
融合字形特征的多任务老挝语文字识别后纠错
2023-03-06 09:58杨志婥琪周兰江周蕾越
小型微型计算机系统 2023年3期
杨志婥琪,周兰江,周蕾越
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 津桥学院 电子与信息工程学院,昆明 650106)
1 引 言
老挝语的光学字符识别(Optical Character Recognition,OCR)能缓解老挝语语料匮乏的问题,但目前老挝语文字识别技术尚在起步阶段,老挝语复杂的字符结构特征及图片背景复杂、文字模糊等原因导致老挝文字识别准确率难以提升,识别结果存在错误使得识别后的老挝文本不能直接用于自然语言处理基础任务.因此,对老挝文字识别后的文本进行纠错以减少错误能有效提高老挝文字识别准确率,以及提升老挝文字识别结果在其他任务上的可利用性.
在先前的老挝文字识别研究中,针对老挝语字符结构复杂导致识别困难的问题进行了相关研究,提升了识别准确率,但识别结果仍存在错误(1)http://kns.cnki.net/kcms/detail/21.1106.TP.20210420.1049.008.html..本文针对先前的老挝文字识别结果进行分析,发现识别结果的错误主要集中在相似字符误识别和字符粘连、断裂导致的识别错误上.因此,本文在老挝语OCR后处理研究中需要解决上述问题.
目前,深度学习模型已被应用到OCR后纠错的研究中,文献[1]中来自荷兰阿姆斯特丹大学的团队提出了OCR后基于字符级seq2seq模型的英文错误校正模型,多层LSTM作为解码器,将校正任务形式化为从拼写错误到目标拼写的翻译,在ICDAR 2019 OCR后文本校正竞赛中得分最高.由于老挝语是词间无分隔语言,故本文同样基于字符级别建模以避免分词造成的错误,且序列到序列的模型架构针对本文数据集中错误语句和目标语句存在长度不等的情况是适用的,使用长短期记忆网络(Long Short-Term Memory,LSTM)建模也能更好地获取老挝长文本的语义信息.但将校正任务形式化为翻译任务,模型容易产生一定程度的误纠,因此借鉴Qiu等人[2]的方法,将语言模型和seq2seq模型结合,以修正深度模型产生的错误.此外,谢海华等人[3]采用音近、形近字判断等多种筛选纠正结果的方法,并针对一些典型且特殊的错误,例如“的地得”误用,采取了数据增强方法.同样地,针对老挝语OCR结果中的高频错误本文生成了相应的数据扩充训练集,以数据增强方式训练模型.叶俊民等人[4]基于预训练语言表征模型(Bidirectional Encoder Representation from Transformers,BERT)建模得到文本的多种语义表示来完成对错误的修正,并将错误检测与错误修正的损失作为整个模型的损失,以此提升模型性能.遗憾的是,BERT模型尚不支持老挝语(2)https://github.com/google-research/bert/blob/master/multilingual.md,但借鉴该方法,本文引入多任务学习的方式,以辅任务的损失值提升模型训练效果.
本文借鉴前人研究,针对老挝文字识别结果中存在的错误,构建了以seq2seq架构为基础的多任务老挝语文字识别后文本纠错模型.首先,本文将融合了字形分类特征的老挝文字识别结果作为编码端输入,对采用BiLSTM网络以及多尺度卷积网络提取老挝文本的上下文语义表示,并进行线性组合,再通过带有注意力机制的LSTM网络对上下文向量进行解码,对解码端预测序列与原始文本序列用n-gram语言模型比较概率得分,并将概率更大的序列作为最终的文本纠错结果.同时,本文增加辅助任务以检测输入字符序列中的错误字符,通过共享参数的形式优化文本纠错主任务,并以损失值增强模型训练效果.
本文主要贡献如下:
1)针对识别后老挝相似字符替换错误的纠正,本文对老挝字符进行字形分类,并将字形特征融入模型,提高了模型对相似字符替换错误纠正的能力.
2)针对识别后老挝字符断裂、粘连导致的插入、删除错误的纠正,本文采用多尺度CNN网络对编码器进行补充以提升模型对字符插入、删除错误的纠正能力.
3)针对模型的误纠问题,本文引入多任务学习,以错误检测的辅任务优化文本纠错主任务,并且对模型的预测序列与原始文本序列使用语言模型进行排序来决定最佳候选,以改善模型的误纠问题.同时,为防止模型过拟合,本文通过老挝相似字符表及高频粘连、断裂错误字符对进行数据增强工作以扩充训练数据集.
2 相关工作
近年来,针对OCR后纠错和与其类似的文本拼写纠错主要有基于统计规则的方法和基于深度学习模型的方法.
