
基于DeepLabV3s的曳引轮磨损测量研究*
2023-03-11 07:56:42刘士兴汪一丹王金博
机电工程 2023年2期
刘士兴,汪一丹,王 野,王金博
(1.合肥工业大学 微电子学院,安徽 合肥 230009;2.安徽省特种设备检测院,安徽 合肥 230041)
0 引 言
随着我国经济社会的快速发展和城镇化速度的加快,高层建筑中必不可少的电梯的数量快速增加。2020年我国电梯产量达到了105万台,在电梯领域已经成为产能最大、配套最完善、出口最多的国家[1]。
曳引系统是电梯中重要的组成部分,用于提供动力、驱动轿厢的正常运行[2]。在电梯的运行过程中,曳引轮与钢丝绳反复摩擦,导致绳槽面产生磨损[3]。如果其过度磨损,可能引发钢丝绳断裂、轿厢振动、冲顶等事故[4],对电梯的安全运行具有重大影响。
根据调查,使用年限较久的电梯都存在曳引轮磨损严重、曳引力不符合要求的情况,部分电梯的绳槽出现缺损和裂纹[5],存在比较严重的安全隐患。因此,按时检测曳引轮的磨损情况对于电梯的安全运行意义重大。
曳引轮磨损量传统测量法包括目视法、角尺与塞尺结合法、橡皮泥或塑性胶法等[6]。陈本瑶等人[7]提出了一种规塞式工装测量法,该方法可以同时测量绳槽宽度、深度以及切口上宽度等多个信息,测试精度高;但其通用性不强。
非接触式测量有利于提高测量的自动化水平,降低人工成本[8]。谢晓娟等人[9]提出了一种基于图像处理的曳引轮磨损识别方法,该方法不仅简单有效,还可以降低检测的成本;但该方法不适用于绳槽磨损均匀的检测情况[10]。陈建勋等人[11]将激光三角法应用于曳引轮磨损的非接触测量中,该方法具有检测精度高、自动化程度高等特点;但其无法实现便捷检测,且实时检测的可操作性差。林永森等人[12]提出了一种基于线激光位移法的磨损检测法,该方法测量精度高,与其他方法相比效率也有所提升;但其有效测试区域长度有限。刘士兴等人[13]研制了一种基于单目视觉的曳引轮磨损检测系统,完成了对曳引轮磨损的非接触测量,且与传统方法比,其测量的精度更高。
为了提高计算效率,研究人员进一步提出了一种基于机器视觉的曳引轮磨损检测方法[14]。该方法解决了弱光环境下测量不准确的问题;但其测量过程中需要人工选取测量点,因此,其自动化程度还有待于提高。
