
基于上下文注意力的室外点云语义分割方法
2023-03-16 10:21苏鸣方胡立坤黄润辉
计算机工程 2023年3期
苏鸣方,胡立坤,黄润辉
(广西大学 电气工程学院,南宁 530004)
0 概述
3D 点云语义分割作为3D 环境感知的基础问题,为点云场景下的每个点分配语义标签,被广泛应用于自主移动机器人、增强现实、自动驾驶等领域。传统人工设计特征的点云分割方法难以满足复杂场景下室外点云数据的处理需求。随着计算机性能的提升和神经网络技术的发展,传统分割方法逐渐被以数据驱动的深度学习方法取代。
点云非栅格结构具有稀疏性、无序性等特点,其处理方式是多样的。根据点云处理方式的不同,基于深度学习的点云语义分割方法可分为基于投影、基于体素和基于直接点的方法。基于投影的点云语义分割方法[1-2]将点云转换为图像,利用成熟的图像语义分割方法进行分割后重映射到点云空间,降低了3D 点云处理的复杂度。基于体素的点云语义分割方法[3-5]将点云转化为体素,利用3D 卷积进行分割,保留了点云的3D 几何结构。上述两类方法能够有效解决点云非结构化的问题,但在转换过程中造成点云结构信息的损失。为直接处理点云获取的原始高分辨率特征,PointNet[6]直接利用共享感知机捕获逐点特征,通过最大池化获取全局特征,然而,该方法缺乏对局部细节的描述。为捕获局部特征的依赖关系,研究人员设计不同的局部特征提取模块以捕获局部依赖关系。PointNet++[7]采用分层扩大感受野聚合局部特征。KPConv[8]设计一种刚性和可变形的类网格卷积算子,通过内核点权重卷积聚合球形邻域特征。文献[9]引入循环神经网络(Recurrent Neural Network,RNN)对上下文信息进行编码。文献[10]设计多尺度特征融合模块扩大局部感受野。文献[11]将分组注意力变换与多层感知机(Multi-Layer Perceptron,MLP)共同作用于局部特征的提取,提高点云分类分割的准确率。文献[12]设计通道注意力和空间注意力机制,基于自适应集成的局部和全局依赖关系关注不显著的对象特征。文献[13]设计尺度和通道注意力选择单元,结合语义和尺度上下文信息,通过特征金字塔进行分割。由于以上方法主要局限于复杂的网络结构,且难以一次性处理大量点云,因此只适用于小规模的室内场景,无法直接扩展到大规模的室外点云分割领域。
