
基于本体与认知经验的农业机器人视觉分类决策方法
2023-03-07 03:30熊俊涛廖世盛梁俊浩韦婷婷陈淑绵郑镇辉
农业机械学报 2023年2期
熊俊涛 廖世盛 梁俊浩 韦婷婷 陈淑绵 郑镇辉
(华南农业大学数学与信息学院,广州 510642)
0 引言
信息科技与农业的深度融合使得农业生产进入网络化、数字化、智能化的新阶段[1]。农业机器人是智慧农业发展的重要方向,其智能化程度是应对农业人口老龄化的有效手段,而机器人在进行对象众多、操作复杂且需要与环境进行交互的作业时,常常会碰到未知条件的工作任务,这要求机器人需具备一定的认知决策能力以适应不同对象的随机性。如何提升机器人的认知能力仍是当前机器人研究的关键[2]。基于认知经验是人在农业作业过程进行物品识别、行为动作等决策操作的重要依据。因此,面对环境复杂多变的农业作业过程,希望农业机器人可以模仿人工进行认知计算与决策判断,并能有逻辑地给出决策的依据与过程,赋予其认知思考的能力,以促进机器人的智能认知决策水平。
机器人的视觉认知是其进行作业操作的基础能力。由于作业对象与作业环境的特殊性,目前基于认知经验知识进行农业机器人视觉决策分类的研究内容较少,当下主要是简单利用深度学习方法对图像进行特征提取。如MARANI等[3]基于AlexNet网络完成葡萄串的分割识别;KANG等[4]使用残差神经网络对苹果果实进行检测识别;孟庆宽等[5]基于轻量二阶段检测模型实现多类蔬菜幼苗识别;熊俊涛等[6]基于改进YOLO v3网络实现机器人夜间环境的柑橘识别。虽然相关方法能在大数据驱动下令机器进行有效学习,但训练数据量不足或过多则会导致模型出现欠拟合、过拟合等问题[7],并且方法技术的能力拓展性和共享性不足,人赋予机器相关经验知识的过程也十分复杂,机器进行决策过程的逻辑性和交互性有待提高。
针对上述不足,面向农业机器人实现认知智能化的智慧农业发展需求,本文以机器人视觉认知决策为研究内容,以多种类水果图像的逻辑决策分类为对象,提出在计算机具有图像属性信息判断能力基础上,基于认知经验知识下的相关本体知识库和推理规则,根据图像中获取的属性信息,经搜索推理完成水果图像的分类决策任务。本文视觉分类决策方法主要基于本体技术与认知经验知识,实现机器人模仿人类认知行为对视觉目标进行主动认知与推理决策。当生产作业环境中存在多种类水果与物品时,机器人能实现水果的视觉分类感知和决策知识推理。
1 方法概述
1.1 方法背景与技术流程
基于人类对物体分类决策的逻辑思维,以及物体属性在图像中能表示出来的信息主要有颜色和形状等,当人对图像中物体进行决策学习时,会根据自己眼睛所看到的颜色和形状进行经验学习并记忆。因此,当已学习的物品在新图像中重新出现,人仍能准确对该物体进行识别。
