
融合轻量级ViT与CNN的广范围红外图像超分辨率重建
2023-03-08 10:56沈恺涛闵天悦胡德敏
软件导刊 2023年2期
沈恺涛,闵天悦,胡德敏
(1.上海理工大学 信息化办公室;2.上海理工大学 光电信息与计算机工程学院,上海 200093)
0 引言
图像超分辨率重建是指根据低分辨率图像(Low Resolution,LR)通过一定方法重新构建成为高分辨率图像(High Resolution,HR)。基于深度学习的超分辨率重建方法采用人工神经网络构建LR 至HR 的端到端模型,重建效果比传统的重建方法更佳。以街景路况为主的远红外图像像素分布均匀、目标物较少,需要重建的原始分辨率较低,在超分辨率模型中采用注意力机制可根据不同特征图的贡献度赋予权重以辅助重建,而更复杂的红外图像,如近红外图像细节纹理更丰富,原图尺寸较大,因此降质退化更复杂,进行超分辨率上采样时解空间更广。卷积神经网络(Convolution Neural Networks,CNN)模型的注意力机制感受野过小,难以捕捉全局像素注意力关联信息。红外图像的超分辨率重建本身受限于高分辨率纹理在退化过程中的复杂降质,可能导致生成图像模糊、缺乏细节纹理,基于生 成对抗网络[1](Generative Adversarial Networks,GANs)的图像重建方法[2]可以缓解此问题,但产生的伪影无法彻底解决,导致客观评价指标偏低。
图像超分辨率重建是根据现有的稀疏像素预测出密集像素的问题。例如,Dong 等[3]将CNN 应用于图像超分辨率重建中,并提出3 层SRCNN(Super Resolution Convolutional Neural Network)模型结构;Shi 等[4]采用亚像素卷积层进行上采样,改进了双三次插值法以及反卷积的上采样效果。此外,浅的CNN 性能有限,而单纯加深模型易出现梯度消失和梯度爆炸的问题,自ResNet[5]和DenseNet[6]被提出后,许多模型采用残差连接或密集连接构建深层网络进行重建;TTSR(Texture Transformer Network for ImageSuper-Resolution)[7]模型采用Transformer[8]的自注意力机制捕获图像不同区域的长距离相关性,虽然取得了优异的重建效果,但训练时需要大量先验参考图像。
目前,通用的超分辨率方法常直接应用于红外图像的重建。例如,Choi等[9]将SRCNN 用于红外图像的超分辨率重建,但与传统的插值方法相比峰值信噪比提升幅度有限;Du 等[10]将RGB 与红外特征图融合输入模型进行重建,但需要大量一一对应的红外与RGB 图像对;Yang 等[11]通过特征空间的相互依赖自适应调整空间区域的权重,混合使用通道和空间注意力机制,使得红外图像的重建过程中保留了更多结构信息,取得了较高的结构相似度;邵保泰等[12]考虑到SRGAN(Super Resolution Generative Adversarial Network)能够改善视觉效果的特性,将其应用于以街景路况为主的热红外图像重建,适应了4 倍放大倍率下的细节修复,但该模型损失函数出现震荡,需要改进训练策略;邢志勇等[13]通过引入残差中的残差块和特征判别器减少了伪影的产生,有效改善了红外图像的重建质量。