
面向航天光学遥感场景压缩感知测量值的舰船检测
2023-03-10 02:11:22肖术明常旭岭孙建波
光学精密工程 2023年4期
肖术明, 张 叶*, 常旭岭, 孙建波
(1.中国科学院 长春光学精密机械与物理研究所,吉林 长春 130033;2.中国科学院大学,北京 100039)
1 引言
航天光学遥感(Space Optical Remote Sensing,SORS)场景的舰船检测是遥感领域的研究热点。舰船检测具有广泛的民用和军事价值,例如搜索和救援、港口管理、海洋环境监控、领土安全和军事侦察[1-4]。随着SORS成像系统成像分辨率的不断提高,系统获取的场景数据量也急剧增加。为了缓解数据存储和实时传输的巨大压力,传统的SORS成像系统并不会直接存储和传输探测器采集的原始场景数据,而是在传输前对数据进行压缩,以节省时间和空间资源。然而,这种方法数据采集的理论基础是奈奎斯特采样定理,必须以不小于信号带宽两倍的采样率对原始模拟信号进行均匀采样,以保存信号信息[5]。这就导致冗余信息只能在压缩阶段被丢弃,从而浪费了成像系统前端使用高成本检测器获取的采样资源。
压缩感知(Compressive Sensing,CS)是一项新兴技术,如果信号在某个变换域是稀疏的,则高维信号可以通过与变换基无关的测量矩阵投影到低维空间,并且可以以远低于该变换基的采样率准确恢复原始信号[6-7]。CS技术突破了奈奎斯特采样定理的瓶颈,能够以较低的采样率(远低于奈奎斯特采样率)采集场景数据,从而在数据采集的同时完成数据压缩。此外,CS重构算法可以在原始数据稀疏的前提下,根据采集到的采样数据,理想地重构原始数据[8],这就缓解了数据存储和实时传输的巨大压力。
最近,一种基于CS的SORS成像系统被提出[9-11],它凭借CS技术在采样阶段通过硬件同时进行采样和压缩。因此,成像系统可以减少对采样设备的需求,有效减少采样数据,节省存储空间,降低传输成本。当基于CS的SORS成像系统面临舰船检测任务时,需要的结果是舰船的位置属性。图1(a)显示了基于CS的SORS成像系统执行船舶检测任务的流程。首先,光学系统对场景进行压缩采样获得CS测量值。然后,图像重建算法[12-14]作用于测量值得到重建的原始场景。最后,基于图像的舰船检测算法[15-17]作用于重建场景得到舰船位置信息。然而,将测量值重建为原始场景的过程计算成本高、内存要求高且耗时。因此,直接对CS测量值进行舰船检测可以有效地解决上述问题。图1(b)显示了本文提出的基于CS的SORS成像系统执行舰船检测任务的流程。首先,与图1(a)中的第一步相同,光学系统对场景进行压缩采样获得测量值。然后,将基于测量值的舰船检测算法直接应用于测量值得到舰船检测结果。
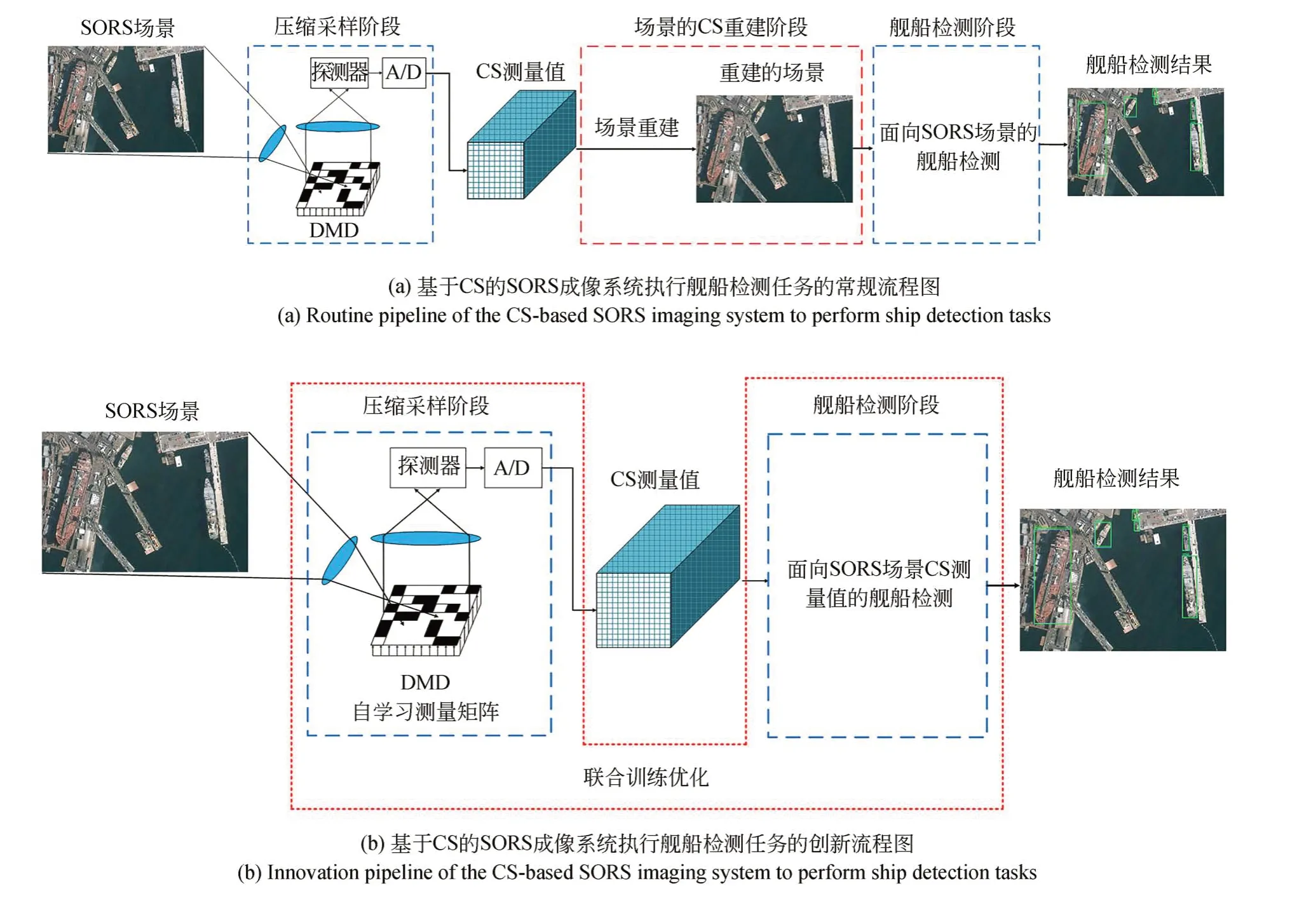
图1 基于 CS 的 SORS 成像系统执行船舶检测任务的流程示意图,其中数字镜像设备 (Digital Mirror Device,DMD) 表示基于 CS 的成像系统中的测量矩阵Fig.1 Illustration of the pipeline of the CS-based SORS imaging system to perform ship detection tasks, where digital mirror device (DMD) denotes a measurement matrix in the CS-based imaging system
近年来,基于卷积神经网络(Convolutional Neural Network,CNN)的图像舰船检测算法可以有效地学习复杂特征,实现高精度的舰船检测。文献[18]借助多尺度特征金字塔网络,利用RetinaNet来检测SAR图像中的船只,可以更好地检测多尺度舰船。文献[19]采用基于无先验框的目标检测方法,利用CenterNet来检测遥感图像中的舰船。文献[20]通过分辨率归一化制作混合的训练样本数据集,在Faster-R-CNN的框架下构建了一个3层卷积神经网络的舰船检测算法,取得了较好的检测效果。文献[21]通过模型剪枝,利用剪枝后的YOLOv3框架对卫星图像进行船只检测,取得了较好的实时检测效果。然而,这些基于CNN的方法都用于提高场景舰船检测的准确性,而不能应用于CS测量值的舰船检测。
基于CNN的方法可以有效地处理压缩后的图像数据。Fu等人[22]提出了一种基于离散余弦变换(Discrete Cosine Transform ,DCT)的算法来对图像进行压缩,然后将其输送到神经网络。该方法在减小少量准确率的基础上大大增加了神经网络的训练速度。Torfasson等人[23]设计了一个编解码神经网络来学习RGB图像压缩域中的目标属性。Benjamin Deguerre等人[24]使用8×8内核和8步长的卷积层来保持DCT块的一致性,随后连接到改进的SSD网络,以实现压缩域图像的快速图像处理。然而,这些基于CNN的方法似乎是对压缩域进行图像处理,但实际上,它们仍然使用原始图像进行图像处理。
