
融合MS3D-CNN和注意力机制的高光谱图像分类
2023-03-14 03:50吴庆岗刘中驰贺梦坤
重庆理工大学学报(自然科学) 2023年2期
吴庆岗,刘中驰,贺梦坤
(郑州轻工业大学 计算机与通信工程学院, 郑州 450002)
0 引言
高光谱图像(hyperspectral image,HSI)[1]的光谱维度划分更加细致,与彩色图像包含红、绿、蓝3个光谱波段不同,它由几十甚至上百个光谱波段组成。丰富的光谱信息使HSI具有较强的地物区分能力,在军事侦察、城市规划、农作物估产和环境监测等领域有着广泛的应用,这离不开高光谱图像分类技术。近年来,许多方法被应用于HSI分类任务中,包括支持向量机(support vector machine,SVM)[2]、决策树(decision tree,DT)[3]和最大似然分类法(maximum likelihood classifier,MLC)[4]等。但是,这些传统高光谱图像分类方法只能提取浅层特征,往往忽略了深层特征,导致分类精度受到极大影响。
深度学习在图像深层特征提取方面具有较强的优势,越来越多的学者使用深度学习方法对高光谱图像分类进行研究,其中典型代表是卷积神经网络(convolutional neural network,CNN)[5]。Hu等[6]采用单层卷积对HSI进行特征提取,尝试将卷积神经网络用于高光谱图像分类任务。Chen等[7]采用多层卷积网络对高光谱图像深层特征进行提取,该方法使用少量训练样本提升了分类效果。仅利用光谱信息不能够全面有效地表达高光谱数据特征,在光谱特征基础上融合空间特征是高光谱图像分类的有益补充。一些研究表明,上下文信息可以有效提高HSI分类性能,联合空间信息和光谱信息的分类方法逐渐成为研究热点。Yang等[8]使用两路卷积神经网络提取高光谱遥感图像的空间特征和光谱特征,实验结果表明,空谱联合特征可显著提高HSI的分类精度。但是,二维卷积网络(2D-CNN)需要在光谱和空间2个维度分别进行特征提取,容易丢失光谱信息,导致提取的空谱联合特征不够充分。然而,三维卷积网络(3D-CNN)[9]可以有效提取空谱联合特征,为高光谱图像的精准分类提供基础。Zhong等[10]提出端到端的光谱残差网络(SSRN)对高光谱图像进行分类,以原始的三维数据立方体作为输入,通过3D-CNN同时提取光谱特征和空间特征。齐永锋等[11]结合多尺度与残差思想,从不同感受野提取层次更深、鲁棒性更强的特征,进行高光谱图像分类。Ma等[12]在DBDA网络模型中引入注意力机制细化高光谱特征提取,获得了更好的分类性能。