为了提高电梯曳引轮磨损测量的精度和自动化程度,笔者提出一种电梯曳引轮磨损自动测量算法。
通过改进后的模型DeepLabV3s,笔者对制作好的数据集进行训练,将曳引轮与钢丝绳区域划分,并采用融合曳引轮特征的图像处理算法,实现边缘快速提取、目标区域截取以及磨损点定位的目标;最后,在实验平台进行测量,以验证该算法的精度与可行性。
同时,根据国家相关标准,笔者建立曳引轮磨损物理模型,以在不同光照环境下可以对磨损进行精准测量。
1 曳引轮磨损自动测量系统
1.1 曳引轮绳槽磨损模型
电梯曳引轮绳槽分为凹型槽、半圆槽、V形槽等[15]。笔者以带切口的V形槽为研究对象,使用工业相机对V形槽磨损量进行非接触测量。
曳引轮磨损测量系统示意图如图1所示。

图1 曳引轮磨损测量系统示意图
磨损主要是压力和运动摩擦的产物[16]。根据曳引轮检测国家标准,在未磨损情况下,曳引轮绳槽底部到钢丝绳外缘最大间距为6 mm,当间距小于3 mm时,需严密监测。
假设曳引轮绳槽两侧磨损均匀,曳引轮绳槽的磨损量即为钢丝绳的下沉量。为实现下沉量的计算,笔者基于曳引轮实际特征构建V形槽截面的物理模型。
曳引轮磨损物理模型如图2所示。
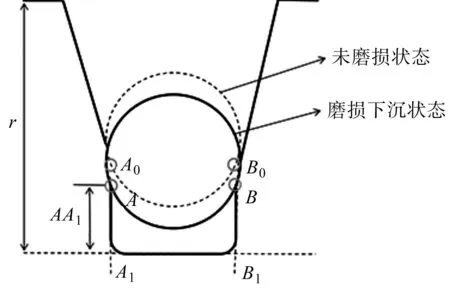
图2 曳引轮磨损物理模型r—曳引轮绳槽深度;AA1—绳槽切口长度
由图2得:当曳引轮未磨损时,A0为钢丝绳与绳槽的左侧接触点,B0为右侧接触点。从A0、B0两点垂直于绳槽底部构建两条直线,与绳槽底部延长线交于A1、B1。忽略钢丝绳的磨损,当曳引轮发生磨损后,钢丝绳竖直下沉,A0、B0移动至A、B两点,A、B即为磨损点。
1.2 算法流程
基于曳引轮磨损物理模型,笔者提出一种基于改进DeepLabV3的磨损自动测量算法。该算法基于PyCharm平台,使用python语言开发,分为语义分割和图像处理两个模块。
曳引轮磨损自动测量算法流程如图3所示。
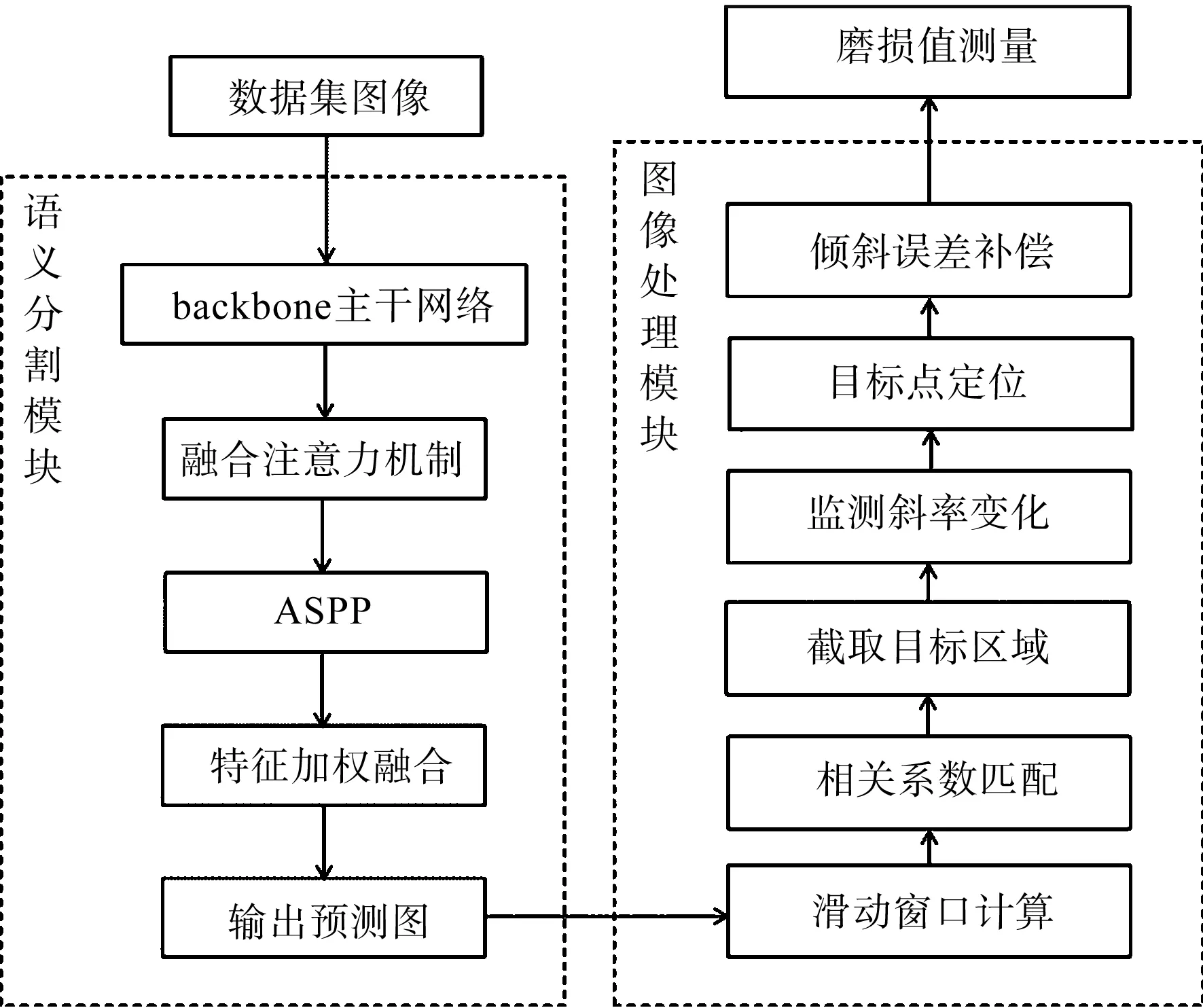
图3 曳引轮磨损自动测量算法流程
由图3可知:语义分割模块主要用于解决原图像纹理复杂、轮廓不清晰、干扰性特征点过多、受光照影响大等问题,通过深度卷积神经网络对制作好的数据集进行训练,实现对钢丝绳和曳引轮的图像分割;
图像处理模块主要用于解决传统目标区域匹配方法限制物距的问题,以及测量的实时性和准确性较差等问题,以实现实时、自动化且不受相机物距限制的磨损值测量的目的。