本文在基于CS的SORS成像系统的基础上,提出了应用于SORS场景CS测量值的舰船检测模型——基于压缩感知和改进YOLO(Compressive Sensing and Improved You Only Look Once,CS-IM-YOLO)的测量值舰船检测算法。CS-IM-YOLO首先利用卷积测量层模拟CS成像系统的压缩采样过程从而获得全图测量值,然后利用改进的主干网络提取测量值的特征信息,最后利用特征金字塔网络加强特征提取,获得舰船目标的位置信息。
2 CS测量值舰船检测算法
本文提出的CS-IM-YOLO算法可以用于SORS场景CS测量值的舰船检测,CS-IM-YOLO的总体组成如图2所示,网络由三部分组成:场景压缩采样部分,测量值特征提取部分和多特征层特征预测部分。本章首先是模型整体概述,然后是模型中三个关键组件的详细实现,最后介绍了整体框架的联合训练优化。
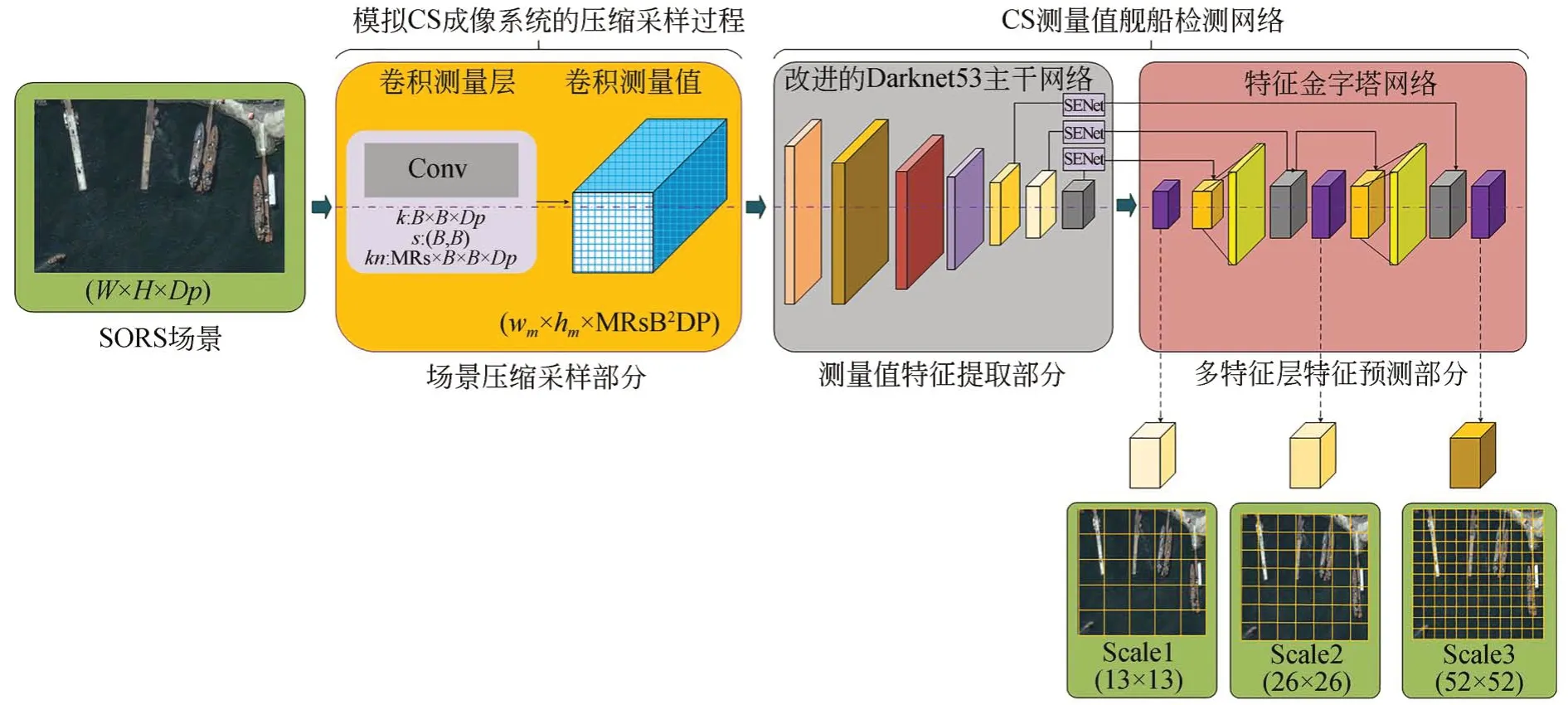
图2 CS-IM-YOLO的总体框架示意图,包括三部分:CML,IDBN和FPNFig.2 Illustration of the overall framework of CS-IM-YOLO, including three parts: CML, IDBN and FPN
2.1 CS-IM-YOLO概述
给定SORS场景X,首先卷积测量层(Convolutional Measurement Layer,CML)对场景分块压缩采样获得全图CS测量值Y,该过程模拟了基于CS的SORS成像系统的压缩采样过程。该过程可以表示为:
其中,CML(·)表示压缩采样过程。然后,给定获取的全图测量值Y,改进的Darknet53主干网络(Improved Darknet53 Backbone Network,IDBN)对测量值进行特征提取得到舰船特征信息,特征金字塔网络(Feature Pyramid Network,FPN)进一步强化特征提取并且融合浅层、中层和高层特征信息,进而完成舰船目标的位置预测。主干网络提取测量值多层特征信息feat1′,feat2′和feat3′的过程可以表示为:
其中:IDBN(·)表示特征提取过程。FPN输出的特征层y1,y2和y3分别为13×13×18,26×26×18和52×52×18,通道数18表示采用3种先验框预测的3个预测框信息。FPN的加强特征提取过程可以表示为:
其中,FPN(·)表示加强特征提取过程。利用非极大值抑制(Non Maximum Suppression,NMS)算法去除多余预测框,获得得分最高的舰船位置预测框。
在整体框架联合训练后,优化后的CML权重值为基于CS的SORS成像系统中的测量矩阵。IDBN和FPN组成场景CS测量值的舰船检测模型。
2.2 场景压缩采样部分
CS测量值舰船检测的前提是测量值的获取。在基于CS的SORS成像系统中,通过压缩采样过程完成数据采集。CS理论中传统压缩采样问题首先场景需要满足稀疏条件,然后采样矩阵需要满足约束等距性质(Restricted Isometry Property,RIP)。现有的采样矩阵都是信号独立的,没有考虑被采样信号的特性从而不能使测量值中保留更多的信息。而基于CNN的方法可以更加有效地解决CS中的压缩采样问题。
为了模拟这个过程,参考压缩感知重建相关工作[25]中的压缩采样过程,本文采用一个无偏置无激活函数的CML来测量场景。训练后CML中卷积核的权重值为自学习测量矩阵(Learned Measurement Matrix,LMM)[25,26],即CS中 压 缩采样过程的测量矩阵。
压缩采样过程如图3所示。在图3(b)中,场景首先被划分为非重叠的场景块wm×hm=。其中,W,H和Dp分别是场景的宽、高和通道数(Dp=3),B是场景的分块尺寸。在图3(a)中,每个场景块可以表示为,其中i是场景块的标签(i=1,2,…,wmhm),使用尺寸为MRsB2Dp×B2Dp的CS测量矩阵ΦCML来获取场景块的CS测量值(MRs是CS技术中的测量率,即基于CS的SORS成像系统获得的压缩测量数据量与原始场景数据量的比值)。这个过程可以表示为:
由于测量矩阵ΦCML中的列数为B×B×Dp,所以CML中每个卷积核的尺寸也为B×B×Dp,因此每个卷积核输出一个测量值。由于测量矩阵ΦCML中的行数为MRs×B×B×Dp,所以CML中需要MRs×B×B×Dp个卷积核来获得MRs×B×B×Dp个测量值。此外,CML中没有偏置值和激活函数,CML的步幅尺寸设置为B×B实现非重叠采样。如图3(b)所示,每个场景块的输出由MRs×B×B×Dp个特征映射组成。场景压缩采样过程可以表示为:
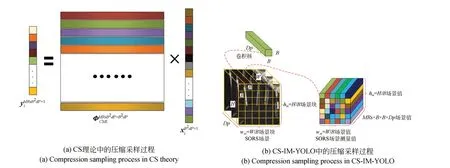
图3 压缩采样过程的示意图Fig.3 Illustration of compression sampling process
其中:*表示卷积运算;X表示场景;Wcml表示CML的权重值,即CS中的LMM;Y表示场景的CS测量值。
因为卷积核的数量需要满足不等式MRs×B×B×Dp≥1,所以需要MRs≥1/12。为了避免在单个MR中场景压缩采样的偶然性,在CS的研究工作[27-28]中将MRs直接取为25%,10%,4%和1%。因此,本文设置的步幅和MRs之间的对应关系如表1。

