
基于改进U-Net的视网膜血管动静脉分割和分类算法
2023-03-16 06:19吴诗雨卓广平朱俊东张光华
中北大学学报(自然科学版) 2023年1期
吴诗雨, 卓广平, 朱俊东, 张光华
(1. 太原师范学院 计算机科学与技术学院, 山西 晋中 030619; 2. 太原学院 智能与自动化系, 山西 太原 030032)
0 引 言
眼底视网膜血管是全身唯一可以无创无痛观测到的血管, 视网膜血管的分割图像为毛细血管瘤、 视网膜出血斑、 血流分析、 视网膜图像配准或视网膜图像合成等血管疾病提供了诊断依据[1]。 目前, 视网膜动脉和静脉的分割大多是眼科医生从眼底图像中根据动静脉血管的颜色深浅、 口径粗细、 分支情况等进行识别, 但是, 人工分割视网膜血管区分动静脉的方法耗时多, 而且受主观因素影响严重, 具有很多不确定性。 因此, 根据眼底视网膜血管分割结果进行动静脉自动准确分类, 对临床研究有着重要的意义。
近年来, 深度学习技术在图像语义分割领域受到了许多计算机视觉和机器学习研究者的关注[2]。 现阶段视网膜血管自动分割算法主要分为两类: 监督学习和无监督学习[3]。 监督学习算法利用已有的先验标记信息来判断图像中像素点是属于血管还是背景, 无监督学习算法不需要先验标记信息, 而是让图像像素自主学习完成分类。 目前在深度学习中使用较多的是监督学习, 监督学习算法根据先验标记信息可以自动、 准确地识别图像像素信息, 结果也更加准确。 目前, 先进的监督方法模型是从眼科专家分割的图像中获取, 根据特征提取训练分类器, 并利用这个分类器进行血管动脉和静脉的自动分类和分割。 Mirsharif等[4]利用一组像素特征和一组不同的分类器来实现动静脉分离。 Relan等[5]提出使用最小二乘支持向量学习分类器[6]来分割血管, 提高了小动脉和静脉分类的准确率。 Wang等[7]提出一种结合卷积神经网络 (CNN) 和随机森林 (RF) 的算法完成了对视网膜血管分割的任务。 Liskowski 等[8]通过实验证明将深度卷积神经网络引入视网膜血管分割领域, 能有效解决传统机器学习毛细血管难以分割的问题。 高宏杰[9]提出了一种基于U-Net网络的视网膜血管分割方法, 该方法修改了卷积层之间的连接方式, 并且添加了PReLU激活函数和批量归一化优化模型。 Jin等[10]提出的DU-Net 网络结合了可变形卷积和U-Net网络的优点, 针对眼底视网膜血管细小、 分割精度较低等问题, 增加了大量的上采样算子的特征通道用于提取上下文信息, 进而提高了输出的分辨率。 