针对大规模室外场景,SPG[14]将点云均匀分割后建立超点图,利用图卷积网络提取超点图中的上下文信息,但分割效率较低,只适用于离线点云分析。RandLA-Net[15]通过随机点采样(Random Sampling,RS)能解决主流最远点采样方法处理大规模点云时计算成本昂贵的问题,并设计局部特征聚合(Local Feature Aggregation,LFA)模块,以弥补随机点采样时关键点信息的丢失,但缺乏对多尺度上下文信息的利用。文献[16]在RandLA-Net 的基础上结合不同尺度上下文信息,并利用图卷积网络处理全局特征,然而未对浅层特征信息进行筛选。以上方法未对不同特征通道和点分配不同的注意力权重,缺乏对浅层细粒度信息的捕获。
本文提出一种基于上下文注意力的点云语义分割方法CAF-Net,在不同尺度间的上下文信息中选择性地聚合局部和全局特征,主要包括双向上下文注意力融合(Bidirectional Contextual Attention Fusion,BCAF)和上下文编码-通道自注意力(Contextual Encoding-Channel Self-Attention,CE-CSA)两个模块。BCAF 模块分别结合浅层特征和高层语义特征生成注意力权重,逐层融合邻近尺度特征的上下文信息,CE-CSA 模块基于多尺度特征编码全局信息,采用通道自注意力机制建立全局特征通道的相互依赖关系,避免了特征的冗余,同时提高点云语义分割精度。
1 本文方法
1.1 网络结构
本文提出基于上下文注意力的点云语义分割网络CAF-Net,其网络结构如图1 所示。
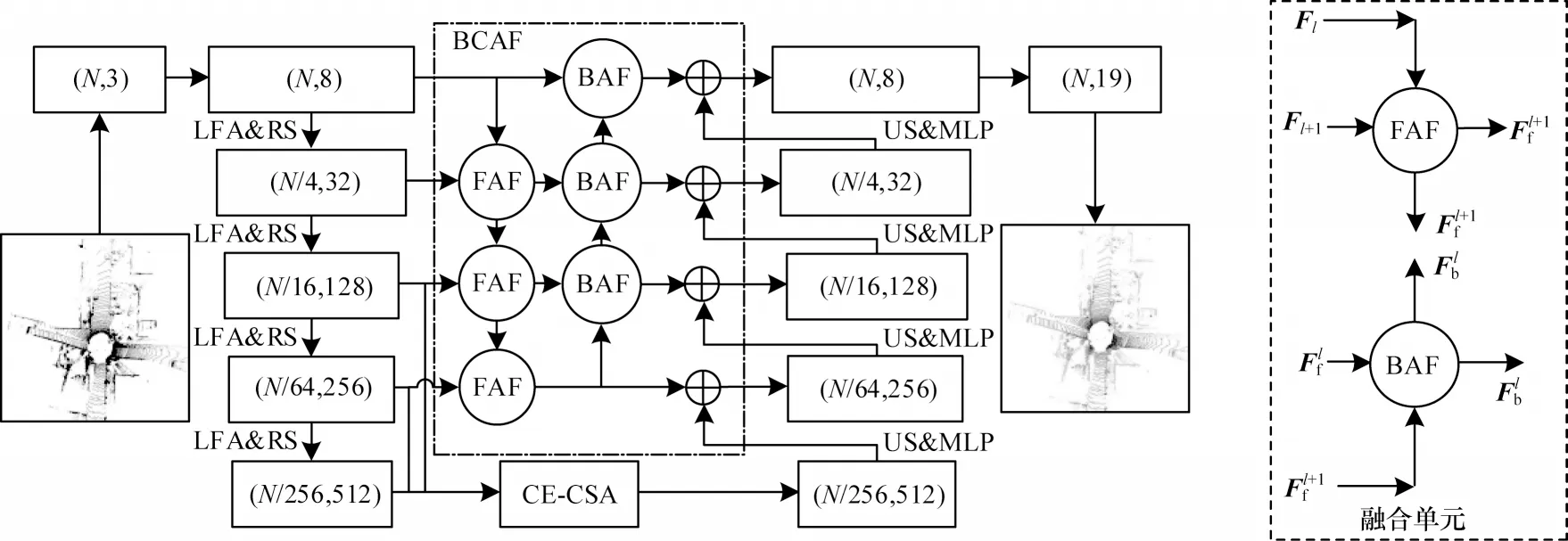
图1 CAF-Net 网络结构Fig.1 Structure of CAF-Net network
本文方法以RandLA-Net 为主干网络,主要采用编码-解码结构。其中,编码器通过随机点采样减小点的规模,以实现分层聚合局部特征的目的。为弥补随机点采样造成数据点信息丢失的不足,本文通过局部特征聚合[15]模块编码数据点与对应邻近点的空间特征。解码器利用最近邻插值(Nearest Interpolation,NI)上采样方法和MLP 逐步恢复原始分辨率的点云特征,并融合低层特征与高层特征,以改善模型效果。然而,RandLA-Net 网络未利用多尺度特征间的上下文信息对底层信息进行筛选,只是在解码过程中简单地将编码特征与上采样特征相结合,容易造成浅层噪声信息对高层语义信息的干扰,从而影响语义分割结果。
双向上下文注意力融合模块基于邻近浅层特征,通过前向注意力融合(Forward Attention Fusion,FAF)组件生成注意力权重,逐层融合相邻尺度特征,并将融合后的特征传入到下一个融合单元,反向注意力融合(BAF)组件进一步依赖高层语义特征进行逐层反向融合,最终有效地融合多尺度特征,融合单元如图1 中虚线框所示。CE-CSA 模块结合不同尺度特征编码全局上下文信息,设计通道自注意力机制学习全局信息,输出特征通过上采样与BCAF模块特征逐层融合,最后利用全连接层(FC)为每个点分配语义标签。
