
基于D2-YOLO去模糊识别网络的果园障碍物检测
2023-03-07 03:31蔡舒平潘文浩孙仲鸣
农业机械学报 2023年2期
蔡舒平 潘文浩 刘 慧 曾 潇 孙仲鸣
(江苏大学电气信息工程学院,镇江 212013)
0 引言
随着人们对果品类的消费需求日益增加,国内外果园种植面积不断扩大[1]。传统的果园种植模式耗时、费力、成本高。近些年,由于人工智能技术的高速发展,农业机器人[2-3]越来越多地应用于果园种植[4],如修剪、采摘和喷洒农药等。智能农业机器人的自动导航技术受到了科研人员的广泛关注[5-7]。果园环境是一个复杂的非结构化环境,智能农业机器人在园内道路上作业时,难免会遇到各类障碍物[8],包括人、树、灯杆等,如果不及时发现和规避,将会造成严重的安全问题。为了保证农业机器人在果园自主作业时的安全性和准确性,能够快速准确地检测周围的障碍物非常重要。
果园障碍物检测属于深度学习[9-10]中目标检测[11]的范畴,目标检测算法主要分为两类:一类是基于Region Proposal的目标检测算法,代表模型包括R-CNN系列,它们属于两阶段目标检测算法,即让算法先生成目标候选框,对候选框区域的图像进行特征提取,再对提取到的特征进行分类与回归;另一类是使用端到端思想的一阶段目标检测算法,代表模型包括SSD[12](Single shot multiBox detector)、YOLO[13-15](You only look once)系列等,此类算法仅使用卷积神经网络(CNN)直接提取图像特征后对特征进行分类和检测框坐标的回归。随着一阶段目标检测算法的不断更新,无论是检测速度还是检测精度都比两阶段目标检测算法更具优势。
基于稳定、高质量图像采集的目标检测技术日趋成熟[16]。然而,农用机器人在果园作业时,行驶经过的地面凹凸不平,车体容易出现剧烈颠簸,导致摄像头大幅不规则抖动,采集的图像模糊不清,这种模糊严重降低了图像质量,从而对后续基于图像的目标检测、语义分割等高级视觉任务产生负面影响,在实际应用中,会降低农业机器人在作业过程中的检测精度,导致漏检或误检,作业效率低。
目前,林开颜等[17]提出了基于模糊逻辑的植物叶片边缘检测方法,该方法克服了常规算法未考虑叶片像素和背景像素的颜色差异,从而导致产生大量伪边缘的问题,但由于是基于传统的图像去模糊算法,过程较为复杂。马晓丹等[18]提出了一种将量子遗传算法的全局搜索能力和模糊推理神经网络的自适应性相结合的算法来识别苹果果实,该算法有效解决了图像边界像素的模糊性和不确定性,但耗时较长。FAN等[19]提出一种基于深度学习的局部模糊图像去模糊方法,用于作物病虫害分类。陈斌等[20]提出一种改进YOLO v3-tiny的全景图像农田障碍物检测,该算法在YOLO v3-tiny的基础上增加一层52×52的预测层来提升对小目标的检测能力,另外还在主干网络引入了残差模块提高网络的检测能力,但是该算法依旧存在着模型参数量较大且针对输入模糊图像检测能力不足的问题。