
嵌入压缩—激励机制ResNet的民族药植物图像识别
2023-03-08 10:56杜建强朱彦陈冯振乾
软件导刊 2023年2期
周 婷,杜建强,朱彦陈,冯振乾
(江西中医药大学 计算机学院,江西 南昌 330004)
0 引言
中国拥有世界上最丰富的药用植物资源,对药用植物的发掘、使用和栽培有着悠久的历史[1]。民族药是传统医药的重要组成部分,包括藏药、蒙药、维药、彝药、傣药、壮药、瑶药、苗药等在内的药品数量达8000 余种[2],在防病治病和卫生保健事业中发挥着重要作用。在实际应用中,民族药主要依靠专业人员的感官和经验进行识别,这种人工识别方法工作繁琐、效率低,且具有一定的主观性,常会有误判现象。因此,探索一种智能化、高效率、高准确性的方法实现对民族药的自动识别具有重要现实意义。
图像识别是计算机视觉领域的一个重要分支,其包含的特征提取和图像分类技术有助于民族药的识别。在传统机器学习中,研究人员提出局部二值模式(Local Binary Pattern,LBP)[3]、尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[4]、基于FAST 角点的特征点检测(Oriented Fast and Rotated Brief,ORB)[5]和Gabor 滤波[6]等方法对图像进行特征提取。而图像分类通常使用支持向量机(Support Vector Machine,SVM)[7]、随机森林(Random Forest,RF)[8]、K 近邻(K-Nearest Neighbor,KNN)[9]和反向传播神经网络(Back Propagation Neural Network,BPNN)[10]等方法。然而,传统的图像识别方法依赖人为设计特征,无法提取到图像的高级语义特征[11]。
近年来,深度学习技术在图像识别中广泛应用,其能很好地将底层特征映射到高层领域,得到更加本质的特征表 示。自2012 年以后,AlexNet[12]、VGGNet[13]、GoogLeNet[14]、ResNet[15]等经典神经网络模型被相继提出,许多研究者开始将卷积神经网络(Convolutional Neural Network,CNN)应用于植物图像识别中。例如,Lee 等[16]采用反卷积网络从44 种植物图像中学习识别特征,证明了通过CNN 学习特征优于传统的手动提取特征;冯海林等[17]使用AlexNet 等4 个网络模型在大数据集ImageNet[18]上进行预训练,迁移到目标树种数据集上,将训练得到的4个CNN 集成得到最终模型,较大提升了复杂背景的树种图像识别精度;何欣等[19]在ResNet18 