引入注意力机制[19]实现该目标。注意力机制在自然语言处理领域被广泛使用,其能迫使模型关注更有价值的信息。因此,本模型使用注意力机制使模型在所有离群点通道中更关注与给定样本匹配的最佳离群点通道,使其更好地重构样本。将注意力选择器的输出rout作为第1 阶段的选择结果,其表达式如式(4)所示:
其中:ri(i=1,2,…,k-1)是第i个离群点通道的重构结果;α是注意力权重的向量。特别地,多通道解码器的第k个通道被指定为合群点通道。通过正则化技巧,每个样本的注意力权重都被尽量约束在向量的某一元素上,也就是说,向量α只有一个元素近似为1,其他元素值都趋于0。这就保证了式(2)的加权求和操作近似地等价于选择。注意力权重向量α的值通过对各解码器通道的重构结果(r1,r2,…,rk-1)进行评分并将分数标准化得到,其表达式如下:
其中:v、W、V和b是模型的训练参数。值得注意的是,可以选择其他形式的注意力机制来处理r以得到选择结果rout。通过第1 阶段的注意力选择器选择出了样本的最佳离群点通道,但仍须在合群点通道和最佳离群点通道中选择其中之一作为最终的目标通道。
2.4.2 第2 阶段的竞争性选择器
在该阶段,选择器使第1 阶段的选择结果rout与合群点通道产生的重构rin互相竞争。注意到第k个通道被指定为合群点通道,等式rin=rk成立。考虑到重构的目标是使重构结果尽可能地接近输入数据,提出使用一种直接的竞争策略,即比较两个通道的重构误差,并选择较小的作为竞争胜利一方进行输出,从而得到最终结果rres,其表达式如式(7)所示:
其中:函数RE(x,rc)度量了通道的重构结果rc与样本x之间的重构误差。对于相似性度量,选择闵可夫斯基距离(Minkowski Distance),即p-范数,作为重构误差,函数RE(x,rc)的表达式如下:
其中:p是范数的秩。
通过第2 阶段的竞争性选择器,模型最终为每个样本分配了一个目标通道。下面介绍模型的训练方式以及如何通过模型来确定Xun中各元素是否为合群点。
2.5 模型训练和推断
注意到正样本数据Xpos和无标记数据Xun具有不同的标记可用性,本文模型设计了一个新的策略以在训练阶段处理它们。对于正样本数据Xpos,由于其标记已知,因此直接将其送入合群点通道;对于无标记数据Xun,使其流入由两阶段通道选择器S选择的目标通道中。因此,训练的目标损失函数定义为X中所有数据的平均重构误差,其形式如式(9)所示:
在训练阶段,两阶段通道选择器S持续更新其匹配结果,从而将样本分配至更适当的通道。本模型使用正则化技巧以确保注意力权重尽可能集中于某一特定元素上,从而使加权求和近似地等价于选择某一特定通道。为实现该目标,采用L1 范数约束注意力权重α,其过程如式(10)所示:
综上所述,总损失函数可记为:
其中:λ是正则项的权重。通过最小化上述损失函数来充分训练模型,就可以对无标记数据集Xun中数据是否为正常样本进行评估。定义指示函数IXcorr:Xun→{0,1},并判定Xcorr⊆Xun中包含的样本信息具有标签l:
算法1 详细描述了本文方法及模型的整体工作流程(源码:https://gitee.com/fujisato_FDU/an-anomalydetection-method-based-on-multi-decoder-and-two-stagechannel-selection)。
算法1本文方法及模型的工作流程
3 实验结果与分析
本节全面评估本文方法在进行异常检测任务时的性能,通过在4 个流行数据集上进行实验,证明本文方法相比于其他机器学习或深度学习方法的优越性。此外,还设计了消融实验来证实本文方法所采用的模块和策略的有效性。
3.1 数据集
本文实验采用MNIST[20]、USPS[21]、Fashion-MNIST[22]、CIFAR-10[23]等4 个图像数据集,具体如下。
1)MNIST 是经典的手写数字数据集,包含从0~9共10 个类,共70 000 张图像,其中每张图像为28×28 大小的单个手写数字灰度图。对于每个数字类,其包含的图像为7 000 张。其训练集包含60 000 张图像,测试集包含10 000 张图像。
2)USPS 是美国邮政署提供的手写数字数据集,其规模比MNIST 小,包含0~9 共10 个类,约10 000 张图像,其中每张图像为16×16 大小的单个手写数字灰度图。其训练图像为7 291 张,测试图像为2 007 张。
3)Fashion-MNIST 数据集采用与MNIST 完全相同的配置,但其中包含的图像为服装类物品而非手写数字。数据集包含的类别数、图像总数、各类别图像数、图像属性训练与测试图像数等均与MNIST 数据集保持一致。
4)CIFAR-10 为自然场景物体数据集,包含10 个类,共60 000 张图像,其中每张图像的尺寸为32×32×3 的三通道RGB 彩色图。每个类包含6 000 张图像。其训练集包含50 000 张图像,测试集包含10 000 张图像,在各类之间均匀分布。
图3 为各数据集的样例。

图3 实验中所使用的4 个数据集样例Fig.3 Samples from four datasets used in the experiments
3.2 传统方法介绍
使用基于传统机器学习和深度学习的异常检测方法与本文方法进行对比,其中具有代表性的方法如下。
1)Robust Covariance 方法假定合群点的数据符合高斯分布,并试图在数据空间中学习超曲面以包含他们。因而,当合群点数据的实际分布并非单峰高斯分布时,其方法性能会发生退化,但该方法对训练数据中混入的异常点具有一定的健壮性。
2)One-Class SVM 方法是支持向量机方法在异常检测场景下的推广。该方法试图在高维特征空间中学习超平面,该超平面将所有合群点分至其一侧并与原点保持最远可能距离。
3)Isolation Forest方法是随机森林(Random Forest,RF)方法在异常检测场景下的推广。该方法迭代地将数据空间划分为只包含一个样本点的最小子空间,并将在早期就被分离出来的样本点视为异常点。
4)ARAE[24]方法是基于自动编码器的异常检测方法,以正样本数据为训练数据学习数据相关的低维瓶颈特征,并通过该特征重构输入数据。对于合群点,由于正样本训练数据已经良好地反映了其性质,自动编码器可以给出较为准确的重构,对于离群点则会产生较大的重构误差。此外,通过抑制自动编码器对离群点的重构能力,加大了合群点和离群点重构误差之间的数值差距。最终,以重构误差度量样本点的异常性。