虽然卷积神经网络在高光谱图像分类领域已经获得较好的性能,但是仍然存在一些问题:如高光谱遥感图像标记样本少,如何在样本受限的情况下提取有效的特征十分关键;其次,深层特征在神经网络各节点的贡献度相同,如何区分特征的不同贡献度是一个难题。针对上述问题,提出一种基于多尺度3D-CNN(multi-scale 3D-CNN,MS3D-CNN)和卷积块注意力机制(convolutional block attention mechanism,CBAM)[13]相融合的高光谱图像分类网络模型(MS3D-CNN-A)。结果表明,在样本受限和地物种类复杂的高光谱图像上,本文方法获得满意的分类结果。
1 基于MS3D-CNN-A的高光谱图像分类网络模型
为克服高光谱图像分类中存在的空间信息利用不充分、样本标记数量不足等问题,基于MS3D-CNN和卷积块注意力机制提出高光谱图像分类方法MS3D-CNN-A,该方法的网络结构如图1所示。首先,利用3D-CNN以特征映射方式从不同感受野提取HSI的光谱特征和空间特征,对二者拼接融合得到空谱特征,以减少光谱信息和空间信息的丢失。其次,引入卷积块注意力机制对空谱特征进行细化,增强显著特征表现,过滤与分类任务不相关的特征,提高地物目标特征的辨识能力。然后,随着模型深度的增加,网络退化和梯度消失等问题接踵而来,采用ResNet思想[14]构建深层网络以提取深层特征,防止网络退化和梯度消失。此外,光谱的高维特性使得分类网络需要大量参数进行训练,但是高光谱图像标记样本少,导致参数提供不足,经常出现过拟合现象。使用Dropout方法[15]在网络训练过程中随机丢弃部分神经元,缓解因需要大量参数导致的过拟合现象。最后,利用Softmax分类器实现对高光谱图像的分类。
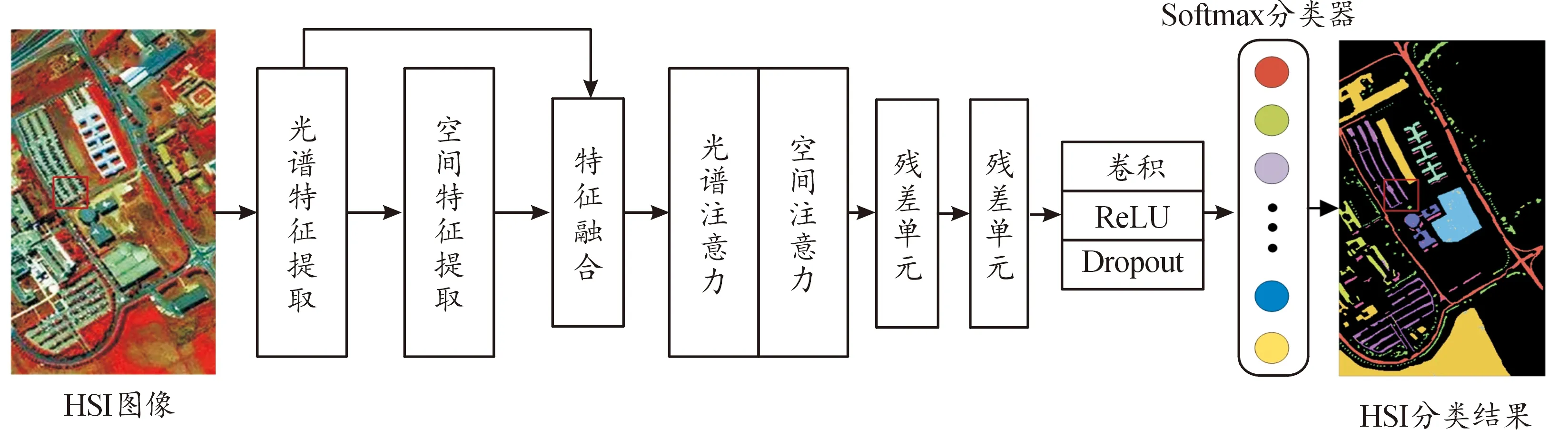
图1 本文高光谱图像分类网络模型结构框图
1.1 多尺度3D-CNN特征提取和融合
多尺度3D-CNN网络结构由多个不同尺度的三维卷积组成,可以提取丰富的上下文信息,为高光谱图像分类提供大量的光谱特征和空间特征。Tran等[16]研究发现卷积核尺度较小的3D-CNN网络可以有效学习视频图像的时空特征。受此启发,将高光谱图像的光谱维看作视频图像的时间维,利用多个小尺度的三维卷积实现对高光谱图像光谱特征和空间特征的提取。多尺度三维卷积计算公式为:
(1)

