
基于改进YOLO v5n的猪只盘点算法
2023-03-07 07:34:14杨秋妹陈淼彬黄一桂肖德琴刘又夫周家鑫
农业机械学报 2023年1期
杨秋妹 陈淼彬 黄一桂 肖德琴 刘又夫 周家鑫
(1.华南农业大学数学与信息学院, 广州 510642; 2.农业农村部华南热带智慧农业技术重点实验室, 广州 510642)
0 引言
猪只盘点是猪场集约化资产管理中的一项重要任务。依据准确的猪只数量可以制定更加合理的养殖计划,帮助养殖户降低成本,减少不必要的损失,提高养殖场收益。传统的人工盘点方法需要高劳动力成本,且容易受到猪群重叠、相互遮挡、摄像头视角或者光照等影响,容易出错。另外,人工盘点会引起猪只的应激反应,出现猪只受惊或乱跑,增加盘点的难度,无法保证盘点的准确性。
随着规模化、信息化智慧养猪建设的快速推进,计算机视觉算法因其具有无侵扰、不间断、成本低等优势,成为智能猪只盘点方法的主要发展趋势[1]。早期的视觉猪只盘点方法利用形态学算法和区域生长法相结合的方法将背景与前景分割,从而实现猪只数量的统计[2-3]。深度学习方法在处理复杂遮挡计数问题上有很大的优势[4-8]。目前,有不少的研究人员已经将深度学习应用于猪只盘点。基于神经网络的密度图回归的计数方法受到不少研究人员的重视[9-11]。此类方法利用像素将图像转换为密度图回归,并对密度图进行积分得到计数。文献[12]提出了一个自底向上的猪只身体关键点检测方法,然后再基于STRF(空间敏感时序响应)方法进行猪只计数。文献[13]用改进的Mask R-CNN网络减少了因光照和生猪遮挡致使猪只目标漏检的问题,其网络在12~22头猪只的单栏的计数准确率达到98%。
综上,基于深度学习的猪只盘点算法虽然优于人工计数方法,但由于猪是一种群居的动物,通常挨靠在一起致使猪只互相遮挡重叠。而且同一猪舍的猪只颜色相近,当猪只体型发生变化的时候,更容易导致猪只个体难以区分,使得识别难度增大。因此,针对猪只相互遮挡、体型变化或者光线暗的情况下导致漏检或者多检的问题,本文结合注意力机制和多尺度特征检测,在YOLO v5n网络的基础上进行改进,拟实现一种改进YOLO v5n猪只计数算法。
1 数据集构建与计数原理
1.1 数据来源
本文的实验数据来源于5种不同的猪场数据集,分别是3个自建实验猪场数据集:广州萝岗实验猪场、云浮范金树实验猪场、隔离舍实验猪场,以及两个公开数据集:文献[14-15]公开的数据集。广州萝岗实验猪场选取长白后备母猪为实验对象,猪栏尺寸为4 m×5 m,单栏内饲养4头猪,猪只数量较少;云浮范金树实验猪场选取育肥期的长白母猪为实验对象,群养猪栏尺寸为5 m×8 m,单栏内平均饲养40头猪,猪只数量较多,但局限于摄像头拍照角度肉眼可见的猪只数量平均为26头;隔离舍实验猪场选取育肥期的长白母猪为实验对象,猪栏尺寸为2 m×4 m,单栏内饲养6头猪;文献[14]的数据集描述了17个不同的猪圈位置,包括1.5~5.5月龄猪只,单栏内饲养的猪只数量有7、8、10、11、14、15头,既包括日间拍摄的图像也包括晚上拍摄的图像;文献[15]实验猪场的单个猪圈尺寸为5.8 m×1.9 m,有8头猪,体质量约为30 kg。各实验猪场信息如表1所示。
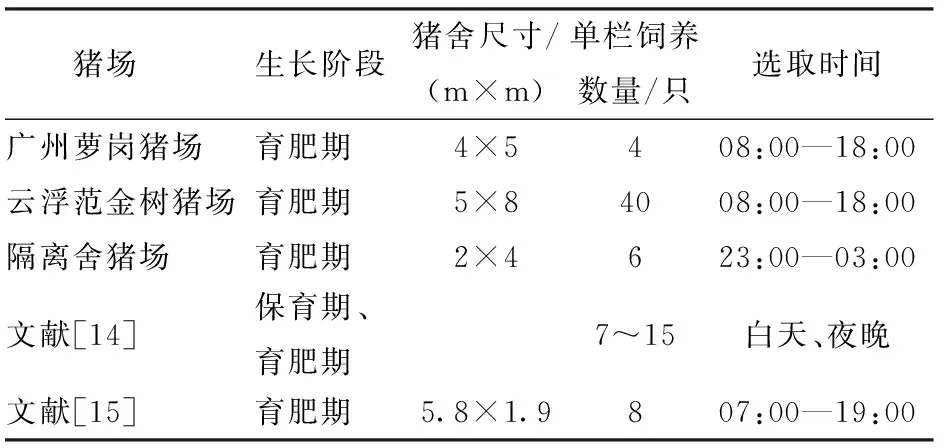
表1 各猪场信息Tab.1 Information of pig farms