笔者先前提出的LI-SRGAN 模型[14]虽然改进了上述方法,融合了轻量级注意力机制,在街景路况红外图像的重建上取得了较好效果,但对于波长范围广的红外图像,例如降质退化更复杂、上采样时解空间更广的近红外图像,CNN 的注意力机制只能聚焦于图像局部特征,难以捕获全局注意力信息。
针对上述问题,本文提出一种重建广范围红外图像的超分辨率模型LI-SRViT(Lightweight Infrared Image Super-Resolution using Vision Transformer),结合无批量归一化层的轻量级残差块和轻量级视觉Transformer 块(Vision Transformer,ViT)构建全局自注意力机制模型,学习不同特征图区域之间的长距离注意力依赖关系以辅助重建,约束解空间;采用Huber 损失函数使模型稳定收敛;采用迭代上下采样的结构学习HR 与LR 图像对的深层变换关系。
1 模型构建
基于深度学习的超分辨率上采样重建方法得到的超分辨率图像为真实高分辨率图像IHR的近似估计ISR,超分辨率重建方法为:
式中,F为超分辨率模型,θ为模型参数,L为损失函数,λ为惩罚系数,Φ(θ)为正则项。
LI-SRViT 模型架构如图1 所示,其采用迭代上下采样结构,以学习高低分辨率图像之间的深层关系。
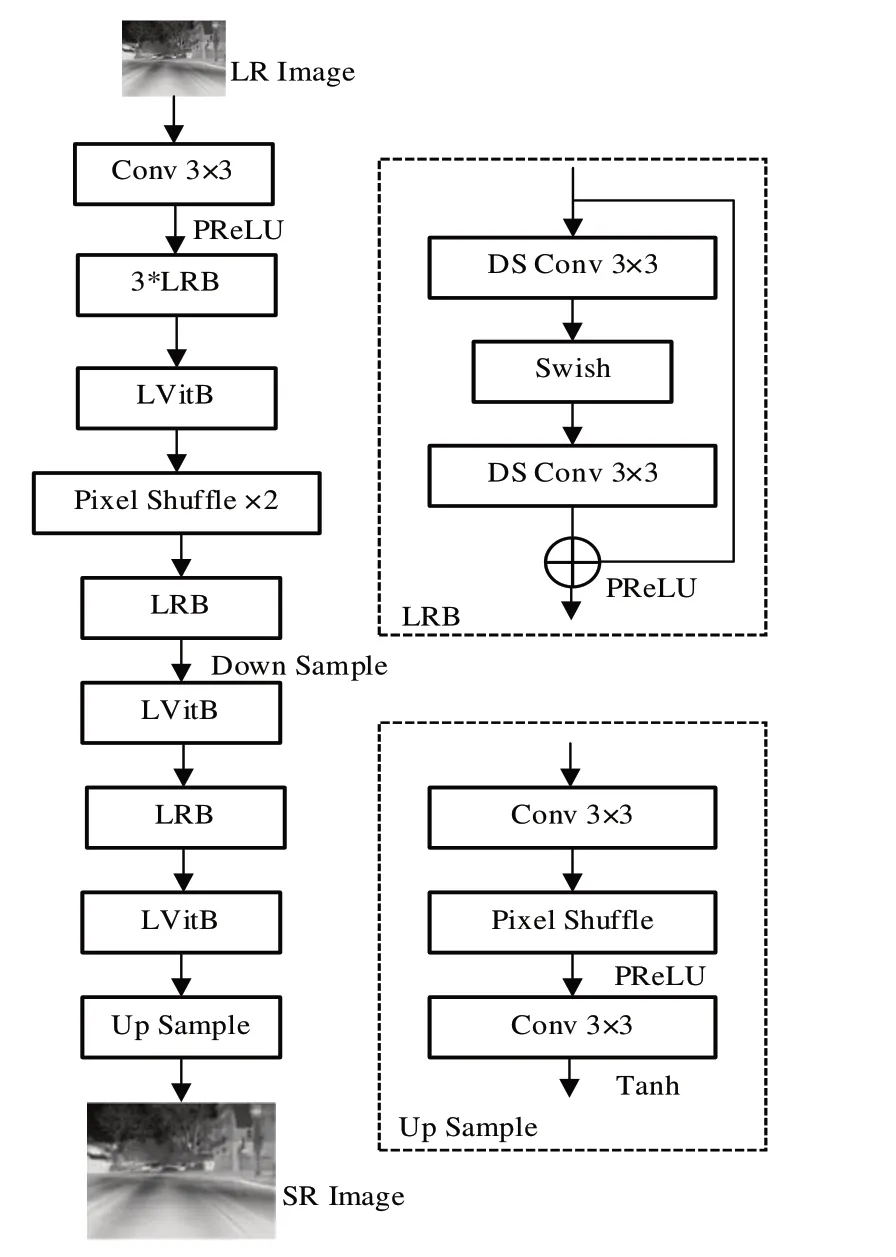
Fig.1 Structure of LI-SRViT图1 LI-SRViT模型结构
当前基于视觉Transformer 架构的模型虽然在许多计算机视觉任务性能上得到了提升[15],但要达到类似SOTA的CNN 模型效果需要堆叠更多Transformer 块[16],耗费大量算力资源。本文模型考虑将Transformer 的自注意力机制计算融入CNN 模型,并实现轻量化。该模型首先通过一个基本3×3 卷积层进行低频特征提取,然后通过3 个轻量级残差块(Lightweight Residual Block,LRB)进行残差特征提取。模型经过轻量级视觉Transformer 块(Lightweight ViT Block,LViTB)进行全局自注意力特征计算,加强图像不同部分之间的注意力关系以辅助重建,在模型中间首先进行图像尺寸的两倍上采样后缩小,然后通过两个LViTB和上采样模块(Up Sample)完成重建。
1.1 LRB