2 DeepLabV3模型
2.1 模型性能对比
在工业领域中,采用机器视觉和非接触式测量的方式,可以减少人为干预,提高响应速度[17]。目前,融合深度学习的非接触式测量方式在工业中得到了广泛应用。其中,语义分割通过神经网络进行数据处理,在提升特征提取能力的同时,也在特征提取过程中去除了人工的干预,实现了特征提取自动化和端到端学习的目的,有利于系统的自动化。
笔者使用fully convolutional networks(FCN)、DeepLabv3、Unet、DeepLabV3+这4个网络模型,对曳引轮数据集进行训练测试。测量目标为带切口的V形槽。
为收集足够的训练样本进行训练,需建立曳引轮磨损数据集。笔者使用工业相机采集不同光照、角度下的曳引轮图片,用标注软件LabelMe对采集到的图像进行标注,利用数据增强方法提高深度学习模型精度与泛化能力[18],最终得到完整的数据集(图片共3 055张,其中训练集2 138张,测试集917张)。
笔者采用相同损失函数、学习率、学习率衰减函数优化器,分别对数据集训练相同的epoch,针对训练后的模型进行预测效果评价;采用平均交并比(mean intersection over union,MIoU)和准确率(accuracy,Acc)作为评价指标。
MIoU计算方法如下式所示:
(1)
式中:i—曳引轮图像实际值;j—预测值;k+1—类别个数(包括背景);pij—将i预测为j的个数;pji—将j预测为i的个数;pii—将i预测为i的个数。
模型性能比较如表1所示。

表1 模型性能比较
由表1可得:除FCN模型表现较差外,其余模型相差不大,DeepLabV3表现较好。
由于曳引轮绳槽边缘预测的准确性对测量结果影响最大,而DeepLabV3在绳槽区域表现最佳,经综合考虑,笔者最终选用DeepLabV3为训练模型。
2.2 DeepLabV3网络
DeepLab网络由CHEN L C等人[19]在2014年提出,是语义分割领域较为先进、优秀的算法。相比于其他网络,DeepLabV3网络舍弃了全连接层,主干网络Backbone使用Resnet101,并对空间金字塔池化进行了改进,解决了分辨率下降、多尺度信息等问题。