表1 步幅和MRs之间的对应关系取值Tab.1 Relationship between stride and MRs
2.3 测量值特征提取部分
由于CS测量值的数据量远低于其对应的原始场景,因此测量值的特征提取网络需要提取高质量的浅层、中层和高层特征信息。本文参考相关工作[29]中的特征提取网络,采用了一种现有的框架结构Darknet53。Darknet53中的残差网络能够通过增加网络深度来提高准确率,其内部的残差块使用了跳跃连接,缓解了在深度CNN中增加深度带来的梯度消失问题。
2.3.1 改进的Darknet53主干网络
改进的Darknet53的结构如图4所示。其中,Conv表示卷积层,ResN表示N个残差块的集合,ResN的特性是在特征图尺寸减半的情况下通道数加倍。CS测量值Y可以表示为Y∈Rwm×hm×MRsB2Dp(wm×hm是测量值的尺寸),首先尺寸为3×3、步长为1的卷积层对测量值进行卷积运算得到通道数为32的特征图。然后不断的通过1×1卷积和3×3卷积以及残差边的叠加得到浅层、中层和高层的舰船特征信息feat1′,feat2′和feat3′。测量值特征提取过程可以表示为:
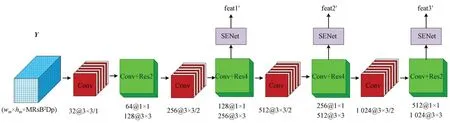
图4 改进的Darknet53主干网络结构示意图Fig.4 Illustration of improved Darknet53 backbone network
其中,Wbb+se表示IDBN的网络参数。
改进的Darknet53网络中除了首个卷积层外其他的卷积层都采用特有的DarknetConv2D结构,即每次卷积都进行BatchNormalization标准化与LeakyReLU非线性运算。LeakyReLU非线性运算的数学表达式如式(7)所示,超参数ai取0.01。
尽管Darknet53网络可以从测量值中提取多层特征信息,但是它无法从测量值中提取到舰船的关键信息。SENet(Squeeze-and-Excitation Netwoks,SENet)模块可以在特征提取过程中将更多注意力放在舰船区域,以获取有关舰船的关键特征信息,并且抑制其他无用信息。本文将SENet添加到Darknet53网络中,得到改进的Darknet53主干网络。
2.3.2 SENet模块
SENet模块添加到Darknet53的位置如图4所示,即SENet添加到浅层、中层和高层特征的输出部分。SENet模块的特征处理过程如图5所示,MaxP表示max pool层,AvgP表示avg pool层,Sig表示sigmoid函数。输入该模块的特征可以表示为,其中W×H是场景的尺寸,Cse是Fint的特征通道数(se=1,2,3,C1=256,C2=512,C3=1024),sse对应输入场景的下采 样 率(se=1,2,3,s1=8,s2=16,s3=32)。首先,采用MaxP和AvgP沿通道轴生成一维特征。然后,采用Conv和Sig来获得特征中元素特性。最后,将得到的各个元素特性乘以输入特征。SENet的运算过程可以表示为:

图5 SENet的结构示意图Fig.5 Illustration of SENet
其中:×表示乘法运算;MPool(·)和APool(·)分别表示最大池化运算和平均池化运算;Conv3×3(·)表示3×3的卷积运算;Sig(·)表示sigmoid非线性运算。
2.4 多特征层特征预测部分
基于无先验框的目标检测模型有很多研究工作[30-31],但是基于先验框的目标检测模型才是主流算法,而且基于无先验框的目标检测模型并没有明显的检测优势[32]。因此,CS-IM-YOLO采用基于先验框的模型来预测舰船的位置信息。
2.4.1 基于特征金子塔的加强特征提取
为了采用基于先验框的模型预测舰船的中心位置信息和宽高位置信息,本文利用特征金字塔网络来加强特征提取。由于待检测舰船的目标尺寸差异很大,包括大型货轮、中型船只和小型巡洋舰,FPN会提取3个尺度的特征层。FPN的结构如图6所示,其中ConvSet表示卷积层的集合,Upsam表示上采样。来自IDBN的浅层、中层和 高 层 的特征信息feat1′,feat2′和feat3′可以表示为,其中Ca是Ffeat的特征 通 道 数(a=1,2,3,C1=256,C2=512,C3=1 024)。sa对应输入场景的下采样率(s1=8,s2=16,s3=32)。通过FPN网络完成上采样和特征信息融合得到输出特征层y3,y2和y1。图6展示了3种尺度特征层的前图感受野:13×13,26×26,52×52。加强特征提取的过程可以表示为:
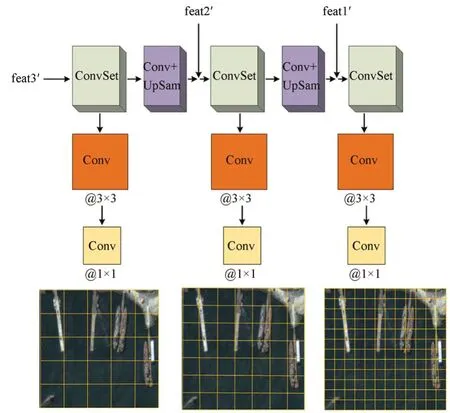
图6 FPN的结构示意图Fig.6 Illustration of FPN
其中,Wfpn表示FPN的网络参数。
2.4.2 多特征层位置信息预测
对于输出特征层y1,y2和y3,每个特征层存在3种尺寸的先验框。先验框的大小和形状是通过k-means算法在训练集上获得,本文获得的3种尺度的9个先验框分别为:(20,29),(40,70),(99,30),(20,147),(123,67),(51,170),(96,127),(96,247)和(178,166)。对于特征层y3,y2和y1,每个网格单元(y1具有169个网格单元,y2具有676个网格单元,y3具有2 704个网格单元)会预测3个预测框的信息,预测信息包括预测框的中心坐标(tx,ty),宽度和高度(tw,th),舰船的置信度和类别概率(c,p)。预测目标绝对位置(bx,by,bw,bh)的 计 算 公 式 如 式(10)~式(13)所示:
其中:cx和cy表示网格单元左上角点的坐标;pw和ph分别表示先验框的宽度和高度;exp(·)表示指数运算。
2.5 CS-IM-YOLO联合训练优化
由于联合训练优化在测量值舰船检测算法中起着至关重要的作用,本文通过学习模型中的所有参数来训练CML和测量值舰船检测网络。模型中所有参数的集合可以表示为Θ={Wcml,Wbb+se,Wfpn},而联合训练的过程就是获得最优的网络参数。如图7所示,黑色箭头表示压缩采样部分和测量值舰船检测部分的联合训练过程,红色箭头表示测量值舰船检测的测试过程。首先,训练好的CML对SORS场景进行压缩采样得到测量值,然后测量值舰船检测网络提取测量值中的舰船位置信息(彩图见期刊电子版)。