对于只能存储和比较数字的计算机而言,要实现人类这种物体分类决策的逻辑思维主要存在以下困难:①如何对物体颜色、形状这类难以量化的经验特征进行学习和记录。②如何处理物体中多种非结构化信息间的异构性问题。③如何有效使用物体间可重复利用的经验知识与属性能力。
针对上述困难,本文提出使用不同统计分类方法针对颜色、形状等不同非结构化信息进行模糊表示,让计算机获得学习与记录经验特征的能力,而后使用本体语言对物体、颜色、形状等特征对象进行知识描述,解决信息消融与知识共享问题。方法基于图像中获取的颜色属性信息和形状属性信息,在物品视觉认知库中进行搜索推理,进而得到物品的分类决策结果。其流程如图1所示。
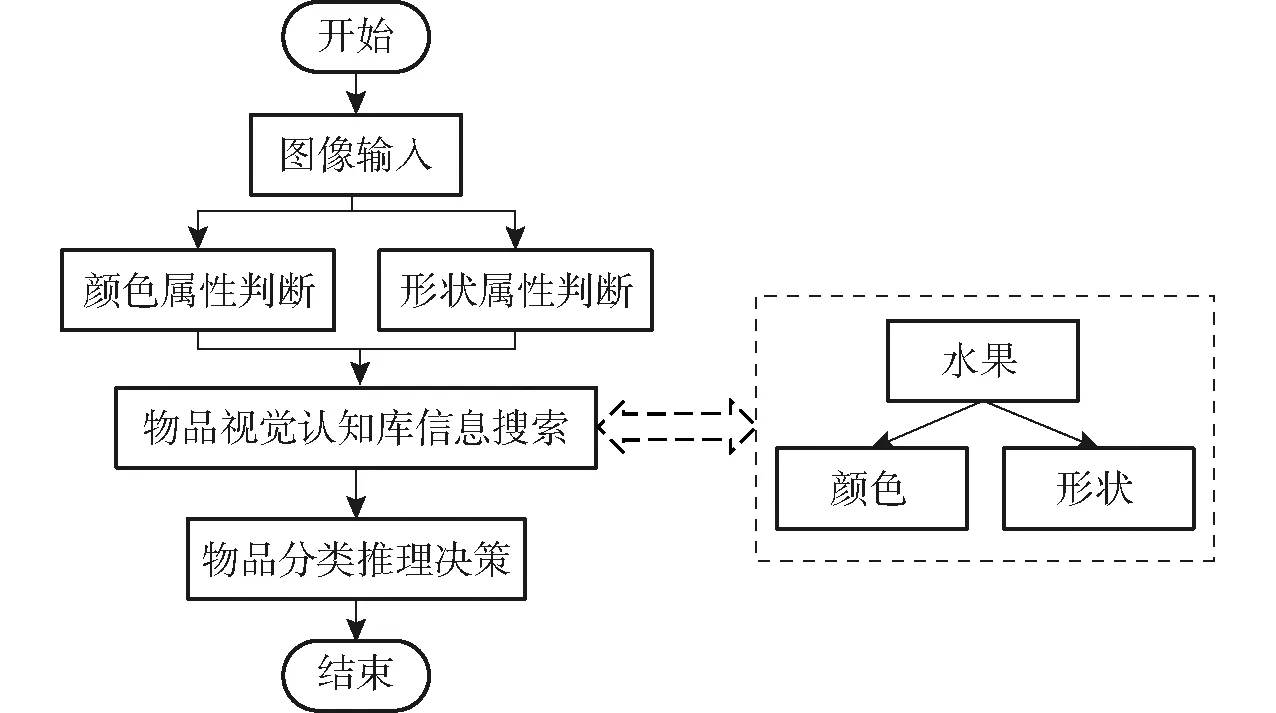
图1 方法流程
1.2 属性特征学习方法
1.2.1颜色属性特征学习方法
在对物体进行识别寻找过程中,颜色是确定物体是否为目标物的重要依据之一。同时,不同颜色还能代表物体的不同状态,如不同颜色状态下的柑橘、香蕉等水果,代表着水果的不同成熟期。因此,让机器人掌握颜色属性的特征学习能力,对其智能化水平的提升也有重要意义。
图像在计算机下,颜色常常是以多个数字矩阵共同表示,如RGB颜色空间数字矩阵组、YUV颜色空间数字矩阵组等,给出的是定量的数字表示。而人眼通常是根据学习经验进行模糊的定性判断,如红色、浅红色、深红色、粉红色等。
为将经验下的模糊定性有效转为计算时的准确定量表示,基于图像颜色是由位置上颜色空间数值决定,本文提出控制单一变量下的计数统计方法,利用连续的一定频数区间来表示颜色的定性经验。
首先,设目标图像尺寸为N×N,图像在常用的RGB颜色空间表示下可以得到一个尺寸为N×N×3的三维数字矩阵A。而后,取出每个图像位置点对应的RGB值,按位置点从左至右、从上至下的顺序,将三维数字矩阵A转换成为(N×N)×3的二维数字矩阵T,其中每行矩阵元素表示图像一个位置点的RGB值。之后,根据数字矩阵的尺寸以及目标物颜色情况,依据人工经验初步设定阈值Z,先对R分量的数字列进行计数筛选,将计数值大于Z的连续范围视为颜色的R分量定量表示区间。而后,在满足R分量表示区间的各位置点上,计数筛选获得G分量表示区间,并在共同满足R、G分量表示区间的各位置点上,同理计数筛选获得B分量表示区间,进而初步得到经验颜色的RGB定量表示区间。最后,经一定数量基础图像测试后,修正的表示区间即为经验颜色的定量表示。其流程如图2所示。
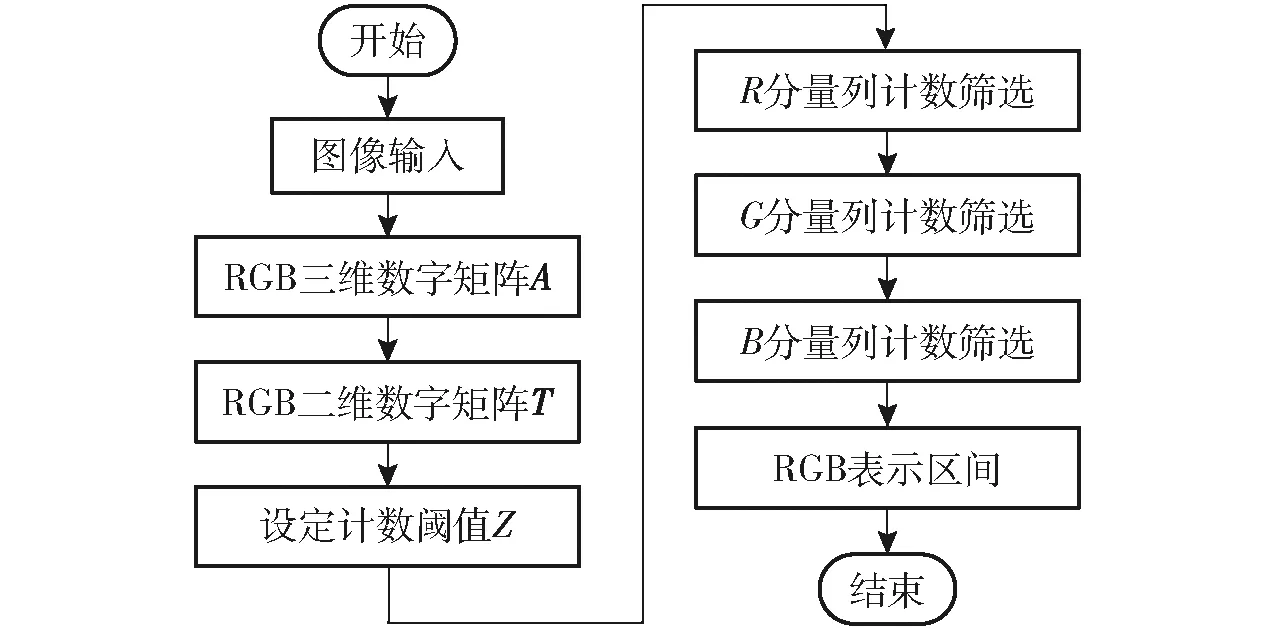
图2 颜色属性特征学习流程图
1.2.2形状属性特征学习方法
物体形状属性由于不会受到光照、颜色等状态量变化而产生变化,被研究者视为比较稳定的属性特征。计算机对物品形状属性的学习,通常是选用机器学习分类器进行形状分类,在提取出形状特征后,通过选取训练样本,训练分类器,最终可以得到有效的模型,完成形状分类识别[8]。