多尺度三维卷积特征提取和融合模块包含光谱特征提取、空间特征提取和空谱特征融合3个组成部分,结构如图2所示。光谱特征提取包含4个并行的多尺度三维卷积,从不同感受野提取光谱特征,对提取的多尺度光谱特征进行相加运算。高光谱图像除了提供大量的光谱特征外,还包含丰富的与之相互补充的空间特征,空间距离较近的像素通常很大概率属于同类地物。因此,为弥补光谱特征难以有效描述高光谱数据的缺点,在光谱特征基础上融合空间特征对高光谱图像分类是有益的补充。比如,当2个不同的地物受其他光谱的干扰而具有相同的光谱特征时,可以利用形状和纹理等空间特征辅助对其进行分类。所以,引入空间特征可有效解决高光谱分类结果中空间不连续性问题。空间特征提取模块包含2个并行的三维卷积,提取不同尺度的空间特征。在空谱特征融合部分,如图3所示,以拼接方式将光谱特征和空间特征进行融合,通过卷积操作输出空谱联合特征。
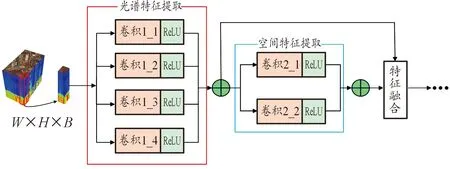
图2 HSI光谱特征和空间特征提取与融合模块结构框图
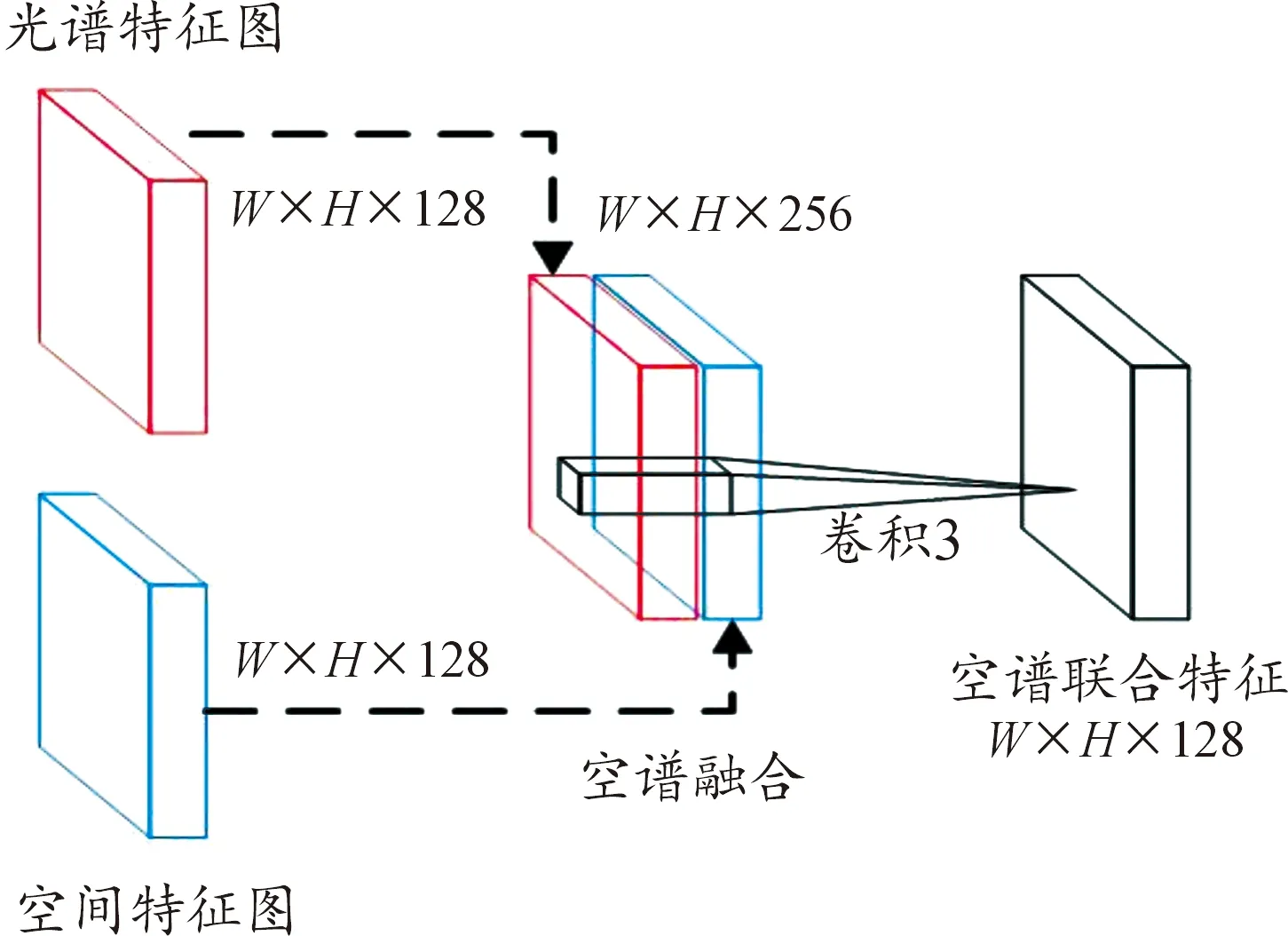
图3 HSI光谱特征和空间特征融合模块示意图
在上述特征提取与融合模块中,卷积核的详细参数如表1所示,其中H和W为空间维大小,B为光谱维大小。在多尺度三维特征提取和融合过程中,为分析从不同感受野提取光谱和空间特征对运算成本的影响,在表1最后一列给出相应卷积核的参数个数。在光谱特征提取过程中,多尺度三维卷积沿光谱维的滑动步长为1,不同尺度需要不同的参数。从表1可以看出,卷积1_x的参数个数随卷积核尺寸的增大而增加。在空间特征提取过程中,由于光谱信息参与空间特征提取的计算,使得卷积2_x的参数个数增加到1282×H×W×B+128(B为HSI图像的光谱维度)。在空谱特征融合阶段,卷积核的参数个数为32 896。参数个数越多,多尺度三维特征提取和融合模块的计算成本越多,具体运行时间在2.4节进行详细讨论。

表1 光谱特征和空间特征提取与融合模块卷积核详细参数
1.2 卷积块注意力机制细化特征提取
为实现对深度特征的细化,Woo等[13]通过计算通道注意力和空间注意力为深度特征分配不同的权重,提出卷积块注意力机制,并在普通图像分类中获得满意的效果。受此启发,本文将卷积块注意力迁移至高光谱图像分类任务中,设计光谱注意力和空间注意力2个级联的子模块,其计算方法为:
F′ =Mc(F)⊗F
(2)
F″ =Ms(F′)⊗F′
(3)
式中:F为高光谱图像特征提取和融合后的空谱联合特征;Mc(·)和Ms(·)分别为光谱注意力子模块和空间注意力子模块;⊗代表乘法运算;F″为经过卷积块注意力机制重新分配权重细化后的空谱联合特征。
1.2.1光谱注意力子模块