基于统计规则的方法主要分为错误检测、错误纠正两步.通常是使用混淆集定位错误位置,并将混淆集作为纠正候选集,通过语言模型计算经不同纠正候选替换后的句子概率,得到使句子概率最高的词,即为纠正词.文献[5]对蒙古文字形编码和国际标准编码一一对应整理成编码转换词典以实现对蒙古文字识别的后处理;文献[6]通过改进的TF-IDF算法对多候选字列表进行权重生成并排序,再利用汉字知识图谱辅助对OCR识别时的错误规则进行预测;Bassil等人[7]基于Google的在线拼写建议来检测和校正英文OCR非单词和真实词错误;Del等人[8]基于频率统计学上的显著差异和定性分析产生错误列表,并将纠错规则定义为正则表达式以匹配错误,并将其替换为正确形式;Metwally等人[9]将OCR后文本与词典中的单词进行匹配以生成完整的单词,进一步提高单词识别率;ICDAR 2019 OCR后文本校正竞赛[1]中来自焦特布尔的团队提出采用基于字典的方法,基于编辑距离生成一组候选有效词,候选词的排名基于通过字符n-gram混淆矩阵捕获的错误模型给出的可能性;Dhivya等人[10]所提出的工作支持向量机分类器从中识别文本,再结合n-grams后处理算法用于纠正识别的药片剂文本中的替换、插入和删除错误.
基于深度学习的方法已成为目前主流方法.Bao等人[11]使用类似的发音,形状和语义混淆集以提出的基于块的解码方法,并采用全局优化来选择最佳矫正,实验证实该方法对OCR误差校正是有效的,但上述方法需要较大的混淆词典或者音节词典,所需人工工作量较大.文献[1]中来自蒙纳士研究院的团队针对英文真正的单词错误以及非单词错误,在解码器输出中使用光束搜索的字符级注意模型;Etoori等人[12]提出基于字符表示的具有双向RNN编码器和注意解码器的序列到序列注意模型针对资源稀缺语言的自动拼写矫正;Chollampatt等人[13]同样采用编码器-解码器架构,提出多层卷积网络及门控线性单元(GLU)进行编码和解码的神经网络模型,以实现文本的自动校正;Guo等人[14]针对语音识别器做出的错误,提出的纠错模型由编码器中的3个双向LSTM层和解码器中的3个单向LSTM层组成,将残差连接添加到编码器和解码器的第3层,并引入四头注意力机制;张佳宁等人[15]提出一种基于word2vcc的语音识别后文本纠错方法,利用word2vcc结合语境核心词生成关键词,并使用拼音混淆集结合语义和语境信息对可能出错的词进行纠错.
基于统计规则的方法速度较慢,语言模型所需混淆集、词典、规则的构建需要花费大量人工工作量,尤其在通用领域使用的混淆集需要涵盖的内容甚多,这是极其困难的任务,且老挝语其本就存在大量相似字符,若构建其混淆词表数量之大不可估计,但语言模型本身对错误定位及错误纠正任务的效果不容忽视.而深度学习方法与基于统计规则的方法相比,无需人工提取特征,具有更好的泛化能力,因此,本文采用深度模型对老挝OCR后文本进行纠错,并结合语言模型对深度模型输出结果进行处理.
3 老挝语OCR后文本错误及字形特征分析
3.1 老挝语OCR后文本错误
本文使用先前研究中基于CRNN改进的老挝文字识别模型作为印刷体老挝文字图片识别的工具.通过对识别结果的分析,发现识别后的文本错误主要集中在3类:相似字符替换错误,字符断裂、粘连导致的非相似字符替换错误及字符插入、删除错误,其中,相似字符替换错误占主要的比重.


表1 错误示例Table 1 Some examples of errors
因此,本文统计出了高频出现的字符断裂、粘连的字符对,并采用Wang等人[16]的方法获取老挝语相似字符混淆集,方法流程如图1所示.如:随机模糊老挝字符“”的上部,再通过OCR识别,字符“”即为模糊处理后的OCR错误结果候选,即可将“”加入到字符“”的相似字符混淆集中.该方法通过OCR识别得到的错误候选集合是真正在形状上相似的字符混淆集,适用于本文针对OCR后纠错问题的研究.
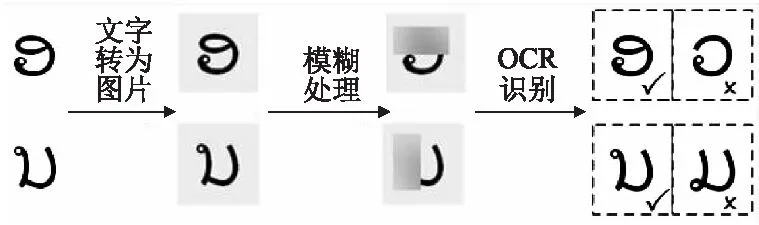
图1 相似字符混淆集获取流程Fig.1 Similar character confusion set acquisition process
最终将统计得到的相似字符表和高频出现的断裂、粘连的字符对表用于数据增强,使模型针对这两类错误进行训练,以提升模型训练效果,部分示例如表2所示.