为解决输出图像分辨率过低的问题,DeepLabV3中使用空洞卷积。空洞卷积中的膨胀率可以扩展滤波器的感受野,膨胀率越大,其感受野也越大。
当使用空洞卷积,则卷积输出和输入关系的表达式如下式所示:
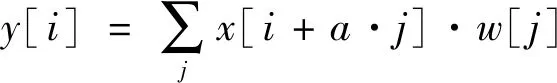
(2)
式中:x[i]—输入;y[i]—输出;a—膨胀率;w[j]—卷积核。
当膨胀率设为2,空洞卷积结构如图4所示。
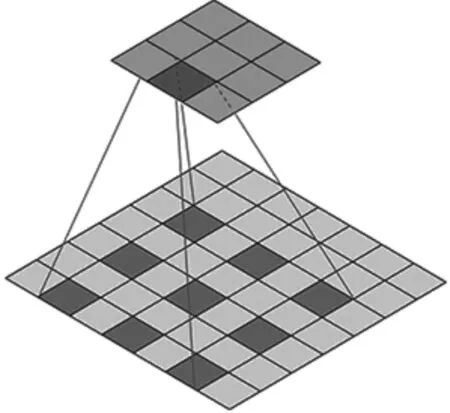
图4 空洞卷积结构
由图4可得:大小为3×3的卷积核可以覆盖5×5的区域。以此类推,当膨胀率设为3,则卷积核可以覆盖7×7的区域。
在光照较强或图片模糊状态下,采用DeepLabV3网络进行图片分割时,会导致误判,对后续图像处理产生干扰,影响最终的测量结果。因此,需要对其做适当的改进处理。
2.3 改进的DeepLabV3网络
光照对曳引轮图像的分割存在一定影响。预测图像不可避免地会出现误判区域,对后续图像处理、磨损值测量影响较大。为了解决这个问题,笔者提出一种融合SEnet和ECAnet双注意力机制的DeepLabV3网络—DeepLabV3s。
融合双注意力机制的DeepLabv3s网络结构如图5所示。
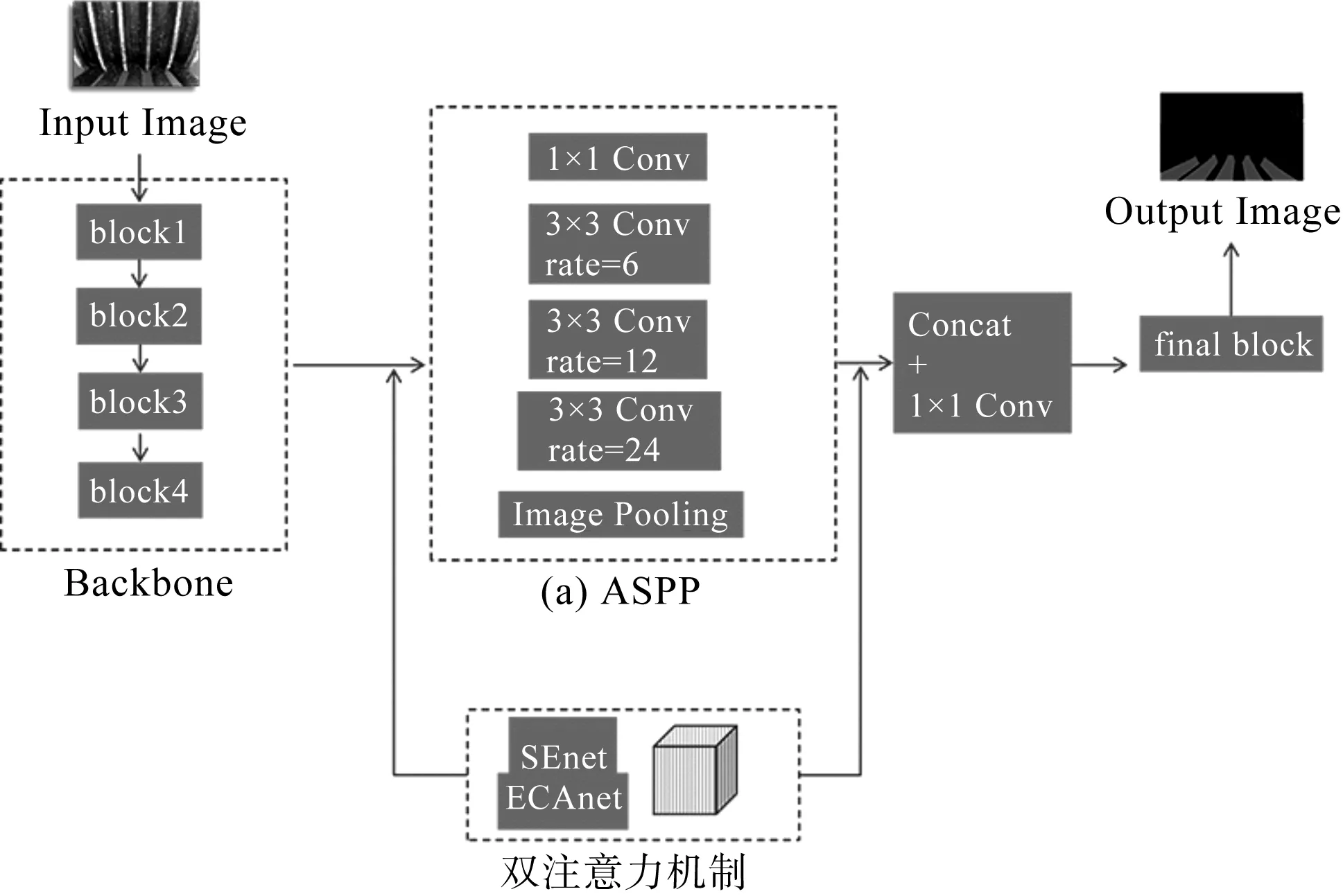
图5 融合双注意力机制的DeepLabv3s网络结构
SEnet(即通道注意力机制)通过分配给每个通道权重,以此来平衡不同通道的作用力,解决因不同通道所占权重不同而导致的损失问题。
最终的特征值为:
ω=σ(f{w1,w2}(g(χ)))
(3)
式中:σ—Sigmoid函数。
f(w1,w2)(y)表达式为:
f(w1,w2)(y)=w2·ReLu(W1y)
(4)
全局平均池化函数g(χ)表达式为:
(5)
SEnet通过提取图像特征,得到特征图的维度[C,H,W],在平均池化后,将通道[H,W]压缩至[1,1],再经过两个全连接层,增强通道间的相关性,得到每个通道的权重,然后作用于特征图,使得每个通道各自乘以对应的权重。
ECAnet是一种轻量级的通道注意力机制,通过自适应函数改变卷积核大小,实现跨通道的信息交互。
自适应函数如下:
(6)
其中:γ=2,b=1。
