
结合残差收缩和时空上下文的行为检测网络
2023-03-10 02:11:34陶孟元占生宝
光学精密工程 2023年4期
黄 忠, 陶孟元, 胡 敏, 刘 娟, 占生宝
(1.安庆师范大学 电子工程与智能制造学院,安徽 安庆 246133;2.合肥工业大学 计算机与信息学院,安徽 合肥 230009)
1 引言
随着机器人被广泛应用于迎宾讲解、体感游戏、老人陪护等自然人机交互场景,如何让机器人正确理解人的行为成为人机交互的研究热点[1]。行为检测作为提升人机交互质量最重要的手段,受到研究者高度重视和广泛关注。行为检测的主要任务是在未经过剪辑处理的视频流中,自动定位动作时间边界(即行为起止时间)并进行动作识别[2]。因此,与已知动作边界的行为识别方法相比,行为检测方法更符合机器人在自然人机交互场景中的应用。然而,当前行为检测方法一方面由于视频流易受光照、遮挡、背景等因素影响,提取的动作特征包含较多冗余信息;另一方面由于缺乏时空上下文信息,动作边界定位精度和行为分类准确度有待提高[3]。设计能够抑制冗余特征信息并融入时空上下文信息的时序网络仍是行为检测领域亟待解决的问题。
当前行为检测网络主要分为单阶段方法、两阶段方法以及弱监督学习方法[4]。单阶段方法是在一维时序特征基础上,直接生成时间边界并预测 行 为 类 别,如 SMS[5],I2Net[6],DecoupleSSAD[7]等;两阶段方法则是先从视频流中提取大量包含行为的时序候选片段,然后从中筛选优质的时序片段再进行边界定位和行为分类。Zhao Y等[8]采用结构化时间金字塔对每个动作的时序进行建模,并引入判别模型实现边界定位和行为识别;Lin T等提出LGN[9]实现行为局部和全局上下文信息的融合;Xu H等[10]提出RC3D方法,首先采用3D全卷积网络对视频流进行编码,然后利用候选网络生成包含行为的候选片段并分类。由于R-C3D完善的框架和优秀的检测性能,受到研究者的广泛关注并提出了多种改进的方法。如Chen G等[11]利用时间位置感知网络达到筛选高质量时序候选片段和行为分类的目的;Xu H等[12]融合运动光流和RGB流,采用双流结构实现行为分类;Yang L等[13]在anchorbase基础上通过改进锚框机制解决视频序列过长或过短的问题。与单阶段方法相比,两阶段方法在数据不均衡等情况下的检测精度和分类效果具有较大提升。但由于缺乏冗余信息的抑制机制和时序候选片段间的上下文信息,两阶段方法的边界定位精度和行为分类准确度仍难以满足机器人用户感知和理解的应用要求[14-15]。弱监督学习方法则是在已有模型基础上计算片段的动作概率,再依赖多实例学习策略实现行为分类,代 表 性 的 有AffNet[16],MSA-Net[17],Back-TAL[18]等。尽管弱监督学习方法不需要标注大量样本,但其检测精度和算法性能仍有待进一步提高。