Alom等[11]提出了U-Net++, 设计了网状跳跃连接, 聚合解码器子网络上不同的语义尺度特征, 形成高度灵活的特征融合方案。 Yang等[12]提出了一种拓扑结构约束的生成对抗网络(topGAN)来自动识别和区分视网膜图像中的动脉和静脉。 尽管针对视网膜动静脉血管分类已经提出了许多方法, 但是现有的眼底图像视网膜动静脉分类中仍存在许多问题, 例如微细血管末端出现假阳性、 对血管分割不足、 对病灶敏感、 血管连通性差和分类准确率低等[13]。
本文中针对上述不足, 对传统U-Net模型进行改进, 提出FUnet(Four-U-net)模型算法。 经过多次串联的改进U-Net网络, 将编码器中提取的特征经过特征融合输入解码器中恢复图像大小, 经过多次的融合、 分割、 合并, 根据像素特征进行动静脉分类, 最终得到眼底视网膜动静脉血管分割图像。 视网膜血管动静脉分类是在血管分割结果的基础上对背景像素进行标注分类, FUnet将预测结果传到下一级网络中, 进而细化分类结果, 能够平衡动静脉标注的分布, 解决了传统U-Net网络模型中动静脉分类存在偏差的问题。
1 U-Net模型简述
U-Net最初就是用于医学影像分割, 并以其在医学领域的杰出表现而闻名于世。 2015年, U-Net网络模型由Ronneberger等在MICCAI会议上提出[14], 它是一种卷积自动编码器, 下采样由CNN组成。 U-Net网络包含跳过连接, 通过连接或激活卷从下采样路径链接到上采样路径, 以使获取更高分辨率信息。
U-Net是基于全卷积网络的分割模型, 模型左右对称, 可分为编码器和解码器。 U-Net模型编码器采用3×3的卷积层, 激活函数为ReLU, 每两个卷积层之后连接1个池化层进行特征提取, 每经历1次下采样都会使图像尺寸和分辨率减小为原来的1/2。 编码器和解码器中间通过跳跃连接Skip-Concatenate, 将图像各层次的多维要素进行融合, 提高网络对特征信息的学习能力和获取的敏感度[15]。 U-Net在解码器阶段进行上采样操作, 反卷积后的特征图通过跳跃连接同一级层编码器输出的特征图, 经过特征融合之后作为下一层的输入, 继续上采样, 提取图片的特征, 还原图像尺寸和分辨率, 最后输出一个有效特征图对特征点进行分类。
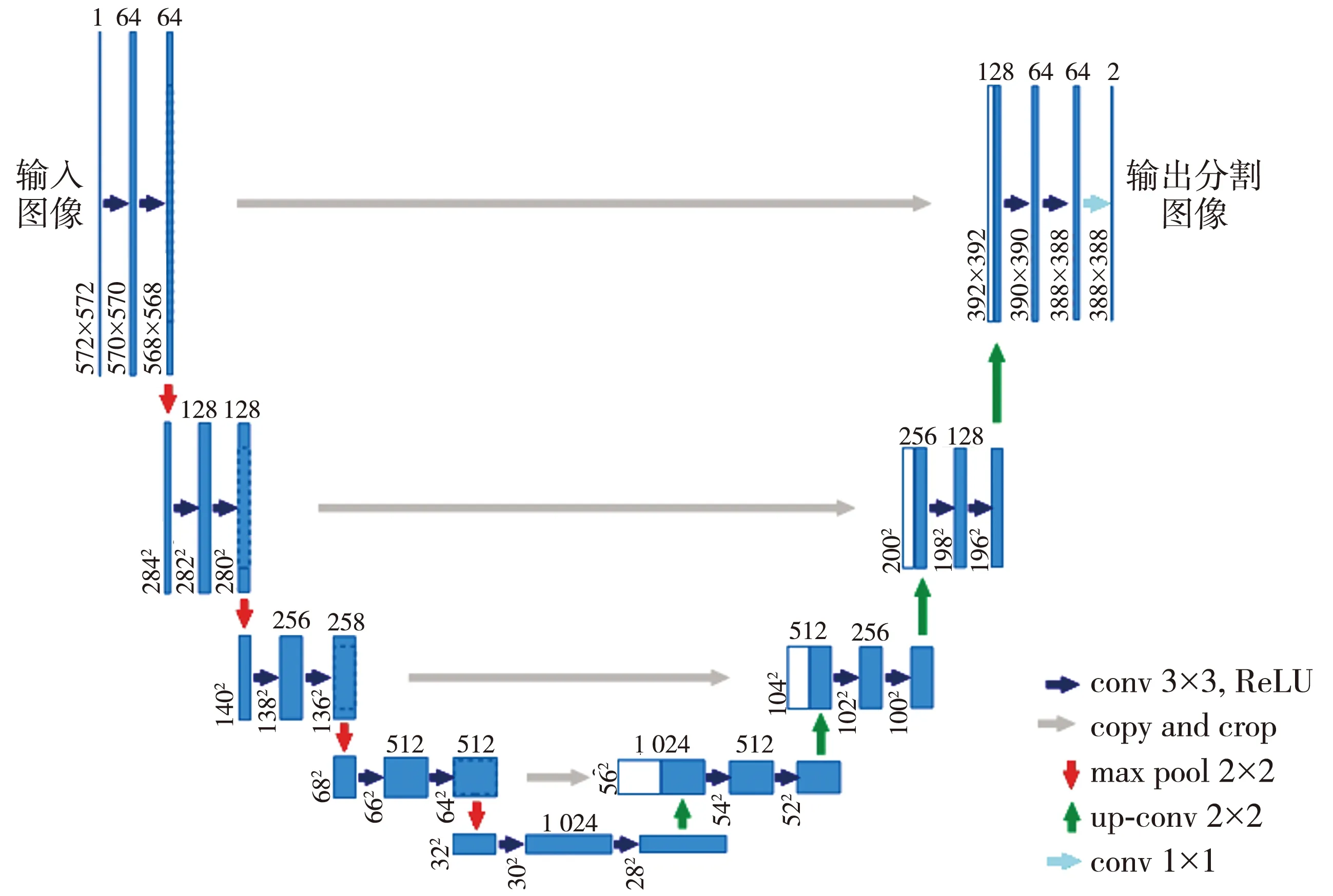
图1 U-Net模型结构示意图[14]
