
利用依存句法分析和关键词共现的机器阅读理解模型
2023-03-15 08:47:08蔡东风樊睿文
计算机应用与软件 2023年2期
赵 耀 白 宇 蔡东风 樊睿文
(沈阳航空航天大学人机智能研究中心 辽宁 沈阳 110136)
0 引 言
机器阅读理解(MRC,machine reading compreh-ension)是自然语言处理领域的一个重要且富有挑战性的任务。阅读理解能够让机器理解文章进而回答相关问题,对自然语言理解和人工智能具有重要意义。
中文片段抽取式阅读理解中[5],问题多样化,如谁/何时/何地/为什么/如何等,问题中常常不直接使用文章中的描述,使用释义和语法转换,很多疑问句往往有着复杂的语言现象,如共指、省略和多疑问词等。答案属于某一类型的命名实体或特定类型(如姓名、日期和颜色等),则它可能不是上下文中的唯一答案,现在的深度学习模型无法根据其类型轻松地获得与问题匹配的答案。评测中多数模型都是关于注意力模型[1],通常利用循环网络将篇章编码成固定长度的中间语义向量,利用该向量指导每一步长输出,该模型结构简单,获得正确答案的效率和准确率低。尤其是在阅读长文本时,比如长问题或者长答案,通过词向量之间的相似度评分来获得关注度大小,对于一些无关紧要词过度关注,核心关键词得分容易被这些无关词稀释,这些无关词的噪声干扰加上词之间长距离的关联跨度,使模型模糊了关注度[2],造成误差的传播和结果的偏离。依存句法分析可以反映出句子各成分之间的修饰关系,经过依存句法分析的中心词,获得长距离的词之间关联信息,并与句子成分的物理位置无关,依存句法分析在文本理解、语义消歧和主干抽取中具有很大的作用,长文本分析就离不开描述对象关系信息提取,更是下一步语义分析的前提。
人类在做阅读理解时首先会进行略读,略读就是通过问题关键词查找篇章中答案最可能出现的位置,聚焦之后进行有选择地精读相关的片段。机器阅读理解模型主要思路亦是找到问题与篇章中答案的关联性,突出其中重要特征,忽略部分无关信息。问题与篇章最重要的关联性特征就是问题中的关键词,预测答案跨度类型应与问题给出的答案类型相对应,正确答案应该处于问题关键词出现范围之中。因此本文提出了一种基于依存句法分析和关键词共现特征的阅读理解模型。
提取问题关键词,将其与篇章做共现特征进行指导阅读,其次进行依存句法分析,获得篇章和问题每个句子中词的依存句法关系信息,句子每个词用中心词向量化表示。篇章和问题使用预训练模型输入,依存信息与预训练模型输出加权,使用Self-attention建立文本之间全局依赖关系对文章和问题作深度理解,挖掘不同的语义信息,提高阅读理解效果。