图7 CS-IM-YOLO联合优化过程示意图Fig.7 Illustration of joint optimization process of CS-IM-YOLO
3 实验与结果分析
本节通过实验来验证CS-IM-YOLO应用于HSR2016数据集[33]中SORS场景CS测量值舰船检测的准确率。
3.1 数据集
HRSC2016数据集中的舰船包括海上舰船和近海舰船,共有1 680张图像。数据集分为训练集,验证集和测试集,其中验证集损失值最小时所对应的迭代次数就是最佳训练次数。表2列出了训练集,验证集和测试集中的样本数量,分别包含1 176,168和336张场景。部分数据集图像如图8所示。

图8 HRSC2016部分数据集图像Fig.8 Part of HRSC2016 dataset

表2 数据集的划分Tab.2 Dataset partitioning
3.2 实验环境
深度学习(Deep Learning,DL)对硬件要求较高,因此CS-IM-YOLO采用表3中的实验环境。由于实验中场景尺寸不同,在输入网络之前将数据集图像统一设置为416×416。

表3 实验环境Tab.3 Experimental environment
3.3 实验参数
表4显示CS-IM-YOLO训练的参数设置。考虑到GPU内存8 G,将批量大小设置为8。

表4 实验参数Tab.4 Training parameters
3.4 评估指标
舰船检测的预测框与舰船真实框之间的重合度由相交比(Intersection over Union,IoU)表示,其计算公式如式(14)所示:
其中:S∩是预测框和真实框重叠区域面积,S∪是预测框和真实框的总面积。
如果预测结果与真实值之间的IoU>0.5,则将其定义为真正的正样本(True Positives,TP)。如果IoU<0.5,则将其定义为假的正样本(False Positives,FP)。未检测到的真实目标定义为错的负样本(False Negatives,FN)。精度和召回率通常用作评估标准,其计算公式如式(15)~式(16)所示:
然而,由于精度和召回率在数字上是矛盾的,本文添加了F1值和AP值作为评估指标。F1值是精确性和召回率之间不平衡的综合指标。AP值反映了网络性能的整体质量,它定义了一组等距召回率下的平均精度。本文计算了当IoU阈值为0.5时的AP值。F1和AP的计算方法如式(17)~式(18)所示:
3.5 实验结果
为了测试CS-IM-YOLO对于CS测量值的舰船检测效果,本文通过数据集HRSC2016评测算法性能。表5显示了算法的舰船检测精度率、召回率、F1值和AP值。图10显示了测试集部分场景的测量值舰船检测效果。

图10 测试集部分场景的测量值舰船检测效果Fig.10 Ship detection results or CS measurements in some scenes of the test set