广州萝岗猪场、云浮范金树猪场、隔离舍猪场均采用海康威视DS-2CD3345-I型红外网络摄像头。广州萝岗猪场每天24 h共持续32 d对猪栏进行监控,但只选取08:00—18:00猪只比较活跃的时段。云浮范金树猪场与隔离舍猪场每天24 h不间断拍摄监控,同时选取白天活跃时段和夜晚睡眠阶段拍摄。
1.2 数据预处理与数据集构建
对采集到的视频每隔35帧截取一幅图像,并去除相似度过高、清晰度较差的图像。为更准确地计算单栏内猪只数量,排除其他相邻栏位猪只对实验计数结果的影响,本文对包含多个猪栏的图像进行了掩膜处理,在原始图像上以盘点猪栏为界限,添加一掩膜层,遮住其他栏位的猪只,掩膜的处理效果如图1所示。

图1 掩膜处理图像Fig.1 Mask processing pictures
最终数据集共有3 000幅图像,并用LabelImg标注软件进行标注。整个猪只盘点数据集按6∶2∶2的比例划分训练集、验证集和测试集。为保证数据集的多样性,利用Python脚本程序分别从各猪场随机选取600幅图像,其中训练集360幅图像,验证集和测试集均为120幅图像。依据上述方法本文构建的猪只盘点数据集如表2所示。

表2 猪只盘点数据集Tab.2 Pig counting dataset
1.3 研究方法
本文提出了一种改进YOLO v5n猪只计数方法。首先,构建多场景的猪只盘点数据集(包括不同猪舍尺寸、不同群养猪只数量、不同遮挡程度、不同拍摄角度、不同光线强度等)。该方法在处理猪只遮挡重叠的问题,通过利用通道注意力机制在筛选特征时,能够提高感兴趣的区域信息权重,弱化与当前任务无关的特征信息以提升模型效果[16],同时增加多尺度物体检测层,获得更丰富全面的特征信息,增强模型在复杂场景下多尺度学习的能力;并对边界框的损失函数以及加权的非极大值抑制(Non-maximum suppression,NMS)进行改进,提高模型在遮挡场景下的检测精度和速度,降低漏检率。最后经过非极大值抑制(DIoU-NMS)处理输出最终预测结果,并计算得到最终的猪只数量。本文方法流程如图2所示。

图2 本文方法流程图Fig.2 Flow chart of proposed method
2 猪只计数网络实现
2.1 YOLO v5n网络
YOLO v5[17]是基于YOLO v4算法基础上进行改进,同属于单阶段目标检测算法,其速度与精度较之前版本都得到了大幅提升。YOLO v5支持5个不同规模的模型,根据网络的深度和宽度可分为YOLO v5n、YOLO v5s、YOLO v5m、YOLO v5l、YOLO v5x版本,其相对应模型的检测精度和模型参数量依次提高。为了从上述5个不同规模的模型中选择更适合猪只盘点的模型,使用本文的猪只盘点数据集重新训练上述5个模型,并分别用训练好的模型对测试数据集中的图像进行测试。其实验结果如表3所示,平衡模型的精度、参数量以及在猪只盘点实际应用中实时5性要求3个指标,在精度相近的情况下,YOLO v5n模型的参数量只有1.9×106,其单幅图像平均识别时间仅为0.017 4 s,相比较于参数量最多的YOLO v5x,平均精确度(Average precision,AP)相差1.49个百分点,但单幅图像平均识别时间快了 48.4 ms。 其次,与YOLO v5s模型相比,虽然识别速度相近,但两者的参数量相差近4倍。由于在猪场的盘点应用中,常采用边缘设备进行猪只盘点,此类设备对算法的处理速度要求较高。因此,本文最终选用参数量最少、识别速度最快的YOLO v5n作为本次实验的基础模型以便能够实时获取猪场猪只总数。

表3 YOLO v5不同规模模型的准确度比较Tab.3 Accuracy comparison of different scale models of YOLO v5
