
基于自适应分段聚合近似的户变关系聚类识别方法
2023-03-15 02:56:14尹善耀肖毅许晓春任洪男何奕枫
广东电力 2023年2期
尹善耀,肖毅,许晓春,任洪男,何奕枫
(1.南方电网广东惠州供电局,广东 惠州 516003;2.杭州沃瑞电力科技有限公司,浙江 杭州 310012)
近年来,随着经济的发展和城市化进程的不断推进,低压台区的用户数量增长迅速,导致网络结构愈加复杂,加之大量施工改造导致台区户变关系变动频繁,但因为排查效率低,台区管理档案中的信息未能及时更新,造成部分用户的真实户变关系与档案记载不相符的情况发生[1-3]。正确的户变关系是负荷平衡管理、台区线损计算以及线路改造等业务开展的保障[4-5],因此户变关系识别成为一个亟待解决的关键问题。
现场停电校验和载波通信校验[6-7]是当前一线工作中常用的2种方式,均需要人工现场排查。现场停电校验方式需要对现场线路拉闸验电,会影响居民用电,目前无法大范围实施。载波通信校验方式对硬件设备要求较高,且载波通信易受到噪声干扰,在波动较大的台区效果不好。
随着配电网用户信息采集系统的完善和用户侧智能电表的安装和普及,电力公司能够获取到如电压、电流、用电量等海量电气数据,这为开展基于数据驱动的配电台区户变关系识别研究提供了信息基础[8-9]。文献[10]根据电压数据的时间和空间相关性分别训练2个分类器,通过计算各智能电表与每个分类器的归属概率判定台区归属关系;文献[11]通过整合低压台区信息系统数据构建台区图谱体系,从中挖掘户变关系信息;文献[12-15]通过皮尔逊相关系数判断户表之间的电压序列曲线相似性,从而得到户变关系结论;文献[16]根据高级量测体系(advanced metering infrastructure,AMI)提供的配电台区各耦合节点电压和电流,进行户变关系分析;文献[17]利用K-Means聚类对采集到的电压时序数据进行聚类分析,得到户变关系情况;文献[18-19]采用灰色关联方法计算用户与台区变压器二者的电压数据相似度,由此识别用户所属的台区及相位;文献[20]采用离散弗雷歇距离比较电表之间的电压曲线相似度,从而形成准确的户变关系;文献[21]使用主成分分析(principal component analysis,PCA)法对数据降维,而后采用模糊C均值聚类法辨识台区电压与用户的关系;文献[22]首先利用深度学习提取谐波谱特征,然后利用皮尔逊相关系数计算用户与配电变压器(以下简称“配变”)低压侧之间的相关程度,实现台区与相位的双重识别。综上发现,同一台区下的用户电压曲线波动具有一定的相似性,可据此进行台区户变关系识别研究。
本文依据台区变压器和用户电压曲线相似性的原理,采用自适应分段聚合近似(adaptive piecewise aggregate approximation,APAA)算法[23-24]和谱聚类算法实现户变关系识别。相较于分段聚合近似(piecewise aggregate approximation,PAA)算法,APAA算法在特征提取过程中增加了形状特征和变化趋势的分析,提高了特征提取的精确度。依据零均值标准化和APAA算法降维得到的结果,利用谱聚类算法将具有高相似度的变压器和用户电压曲线聚成一类,实现台区户变关系的智能识别。
1 电压时序数据特征提取
1.1 电压数据标准化