光谱注意力子模块是CBAM中通道注意力子模块的改进版本,将对普通图像的通道处理方法迁移到高光谱图像的光谱维,通过关注不同光谱维间的相互关系,生成不同维度的光谱特征权重,其结构如图4所示。
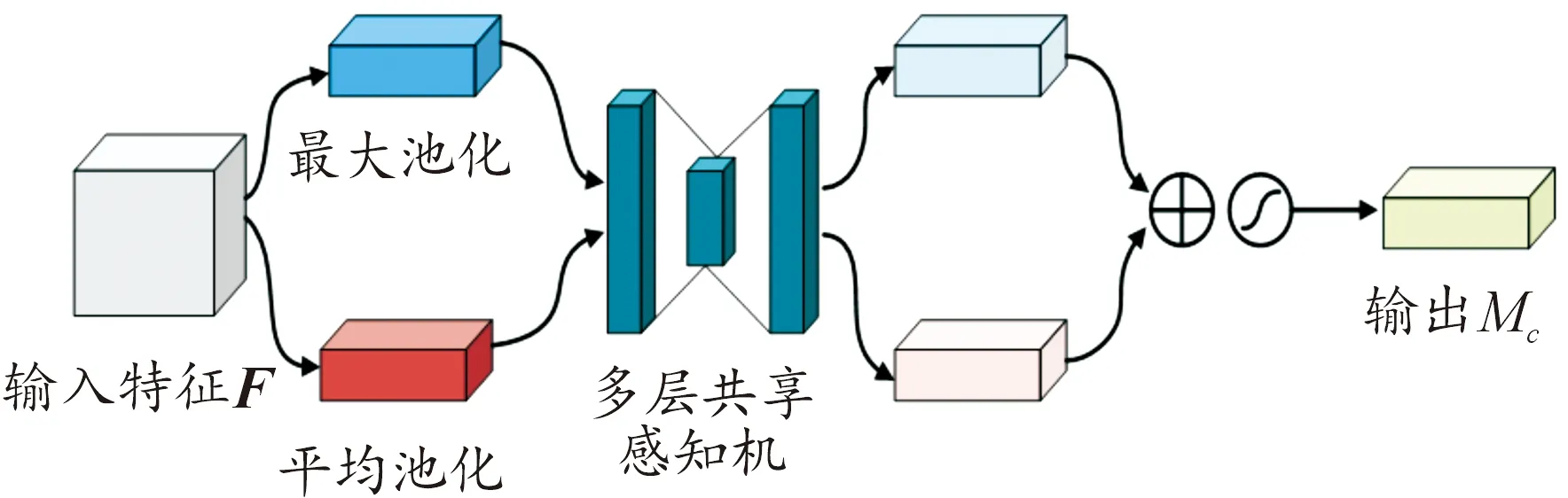
图4 光谱注意力子模块结构

Mc(F) =σ(MLP (AvgPool (F))+
MLP (MaxPool (F)))=
(4)
式中:σ表示Sigmod激活函数;W0∈RC/r×C和W1∈RC×C/r分别表示多层感知机中第1个隐含层和第2个隐含层的权重;r表示特征压缩率。
1.2.2空间注意力子模块
空间注意力子模块关注高光谱图像中相邻像素的空间位置关系,生成与空间特征相关的不同权重,模块结构如图5所示。光谱特征F′作为该模块的输入,在光谱维度依次经过最大池化和平均池化进行维度压缩,之后依次经过卷积操作和激活函数得到重新分配的权重Ms∈RW×H×1,即Ms(F′)(其中s表示对高光谱图像空间维进行注意力处理后的结果)。空间注意力计算公式为:
Ms(F)=σ(f7×7([AvgPool (F); MaxPool (F)]))=
(5)
式中:σ表示激活函数;f7×7表示大小为7×7的卷积操作。

图5 空间注意力子模块结构
1.3 全卷积残差网络结合Softmax分类器。
在高光谱图像分类网络模型MS3D-CNN-A中,空谱联合特征经过卷积块注意力细化后,输入到残差连接块、预分类卷积块和Softmax分类器,具体如图6所示。若将2个卷积操作和Relu激活函数看作某个函数F,则残差结构的计算公式为:
xm=F(xm-1)+xm-1
(6)
式中:xm-1和xm分别为残差块的输入和输出,当F(xm-1)=0时,xm=xm-1被称为恒等映射。之后是通道数与地物种类数N一致的预分类卷积,输出W×H×N的局部特征图。在预分类卷积后,为防止过拟合,加入Dropout操作随机丢弃部分神经元,最后通过Softmax分类器完成对高光谱图像的分类。
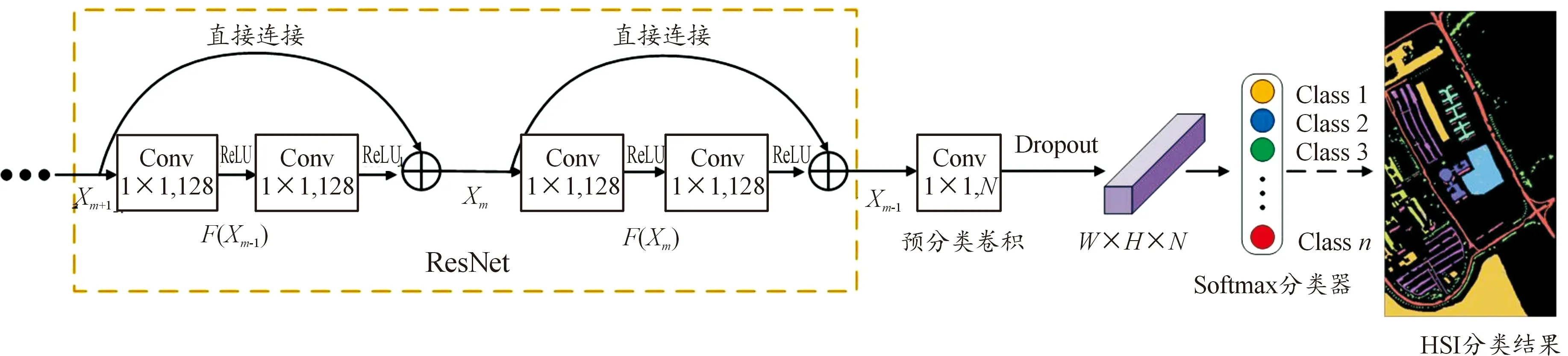
图6 全卷积残差网络分类模块结构
2 实验结果分析
为验证MS3D-CNN-A高光谱图像分类方法的有效性,在常用高光谱遥感数据集上进行地物分类实验,使用总体精度(overall accuracy,OA)、平均精度(average accuracy,AA)和Kappa系数(Kappa coefficient)3种性能指标评估不同高光谱图像分类算法的性能。
2.1 数据集