如图3所示,YOLO v5n网络结构分为输入端、主干特征提取网络Backbone、颈部Neck网络和输出端共4部分。

图3 YOLO v5n网络结构图Fig.3 YOLO v5n network structure diagram
YOLO v5n的输入端对输入图像预处理,即将任意尺寸的输入图像缩放为网络的输入尺寸,并进行Mosaic数据增强丰富图像检测目标的背景,而且能够提高小目标的检测效果,并且在归一化计算时一次性处理多幅图像。其次,YOLO 系列检测算法中,针对不同的数据集往往需要设定特定长宽的锚框。在网络训练阶段,模型在初始锚框的基础上输出边界框,从而跟真实框对比,计算两者间的差距,再反向更新,迭代网络参数。在YOLO v3和YOLO v4检测算法中,在网络训练前单独采用K-Means聚类方法以获取不同数据集的最佳锚框值。但在YOLO v5检测算法中通过内嵌自适应锚框计算方法,每次训练前对数据集标注信息进行计算,得到该数据集标准信息针对默认锚框的最佳召回率,当最佳召回率大于或等于98%时,则不需要更新锚框;否则,重新计算符合该数据集的锚框,从而能够自适应地计算出不同训练集中最佳锚框值。
主干特征提取网络Backbone使用CSPDarknet53结构,且加入Conv卷积,CSP及SPPF[18]结构。通过使用一个卷积核尺寸为6×6,步长为2的卷积结构代替Focus结构,既能达到2倍下采样特征图的效果,又可避免多次采用切片操作,提高计算和推理速度[19]。其次,不同于YOLO v4,YOLO v5n设计了两种CSP结构,CSP1_X结构应用于主干特征提取网络Backbone中,CSP2_X结构应用于Neck网络中,其结构图如图4所示。SPPF结构(图5)与SPP结构一样,均采用1×1、5×5、9×9和13×13的最大池化方式,进行多尺度特征融合,但SPPF结构可以降低每秒浮点运算次数,运行的更快。

图4 两种CSP结构Fig.4 Two CSP structures
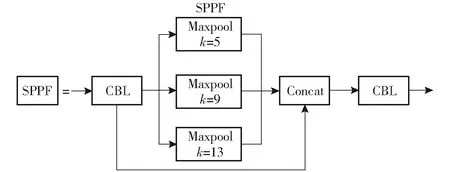
图5 SPPF结构Fig.5 SPPF structure
Neck部分将特征金字塔的不同层级的图像组合在一起来完成多尺度混合,并将图像特征传递给预测层[20]。该部分仍采用FPN和PANet结合的双金字塔结构。特征金字塔网络(Feature pyramid networks,FPN)自顶向下,将高层的语义特征往下传递,得到预测的特征图[21]。路径聚合网络(Path aggregation network,PANet)是针对FPN只增强了语义信息,但并没有对定位信息进行传递的缺点[22]。通过在特征金字塔FPN的后面增加一个自底向上的路径,用底层精确的定位信息来增强整个特征层次结构,从而缩短底层特征与高层特征之间的信息路径。
输出端采用GIoU Loss作为边界框损失函数,其解决了当边界框与真实框没有交集时,交并比(Intersection over union,IoU)等于0,其损失函数导数也为0,从而无法优化两框重叠的问题。在目标检测的最后处理过程中,YOLO v5n使用加权的NMS方式筛选N个目标框。
2.2 SE-Net注意力模块
注意力机制是通过参考人的视觉感知能力,即人在处理视觉信息初期会集中专注于当前情景下重点区域,而其他区域将相应降低,这为更高层级的视觉感知和逻辑推理以及更加复杂的计算机视觉处理任务提供更易于处理且更相关的信息[23]。