研究用户与台区变压器电压之间的关系是基于历史数据,本文使用的电压数据由智能电表采集而来,采用插值法对电压数据缺失值进行处理后得到原始电压矩阵
(1)
式中:N为用户端和配变端对应的电表总数;l为电表采集的电压数据连续时段长度;ui,t为电表i在t时刻的电压测量值。U的行向量U′i表示单个电表i在每一时刻的电压测量值,列向量U″t表示所有电表在t时刻的电压测量值。
由于原始电压数据间差异相对较小且分布相对集中,直接进行数据特征提取的效果可能不佳。为了提高后续特征提取以及聚类算法的结果精度,采用标准化方法对原始电压数据进行预处理。数据标准化处理常用的方法有小数定标标准化、最大/最小值标准化、零均值标准化等[25]。本文采用零均值标准化方法,通过调整参数能够达到放大数据间差异并保持其分布特性的效果,标准化后的矩阵
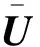
(2)
其中
(3)
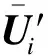
1.2 APAA算法提取特征
1.2.1 APAA与PAA的区别
APAA是PAA的改良算法。PAA是用低维序列数据近似表示高维序列数据的方法,将高维序列数据平均分成若干连续的子序列数据段,对每一子序列数据段求取均值后用均值取代子序列数据段,从而达到降维效果。整个过程可表示为:
(4)
(5)
(6)
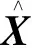
采用PAA算法虽然能够起到降维效果,但由于对每个子序列数据段进行无差别均值化处理,导致部分子序列数据段内的重要数据特征信息丢失,其结果不能很好地代替原高维序列数据。APAA算法从数据变化趋势的角度分析每一子序列数据段,由具体限定条件决定特征提取结果,结果可分为2种:一是保留该段整体数据,二是依照PAA算法进行降维。
1.2.2 特征提取条件
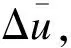
(7)
(8)
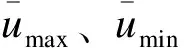
对于N个电表,在该子序列数据段内,电压爬坡事件数
(9)
在子序列数据段内,电表i标准化后t时刻电压与t-1、t+1时刻电压线段斜率分别为k1、k2,将二者的差值与阈值ε相比较,判断电表i在t时刻是否存在电压波动事件βi,t,定义:
(10)
在子序列数据段的左右边界时刻不进行电压波动事件判断,电表i在子序列段中的电压波动事件总数βi为除边界时刻外的其余时刻电压波动事件和。对于N个电表,在该子序列数据段内,电压波动事件数
(11)
1.2.3 APAA算法具体步骤
利用APAA算法对标准化后电压矩阵进行重构具体过程如下。
步骤2:输入阈值γ和ε,计算每个子序列矩阵的电压爬坡事件数α和电压波动事件数β。
步骤3:输入阈值δ和η,若α<δ、β<η则表明该段数据变化特征不明显,不具有提取价值,利用每一电表该段数据的均值取代原数据,将该段维数降为1;反之,说明该段数据包含重要变化特征,保留原有数据。
步骤4:计算现有数据集维度,若维度达到预期效果ζ,则转至步骤5,若维度未达到预期效果,则转至步骤2,重新调整阈值γ和ε的大小,当二者可选调整数值均遍历后,数据维度仍未达预期效果时转至步骤3,重新调整阈值δ和η的大小。
2 基于谱聚类的户变关系识别算法
2.1 谱聚类算法