针对行为检测特征提取冗余度高及行为边界定位不准确的问题,本文以两阶段的R-C3D方法为基础,提出一种改进的行为检测网络(RSSTCBD)。在特征提取子网中,为了抑制背景、噪声等冗余信息,在3D-ResNet卷积网络基础上融合收缩结构和软阈值化操作,设计通道自适应阈值的残差收缩单元(3D Residual Shrinkage unit with channel-adaptive Soft Thresholds,3DRSST);在时序候选子网中,针对在R-C3D网络中使用一次卷积策略易造成空间特征信息丢失的问题,采用多层卷积策略增加时序侯选片段的时序维度感受野;在行为分类子网中,采用非局部注意力机制捕获优质时序片段间的时空上下文信息。本文创新点如下:(1)结合残差收缩结构和时空上下文,提出一种改进的行为检测网络RS-STCBD。该网络通过抑制行为特征中的冗余信息并融合行为时空上下文信息提高行为检测的准确度;(2)嵌入收缩结构和软阈值化操作,设计3D-RSST单元,并构建多个3D-RSST单元级联的特征提取子网。通过自动学习通道阈值和软阈值化操作,该子网能够自适应消除冗余信息以提升特征提取的有效度;(3)采用多层卷积策略增加时序侯选片段的时序维度感受野,并引入非局部注意力机制获取优质时序片段间的时空上下文信息。通过改善时序候选子网和行为分类子网的时空上下文捕获能力,从而提升动作边界定位和行为分类的精度。
2 RS-STCBD网络设计
R-C3D行为检测网络主要由特征提取子网、时序候选子网以及行为分类子网三部分组成。针对R-C3D行为检测网络提取特征冗余度高及边界定位不准确的问题,本文提出一种改进的行为检测网络RS-STCBD,如图1所示。其主要包括嵌入残差收缩结构的特征提取子网(Feature Subnet)、基于多层卷积的时序候选子网(Proposal Subnet)以及引入非局部注意力机制的行为分类子网(Classification Subnet)。

图1 RS-STCBD网络结构Fig.1 Network structure of RS-STCBD
2.1 嵌入残差收缩结构的特征提取子网
在人机交互自然情景下,行为检测易受噪声、光照等环境因素的干扰。由于缺乏抗干扰机制,R-C3D特征提取子网获取的行为特征包含较多冗余信息。同时,由于视频中不同行为的冗余信息存在较大差异,其抑制阈值也应各不相同。为自适应的抑制不同视频流的冗余信息,本文在3D-Resnet[19-20]基础上通过嵌入收缩结构(Shrinkage Module)和软阈值化(Soft Thresholding)操作构建3D-RSST单元,如图2所示,其中红色虚线框部分为嵌入的收缩结构(彩图见期刊电子版)。
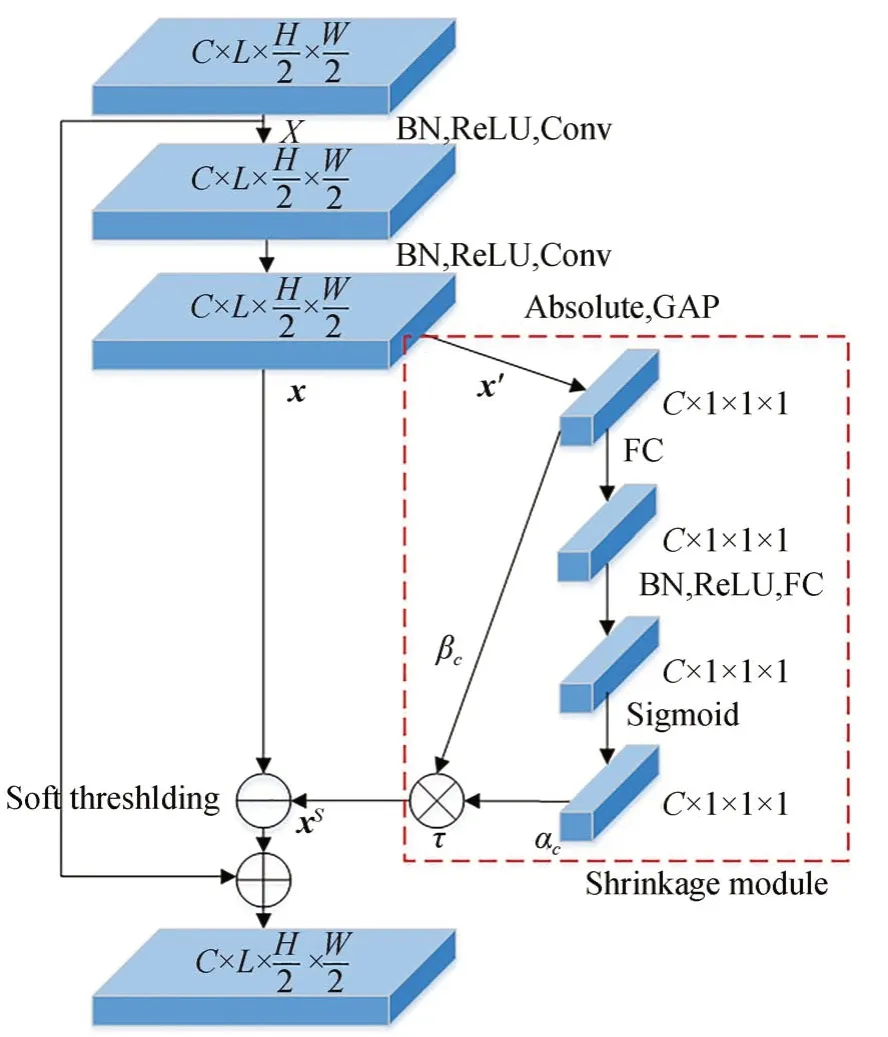
图2 3D-RSST单元Fig.2 Unit of 3D residual shrinkage with channel-adaptive soft thresholds (3D-RSST)
首先,将经卷积和最大池化操作后的视频图像特征图作为3D-RSST单元的输入X,再将X进行批标准化、ReLU及卷积操作等得到收缩结构的输入x,并采用绝对值和全局均值池化操作将x简化为一维向量x′:
其中:ReLU(·)为ReLU激活函数;BN(·)为批标 准 化;Conv(·)为3×3×3大 小 的 卷 积;GAP(·)为全局均值池化,C,L,H,W分别代表特征图的通道数、帧长度、长和宽。
然后,将简化后的向量x′分别送入通道收缩系数支路和通道均值特征支路。在通道收缩系数支路中,利用两层全连接层计算x′第c通道的收缩系数αc:
其中:FC(·)为全连接层;δ(·)为Sigmoid激活函数;αc∈(0,1)为第c通道的收缩系数。在通道均值特征支路中,分别计算各通道特征的平均值βc:
其中,average(·)为平均值函数。
通过通道收缩系数支路和通道均值特征支路分别获取αc和βc后,第c通道的收缩阈值τc可表示为:
通过计算C个通道的收缩阈值,可以获得输入特征x的收缩阈值向量τ=(τ1,τ2,…,τC)。
最后,为抑制与行为目标无关的冗余信息,利用式(4)计算的收缩阈值向量τ对输入特征x进行软阈值化[21]:
其中:sign(·)和max(·)分别表示符号函数和最大值函数;xs为输入特征图x软阈值化后的特征。由式(5)可知,当|x|<τ时,xs置为零;当|x|>τ时,xs朝着零的方向收缩。本文将软阈值化的输出xs与特征图X做残差连接,并作为3D-RSST单元的输出,即:
由以上步骤可知,构建的3D-RSST单元可根据自动学习的阈值对各个特征通道进行软阈值化,从而自适应地消除冗余特征信息。为了提高抑制冗余信息的效果,将多个3D-RSST单元进行级联并构建特征提取子网,如图1中特征提取子网所示。图1特征提取子网中包含1个卷积层、1个最大池化层和3个不同结构的3D-RSST单元级联模块(3D-RSST Cascade Module),其结构参数如表1所示。通过特征提取子网处理后的时空特征图E可表示为:
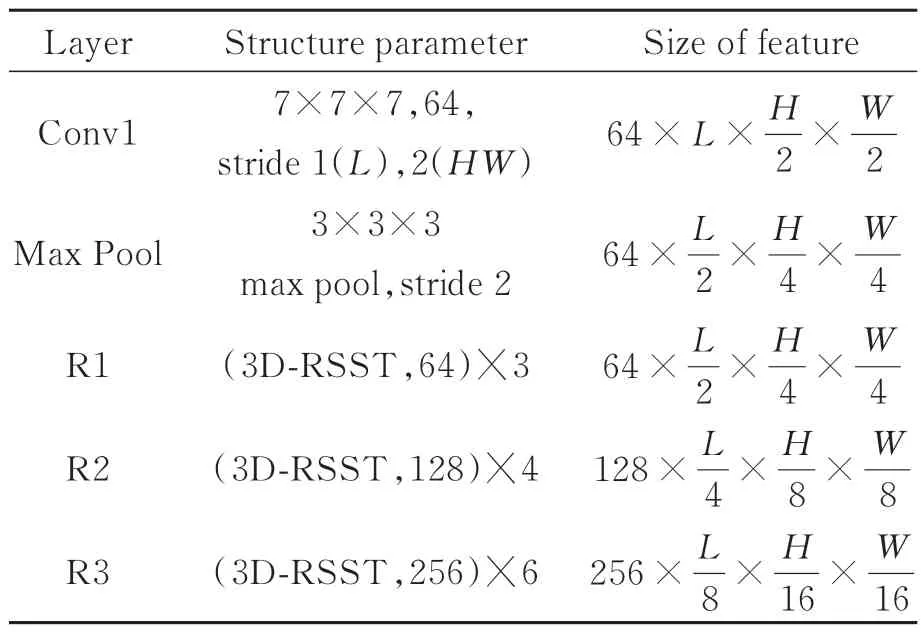
表1 特征提取子网结构参数Tab.1 Structure parameter of feature subnet
其中:E∈,R1(·),R2(·),R3(·)分别表示3个不同结构的3D-RSST单元级联模块。
2.2 基于多层卷积的时序候选子网
在时序候选子网中,需要从时空特征图E中分割出包含行为的时序候选片段。针对R-C3D一次卷积易造成空间特征信息丢失的问题,本文采用多层卷积增加时序维度感受野。改进后的子网结构如图1中时序候选子网所示。在改进后的时序候选子网中,首先使用3个卷积层对时空特征图E做卷积操作,并采用3×3×3的卷积核增加时序维度感受野;然后利用池化将时空特征图E转化为时序特征图E′:
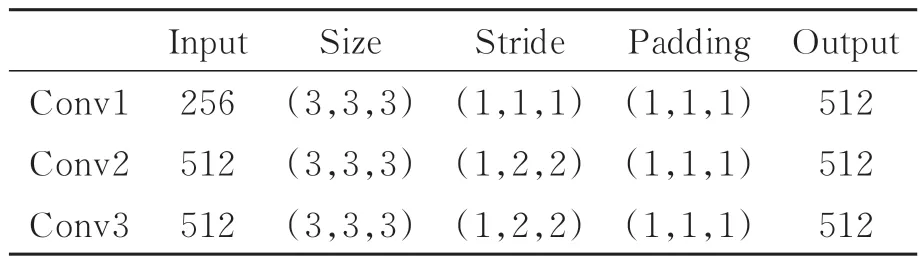
表2 多层卷积的参数Tab.2 Parameter of multilayer convolution
最后将时序特征图E′上L8个时间点作为锚点(即时序候选片段的中心点),并在每个锚点位置设置S个不同尺度的锚框长度,因此可获得(L8)*S个时序候选片段。将这些时序候选片段特征图输入至1×1×1卷积层可得到其边界起止时间以及边界置信度:
其中:proposal表示时序候选片段;[tstart,tend]表示时序候选片段的起止时间边界;score为边界置信度。
2.3 引入非局部注意力机制的行为分类子网