1.2 双向上下文注意力融合模块
由于室外点云范围广且物体尺度复杂多样,因此需要融合多尺度特征以扩大模型的感受野,从而保留更多的局部细粒度信息。为此,本文设计邻近尺度的上下文注意力融合模块,考虑到不同尺度特征间的差异,通过对相邻尺度特征进行注意力权重的设计,有效地融合浅层局部结构信息和高层语义上下文信息。双向上下文注意力融合模块结构如图2所示。
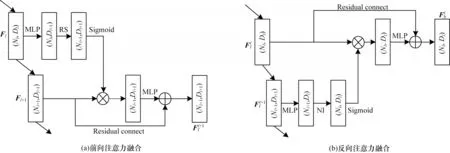
图2 双向上下文注意力融合模块结构Fig.2 Structure of bidirectional contextual attention fusion module
BCAF 模块主要包含FAF 组件和BAF 组件。FAF 组件结构如图2(a)所示,通过随机采样和MLP将浅层特征与相邻高层特征对齐,并通过Sigmoid 函数生成前向注意力权重,定义如式(1)所示:
其中:Fl为第l层的特征,Fl∈RNl×Dl,l∈(1,2,3),Nl和Dl分别为第l层的点数和特征维度;Wf为前向注意力权重;RS(·)为随机采样。
将得到的前向注意力权重与邻近高层特征逐元素相乘,并通过残差连接得到最终前向注意力融合后的特征,如式(2)所示:
其中:⊕为逐元素相加;⊗为逐元素相乘;Ff为前向融合特征。
BAF 组件结构如图2(b)所示,其输入的是前向注意力融合后已经保留了部分浅层细节的特征。反向注意力融合是结合相对高级的语义信息,通过对输入特征进行选择,在捕获浅层细粒度特征的同时,将高层语义信息融入到点的分类任务中,提高语义分割的准确率。反向注意力融合的流程主要是通过最近邻插值和MLP 将高层特征与邻近浅层特征对齐,利用Sigmoid 函数为每个点生成反向注意力权重,并通过残差连接尽可能地保留邻近尺度中的浅层特征,得到反向注意力融合后的特征。具体流程如式(3)所示:
1.3 上下文编码-通道自注意力模块
文献[17-18]通过编码单层特征图构造全局特征描述子,以捕获全局上下文信息,但是缺乏对多尺度特征的利用。为此,本文设计CE-CSA 模块,主要由上下文编码(CE)和通道自注意力(CSA)组件组成。CE 组件基于多尺度特征聚合全局上下文信息,CSA 组件结合全局依赖为通道分配不同权重,增强特定通道的可分辨性。
1.3.1 上下文编码组件
上下文编码组件结构如图3 所示。本文设计以高层特征维度融合为主的前向采样编码(FSE)和以浅层特征为主的反向插值编码(BIE)两种多尺度上下文聚合方式。前向采样编码是基于最高层特征图进行最大池化,得到全局信息特征,再通过维度复制与多尺度特征连接,从而得到全局上下文信息。反向插值编码侧重于低层特征,通过第一层特征图最大池化得到全局特征,并与多尺度特征连接。