LI-SRViT 模型通过LRB 进行初步特征提取,其首先在深度可分离卷积层(Depthwise Separable Convolution,DS Conv)中间进行通道收缩,使用更适合重建的Swish 激活函数[17]激活后进行通道扩张。Swish激活函数表示为:
相较于ReLU 激活函数,Swish 激活函数可使输出均值接近于0 而不是将负值全部舍弃,可有效利用全局参数[18]。
1.2 LViTB
LI-SRViT 模型经过LRB 进行初步特征提取后,通过LViTB 进行全局自注意力机制计算,以增强图像整体语义表达。LViTB 结构如图2 所示,其由MobileViT[19]改进而来,在特征融合阶段引入红外特征图线性灰度变换(Linear Grayscale Transform,LGT)以适应红外图像的重建。
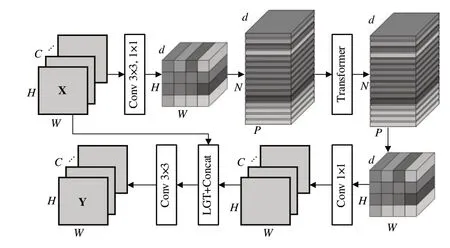
Fig.2 Lightweight vision transformer block structure图2 轻量级视觉Transformer块结构
LViTB 的核心在于将每张单通道图像的二维矩阵平铺转换为一维向量,原始Tranformer 的最大序列长度为512[8],若将图像以像素形式平铺为一维则计算量非常大,因此在该模型中以中间通道的小尺寸特征图进行Transformer 自注意力计算,并截取特征图特定尺寸的补丁(Patch)转换成一维向量。
LViTB 使用较少的参数量对输入特征图张量的局部与全局特征信息进行统一建模。给定一个输入张量X,表示为:
式中,H、W分别为特征图的高和宽,H为通道数。
LViTB 首先使用1 个3×3 标准卷积和1 个1×1 卷积产生特征,表示为:
其中,3×3 标准卷积用于编码图像局部信息,1×1 卷积用于学习输入通道的线性组合后将此张量投影到高维空间,d为高维度。
LViTB 将特征XL展开为N个非重叠扁平图像特征Patch 形成XU,表示为:
采用Transformer 自注意力机制编码Patch 之间的关系形成XG,LViTB 在该步骤中类似原始Transformer 进行位置编码,保证不丢失Patch 的顺序,表示为:
式中,p为单个Patch,P为单个Patch 的面积,N为Patch个数。将XG进一步折叠得到XF,通过1×1 卷积投影到低维空间后,采用红外特征线性灰度变换和Concat 操作与X结合,线性灰度变换表示为:
式中,i为通道编号,fmapout和fmapin分别表示输出特征图和输入特征图,a和b分别为对比度的调节因子和亮度的调节因子。
在该模块中输入特征图的每个像素区域均可以对其他区域信息进行编码,整体有效接收域为H×W,可获得比CNN 更大的感受野。