薛金林等[21]提出了一种基于改进Faster R-CNN和SSRN-DeblurNet的两阶段检测方法,有效解决了农田中由于模糊障碍物产生的问题,但该算法在训练阶段,Faster R-CNN和SSRN-DeblurNet相互独立进行训练,过程较为复杂且耗时。目前针对果园环境下,解决农业机器人在行进间作业时产生运动模糊图像的一阶段去模糊检测算法研究依旧不充分。
为了解决上述问题,本研究提出将改进的DeblurGAN-v2去模糊网络和YOLOv5s目标检测网络相融合,得到D2-YOLO一阶段去模糊识别网络。将模糊图像转换为相对清晰的图像再进行检测,以提高实际目标检测过程精度。
1 网络分析与改进
1.1 DeblurGAN-v2去模糊网络
图1为DeblurGAN-v2的网络结构图,该网络由生成器和鉴别器组成[22-23]。生成器接收噪声作为输入并生成样本,鉴别器接收真实样本和生成样本并尝试将两者进行区分。生成器的目标是通过生成无法与真实样本区分开来的感知说服样本来迷惑判别器。两者始终处于最大最小博弈状态,直到判别器无法区分生成样本和真实样本,达到纳什平衡。其中,生成器使用的骨干网络为Inception-ResNet-v2或MobileNet及其变形。DeblurGAN-v2首次将特征金字塔网络(FPN)[24]的思想引入到图像去模糊中。FPN可以提高网络的多尺度特征融合能力,实现准确率和速度的平衡,其结构如图2所示。

图1 DeblurGAN-v2结构图

图2 特征金字塔网络(FPN)框架
1.2 YOLOv5s目标检测网络
YOLOv5s网络参数量较少、部署成本低,有利于快速部署至农业机器人,适用于中大型目标障碍物检测。YOLOv5s的网络结构图如图3所示,图中,Conv表示卷积层(Convolution),CBL综合模块由卷积层、批量归一化层(Batch norm)和激活函数(Leaky ReLU)组成,CSP(Cross stage partial)表示跨阶段部分的结构,Residual unit表示残差模组件,Concat表示通道数的特征融合。
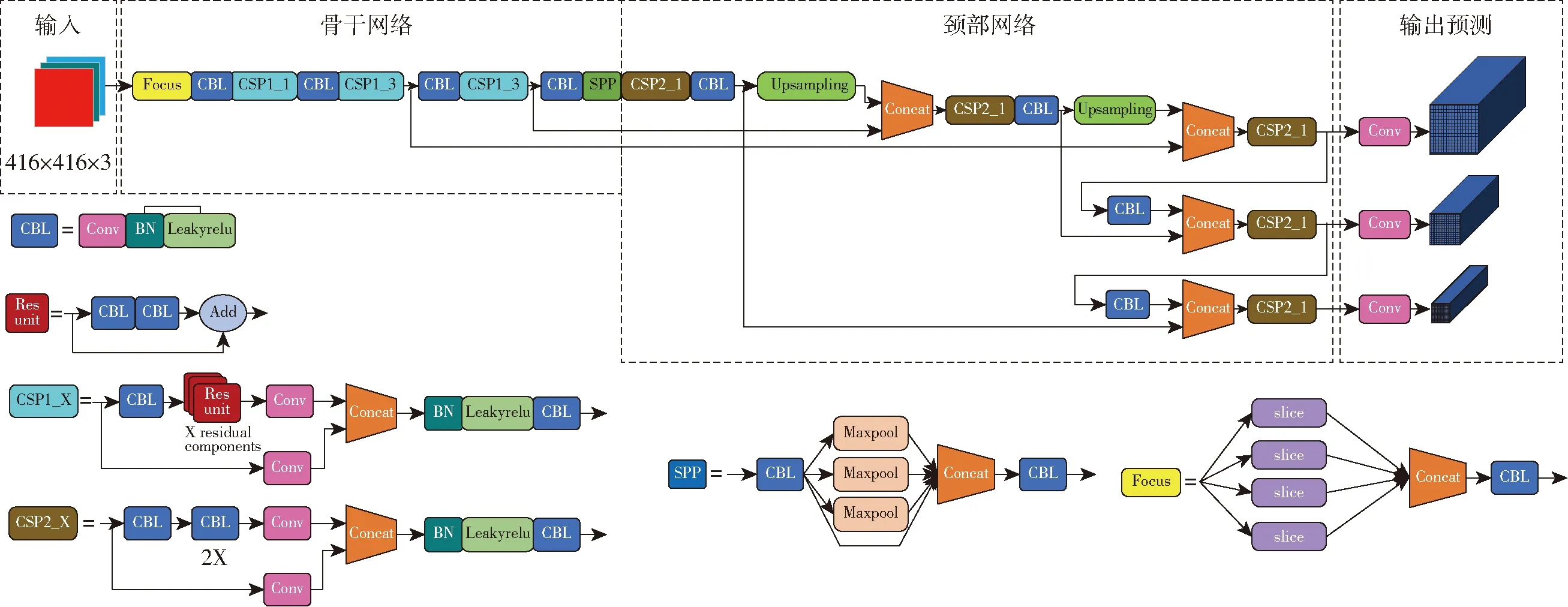
图3 YOLOv5s结构图
该网络工作流程为:首先对输入图像进行自适应图像缩放,其次通过骨干网络(Backbone)对输入图像进行特征提取,然后经过颈部网络(Neck)对这些大小不同的特征图进行分层特征融合,最后在预测层(Prediction)上对多个特征图进行同时分类和位置回归。
1.3 骨干网络改进