表5 HRSC2016数据集下测量值的舰船检测结果Tab.5 Ship detection results on measurements in HRSC2016 dataset
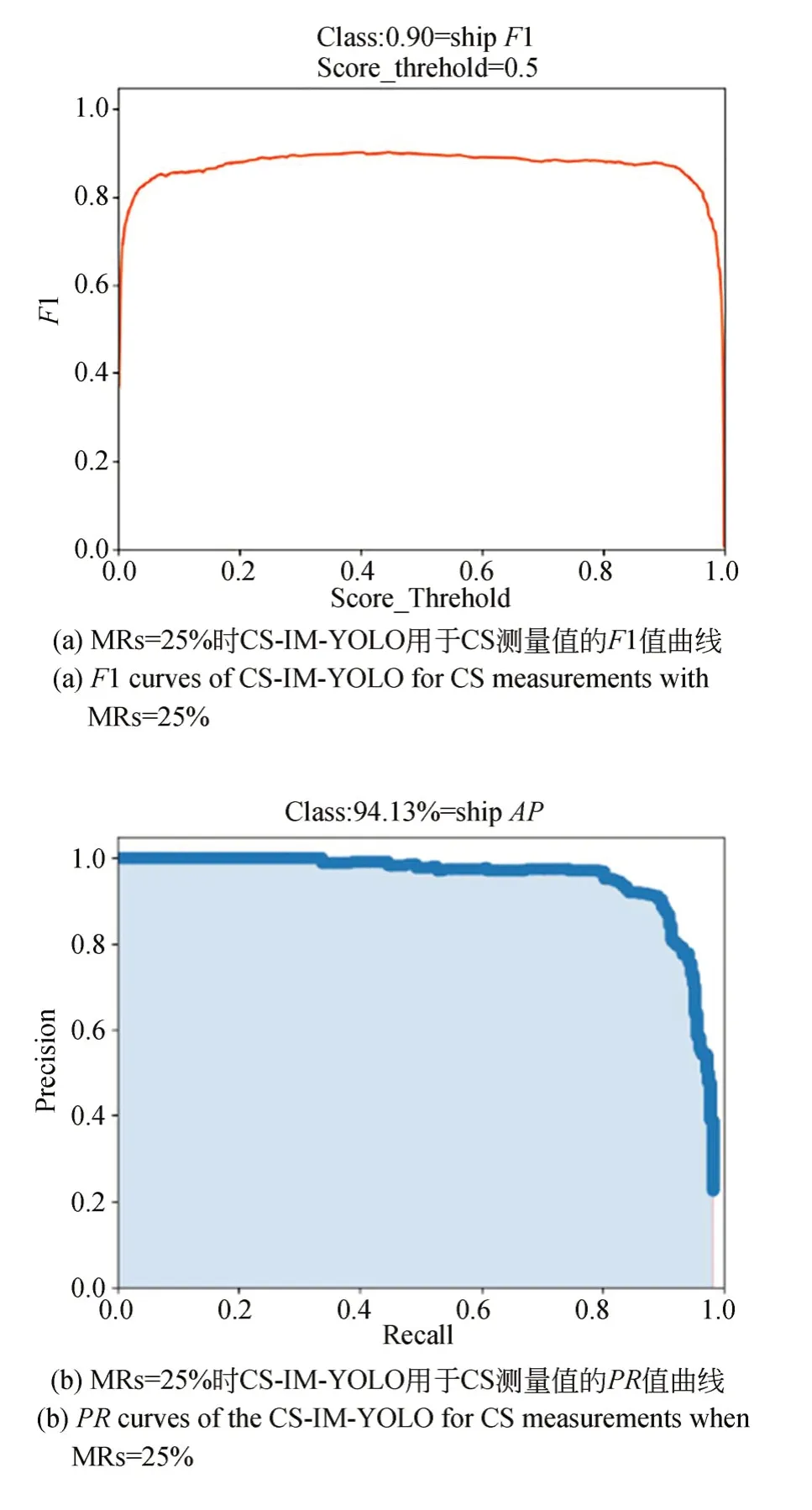
图9 MRs=25%时 CS-IM-YOLO用于CS测量值的 F1 曲线和PR曲线Fig.9 F1 and PR curves of CS-IM-YOLO for CS measurements with MRs=25%
检测精度方面,CS-IM-YOLO模型得分为91.60%;在召回率方面,CS-IM-YOLO的得分为87.59%。由CS-IM-YOLO模型的精度和召回率可得到它的F1值为0.90。CS-IM-YOLO模型对于舰船检测的AP值为94.13%。因此,CS-IM-YOLO可以对场景CS测量值进行舰船检测,同时保证检测的高精度。
如3.2节所述,CS测量值的大小与分块压缩采样中的MR有关。为了测试在不同采样率下的舰船检测性能,本文测试了CS-IM-YOLO 在不同MR下的舰船检测性能,结果如表6所示。此外,通过设置不同的阈值,可以得到CS-IMYOLO在MRs=25%和10%时的F1曲线和PR曲线,如图11所示。从表6中可以看出,CS-IMYOLO的舰船检测性能在MRs=10%时比CSIM-YOLO在MRs=25%时的舰船检测性能差。这是因为随着获取的场景数据量减少,测量值中舰船的特征信息减少,从而导致测量值舰船检测的性能下降。
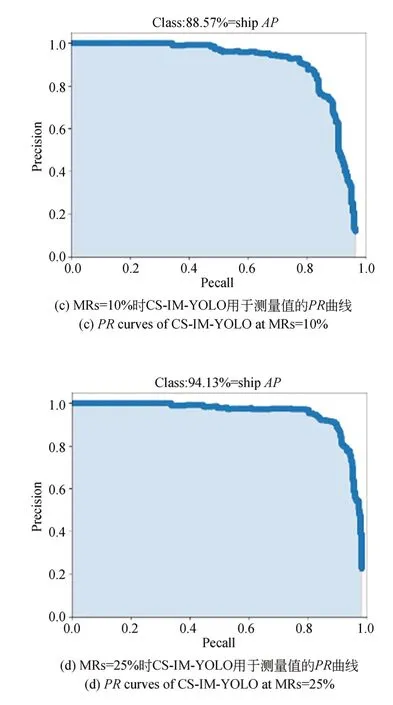
图11 MRs=25%和10%时CS-IM-YOLO用于测量值的F1曲线和PR曲线Fig.11 F1 and PR curves of CS-IM-YOLO for measurements when MRs=25% and 10%
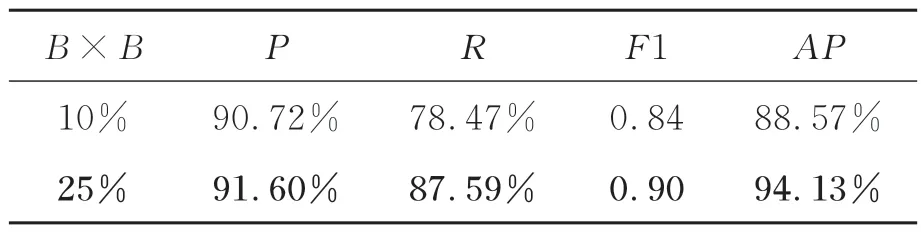
表6 CS-IM-YOLO在不同MRs下的舰船检测结果Tab.6 Ship detection results of CS-IM-YOLO under different MRs
为了评估主干网络中SENet模块的功能,我们对SENet进行了消融实验,相应的实验结果如表7所示。此外,通过设置不同的阈值,可以得到“Darknet53+FPN”和“IDBN+FPN”在MRs=25%时的F1曲线和PR曲线,如图12所示。在表7中,通过对比“Darknet53+FPN”和“IDBN+FPN”的实验结果可以分析SENet的性能,从表中可以看到P增加了2.29%,R增加了2.19%,F1值增加了0.03,AP值增加了1.74%。因此,使用SENet模块去改进Darknet53主干网络可以达到更好的检测效果。这是因为SENet模块可以从CS测量值中更好地捕获舰船特征信息。
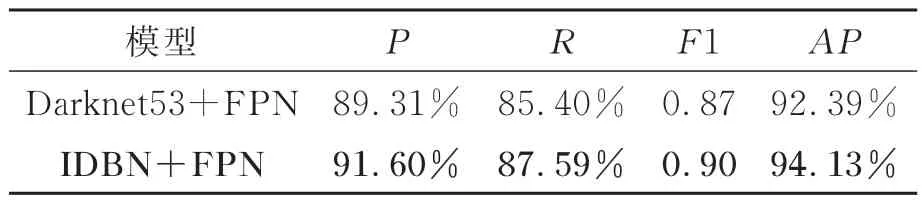
表7 在MRs=25%时,SORS场景CS测量值舰船检测结果Tab.7 Ship detection results on CS measurements of SORS scenes at MRs=25%