网络基础上引入多卷积以提升网络的特征提取能力,对一般程度葡萄叶片病害的识别准确率较高,对严重程度的病害识别率有所下降,模型的鲁棒性尚不够;Zhu 等[20]提出一种改进的深度卷积神经网络用于对植物叶片特征的识别,将原始图像分割成子图像加载到网络中,获得了较高的识别率,但对于复杂环境中小物体进行检测和分类的效果则不如简单背景;张帅等[21]通过构建8 层CNN 对简单背景和复杂背景的植物叶片图像进行识别,发现对简单背景下的图像识别效果较好,但复杂背景下的识别率较低。
目前,利用深度学习技术对民族药图像进行识别分类尚有许多亟需解决的问题。一方面,民族药分布广泛、生长环境特殊、品种稀缺等原因给民族药植物图片的采集增加了难度,数据集样本量较少,易导致网络过拟合;另一方面,所采集到的民族药植物图像大多具有土壤、石头、杂草、枯叶等不能表征类别的无效区域,加大了图像特征提取的难度。为解决上述问题,本文自建民族药植物图像数据集,结合民族药植物图像数据的特点,提出嵌入压缩—激励(Squeeze and Excitation,SE)机制的ResNet 结合迁移学习的图像识别方法(SE-ResNet34-Transfer)。该方法在ResNet34 网络的浅层部分引入SE 机制,实现浅层细粒度特征与深层高级语义特征的融合,有效提升模型在背景复杂图像中的特征表现力;同时采用模型参数迁移对网络微调训练的方式,减少小样本数据集对网络性能的影响;最后通过多个数据集上的多组比较实验,证明了该方法的有效性。
1 相关方法
1.1 ResNet
ResNet 的核心为残差块,加入的残差连接直接将输入信息通过跳跃结构传给输出,一定程度上保留了信息的完整性,提高了网络的映射能力,从而缓解CNN 中由于层数增加导致梯度消失的网络退化问题。假设x为网络输入,H(x)为对应的输出,当输入维度与输出维度一致时,残差连接可以表示为H(x)=F(x) +x,转化为学习的残差函数F(x)=H(x) -x,若残差为0,存在恒等映射H(x)=x,即通过拟合残差拟合恒等映射关系。
图1 为ResNet 中的一个残差块。对于输入样本x,通过网络层后得到的输出为:
式中,W、W1、W2表示权重,δ表示ReLU 激活函数[22]。
将该输出与原始输入x相加,得到网络的最终输出为:
式中,y为网络的输出向量,F(x,W)为待学习的残差映射。
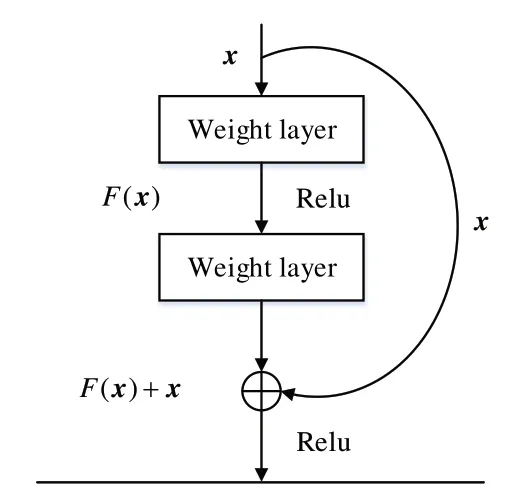
Fig.1 ResNet residual module图1 ResNet残差模块
公式(3)为残差块在反向传播时的梯度计算表达式,在梯度计算中每个导数值加1,一定程度上解决了由于网络深度增加,误差反向传播过程中导数连乘后的梯度值逐渐增大或减小,最终出现的梯度爆炸或弥散问题,使网络有效地进行反向传播。