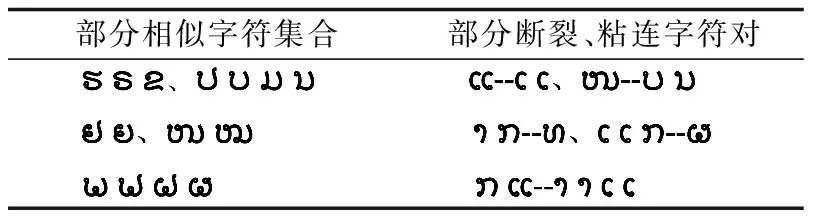
表2 部分相似字符及断裂、粘连字符对示例Table 2 Examples of some similar characters, broken and glued character pairs
3.2 老挝语的字形特征
老挝文字中存在大量相似字符,导致OCR结果中产生了大量的相似字符替换错误,在对该错误进行纠正时,模型对纠正候选的选择应倾向于当前字符的相似字符集合.因此,本文对老挝文字中相似字符的字形进行了分析,发现老挝相似字符之间往往具有相同的开口方向,如图2所示.
故本文根据老挝相似字符开口方向一致的字形特点,将老挝字符根据开口方向分为10个类别,示例如表3所示.

表3 部分字形分类示例Table 3 Some examples of glyph classification
在构建本文的纠错模型时,先对需要输入模型的待纠错老挝文本添加字形分类标签Si∈{a,b,c,…,j},再将老挝文本字符序列C=(C1,C2,…,Cn)与字形分类标签序列S=(S1,S2,…,Sn)在Embedding层进行拼接,如式(1)所示.将得到的融合字形特征的字符嵌入表示V∈Rn×(dc+ds)=(V1,V2,…,Vn)输入到编码器中,使模型更好地学习老挝相似字符之间的相关信息,增大模型预测正确的概率,以提升模型对相似字符替换错误的纠正能力.
Vi=concat(Ci,Si)
(1)
4 融合字形特征的多任务老挝语文字识别后纠错
4.1 模型结构
本文构建的融合字形特征的多任务老挝语文字识别后纠错模型基于seq2seq架构进行改进,具体结构如下:1)输入层:待纠错老挝文本序列;2)预处理层:对待纠错老挝文本进行字形类别标记;3)Embedding层:将输入的文本序列及字形类别标签序列转换为字符向量表示,并在主任务中进行拼接,生成带有老挝语特征的字符向量;4)编码层:采用BiLSTM网络及多尺度CNN网络分别对字符特征向量进行编码,生成隐藏状态向量后组合输入解码层;5)解码层:采用带有Luong注意力机制的单向LSTM网络,传递编码层的隐藏信息,并用softmax函数预测字符序列的概率分布;6)语言模型处理层:通过Kenlm语言模型计算预测字符序列和原始输入字符序列的概率,选取概率更大的一个作为模型最终的纠错结果;7)多任务学习:在错误检测辅任务中,模型对带有错误标记的待纠错文本序列进行有监督训练,最后得到错误标记的预测序列,辅任务与文本纠错主任务共享网络结构,同时以参数共享方式与主任务共享语义信息,并结合辅助任务的损失函数以提升模型性能.模型结构图如图3所示.
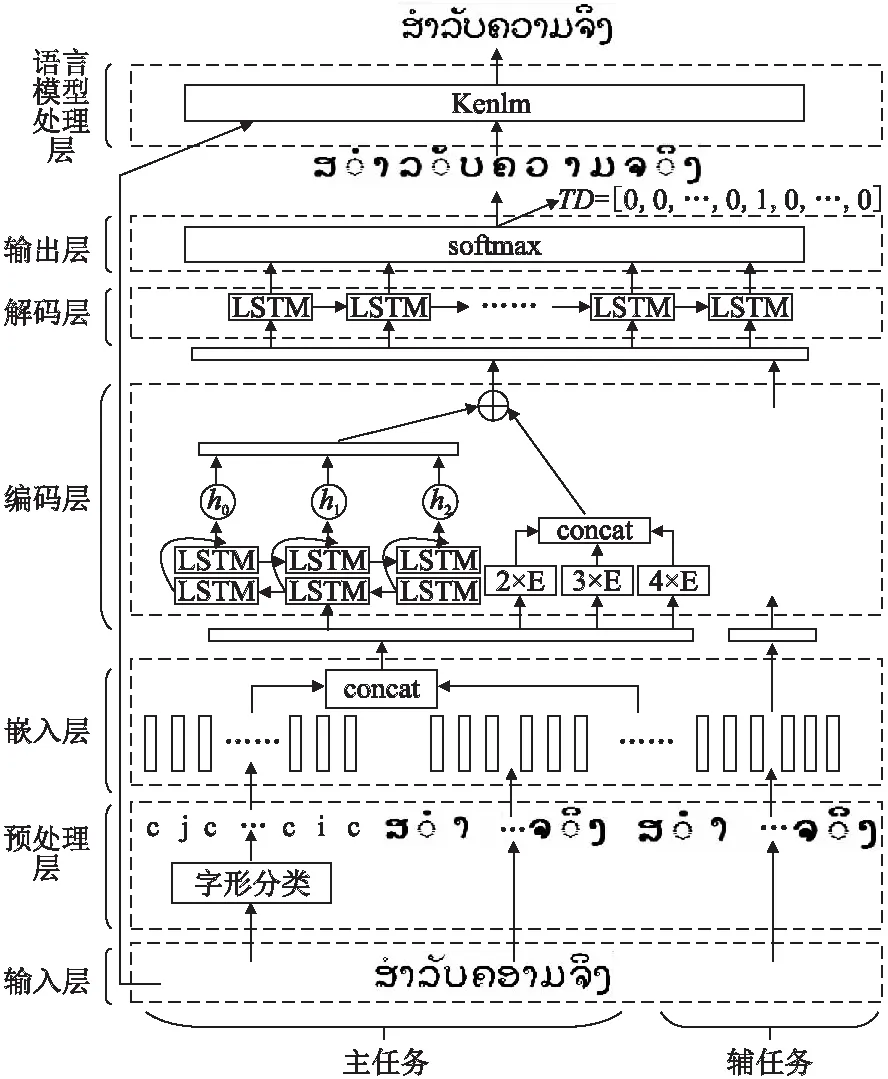
图3 模型结构图Fig.3 Model structure diagram
4.2 seq2seq模型架构