5)DSVDD[25]方法受支持向量机方法的启发,在数据空间中寻找一可以包含所有正样本训练数据的最小超球体,并将分布在该超球体球面内部的点判定为合群点,将外部的点判定为离群点。
6)GT[26]方法是基于几何变换的异常检测方法。该方法通过训练多分类模型,使其尽可能地区分正样本训练数据及其各种不同的几何变换结果,并使用该模型的输出对样本的异常性进行评估。
3.3 实验配置
实验均在配有4 张Nvidia GeForce RTXTM3090图形卡的Linux 服务器上进行,操作系统为Ubuntu 18.04 LTS。使用的深度学习框架为PyTorch 1.9.0 的GPU 版本。Python 版本为3.8.0。
对于性能比较实验,为与其他文献保持一致,采用了深度异常检测领域常用的一对多数据配置,即对于每个数据集的每个类,把该类的训练集作为正样本数据,并在所有类的测试集中随机抽取一定比例的样本作为无标记数据。本文方法和所有对比方法的抽样比例均为0.3。对于消融实验,数据配置与性能比较实验相同,但抽样比例设为0.5,在MNIST数据集上进行实验,并取各类的平均结果作为实验结果。CIFAR-10 数据集的数据使用了ImageNet 数据集上预训练过的VGG-16 网络,将最后一层的1 000 维特征作为本文模型的输入。其他数据集直接以原始数据作为输入。
编码器和解码器均使用多层感知机,层数为2,编码器各层输出维度分别为64 和32,且解码器使用了编码器的镜像结构。激活函数采用ReLU,相似度度量的范数p设为2,正则化项权重λ设为0.15,在批抽样时每批的数量(Batch Size)取64。在性能比较实验中多通道编码器的通道数取固定值9。消融实验则根据后文所描述的具体配置确定通道数。
3.4 性能比较
3.4.1 传统异常检测方法
虽然基于深度神经网络的方法已在大量应用领域中占据主导地位,但在异常检测领域中,一些经典的机器学习方法仍然保持着不弱于深度学习方法的性能。先将本文方法与这些机器学习方法进行对比。为了保证实验的全面性,选用Robust Covariance、One-Class SVM、Isolation Forest和Local Outlier Factor这4 种基于机器学习的异常检测方法进行对比实验,这4 种方法覆盖了异常检测方法领域主要使用的3 种策略。使用被广泛接受的异常检测性能指标——F1-分数(F1-Score)和接受者操作特征曲线下面积(Area Under the Receiver Operating Characteristic Curve,AUROC)来评估各方法的性能。如图4 所示,在大多数情况下,本文方法都能取得较好的结果,仅在极少数情况下,某个机器学习方法的性能能够接近本文方法,但不能显著超越。值得注意的是,这些机器学习方法的超参数都需要进行重复微调才能使其性能达到可能的最高值,而本文方法则无须进行微调就能获得较好的性能。
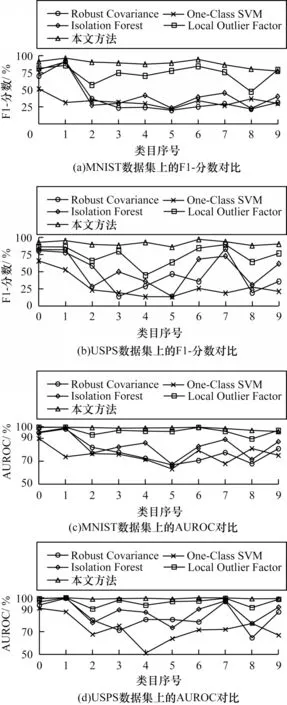