支持向量机(Support vector machine,SVM)是现有研究中常用来进行二维形状分类的分类器之一。它以线性分类器为基础,通过引入最优化理论、结构风险最小化原则和核函数等演化而成[9]。SVM的基本思想可以概括为:通过定义适当内积函数来进行非线性变换,从而将输入空间变换到高维空间,进而在高维新空间中求取最优的线性分类面,完成分类任务[10]。
1.3 本体技术概述
本体的概念最初是在哲学领域提出的,旨在抽象地对客观现实进行说明和解释[11],是一种通用、被广泛认可的知识表征方法,其具有共享性和可拓展性等特点[12]。基于本体语言描述建立的知识库,能够让机器人通过本地网络快速获取知识库中的知识信息[13]。目前本体技术已经广泛地应用于上下文感知[14-15]、环境建模[16-18]、任务决策[19-20]和资源整合[21-23]等方面。
1.3.1本体定义与描述语言
本体(Ontology)是一种对知识进行集成和建模的工具[24]。关于本体定义目前普遍认同的是:Ontology是共享概念模型明确的形式化规范说明[25]。在本体语言的描述中,可以将知识库视为一个对象本体,物品、形状、颜色等可以作为描述资源。
本体的描述语言主要是通过三元组的形式存储内容,将知识划分为主语、谓语、宾语进行内容储存与查询,它的语言格式有多种,如网络本体语言(Web ontology language,OWL)、可扩展标记语言(Extensible markup language,XML)、资源描述框架(Resource description framework,RDF)等,目前使用较为广泛的是OWL[26]。
OWL主要基于已有的XML、RDF等标准形式语言,通过添加大量基于描述逻辑的语义,来描述和构建各种本体。与XML和RDF等语言相比,OWL语言在表达语义和目的方面具有更强大的能力[27]。
1.3.2本体优势
本体在知识管理与知识组织的优势主要有:首先,本体描述语言可以使逻辑表达语言更加自然化,并基于规则推理能促进隐性知识的显性化;其次,本体技术可以集成来自作业环境中的异构数据,消除不同信息间的异构性,从而为环境空间中的异构信息提供统一的知识化表示平台,是实现知识共享和重用的一种主要方法;最后,领域本体能够描述某个特定领域内的基本概念、结构关系、实体活动原理等,构建的语义模型可以为用户进行个性化、智能化服务提供基础[28]。
1.3.3本体建立与编辑工具
Protégé软件主要用于语义网中本体的构建,是语义网中本体构建的核心开发工具[29]。它提供了本体概念类、关系、属性和实例的构建,并且屏蔽了具体的本体描述语言,用户只需在概念层次上进行领域本体模型的构建。用户可以根据具体应用领域的知识结构通过定义Class(类)、表述Class之间关系的Object Properties(对象属性)以及向Class中填充Instance(实例)来构建本体。