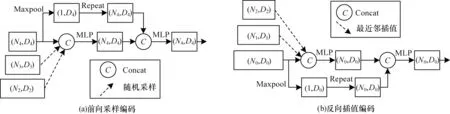
图3 上下文编码组件结构Fig.3 Structure of contexual encoding components
由于FSE 可以有效融合高层语义信息进行编码,在插值过程中BIE 是复制邻近点的特征,缺乏对高层语义信息的利用,因此本文最终选用FSE进行全局上下文编码,并且为减少特征冗余和提高编码效率,选用三个邻近尺度特征图进行融合。
1.3.2 通道自注意力组件
针对点云无序造成数据点相互关系编码的不确定性,自注意力机制对全局特征的建模和数据点相关性的挖掘有良好的效果[19]。但是,自注意力机制只适用于小范围点云,难以直接拓展到大规模点云,其原因为大规模点云的N×N点注意力图会占用大量的计算资源与内存。本文设计通道自注意力组件,其结构如图4 所示。通过生成特征维度为D×D的通道注意力图,使网络关注有意义的通道并避免大量的计算,此外,采用学习多尺度输入特征和自注意力特征之间的偏差取代学习整体自注意力特征,使网络更专注于偏差的学习,从而得到更关键的全局特征。
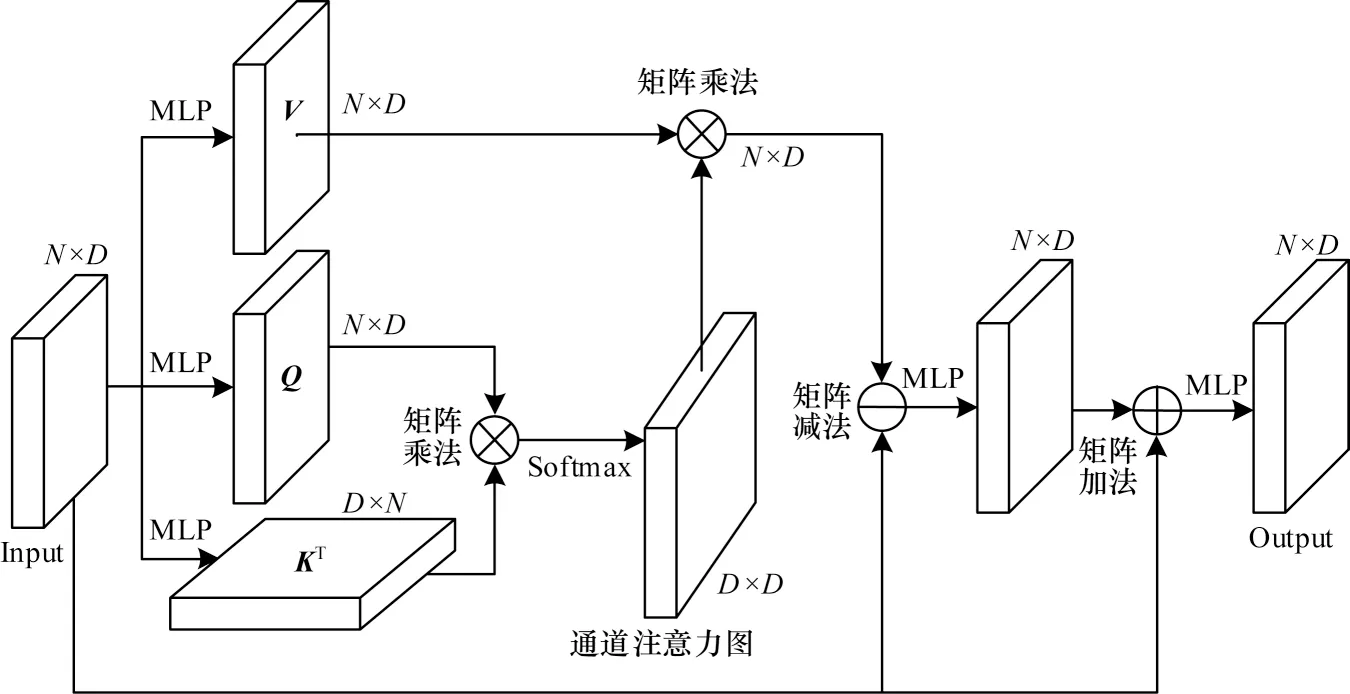
图4 通道自注意力组件结构Fig.4 Structure of channel self-attention component
通道自注意力组件将CE 组件编码后的多尺度全局上下文特征FCE作为输入,经MLP 线性变换得到查询张量Q∈RN×D、关键张量K∈RN×D和值张量V∈RN×D矩阵,如式(4)所示:
其中:Wq∈RD×D、Wk∈RD×D和Wv∈RD×D为对应的权重参数;×为矩阵乘法。
通过关键张量矩阵的转置与查询张量矩阵相乘以获得注意力权重,并进行Softmax 归一化,得到归一化注意力图矩阵FSoftmax,表示如式(5)所示:
值张量矩阵与归一化注意力图矩阵进行矩阵乘法得到通道自注意力特征,学习多尺度输入特征和自注意力特征之间的偏移量,最终得到输出特征FCSA,关注特征之间的语义联系,提高特征的可分辨性。由于维度D远小于点数N,因此矩阵乘法可减少大量内存,具体定义如式(6)所示:
2 实验与结果分析
为验证本文所提方法的有效性,本文在SemanticKITTI 和Semantic3D 大规模室外场景数据集上进行定量对比验证。此外,在SemanticKITTI 数据集上进行不同模块的消融实验以证明模块的有效性,进一步探究BCAF 模块个数对网络性能的影响,并验证前向采样编码组件和通道自注意力组件同时作用的有效性。
2.1 数据集