YOLOv5s使用CSPDarknet作为骨干网络,其优点是不仅增强了卷积神经网络的学习能力,还降低了计算瓶颈和内存成本,同时保持了准确性和轻量级。但是,CSPDarknet参数量依旧存在可优化空间,本研究将CSPDarknet中的标准卷积替换为深度可分离卷积,并将其用作融合网络。
如图4所示,标准卷积过程是对每个通道的输入特征图和对应的卷积核进行卷积运算,然后将它们相加输出特征。计算量Q1为

图4 标准卷积和深度可分离卷积
(1)
式中Dk——卷积核大小
M、N——输入、输出数据通道数
Dw、Dh——输出数据长度和宽度
深度可分离卷积将标准卷积中的一步运算改为3×3深度卷积和1×1逐点卷积,计算量Q2为

(2)
因此,深度可分离卷积与标准卷积的计算量比为
(3)
通常Dk设为3,改进后网络计算量和参数实际减少约1/3。
1.4 损失函数改进
YOLOv5s的输出预测端使用GIoU_Loss作为边界框回归损失函数,得到
(4)
式中AC——边界框和真实框的最小外接矩阵面积
u——边界框和真实框的并集
当真实框包含边界框时,两者的最小外接矩阵面积和并集相等,此时GIoU退化为IoU,无法区分两者的相对位置。
本文使用CIoU_Loss代替GIoU_Loss,CIoU_Loss取边界框和真实框的中心,求两者的欧氏距离,并引入权重α来确定边界框和真实框的纵横比,计算式为
(5)

(6)
式中ρ——边界框与真实框中心点欧氏距离
c——边界框与真实框的最外接矩阵对角线长度
wgt、hgt——真实框宽、高
w、h——边界框宽、高
v——衡量边界框和真实框之间纵横比一致性参数
采用CIoU_Loss作为边界框回归损失函数后,一定程度上提高了预测速度和准确率。
1.5 D2-YOLO去模糊识别网络
为了解决模糊图像给果园障碍物检测带来的影响,本研究将DeblurGAN-v2去模糊网络与YOLOv5s目标检测网络相融合。与图像去模糊和目标检测两步走的方法不同,本研究提出的D2-YOLO去模糊检测网络属于一阶段检测网络。D2-YOLO仅使用改进的CSPDarknet作为骨干网络进行特征提取,采用特征金字塔思想将多个不同的特征图进行层级特征融合,充分利用去模糊后的清晰图像进行预测,提高了图像恢复质量和利用率。图5为D2-YOLO去模糊识别网络结构。

图5 D2-YOLO去模糊识别网络结构图
整个网络分为前端、中部和末端3部分。当网络前端接收到输入图像经过自适应图像缩放生成416像素×416像素的帧图像后,通过卷积和多个残差块进行下采样操作,最终得到13像素×13像素的帧图像,此部分在YOLOv5s中将采用多尺度特征融合并进行预测。但在本文中为了恢复图像自然信息,会在网络的中间阶段进行反卷积及上采样操作,将图像尺寸重新恢复成416像素×416像素并得到清晰的RGB三通道图像,完成去模糊操作。在网络末端,首先采用Focus切片操作将恢复过后的清晰图像进行处理,再次通过卷积和多个残差块进行下采样操作,将3个阶段的相同尺寸帧图像进行特征融合,极大增强了图像自然信息的特征。