1.2 SE机制
SENet[23]中提出一种能够使网络对特征进行校准的SE 机制,其通过学习卷积中不同特征通道的重要性赋予各通道不同的权重,即关注信息量大的有效通道特征,抑制不重要的通道特征,进而提升网络模型的特征表现力。如图2 所示,SE 模块主要包含压缩(Squeeze)和激励(Excitation)两个模块,假设卷积得到的特征图大小为W×H×C,W和H分别表示特征图的宽和长,C表示通道数。
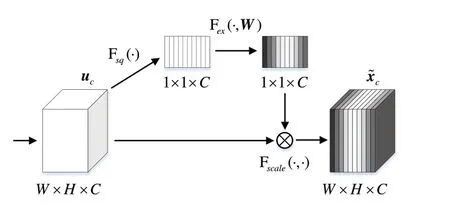
Fig.2 SE module图2 SE模块
首先对特征图在空间维度W×H上进行压缩操作得到1 × 1 ×C的向量,即通过一个全局平均池化(Global Average Pooling)得到通道级的全局特征,压缩模块的公式为:
式中,zc表示压缩操作输出特征图,uc表示输入特征图,Fsq表示压缩函数。
然后对全局特征进行激励操作,即通过两个全连接层学习特征通道之间的相关性,进行权重分配,生成的通道权重维度为1 × 1 ×C,激励模块的公式为:
式中,sc表示激励操作生成的权重,δ表示ReLU 函数,σ表 示sigmoid 函 数,Fex表示激励函数,;r表示压缩比例,以减少网络参数量,提高泛化能力。
最后经过Scale 操作,将得到的各通道权重值与原特征图对应通道的二维矩阵相乘,得到最终特征输出,计算公式为:
2 本文模型
ResNet 含有的残差块结构在一定程度上能够解决随着网络层数加深而导致的网络退化问题,常用ResNet 包括ResNet18、ResNet34、ResNet50。本文以ResNet34 网络结构为基础,提出SE-ResNet34-Transfer 模型,结构如图3 所示,其主要由迁移学习模块和嵌入SE 机制的网络模型构成。
2.1 模型的迁移学习
民族药植物图像样本量少,不利于网络对特征的提取,且容易出现过拟合现象。迁移学习(Transfer Learning)是指将相关源领域中的有用信息迁移应用到目标领域中,从而解决目标领域的学习任务[24],对于图像识别研究中存在训练成本高、数据集小等问题,是一种有效的解决方法。
模型的迁移学习模块如图3(a)所示。首先在ImageNet(包含1400 多万张标记的图片)大规模图像数据集上对ResNet34 权重进行预训练,提取与目标领域具有一定共性的特征(边缘、纹理、色彩等),然后将训练好的权重参数迁移至目标领域中,重构Full Connection(FC)层的输出类别数,最后进行参数微调(finetune)训练。
2.2 嵌入SE机制的网络模型