2 U-Net模型相关改进
本文提出一种基于U-Net模型改进而来的FUnet, 用于对视网膜血管进行分割和动静脉分类, 整体分割示意图如图2 所示。 首先, 对U-Net模型进行改造, 在每次卷积操作之后插入批量归一化, 并在全连接层添加跳跃连接, 提高模型训练速度; 然后, 将改造后的4个连续的U-Net模型串联组成FUnet网络模型, 在FUnet中自定义模型层需要训练的参数, 对图像进行多次的像素级训练, 将每次生成的血管预测图像和原始血管图像进行像素相乘并作为输入再次进行预测, 提取血管的局部信息; 最后, 经过4次预测, 输出动脉和静脉血管分类预测结果图像, 训练结束后保留最佳模型。 通过对血管特征的不断提取和融合, 捕获更多的血管特征信息, 更大程度地保留血管分割的完整性。
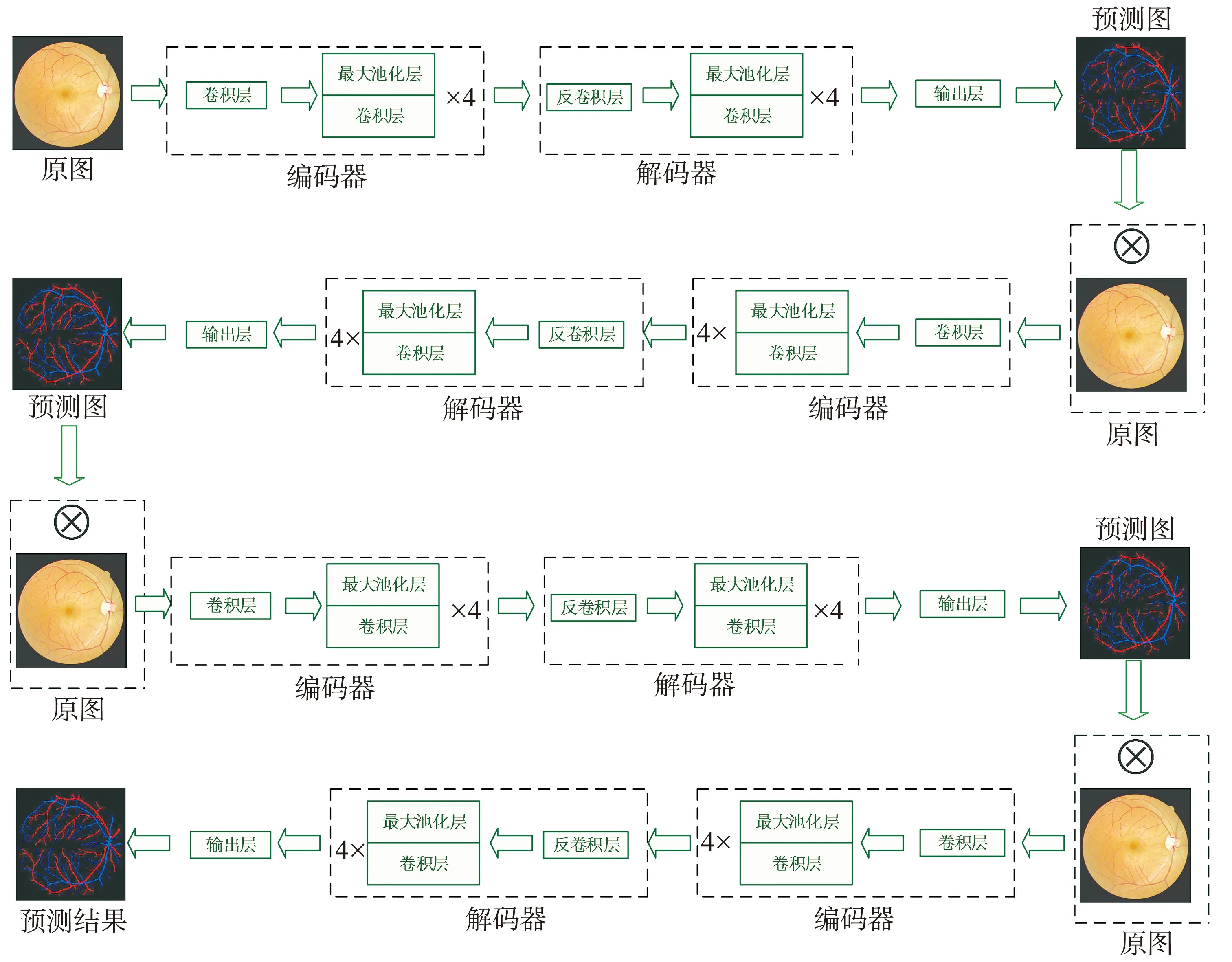
图2 FUnet分割示意图
原始图像中的像素包括视网膜动脉、 静脉和背景。 在FUnet模型训练时, 通过Mask掩码图像去除图像黑色背景, 保留视网膜目标部分, 更大程度地提取血管信息。 预测结果图像中, 根据像素将动脉血管标记为红色, 静脉血管标记为蓝色。
FUnet训练时采用交叉熵损失函数计算输出损失, 公式为

(1)

通过对比不同优化器, 最终采用效果优于其它优化器的Adam优化器, Adam吸收了Adagrad(自适应学习率的梯度下降算法)和PMSprop(动态梯度下降算法)的优点, 在训练过程中为不同的参数计算不同的自适应学习率, 这样有利于网络的优化, 可适用于含大规模参数的问题, 并且其对内存的需求较小[16]。 设置学习率的最大值为10-2, 最小值为10-8, 采用余弦退火策略进行调整。 余弦退火是采用余弦函数来降低学习率, 前半个周期从最大值降到最小值, 后半个周期从最小值升到最大值, 原理如下:

(2)
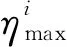
余弦函数的特点是开始时缓慢下降, 中间加速下降, 接着再减速下降。 随着模型的训练, 所需要的参数量越来越少, 所以需要更小的学习率, 使网络得到更好的收敛。 当梯度为0时, 模型就无法进行更新训练, 所以当训练梯度陷入到局部最小值时, 要通过提高学习率来更新参数, 提高权重, 使模型跳出局部最小值。 动态调整每次迭代训练的学习率, 在相同的批处理中采用同一个学习率, 不同的批处理中采用不同的学习率。
3 实验结果与分析