实验采用3种经典的高光谱图像测试本文方法的分类性能,即印第安松树(indian pines,IP)、帕维亚大学(pavia university,PU)和萨利纳斯谷(salinas valley,SV)。3种伪彩色高光谱图像如图7所示。

图7 实验采用的高光谱图像
印第安松树图像:由机载可见光红外成像光谱仪(AVIRIS)于1992年在美国印第安纳州一块印度松树进行成像得到。该数据集包含16个地物覆盖种类,共有145×145个像素。光谱带的波长范围为0.4~2.5 μm,通过去噪处理去除20条噪声带,剩下的200个光谱带作为研究的对象。
萨利纳斯谷图像:利用AVIRIS传感器在美国加利福尼亚州萨利纳斯谷扫描采集得到。该图像包含16个地物种类,共有512×217个像素,空间分辨率为3.7 m/像素。光谱带的波长范围为0.4~2.5 μm,经过去噪处理去除20条光谱带,其余204条光谱带用于实验分析。
帕维亚大学图像:采用反射式光学成像光谱仪(ROSIS-3)扫描意大利帕维亚大学场景得到。该数据集包含9个地物种类,共有610×340个像素,空间分辨率为1.3 m/像素。光谱带的波长范围为0.43~0.86 μm,通过去噪处理去除12条噪声带,剩下的103个光谱带用于分析高光谱图像分类算法的性能。
2.2 实验环境
为保证实验公平性,所有方法均不对训练集做任何预处理,且都在同一台图形工作站上实现。该工作站配置了32 GB内存和NVIDIA GeForce GTX3090 Ti 的GPU,详细配置参数如表2所示。

表2 实验环境配置参数
2.3 参数设置
高光谱图像输入样本的空间尺寸对分类结果有较大影响。为确定网络输入样本的尺寸,根据地物覆盖的稀疏程度,选取帕维亚大学和萨利纳斯谷图像进行实验,将输入样本大小设置为5×5、7×7、9×9、11×11和13×13,以5%样本作为训练集,5%验证集,90%测试集,根据分类结果确定该参数的最佳取值。从表3可以看出,随着网络输入尺寸的增加,训练样本包含的空间信息逐渐增多,总体精度、平均精度和Kappa系数均有所增加。然而,当输入尺寸大于9×9时,训练样本包含过度复杂的空间信息,为特征提取和分类任务带来干扰,3个指标开始下降。因此,本文高光谱图像分类网络模型的输入及输出尺寸均设置为 9×9。

表3 输入样本尺寸对分类精度的影响 %
在本文实验中,所有方法的输入样本尺寸均设置为9,学习率为0.001,Dropout正则化参数为0.5,对每个方法进行100次迭代训练。为减少训练开支,采用早期停止策略(early stopping strategy),即如果验证集的分类精度在20次迭代后仍然保持不变,则训练过程将自动终止。
2.4 实验分析与讨论