在LViTB 中,嵌入向量为每个Patch 及其后面通道数所组成的向量,Transformer 则为Self-Attention 计算模块。在Self-Attention 的计算过程中(见图3),尺寸为d×N×P的特征图Patches 向量分别通过1×1 的卷积运算3 组Patches向量,表示为:
式中,Q、K和V分别为Query、Key和Value。
当处理某1 个Patch 向量时,该向量会用自己的Query与当前序列中其他Patch 向量的Key进行逐一比对,完成后得到一个相似向量,该向量维度与当前序列的Patch 向量个数相同,其中每个元素代表对应Patch 向量与发出Query向量之间的相似度,值的大小与相似度正相关。得到相似度后可对每个Patch 向量的值Value加权求和,最终得到一个融入所有相关Patch 向量信息的新向量。
注意力特征图Ωj,i由Softmax 函数计算得到,表示为:
式中,ri,j表示合成第j个向量与第i个向量之间的自注意力关联度。自注意力输出特征图Patches(oj)表示为:
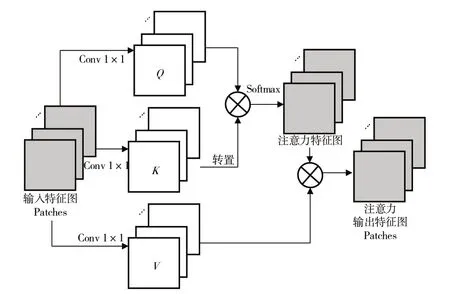
Fig.3 Computation of Self-Attention图3 Self-Attention计算
1.3 上采样重建模块
上采样重建模块结构如图1 的Up Sample 模块所示,采用亚像素卷积层进行整数倍的放大,进一步经过一个卷积层和Tanh函数激活,以输出高分辨率图像。
1.4 损失函数
主流的图像超分辨率模型优先考虑使用L2 损失函数(即MSE 损失函数)和L1 损失函数(即MAE 损失函数),前者与客观评价指标峰值信噪比(Peak Signal to Noise Ratio,PSNR)有直接相关性,后者能使模型在训练后期阶段有较快的收敛趋势。然而L1 用于神经网络训练会使梯度始终处在局部较大的位置,虽能较快收敛模型,但在训练结束时容易遗漏局部最小值。而L2 损失函数对异常值有较大的惩罚力度,在梯度下降过程中接近最小值时收敛较为缓慢。本文综合两者优势,采用Huber 损失函数(即Smooth L1损失函数),如式(13)所示,其围绕的最小值范围可以逐步平滑地进行梯度下降,对异常值更鲁棒。此外,其含有的可学习参数δ可根据当前训练梯度自适应调节更趋近于L1或L2损失函数。
式中,W、H分别表示图像的宽和高。
2 实验方法与结果
2.1 数据集与实验细节
本文模型首先在大规模图像数据集ImageNet-1K 进行预训练,使Transformer 结构学习不同物体的注意力特征结构,然后在红外图像数据集NIR、CVC-09/14 上进一步训练100 个epoch。实验在服务器上进行,操作系统为Ubuntu 20.04,使用CUDA 加速的PyTorch 1.7 深度学习框架,IDE为PyCharm;硬件采用英特尔Core i78700 CPU,内存16GB,GPU 为英伟达GeForce RTX 3070,显存8GB。