将SEnet和ECAnet注意力机制融合在DeepLabV3的网络结构中,减轻了SEnet带来的维度缩减,同时可以有效地增强多维度信息交互。
2.4 改进后的模型性能分析
预测图对比如图6所示。

图6 预测图对比
由图6可得:由于不同类别的训练权重不平衡,使用无注意力机制的DeepLabV3时,其预测结果常常会出现误判区域,对后续的图像处理造成较大影响,使测量结果不稳定。
笔者提出的改进模型解决了因通道权重不平衡而导致的损失问题,更专注于所需类别,有效地降低了其误判几率。
模型性能对比如图7所示。
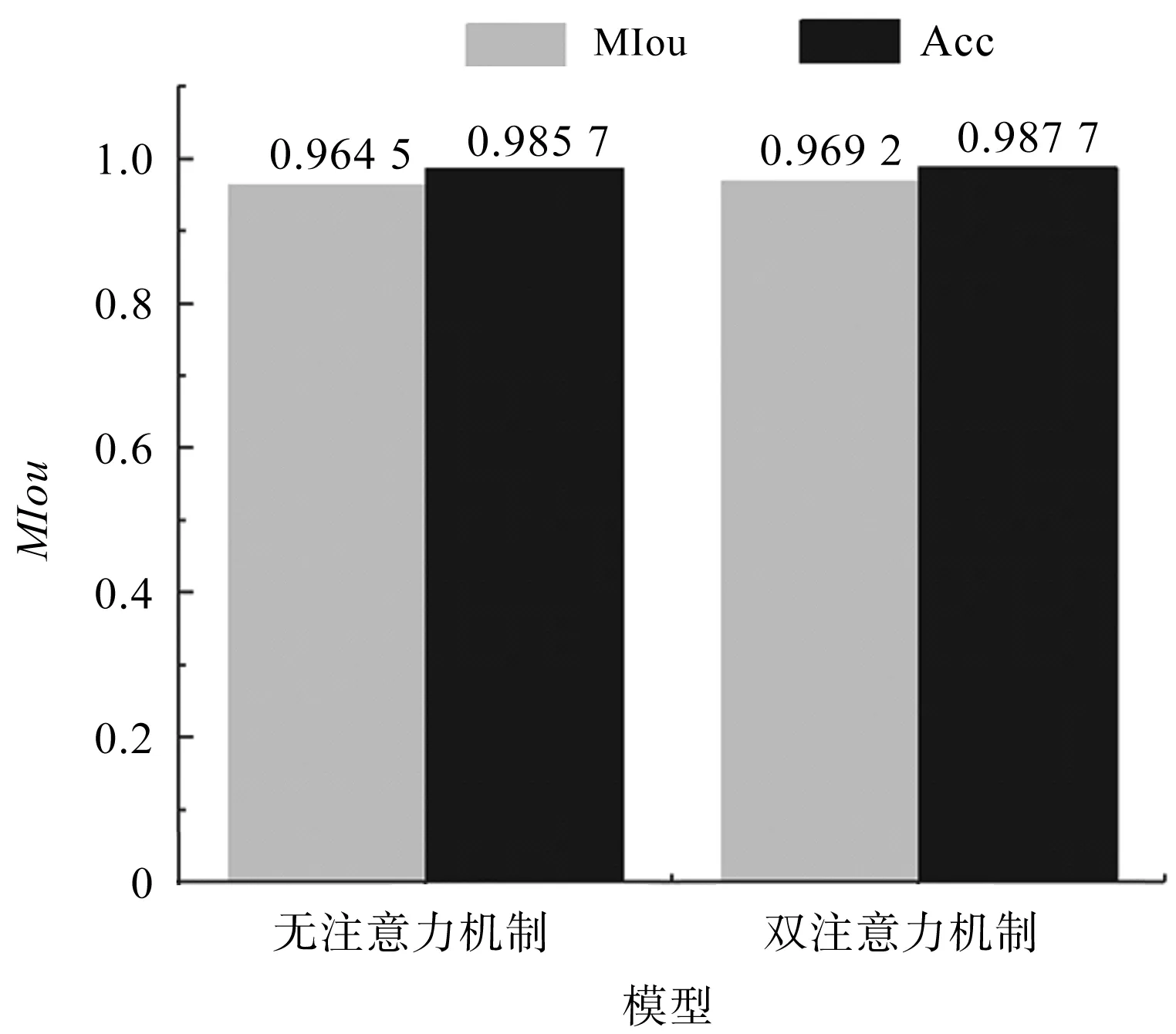
图7 模型性能对比
由图7可得:DeepLabV3在曳引轮数据集中表现良好;MIoU可达0.964 5,改进后的模型对MIoU的提高比较有限,但是对于类别的判断能力有很大提升。
Loss值对比如图8所示。
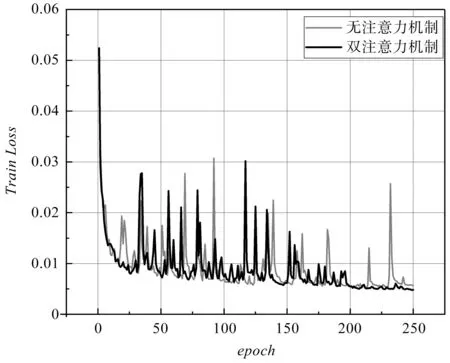
图8 Loss值对比
由图8可得:融合双注意力机制的DeepLabV3模型Loss值下降速度相对较快,收敛效果更好。
该结果表明:改进后的算法精度有一定的提升,有效消除了图像中的预测偏差,明显减轻了光照对语义分割效果的影响,使其对光线鲁棒性更强,有利于后续图像的处理和磨损测量精度的提升。
3 曳引轮磨损测量算法
3.1 基于预测图像的目标匹配
为了实现对目标绳槽的精准提取,并为后续目标点的提取做准备,笔者采用相关匹配法进行模板匹配。
模板匹配即是在图像中用滑动窗口遍历像素,判断其是否与模板相似,计算模板与窗口区域的相关系数,当相关系数足够高时,则认定为要寻找的目标;若匹配到了多个区域,则通过设置阈值得到目标的最佳匹配。
相关系数的计算如下式所示:
(7)
式中:T(m,n)—模板图像;S(w,h)—搜索图像;w,h—模板的高度和宽度;Sij—模板与搜索图重合的子图;i,j—子图在被搜索图中的左上角坐标。
为了加快匹配速度,当目前子图的相关系数小于一定阈值时,搜索步长加大。在相关匹配法中,由于亮度变化对相似度的计算影响较小,满足曳引轮在不同光照条件下测量的需求。
目标匹配如图9所示。

图9 目标匹配
由图9可得:该算法对目标绳槽匹配的效果较为精准(其中,方框表示匹配到的目标区域)。
3.2 磨损点定位