1 相关研究
随着多个阅读理解数据集的发布[3-11],大大推动了端到端神经阅读理解模型的发展,机器阅读理解根据任务的划分,可分为完形填空式、选择填空式、片段抽取式和自由类型式。其中,片段抽取式阅读理解任务作为机器阅读理解任务的一种重要形式,要求从给定的文章中找到一段连续的片段作为问题的答案。机器阅读理解最初由Winograd[12]提出构想,并设计了首个自动阅读理解测试系统Deep Read[13],该系统以故事为基础衡量阅读理解任务,利用人工编写的规则进行模式匹配。例如,Wang等[14]提出Match-LSTM模型通过使用多种注意力机制将问题信息融入到上下文表示,在输出层使用指针网络(Pointer Network[15])预测答案的开始和结束位置。文献[16]提出BiDAF(Bi-Directional Attention Flow)模型,核心层是双向注意力流层,模型验证了双向LSTM在篇章和问题的上下文信息特征的提取有一定的效果,但是与最好的模型还有很大差距,双向LSTM也仅仅是对篇章和问题向量的简单运算,浅层比较,在训练和推理方面效率较低。随着神经网络的不断发展,注意力已成为神经网络结构的重要组成部分,被用于提高阅读理解模型的可解释性,有助于克服递归神经网络中的一些挑战。R-NET模型[17]是基于MatchLSTM和门控制方式对注意力模型做了改进,输出答案过程中借鉴了指针网络(Pointer-Network)的思想。QaNet模型[18]使用CNN提取局部文本特征,通过self-attention建立文本之间全局依赖关系,使阅读理解生成的答案更加符合正确答案。在保持准确率的情况下,模型训练效率的大幅提升,QaNet模型是预训练模型发布之前排名前列的一个阅读理解模型,也验证了编码器Transformer的并行能力以及信息提取能力。
深层语境语言模型(Deep Contextual Language Model)是学习通用语言表征的有效工具,并在一系列主流自然语言理解任务中取得优秀成果。例如Elmo、GPT[19]、双向编码器表示的BERT[20]和XLNet[21]等。这些语言模型提供细粒度的上下文嵌入,可以很容易应用于下游模型。预训练语言模型在各种自然语言处理任务上取得了一系列成功,发挥了编码器的作用,但是将大量的一般知识从外部语料库传授到一个深层的语言模型中是非常耗时和耗费资源。预训练模型提高相似数据任务的效果,降低由于缺少数据而训练不充分的问题影响,且本文模型的评测语料也存在数量不足问题。
