
基于Schema增强的中文实体关系抽取方法
2023-03-08 10:57饶东宁
软件导刊 2023年2期
饶东宁,李 冉
(广东工业大学 计算机学院,广东 广州 510000)
0 引言
实体关系抽取是知识图谱构建、智能问答、信息检索等下游任务的核心技术之一,旨在从非结构化文本中抽取出结构化信息,即抽取出实体及其间关系,并以三元组的形式<头实体,关系,尾实体>展现,例如“甄嬛传由郑晓龙执导”经过实体关系抽取得到三元组<甄嬛传,导演,郑晓龙>。
早期基于神经网络的实体关系抽取工作采取流水线式抽取方法,先抽取实体再进行关系分类,这种方法实现起来比较简单,但存在错误积累、交互缺失和实体冗余等问题。后期的联合式抽取方法[1]能够在一个模型中实现实体抽取和关系抽取,这种方法能够进一步利用两个子任务之间的潜在信息,缓解流水线式方法所带来的问题,逐渐成为实体关系抽取主流方法。然而,目前大部分联合式抽取方法主要存在3 个问题:首先,针对中文文本的实体关系抽取,在进行分词时常会因边界切分错误而引起歧义问题;其次,无法解决实体冗余和关系重叠问题;最后,关系种类和数量均是预定的,往往存在不够全面的问题。
针对以上问题,本文在已有方法的基础上:首先采用基于字词混合嵌入的方式避免实体边界切分错误引起的歧义问题,在保留字的灵活性的基础上融合了词的信息,并加入位置嵌入保留字的位置信息;其次采用指针标注的方式解决实体嵌套和关系重叠的问题,通过识别出的头实体信息标记其对应的关系和尾实体,每个头实体可存在多个关系和尾实体;最后提出基于Schema 增强的方法,根据不同数据集抽取出其对应的实体类型以及关系种类之间存在的模式并进行融合,构建出适配于不同数据集的Schema,以提高实体关系抽取方法在不同数据集间的可迁移性,同时可以解决实体冗余的问题。本文将该方法称为基于Schema 增强的中文实体关系抽取方法,简称为SCHEMA。
1 实体关系抽取方法研究现状
早期的实体关系抽取工作多采用基于规则的方法,需要专家设计大量规则或人工进行特征筛选,不但需要操作人员有专业的知识背景,而且对数据的迁移且信息迁移很差,无法满足大规模的实体关系抽取。近年来,由于深度学习技术[2]的持续发展与水平提高,神经网络模型框架[3]日渐丰富,神经网络方法也被引入到实体关系抽取任务中。现阶段,基于神经网络的实体关系抽取方法根据实体识别和关系抽取这两个子任务是否独立,分为流水线式抽取方法和联合式抽取方法两类。流水线式抽取方法通常先进行命名实体识别[4],再进行实体对间的关系分类[5],其优点为实现起来比较简单,可以灵活针对两个子任务分别选择合适的实体识别和关系抽取模型,在工业界被广泛运用。但同时缺点也是显而易见的,首先命名实体识别阶段的错误会影响下一步关系分类的表现,存在误差积累问题;其次,需要逐一遍历任意两个实体对,判断是否存在关系并进行关系分类,但并不是所有实体对之间都存在关系,存在实体冗余问题;最后,忽略了这两个子任务间天然存在的语义联系和依赖关系,存在交互缺失问题。