实验的仿真平台为Pycharm, 使用PyTorch框架对模型进行训练、 验证和测试。 整个实验的GPU为Nvidia GeForce RTX 208 。 迭代次数为50次, 每次迭代40个批处理大小, batch size为4, 学习率最大值设置为10-2, 最小值设置为10-8, 并进行动态调整。
3.1 数据集
本文使用公开的视网膜血管分割的DRIVE数据集和HRF数据集。 DRIVE数据集包含40张像素尺寸为568×584的清晰眼底彩色图像, 16张为训练图像, 4张为验证图像, 20张为测试图像。 其中, 33张为没有病理的正常图像, 其余7张为显示轻度早期糖尿病视网膜病变迹象的图像。 HRF数据集包含45张像素尺寸为3 504×2 336的眼底彩色图像, 33张为训练图像, 6张为验证图像, 6张为测试图像。 其中, 15张为健康患者的图像, 15张为糖尿病性视网膜病变患者的图像, 15张为青光眼患者的图像。
3.2 评价指标
分别从受试者工作特征曲线(ROC曲线)下的面积(AUC)、 准确度A(Accuracy)、 特异度S(Specificity)3个方面对FUnet模型的分割性能进行评价。 AUC表示正样本大于负样本的概率, 可由ROC曲线的面积直接获取。 AUC的取值范围为[0,1], AUC越接近1, 表示检测方法的准确性越高。 准确度、 特异度按式(3)、 式(4)来计算。
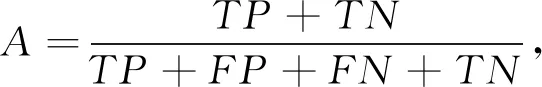
(3)
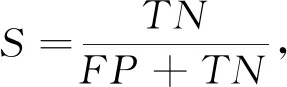
(4)
式中:TP为正类预测的正类数;TN为负类预测的负类数;FN为负类预测的正类数;FP为负类预测的正类数。
3.3 结果分析
数据集DRIVE和HRF中的病变图像和健康图像对比如图3 所示, 由图可以看到, 病变图像中出现明显的色素上皮萎缩和糖尿病视网膜病变迹象。 比较图中圈出的细节可发现, 不论是视盘周围血管还是末梢血管, FUnet方法均能精确分割血管, 对动脉和静脉的分类也更加明显, 表现优于U-Net方法。
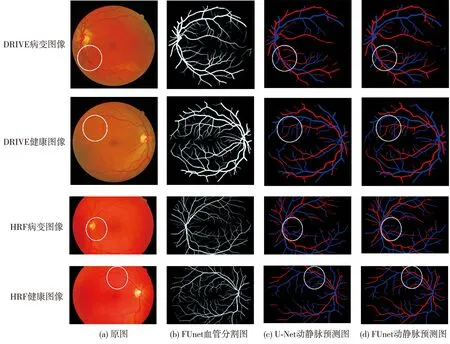
图3 病变图像和健康图像的动静脉分割和分类图
在DRIVE和HRF眼底图像数据集上分别进行实验, 对比U-Net和FUnet算法的性能, 结果见表1 和表2。

表1 DRIVE数据集分割结果

表2 HRF数据集分割结果