本文在物品属性特征学习的基础上,将机器人作为认知本体,构建物品、形状、颜色3个子类,并搭建物品与形状、物品与颜色之间的类间谓语关系,如图3所示。通过类内实例补充和实例与实例间的谓语关系联系,使机器人拥有物品决策分类的内容与逻辑基础,进而当获得物品相关宾语信息即颜色与形状信息后,可以根据相应关系获得物品的决策预测。

图3 决策本体库构建示意图
1.3.4本体知识查询方法
SPARQL是基于图模式匹配的一种查询语言方法。三元组模式与RDF三元组类似,是最简单的图模式,也是组成其他图模式的基础。在三元组模式中,subject、predict、object均可用前缀为“?”的变量即查询对象替换。典型的SPARQL查询语句由SELECT、FROM、WHERE组成,此外还可包含OPTIONAL、FILTER、ORDER BY、LIMIT、OFFSET等部分。形如:SELECT ?aname WHERE{?a foaf:knows Lily.?a foaf:name ?aname.}。
本文为表述方便在后面将以三元组形式进行描述,形如〈?a,has_shape,长条形〉,表示搜索获取形状为长条形的实体。
2 实验与结果分析
为验证方法的可行性,实现基于属性学习与本体知识库的图像分类决策。面向多种类水果自动化分拣流水线背景环境,本文从Fruit360数据集中筛选出樱桃、葡萄、香蕉、黄桃等水果图像,在构建图像环境下樱桃、葡萄、香蕉等水果的本体视觉知识库与搜索推理规则的基础上,选取部分图像作为样本数据,令计算机获得数据集下的颜色和形状判别能力,再经知识库搜索推理获得图像的分类决策。
2.1 数据集获取
Fruit360数据集由HOREA等建立,截至2020年5月18日数据集内包含有131种水果和蔬菜的90 483幅图像,并不断更新。其中的图像是水果按一定速率旋转录制截图并处理后获得,可以在很大程度上降低图像数据集因灯光环境和拍摄条件等变化带来的影响。此外,数据集中图像背景简单,在一定程度上能较好地模拟机器对水果识别分类的情景。因此,选用Fruit360数据集中樱桃、葡萄、香蕉、黄桃等水果图像作为实验所用数据集,如表1所示。
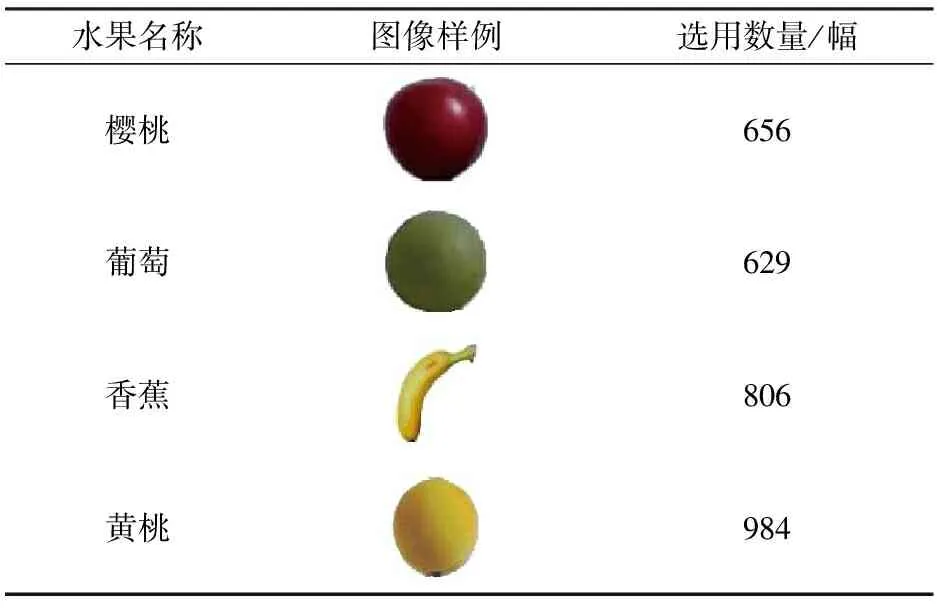
表1 实验数据统计
2.2 视觉知识库搭建
基于1.3节的基本理论,在Protégé 5.5工具环境下以机器人视觉认知为本体,构建水果、颜色、属性3个类,并在水果与颜色、水果与形状间分别添加类间关系has_color、has_shape,并在水果类下添加实例:樱桃、葡萄、香蕉,颜色类下添加实例:红色、青色、黄色,形状类下添加实例:圆形、长条形。随后,逐一添加实例间公理,其三元组格式为〈樱桃,has_color,红色〉、〈樱桃,has_shape,圆形〉、〈葡萄,has_color,青色〉、〈葡萄,has_shape,圆形〉、〈香蕉,has_color,黄色〉、〈香蕉,has_shape,长条形〉。如图4所示。