训练模型时使用Adam 优化器,设置初始学习率α为0.0001,衰减率β为0.9。受显存大小限制,2 倍放大倍率的模型批量大小Batch Size 设置为128,随机裁剪分辨率为96×96 的HR 图像通过双三次插值下采样至48×48 的LR 图像作为图像对;4 倍放大倍率模型Batch Size 为64,随机裁剪192×192 下采样至48×48 作为图像对,模型中间通道数为64。为防止模型过拟合,增强鲁棒性,随机将训练集图像进行翻转和镜像。模型测试时选取9 张NIR 数据集的近红外图像作为评价测试集Test1,选取100 张来自CVC-09/14 和TNO 数据集的远红外图像作为测试集Test2。
2.2 评价指标
使用PSNR 和结构相似度(Structural Similarity Index,SSIM)作为客观评价指标,计算方式如式(14)和(15)所示,其中PSNR 与SR 和HR 图像之间的灰度值均方误差相关;SSIM 体现了HR 图像与SR 图像的亮度、对比度等相似关系。
式中,H、W分别为图像的高和宽,(x,y)表示各个像素点在图像中的坐标位置,μ为灰度平均值,σ为方差,C1和C2为维持等式有效性的常数。
2.3 预训练和损失函数影响实验
虽然当前Transformer 在各类计算机视觉任务中表现优异,但由于其缺乏空间归纳偏差,需要大量数据进行预训练以保证精确度[16],因此本文模型同样先在ImageNet-1K 数据集进行预训练。大多数重建模型采用L2 损失或L1 损失函数,以下比较预训练、未预训练以及采用不同损失函数之间的差异。
采用Model A(已预训练+Huber 损失)、Model B(未预训练+Huber 损失)、Model C(已预训练+L2 损失)Model D(已预训练+L1 损失)在红外图像数据集上训练100 个epoch 的PSNR 变化和损失函数收敛情况如图4 和图5 所示。模型在得到预训练后,第20 个epoch 开始逐步收敛,可以清晰看出未经过预训练的模型PSNR 变化曲线峰值没有经过预训练的高,PSNR 变化不稳定,损失函数的震荡也更明显。采用L2 损失和Huber 损失的模型PSNR 峰值更高且损失值更小,采用L1 损失的模型能够更平稳收敛,但PSNR不占优势。
Model A、Model B、Model C、Model D 在本文测试数据集Test1 比较2 倍放大倍率下的PSNR 和SSIM 指标如表1所示,可以看出采用Transformer 的模型得到预训练后在重建指标方面提升显著;采用Huber 损失的模型在SSIM 上比L2 损失有明显提升,PSNR 的提升不大;采用L1 损失的模型在SSIM 方面最有优势,但PSNR 偏低,因此综合比较来看本文选择Huber损失函数。
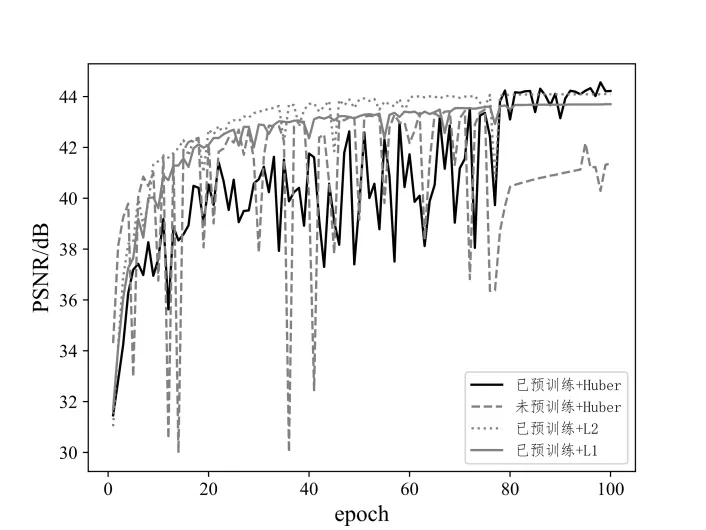