行为分类子网的任务是结合特征提取子网所提取的时空特征图E和时序候选子网生成的时序候选片段proposal,根据一定策略筛选优质时序候选片段并对其进行边界调整和行为分类。在R-C3D中,行为分类子网利用非极大值抑制策略获取K个优质时序片段,并将各自特征图送入全连接层进行时序边界回归和行为分类。由于人类行为具有连续性和整体性,利用非极大值抑制策略筛选的优质时序片段在时间和空间上均存在相关性。因此,本文在行为分类子网络中引入非局部注意力机制[22]以获取K个优质时序片段间的上下文运动信息。改进后的行为分类子网如图1中行为分类子网所示。
首先,采用三维ROI池化操作将K个不等长的优质时序片段映射到时空特征图E的对应位置上:
其中:NMS(·)和ROIPooling(·)分别表示非极大值抑制操作和三维ROI池化操作;γ表示为非极大值抑制阈值;Pk∈R256×1×4×4(k∈[1,K])为优质时序片段特征图,即通过三维ROI池化操作将不等长的优质时序片段固定为等长(1×4×4)的特征图。
其中:Wθ,Wφ为权重矩阵;(k∈[1,K])表示特征 图Pk第i(i∈[1,16])个 位 置 特 征 ;(l∈[1,K])表示特征图Pl第j(j∈[1,16])个位置特征;度量位置向量与的相似度。同时,将特征图第j个位置的通道特征(256维)进行线性转换:
其中,Wg为权重矩阵。
最后,根据特征图Pk与特征图Pl之间的相似度以及计算第k个特征图第i个位置的时空上下文特征,并将其与原始特征图作残差连接:
将特征图Pk所有位置点的残差连接特征进行级联,并输入至两个独立的全连接层,可分别得到第k个优质时序片段的时间边界位置和行为类别概率:
2.4 RS-STCBD算法描述
综上,本文提出的RS-STCBD方法可分为特征提取、时序候选以及行为分类三部分,其网络结构如图1所示,具体算法描述如下:
输入:视频流V,特征图通道数C,3D-RSST单元级联深度D,视频帧长度L,锚框长度列表S,非极大值抑制阈值γ,行为类别数m。
输出:视频流V包含的K个时序片段的边界以及被预测为各类行为的概率。
第一步:将视频流V输入至基于表1参数的特征提取子网,获取特征图E。
第二步:将特征图E输入至基于表2参数的时序候选子网,获取时序候选片段proposal。
第三步:将时序候选片段proposal输入至基于非局部注意力机制的行为分类子网,输出时序片段的边界以及各类行为的概率。
3 RS-STCBD网络优化
在RS-STCBD网络中,时序候选子网优化时序候选片段的边界以及判别其是否包含动作,行为分类子网则完成优质时序片段的边界回归和行为分类。本文采用时序候选子网和行为分类子网联合优化策略:
其中:λ为平衡因子;Lpro为时序候选子网损失函数,Lact为行为分类子网损失函数,计算方式如式(16):
4 实验结果分析
4.1 行为数据集及实验环境
为了训练RS-STCBD网络参数以及验证模型 的 有 效 性,本 文 在 公 开 的THUMOS14[23]和ActivityNet1.2[24]数据集上进行实验。两个数据集均包含大量真实环境下人类日常生活和体育运动的行为视频,各数据集分布如表3所示。THUMOS14数据集含有613段视频数据,具有20种动作类别;ActivityNet1.2数据集含有9 682段视频,具有100种动作类别。本文主要解决自然场景中的行为检测问题,因此需要使用未经过剪辑的视频数据作为数据集。考虑THUMOS14训练集中200个视频均为已剪辑过的行为片段,不符合本文行为检测任务要求,因此实验中以THUMOS14验证集中的200个视频(3 007个行为片段)作为训练集、测试集中的213个视频(3 358个行为片段)作为测试集;在ActivityNet1.2数据集中分别以训练集中4 819个视频(7151个行为片段)作为训练集、验证集中2 383个视频(3 582个行为片段)作为测试集。