在深度卷积神经网络中,通过构建一系列的卷积层、非线性层和下采样层使得网络能够从全局感受野上提取图像特征来描述图像,但归根结底只是建模了图像的空间特征信息而没有建模通道之间的特征信息,整个特征图的各区域均被平等对待。然而,在猪只遮挡重叠、光线不足、皮毛颜色相似等实际猪场生产场景下,原始YOLO v5n算法难以检测到被遮挡的猪只,或者容易漏检一些边缘区域的猪只。在目标检测领域中每一个目标都被周围背景所包围,目标物体周围的环境有着丰富的上下文信息,这可以作为网络判断目标类别和定位的重要辅助信息[24]。通常在实际猪场生产图中,通过对目标区域的特征进行加权能使其更有效地定位到待检测猪只,提高网络性能[25]。SE-Net通道注意力模块基于特征图上通道间的相关关系,网络通过损失函数去学习权重,强化有效特征,弱化低效或无效特征,提高了特征图的表现能力,从而提高了模型识别精度,能够在光线不足、密集遮挡的情况下有效检测出目标物体[26-27]。
针对YOLO v5n目标检测算法存在边界框定位不够准确导致难以区分重叠物体、鲁棒性差等问题,本文在主干特征提取网络中加入SE-Net(Squeeze-and-Excitation networks)通道注意力模块来改进算法,在特征图的通道间建立特征映射,使网络自动学习全局特征信息并突出重要的特征信息,同时弱化对当前任务无关的特征信息,使模型更专注于训练遮挡对象的目的。
SE-Net结构单元图如图6所示,SE-Net模块具体含括3个操作:压缩(Squeeze)、激励(Excitation)和缩放(Scale)。首先对原始输入进行全局平均池化操作(即压缩过程)将原始特征层维度H×W×C压缩为1×1×C,使得感受野更大,得到每个通道的全局特征。然后用两个全连接层(第一个全连接层用于降低维度,另一个还原为原始的维度)融合各特征通道的特征图信息。再使用Sigmoid函数对权值进行归一化。最后是缩放操作,将激励操作后输出的权重映射为一组特征通道的权重,然后与原始特征图的特征相乘加权,实现对原始特征在通道维度上的特征重标定。网络通过加强训练SE-Net模块学习后的特征,提高了猪只遮挡的通道权重,指导模型更侧重学习猪只间遮挡的特征信息,进而提升模型在猪只遮挡场景下的检测性能[28]。
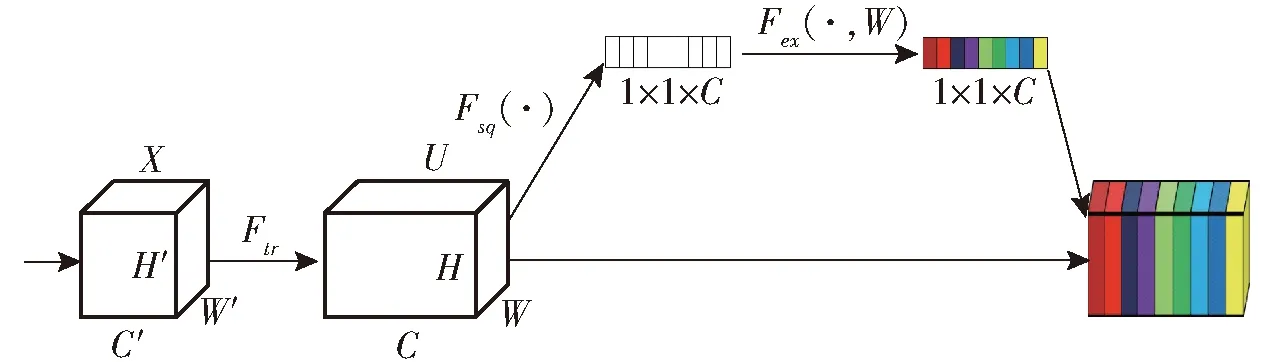
图6 SE-Net结构单元图Fig.6 SE-Net block
如图7所示,本文将SE-Net通道注意力模块分别加入到原始YOLO v5n主干特征提取网络Backbone的C3卷积模块后(图7a)和颈部网络Neck的C3卷积模块后(图7b)。两种添加方法的检测结果对比如图8所示:图8a为原始YOLO v5n检测效果图,漏检的情况比较严重;图8b为在主干特征提取网络中加入SE-Net模块,图8c为在颈部网络中加入SE-Net模块,加入SE-Net注意力模块后漏检猪只数量相对较小,但在主干特征提取网络中引入相比于在颈部网络中能够更好地检测到遮挡猪只。因此本文采用在YOLO v5n主干特征提取网络引入SE-Net通道注意力模块。

图7 引入SE-Net通道注意力模块Fig.7 Introducing SE-Net channel attention module
2.3 多尺度特征检测