联合式抽取方法使用一个模型进行实体识别和关系抽取,考虑到了两个子任务之间潜在存在的交互关系,可以进一步利用两个子任务之间的潜在信息,在一定程度上避免了流水线式方法中存在的弊端,与之前的方法相比有明显提高,但大多数现有方法无法解决文本边界切分错误引起的歧义问题,同时无法处理句子中包含的实体冗余以及关系重叠的情况,也存在不同数据集的关系不能很好迁移的问题。
为了应对句子中包含关系的重叠情况,许多研究者进行了改进。例如,Bekoulis 等[6]提出的MHS 模型使用条件随机域[7]层将实体识别任务和关系提取任务建模为一个多头选择问题;Zhang 等[8]提出的Seq2UMTree 模型通过将三元组中的解码长度限制为3 个,并通过去除三元组之间的顺序来最小化曝光偏差的影响;Ren 等[9]提出的CoType模型使用数据驱动的文本分割算法来抽取实体,并将实体、关系、文本特征和类型标签共同嵌入到二个低维空间,分别进行实体和关系抽取;Wei 等[10]提出一种级联式解码实体关系抽取框架CASREL,使用多层二元指针网络标记实体,将关系建模为将头实体映射到尾实体的函数,级联解码器包含一个头实体标注器和一系列关系特定的尾实体标注器,将两个子任务转化为序列标注问题;Wang 等[11]提出的TPLinker 模型是一种单阶段联合式的实体关系抽取模型,将实体关系联合抽取转化为标记对接问题,采用统一的标注方法提取实体和重叠关系,模型不存在训练与推理之间的间隙,可以解决暴露偏差问题;Ye 等[12]提出的CGT 模型是一个带有生成式Transformer 的对比学习实体关系三元组提取的框架,该框架是一个共享的Transformer模块,将三元组抽取视为一个序列生成任务,并提出一种新颖的三元组校准算法,能够在推理阶段过滤掉错误的三元组;葛君伟等[13]采用分层标注的方式进行实体关系的联合抽取,能够在一定程度上解决关系重叠的问题。
为解决文本边界切分错误引起的歧义问题,许多研究者进行了尝试。例如,Li 等[14]提出的MG Lattice 模型将字级信息集成到字符序列输入中,从而避免分割错误,同时利用外部语言知识减轻多义歧义;Zhong[15]提出一种融合词级信息和字符级信息的深度学习框架FGGRM,利用多粒度特征与门控循环机制的高效融合动态学习语义信息,以减少分割错误的影响;Zhong[16]设计了一个多级门控循环机制的框架MGRSA,将词粒度信息统一为字符粒度信息。为了减少多义性歧义,在两部分上使用了自我注意,包括具有外部语义知识的词向量;葛君伟等[13]采用基于字词混合嵌入的方式,在词向量的基础上融合字向量信息,并且加入了位置嵌入来保留字在文本中的顺序,能够在一定程度上解决中文分词时边界切分错误所造成的歧义问题。
然而,目前已有的方法往往不能同时解决实体冗余、关系重叠以及中文文本的边界切分问题,同时不同方法对特定的训练预料依赖性较高,可迁移性较差。因此,本文融合Wei 等[10]和葛君伟等[13]的思想,分别使用指针标注的方法和字词混合嵌入的方法解决关系重叠以及中文文本边界切分的问题,同时自行构建了一个融合不同数据集实体类型和关系种类之间模式的Schema,以解决实体冗余问题,同时可以提高实体关系抽取方法在不同数据集之间的可迁移性。