依存句法分析(Dependency Parsing,DP)通过分析语言单位内成分依存关系揭示其句法结构[22]。与神经网络结合使得依存句法分析获得进一步发展[23],在神经机器翻译中依存句法分析与编码器Transformer进行结合[24-25],引入依存句法信息指导的上下文词向量,提高了模型的精度。
2 模 型
本节将介绍抽取式阅读理解模型DP-reader,模型是基于预训练模型BERT,预训练模型能够很大程度地提升自然语言处理任务的效果,预训练模型能够直接应用当前的任务中,弥补训练语料不足的缺陷,又能加快模型的收敛速度。将预训练模型与依存句法分析信息(Dependency parsing)和关键词特征(Key word co-occurrence)结合在一起,模型主要包括输入层、编码层和匹配层。其中输入层将问题和篇章向量化并提取特征,编码层将文本信息和特征融合,匹配层查找问题在篇章中对应的答案,将答案区间输出。模型结构图如图1所示。

图1 模型结构
2.1 输入层
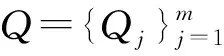
2.1.1 关键词共现特征
深度学习模型做阅读理解本质就是找到问题与答案的关联性,问题与答案的关联特征就是关键词,在篇章中答案的位置附近就有问题的关键词出现。例如问题“1990年,范廷颂担任什么职务”,整个问题关键词排序为[‘1990’,‘范廷颂’,‘职务’,‘担任’,‘什么’,‘年’],关键词排序第一个是最关键的词,其中‘1990’为最关键的词,越往后关键性越弱,设置阈值为3,即取前3个关键词。篇章中的标准答案为“1990年被擢升为天主教河内总教区宗座署理”,关键词‘1990’出现在答案中。有些问题的关键词虽然不在答案中,但是却在答案的附近,例如问题“锣鼓经常用的节奏型称为什么”,前三个关键词[‘锣鼓’,‘节奏’,‘经常’],答案为“锣鼓点”,在篇章中“常用的节奏型称为「锣鼓点」”,经过统计发现答案的前部会经常出现关键词,答案的后部出现关键词的频率较低,关键词出现密集的位置就是答案的位置。若阈值设置太低,会由于误差,关键词出现偏离;若阈值设置太高,就失去提取关键词的意义,经过测试阈值设置为3~4时,阅读理解模型效果较好。当关键词在篇章中和问题中同时出现,则共现次数为1,共现特征K的计算方式如式(1)所示。
(1)
2.1.2 预训练模型
将篇章和问题拼接成一个长度为m+n+3的序列,m+n+3
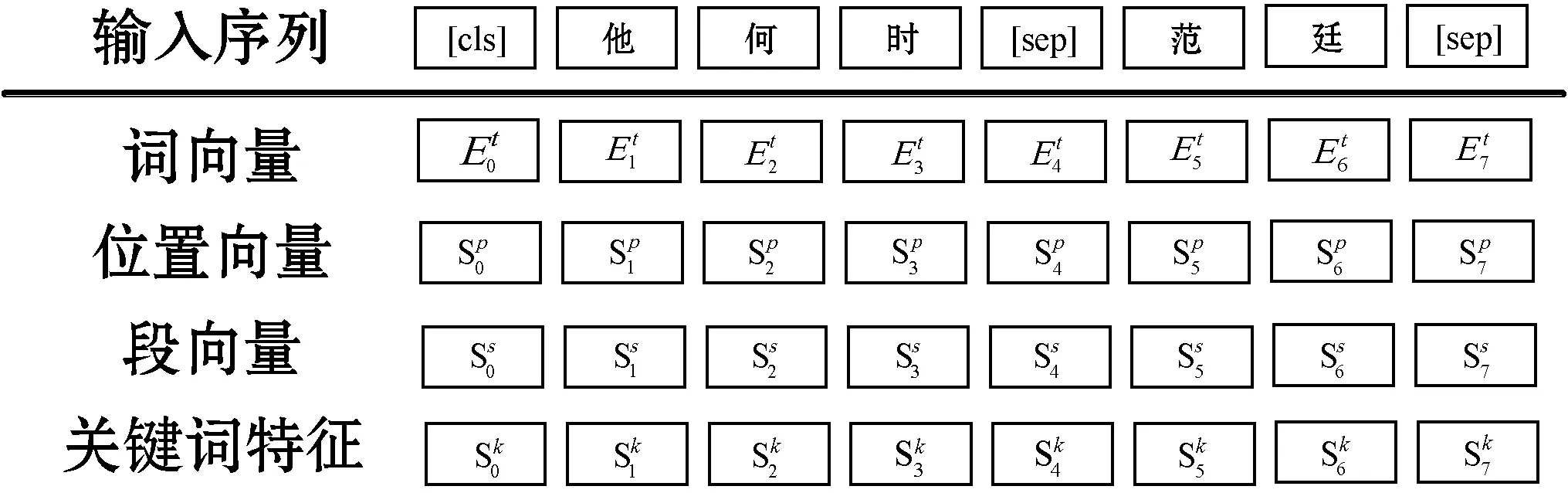
图2 预训练模型输入