原始YOLO v5n网络使用3种类型的输出特征图来检测不同尺寸的物体,当输入图像尺寸为1 280像素×1 280像素时,其对应的3种检测尺度分别为40像素×40像素、80像素×80像素、160像素×160像素,用来检测大、中、小目标,其感受野大小依次递减。在现有的3个尺度特征图上进行猪只检测,对于某些尺度超大的猪只,感受野最大的特征图可能仍然提取不到有效的高级语义信息,相反,对于某些尺度超小的猪只,感受野最小的特征图也会丢失其轮廓和位置信息[29]。在实际猪场应用场景中,猪只姿态各式各样,猪只间相互拥挤遮挡,而且,由于摄像头安装位置不同,其拍摄的猪只体积、体形也有较大的差异。例如,受限于猪场的高度,范金树实验猪场的摄像头拍摄出猪只形状既存在超大尺度的猪只,也存在超小尺度的猪只,所以映射到图像中的猪只也有多种不同尺度。为了应对复杂密集遮挡的实际生产猪场场景,得到更加丰富全面的特征信息,本文在原有3个不同尺度的检测层的基础上,增加一个超小尺度的检测层[30]。选择此尺度的检测层对于超小的猪只来说,能够保留下有效语义信息的可能性更大;另外,对尺寸超大的猪只来说,能够提取到更高层次的语义信息,同时也包含了更多的轮廓信息和位置信息,将此类特征图融合之后会使得融合之后的特征信息更加丰富全面,从而有利于提高猪只定位的准确率[29]。
本文在原始YOLO v5n的主干网络中加入SE-Net模块的基础上,在32倍下采样后继续增加一次下采样得到20×20的特征图,同时颈部Neck网络相应增加一次上采样,与主干网络的第8层拼接(原始颈部网络只经过两次上采样,分别与主干网络的第6层和第4层拼接)。改进后的YOLO v5n颈部网络经过3次上采样后再进行下采样操作。即主干网络在32倍下采样后继续一次2倍下采样得到20×20的特征尺寸图。同时,在颈部网络增加一次2倍上采样,然后经过8、16、32倍下采样分别得到160×160、80×80、40×40尺度的检测层特征图。再进行64倍的下采样得到20×20尺度的检测层特征图。
经过改进后的YOLO v5n网络(图9)存在4个检测层,加深了网络的深度,进一步提高模型的表达能力,使得模型能够提取到更高层次更丰富的语义信息,帮助模型在复杂猪舍场景下提取多尺度特征信息,将复杂的目标区分开来,提升模型的检测性能[31]。在猪只遮挡密集场景下YOLO v5n网络改进前后的检测效果如图10所示,左边为原始YOLO v5n检测结果,右边为增加一个检测层后的检测结果。由图10可以看出,改进后的模型在猪只挤靠相互遮挡的场景下,仍能更好地检测识别出被大面积遮挡的猪只,且也可检测出图10d中边缘的猪只,而原始YOLO v5n模型并没有检测到被大面积遮挡的猪只。由此可见添加一个检测层后的模型在复杂遮挡场景下的检测效果更佳。
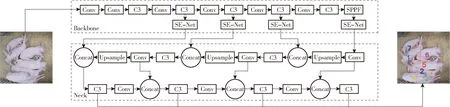
图9 添加一个检测层后的YOLO v5n网络结构Fig.9 YOLO v5n network structure after adding a detection layer

图10 增加检测层前后效果对比Fig.10 Comparison of effects before and after adding a detection layer
2.4 改进边界框损失函数
根据2.1节,YOLO v5n的边界框(Bounding box)采用GIoU Loss作为损失函数,在IoU的基础上,解决了边界框不重合的问题,但当边界框与真实框有包含情况时(如图11所示,绿色和红色分别表示目标框和预测框),GIoU退变为IoU,导致难以分辨两框的相对位置关系,此时GIoU的优势消失[32]。因此,GIoU不能准确反映两个边界框之间的重叠关系,也不能给出一个边界框被另一个边界框包围时的优化方向[33]。文献[34]提出的CIoU是在DIoU的基础上,不仅考虑边界框的重叠区域和中心点的距离,还权衡了边界框的纵横比,弥补了GIoU损失函数的不足。因此,本文采用更优的CIoU Loss测量方法,包括重合面积、中心距离和宽高比3个测量维度,具有更快的收敛速度和更佳的性能。CIoU Loss函数定义为