1.6 D2-YOLO训练方法
首先将采集的图像进行运动模糊处理。假设原始图像为σ(x,y),模糊图像为φ(x,y),则生成图像为
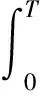
(7)
式中Crandx——随机方向x上的投影
Crandy——随机方向y上的投影
T——模糊时间n——随机噪声
网络分3个阶段进行训练。第1阶段,单独对去模糊过程进行训练,即只用网络的前端和中部,价值函数V(G,D)为
(8)
式中D(x)——取判别器均方根误差
第2阶段,固定网络前端和中部的参数,不再进行去模糊,只训练网络的末端部分,即目标检测阶段。目标检测阶段总损失函数为
Lobjdet=Lcen+Lwh+Lcat+Lcon
(9)
其中
(10)
(11)
(12)
(13)
式中Lcen——预测中心坐标损失值
Lwh——预测边界框宽和高损失值
Lcat——预测类别损失值
Lcon——预测置信度损失值
λcoord——位置损失系数
pi(c)——目标类别概率
Ci——第1个网格中边界框置信度
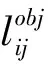
第3阶段,总体训练。在前面2个阶段完成之后,对整个网络再进行训练。总体损失函数为
Ltotal=Lobjdet+D(x)
(14)
训练好的网络经过图像计算会产生4种结果,分别对应去模糊后416×416的清晰图像,以及预测阶段为13×13、26×26、52×52的目标检测结果。如果不需要中间去模糊结果,可以对中间图像的输出进行屏蔽,只使用最终的检测结果。
2 试验
2.1 图像采集
图像数据采集场景由两部分构成,一部分是距离江苏大学5 km处的果园,另一部分是江苏大学校内梅园。在2处场景中共拍摄了2 600幅原始图像,其中清晰图像1 500幅,模糊图像1 100幅,自制模糊图像1 500幅,共计4 100幅。图像由7种果园典型障碍物组成:树木、行人、电线杆、指示牌、支撑架、垃圾桶和围栏,其中,树木种类由桂花树、腊梅树、紫薇树、红枫树、樱花树和桑树等乔木以及金森女贞球等灌木组成。
2.2 试验平台
本试验训练处理平台所使用的计算机GPU为NVIDIA RTX 4000,CPU为Intel i9 10900K,内存为64 GB。计算机操作系统为Ubuntu 20.04,搭载CUDA 11.1.1并行计算框架和CUDNN 8.2.1深度学习加速库。采用Python 3.7编程语言在Pytorch深度学习框架上进行试验。果园移动机器人搭载ZED相机作为果园场景图像采集设备,同时配套软件工具SDK和OpenCV库。
以BUNKER型履带式移动机器人底盘为基础,配备本试验使用的便携式计算机、摄像头等设备,形成图像采集移动平台。图像采集平台和采集场景如图6所示。