民族药植物图像背景复杂,通常存在杂草、石头、土壤等不能表征其类别的无效区域,这些干扰因素会影响网络对图像的特征提取。为了解决这个问题,在ResNet34网络中引入改进的SE机制,SE-ResNet34网络模型如图3(b)中所示。
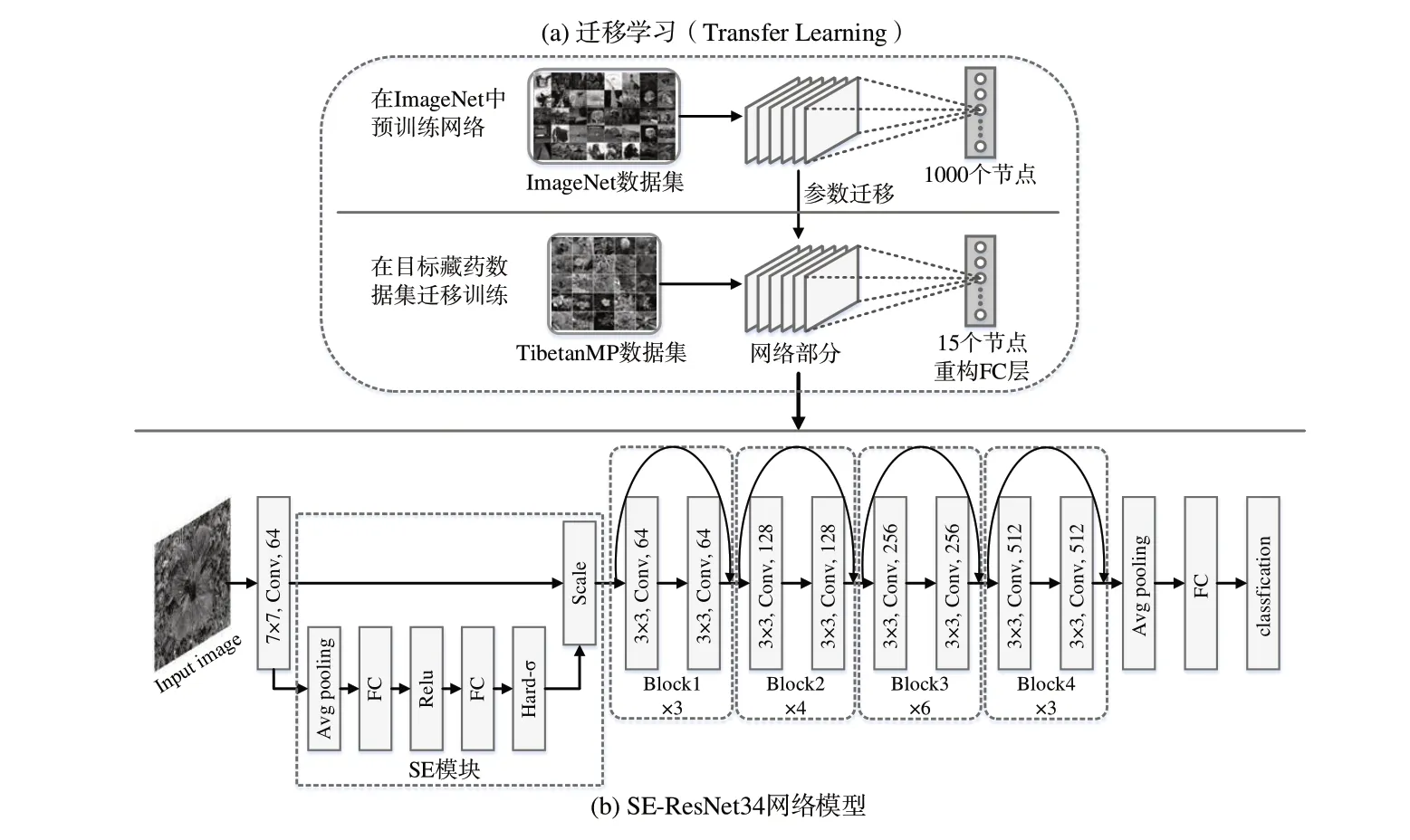
Fig.3 SE-ResNet34-Transfer model图3 SE-ResNet34-Transfer模型
2.2.1 嵌入策略
CNN 中浅层更加关注图像的细粒度特征,高层则可以获得图像的整体性信息。民族药植物图像中通常存在一些无效信息,为提高模型识别率,本文选择在ResNet34 网络第一层卷积层之后引入SE 机制,目的是在存在较多背景信息时提高有效特征的重要度,同时抑制无效特征,帮助网络对特征进行校准。
民族药植物图像背景复杂,每个部分都可能包含图像特征信息。在传统的ResNet34 中,第一层卷积之后运用了最大池化技术,对图像的背景信息有一定丢失。为了使网络能够保留更多图像背景信息,去除卷积层之后的最大池化层,采用SE 机制中的平均池化技术替换最大池化技术。同时为了减少网络参数量,提高泛化能力,采用文献[25]中的设置将压缩系数设定为4。
2.2.2 激活函数
“新生儿睾丸扭转短时间内即可发生坏死,同时可能会引起全身炎症反应及影响另一侧睾丸,必须急诊手术,需紧急转到一师医院救治……”陈正副院长在询问患儿病情后,立即与一起参加义诊的一师医院小儿外科援疆专家钱云忠主任和泌尿外科方家杰副主任进行实时会诊,同时将患儿的检查结果和相关资料通过微信传给了其后方医院——浙江大学医学院附属儿童医院的泌尿外科专家徐珊主任,在返程的车上共同商讨和制定了周详的手术方案,指导赵主任立即进行手术前相关检查并联系120中心马上进行新生儿转运,争取为抢救患儿节省时间。
传统SE 机制中,在对全局特征进行激励操作时,使用sigmoid 作为计算权重的激活函数,sigmoid 函数需要进行指数运算,计算量大,且由图4 可以看出,sigmoid 函数在零附近激活性较好,而在接近饱和区时变化非常缓慢,不利于深层网络的训练。
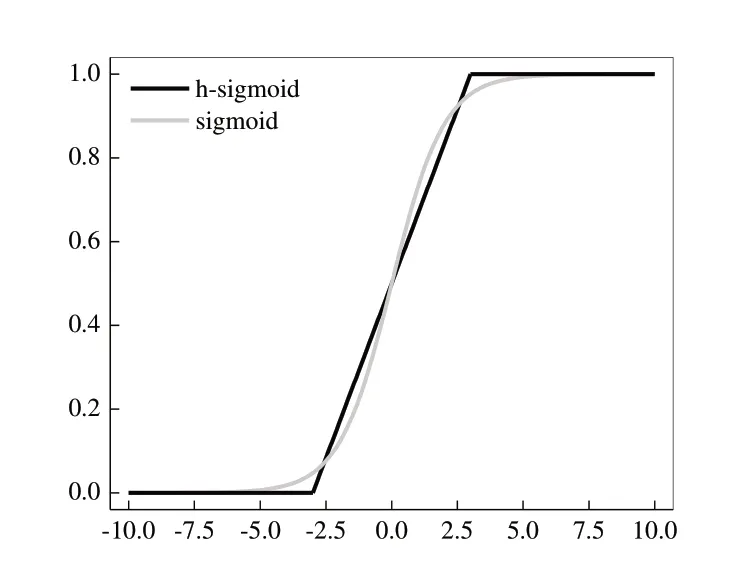
Fig.4 Curves of sigmoid and h-sigmoid functions图4 sigmoid和h-sigmoid函数曲线
为了解决这两个问题,本文使用h-sigmoid 函数近似代替sigmoid 函数,h-sigmoid 函数没有指数运算,能够减少时间消耗,提高网络特征提取精度,h-sigmoid 激活函数计算公式为:
h-sigmoid 函数在ReLU 函数的基础上采用3 个线段拟合整个sigmoid 函数,将原本平滑的sigmoid 函数变得近似平滑。当输入值小于3 时,一部分神经元失活,使得网络更加稀疏,减少了参数间的相互依存,缓解了过拟合问题;当输入值大于3 时,神经元的输出变为固定值,能够减少计算带来的精度损失。
3 实验设计与结果分析
3.1 实验数据集
为证明本文模型的有效性和通用性,设计实验分别在自建的民族药植物图像数据集、公开的植物图像数据集Oxford 102 flowers 和非植物图像数据集CIFAR-10 上验证网络模型性能。其中民族药植物图像数据集通过人工拍摄与网络爬取相结合的方式构建。自建民族药植物图像数据集的一部分来自于江西中医药大学中药资源与民族药研究中心赴各地采集的图片,另一部分在中国植物图像数据库、中国科学院植物主题数据库上爬取获得,之后由研究中心的民族药专家进行数据筛查和图像标注,最后从中选取15 类较为常见的藏药植物,命名为TibetanMP 数据集。TibetanMP 数据集中每类藏药图像数量为200~1500张不等,共有8018 张图像,并按照7∶3 的比例划分训练集和测试集。TibetanMP 数据集具体类别信息见表1。
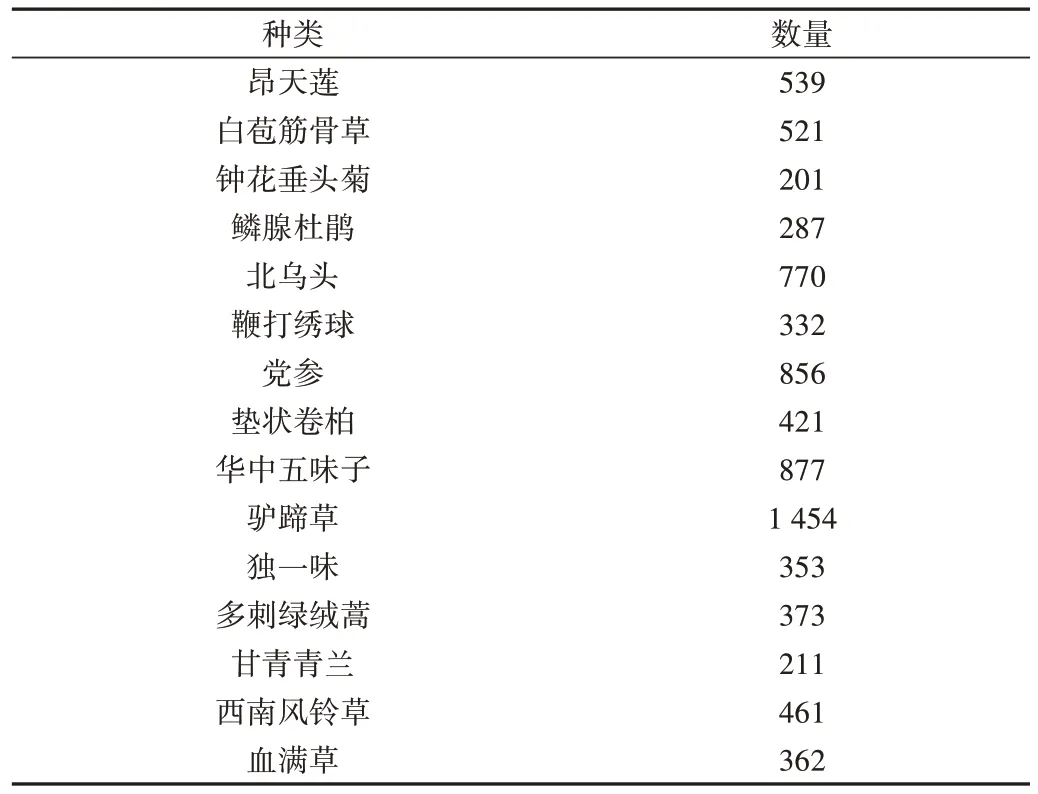
Table 1 Number of categories in the TibetanMP dataset表1 TibetanMP数据集各类别数量
Oxford 102 flowers 是由牛津大学发布的图像数据集,包含102 类英国常见花卉,每个类别包含40~258 张图像,共8189 张图像,具有较大的比例、姿势和光线变化,因此常在多类别复杂植物识别中作为模型验证数据集。
CIFAR-10 是广泛应用于机器视觉领域图像分类任务中的经典数据集,由10 类32×32 的彩色图像组成,每个类别有10000 张图像,训练集包含50000 张图像,测试集包含10000张图像。
3.2 实验设置
本文所有实验均在单个图形处理单元(GPU)模式下进行,参数为NVIDIA VGPU,8.19GB 显存,20GB 内存,选用Python 编程语言,Pytorch 深度学习框架。
为了确保模型在各个数据集上的识别精度达到最优,需要分别对3 个数据集进行参数预设。TibetanMP 数据集的参数通过微调优化得到;Oxford 102 flowers 数据集与TibetanMP 数据集的数据类型相似,前者单个类别样本较少,因此设置更小的批处理大小,其他参数一致;CIFAR-10 数据集使用文献[26]中的配置参数。