谱聚类算法源于图论思想,将所有数据看作空间中的点,将数据之间的关系看作点与点之间边的权重,从而构建出整个关系图。若两数据间关系紧密,则二者边的权重值较大,反之较小,由此可通过切图的方式,使子图间边的权重和尽可能低,子图内边的权重和尽可能高,每一子图即为1个类别,从而达到聚类目的。本文采用谱聚类算法的具体步骤如下。
步骤1:利用高斯核函数构建电表间的关系图,即权重矩阵W。
(12)


步骤3:计算L的特征值和特征向量,并将特征值由小到大排列,取前f个特征值,将其对应的f个特征列向量ξ1,ξ2,…,ξf组成矩阵Y=[ξ1ξ2…ξf]。
步骤4:记Y的行向量分别为y1,y2,…,yf,依次对每一行向量进行单位化处理后按原位置重新构成矩阵Q。
步骤5:以Q的每一行向量为1个f维样本,将p个样本作为K-Means算法的输入,聚类数同样设定为f,进行聚类。
步骤6:输出聚类结果。
2.2 户变关系识别算法流程
低压台区户变关系识别整体流程如图1所示。
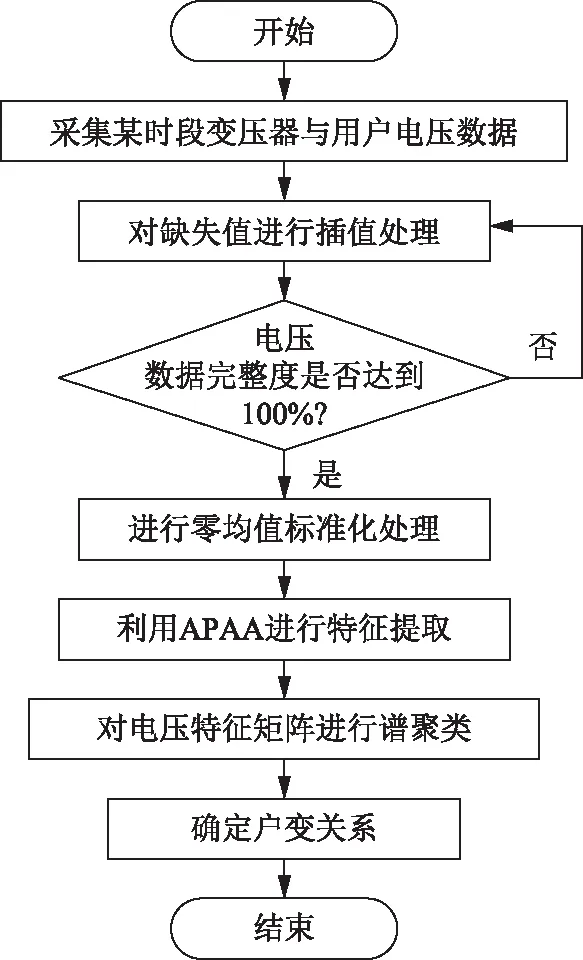
图1 户变关系识别算法流程
3 算例验证及分析
本文以中国南方电网有限责任公司用电信息采集系统获取的广东省惠州市下辖的某3个台区(A、B、C)的用户数据作为输入进行算例分析。算例数据的采样间隔为1 h,时间跨度为连续20 d,A、B、C这3个台区下分别有80、20和40个用户(3个台区变压器低压侧统一当作相应台区下用户处理)。本章首先验证最佳聚类数是否与实际台区数相符,检查数据的准确性;然后运用APAA以及谱聚类算法对该数据集进行户变关系识别;接着将本文所提方法与其他方法就户变关系准确率进行比较,证明本文所提方法的优势。
3.1 聚类评价指标
聚类评价指标是对聚类结果进行定量分析的必要数据,本文从聚类的有效性和准确性入手,采用Silhouette(SIL)、Calinski-Harabasz(CH)、Davies-Bouldin index(DBI)、adjusted rand index(ARI)和Fowlkes Mallows index(FMI)这5种指标来进行聚类结果评价,其中前3种指标用于评价聚类有效性,后2种指标用于评价聚类准确度。
3.1.1 SIL指标
对于单个样本c的SIL指标值ISIL,c,其计算公式为
(13)
式中:e1为该样本到同类别中其余样本的平均距离;e2为该样本到类别最近的所有样本的平均距离。样本集的SIL指标值为该样本集下所有单个样本SIL指标值的算数平均值,取值范围为[-1,1],其值越接近1说明聚类效果越好。
3.1.2 CH指标
CH指标通过计算类中各点与类中心的距离平方和构建类内离差矩阵度量类内紧密度,通过构建类间离差矩阵度量类间分离度。其指标值ICH计算公式为
(14)
式中:Bz和tr(Bz)分别为类间离差矩阵和其对应的的迹;Wz和tr(Wz)分别为类内离差矩阵和其对应的迹;z为类别个数。ICH越大代表类自身越紧密,类与类之间越分散,即聚类结果最优。
3.1.3 DBI
DBI用于计算类内距离之和与类外距离之比,其值IDBI的计算公式为
(15)
式中:so、sj分别为第o类和第j类中所有样本到其聚类中心的平均距离;Moj为第o类与第j类聚类中心的距离;q为类别个数。IDBI越小,聚类效果更佳。
3.1.4 ARI