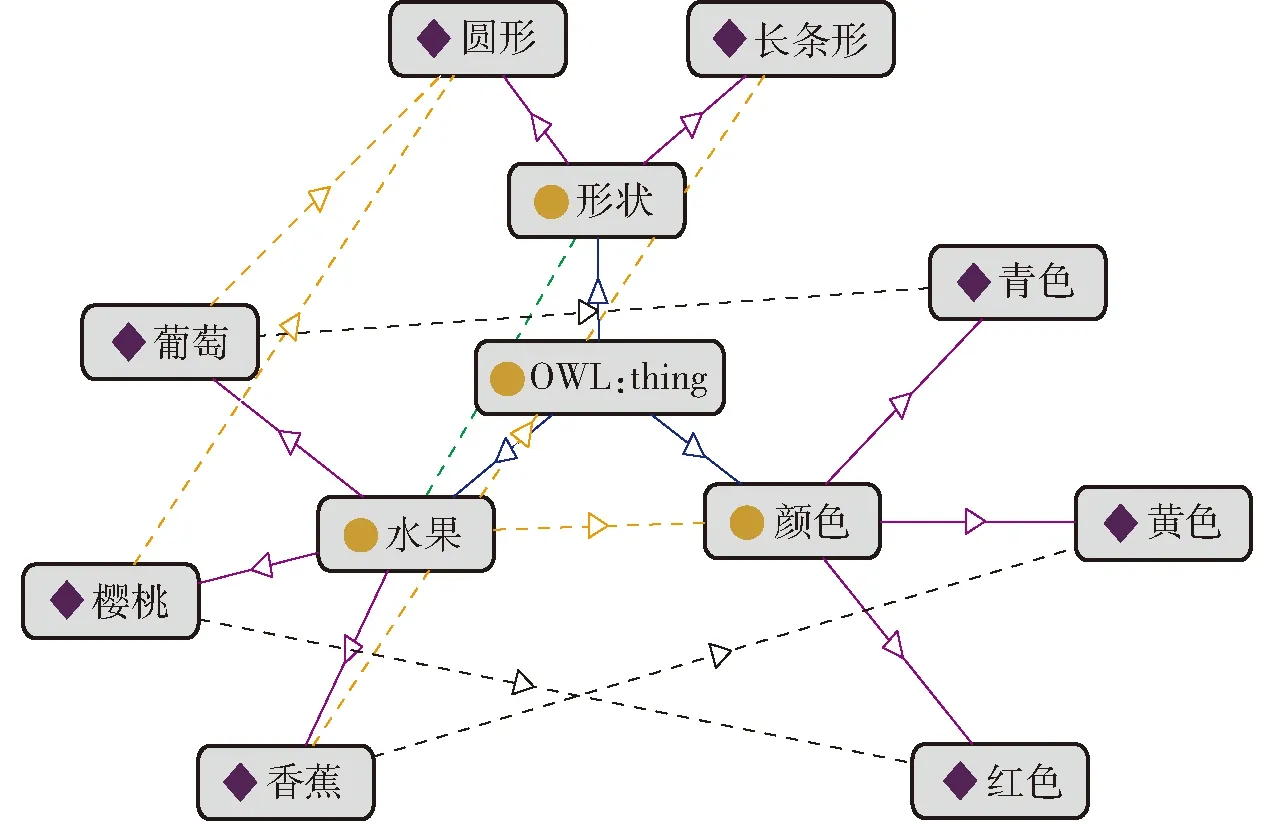
图4 水果视觉知识库
2.3 知识库搜索规则设定
Protégé构建好的本体知识库是以RDF的标准格式存储为OWL文件。通过使用Python中rdflib功能包对本体知识库文件进行解析,并基于已知条件使用SPARQL查询语言在知识库内查询。但为更有效利用知识库内知识与分类方法的逻辑可依性,设定搜索规则如下。
假设计算机获得X水果图像的颜色为C,形状为S。即在知识库中输入颜色C、形状S,经搜索输出水果X。首先,以颜色C、形状S为共同条件搜索:〈?fruit,has_color,C〉&〈?fruit,has_shape,S〉,得到满足条件的水果数N1及搜索结果F1={f1,f2,…,fN1},若水果数N1=1,即可判断F1为水果X,输出:“水果为F1”。若N1>1,则说明在认知库中存在同一颜色和形状的不同水果,需再加入属性进行判断,输出“水果可能为:F1,需添加属性判断”。
若N1<1,则说明认知库中并不存在完全符合条件的水果,或出现属性判别出错导致无法得出结果,输出“未找到完全匹配水果,目标水果颜色为C,形状为S”,通过反馈,可找到为什么系统预判错误的原因。并对颜色C与形状S单独搜索:〈?fruit,has_color,C〉,得到颜色搜索下的水果数N2和搜索结果F2={f1,f2,…,fN2};〈?fruit,has_shape,S〉,得到形状搜索下的水果数N3和搜索结果F3={f1,f2,…,fN3}。若N2≥1,N3≥1,则输出“根据颜色水果可能为:F2;根据形状水果可能为:F3”;若N2≥1,N3=0,则输出“根据颜色水果可能为:F2”;若N2=0,N3≥1,则输出“根据形状水果可能为:F3”;若N2=0,N3=0,则输出“未找到对应水果”,需对知识库进行添加。其流程如图5所示。
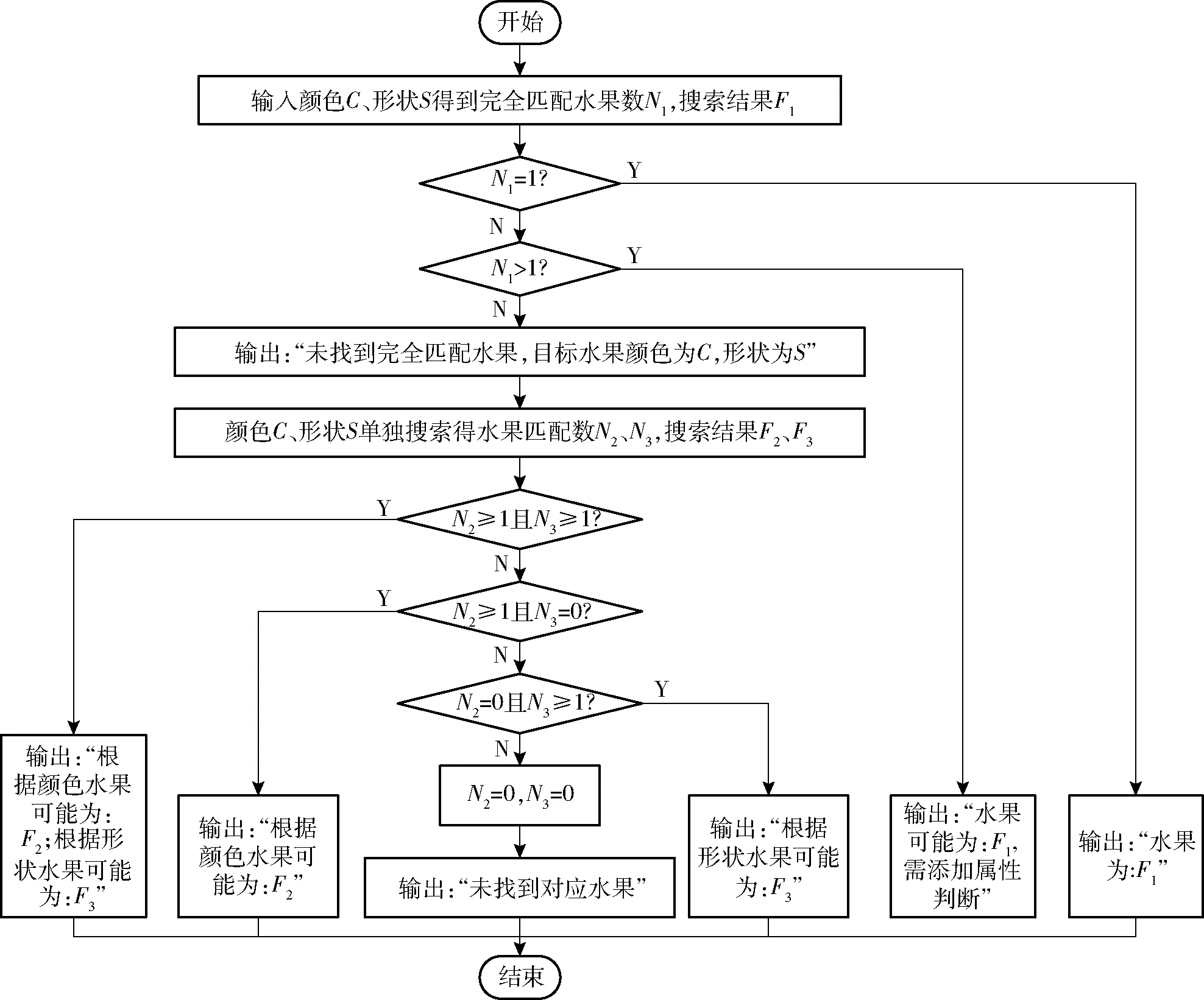
图5 语义搜索流程图
2.4 颜色属性特征学习
基于人的先验认知经验,将水果颜色简单分为:红色、青色、黄色3种。同时获取樱桃、葡萄、香蕉3种水果数据集图像中的30幅图像作为颜色属性特征学习的训练集与测试集。
基于1.2.1节的方法与理论基础,在3种颜色下各随机挑选一幅图像进行RGB分量读取与统计,初步获得能表示该颜色的RGB分量范围。以红色为例,其颜色属性特征学习步骤如下:
(1)随机选取一幅樱桃图像,而后基于Python中cv2库中的imread函数获取得到图像的BGR颜色分量矩阵,并通过矩阵数组操作,将其由100×100×3数字矩阵按从左至右、从上至下的顺序,对应变成10 000×3数字矩阵,而后以10 000×3的数字矩阵形式将其导出至Excel文档中。