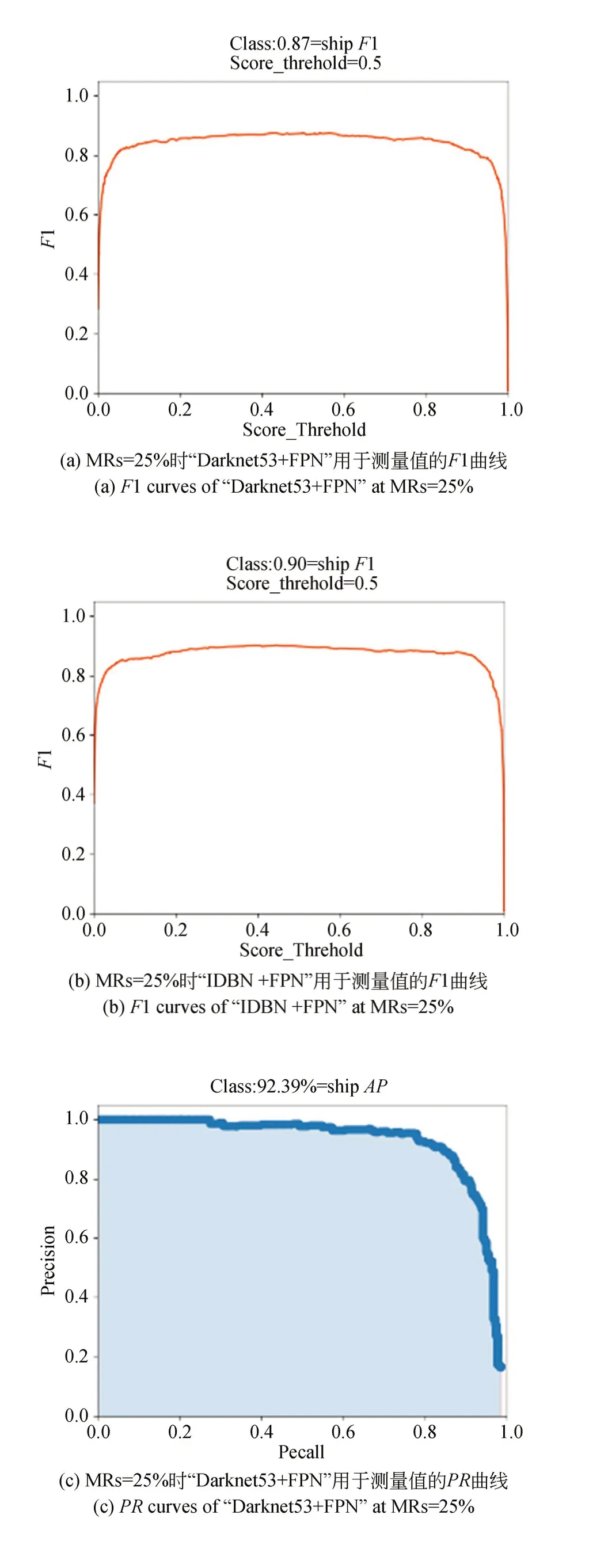
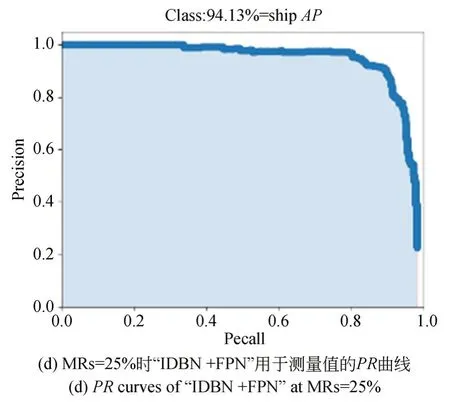
图12 MRs=25% “Darknet53+FPN”和“IDBN +FPN”用于测量值的F1曲线和PR曲线Fig.12 F1 and PR curves of “Darknet53+FPN” and “IDBN+FPN” for measurements when MRs=25%
为了评估模型对SORS场景退化后的适用性,对测试集场景进行退化处理,退化处理分为三种:运动模糊、高斯噪声和运动模糊加高斯噪声。其中,运动模糊的像素偏移值设置为12,偏移方向设置为45°,高斯白噪声的均值设置为0,方差设置为0.01。退化处理后的部分场景如图13~图14所示。本文采用训练后的CS-IM-YOLO模型在MRs=25%时对退化处理的测试集场景进行实验,相应的实验结果如表8所示。对比模型在无退化处理和三种退化处理的实验结果,可以分析场景退化对模型性能的影响。从表8的第1行和第2行实验结果可以看到P降低了0.84%,R降低了8.76%,F1值降低了0.06,AP值降低了6.74%。从表8的第1行和第3行实验结果可以看到P降低了4.29%,R降低了2.19%,F1值降低了0.04,AP值降低了3.62%。从表8的第1行和第4行实验结果可以看到P降低了6.06%,R降低了9.85%,F1值降低了0.09,AP值降低了7.97%。因此,运动模糊和高斯噪声的场景退化都会降低模型的检测效果,而且两者叠加到一起会更加影响检测效果。但是,两者叠加到一起后的模型舰船检测精度为85.54%,召回率为77.74%,F1值为0.81,和AP值为86.16%,这说明CS-IM-YOLO模型也可以完成对退化场景测量值的舰船检测。
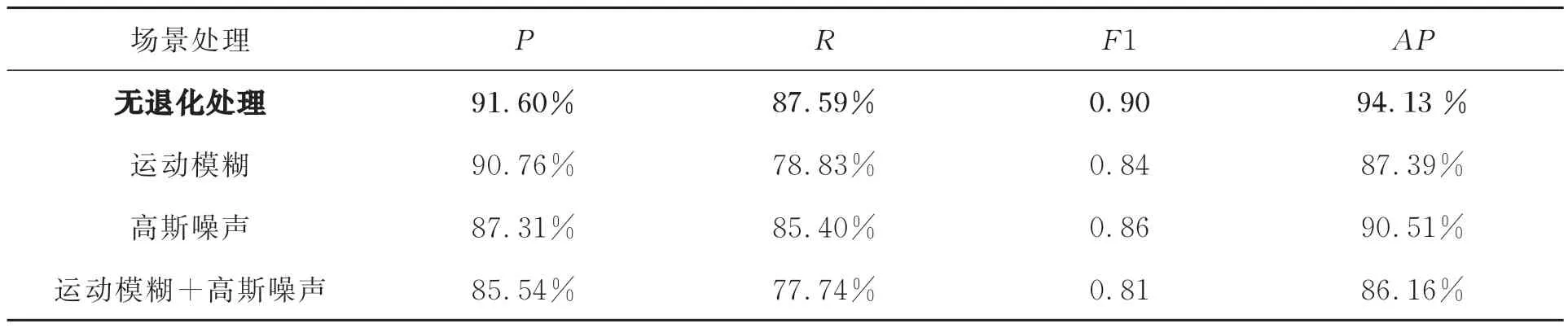
表8 MRs=25%退化后的SORS场景CS测量值舰船检测结果Tab.8 Ship detection results on CS measurements of degraded SORS scenes at MRs=25%