ARI是RI(rand index)基于概率正则化的一种改进。RI计算的是聚类结果和实际信息对应对中聚类准确对数占所有对应对的比例。采用RI的期望值和最大值来修正RI,从而得到ARI值IARI的计算公式
(16)
式中:IRI为RI值;E(IRI)为其期望值;max(IRI)为其最大值。IARI的取值范围为[-1,1],其值越接近1说明聚类准确率越高。
3.1.5 FMI
FMI将召回率和准确率结合在一起,其值IFMI的计算公式为
(17)
式中:NTP为聚类结果与实际信息均为同一类的样本个数;NFP为聚类结果为同一类但实际信息不为同一类的样本个数;NFN为实际信息为同一类但聚类结果不为同一类的样本个数。FMI关注分类正确与分类错误样本间的相对比例,取值范围为[0,1],其值越接近1说明聚类准确率越高。
3.2 验证最佳聚类数与降维效果
本文采用肘部法则[26]来测试验证最佳聚类数。肘部法是基于K-Means聚类算法的聚类数预计算,不同的聚类数测试值v对应不同的成本函数值。成本函数值
(18)
式中:Cj为第j个聚类簇;xi为Cj中任一样本;cj为Cj的聚类中心。
随着v的增加,每类样本数减少,样本距其聚类中心的距离减小,平均畸变程度降低。在v值增大过程中,成本函数下降幅度变化最大的位置即为肘部,对应的v值即为最佳聚类数。图2所示为不同聚类数测试值下的成本函数值。

图2 不同聚类数测试值下的成本函数值
由图2可知,当v=3时,成本函数值曲线变化幅度最大,故根据肘部法则,最佳聚类数为3。通过将其与样本进行比对后发现,最佳聚类数与样本台区数刚好吻合,故在进行算例分析时,谱聚类中聚类数设定为3。
本文依据交叉验证的思想进行参数调节,特征提取部分的参数调节设定如下:每个子序列数据段包括的数据点数m的选定范围为8~24,步长为4;子序列数据段最大差值阈值γ的选定范围为0.5~3,步长为0.2;电压爬坡事件数阈值δ的选定范围60~130,步长为7;子序列电压线段斜率阈值ε的选定范围为3~6,步长为0.3,电压波动事件数阈值η的选定范围为500~800,步长为20;预期维度ζ的选定范围为94~98,步长为1。经过交叉验证后,确定输入参数如下:m=12、γ=1.5、δ=109、ε=4.5、η=600、ζ=95。
对数据集归一化处理后,从3个台区各取出2个用户数据,归一化后波动曲线如图3所示,分别采用PAA算法和APAA算法得到其归一化后波动曲线,如图4、图5所示。

图3 不同台区用户电压波动曲线

图4 PAA降维后用户电压波动曲线
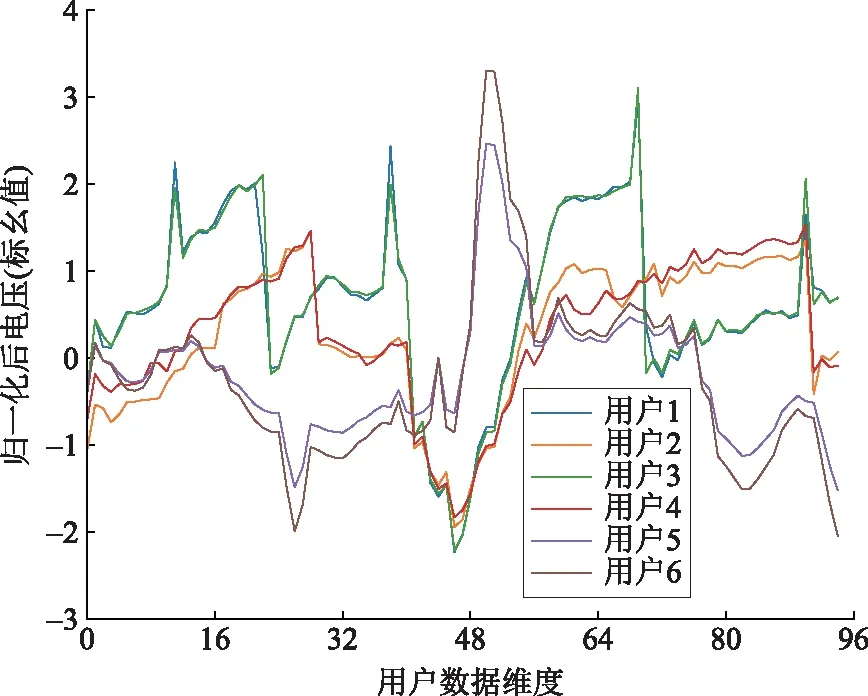
图5 APAA降维后用户电压波动曲线
由图3—5可知,原6个用户的480维数据经PAA算法后降为40维,经APAA算法后降为95维。与原始数据相比,经PAA算法降维后的曲线效果不佳,而经APAA算法降维后仍较好地反映了曲线形态特征及变化规律。
3.3 算例结果
3.3.1 户变关系识别结果
谱聚类过程中聚类数f设定为3,高斯核函数参数σ设定为0.1。本文识别结果为:B台区识别出20户且全部识别正确,A台区中一用户错误识别到C台区,C台区中一用户错误识别到A台区。本文算法结果与实际情况比较见表1。

表1 户变关系识别结果
3.3.2 不同算法结果对比分析