seq2seq模型[17]在各种任务中享有巨大的成功,针对其在输入输出序列映射任务中显示出很大的潜力,如机器翻译.这种架构不要求输入输出序列具有相同的长度,且设置似乎自然地符合映射输入中的噪声,以使校正预测可以被视为不同的语言,故文本拼写纠错任务可以被视为翻译任务,将可能含有错误的序列X转换为错误更少或不含错误的序列Y,使得P(Y|X)概率最大化,编码器捕获数据中更高级的语义表示,而解码器将相应的映射输出到目标序列.
4.3 编码层
4.3.1 BiLSTM编码
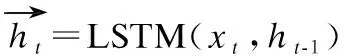
4.3.2 多尺度CNN编码
在文本拼写纠错的研究中,CNN借鉴N-gram语言模型的思想,通过提取相邻n个老挝字符组合形成的局部依赖信息,将提取的局部特征综合为更高级的全局信息,从而得到文本序列的全局语义表示[13].根据这种思想,本文借鉴文献[19]中多尺度CNN提取不同尺度的局部老挝文本特征的方法,采用多尺度卷积网络以获取更优质的老挝语义信息.多尺度CNN结构如图4所示.
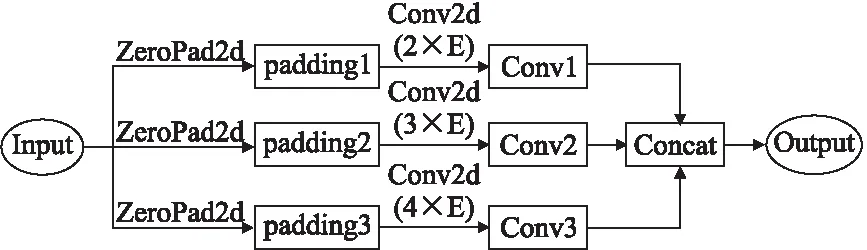
图4 多尺度CNN结构Fig.4 Multi-scale CNN structure
由于老挝字符与字符之间的相关性有所不同,且OCR识别后存在字符断裂、粘连导致的插入删除错误,该错误主要集中在连续的2,3或4个字符上,因此本文采用2×E,3×E,4×E(E表示字符嵌入的维度)3个不同尺寸的卷积核对待纠错文本进行编码,纵向学习文本内部更深层次的特征以及不同尺度相应的局部特征.由于不同尺度的卷积核会导致卷积层输出的特征向量数量不一致,因此先对输入的老挝字符向量左端(卷积操作从左至右,步长为1)进行padding操作后再输入到不同尺度卷积核的CNN网络中,最后将多个不同尺寸卷积输出的老挝语义向量拼接得到多尺度卷积编码的输出向量C=concat(C1,C2,C3).其中,每个尺寸卷积输出的语义向量为Ct=[Ct1,Ct2,…,Ctn-l+1],n表示字符序列的长度,l表示卷积核大小,即在一次卷积操作中,对连续l个老挝字符进行卷积运算:Cti=f(W·Xi:i-l+1+b),f表示ReLU激活函数,W∈RlE为卷积核参数矩阵,X=[X1,X2,…,Xn]为输入的老挝字符序列表示,X∈Rn×E.同时,本文在老挝句子的初始Embedding表示之后添加Dropout,以防止过度拟合.
最终对BiLSTM网络和多尺度CNN输出的状态向量H和C进行线性组合,如式(2)所示,其中,m=n=1,并将得到的老挝语义表示向量F输入解码层.
F=m·H+n·C
(2)
4.4 解码层
seq2seq结构中,编码生成的老挝语义向量c会传递给解码的每一时刻,若传递给每一时刻的语义向量都是同一个c,这显然不合理,句子中的每个老挝字符对解码预测某个字符的影响是不同的,因此,解码中每个时刻接收到的老挝语义向量cj都应该是不同的,故本文引入Luong 注意力机制[20],使用编码层和解码层的隐层状态共同来计算每个时刻的影响程度.具体计算过程如式(3)~式(8)所示.