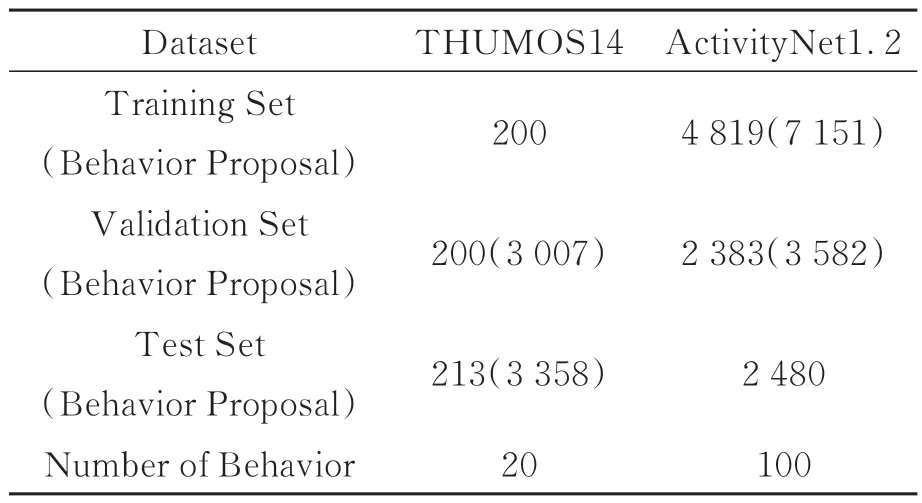
表3 THUMOS14和ActivityNet1.2行为数据集Tab.3 Behavioral datasets of THUMOS14 and ActivityNet1.2
在Ubuntu18.04操作系统上,采用一块Quadro P6000显卡并基于Pytorch构建和训练RS-STCBD网络,其详细实现已开源在Github网 站(https://github.com/huangzhong3315/RSSTCBD)。网络相关参数如表4所示。构建的RS-STCBD网络共包含80.15M个参数,在THUMOS14 和ActivityNet1.2数据集上,一轮训练时间分别约2.6 h和4.2 h;单一动作检测时间约0.8 s。

表4 网络参数设置Tab.4 Parameter setting of network
4.2 RS-STCBD网络评价
4.2.1 行为检测精度评价
基于THUMOS14行为数据集,本文将提出的RS-STCBD方 法 与R-C3D[10],MSA-Net[17],SSN[8],LGN[9],DecoupleSSAD[7],BackTAL[18]等方法进行比较。考虑样本数量、行为类别的不平衡性等问题,本文采用平均精度(Average Precision, AP)和均方平均精度(mean Average Precision, mAP)评估行为检测效果。AP及mAP的计 算 方 法 均 与 以 上 相 关 方 法 保 持 一 致[7-10,17-18]。表5统计了不同方法在交并比阈值iou∈[0.1,0.7]间的检测精度。表5表明:当iou≤0.3时,过小阈值将导致时序候选片段间的重叠程度增大,而RS-STCB的非极大值阈值策略对重叠度高的时序候选片段抑制能力弱,因此其检测精度低于其他检测方法;当0.3<iou<0.5时,RS-STCBD检测精度虽低于DecoupleSSAD、BackTAL方法,但由于时序候选片段间重合程度的逐渐较小,其已优于R-C3D、MSA-Net、SSN、LGN等方法;当iou≥0.5时,RS-STCBD的检测精度均高于其它方法。从表5可以看出,随着交并比阈值iou的增大,各方法mAP值均呈下降趋势。iou<0.5时,各行为检测方法虽具有较高的mAP值,但由于保留了大量的冗余时序候选片段而难以应用于实际场景;iou≥0.5时,本文方法的行为检测精度更具优势,因此其更适合于自然人机交互场景中应用。
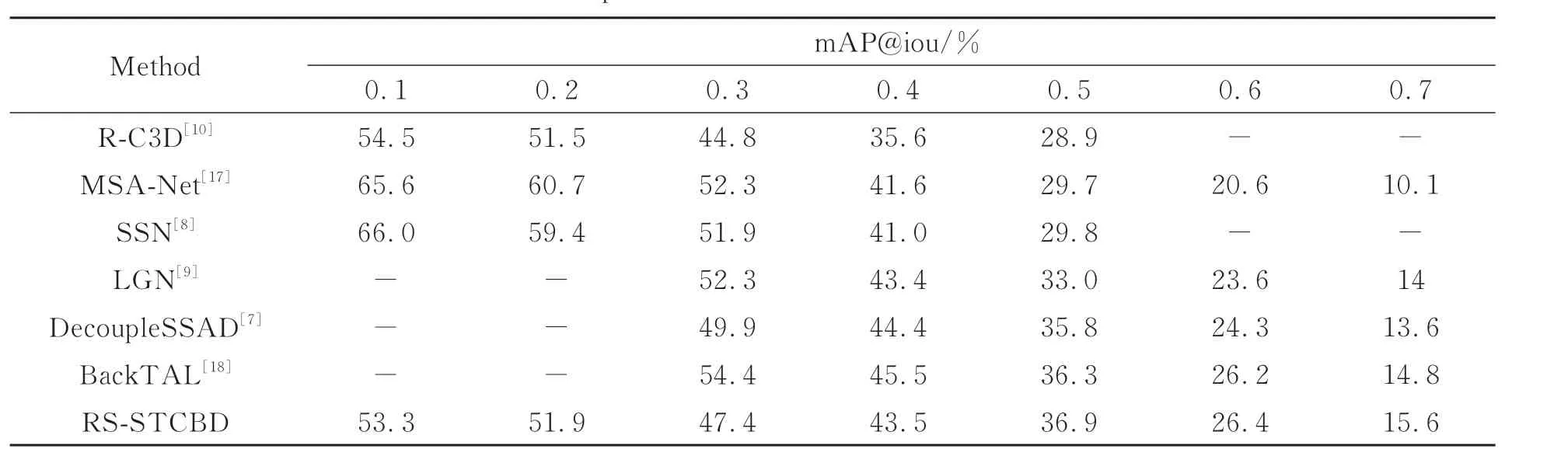
表5 THUMOS14数据集上不同方法的mAP比较Tab.5 mAP comparison of different methods in THUMOS14