为分析本文高光谱图像分类方法MS3D-CNN-A的性能,与经典的RBF-SVM[18]、Li’CNN[19]、M3D-DCNN[20]和DBDA[12]方法进行对比实验。此外,将本文方法MS3D-CNN-A与去除注意力机制的版本MS3D-CNN进行对比实验以验证注意力机制的有效性。在IP、PU和SV 3个高光谱数据集进行实验,每组实验随机抽取5%、10%和15%样本作为训练集和验证集,其余作为测试集,每组实验重复10次,取平均值统计总体精度OA、平均精度AA和Kappa系数。对比实验分类结果如表4—6所示。
为验证本文方法在有限样本高光谱图像上的分类性能,首先利用IP数据集进行分类实验,结果如表4所示。

表4 不同方法在IP数据集上取5%、10%和15%训练样本分类性能
由于RBF-SVM仅利用浅层特征,导致分类性能不佳。Li’CNN和M3D-DCNN方法提取深度特征和多尺度特征,分类性能显著提升,但是由于训练样本不足和特征权重均匀,导致分类精度仍有待提高。从MS3D-CNN网络分类结果看,光谱注意力和空间注意力模块细化空谱特征作用明显。与双分支注意力网络DBDA相比较,本文方法MS3D-CNN-A在5%训练样本下的OA、AA和Kappa系数分别提升0.60、2.12和0.60个百分点;在10%和15%训练样本下,3个评价指标亦均有明显提升。整体来看,虽然IP高光谱数据集训练样本少,地物种类复杂,但是本文方法通过卷积块注意力机制对提取的空谱特征进行细化筛选,过滤与分类任务不相关的空谱特征,仍然取得了较高的分类精度,在不同训练样本下的平均OA达到89.70%。对IP数据集5%训练样本的分类结果进行可视化,通过比较不同方法分类结果与Ground truth之间的差异,可以看出本文方法的分类结果最接近真值标签,如图8所示。
第2组实验采用包含相同地物种类数量、空间分辨率更高的SV高光谱数据集,分类结果如表5所示。本文方法融合空谱特征,空间信息丰富,与同样采用空谱特征的M3D-DCNN方法相比,在5%训练样本下OA、AA和Kappa系数分别提升5.31、1.94和5.13个百分点。与去除注意力机制的MS3D-CNN方法相比,在5%训练样本下,3个评价指标分别提升3.95、3.00和4.33个百分点;在10%和15%训练样本下,各指标亦有较大幅度提升。与双分支注意力网络DBDA相比,在5%训练样本下均获得不低的评价指标;在更多训练样本下,各指标获得最高值。与IP数据集相比,SV高光谱数据集包含更多的训练样本,本文方法利用融合后的空谱特征取得更高的分类精度,不同训练样本下的平均OA达到97.63%。对SV数据集5%训练样本的分类结果进行可视化,通过比较每种方法分类结果与Ground truth之间的差异,可以看出,卷积块注意力机制有助于提升高光谱图像分类性能,如图9所示。