图13 测试集中场景A的退化处理结果Fig.13 Degradation processing results of scene A in the test set

图14 测试集中场景B的退化处理结果Fig.14 Degradation processing results of scene B in the test set
为了评估模型对SORS场景分辨率等级的适用性,本文对测试集场景进行降低分辨率处理,降低分辨率处理分为分辨率/4和分辨率/8。处理后的部分场景如图15~图16所示。采用训练后的CS-IM-YOLO模型在MRs=25%时对处理后的测试集场景进行实验,相应的实验结果如表9所示。对比模型在理想场景和两种降低分辨率处理的实验结果,可以分析场景分辨率等级对模型性能的影响。从表9的第1行和第2行实验结果可以看到P降低了2.54%,R降低了4.38%,F1值降低了0.04,AP值降低了2.25%。从表9的第1行和第3行实验结果可以看到P降低了6.31%,R降低了13.15%,F1值降低了0.11,AP值降低了12.99%。因此,场景分辨率等级的降低会降低模型的检测效果。但是,分辨率/8后的模型舰船检测精度为85.29%,召回率为74.09%,F1值为0.79,和AP值为81.14%,这说明CS-IM-YOLO模型可以完成低分辨率等级的场景测量值的舰船检测。

图15 测试集中场景A的降低分辨率处理结果Fig.15 Reduced resolution processing results of scene A in the test set

图16 测试集中场景B的降低分辨率处理结果Fig.16 Reduced resolution processing results of scene B in the test set

表9 MRs=25%时降分辨率后的SORS场景CS测量值舰船检测结果Tab.9 Ship detection results on CS measurements of reduced resolution SORS scenes at MRs=25%
4 结论
为了对SORS场景的CS测量值进行舰船检测,本文提出了CS-IM-YOLO模型,该模型由模拟成像系统分块压缩测量的CML和测量值舰船检测网络组成。在压缩采样过程中,训练完的CML直接对场景执行卷积运算得到全图CS测量值。对于CS测量值的舰船检测,舰船检测网络首先使用改进的Darknet53主干网络来提取测量值的舰船特征信息,然后使用特征金字塔网络来强化特征提取同时融合多层特征信息进而预测舰船的位置信息。本文用数据集HRSC2016评测算法性能,实验结果表明,该算法对于SORS场景测量值舰船检测的检测精度为91.60%,召回率为87.59%,F1值为0.90,和AP值为94.13%。因此,它可以实现SORS场景测量值的高精度舰船检测。并且该算法也可以完成退化场景测量值和低分辨率等级场景测量值的舰船检测。在未来的工作中,将通过基于CS的SORS 成像系统的物理平台获取CS测量值,研究物理平台下测量值的获取情况,并对其进行高精度舰船检测。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12 08:07:10
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
舰船科学技术(2021年12期)2021-03-29 01:28:44
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2018年19期)2018-11-14 02:37:08
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
自动化学报(2017年11期)2017-04-04 02:52:58
舰船科学技术(2016年1期)2016-02-27 15:39:26
噪声与振动控制(2015年4期)2015-01-01 07:08:21
电视技术(2014年19期)2014-03-11 15:38:20