此外,为进一步比较各类行为的检测精度,在交并比阈值iou=0.5下,统计了各方法20类行为的AP@0.5值及mAP@0.5值。表6中本文方 法mAP@0.5为36.9%。与SMS[4],RC3D[10],Two-stream R-C3D[12],LGN[9]等方 法 相比,RS-STCBD提高了10种动作的检测效果,尤其提升了Clean and Jerk(46.2%),Cliff Diving(61.3%),Hammer Throw(71.5%),Pole Vault(71.6%)等长时序行为的检测精度。然而,Cricket Bowling,Volleyball Spiking,Soccer Penalty等行为检测精度不及部分方法。这主要由于本文通过嵌入收缩结构和软阈值化操作构建3DRSST单元难以自适应抑制人物过多、遮挡面积过大等冗余信息。
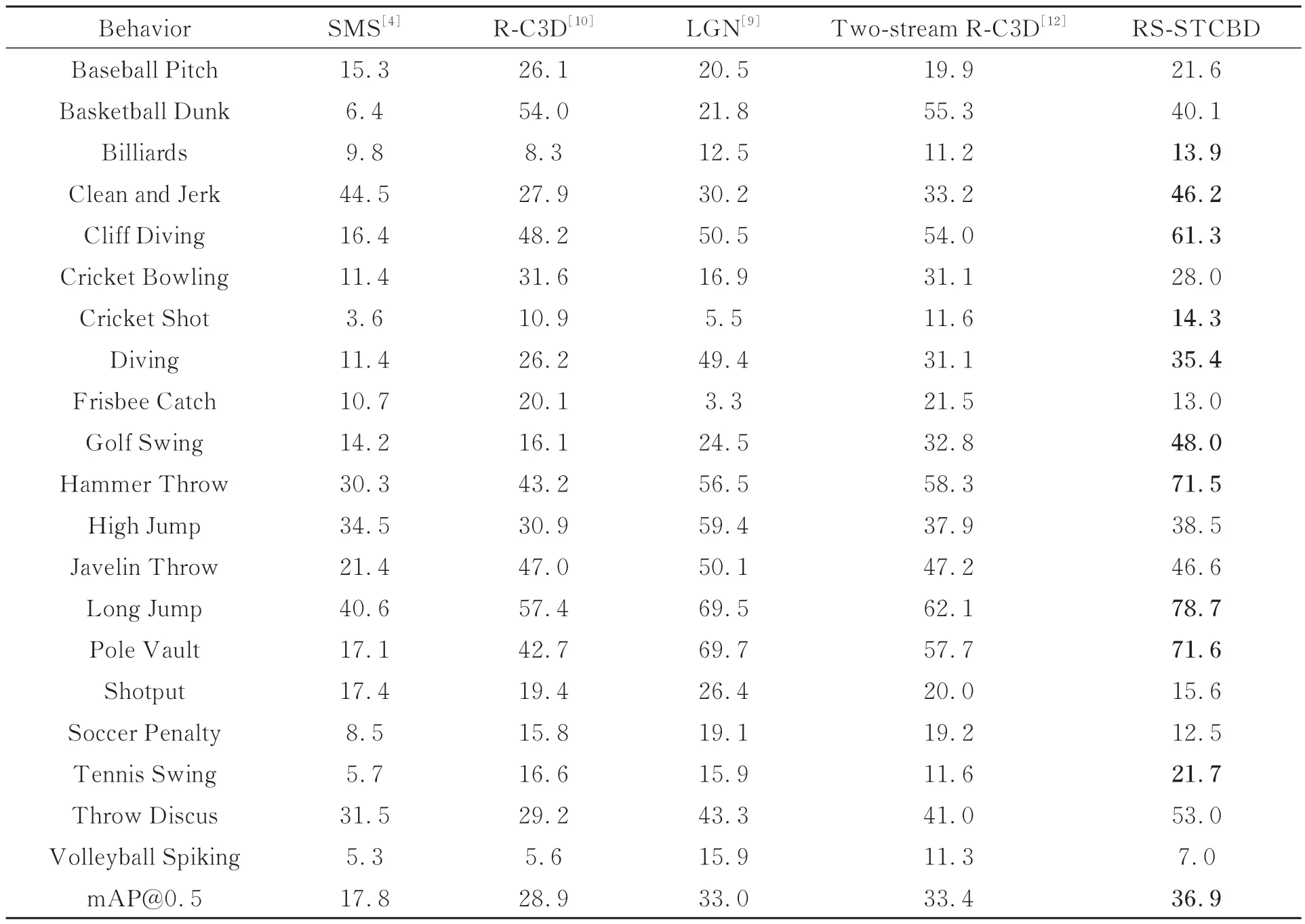
表6 THUMOS14数据集上不同方法下各行为AP@0.5比较Tab.6 Comparison of AP@0.5 of each behavior under different methods in THUMOS14
为了说明本文方法的泛化能力,本文将提出的RS-STCBD方法与R-C3D[10],TwinNet[25],AffNet[16],BackTAL[18],MHCS[26],SSN[8]等 方 法 在ActivityNet1.2数据集上进行比较,实验结果如表7所示。由表7可以看出,本文提出方法在mAP@0.5,,iou∈[0.5, 0.95]之间的平均mAP值以及mAP@0.75,mAP@0.95值普遍高于其他方法。

表7 ActivityNet1.2数据集上不同方法的mAP比较Tab.7 mAP comparison of different methods in ActivityNet1.2
4.2.2 时序边界划分评价
为了说明RS-STCBD时序边界的定位效果,在THUMOS14数据集上,本文将其与R-C3D方法进行比较。图3为同一时序片段中Cricket Bowling和Cricket Shot两类运动的边界定位效果。从图3可以看出,Cricket Bowling和Cricket Shot的时间定位边界在R-C3D方法均有重叠,而在RS-STCBD方法中没有交叉。这说明RS-STCBD方法在区分两种运动的边界方面具有更高的精确度。图4为Billiards动作在R-C3D和RSSTCBD方法上的边界定位效果。从图4中可以看出,R-C3D方法对Billiards运动边界定位包含了背景、人像等非运动信息,而RS-STCBD方法能够较好的区分非运动信息和运动信息。这说明RS-STCBD方法在判别运动信息和非运动信息方面具有较高的区分度。图5为High Jump动作在R-C3D和RS-STCBD方法上的检测结果。与R-C3D方法相比,RS-STCBD方法划分的时序片段边界框更接近于真实边界框GT,且各时序片段的动作分类结果具有更高的置信度。

图3 Cricket在R-C3D和RS-STCBD上的检测结果Fig.3 Detection results of Cricket movement on R-C3D and RS-STCBD