将关键词特征与BERT模型结合,序列的输入如式(2)所示。
(2)

2.1.3 依存句法分析
依存句法分析[26]中一个句子里只有一个成分是独立的,句子的其他成分都从属于某一成分,任何一个成分都不能依存于两个或两个以上的成分,中心成分左右两边的其他成分相互不发生关系。将依存信息融入模型,依存句法分析如图3所示。
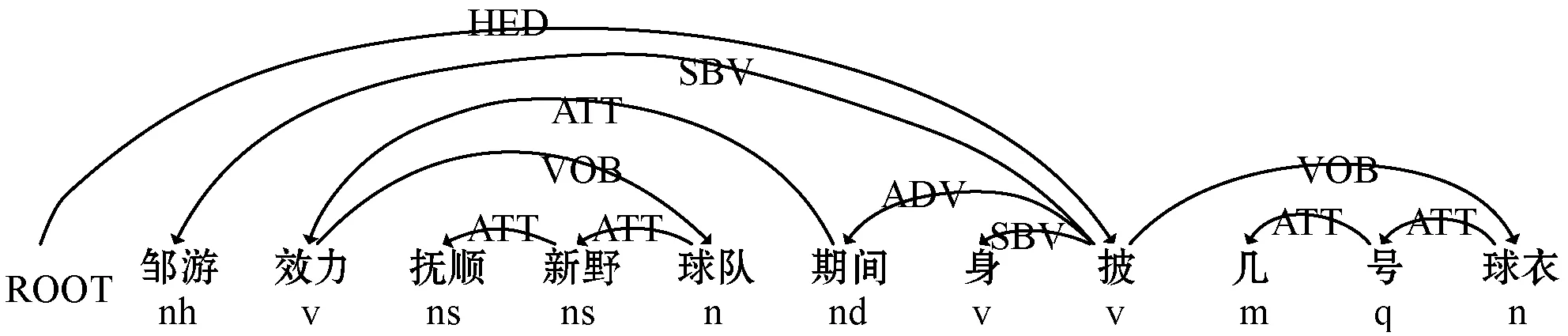
图3 依存句法分析
从依存分析结果可以看到,依存句法分析先识别句子中的成分如主谓宾定状补,分析各成分之间的关系,句子的核心谓词是‘披’,主语是‘邹游’,宾语是‘球衣’,‘效力新野球队期间’是‘披’的时间状语,‘几号’修饰‘球衣’。句子s=w1,w2,…,wn由n个词组成,通过依存句法分析器生成一个依存句法关系集合T(R,wi,wj),例如(nsubj,4,1),其中wi表示中心词,wj表示依存词,R代表这两个词之间的关系,方向是由中心词指向依存词,中心词可以指向多个依存词。经过依存句法分析,使用中心词wi表示每个词wj,中心词的数量相对于句子词的数量少很多,且中心词可以表示句子的主干内容,增强主干内容来降低无关词的影响。图4为CNN提取依存句法信息结构图。
图4 CNN提取特征

(3)

2.2 编码层
编码层Self-attention[27]作用是计算问题与篇章的上下文感知。阅读理解任务中,篇章往往较长,与答案相关内容只是其中的一小部分,本文使用自注意力模型进行篇章语义和问题语义的融合。遍历篇章文本,获得需要重点关注的区域,即注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息。
进入正则化层归一化,编码层有两个子层:第一个子层是多头自注意力,第二个子层是全连接前馈网络,两个子层之间使用残差网络结构进行连接,然后接一个正则化层。多头注意力通过多次线性变换进行投影,最后将不同的attention拼接在一起。编码层模型如图5所示。

图5 编码层
公式如式(4)-式(7)所示:
MhA(Q,K,V)=Concat(head1,head2,…,headh)Wo
(4)
headi=Attention(Q,K,V)
(5)
(6)
(7)
MhA(multi-head attention)自注意力中取Q、K、V相同,每个Q元素与每个K元素相乘,在此基础上乘以一个依存句法矩阵M,相当于是一种双向的传播。注意力打分函数表示为S,S可以是简单的计算,也可以是复杂的神经网络,常见的主要有点积运算、双线性模型、缩放点积模型和加性模型。本模型使用的是缩放点积模型,如式(8)所示。