为了计算出曳引轮的磨损量,需要监测磨损点的变化,以精确定位磨损点。
由图2所示物理模型可知:AA1、BB1几乎垂直于绳槽底部,水平方向变化较小,而A、B两点磨损处水平、垂直方向变化较大。以拍摄图片左上角为坐标原点,竖直向下为y轴正方向,水平向右为x轴正方向。
像素点的斜率变化监测如图10所示。

图10 像素点的斜率变化监测
由图10可得:像素点y值为目标绳槽边缘在坐标中的y轴坐标,磨损处的像素点y值处于[1 050,1 080]区间内,AA1则处于斜率几乎不变的[1 035,1 050]。当斜率变化从几乎不变的区间滑动至变化较大的区间,即可定位至磨损点。由于相机水平位置的偏差,绳槽左侧和右侧斜率存在不可避免的误差,但其变化趋势与实际值一致。
磨损点检测图如图11所示。

图11 磨损点检测图
图11中标注的两个点表示检测到的磨损点A、B。
实验结果表明:曳引轮磨损检测系统目标区域提取准确,目标点检测较为精准,对环境要求不高,在实际应用中具有优势;与传统方法相比,该检测系统对设备的要求较低,其测量方法简便,对相机测量物距的要求较为宽松,可以取得较高的自动化程度。
3.3 磨损量测量
定位到磨损点A、B后,可由像素点差值计算磨损后切口投影至图像中的长度。
绳槽的磨损量A0A为:
A0A=a0-a1
(8)
式中:a0—未磨损的绳槽切口实际长度,即A0A1;a1—磨损后的切口实际长度,即AA1。
根据相机的成像原理,实际长度与投影至二维图片中对应长度的比值为比例系数α。
由下式可得a1:
(9)
式中:a2—绳槽切口长度投影在图片中的尺寸;r—绳槽实际深度;r1—绳槽深度投影在图片中的尺寸。
其中:a0、r可由出厂标准得到(其中,a0=3.31 mm,r=10.65 mm);a2、r1可由像素点坐标计算得到。
为了消除不可避免的相机倾斜误差,笔者使用B点做加权倾斜补偿。
倾斜补偿后的绳槽切口长度a2为:
a2=AA1+β·BB1
(10)
式中:AA1,BB1—图像中绳槽两侧切口长度;β—补偿因子。
4 实验与结果分析
4.1 鲁棒性验证
实验环境为Ubuntu操作系统,其中,GPU为NVIDIA RTX3060,开发环境为CUDA11.5,采用PyTorch网络框架。笔者采用DeepLabV3s为网络模型;ResNet101为预训练模型;初始学习率设置为0.007;批处理大小(batch size)设置为5。