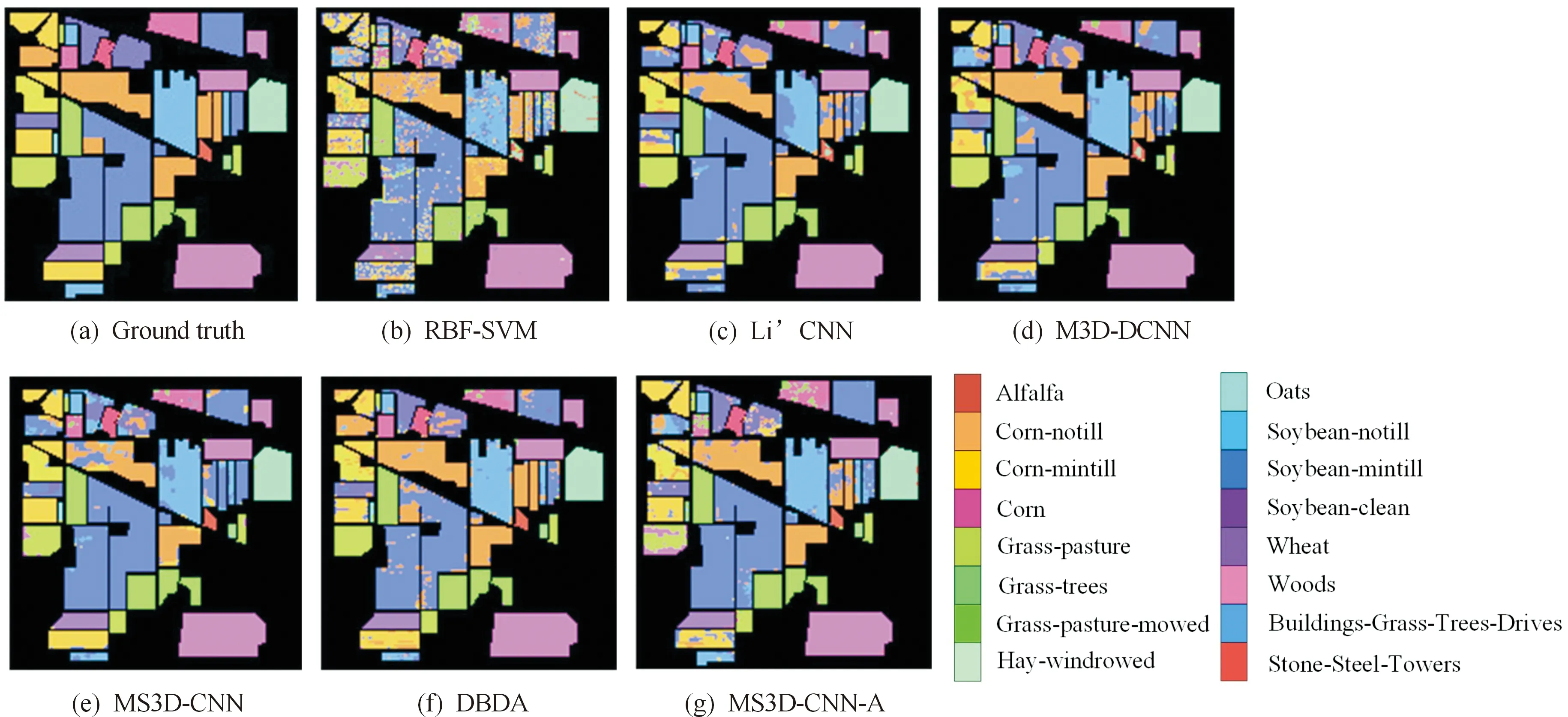
图8 不同方法在IP图像上取5%训练样本分类效果

表5 不同方法在SV数据集上取5%、10%和15%训练样本分类性能
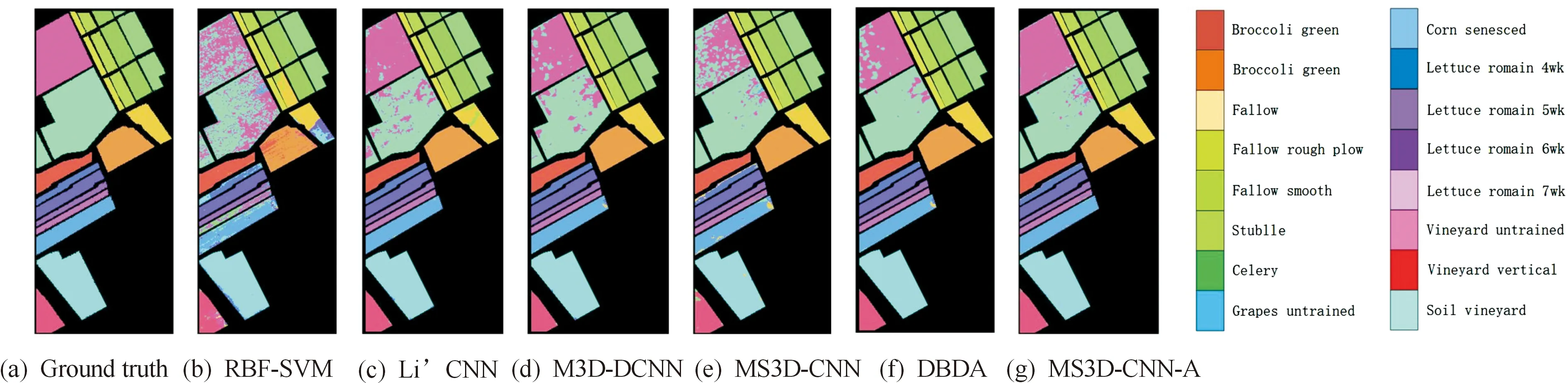
图9 不同方法在SV图像上取5%训练样本分类效果
最后,在光谱分辨率较低、空间分辨率更高的高光谱数据集PU上进行分类实验,结果如表6所示。可以看出,本文MS3D-CNN-A方法在5%、10%和15%训练样本下,3个评价指标OA、AA和Kappa系数均取得最高值。与前面2个高光谱数据集IP和SV相比,本文方法通过多尺度3D卷积和融合后的空谱特征得到最好的分类结果,在不同训练样本下的平均OA达到98.61%。对5%样本作为训练集的分类结果进行可视化,每种方法的分类结果与Ground truth进行对比,可以看出本文方法的分类结果最接近真值标签,如图10所示。
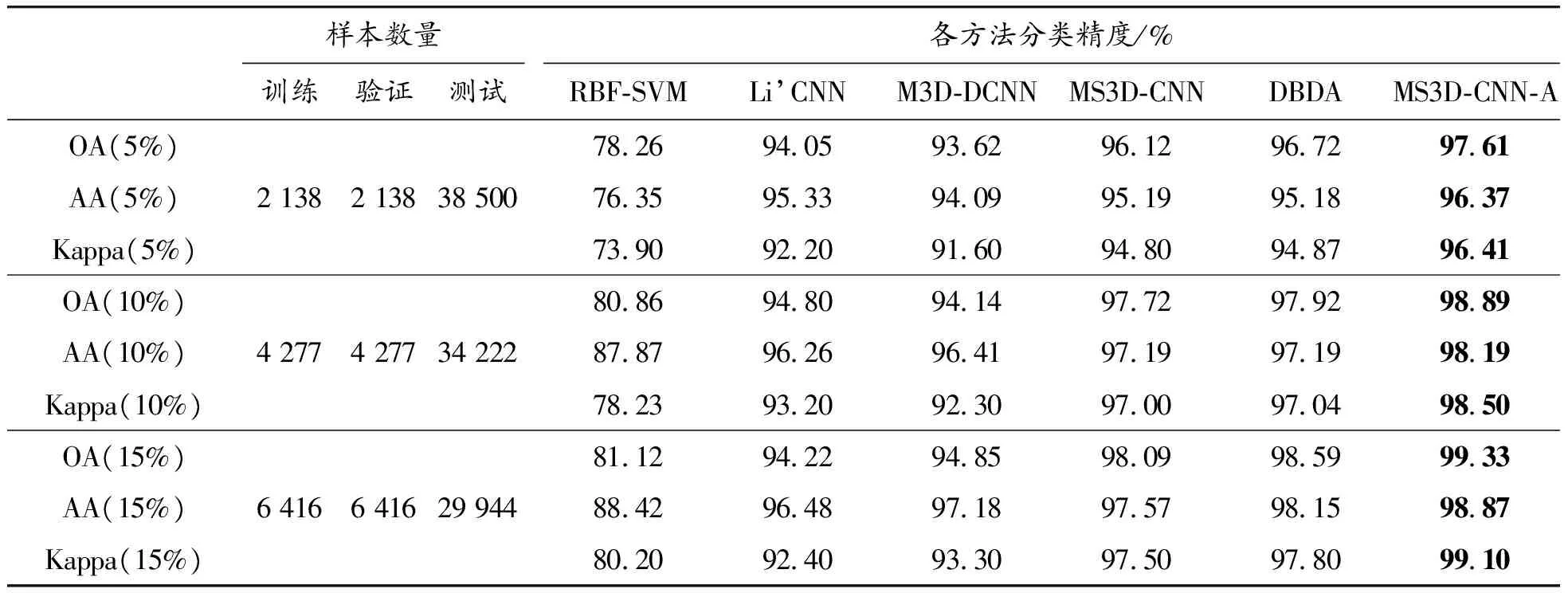
表6 不同方法在PU数据集上取5%、10%和15%训练样本分类性能

图10 不同方法在PU图像上取5%训练样本分类效果
为分析算法的时间性能,选取光谱维数不同的PU和SV两幅高光谱图像的5%作为训练样本进行实验,不同数据集的训练时间和测试时间如表7所示。可以看出,本文方法MS3D-CNN-A的训练时间和测试时间略低于多尺度卷积网络M3D-DCNN,主要是因为本文方法比M3D-DCNN网络使用了更少的三维卷积操作,缩减了网络的运行时间。由于RBF-SVM和Li’CNN算法模型和网络结构相对简单,训练速度较快,运行时间明显低于本文方法和M3D-DCNN网络。而DBDA方法利用DenseNet丰富的训练参数,收敛速度更快,其训练时间和测试时间低于本文方法。总之,本文方法在牺牲少量运行时间的情况下显著提高了高光谱图像的分类精度。
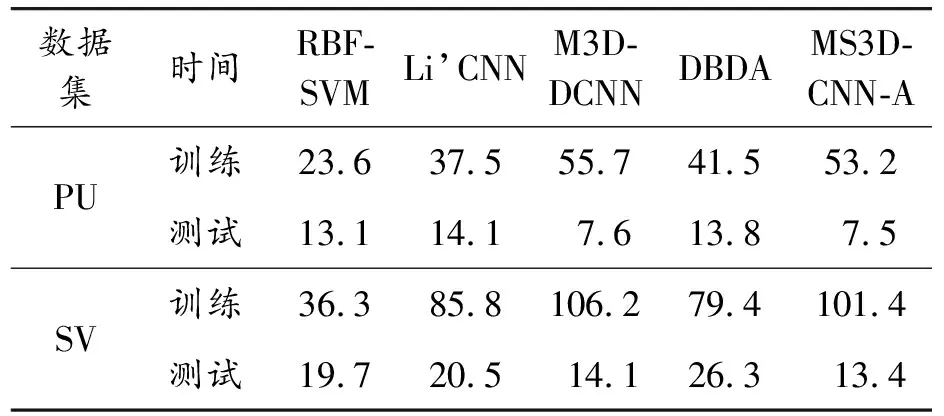
表7 不同方法在PU和SV高光谱数据集的训练时间和测试时间 s
参数量(Params)和每秒浮点运算次数(FLOPs)是评估深度学习网络复杂度的2个重要指标。为分析本文方法及光谱注意力子模块(S)和空间注意力子模块(P)的网络复杂度及对分类精度的影响,选取帕维亚大学数据集的5%作为训练集进行分类实验,结果如表8所示,其中,MS3D-CNN为本文方法去除S模块和P模块后的网络模型,S(AvgPool)和S(MaxPool)分别表示只含有全局平均池化和全局最大池化的光谱注意力子模块。