(8)
残差连接是使网络在训练后不会变差,如式(9)所示。因为增加了一项X,那么该层网络对X求偏导的时候,多了一个常数项1,在反向传播过程中,梯度连乘不会造成梯度消失。
g(X)=X+F(X)
(9)
归一化(LayerNorm)把隐藏层数据转化成均值为0方差为1的标准正态分布,在把数据送入激活函数之前进行归一化,使输入数据不会落在激活函数的饱和区,起到加快训练速度,加速收敛的作用。如式(10)-式(12)所示。
(10)
(11)
(12)
式中:ε是防止分母为0,引入两个可训练参数α、β来弥补归一化的过程中损失掉的信息,一般初始化α为全1,而β为全0。全连接前馈网络由两个线性转换组成,中间是一个ReLU函数连接,如式(13)所示。
FFN(X)=max(0,W1x+b1)W2+b2
(13)
(14)
2.3 基于指针网络匹配层
匹配层借鉴了pointer-network的思想,将篇章与问题做上下文分析,计算一个答案概率p∈[0,1],该概率决定开始节点和结束节点。如图6所示。
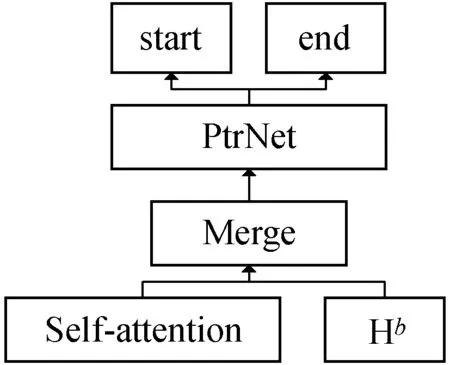
图6 匹配层
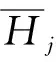
(15)
(16)
(17)
(18)
(19)
得到了两个值p1和p2,判断两者的大小,因为开始位置永远在终止位置之前,最终获得开始位置p1和结束位置p2。
损失函数如式(20)所示。
(20)
3 实验与结果分析
3.1 实验数据
中文评测任务CMRC2018,篇章内容来自中文维基百科,整个语料是由人工标注。数据规模如表1所示,其中测试集没有发布,模型性能在开发集上做测试。

表1 CMRC2018数据集规模
任务是根据所给的文章获得相关问题的答案,即预测的答案在文章中的开始节点和结束节点。数据示例如表2所示。
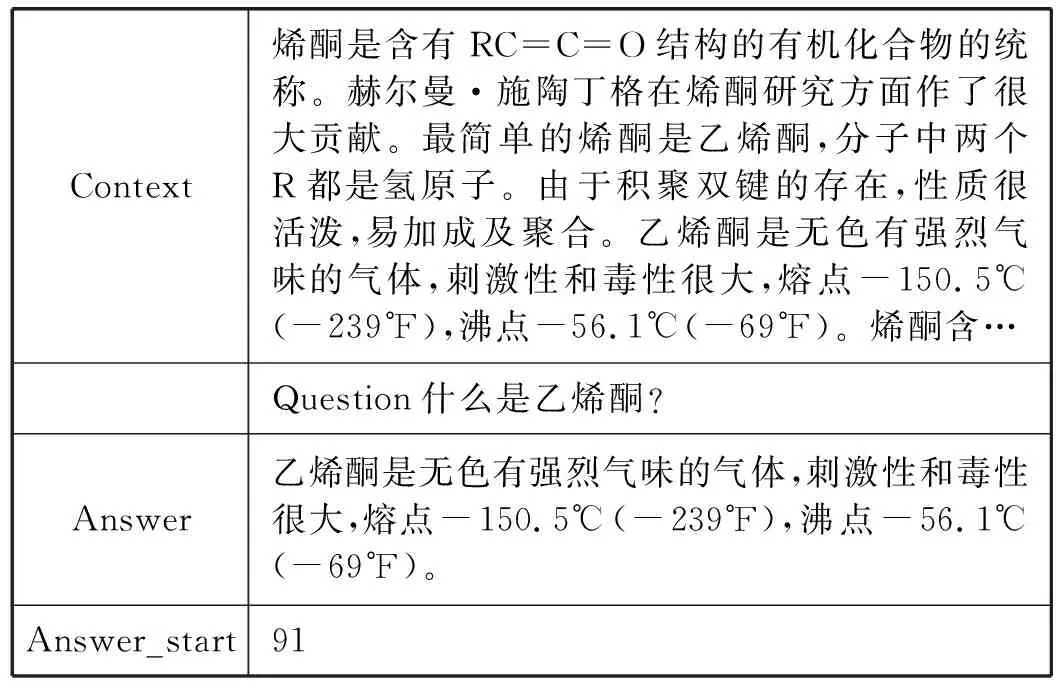
表2 数据示例
任务的基本评价指标有两个:(1) EM(exact match),计算预结果与标准答案是否完全匹配。(2) F1得分,以模糊匹配的方式,通过计算预测答案与标准答案之间字级别匹配程度。计算F1得分时首先计算精确值(precision)和召回率(Recall),精确值表示预测答案词正确的比例,召回率表示被正确抽取的词比例。
3.2 实验设置