(3)
(4)
sj=tanh(W[sj-1,yj-1])
(5)
(6)
(7)
(8)
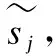
4.5 语言模型处理层
使用语言模型计算句子概率可用来衡量模型预测的文本正确的概率,即预测文本概率越大,文本为正确的概率越大.因此,本文使用n-gram语言模型计算解码输出的老挝字符序列与原始文本序列的概率值,选出两者中概率最大者.该召回机制能够有效处理正确句子经过深度模型之后反而变成错误句子的现象,并有效地把原本不含错误的老挝文本的误判消除,较大程度降低了模型的误纠率.其中,本文使用Kenlm工具(3)https://kheafield.com/code/kenlm/,对拆分成字符序列的老挝正确文本进行训练,构建了4-gram语言模型.句子概率P(S)的计算公式如式(9)所示,P(Cn|C1…Cn-1)表示老挝句子S在前n-1个字符为C1…Cn-1时,第n个字符为Cn的概率.
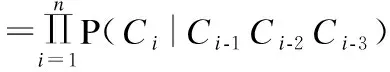
(9)
4.6 多任务学习
端到端纠错任务中只能通过神经网络的学习在解码中对可能出错的字符进行推断,缺少可解释性且其检错效果不如直接进行错误检测任务的效果好.故本文借鉴文献[4]中错误检测与错误修正统一的思路,引入多任务学习架构,在解码层的softmax预测中,一方面预测纠错后的老挝字符序列,另一方面预测待纠错文本序列的错误标记序列.本文将辅任务看作预测文本序列中错误字符的序列标注任务,并将待纠错老挝文本与其对应的错误标记序列作为辅任务训练数据,主任务训练数据则是待纠错老挝文本与其对应的正确老挝文本.两个任务均通过本文模型中相同的网络结构进行训练,共享老挝字符嵌入矩阵、编码层、解码端注意力LSTM层的参数,因此,辅任务学习到的老挝文本特征会以参数形式与主任务共享,同时,通过控制辅任务损失函数的权重来控制辅任务共享参数的重要性,以此界定主辅任务,并通过辅任务损失函数融合字符错误检测信息,优化主任务模型性能,提高了主任务纠错的准确率,同时也降低了其误纠率.
针对两个任务的解码本文采用交叉熵损失函数来计算损失值,如式(10)~式(12)所示.
(10)
(11)
L=L1+λL2
(12)
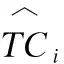
5 实 验
5.1 数据准备及模型设置
本文老挝文字识别后纠错模型的训练和测试包括两部分数据.用来识别的老挝语文字图片共35370张(32×840像素)以及识别工具(基于CRNN改进的老挝文字识别模型)均来自先前工作.包括老挝印刷体PDF文档截取的10700张印刷体老挝文字图片,以及对老挝短句(10~60个老挝字符)进行图像增强工作后批量生成的24670张老挝文字图片.对上述老挝文字图片进行文字识别,得到35370个老挝句子,去除过长的老挝句子(字符数超过70)以及含有错误字符过多的句子(包含4个错误及以上),最终得到不含错误的句子有5017个,及包含错误字符数1~3个的句子有10753个,共同组成第一部分数据.
对错误文本进行错误分析,并对错误字符进行分类统计,如表4所示.其中,有部分老挝句子同时包含字符替换错误和字符插入、删除错误.

表4 错误类型占比统计Table 4 Statistics on the proportion of error types
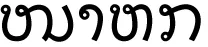
本文将上述第1部分和第2部分数据集作为源语句,并与其对应的正确老挝句子形成源-目标句对,再将第1部分数据中的错误语句和正确语句一同按9:1划分为训练集和测试集,同时,也将第2部分数据扩充到训练集中,使模型能在充足的数据集中学习数据特征,并以增强训练的方式提升模型对特定错误的纠正能力.数据集划分如表5所示.