综合比较本文算法、K-Means算法、PAA与谱聚类组合算法,以及PCA与使用层次结构的平衡迭代减少和聚类(balanced iterative reducing and clustering using hierarchies,BIRCH)组合算法这4种算法的性能,以证明本文算法所提算法的准确性。每种算法均重复聚类10次,并取该10次指标结果的平均值为最终结果,以保证算法比较的客观性,结果见表2。
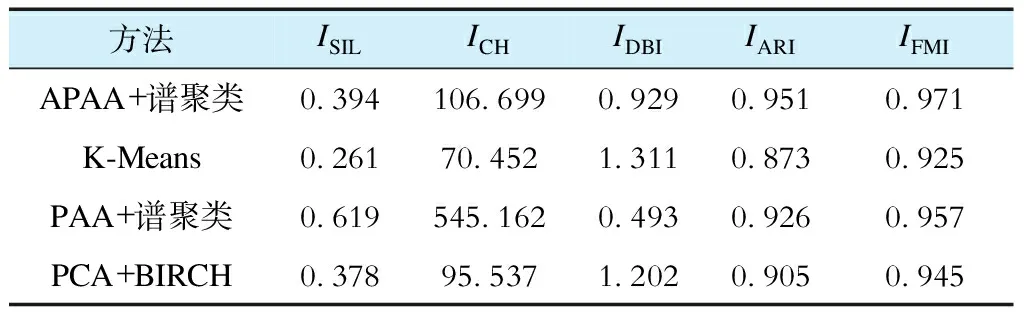
表2 不同算法识别性能对比
从聚类的有效性指标来看,PAA与谱聚类的结合算法与其他算法综合相比,ISIL与ICH更大,IDBI更小,聚类效果更佳;原因是降维程度大,导致样本差异大的部分易被忽略,从而缩短样本间距离,提高了聚类效果,但不能保证良好的准确性。从聚类的准确性指标来看,APAA和谱聚类的结合算法最佳,较其他算法提高程度较大。
综合来看,APAA和谱聚类结合算法明显优于其他算法,APAA算法充分考虑了各时间段的电压变化特征,特征提取效果更佳,在提升聚类效果的同时可提升聚类结果的准确性。
3.4 不同采样间隔和噪声下户变关系识别分析
在工程实际中,由于地域不同,不同台区电表数据的采样间隔也不同,并且电表采集数据时普遍存在噪声影响,导致精度各有偏差。本文从这2个方面入手,分析所提算法在采样间隔和噪声影响下的聚类有效性和准确性。
分别将采样间隔设定为1 h、2 h、4 h和8 h,并为所有电压测试量额外增加标准高斯分布噪声,测得的结果见表3。
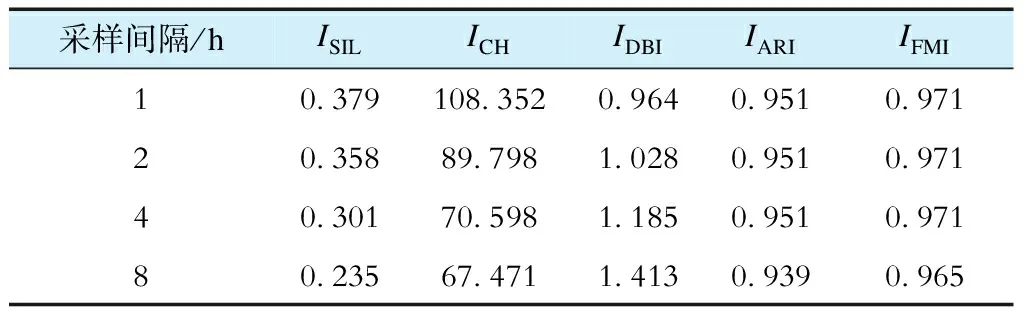
表3 不同采样间隔和噪声下的性能对比
对比3.3节与3.4节结果可知,本文所提算法能有效克服小噪声的干扰,聚类有效性和准确性均不受影响。
4 结论
针对低压配电变压器台区广泛存在户变关系不准确的问题,本文提出基于自适应分段聚合近似和谱聚类算法的户变关系智能识别方法。该方法具有以下特点:
a)采用APAA算法能够达到准确描述电压曲线形态特征和降低数据维度的效果,降低后续聚类算法的计算量,节省算力成本。
b)结合图论思想,采用谱聚类算法度量电压序列间的相似性,自动进行户变关系识别。聚类算法不仅分析了台变和用户电压序列之间的相似性,还分析了用户电压序列之间的相似性,使聚类结果更加准确。
c)本文所提算法在不同采样间隔和噪声下均具有良好的性能指标,且在一定的采样间隔范围内,识别准确率能够保持不变,算法稳定性强。
但本文所提算法仍有一定的改进空间,其研究对象为仅安装单相电表的用户台区,未考虑具有三相四线电表的情况,未能更加全面地反映现实台区的复杂情况。未来将结合该点对所提方法作进一步改进和完善。
猜你喜欢
中学生数理化·中考版(2022年10期)2022-11-10 09:37:38
中学生数理化·中考版(2021年10期)2021-11-22 07:26:40
电子测试(2017年15期)2017-12-18 07:19:27
数学小灵通·3-4年级(2017年2期)2017-05-30 10:48:04
电子制作(2017年2期)2017-05-17 03:55:22
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
电测与仪表(2014年16期)2014-04-22 05:19:40
电测与仪表(2014年13期)2014-04-04 12:04:20
电力需求侧管理(2014年6期)2014-03-20 13:36:07