Fig.4 Comparison of PSNR change during model training图4 模型训练时PSNR变化比较
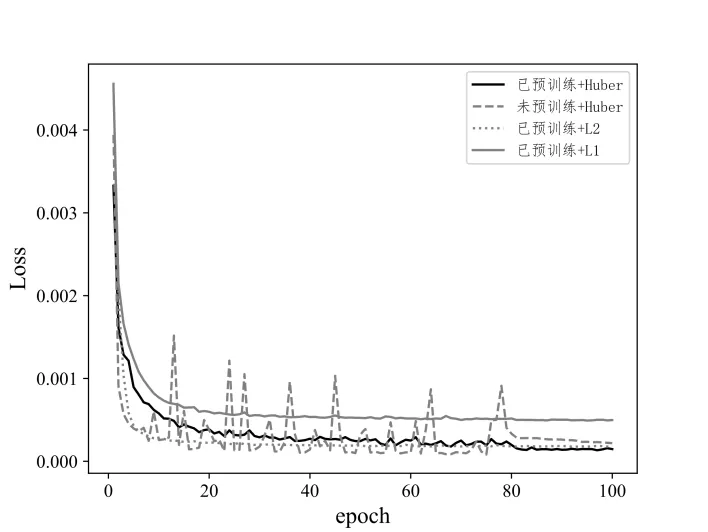
Fig.5 Comparison of loss function change of models图5 模型损失函数值变化比较
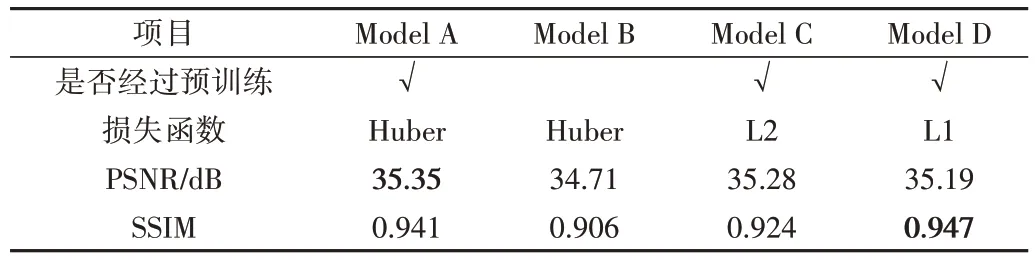
Table 1 Comparison results of pre-training effect表1 预训练影响比较结果
2.4 消融实验
为验证本文模型所采用的各个模块对实验结果的影响,设计消融实验进行4 种模型结构比较,结果如表2 所示。分别训练50 个epoch,在近红外测试数据集Test1 和远红外测试数据集Test2 上比较2 倍放大倍率下的PSNR 指标。根据模型A(本文模型LI-SRViT)和模型B 的比较结果,采用沙漏型LRB 的效果优于原始MobileViT 中采用的MobileNet V2[20]残差块;根据模型A 和C 的比较结果,将DS Conv 替换为常规卷积(Normal Conv)的提升效果不明显,使用深度可分离卷积可极大减少冗余参数;根据模型A 和D 的比较结果,使用Transformer 的自注意力计算可以显著提升模型效果。
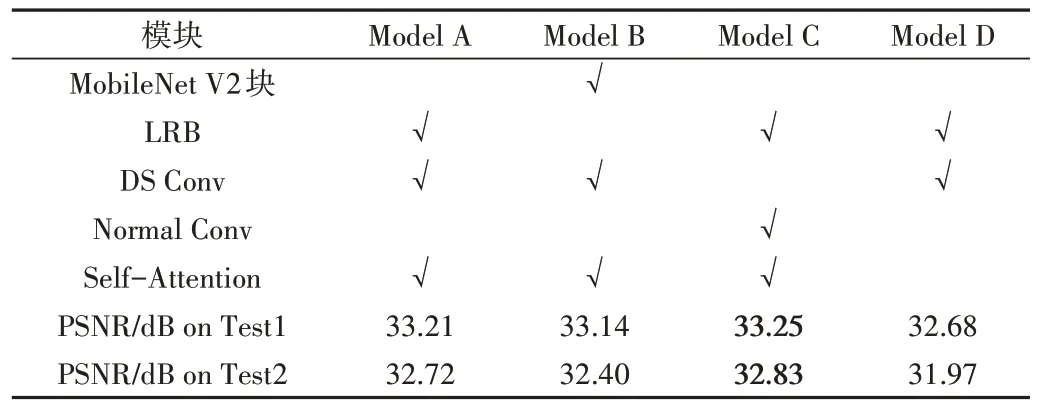
Table 2 Results of the ablation experiment表2 消融实验结果
2.5 算法比较实验
将本文模型与当前经典的双三次插值算法Bicubic[21]、SRGAN[2]的生成器网络模型SRResNet、经典的重量级超分辨率算法EDSR[22]和经典的轻量级超分辨率算法CARN[23]和IMDN[24]进行比较,比较其2 倍放大倍率下的模型参数量(Params)、PSNR 和SSIM。同时将本文模型LISRViT 与笔者先前提出的模型LI-SRGAN 进行比较,可以得出视觉Transformer 的全局自注意力机制使近红外图像的重建效果取得改善,峰值信噪比和结构相似度均有提高。
重建对比评价指标结果如表3 和表4 所示,可以看出本文模型在近红外图像测试集PSNR 指标上以较少的参数数量1031K 超越了参数较大的SRResNet 和CARN 模型,也超越了基于信息蒸馏网络的IMDN 模型。EDSR 的PSNR 指标最佳,本文模型综合评价指标接近EDSR,在Test1 的2 倍放大倍率下本文模型SSIM 指标略高于EDSR。如图6 所示,LI-SRViT 模型对远红外图像能重建出清晰的效果,LI-SRGAN 重建的远红外图像物体边缘细节处更加锐利。如图7 所示,在近红外图像的测试上,本文模型重建的测试示例中的文字细腻度和窗格更接近HR 图像,而LI-SRGAN 有轻微的伪影现象。