(2)使用计数功能选项,对B分量下0~255元素值进行统计计数,初步尝试以平均值39(10 000÷256)为频数作为分割临界值,发现区间[0,64]内分布的元素值满足频数要求,因此,初步将该区间作为红色中B分量的表示区间,并基于筛选得到的6 669个位置点及其对应的G、R分量值进行下一步骤。
(3)对这6 669个位置点的G分量值进行计数统计,仍尝试以平均值39为频数作为分割临界值,得到区间[0,41]的元素满足条件,但发现元素42的计数为38,元素43为27,38离平均值较近且与下一元素统计值较远,因此将G分量表示范围动态调整为[0,42],得到6 466个位置点及其对应的R分量值满足筛选条件进行下一步骤。
(4)对满足B、G分量筛选条件的6 466个位置点进行R分量统计计数,同理得到,该分量满足临界条件的元素值区间范围为[39,125]。
综上,可初步得到红色区间表示为B∈[0,64],G∈[0,42],R∈[39,125]。同理,可对葡萄、香蕉2种水果的单幅图像进行上述操作,初步得到青色区间表示为B∈[17,102],G∈[63,130],R∈[59,119],黄色区间表示为B∈[0,114],G∈[154,200],R∈[157,208]。
同时,设定图像中符合某一颜色区间的计数值最大,则判定该颜色为图像主要颜色。即将图像每一位置RGB分量值与各颜色表示区间进行比较后,得到图像满足各颜色表示区间的统计计数值分别为R1、B1、Y1,记D=max{R1,B1,Y1},D表示R1、B1、Y1中计数值最大的变量,其所表示的颜色即为图像物品主要颜色。其流程如图6所示。
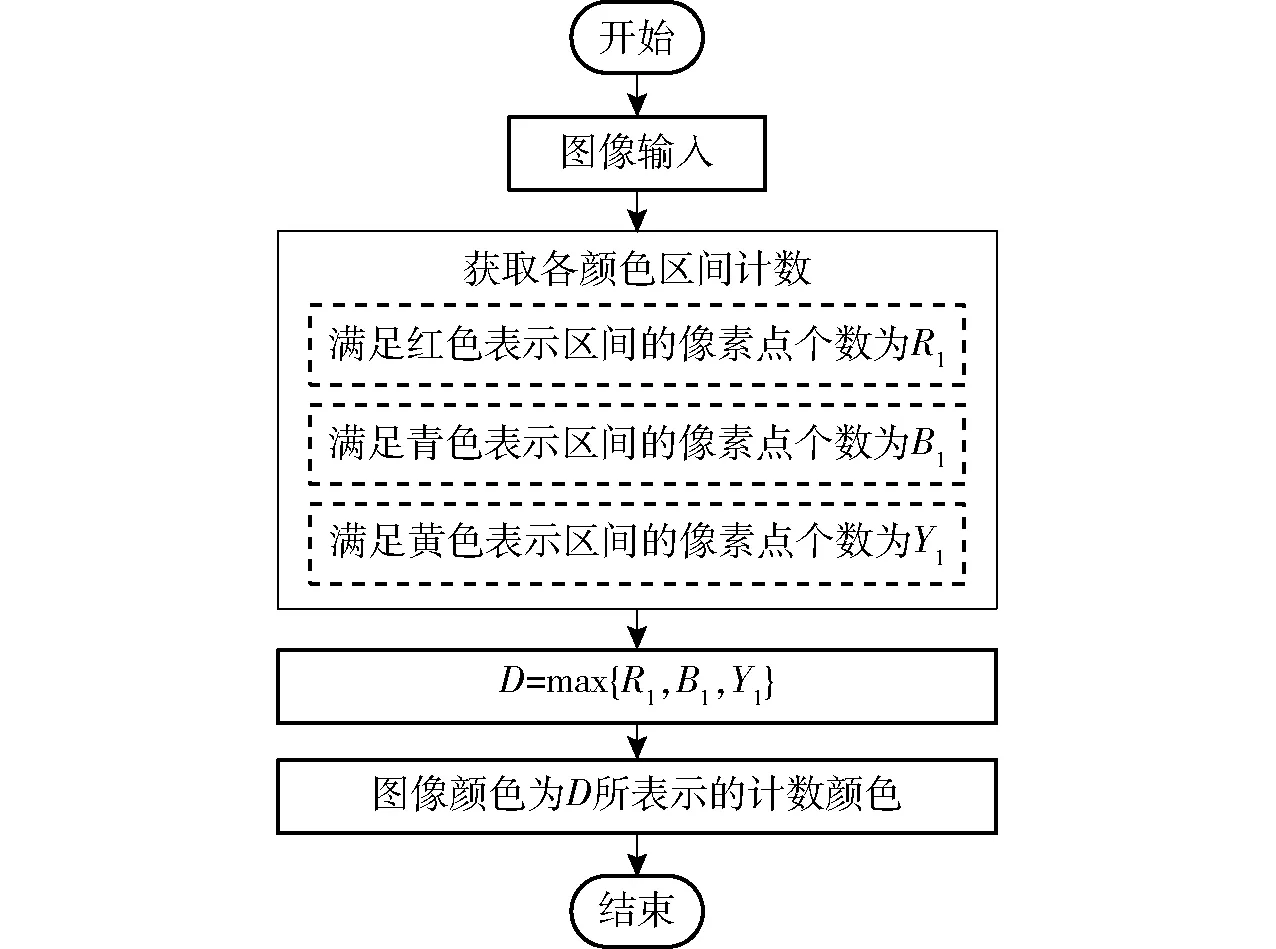
图6 颜色属性获取流程图
而后,对3种水果各使用30幅图像进行测试,根据其颜色区间的统计情况及最终判断结果,对3种颜色表示区间进行了微调,最终确定红色区间表示为B∈[0,64],G∈[0,47],R∈[20,152],青色区间表示为B∈[17,102],G∈[63,130],R∈[59,119],黄色区间表示为B∈[0,114],G∈[92,200],R∈[100,208]。经调整该区间表示,测试集下各颜色的识别准确率均为100%,满足实验所需能力要求。
2.5 形状属性特征学习
结合2.2节所构建的水果视觉知识库,将水果形状简单分为圆形和长条形。基于1.2.2节理论背景,由于水果形状特征差异明显,线性核具有求解速度快、可解释性强等特点。所以,基于Python中sklearn模块的SVM模型,以1为惩罚项系数,linear为核函数使用SVM分类器对水果形状进行分类学习。