SemanticKITTI[20]数据集由机载激光扫描系统获得,包含德国卡尔斯鲁厄附近的市内交通、居民区、高速公路场景和乡村道路场景,由22 个点云序列和45.49 亿个点组成,序列00~序列10 用于训练,共23 201 帧,序列11~序列21 用于测试,共20 351 帧。数据集共有28 个类别,官方只评估19 类。原始输入只有3D 坐标和强度,没有颜色信息。
Semantic3D[21]数据集由固定扫描仪获得,包含集市广场、农场、运动场、城堡和市政厅场景,由15 个训练集和15 个测试集组成,共超过40 亿个点,被手动标记为8 个语义类。原始输入包含3D 坐标、强度、RGB 颜色信息。
2.2 实验环境与评价指标
本文提出的网络在64 位Ubuntu18.04 操作系统、Intel®Xeon®CPU E5-2680 v4@2.40 GHz 三核处理器、128 GB 的RAM、GeForce RTX 3090 GPU 服务器上,基于Tensorflow 框架进行训练,批大小设置为6,训练次数设置为100,损失函数选用交叉熵函数,优化器选用Adam 算法,初始学习率设置为0.01,每个迭代次数的学习率衰减5%。
语义分割性能采用总体准确度(OOA)和平均交并 比(mean Intersection over Union,mIoU)进行评估,如式(7)和式(8)所示:
其中:pij表示假阴性;pii表示真阳性;pji表示假阳性;N表示标签类别的数量。
2.3 结果分析
2.3.1 对比实验
本文在SemanticKITTI 和Semantic3D 两个室外点云数据集进行对比实验,并对实验结果进行分析。
1)在SemanticKITTI 数据集上的对比实验
在SemanticKITTI 测试集上不同方法的实验结果如表1 所示。从表1 可以看出:本文提出的CAF-Net 相较于主流基于投影的方法RangeNet53++的mIoU 提高了2.8 个百分点,相较于基础网络RandLA-Net[15]的mIoU 提高了1.1 个百分点,尤其在行人、自行车场景下的IoU 分别提高了3 和6.9 个百分点,其原因为CAF-Net 可以结合上下文注意力机制,有效地挖掘局部细粒度特征,并融合局部与全局多尺度特征。

表1 在SemanticKITTI 测试集上不同方法的实验结果对比Table 1 Experimental results comparison among different methods on SemanticKITTI testset %