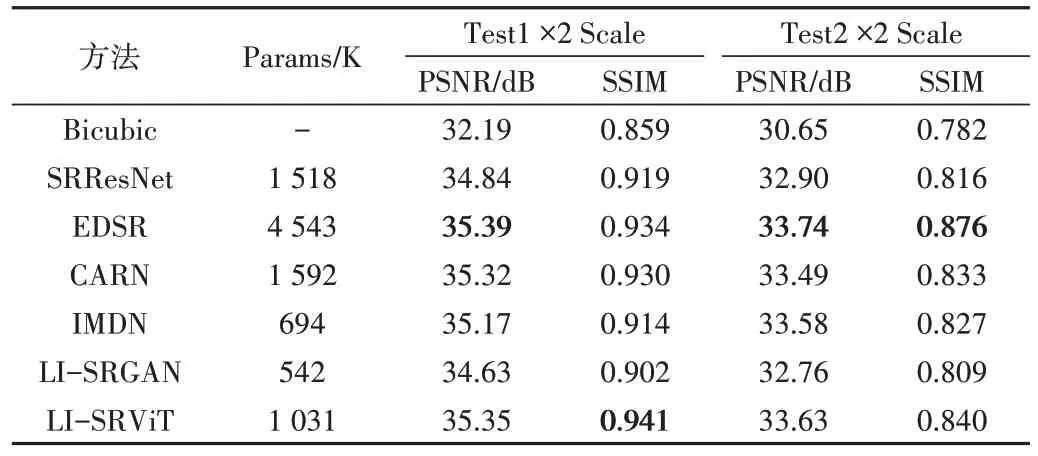
Table 3 Comparison results of LI-SRViT and six other methods on the self-built infrared image dataset at 2x magnification表3 2倍放大倍率下LI-SRViT与其他6种方法在自建红外图像测试集的比较结果
2.6 注意力可视化实验
为进一步体现本文模型的优势,采用CVPR 2021 收录的视觉Transformer 注意力可视化方法[25]对训练得到的模型进行注意力相关性显示。该方法通过深度泰勒分解原理分配局部相关性,然后将相关性传播到各层形成全局相关性,采用迭代消除负面影响整合到注意力图中。如图8所示,LI-SRViT 模型能够学习到图像中的主要物体特征分布,采用Transformer 的全局自注意力能够辅助完成优质重建。
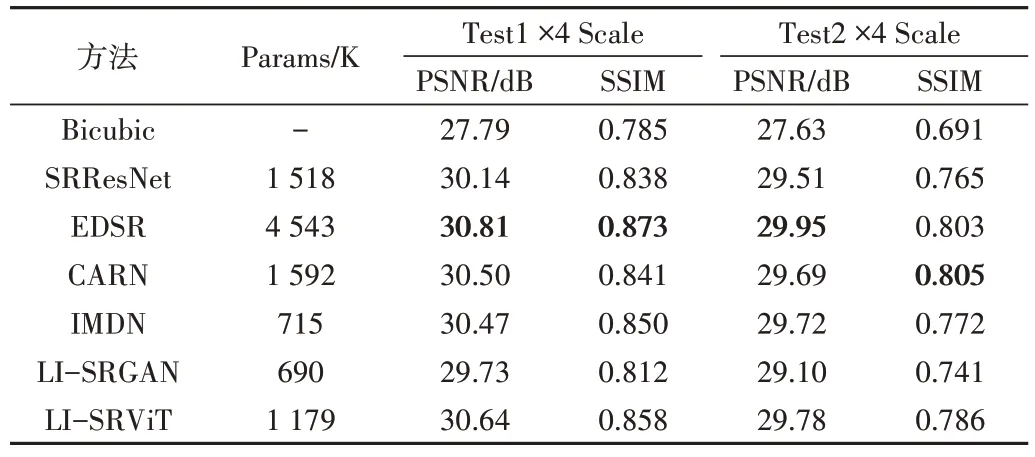
Table 4 Comparison results of LI-SRViT and six other methods on the self-built infrared image dataset at 4x magnification表4 4倍放大倍率下LI-SRViT与其他6种方法在自建红外图像测试集的比较结果

Fig.6 Test results on far infrared images图6 远红外图像测试结果

Fig.7 Test results of near infrared images图7 近红外图像测试结果

Fig.8 Attention visualization of ViT图8 ViT注意力可视化
3 结语
本文通过结合深度可分离卷积、轻量级视觉Transformer 块的全局自注意力机制和迭代上下采样结构,构建了一个适用于重建波长范围广的红外图像的超分辨率模型,该模型参数量较小,且重建效果优于当前数个经典模型。真实的红外图像降质更加复杂,下一步将研究如何结合图像降噪算法完成优质重建。
猜你喜欢
环球时报(2022-05-23)2022-05-23
小雪花·成长指南(2022年1期)2022-04-09
金桥(2021年4期)2021-05-21
数学物理学报(2019年3期)2019-07-23
电子制作(2019年7期)2019-04-25
家庭影院技术(2018年9期)2018-11-02
传媒评论(2017年3期)2017-06-13
自动化学报(2017年5期)2017-05-14
成都信息工程大学学报(2017年6期)2017-03-16
光学精密工程(2016年3期)2016-11-07