图4 Billiards在R-C3D和RS-STCBD上的检测结果Fig.4 Detection results of Billiards movement on R-C3D and RS-STCBD

图5 High Jump在R-C3D和RS-STCBD上的检测结果Fig.5 Detection results of High Jump movement on R-C3D and RS-STCBD
4.3 消融实验
为了说明改进的子网对行为检测的影响,本文进行5类消融实验,并分别统计不同子网组合策略在THUMOS14和ActivityNet1.2数据集上的检 测效果。参考SSN[8],LGN[9],BackTAL[18]等的iou参数设置方式,表8分别统计了THUMOS14数据集在iou∈[0.4,0.7]以及ActivityNet1.2数据集在iou∈[0.5,0.95]的检测精度。表8中,Strategy1表示在特征提取子网中使用3D-RSST单元级联模块替代R-C3D中的C3D模块;Strategy2表示在时序候选子网中使用多层卷积(Multilayer Convolution)替代一次卷积;Strategy3表示在行为分类子网中引入非局部注意力机制(Non-local Attention Mechanism)。从表8可以看出,与R-C3D相比,三种策略在不同iou值下均提高了行为检测的mAP值,这说明本文嵌入残差收缩结构、以多层卷积增加时序维度感受野以及引入非局部注意力机制等的有效性。相比Strategy2和Strategy3,Strategy1的提升效果更为显著,这表明设计的自适应收缩阈值3DRSST单元在提取行为特征的同时,能够有效抑制噪声、背景等冗余信息;此外,这也说明改进特征提取子网仍是提高行为检测性能的重要手段。与其它策略相比,本文构建的RS-STCBD网络嵌入了残差收缩结构并融入了时空上下文信息,从而提升了动作边界定位和行为分类的精度;特别地,在THUMOS14和ActivityNet1.2数据集上mAP@0.5分别达到了36.9%和41.6%,比R-C3D提高了8.0%和14.8%。
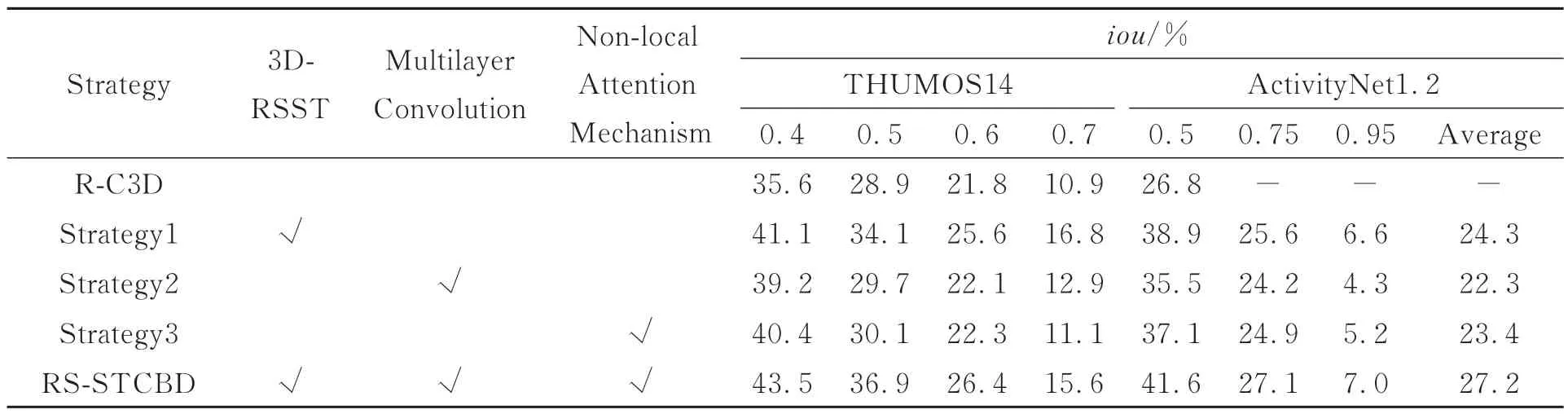
表8 不同改进阶段的消融实验结果Tab.8 Results of ablation experiments at different improvement stages
4.4 参数分析
本文讨论了平衡因子λ、非极大值抑制阈值γ以及优质时序片段数量K对mAP@0.5的影响。图6显示了平衡因子λ∈[0.1,0.9]间的RS-STCBD网络性能。由图6可知,当λ<0.4,mAP@0.5随着λ的增大呈上升趋势;当λ>0.4时,mAP@0.5随着λ的增大显著下降;当λ=0.4时,mAP@0.5达到峰值。因此,本文平衡因子λ取0.4。图7统计了非极大值抑制阈值γ∈[0.0,0.9]对RS-STCBD网络性能的影响。由图7可知,γ<0.2时,随着γ的逐渐增大,漏删的冗余时序候选片段数量逐渐减小,因此mAP@0.5呈上升趋势;γ=0.2时,mAP@0.5达到峰值;0.2<γ≤0.4时,随着γ的逐渐增大,误删的优质时序片段数量增加,从而mAP@0.5逐渐下降;γ>0.4时,筛选的优质时序片段数量达到饱和,因此mAP@0.5维持不变。