图11 边界框包含检测目标的示例Fig.11 Schematic of a bounding box containing the detection target
(1)
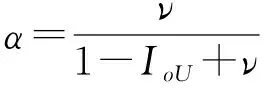
(2)
(3)
式中b——边界框中心点坐标
b(gt)——真实框中心点坐标
ρ——两个中心点间的欧氏距离
IoU——交并比
c——边界框和真实框最小外接矩形的对角线距离
w、h——边界框的宽、高
w(gt)、h(gt)——真实框的宽、高
α——权重系数
ν——宽高比度量函数
2.5 DIoU-NMS代替加权NMS
在经典的NMS中,对同一类别中所有边界框的得分排序,选择分数最高的边界框,然后计算出其与剩余的边界框的IoU值,并将大于阈值的边界框全部过滤掉[35]。但是在实际猪场中,猪群的重叠相互遮挡,当几头猪相互靠近时,IoU值变大,若采用加权NMS,那么其筛选结果可能只留下一个边界框,从而可能致使多头猪只漏检。采用DIoU-NMS算法[36]代替原始的加权NMS,同时考虑了重叠区域和两个边界框的中心点距离,即如果出现两框间的IoU值较大,且中心距离也较大时,DIoU-NMS将此类情况视为是两个目标的边界框,不会被筛选,从而有效提高检测精度,降低漏检率[32],DIoU-NMS的更新公式为
(4)
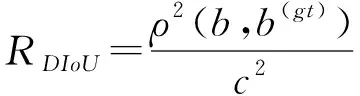
(5)
式中si——分类得分ε——NMS的阈值
M——最高分类得分的检测框
Bi——其余初始检测框
如图12所示,当两头猪只互相粘连时,对应的两个边界框重叠区域较大,但它们的中心点距离较远,若采用DIoU-NMS,因为其不仅考虑到两框的重合部分,还综合权衡了两框中心点的欧氏距离,将两个中心点距离较远的框可以看成是不同猪只目标产生的,所以,在筛选边界框时保留这类边界框,不会将其删除,从而降低了猪只漏检率。因此,本文算法选用DIoU-NMS替换加权的NMS是切实有效的。

图12 DIoU-NMS示意图Fig.12 Schematic of DIoU-NMS
3 实验结果与分析
3.1 实验设置
本次实验用Pytorch框架搭建,操作平台为64位Windows 10,GPU模式(GPU型号为Nvidia RTX3070),显存8GB。本文模型训练的超参数设置如表4所示。

表4 训练参数设置Tab.4 Parameters setting for training procedure
3.2 评估指标
采用准确率、召回率、平均精度(AP)作为衡量目标检测算法性能的指标。
针对深度学习的计数研究常使用平均绝对误差(Mean absolute error, MAE)和均方根误差(Root mean square error, RMSE)。一般情况下,MAE越小,预测的准确率就越高,RMSE越小,鲁棒性也越好。本文选取上述两个指标作为猪只盘点模型的评估指标。
另外,加入漏检率作为模型性能偏差和变化的辅助指标。
3.3 消融实验