在TibetanMP 数据集中,网络的批处理大小(batch size)设置为16,迭代次数设置为100。模型使用Adam(Adaptive Moment Estimation,Adam)作为优化器(optimizer),其学习率(Learning Rate,Ir)设置为0.0001。在Oxford 102 flowers 数据集中,网络的批处理大小设置为8,其他参数设置与TibetanMP 相同。在CIFAR-10 数据集上,模型训练采用随机梯度下降(Stochastic Gradient Descent,SGD)优化算法,动量(momentum)设置为0.99,权重衰减(weight decay)为0.0001,初始学习率设置为0.001,每次训练图片批处理大小为64张,迭代次数为200。
3.2.2 损失函数
本文所有实验均采用交叉熵函数作为网络模型的损失函数,表示为:
式中,xclass表示真实标签值,j表示分类的类别,xj表示预测值。
3.2.3 评价指标
采用准确率(accuracy)作为评价指标,accuracy 越大,模型具有越高的识别精度,计算公式为:
式中,ti为第i类图像分类正确的数量,n为图像类别总数,num为测试集图像的总数量。
3.3 实验结果与分析
3.3.1 迁移学习及ResNet层数比较实验
为了验证迁移学习在本文小样本数据集上的有效性,同时确定后续实验采用的ResNet 层数,本文在ResNet18、ResNet34 和ResNet50 网络中进行迁移学习比较实验。各网络模型在TibetanMP 数据集上的结果见表2。可以看出,ResNet18、ResNet34 和ResNet50 网络在引入迁移学习后,在TibetanMP 数据集上的识别效果有不错提升,表明了迁移学习的有效性。随着网络层数的增加,模型识别的效果越来越好,在ResNet34-Transfer 和ResNet50-Transfer 上分别达到了95.07%和95.91%的准确率。但由于迁移学习是本文模型中对网络训练时间影响最大的因素,结合网络训练时间成本和参数量,ResNet34-Transfer 模型相较ResNet50-Transfer 的训练时间和参数量分别降低了46.7和0.03 × 106,最终确定本文后续实验采用ResNet34-Transfer模型。
3.3.2 模型在不同数据集上的比较实验
为了验证引入SE 机制能够提高网络的图像特征提取能力,以ResNet34-Transfer 为基准,分别在TibetanMP 数据集、Oxford 102 flowers 数据集和CIFAR-10 数据集上进行比较实验,验证SE-ResNet34-Transfer 的有效性。实验结果见表3。
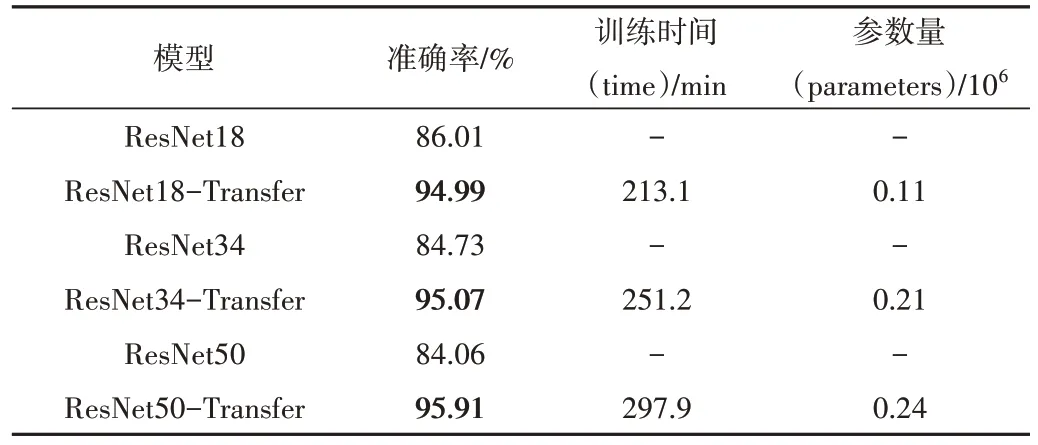