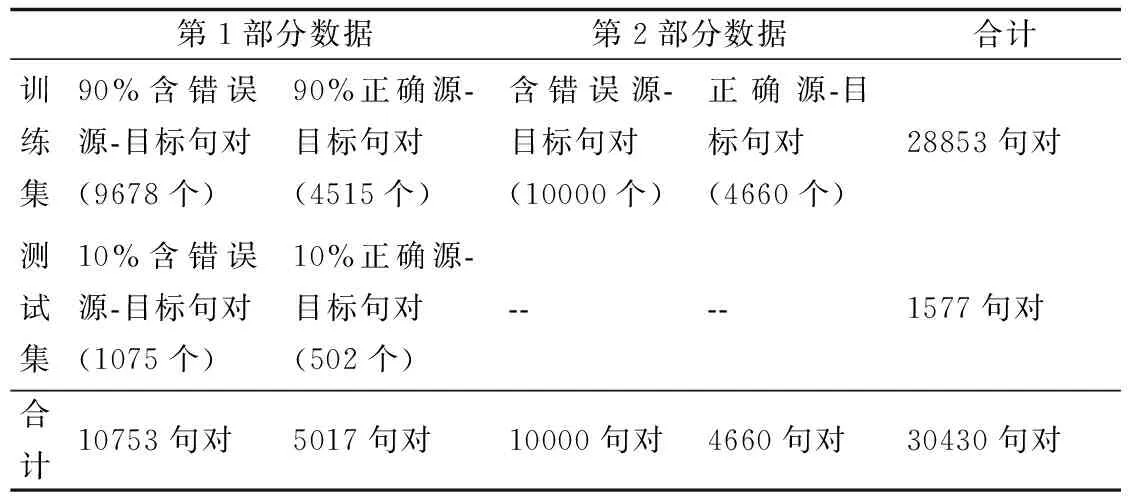
表5 模型数据集划分Table 5 Model data set partition
同时,对数据集进行了如下的预处理操作:
1)对其进行字形分类标记处理.对待纠错老挝语句中的每个字符进行字形类别标记Si,得到字形分类标记序列[S1,S2,…,Sn].
2)对训练数据进行错误标记处理.对每个老挝源语句进行错误标记,正确字符标记为0,错误字符标记为1,并将每个句子与其错误标记序列形成源-目标对用于辅任务的训练.
5.2 模型设置及评价
本文基于Pytorch框架使用Python语言进行建模,其中,本文采用学习率衰减算法,模型优化器采用Adam算法,具体参数设置如表6所示.
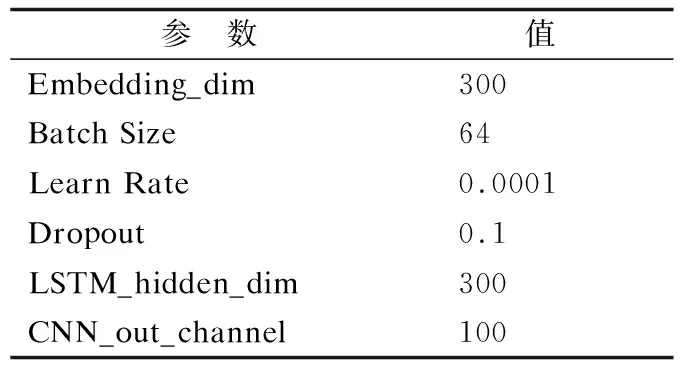
表6 模型参数设置Table 6 Model parameter settings
本文采用文字识别领域的字符错率(CER)作为模型的评估指标,同时,也通过老挝句子的误纠率(FPR)来评估本文模型对减少误纠操作设置的有效性,CER值与FPR值越低,证明模型具有越好的效果.评估指标计算公式如式(13)和式(14)所示.其中,N为总字符数,I,R,D分别为需要插入,替换和删除的字符数,FP为实际没错但被误纠的句子数,TN为实际没错也没被误纠的句子数.
CER=(I+R+D)/N
(13)
FPR=FP/(FP+TN)
(14)
5.3 实验结果与分析
本文以基于双向LSTM编码和注意力解码的序列到序列模型[12]为Baseline,通过3组对比实验验证了模型的有效性:1)数据增强效果对比实验;2)模型设置对比实验;3)文本拼写纠错模型对比实验.
5.3.1 数据增强效果对比实验
文献[4]针对中文“的地得”的误用,采用数据增强方式,对训练数据进行“的”“地”“得”的随机替换,并扩充到训练集中,实现了对该类错误较好的纠正效果.而本文老挝文字识别后的待纠错文本中也存在类似的特定错误类别,可通过随机替换老挝相似字符集和高频断裂、粘连字符对进行数据增强.因此,为提升模型对特定错误的纠正效果,本文借鉴上述思想,将经过数据增强后的第2部分数据扩充到第1部分数据中对模型进行数据增强训练,为了验证在老挝语文本纠错任务中的有效性及适用性,设置如下实验方案:1)仅将第1部分数据按9∶1划分为训练集和测试集用于模型的训练和测试;2)在1)的基础上仅用数据增强后的第2部分数据作为训练集以训练模型;3)在1)的基础上将数据增强后的第2部分数据扩充到第1部分数据中进行训练.实验结果如表7所示.
表7 数据增强效果对比结果Table 7 Data enhancement effect comparison results
由表7可知,1)的CER值和FPR值均最高,其原因是由老挝文字图片经OCR得到的待纠错文本数量有限,导致模型不足以学习足够的文本特征,而错误多样,针对每类错误的训练语料不足也导致模型效果不佳;2)直接采用对文本进行替换得到的待纠错文本作为训练集,其中文本替换所针对的错误类型得到了大量训练语料的增强,模型针对该类别的错误纠正效果得以提升;3)的CER值与FPR值最低,证明了以数据增强方式扩充训练集的有效性.其原因在于通过OCR得到的待纠错文本具有更真实的错误实例,且与测试集具有相同的错误分布,同时,扩充大量经数据增强的数据到训练集以增强模型训练效果,既使模型的泛化能力得到增强,又能有效针对特定类别的错误进行纠正.