本文的模型构建采用PyTorch 1.14、Python 3.4,整体调优在验证集上进行,参数值设置如表3所示。模型采用Adam优化模型参数。实验运行的硬件条件为Tesla T4显卡、显存16 GB。5个参数进行大量的实验,把实验效果最好的参数值作为模型的参数。实验表明,这5个参数均存在局部最优值。
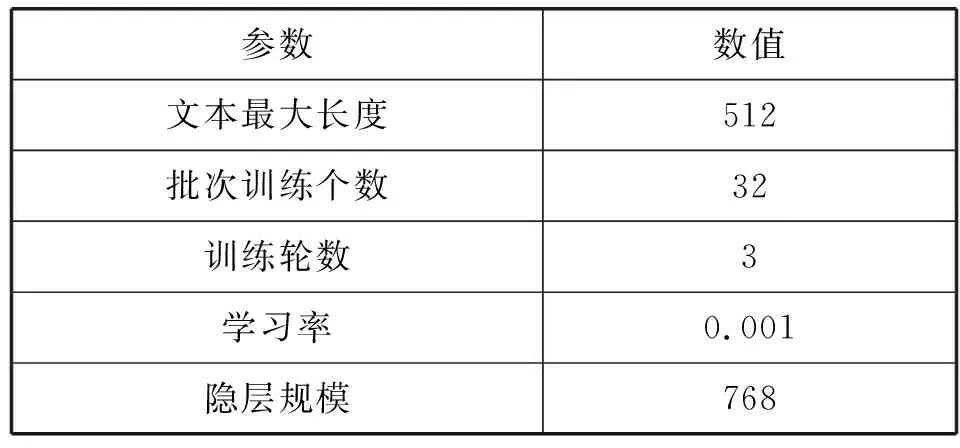
表3 模型参数设置
3.3 实验结果分析
基于预训练模型和未经过预训练模型比较如表4所示,BiDAF和QANet模型未使用预训练模型,Bert和Bert+使用了预训练模型,使用预训练模型普遍效果高于未使用预训练模型,模型集成对效果也有一定的提升。本文设置了8组对比实验来验证本文方法的有效性,如表4所示。

表4 实验结果对比
对比基线模型是BERT模型,BERT基础模型主要有12层Transformer的encoder单元,隐藏层的维度是768维,采用微调方式在预训练模型上训练2轮。模型性能测试在开发集上进行,有3 219条测试数据,将测试数据分7组,第一组的答案长度是一个词,以此类推,整个数据集的答案长度集中在短文本处。BERT与DP-reader随着答案长度的变化F1值的情况如图7所示,答案长度越长,模型的效果会降低,对于答案的边界查找难度加大,DP-reader相对于BERT对于不同长度答案阅读效果均有提升。
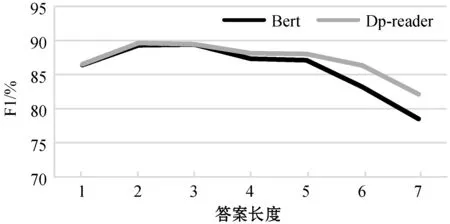
图7 两个不同答案长度F1值对比
对比于Bidaf和QAnet模型,这是机器阅读理解经典模型,对比目的在于说明本模型在整体效果,由表4可以看出,DP-reader在EM和F1相比前两者有大幅度的提升,具有更好的阅读理解能力。
分析原因可得,依存句法分析获得每个词对应的中心词,使用依存句法分析的中心词来刻画句子,中心词数目相对于句子词汇来说数量要小很多,且总结出句子主干内容,大部分的句子都可以使用这个框架来表示。引入依存句法信息指导上下文词向量减少了无关词的噪声影响,提高了回答长问题或者长答案的效果,提升1.12百分点。
对篇章进行关键词检索,模仿人在阅读时进行简单搜索,通过关键词找到答案最可能位置,模型将其权重加大,关键词对模型的提升了2.06百分点。关键词阈值的设置对模型有影响,超参数保持不变,实验结果如表5所示。
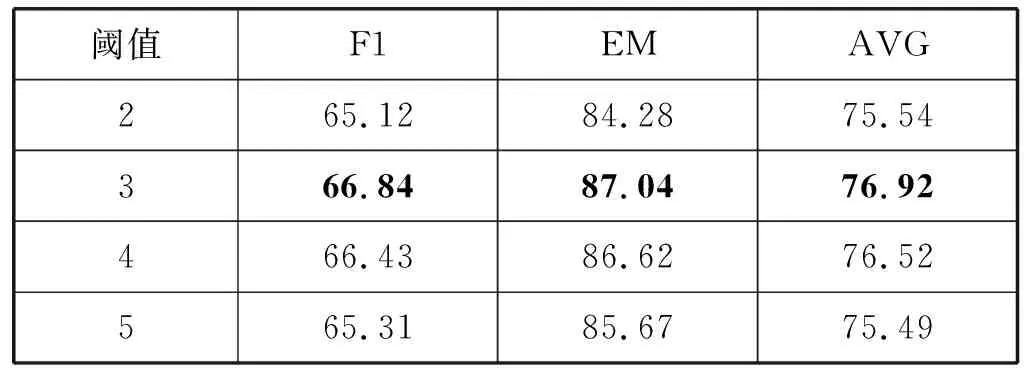
表5 关键词阈值对结果影响
文本的类型比较广泛,包括化学、历史、宗教、生物、建筑、商业、法律和地理等,在训练的语料中相关文本类型训练数据较少,无法做到充足的训练。使用DRCD数据集转换,将繁体文本转换成简体文本,进行数据扩增。