Table 2 Experiment result of transfer learning and ResNet layers表2 迁移学习及ResNet层数实验结果
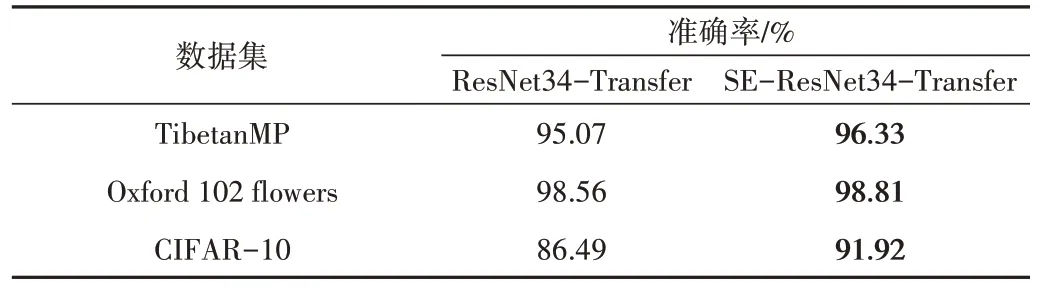
Table 3 SE-ResNet-Transfer effectiveness experiment results表3 SE-ResNet-Transfer有效性实验结果
可以看出,SE-ResNet34-Transfer 模型在Oxford 102 flowers 和CIFAR-10 数据集上均获得了更高的准确率,相较ResNet34-Transfer 分别提高了0.25%和5.43%,表明本文方法能有效提升网络的图像特征提取能力,具有良好的泛化能力。本文方法在TibetanMP 数据集上也取得了较高的识别准确率,相比ResNet34-Transfer 提高了1.26%,表明了其对背景复杂图像识别中特征提取的有效性。
为进一步探究ResNet34-Transfer 和SE-ResNet34-Transfer 模型在TibetanMP、Oxford 102 flowers 和CIFAR-10数据集上的表现,图5 分别展示了这两种模型在各个数据集上的训练结果,其中左边为测试准确率对比图,右边为训练误差对比图。
如图5(a)所示,在TibetanMP 数据集上,改进的SEResNet34-Transfer 模型相比ResNet34-Transfer 具有更优的收敛精度和更低的训练误差;如图5(b)所示,在Oxford 102 flowers 数据集上,两个模型的训练表现区别不大,但ResNet34-Transfer 的收敛速度略快,主要是由于Oxford 102 flowers 数据集样本较小,图像较清晰简单,易于训练,而引入SE 机制增加了模型的参数量,使得收敛速度略慢,但总体看来,SE-ResNet34-Transfer 取得了更好的识别效果;如图5(c)所示,在CIFAR-10 数据集上,SE-ResNet34-Transfer 模型相较ResNet34-Transfer 具有更高的识别精度和更低的训练误差,进一步验证了本文模型的准确性和有效性。
3.3.3 与主流CNN图像识别模型的比较实验
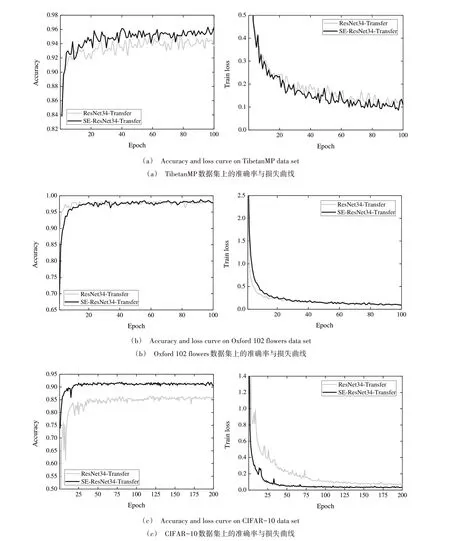
Fig.5 ResNet34-Transfer and SE-ResNet34-Transfer training results comparison图5 ResNet34-Transfer与SE-ResNet34-Transfer训练结果比较