表8展示了采用数据增强方式扩充训练集以及不采用数据增强方式的模型纠错结果示例.其中,加粗的字符为错误字符,两个纠错示例分别为相似字符替换错误和字符粘连导致的非相似字符替换、删除错误.由模型纠错示例可知,采用数据增强方式训练模型确实更加适用于具有特定错误类型的老挝文本识别结果的纠错,进一步证明了该方法在本研究中的适用性.

表8 纠错结果示例分析Table 8 Example analysis of error correction results
5.3.2 模型设置对比实验
本文在Baseline的基础上,以改变编码器结构、增加多任务学习和融入字形特征等不同设置对模型进行训练.具体设定为:1)BiLSTM+At_LSTM(Baseline),采用双向LSTM编码和单向LSTM注意力解码;2)将Baseline中编码器替换成卷积核分别为2×E,3×E,4×E的多尺度CNN网络(multi_CNN):3)将multi_CNN与Baseline联合进行编码;4)在3)的基础上融合老挝字形分类特征;5)在4)的解码后增加语言模型处理层;6)使用多任务学习增加错误检测辅任务.实验对比结果如表9所示.
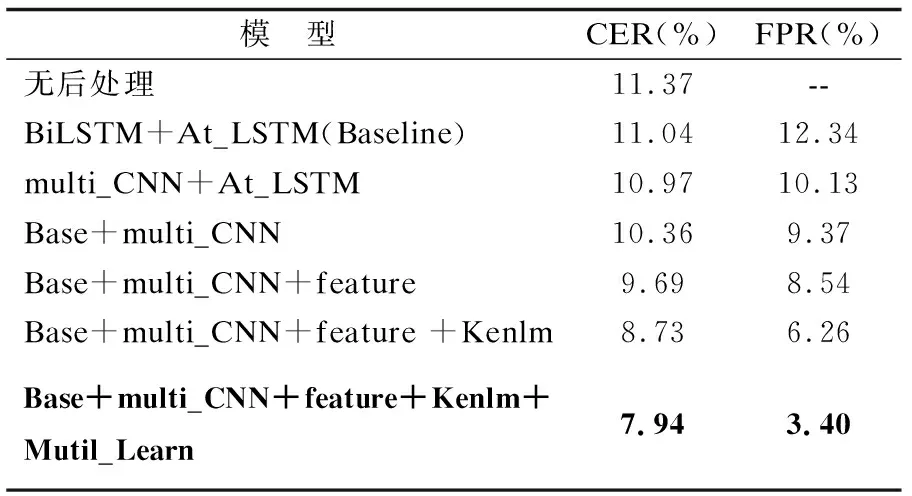
表9 模型设置对比结果Table 9 Model settings comparison results
由表9可知,本文的模型设置使模型的CER值与FPR值均得到了降低.未经过任何后处理操作的OCR结果的字错率为 11.37%,Baseline在此基础上具有小幅度的下降,证明Baseline选取的有效性,BiLSTM网络的编码能较好地提取老挝长文本序列的上下文语义信息.采用multi _CNN网络编码从模型字错率来看,与采用BiLSTM网络编码差距不大,但略低于Baseline,其原因为multi _CNN以不同滑动窗口大小深入提取了老挝文本序列的局部信息,而误纠率降低了2.21%,表明文本的局部信息对文本查错起到关键作用.联合BiLSTM与多尺度CNN编码,使模型提取的老挝文本的上下文全局信息与局部信息较好地结合,有效提升了模型甄别错误与纠正错误的能力.融入字形特征的模型的CER值和FPR值比不加特征的模型分别降低了0.67%和 0.83%,证明对老挝语字形分类使模型更好地学习了老挝相似字符之间的形状特征,提升了模型预测正确字符及发现错误字符的概率,对纠错效果有一定的贡献值.加入语言模型以选择概率更大的老挝句子作为模型纠错结果,模型误纠率降低了2.28%表明该召回机制对模型误纠现象的改善是有效的.多任务学习使模型的字符错率和误纠率分别低至7.94%和3.40%,是因为错误检测辅任务能与主任务共享参数,并通过预测可能错误的老挝字符进一步减少模型的误纠操作,同时也有效提升了主任务的纠错效果.
5.3.3 文本拼写纠错模型对比实验
为进一步验证本文模型的有效性,本文与4个其他文本拼写纠错模型进行了比较:1)n-grams模型[10]:使用基于字符的n-grams语言模型并结合字符混淆集进行纠错(n=3);2)BiLSTM+At_LSTM模型[12]:基于LSTM的注意力解码seq2seq模型;3)7CNN+7CNN[13]:具有7个编码器和解码器层,每个编码层由卷积网络及门控线性单元组成,解码层在此基础上引入注意力机制;4)3BiLSTM+3LSTM模型[14]:编码器由3个双向LSTM层组成,解码器包括3个单向LSTM层组,将残差连接添加到编码器和解码器的第3层,并引入四头注意力机制;5)本文模型.对比实验结果如表10所示.