在SemanticKITTI 验证集上不同网络的可视化效果对比如图5 所示(彩色效果见《计算机工程》官网HTML 版)。从图5 可以看出:RandLA-Net 容易混淆一些相似物体(如栅栏和植被),并且不能准确地识别小目标(如自行车和其他交通工具),而CAF-Net 能有效利用不同尺度间的层次特征,并区分相似目标,同时缓解了小目标特征在下采样时的信息丢失问题,对小目标物体具有较优的识别效果。
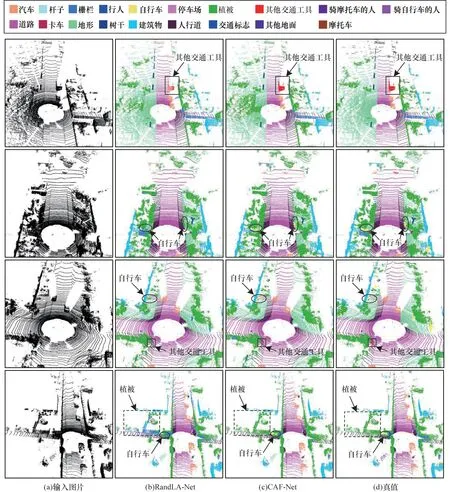
图5 在SemanticKITTI 验证集上不同方法的可视化效果Fig.5 Visualization effect comparison among different methods on SemanticKITTI verification set
2)在Semantic3D 数据集上的对比实验
在reduced-8 测试集上不同方法的对比结果如表2 所示。CAF-Net 的实验结果均优于基于体素的方法[27-28],其原因为体素化会丢失大量的空间位置信息,而相较于其他基于点的方法,CAF-Net 在mIoU 和OA 方面都表现出优异的效果,并且在人造地形、自然场景、建筑物和杂乱场景四个类别的IoU中取得较优的实验结果。
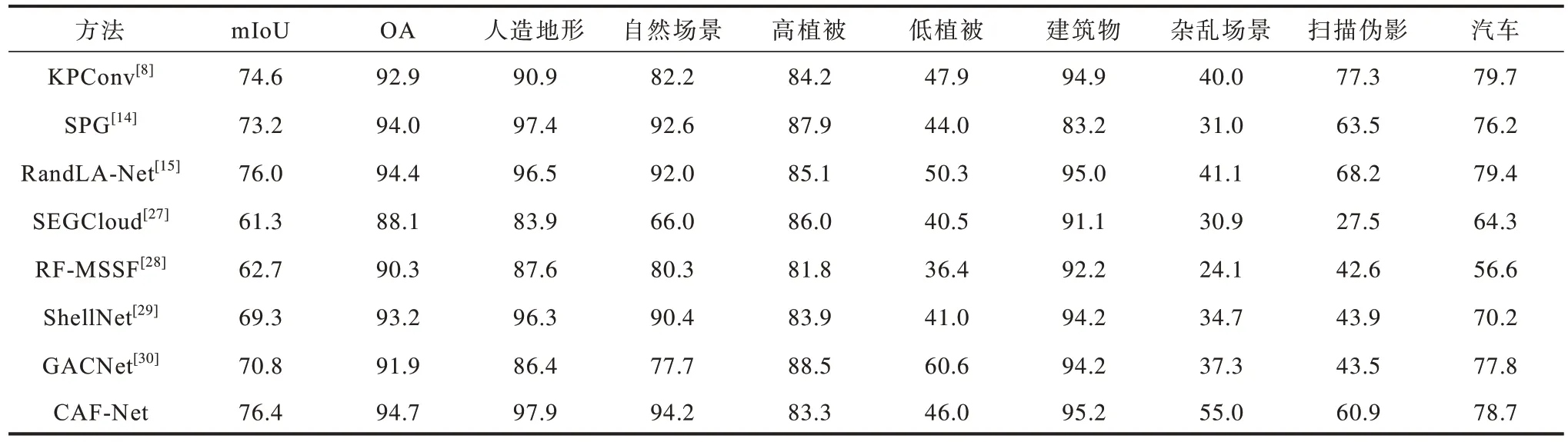
表2 在Semantic3D reduced-8 测试集上不同方法的实验结果Table 2 Experimental results comparison among different methods on Semantic3D reduced-8 testset %
在 Semantic3D 数据集上 RandLA-Net 与CAF-Net 方法的部分可视化结果如图6 所示(彩色效果见《计算机工程》官网HTML 版),其中矩形框表示相似物体的识别,椭圆框表示地面停车线的识别。从第一行castleblatten_station1 场景中的可视化结果可以看出:CAF-Net 能够准确地识别建筑物和人造物体,可以较准确地识别相似物体。从第三行sg27_station10-reduced 场景中的可视化结果可以看出:RandLA-Net 未识别出停车线,而CAF-Net 能准确地识别停车线。
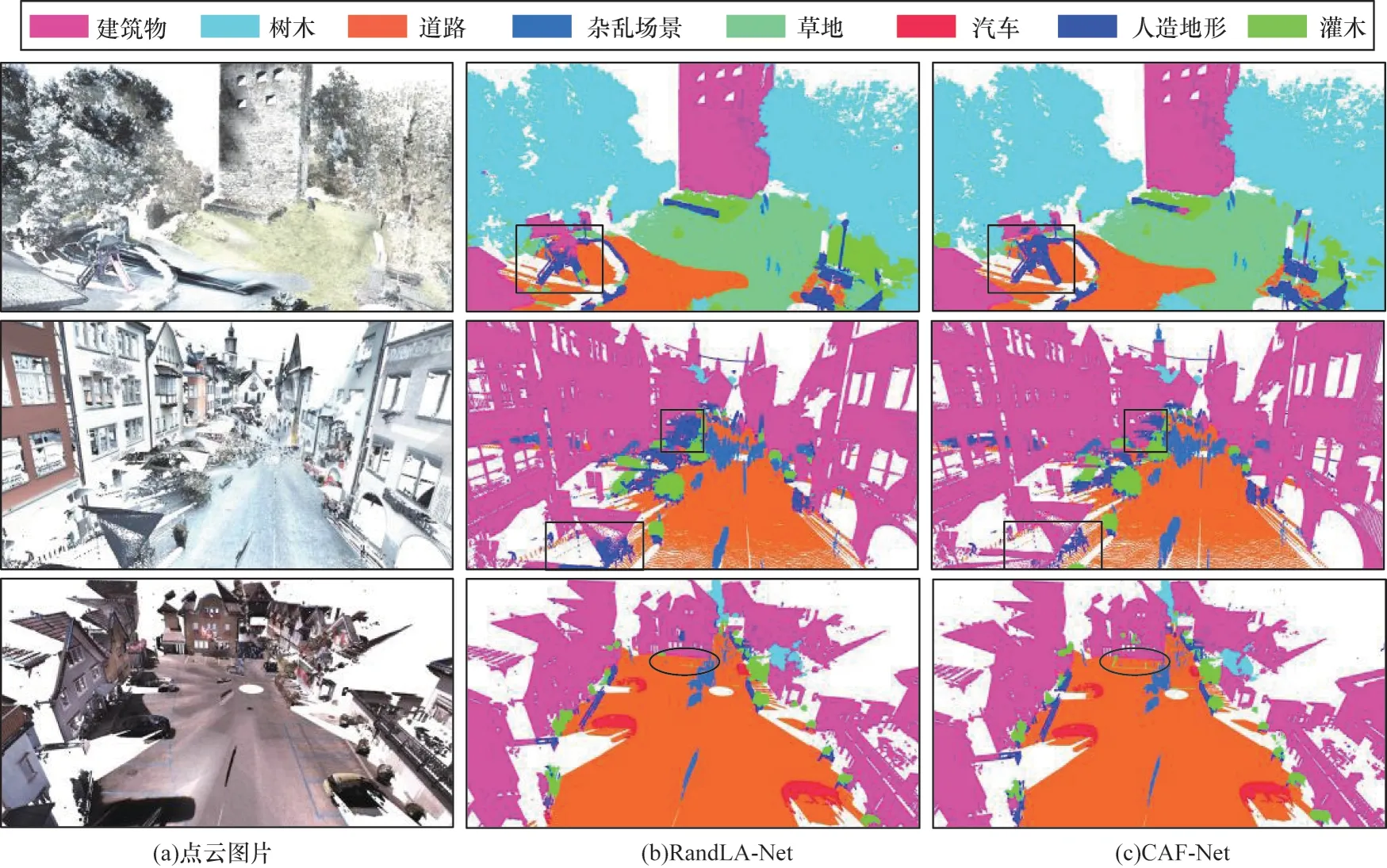
图6 RandLA-Net 与CAF-Net 方法的部分可视化结果Fig.6 Partial visualization results of RandLA-Net and CAF-Net methods
2.3.2 CAF-Net 的模块消融实验
为了定量评估本文所提的BCAF 和CE-CSA两个模块的有效性,本文对这些模块的不同组合进行消融实验,所有实验均在SemanticKITTI 数据集上进行训练和验证。