测量实验平台如图12所示。

图12 测量实验平台
笔者使用MIoU和Acc来评价训练效果。MIoU最终可达到0.969 2,Acc可达0.987 7。
不同情况下曳引轮绳槽预测图如图13所示。

图13 不同情况下曳引轮绳槽预测图
由图13可知:目标区域几乎没有区别,在弱光、强光环境下和画面模糊状态下的预测效果良好;
该方法对清晰度要求不高,对光照的鲁棒性很强,有利于在电梯弱光环境中进行测量。
笔者对4种不同情况下的图片进行磨损量测量。已知测量标准值为3.31 mm,不同情况下基于DeepLabV3的磨损量测量值,如表2所示。
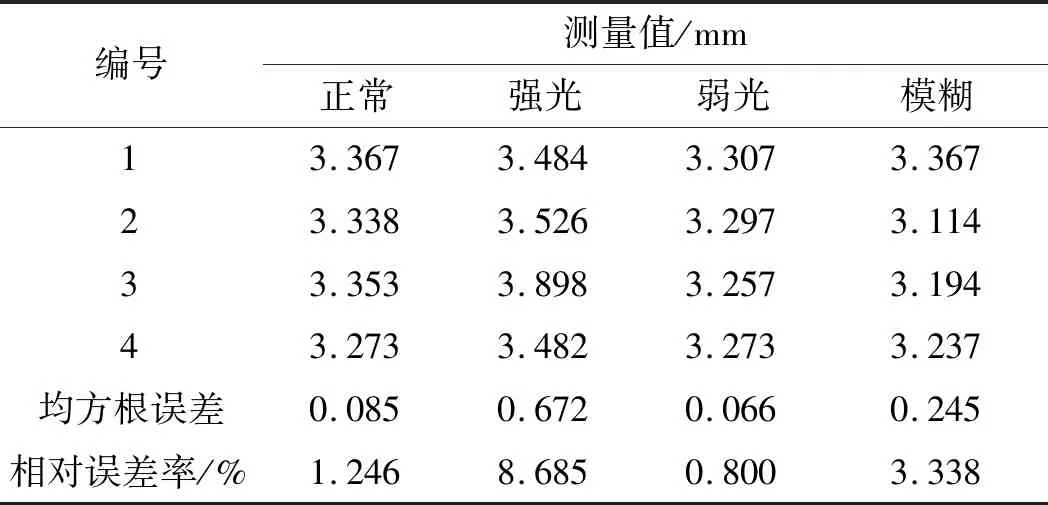
表2 不同情况下基于DeepLabV3的磨损量测量值
不同情况下基于DeepLabV3s的磨损量测量值如表3所示。
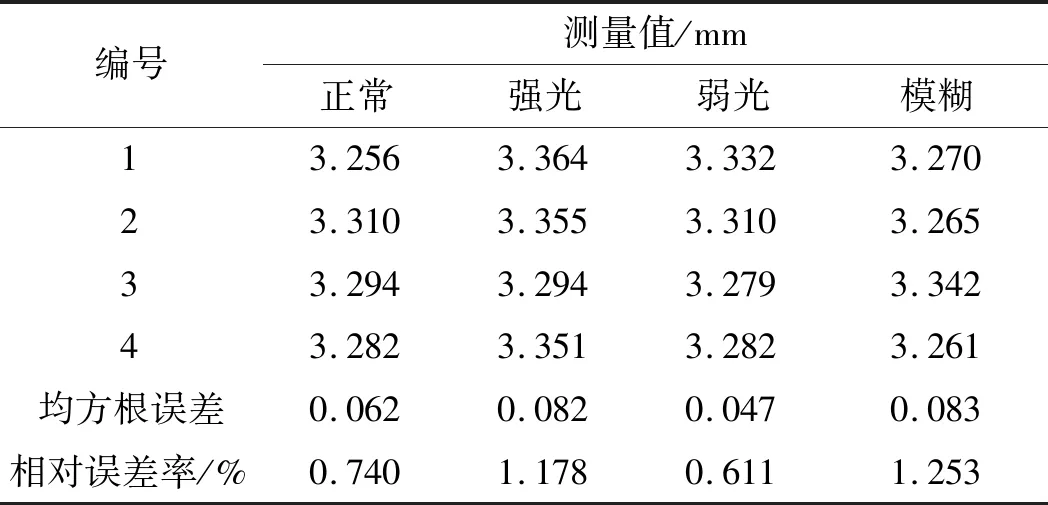
表3 不同情况下基于DeepLabV3s的磨损量测量值
对比表2、表3中4种不同情况的测量值和误差可得:强光会导致边缘细节丢失,测量结果总体偏大,误差值最大;弱光却能在一定程度上保留更多的暗部纹理细节,测量值最接近标准值,误差值最小;轻微的模糊对测量结果影响较小。
综上所述,在测量时应尽可能避免强光环境,而电梯实际测量环境较暗,有利于该算法的测量;在光线环境较为极端的情况下,基于改进后模型的测量值误差下降明显,强光环境下的均方根误差从0.672下降到0.082,相对误差率从8.686%下降到1.178%,验证了DeepLabV3s模型改进的有效性。
4.2 精度与误差
为了验证上述自动测量算法的精度与效率,笔者选择12张未经处理的原图像作为测量对象(包括模糊、正常、强光、弱光状态,保证测量的普适性与真实性),并以绝对误差、相对误差和均方根误差为评价标准。
测量实验结果如表4所示。
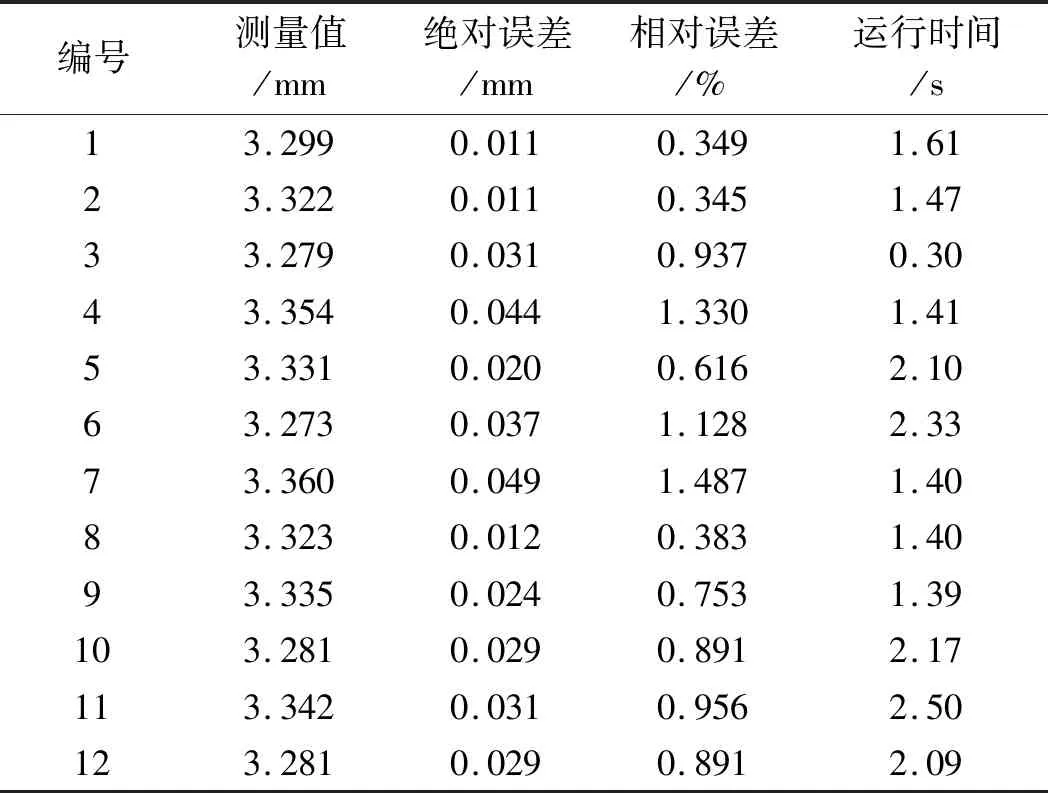
表4 测量实验结果
由表4可得:针对不同的图片,该算法表现较为稳定,其中,编号3相机物距较小,图像中仅需处理两个绳槽,故运行时间较短,而编号11相机物距较远,背景、绳槽边缘复杂,因此处理时间相对更长;