2 基于Schema增强的中文实体关系抽取模型
本文模型结构如图1 所示。首先进行字id 序列的输入,利用字词混合嵌入得出相应的文本向量序列,再加上位置嵌入,进入编码层进行编码,得到经过编码后的序列H。将文本向量序列H 输入主体指针网络,从而得到头实体S;然后查询与头实体S 对应的Schema,筛选出所有的候选关系作为先验特征与S 对应的子序列HS以及编码序列H 进行相加;最后将相加后的序列输入Transformer 层,对S在Schema 中对应的每一个候选关系均预测对应的尾实体的首、尾位置,最终得到文本中所有的三元组。在整个过程中,对于在Schema 中不存在对于关系的头实体,则不进行其对应关系的尾实体抽取。
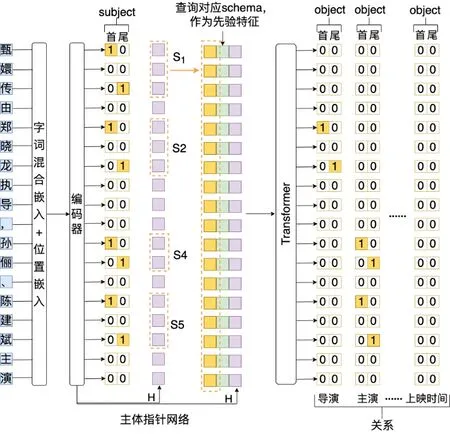
Fig.1 Chinese entity relationship extraction model based on Schema enhancement图1 基于Schema增强的中文实体关系抽取模型
2.1 字词混合嵌入
在中文分词中往往会出现词语边界切分错误所引起的歧义问题,不同的分词边界往往代表作不同的含义,例如对于“下雨天留客天留我不留”,不同的分词方式会造成完全不同的含义,分别为“下雨天留客/天留我不留”和“下雨天/留客天/留我不/留”。通常采取字标注的方法避免这个问题,即以字为单位进行输入。然而单纯的字嵌入难以存储有效的语义信息,为更有效地融入语义信息,本文采取葛君伟等[13]使用的字词混合嵌入思想,即预先训练一个word2vec 模型,通过该模型加载对应的词向量,然后与字向量进行融合。为保持向量维度不变,使用一个变换矩阵对词向量的维度进行转换。通过公式(1)进行字向量与词向量的融合:
式中,ti表示字词向量混合的结果向量,wk表示加载的第k个词向量,E为变换矩阵。为保持维度不变,词向量重复转换、融合的次数与该词语的字数相同。
在执行实体关系抽取任务时,字在文本中的的位置也非常重要,字与字之间的不同顺序会影响对整个句子的意思理解。为充分利用字的位置信息,在融合字向量与词向量的基础上加入位置向量。具体做法为从0 开始依次加1对句子中的每一个字进行编码,用于代表每个字在句子中的不同顺序,然后全零初始化一个与字向量维度相同的嵌入层,传入位置编码信息后输出对应的位置向量pi,然后与融合字词向量的结果ti相加传到下一层。
2.2 指针标注
传统的序列标注方案假定每个字只有一种标签,无法解决实体嵌套问题。同时这类标注方案假定一个实体对之间最多存在一种关系,无法解决关系重叠问题。为解决实体嵌套和关系重叠问题,本文采用Wei 等[10]的指针网络标记方案CASREL 的思想。
在头实体识别阶段,首先抽取出所有可能存在的实体。头实体的开始和结束字符均用1 表示,不是边界的字符用0 表示。对于文本中存在的多个实体,采用就近原则,某个开始位置为1 的字符到其后最近的结束位置为1的字符之间的词就是一个头实体。通过公式(2)、(3)计算字符是头实体边界的可能性:
在关系—尾实体识别阶段,针对每一个头实体,遍历其所有在Schema 中的候选关系 r,为每一个关系 r 都确定相应的尾实体。如果存在多个尾实体,则采用就近原则确定实体边界;如果尾实体不存在,则采用null 型尾实体表示。通过公式(3)、(4)计算字符为头实体特定关系对应的尾实体边界的可能性:
2.3 Schema增强
本文所使用的Schema 是指已标注数据集的三元组中实体类型与关系种类之间存在的模式。在进行模型训练前,首先根据已有的数据集去构建其关系模式Schema,进而在模型训练过程中将Schema 作为先验特征输入模型中,以提高实体关系抽取的效果。
2.3.1 Schema构建过程
首先针对不同的数据集自动抽取其Schema,对于Du-IE 数据集,其已对实体类型进行了标注,且本身数据标注比较详细且规范,因此直接根据数据集中所有的头实体类型、关系种类、尾实体类型抽取出对应的Schema;对于FinRE 以及SanWen,由于原始数据集没有对实体类型进行标注,因此本文先对其数据集中的所有实体进行了类型的标注,使用方法为Stanford CoreNLP,并使用了自定义词典进行文本分词,以提高分词准确性。在对数据集的实体进行类型标注后,采取与DuIE 同样的方式抽取出各自对应的Schema。最后合并3 个数据集对应的Schema,作为一个Schema 库,通过整体实体关系抽取任务的先验特征进行效果增强。本文使用的Schema 示例如图2 所示,其中subject_type 表示首实体类型,predicate 表示关系名,object_type 表示尾实体类型。

Fig.2 Schema example图2 Schema示例
2.3.2 利用Schema进行增强的方法
将构建好的Schema 库包含的所有关系模式标注上特定的序号,变成一个数字与模式一一对应的词典。当模型输入一个新文本时,首先经过头实体识别步骤,识别出所有实体,对于每个头实体,根据其实体类型去Schema 库中进行匹配,定位头实体类型所存在的关系种类以及对应的尾实体类型,将其转化为与标注结构相同的0/1 向量,与编码向量进行相加,然后进行下一步尾实体的标注。对于在Schema 库中找不到对应类型的头实体,则不进行下一步的尾实体标注任务。
2.3.3 使用Schema进行增强的作用
一方面对于所有标注出的实体均根据其实体类型在Schema 库中进行匹配,不存在对应关系种类的实体则不进行后续的尾实体标注任务,可以在一定程度上解决实体冗余的问题;另一方面,由于融合了不同数据集的关系模式,且针对一个新的数据集均可抽取出其关系模式进行初始的Scheme 扩展,可以在一定程度上增强实体关系抽取方法在不同领域数据集的可迁移性以及关系种类的约束。
3 实验方法与结果分析
3.1 数据集