本文分析了FAF、BAF 和CE-CSA 模块对分割性能的影响。CAF-Net模块的消融实验结果如表3所示。FLOPs 表示模型的计算量,即模型复杂度。基线方法是RandLA-Net。FAF通过对浅层特征进行筛选,以关注局部细节,RandLA-Net+FAF相较于RandLA-Net的mIoU 提高了0.85 个百分点。BAF 组件结合相对高级的语义特征进行注意力融合,有助于对相似物体的区分,RandLA-Net+BAF 相较于RandLA-Net的mIoU 提高了0.91 个百分点。本文将BAF 与FAF 相结合实现浅层细节与高层语义特征的有效融合,因此,RandLANet+BAF+FAF 相较于RandLA-Net 的mIoU 提 高1.22 个百分点。为了更好地实现特征之间的融合,CE-CSA 模块通过上下文编码和自注意力机制丰富了语义信息,RandLA-Net+CE-CSA 相较于RandLA-Net的mIoU 提高0.31 个百分点。本文将三个模块综合得到的RandLA-Net+BAF+FAF+CE-CSA(本文所提的CAF-Net)的mIoU为57.98%。
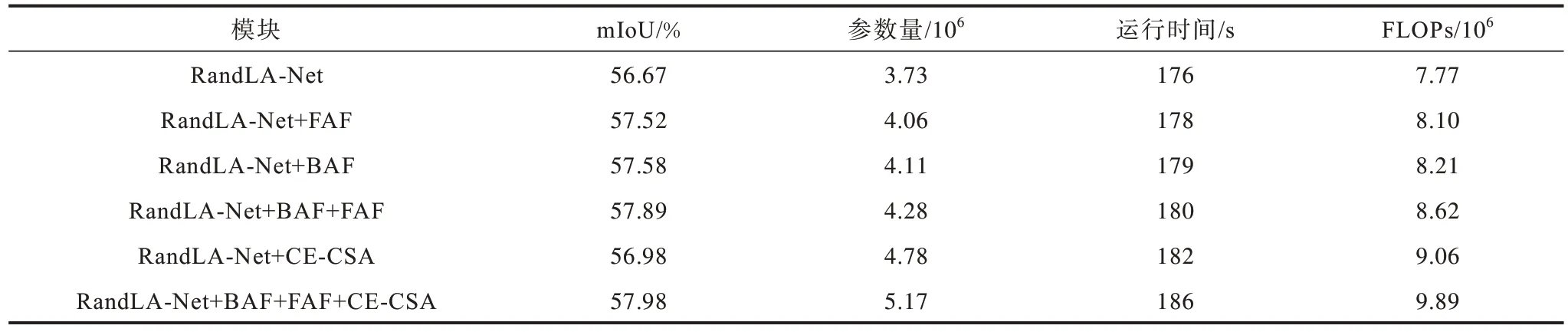
表3 CAF-Net 模块的消融实验结果Table 3 Ablation experiment results of CAF-Net module
2.3.3 双向上下文注意力融合组件个数实验
本文进一步探究FAF 组件和BAF 组件的个数对网络性能的影响。双向上下文注意力融合组件个数实验结果如表4所示。基线网络RandLA-Net的mIoU 为56.67%。当加入两组融合组件时,RandLA-Net受限于网络层数较少,对局部特征的聚合和不同尺度的特征融合还不够充分,相比RandLA-Net的mIoU 仅提高了0.59 个百分点。当加入四组融合组件时,RandLANet+4×(FAF+BAF)网络的参数量增加,推理时间也有一定的延长,而mIoU 相较于RandLA-Net仅提高了0.42 个百分点。当加入三组融合组件时,RandLANet+3×(FAF+BAF)分割精度取得最优的效果,mIoU 为57.89%,而参数量和模型复杂度仅有小幅度增加。

表4 双向上下文注意力融合组件个数的实验结果Table 4 Experimental results of the number of bidirectional contextual attention fusion components
2.3.4 CE-CSA 模块组件的消融实验
本文进一步探究CE 组件与CSA 组件分别对网络精度的影响,CE-CSA 模块组件的消融实验结果如表5 所示。