测量值的均方根误差为0.044 mm,绝对误差值范围为0.011 mm~0.049 mm,相对误差率最大不超过1.487%,满足曳引轮磨损测量的精度需求;
运行时间控制在2.50 s内,初步实现了曳引轮磨损的实时测量。
与其他算法相比,该算法最大均方根误差从0.05 mm降低到0.044 mm,且无需限制相机的物距,实现了曳引轮磨损测量自动化的目的,同时提高了测量的精度,这对于电梯安全运行有重要的意义。
5 结束语
笔者采用融合注意力机制的语义分割网络,将曳引轮绳槽和钢丝绳进行图像边缘分割,设计了一种融合曳引轮图像特征的图像处理算法,并通过测量实验对算法性能进行了验证,解决了不同光照环境下的曳引轮磨损非接触式测量问题。
研究结果表明:
(1)与传统边缘提取算法相比,基于语义分割的边缘提取效果更好,并解决了在强光环境下测量误差大的问题;
(2)算法实现了目标区域截取、磨损点定位、磨损量测量自动化的目标,同时缩短了运行的时间,提高了操作的便捷性;
(3)曳引轮磨损自动测量系统绝对误差小于0.049 mm,相对误差率小于1.487%,均方根误差为0.044 mm,可满足曳引轮磨损测量的各项要求;同时,验证了基于DeepLabV3s的曳引轮测量方法在不同光照条件下的鲁棒性及测量的精确性。
该方法具有在实际工业场景下应用的潜力。在后续的工作中,笔者将进一步收集足够数量的实验数据,改进深度卷积网络框架,建立更完善的数学模型,以期能够预测电梯曳引轮的寿命,拓展该系统的功能。
猜你喜欢
中国设备工程(2023年4期)2023-02-28 10:26:54
机电工程技术(2022年10期)2022-11-27 10:37:38
设备管理与维修(2020年9期)2020-06-01 10:25:56
制造技术与机床(2019年11期)2019-12-04 05:50:18
中国特种设备安全(2019年7期)2019-09-10 07:30:56
中国特种设备安全(2018年4期)2018-05-15 11:32:21
小学生学习指导(低年级)(2018年3期)2018-01-31 02:18:58
光学精密工程(2016年4期)2016-11-07 09:04:57
小学生时代·综合版(2016年7期)2016-05-14 17:53:49
红蜻蜓·低年级(2015年11期)2016-02-02 10:54:54