本文使用的数据集为DuIE、FinRE、SanWen 三大主流中文实体关系抽取数据集,原因是这3 个数据集均为开源免费的数据集,原始数据获取比较简单,可供大部分人进行研究,而且这3 个数据集的文本表述规范程度不同,代表了不同领域的数据。①DuIE 数据集[17]是来自百度信息抽取比赛的公开数据集,数据来源于百度百科和百度新闻摘要,文本表述整体相对规范;②FinRE 数据集是Li 等[14]手动标注的来自新浪财经和财经新闻的数据集,文本表述整体比较规范,包含44 类关系(包含双向关系),其中包含一类特殊关系NA,表示标记的实体对之间不存在关系;③SanWen 数据集[18]包含837 篇中文散文,文本表述整体比较口语化,包含9 类关系,其中训练集695 篇,测试集84篇,验证集58篇。数据集统计信息如表1所示。
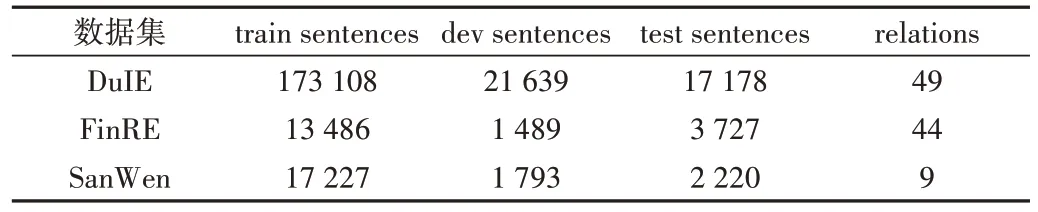
Table 1 Statistics Information of datasets表1 数据集统计信息
3.2 评估指标
实体关系抽取任务通常使用精确率(precision)、召回率(recall)和F1(F-measure)值作为评价指标,计算公式如下:
3.3 实验设置
操作系统为Ubuntu 18.04.4,CPU 型号为Inter(R)Xeon Silver 4110,显卡型号为GeForce RTX 2080Ti。实验环境为Python3.6、Tensorflow1.14。编码器为BERT,其版本为谷歌官方提供的中文Base 版模型。字词混合嵌入使用的word2vec 词向量已在百度百科以及搜狗实验室数据集上预先训练完成,模型训练时直接加载word2vec 词向量。实验中初始化字嵌入向量维度为128,词嵌入向量维度为256,位置向量维度为128。训练过程采用学习率为0.001的反向传播算法,dropout 取0.25,批大小为32。在训练阶段使用Adam 优化器,激活函数为sigmoid。
3.4 实验结果与分析
为验证在对中文数据集进行实体关系抽取时SCHEMA 的提升效果,在3 个数据集上与文献[6]、[8]、[9]、[14]、[15]、[16]中的方法进行比较实验,结果如表2 所示。可以看出,本文方法是所有比较方法中表现最好的。在DuIE 数据集上,SCHEMA 与比较方法中表现最好的分别实现了precision、recall 以及F1 值近7%、10%、10%的提升;在FinRE 数据集上,SCHEMA 与比较方法中表现最好的分别实现了precision、recall 以及F1 值近14%、22%、18%的提升;在SanWen 数据集上,SCHEMA 与比较方法中表现最好的分别实现了precision、recall 以及F1 值近11%、10%、10%的提升。可见,SCHEMA 在FinRE 和DuIE 数据集上具有更好的表现,但在SanWen 数据集中的表现不如在DuIE和FinRE 上的表现,这可能是由于SanWen 中的句子均较口语化,非正式表达句子中的实体关系抽取面临的挑战更大。值得一提的是,SCHEMA 在FinRE 数据集上的表现与其他已有方法相比有较大提升,说明SCHEMA 对于类似于FinRE 数据集这种较为规范化书写的文本有较大提升,进一步表明了利用Schema 增强的有效性。虽然SCHEMA 在不同数据集上的表现略有不同,但从整体性能来看SCHEMA 的性能最为均衡,表现出其在不同数据集上的可迁移性。同时,SCHEMA 可以解决关系重叠问题,如“甄嬛传由郑晓龙执导,孙俪、陈建斌主演”,SCHEMA 可抽取出三元组<甄嬛传,主演,孙俪>以及<甄嬛传,主演,陈建斌>。