图6 图像采集平台及采集场景
2.3 模型训练
训练模型采用YOLO数据集格式,其中训练数据集、验证数据集和测试数据集比例为8∶1∶1。使用LabelImg软件对7类目标的最终训练集进行标注。训练时,采集的图像尺寸先进行padding操作,然后尺寸调整为416像素×416像素作为输入图像,较小的输入尺寸可以加快网络的计算速度,将图像顺时针旋转90°、180°,然后裁剪、翻转、随机拉伸、随机扭曲、添加马赛克干扰等方法达到数据增强的目的。训练参数为:批量大小32、动量0.97、初始学习率0.005、衰减系数0.9。
2.4 结果分析
表1和图7为不同去模糊算法性能和结果对比,去模糊评估指标包括峰值信噪比(PSNR)和结构相似度(SSIM)[25]。
从表1可以看出,D2-YOLO的去模糊用时约为SRN-Deblur的1/10,约为SSRN-DeblurNet的1/3。在去模糊时间相近的情况下,整体性能优于DeblurGAN和DeblurGAN-v2。从图7可以看出,与模糊图像相比,D2-YOLO在一定程度上还原了图像原有的自然信息,使图像更加清晰。在比较模型中,去模糊结果优于DeblurGAN和DeblurGAN-v2,虽与SRN-Deblur结果相似,但速度快了将近10倍。
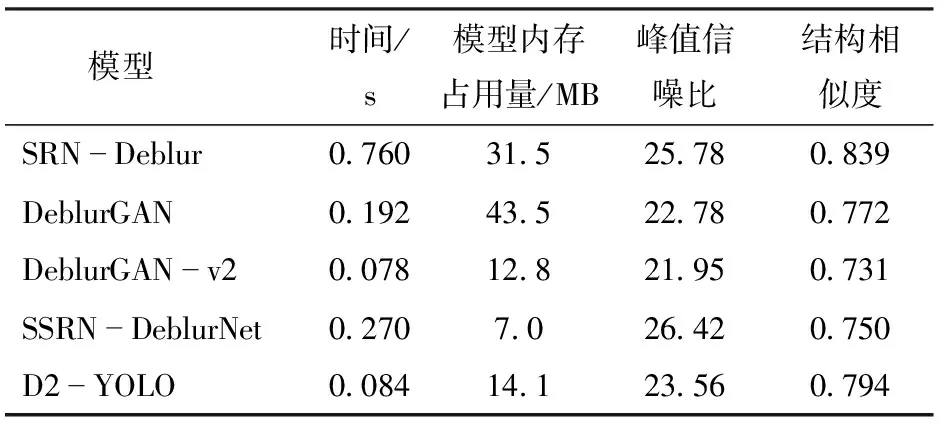
表1 不同去模糊算法性能对比

图7 不同去模糊算法去模糊结果对比
本文所提出的D2-YOLO网络不仅可以去除图像模糊,而且可以同时对障碍物进行识别,为验证D2-YOLO去模糊识别网络检测效果,分别与分步训练的DeblurGAN-v2+YOLOv5s、DeblurGAN-v2+Faster-RCNN以及YOLOv5s检测网络用同样的数据和训练参数进行训练,为防止过拟合,在代码中设置30 Epoch收敛停止训练。评价指标包括准确率、召回率、F1值[26]。
训练完成后,使用果园障碍物数据集中的测试集图像测试各个模型的性能,结果如表2所示。从表2可以看出,D2-YOLO一阶段去模糊识别网络对果园障碍物进行检测时,准确率比DeblurGAN-v2+YOLOv5s、DeblurGAN-v2+Faster-RCNN以及YOLOv5s分别提高1.36、6.82、9.54个百分点,召回率分别提高2.7、5.65、9.99个百分点。同时,D2-YOLO去模糊识别网络参数量比DeblurGAN-v2+YOLOv5s小29.5%,比DeblurGAN-v2+Faster-RCNN小92.91%。在检测速度方面,D2-YOLO去模糊识别网络比DeblurGAN-v2+YOLOv5s快22.05%,比DeblurGAN-v2+Faster-RCNN快183.55%。虽然D2-YOLO在参数量以及检测速度方面逊色于YOLOv5s,但其准确率、召回率、F1值均高于YOLOv5s,在兼顾去模糊功能的前提下,模型的参数量相较于文献[27]方法缩小77.97%,很大程度上解决了针对模糊图像检测精度较差的问题,表明D2-YOLO去模糊识别网络具有更优秀的性能。图8为不同模型平均精度均值(mAP)变化曲线。