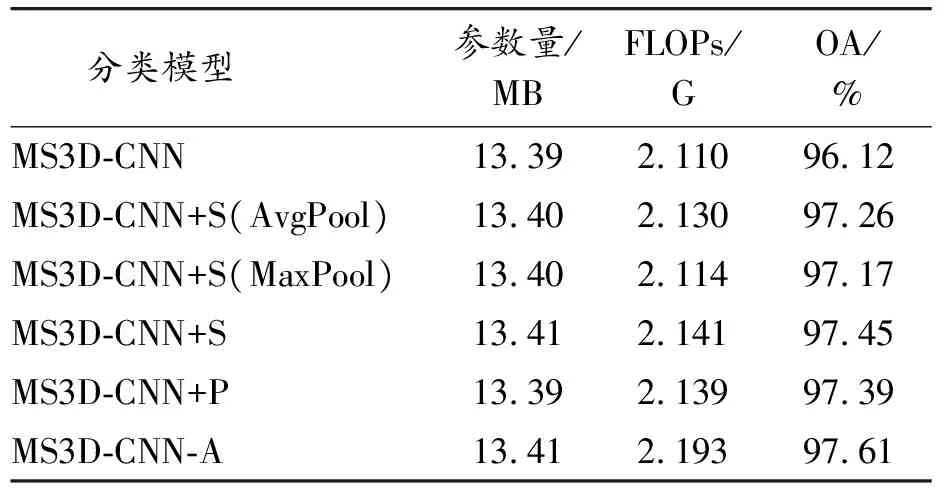
表8 本文网络模型含不同组成模块时参数量、FLOPs和OA
可以看出,与MS3D-CNN相比,虽然S和P 2个模块的每秒浮点运算次数有所升高,但是升幅在0.03左右,而S(AvgPool)和S(MaxPool)2个模块升幅不超过0.02,这表明全局平均池化和全局最大池化对模型运算复杂度的影响几乎可以忽略。从参数量角度看,S模块需要20 K的参数量,P模块需要的参数量更少。S(AvgPool)和S(MaxPool)2个模块仅需要10 K 的参数量,而模型总体参数量在10 M以上,前者占比不足千分之一,故全局平均池化和全局最大池化对模型空间复杂度的影响非常小。从分类精度看,S模块和P模块不同程度地增加了MS3D-CNN方法的分类精度。在光谱注意力子模块S中,全局平均池化较全局最大池化对分类精度的提高效果更加明显。总体来说,全局平均池化和全局最大池化对本文方法运算复杂度和空间复杂度的影响几乎可以忽略,但是对高光谱图像分类精度的提升作用明显。
3 结论
在高光谱图像分类中,针对标记样本少、空间信息利用不足以及特征区分度不够明显等问题,提出一种新型融合卷积块注意力机制的多尺度MS3D-CNN-A网络模型。在IP、PU和SV 3个高光谱数据集上的实验表明,相比于传统高光谱图像分类方法和多尺度三维卷积网络,本文方法在牺牲少量运行时间的情况下,总体精度、平均精度和Kappa系数3项评估指标表现最好,分类效果提升明显。在未来的工作中,将尝试针对少样本问题进一步优化网络结构,降低网络运算成本,在样本更加受限的情况下提高网络的分类性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
科技创新与应用(2020年6期)2020-02-29
电子制作(2018年19期)2018-11-14
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
北京理工大学学报(2016年6期)2016-11-22
第二课堂(课外活动版)(2016年2期)2016-10-21
电视技术(2016年9期)2016-10-17
系统工程与电子技术(2016年7期)2016-08-21
噪声与振动控制(2015年4期)2015-01-01