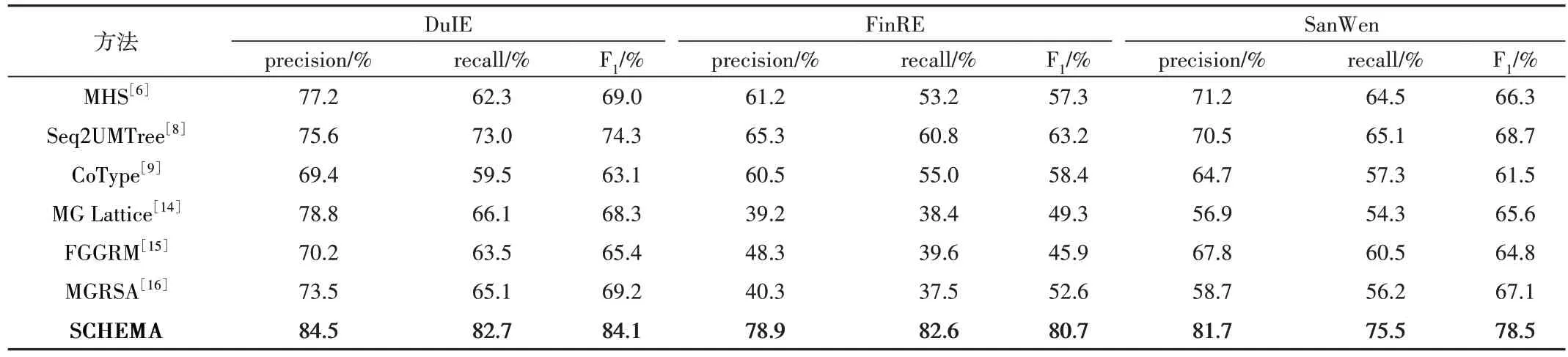
Table 2 Comparison of experimental results表2 实验结果比较
为进一步研究SCHEMA 的各个模块组件对整体性能的贡献,本文还对所有数据集进行了消融实验,结果如表3所示,其中w/o 表示不使用。可以看出,字词混合嵌入提供了5%以上的F1值提升改进,Schema 将其提高了1 倍,获得近10%的F1值改进,进一步表明了利用Schema 进行增强方法的有效性。具体而言,在DuIE 数据集上只使用Schema,不使用字词混合嵌入的方法,出现了最高的precision值(87.1%),但recall 和F1 值并不高,表明Schema 与字词混合嵌入方法结合的有效性;在FinRE 数据集上进行Schema增强取得的性能提高最显著,说明Schema 增强方法对类似于新闻这种行文比较规范的数据集更加友好;在DuIE和FinRE 数据集上进行字词混合嵌入带来的性能改进比在SanWen 数据集上更为显著,可能是由于word2vec 的训练材料是百度百科词条,比散文的表述要正式。
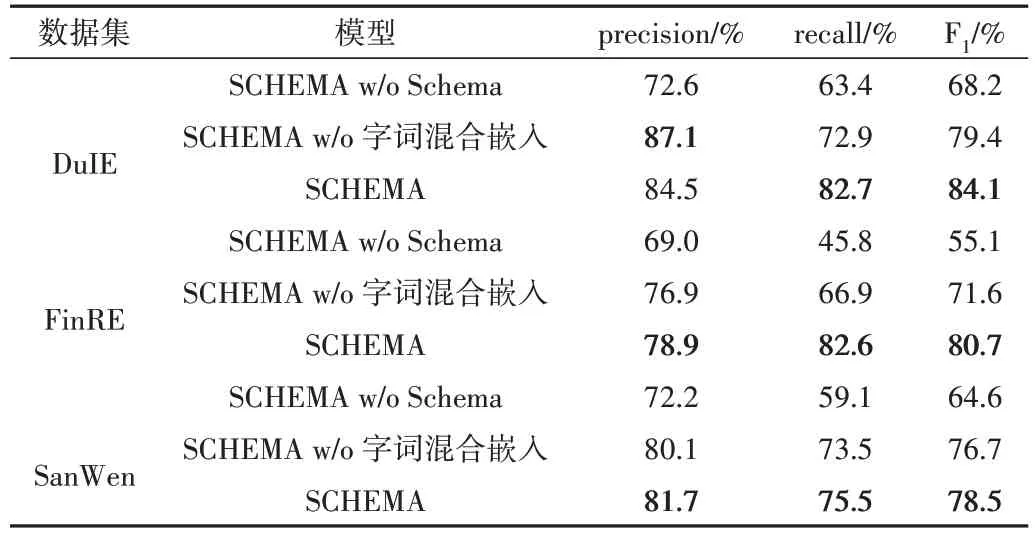
Table 3 Ablation experiment results表3 消融实验结果
4 结语
本文提出的基于Schema 增强的中文实体关系抽取模型通过构建Schema 改善目前实体关系抽取面临的关系种类和数量不够全面的问题,提高了模型在不同数据集之间的迁移性以及在一定程度上解决了实体冗余的问题。该模型同时采用字词混合嵌入和指针标注的方法,分别解决了中文分词可能遇到的边界切分出错问题和实体重叠问题。比较实验结果表明,该模型在DuIE、FinRE 和SanWen数据集上的表现优于MHS、Seq2UMTree、CoType 等现有模型。Zhong 等[19]研究表明实体类型信息对于实体关系抽取任务至关重要,后续将尝试将实体类型与关系抽取任务进行融合[20-21],进一步提升中文实体关系抽取效果。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
山西大学学报(自然科学版)(2021年1期)2021-04-21
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
中国外汇(2019年18期)2019-11-25
五邑大学学报(自然科学版)(2019年3期)2019-09-06
数学物理学报(2017年5期)2017-11-23
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