图4 机器学习方法在两个数据集各个类上的异常检测性能对比Fig.4 Machine learning method performance comparison for anomaly detection on various categories of two datasets
3.4.2 深度异常检测方法
将本文方法与一系列具有代表性的深度异常检测方法进行比较,并采用AUROC 作为评价指标。实验配置与该领域主流工作中采取的配置保持一致。表1~表3 为本文方法与几种主要的深度异常检测方法的性能对比。每个数据集的最优实验结果用粗体表示,次优则用下划线表示。实验结果显示,本文方法的性能在大多数情况下都能超过其他对比方法,且本文方法在达到上述性能的同时,仍可保持较高的计算效率,所需时间开销较小,几乎不需要进行超参数筛选和微调。对于数据集的类间平均结果,本文方法在数据集Fashion-MNIST 和CIFAR-10 上均达到最优,在MNIST 数据集上则与表现最好的U-Std 方法仅保持着极微弱的差距。U-Std 方法必须进行数种费时操作才能达到上述最优结果,而本文方法在减少计算和人工开销的同时仍保持几乎一致的性能。综上所述,本文方法总体上优于现有的深度异常检测方法。

表1 不同方法在MNIST 数据集各个类上的AUROC 指标对比Table 1 Comparison of AUROC indicators of different methods in various categories of MNIST dataset %
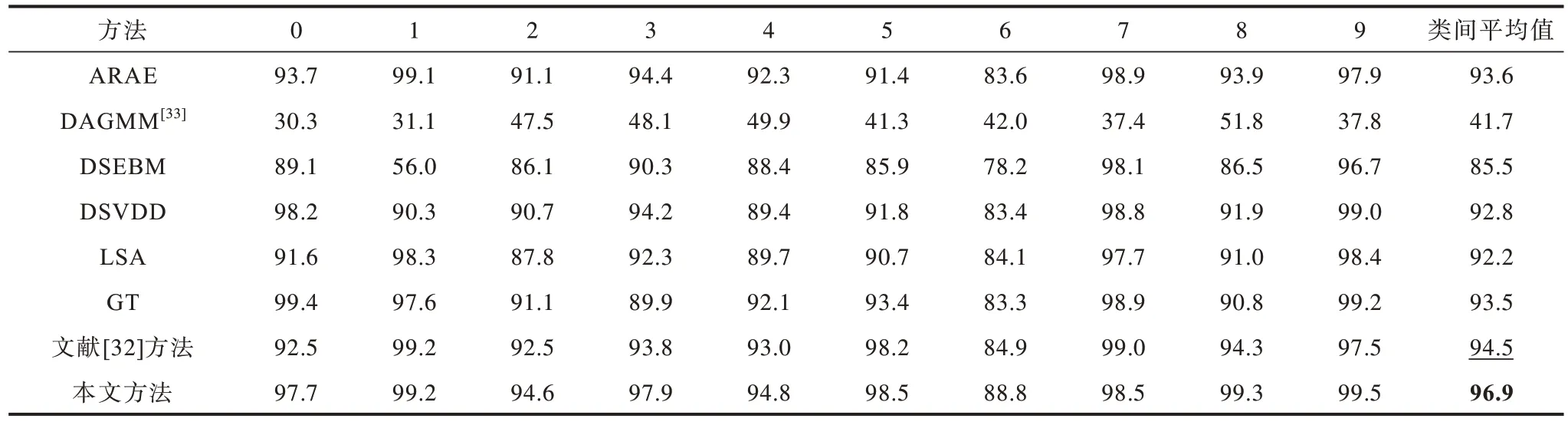
表2 不同方法在Fashion-MNIST 数据集各个类上的AUROC 指标对比Table 2 Comparison of AUROC indicators of different methods in various categories of Fashion-MNIST dataset %

表3 不同方法在CIFAR-10 数据集各个类上的AUROC 指标对比Table 3 Comparison of AUROC indicators of different methods in various categories of CIFAR-10 dataset %
由于只有U-Std 方法在MNIST 数据集上达到了与本文方法几乎可比的性能,因此分析本文方法的效率优于U-Std 方法的原因,主要有如下3 点:
1)U-Std,即Uninformed Students,需要在大规模自然图像数据集上预训练一个描述性的教师网络T,以获得学生网络的回归目标值。这一预训练过程相当耗时,而本文方法不需要此种预训练。
2)U-Std 方法需分别训练大量与教师网络T具有相同网络结构的学生网络,然而本文方法只需要一次性训练一个端到端的注意力多通道自动编码器。
3)U-Std 方法需要在一个包含无异常图像的验证集上实施对数据集依赖的微调。这一微调操作需要一定的计算开销,但本文方法无须该操作。
本文对其他对比方法也进行了上述分析,在表4中展示了影响各方法时间效率的主要因素,其中“—”表示未使用,“√”表示使用。