为了更直观地评估改进技术对模型性能的影响,本文进行了消融实验。如表5所示,以未做任何改进的原始YOLO v5n为基准,+表示模块混合改进,分别训练划分好的6组实验。如表5所示,在本文的测试集中原始YOLO v5n的MAE、RMSE、AP和漏检率分别为0.682、1.21和97.71%和4.06%。以此为基线,每一处改进后各评估指标都有所提升。由表5可知,在主干特征提取网络中引入SE-Net模块,其MAE、RMSE以及漏检率均比添加在颈部网络中低,分别低0.095、0.38以及1.34个百分点,AP也提高0.67个百分点。无论是原始YOLO v5n,还是增加一个检测层后,在主干特征提取网络加入注意力机制模块比在颈部网络加入注意力机制模块,MAE、RMSE、AP和漏检率均比未增加相应模块有所提升。而增加检测层和在主干特征提取网络中引入SE-Net模块,MAE、RMSE以及漏检率也比基线分别降低0.509、0.708以及3.02个百分点,AP达到99.39%,较基线提高1.62个百分点。其次,结合表3可知,改进后的模型的参数量是YOLO v5x模型的1/46,而且两者的AP很相近。综合而言,增加一个检测层与在主干特征提取网络加入注意力机制模块的组合改进效果最佳,虽然模型参数量相对比较大,但其在复杂遮挡场景下的检测效果比其他组合更好。

表5 不同模型的消融实验Tab.5 Ablation experiment of different modules
3.4 不同盘点算法对比
为更好地分析验证本文算法的性能,将本文改进后YOLO v5n与YOLO v4[37]、YOLO X[38]、Faster R-CNN[39]、专门修改用于猪计数的CCNN[9]、基于多尺度感知的猪计数网络PCN[10]、基于关键点检测和STRF的猪计数网络[12]和中心集群计数网络CClusnet[40]的猪只计数网络进行比较。其中,YOLO v4、YOLO X和Faster R-CNN网络均采用本文的猪只盘点数据集进行训练和测试;而基于多尺度感知的猪计数网络PCN、专门修改用于猪计数的CCNN、中心集群计数网络CClusnet以及基于关键点检测和STRF的猪计数网络则引用文献中的相关实验结果。实验结果如表6所示。
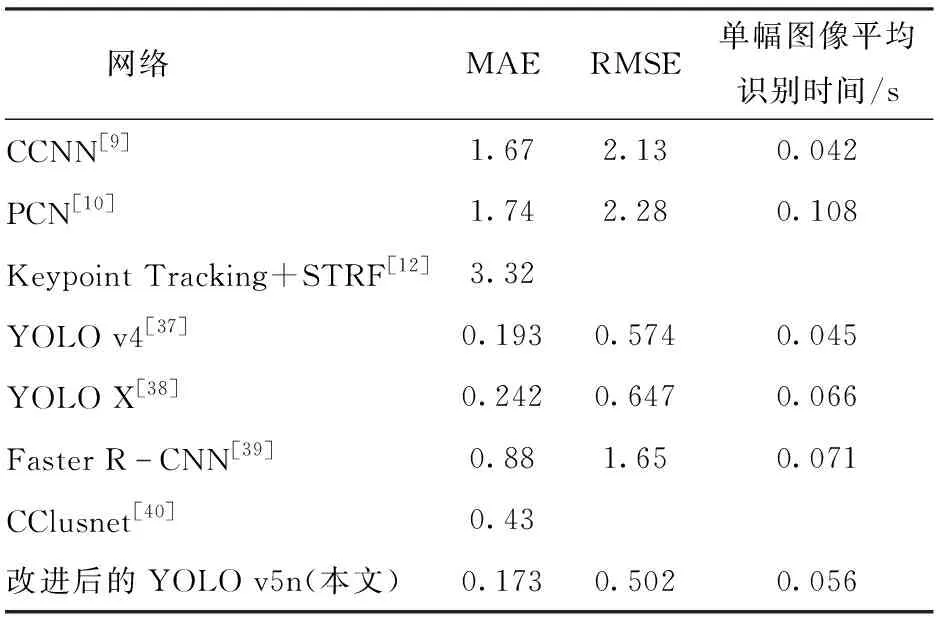
表6 不同猪只盘点算法性能比较Tab.6 Performance comparison of different pig counting algorithms
由表6可知,CCNN、CClusnet、YOLO v4、YOLO X和Faster R-CNN的MAE分别为1.67、0.43、0.193、0.242和0.88,说明这5种计数方法在一定程度上能够处理遮挡问题。虽然CCNN计数方法的单幅图像平均识别时间最低(0.042 s),本文改进后的YOLO v5n网络模型与其只差0.014 s,但本文的计数网络准确性和鲁棒性均优于其他计数网络。这是因为本文的计数网络在处理不同场景时,如光照变化、遮挡和重叠,通过增加注意力机制和多尺度特征检测,减少了猪只漏检多检情况,且不需要控制特定的环境,速度和精度均能达到实际猪场的猪只计数要求。
3.5 实验结果分析
猪只遮挡是造成猪只盘点精度低的主要原因之一。当猪只严重拥挤相互遮挡时,猪只目标轮廓信息缺失。图13为YOLO v5n改进前后的检测结果,左侧为原始YOLO v5n检测图,右侧为改进后的YOLO v5n检测效果图。图13a可知,改进后的YOLO v5n对于边缘小目标的检测效果有一定的提升,图13a中改进后的模型能够检测出原始模型漏检的目标;图13b、13c为不同场景下遮挡重叠的图像。通过观察可知,原始模型对于猪只相互遮挡密集或者边缘小目标模糊的图像漏检相对严重,而改进后的模型依旧可以准确检测到上述复杂情景下的猪只目标。