为消除颜色对形状分类的影响,先将图像进行二值化,以获得水果单纯的形状图像。并随机选取二值化后的香蕉、葡萄图像各5幅,保存至对应文件夹中,作为训练集。之后,随机选择葡萄、樱桃、香蕉3种水果各30幅图像以验证学习效果,其分类准确率可达100%,表明形状属性学习成功有效。具体步骤为:①随机选取葡萄、香蕉图像各5幅,将其二值化后,保存至对应训练集文件夹中。②读取图像,并分别对图像进行灰度直方图特征提取和SIFT特征提取,并将特征提取处理后的图像拉伸为一维向量。③将训练集代入 SVM 算法中进行训练生成一个模型,并形成可进行分类预测的功能函数。④批量读取测试集图像,经二值化后,进入步骤③中功能函数得到分类预测结果。⑤将分类结果与实际值进行比对,得到其形状分类准确率为100%。表明实验方法准确、有效。
2.6 分类方法系统集成及实验测试
基于上述实验准备与测试,将各模块功能进行集成整合,其整体流程如图7所示。

图7 方法技术流程图
随后,对实验数据集下所有图像进行分类测试,结果如表2所示。

表2 第1次图像分类测试结果
将香蕉未能识别成功的图像进行决策过程显示,发现有93幅图像被识别判断为“青色、长条形”,26幅图像被识别判断为“黄色、圆形”,28幅图像被识别判断为“青色、圆形”。
经图像溯源可知,部分图像中香蕉未成熟,其中青色区域比黄色区域多,故被识别判断为“青色”,而有些香蕉图像因拍摄角度问题,经二值化后图像整体呈类圆形。因此,根据溯源结果与客观事实,在知识库内添加补充知识〈未成熟香蕉,has_color,青色〉、〈未成熟香蕉,has_shape,长条形〉。对于形状被识别为圆形的图像,则认定为异常数据值。最后,进行二次实验,其结果如表3所示。
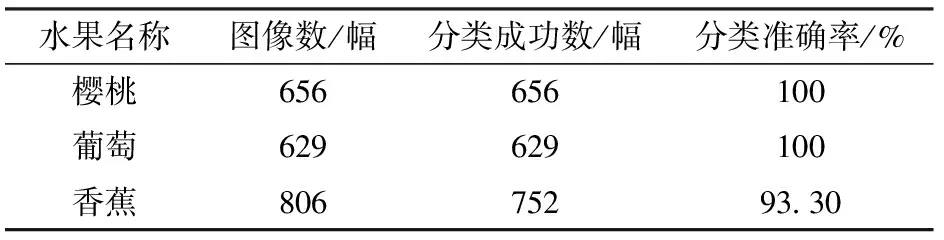
表3 第2次图像分类测试结果
2.7 经验目标测试
基于上述实验可知,本文方法对经过基本属性训练的水果图像有优异的决策分类能力。基于方法属性能力的可迁移性和知识库内容的可拓展性,在水果类下加入一个新实例——黄桃,用来测试方法在无样本训练下的决策分类能力。
根据原知识库与图像数据中颜色和形状情况,可知认知经验下黄桃图像更倾向圆形,且颜色应为黄色。因此,在本体知识库的水果类中添加黄桃这一实例,并创建其与黄色实例和圆形实例间的属性连接,更新的知识库如图8所示。
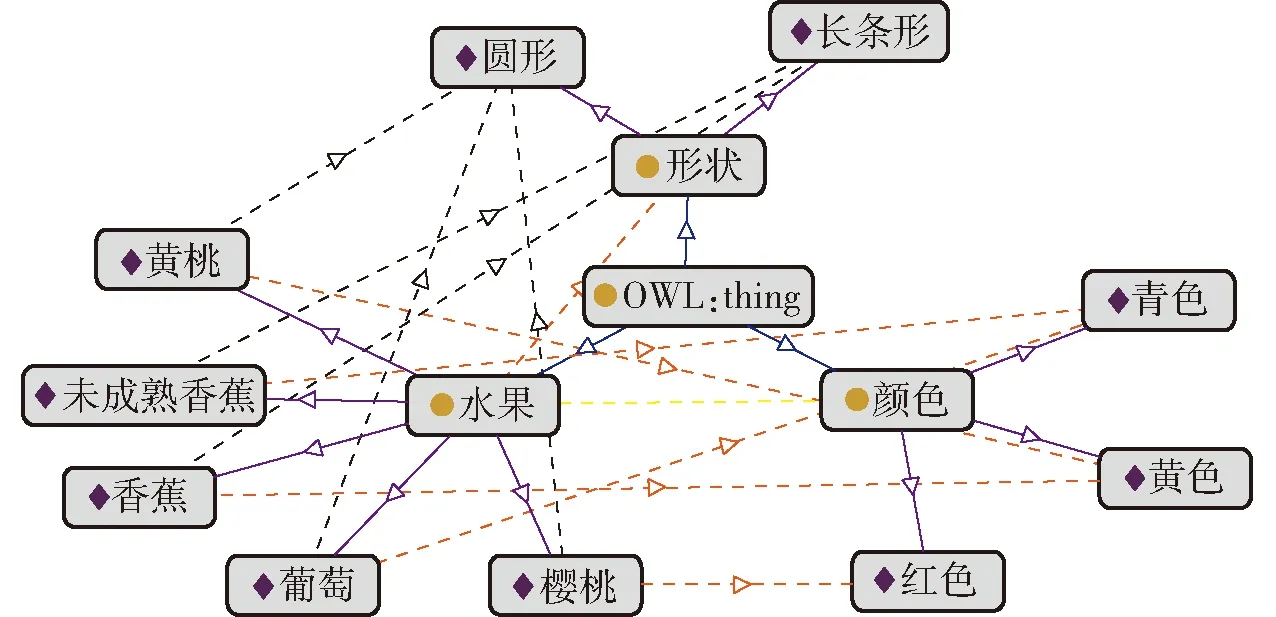
图8 新知识库
之后,用实验数据集中挑选的984幅黄桃图像进行决策分类测试,结果显示其准确分类的图像数为955幅,分类准确率为97.05%。其中29幅图像被错误判别为葡萄,根据葡萄定义的颜色和形状为青色、圆形,返回错误判别图像可知,图像部分呈不成熟的青色状,导致判别错误,若要提高分类准确率,则应提高颜色属性的判别能力。
由此可以说明,基于一定条件,在本文方法下,人的先验知识可以很好地辅助计算机对未知图像样本进行决策分类,进一步验证了本文方法设想的可拓展性和先进性。
2.8 实验结果分析