表4 影响不同方法时间效率的主要因素Table 4 Main influential factors on the time efficiency of different methods
3.5 消融实验
为验证本文方法采用的各模块和策略的有效性,本节通过移除模型中部分模块或取消部分策略进行消融实验,并观察性能下降与否。
3.5.1 第1 阶段的注意力选择器
相较于本文方法的两阶段结构设计,一种更直接的做法是去掉注意力选择器,此时通道选择过程变为先比较样本在各通道的重构误差,再将样本直接送入具有最低重构误差的通道。表5 展示了以上述方式(记为Naive)进行异常检测的结果。直观地说,较低的重构误差与较高的匹配可能性具有强相关性,这一朴素的策略应当是有效的。然而,表5 的结果说明这一简单比较重构误差的方法会导致模型性能的弱化。

表5 注意力选择器的消融实验结果Table 5 Ablation experiment results of attentive selector %
本文注意到在训练阶段简单地对重构误差进行比较实际上是一种贪心策略(Greedy Strategy),其总是在当时状况下选择局部最优的结果。对本文方法而言,在每次分配样本时,总是将样本送入当时状况下其重构误差最小的通道中。由于局部最优点和全局最优点之间存在不一致性,该策略将受到局部极值点的误导。也就是说,在训练阶段,某时刻重构误差最小的通道并不一定是实际上的最佳匹配通道。
图5 给出了与此相关的几个示例,对于每一个样本,左数第1幅图给出了其真实图像和标记,左数第2幅图展示了特征更接近真实图像的重构,但其重构误差(Reconstruction Error,RE)大于左数第3 幅图的重构。通常来说,贪心策略将选择第3 列的重构。对于有些通道,他们即便不是某样本在某时刻的局部最优,也学习到了该样本最有意义的重构。因此,朴素地比较重构误差可能会将样本送入错误的通道,削弱重构模块对目标数据的建模能力,一种更好的办法是使用注意力机制捕获样本和通道之间更深层的潜在关联关系。实验结果证明注意力选择器的引入可提高方法的性能。

图5 全局最优重构和局部最优重构示意图Fig.5 Schematic diagram of global optimum and local optimum
3.5.2 第2 阶段的竞争性选择器
如果将竞争性选择器移除,则模型变为一个纯粹的、单阶段的注意力选择器,也就是说,样本的去向直接取决于单一注意力选择器的选择结果。表6 展示了以上述方式(记为ATT)进行异常检测的结果。由表6可知,使用该策略会在一定程度上降低本文方法的性能。其原因在于,经过充分训练以后,竞争性选择器比注意力选择器更直接地利用合群点通道中学习到的监督信息,可以有效地对注意力选择器生成的匹配结果进行矫正,提高模型的最终表现。
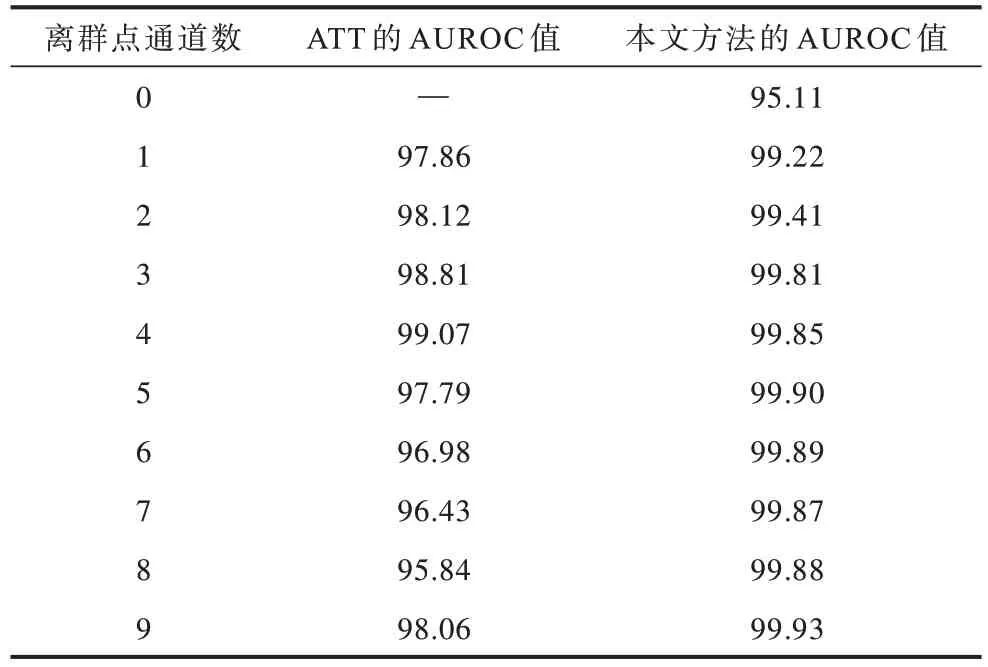
表6 竞争性选择器的消融实验结果Table 6 Ablation experiment results of competitive selector %