图13 检测结果对比Fig.13 Comparison of test results
另外,光照也是影响猪只盘点精度的原因之一。在实际生产应用中,猪场可能会突然遇到短暂光照骤变等噪声致使出现猪只阴影[41],或者夜间光线不足导致猪只目标轮廓特别不清晰。尽管YOLO v5n算法能在一定程度上尽量减少光照影响,但是猪只阴影、目标轮廓不清晰还是会造成算法的误检或者漏检。如图13d所示,右侧围栏处的两头猪只间形成了阴影,加之光线暗等原因导致原始YOLO v5n算法将中间的猪只阴影识别为一头猪只,而改进后的算法能够准确检测出阴影处的所有猪只。如 图13e 所示,图中绿框的猪只因光线不足,且被其他猪只夹在中间,猪只目标轮廓不清晰致使原始 YOLO v5n 算法漏检该猪只,但改进后的模型能够检测出原始模型因阴影漏检的猪只。
综上所述,改进的YOLO v5n算法对复杂场景中的猪只图像盘点鲁棒性更强,这表明改进后的网络在不同遮挡重叠目标场景下泛化能力有所提升。但目前本文算法在应对特别严重遮挡目标导致目标轮廓的特征信息不明显的情况时会存在一定程度的漏检。
4 结束语
为了改进现有的猪只盘点算法在遮挡、体型变化或者光线较暗等场景下的不足,提出并实现了一种改进的YOLO v5n猪只盘点算法。该算法针对复杂场景下的猪只盘点问题提出了在主干特征提取网络中加入SE-Net注意力模块,从而提升了模型对于复杂密集遮挡、光照不足等场景下的鲁棒性;增加了一个尺度的检测层,加深网络的深度,进一步提取多尺度特征信息将复杂的目标区分开来,提升模型的检测性能;改进边界框损失函数和NMS,以此提高模型在复杂遮挡场景下的泛化能力。消融实验结果表明,改进的YOLO v5n模型在本文测试集中的检测精度较原YOLO v5n模型得到改善,其MAE、RMSE以及漏检率分别比原YOLO v5n降低0.509、0.708以及3.02个百分点,平均精度提高1.62个百分点,其AP为99.39%。对比实验结果表明,与Faster R-CNN、CCNN和PCN猪只盘点算法相比,本文算法的MAE和RMSE分别为0.173和0.502,MAE比其他3种算法分别减少0.707、1.497和1.567,RMSE比其他3种算法分别降低1.148、1.628和1.778。在遮挡拥挤、光照不良等复杂场景下,本文提出的YOLO v5n算法减少了猪只漏检的情况,能得到理想的计数结果,具备较好的准确性和鲁棒性;模型的单幅图像识别时间仅为0.056 s,比大多数猪只盘点算法快,能够满足实际应用场景的实时性要求,为后续应用到边缘设备(如猪只盘点仪等)提供了算法支撑。
猜你喜欢
猪业科学(2022年11期)2022-12-17 08:43:54
中国畜禽种业(2020年4期)2020-12-16 13:52:34
今日农业(2020年17期)2020-12-15 12:34:28
动漫星空(2020年10期)2020-10-29 06:57:00
河南畜牧兽医(2020年21期)2020-01-10 00:20:08
猪业科学(2018年5期)2018-07-17 05:56:18
饲料与畜牧(规模养猪)(2016年12期)2017-01-18 02:09:35
饲料与畜牧(规模养猪)(2016年5期)2016-12-01 03:48:40
饲料与畜牧(规模养猪)(2016年5期)2016-12-01 03:48:39
新农业(2016年13期)2016-08-16 12:12:41