从表1 可以看出, FUnet算法在DRIVE数据集上的AUC、 准确度和特异度分别为0.849 7, 0.979 2 和0.991 2, 同传统U-Net模型算法相比分别提升了4.11%, 7.61%和0.06%。 从表2 可以看出, 本文算法在HRF数据集上的AUC、 准确度和特异度分别为0.823 9, 0.927 2 和0.999 4, 同传统U-Net模型算法相比分别提升了17.24%, 0.6%和0.18%。 以上分析表明, FUnet模型各指标均优于U-Net模型。
图4 为U-Net和FUnet两种视网膜动静脉分类算法在两个数据集上的分割结果。 在眼底视网膜动静脉分割中, 通过Mask图像去除背景, 可以更有效更精准地对视网膜血管进行分割。 从图4 中可以看出, 与专家标记图像相比, U-Net算法在血管交叉点和血管末梢会出现断裂、 缺失, 血管连通性差。 相比较而言, FUnet可以更好地分割出血管, 减少了微小血管的丢失, 保留了血管的更多细节, 也能更加准确地对动脉和静脉进行分类。 FUnet能有效提升血管分割的性能并对动脉和静脉进行准确分类, 并能更好地保留眼底视网膜血管的完整性、 连接性和准确性。

图4 视网膜动静脉分类结果对比图
4 结 论
本文基于U-Net网络模型提出了一种用于视网膜血管分割和动静脉分类的神经网络FUnet模型算法。 与U-Net模型相比, FUnet模型在DRIVE和HRF数据集上的AUC分别提升了4.11% 和17.24%, 准确度分别提升了7.61%和0.6%, 特异度分别提升了0.06%和0.18%。 结果表明, 采用FUne网络模型可以有效分割动静脉血管, 提高动静脉分类的准确性。 下一步将研究更优的动静脉分类模型, 利用血管分割的任务, 减少微小血管分类不准确的问题, 提高对眼底视网膜动静脉分类的性能。
猜你喜欢
现代仪器与医疗(2022年2期)2022-08-11
北京航空航天大学学报(2021年9期)2021-11-02
中医眼耳鼻喉杂志(2021年1期)2021-07-22
中国民间疗法(2021年8期)2021-07-22
中医眼耳鼻喉杂志(2021年2期)2021-07-21
国际呼吸杂志(2019年22期)2019-12-09
电子制作(2019年11期)2019-07-04
心肺血管病杂志(2019年4期)2019-06-27
北京航空航天大学学报(2018年1期)2018-04-20
湖南中医药大学学报(2016年1期)2016-12-01