3.5.3 编码-重构模块
移除编码-重构模块意味着直接构造一个选择器,将数据样本分入各个类中,并且不是使用自动编码器的通道对样本进行重构,而是通过对目标数据聚类来实现。本文将3种聚类算法K-means、Spectral和BIRCH分别与本文方法进行比较,结果如表7 所示。可以看出,聚类算法在异常检测任务上的结果均低于本文方法。这说明,将常用于异常检测领域的自动编码器重构模块与针对异常检测任务设计的选择器相结合,其算法性能将超过其他单独执行选择操作的算法。
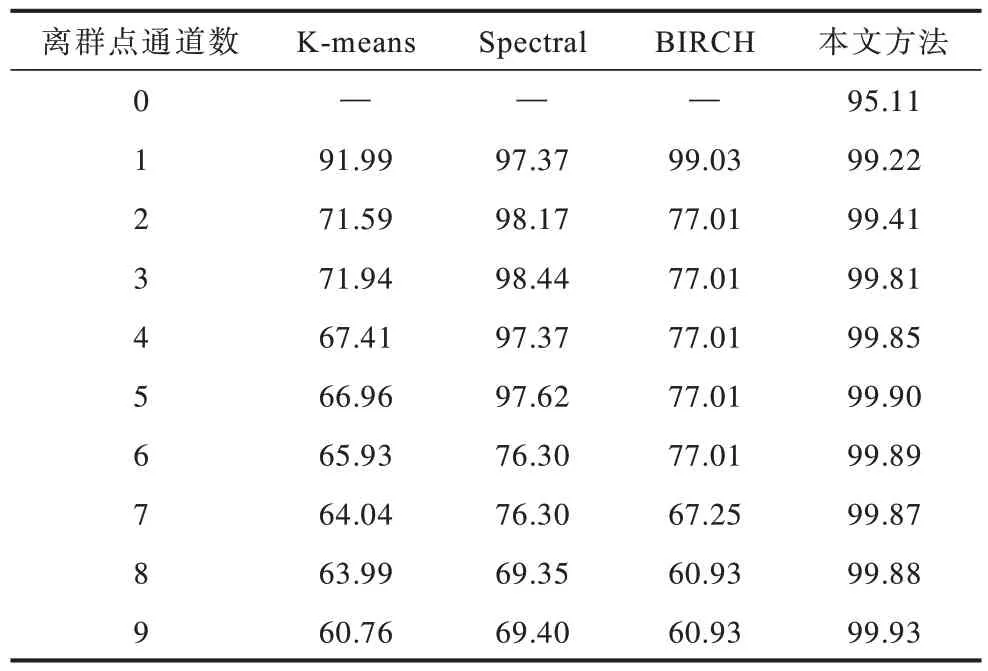
表7 编码-重构模块的消融实验结果(AUROC 值)Table 7 Ablation experiment results of decoding module(AUROC value)%
3.5.4 正样本数据增强
本文希望找到潜藏在无标记数据中的合群点,并在训练时将其补充到正样本数据集中,从而达到控制过拟合的效果。可以推测,如果取消这一策略,也就是将这部分合群点从训练数据集中移除,将会降低本文模型的性能。由表8 可知,随着参与训练的无标记数据中合群点数量的减少,本文模型的性能会逐步下降,这说明使用无标记数据中的合群点确实能增强训练数据,抑制过拟合问题,提升本文模型的性能。

表8 合群点利用率对本文模型性能的影响Table 8 Influence of the utilization of Inliers on the performance of model in this paper
3.5.5 离群点建模
如果移除本文方法中的离群点通道,将会取消对离群点建模,使模型退化为一个自动编码器,这一变化将迫使模型必须使用一个经验性的阈值来分离合群点和离群点。这里,采用训练数据平均重构误差与3 倍标准差的和作为截断阈值。
图6 中k=0 的点展示了以上述方式进行异常检测的结果。可以看到,取消离群点建模对模型性能产生了很大影响。这是因为模型无法对离群点建模,在进行异常检测时只能经验性地推断合群点的边界并确定阈值,而不是通过比较样本对正常类和异常类的归属度来判别其异常性。此时,大量可用的无标记数据中的信息被浪费,导致性能下降。
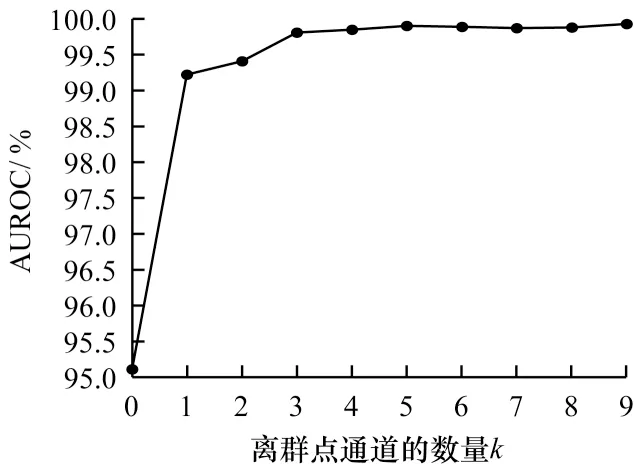
图6 离群点通道数量对本文模型性能的影响Fig.6 Influence of the number of Outlier channels on the performance of model in this paper
3.5.6 不对称建模
通过改变多通道解码器中离群点通道的数量(即图6 中的横坐标k)以调整模型的对称度。当离群点通道数设置为1 时,模型对合群点和离群点进行完全对称的建模;当离群点通道数设置为0 时,不为离群点分配任何通道,没有了离群点建模过程,模型退化为一个自动编码器(即上一小节的情况)。随着离群点通道数量的增加,模型的不对称性逐渐增加。考虑到计算资源有限,将离群点通道的数量控制在0~9 的合理范围内进行实验。