将SE-ResNet34-Transfer 与其他主流CNN 图像识别模型进行比较,进一步验证SE-ResNet34-Transfer 的分类性能。选取AlexNet、VGG16、GoogleNet、MobileNet 作为对照模型,分别在3 个数据集上对上述CNN 网络模型进行比较实验,结果见表4。其中,CIFAR-10 数据集上由于图片大小为32×32,而AlexNet 要求图片的输入为224×224,因而此处没有对比AlexNet-Transfer 模型的实验。可以看出,在采用同样迁移学习方式的前提下,SE-ResNet34-Transfer 模型相较其他CNN 图像识别模型在3 个数据集上均取得了最好结果。在TibetanMP 数据集上,本文模型分类效果最佳,识别精度达到96.33%,表明嵌入SE 机制的ResNet结合迁移学习的图像识别方法能够有效提高网络的图像特征提取能力。
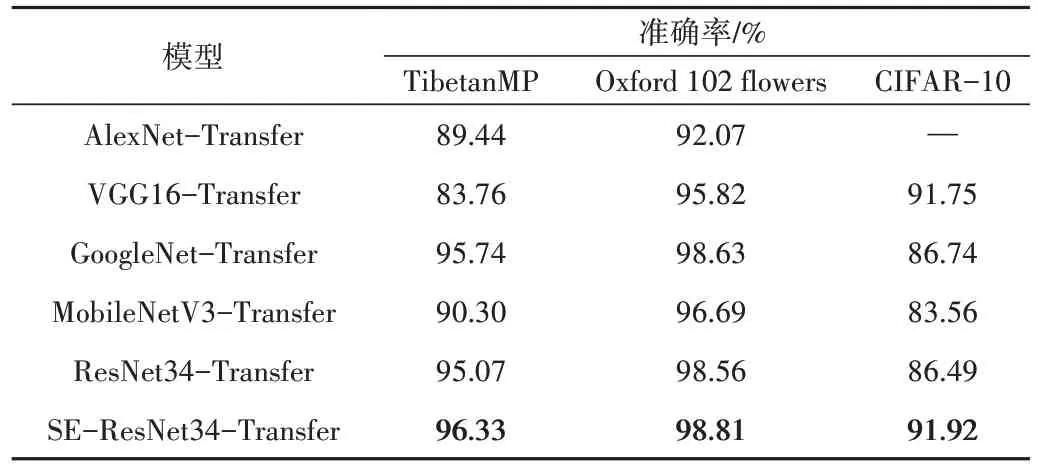
Table 4 Experimental results of each image recognition model表4 各图像识别模型实验结果
4 结语
为了推动民族药智能化发展,解决民族药植物图像数据集稀缺、样本量少和图像特征提取困难等问题,本文自建TibetanMP 数据集,并提出一种嵌入SE 机制的ResNet 结合迁移学习的图像识别方法。该方法利用迁移学习提高网络在小样本数据集上的识别率,通过引入SE 机制提高网络对复杂背景图像的特征提取能力,最终在TibetanMP数据集上进行微调,取得了可观的测试精度,较好地解决了样本量较少、背景复杂的民族药植物图像识别问题,为相关研究者提供了可靠的技术支持。同时,在两个公开图像数据集上的对比实验结果表明,与其他主流CNN 图像识别模型相比,SE-ResNet34-Transfer 获得了更高的准确率,。然而民族药种类繁杂,本文方法仍具有一定的局限性,在未来的研究工作中,将从长尾分布数据背景下的图片分类问题出发,提高测试精度,并考虑调整迁移学习策略,继续优化现有模型。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子制作(2019年16期)2019-09-27
中国交通信息化(2019年4期)2019-07-13
电子制作(2018年19期)2018-11-14
电子制作(2018年19期)2018-11-14
电子制作(2018年14期)2018-08-21
数学物理学报(2017年5期)2017-11-23
自动化学报(2017年11期)2017-04-04
噪声与振动控制(2015年4期)2015-01-01