图8 不同模型平均精度均值(mAP)变化曲线
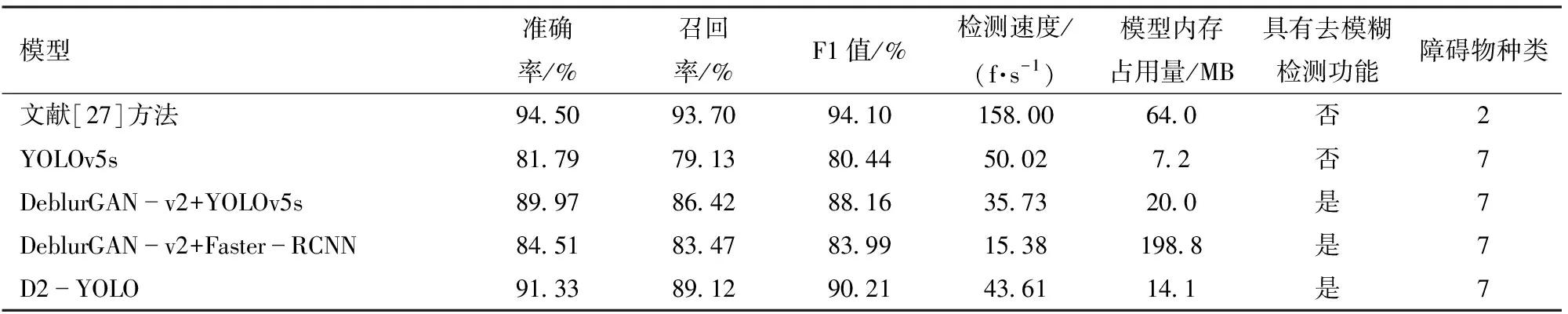
表2 不同模型检测结果对比
为进一步验证本文所提方法的优越性,于真实果园和江苏大学校内共选取12处不同场景进行检测试验。将试验分为2个类别:
第1类,在江苏大学校内选取3处场景用以模拟真实果园场景检测,如图9a~9c所示。从图中可以看出,YOLOv5s在接收到模糊图像后,对被遮挡住的行人和部分树木以及电线杆出现漏检和误检现象,但使用D2-YOLO进行去模糊后的目标检测,有效解决了这一问题。

图9 不同场景下不同模型的检测结果对比
第2类,真实果园中选取9处不同场景进行试验,其中3处场景中的树种为金森女贞球等灌木,如图9d~9f所示,6处场景中的树种为桂花树、腊梅树、紫薇树、红枫树、桑树等乔木,如图9g~9l所示,可以看出,无论是乔木还是灌木,YOLOv5s在接收到模糊图像后,对支撑杆和部分树木均出现误检和漏检现象,对围栏位置检测也不够准确,但是,同样使用D2-YOLO进行去模糊后的目标检测,极大程度上解决了输入模糊图像造成的漏检和误检问题,与模拟场景下的检测结果一致,充分验证了本文所提方法的优越性。
3 结论
(1)提出了一种D2-YOLO一阶段去模糊识别网络。为了减少融合网络的参数量并提高检测速度,首先将YOLOv5s骨干中使用的标准卷积替换为深度可分离卷积,并使用CIoU_Loss作为边界框回归损失函数。融合网络使用改进的CSPDarknet进行特征提取,将模糊图像恢复图像原始自然信息后,结合多尺度特征进行模型预测。
(2)将D2-YOLO一阶段去模糊识别网络与DeblurGAN-v2+YOLOv5s、DeblurGAN-v2+Faster-RCNN、YOLOv5s模型进行对比试验,结果表明D2-YOLO具有更好的检测性能,准确率和召回率分别达到91.33%和89.12%,且网络参数量更少,极大程度上解决了相机抖动和物体相对运动等原因所导致的图像模糊给障碍物检测带来干扰的问题,能够满足果园环境下作业要求。
猜你喜欢
今日农业(2022年16期)2022-09-22
小哥白尼(军事科学)(2022年2期)2022-05-25
快乐语文(2021年27期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
中国与非洲(法文版)(2017年10期)2017-11-23
小学生作文(低年级适用)(2017年9期)2017-10-13
CHIP新电脑(2016年3期)2016-03-10