错误案例分析:
(1) 答案需要进行多步推理获得,如“凡式下银汉鱼在中国主要分布什么地区?”正确答案为“中国沿海”,预测答案为“印度西太平洋区”,部分篇章为“本鱼分布印度西太平洋区,包括东非、红海、阿拉伯海、波斯湾、日本南部、中国沿海、越南、菲律宾、印尼、澳洲、马来西亚、孟加拉湾、印度沿岸、新喀里多尼亚和所罗门群岛等海域。”模型需要知道什么地方属于中国地区,这需要参考外部知识库知识。
(2) 问题语义复杂,出现多个问题词,模型无法分辨出问题重点是哪个问题词,如“威尔特郡作为非都市郡,实际管辖了哪几个非都市区?”问题中有“哪”“几个”问题词,正确答案为“索里兹伯里(Salisbury)、威尔特郡西(West Wiltshire)、肯尼特(Kennet)、威尔特郡北(North Wiltshire)”,预测答案为“4个”,模型回答“几个”问题,但是中文理解应该是“哪”,这与中文的语言特点有关系,中文表达方式相对英文或者其他语种更加丰富且复杂。
4 结 语
针对CMRC2018评测任务,本文提出一种基于依存句法分析和关键词共现的阅读理解模型,该模型是一种简单且有效的网络模型,在自注意力中模型可以学习到关于篇章和问题的不同特征信息,利用句子的句法依存树所提供的中心词与依存词之间的关系,减少长文本中的噪声影响,用关键词共现方式对答案进行纠正,这样可以更准确找到答案的位置。
本文中对于知识的融入工作还不够,在性能上尚未达到最优,还有提升的空间。现在主流的研究方向是将预训练模型结合知识库来指导机器阅读理解,使模型的泛化能力加强,即使是未训练的语料也能够使用模型经过知识库的辅助理解后达到较好的结果。这是我们下一步的研究目标。
猜你喜欢
童话王国·奇妙逻辑推理(2024年5期)2024-06-19 16:03:38
中学生数理化·七年级数学人教版(2020年10期)2020-11-26 08:24:50
数学物理学报(2020年2期)2020-06-02 11:29:24
疯狂英语·新悦读(2020年2期)2020-04-29 10:50:22
制造技术与机床(2019年10期)2019-10-26 02:48:08
电子制作(2018年18期)2018-11-14 01:48:06
光学精密工程(2016年6期)2016-11-07 09:07:19
高中生学习·高二版(2016年2期)2016-05-30 19:07:04
小学教学参考(2015年20期)2016-01-15 08:44:38
语文知识(2014年1期)2014-02-28 21:59:13