基于上述实验结果可知,本文方法下樱桃、葡萄和香蕉等经过属性训练的水果图像数据集,初次分类准确率分别为100%、100%、81.76%,经决策过程溯源,知识库内添加相关知识后,第2次分类准确率分别为100%、100%、93.30%。在此基础上,对于未经训练的黄桃图像数据集,在认知经验指导下,仅扩充知识库知识,其分类准确率为97.05%。表明本文方法辅助计算机进行分类决策的效果十分优异,说明一定环境下本文方法可以较好地将人的认知经验传输给计算机,并能被计算机所利用。其中逻辑化的处理过程,也可以搭建良好的人机沟通平台,让计算机在较少数据样本下完成学习任务,并在出现决策错误时可以通过溯源找到问题原因,通过反馈找到解决问题的方法。
2.9 讨论
基于实验过程与结果可以发现,樱桃和葡萄的精准分类,不仅源于其形状、颜色相对固定,在属性能力训练与验证时进行了针对性学习也是其分类准确率高的因素之一。同时,当前知识库内容较少,本体结构相对简单也是良好实验结果的部分原因。
因此,针对对象形状、颜色等属性或受生长环境影响而不稳定的问题,可在认知经验辅助判断下,基于决策反馈结果对错误决策样本情况,在机器人进行属性特征学习时进行属性的模糊表示。此外,当面向丰富的知识库知识与复杂的本体结构时,可在提升属性学习方法鲁棒性情况下,充分利用本体技术的可拓展性,基于条件添加可学习的属性特征,如图像信息条件下添加纹理、面积等特征,机器实物操作信息条件下添加对象硬度、三维体积等特征。通过多属性信息情况对对象间的差异进行知识描述,并使用语义网络规则语言等规则语言对复杂本体结构进行知识的调用推理。
3 结论
(1)基于认知经验,使用Protégé等工具构建水果识别分类的专业知识库,结合统计计数和SVM方法实现了农业机器人的图像颜色和形状属性的学习和判断的认知。
(2)设计了葡萄、香蕉和樱桃的图像分类实验,实验结果显示,当前数据下葡萄与樱桃识别准确率为100%,香蕉识别准确率为93.30%,表明基于机器人对图像的属性判断能力和认知经验建立的本体知识库,可以有效指导农业机器人在小样本环境下完成物品的分类决策任务。
(3)设计了黄桃图像分类的认知实验,其分类准确率为97.05%,表明基于可共享的属性判别能力,通过对本体知识库的扩充,可以在无目标样本图像训练的条件下,实现农业机器人分类决策能力的扩展。
猜你喜欢
中学生天地(A版)(2022年11期)2022-11-25
制造技术与机床(2019年6期)2019-06-25
新世纪智能(英语备考)(2018年11期)2018-12-29
制造业自动化(2017年2期)2017-03-20
小学生学习指导(低年级)(2016年10期)2016-12-01
中国交通信息化(2016年9期)2016-06-06
文学教育(2016年27期)2016-02-28
图书馆研究(2015年5期)2015-12-07
图书与情报(2013年1期)2013-11-16
卷宗(2013年6期)2013-10-21