图6 的实验结果显示,尽管模型的性能表现和离群点通道的数量并非严格满足单调性,但总体上仍呈现正相关性。对于模型性能和离群点通道数量关系的非严格单调性可做如下解释:如先前研究[36]所报道的,随着备选特征数量的增长,模型的参数规模也随之增加,这将导致模型要在更大的参数空间中搜索最优点,也会更容易陷入局部极值点,从而使注意力机制变得难以优化。同时,分配至每一个离群点通道的训练数据量也会缩减,这进一步影响了模型性能。这一事实说明,尽管在理想情况下目标数据中的每一类都应该被分配一个单独的通道进行建模,但在实际应用时必须考虑到平衡模型容量和全局最优点可达性,即通过提高模型找到全局最优点的概率,从而提高模型性能,需要损失模型对目标数据分布的拟合能力。
3.6 大规模数据实验
在较大数据集上进行实验以检验本文方法在大规模数据下的性能表现。具体地,分别将MNIST 数据集和Fashion-MNIST 数据集通过叠加、水平翻转、直角旋转等8 种方式进行数据增强后,取其中一个数据集的所有训练数据为正样本数据,取两个数据集的所有测试数据为无标记数据。通过该方式,将实验使用的数据规模从9 000个样本提高到640 000个样本。表9 所示为在不同比例数据r下分别取两个数据集做正样本数据的实验结果。其中,当r取0.05时使用32 000个样本,当r取1时使用640 000个样本,以此类推。表9 的实验结果显示,本文方法在数据量大幅增长时依然可以保持原有的性能水平,显示出一定的健壮性。

表9 数据量对本文模型AUROC 值的影响Table 9 Influence of data amount on AUROC value of model in this paper %
4 结束语
针对当前深度异常检测方法中存在浪费无标记数据、只度量正常类样本、对等处理不同类型样本等问题,本文提出一种基于多解码器与两阶段通道选择的异常检测方法。该方法的模型由一个编码器、一个多通道解码器(即多解码器)和一个两阶段通道选择器组成,其中,通道选择器能够将每个数据样本与其最适合的通道进行匹配。在模型训练阶段:正类样本训练数据被直接送入指定的合群点通道,使该通道能充分学习合群点的模式;无标记数据则流入由选择器所决定的通道中。此外,通道选择器以一种两阶段的方式为样本分配通道,在模型得到充分训练后,各无标记数据样本的标签(即异常与否)由其被最终分配进入的目标通道属性来确定。实验结果表明,该方法具有优越的性能,所采用的各模块和策略均具备有效性。下一步将引入小样本的有标记离群点信息,以训练和引导异常检测中采用的注意力机制,从而增强学习离群点模式的学习能力。
猜你喜欢
中学政史地(2022年31期)2023-01-05
科学与财富(2019年19期)2019-12-11
中学生博览(2019年10期)2019-04-28
小型微型计算机系统(2018年8期)2018-09-07
数码世界(2018年5期)2018-06-04
下一代英才(酷炫少年)(2017年4期)2018-01-03
电脑与电信(2017年6期)2017-08-08
小学生学习指导(低年级)(2016年3期)2016-11-11
中国房地产业(2016年9期)2016-03-01
大学物理实验(2015年2期)2015-10-22