图8统计了优质时序片段数量K∈[50,400]对RS-STCBD网络性能的影响。由图8可知,K<150时,随着K的增加,筛选的优质时序片段数量也随之增加,因此mAP@0.5呈上升趋势;K≥150时,由于K与网络输出的优质时序片段数量相当,筛选的候选片段将包含所有的优质时序片段,因此mAP@0.5趋于稳定。此结果也表明本文采用非极大值抑制策略优选时序片段的有效性。

图6 平衡因子对mAP@0.5的影响Fig.6 Influence of balance factor on mAP@0.5
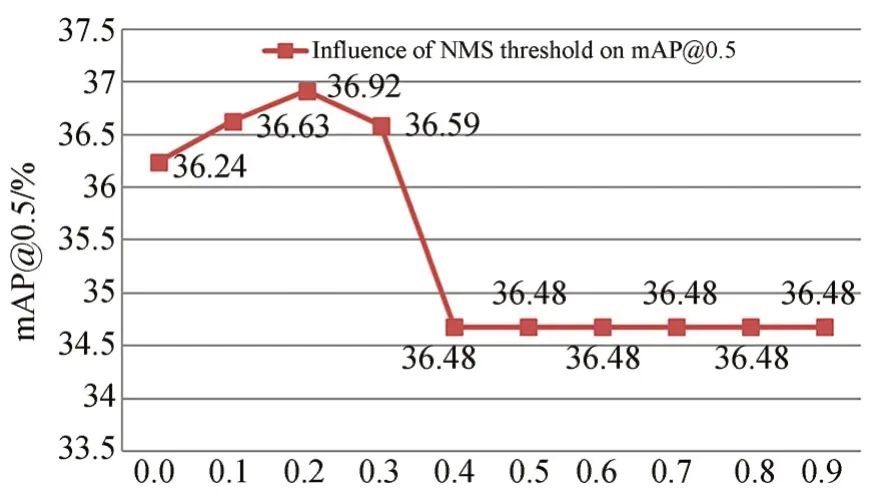
图7 非极大值抑制阈值对mAP@0.5的影响Fig.7 Influence of NMS threshold on mAP@0.5
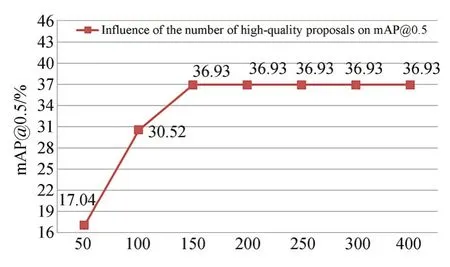
图8 优质时序片段数量对mAP@0.5的影响Fig.8 Influence of number of high-quality proposals on mAP@0.5
5 结论
为提高行为时间边界定位精度和分类准确度,本文基于R-C3D方法提出一种改进的RSSTCBD行为检测网络。在特征提取子网中,设计3D-RSST单元并构建特征提取网络以自适应消除行为特征中的噪声、背景等冗余信息;在时序候选子网和行为分类子网中,通过多层卷积和非局部注意力机制,增加时序侯选片段的时序维度感受野和优质时序片段间的上下文时空运动信息。在THUMOS14和ActivityNet1.2数据集上评价了RS-STCBD网络的动作边界定位和行为分类精确度,并讨论了交并比阈值、平衡因子、非极大值抑制阈值以及优质时序片段数量等超参数对网络性能的影响。实验结果表明:在两个数据集上,RS-STCBD方法的mAP@0.5达36.9%和41.6%,比R-C3D方法分别提高了8.0%和14.8%。因此,基于改进网络的行为检测方法有利于改善自然场景下的人机交互质量。由于受物体遮挡、行为动作相似等影响,各类行为检测的精度仍存在较大差异,如何从行为时空特征建模、行为多模态信息融合等角度进一步提高各类行为分类的准确度将是下一步需要开展的工作。
猜你喜欢
中国农业信息(2023年3期)2023-03-18 08:19:04
计算机时代(2023年1期)2023-01-30 04:08:22
中国农业信息(2021年3期)2021-11-22 06:44:48
中国新通信(2019年21期)2019-03-30 04:01:30
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
电子制作(2016年15期)2017-01-15 13:39:08
网络安全和信息化(2016年2期)2016-11-26 06:42:30
噪声与振动控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年16期)2014-02-27 14:13:04