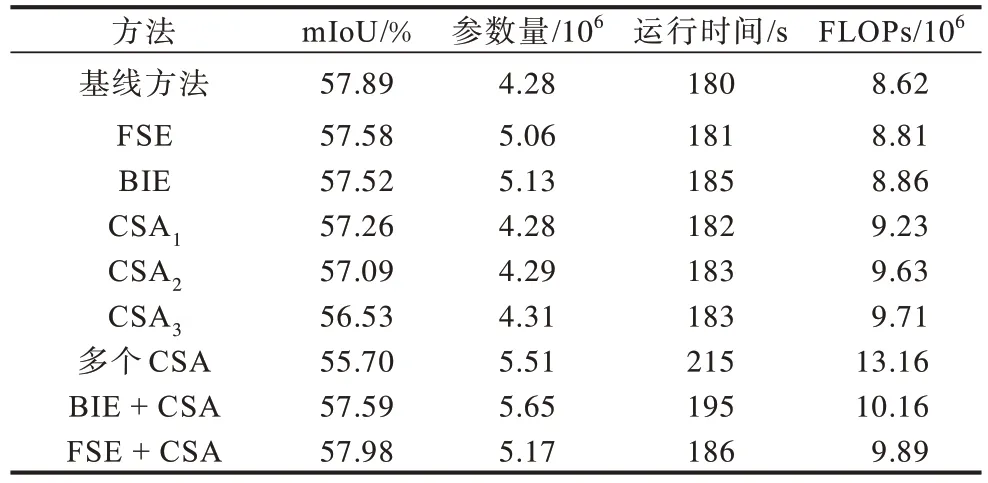
表5 CE-CSA 模块组件的消融实验结果Table 5 Ablation experiment results of CE-CSA module component
为了保证唯一变量,基线方法是RandLA-Net+3×(FAF+BAF)。当单独选用FSE 和BIE 组件编码全局多尺度信息时,相较于基线方法的mIoU 下降0.31和0.37 个百分点。采用CSA 组件分别关注原始特征、浅层特征和高层语义特征,记作CSA1、CSA2、CSA3,其mIoU 相比基线方法下降0.63、0.8、1.36 个百分点。如果将所有尺度特征图都经过通道自注意力关注不同通道特征,会大幅增大模型的复杂度,降低推理速度,同时产生大量参数。多个CSA 组件方法与基线方法相比的mIoU 下降了2.19 个百分点。BIE 组件在编码时浅层特征权重大,没有结合高层语义信息,BIE+CSA 方法相较于单独BIE 方法,在一定程度上提高精度,但是会引入一定噪声。BIE+CSA 方法相较于基线方法下降了0.3 个百分点,而FSE+CSA 方法能够更充分地捕获有价值的高层语义信息,因此FSE+CSA 方法具有较优的效果,mIoU为57.98%,且未引入大量的参数和延长运行时间,说明只有同时利用FSE 和CSA 才能对网络的精度起到提升的效果。
3 结束语
本文提出基于上下文注意力的室外点云分割方法CAF-Net,该方法主要由双通道上下文注意力融合模块和上下文编码-通道自注意力模块组成。双通道上下文注意力融合模块通过双通道注意力融合浅层特征和高层语义特征,以捕获局部上下文特征,上下文编码-通道自注意力模块通过编码多尺度特征以捕获全局上下文信息,并设计通道自注意力机制关注特征通道之间的相关性。实验结果表明,CAF-Net 能有效提高整体分割精度,且对小目标具有较优的分割效果。由于在自动驾驶等实际应用中通常对时序点云进行语义分割,因此下一步将对帧间语义一致性与轻量化分割方法进行研究,以降低模型复杂度,实现更准确且可移植的室外大场景点云语义分割。
猜你喜欢
能源工程(2022年2期)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
重型机械(2020年2期)2020-07-24
装备制造技术(2019年12期)2019-12-25
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
太阳能(2015年11期)2015-04-10
时代英语·高三(2014年5期)2014-08-26