表10 不同文本拼写纠错模型对比结果Table 10 Different text spelling error correction models comparison result
由表10可知,n-grams语言模型具有最低的误纠率,原因是语言模型的计算具有较好的错误检测效果,能更大程度地避免对正确字符的误纠,但其对字符插入、删除错误的纠正效果不佳,且由于老挝语存在大量的相似字符,大部分字符均存在大量相似字符混淆候选,且相似字符的出现频率无较大差别,均较高,因此语言模型对老挝语相似字符替换错误的纠正存在一定的困难.BiLSTM+At_LSTM模型的CER值降低了0.33%,证明其对老挝语文字识别后纠错任务是有效的.7CNN+7CNN模型CER值与FPR值分别比BiLSTM+At_LSTM模型降低了1.78%和6.19%,原因是多层卷积网络有效捕获了每个老挝字符的周围上下文信息,但其在相似字符替换错误的纠正上效果一般,字符错率比3BiLSTM+3LSTM略高,说明多层的LSTM网络更适用于捕获老挝长文本上下文的语义表示,且FPR值表明BiLSTM网络对老挝文本具有更低的误纠率,这是因为BiLSTM网络更倾向于复制含有少量错误的老挝文本中正确的原始文本.3BiLSTM+3LSTM模型采用带有多头注意力机制的多层BiLSTM及LSTM网络进行编码与解码,字符错率比BiLSTM+At_LSTM模型降低了2.49%,原因是深层的LSTM网络对老挝长文本序列的上下文语义学习效果是显著的,且多头注意力机制使模型通过不同的空间表示进而得到包含多方面信息的全局信息,也进一步降低了误纠率.而本文模型效果略好于3BiLSTM+3LSTM模型的原因是,本文模型联合多尺度CNN网络获取老挝文本的局部特征,对字符插入、删除错误有着更好的纠正效果,且本文还加入了语言模型及多任务学习策略,使模型具有更低的误纠率.
5.3.4 OCR后处理结果分析
为进一步分析不同编码方式使模型针对老挝OCR结果中哪一类错误的纠正效果得到了更大的提升,本文基于Baseline,对仅通过BiLSTM编码和仅通过multi_CNN编码的模型纠错结果进行分析,分析结果如图5所示.
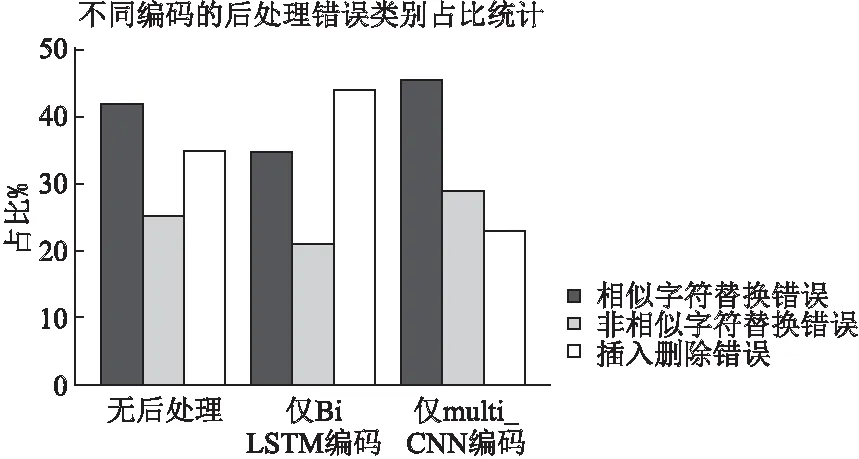
图5 错误类别占比统计Fig.5 Statistics on the proportion of error categories
由图5可知,与无后处理的错误占比相比较,BiLSTM网络编码对字符替换错误的纠正有较高的贡献度,纠正了大部分的字符替换错误,其中相似字符替换错误和非相似字符替换错误占比均有所减小,而multi_CNN网络编码则使字符插入、删除错误占比大幅减小,有效纠正了大部分字符插入删除错误.由此可见,BiLSTM网络编码和multi_CNN网络编码分别针对老挝OCR后文本错误中的主要错误进行了有效纠正,进一步表明了本文模型的有效性.
6 结 论
本文针对老挝语文字识别后纠错展开研究,基于seq2seq模型架构,融入老挝语的字形特征,并将多尺度CNN网络与BiLSTM网络联合编码,以提升模型对老挝语OCR结果中的相似字符替换错误及字符断裂、粘连所导致的字符插入、删除错误的纠正能力,同时,利用语言模型及多任务学习策略大大降低了本文模型的误纠率.实验表明,本文模型在老挝语文字识别后纠错任务中取得了不错的效果,字错率和误纠率分别低至7.94%和3.40%,使得老挝图片资源在文字识别后具有更高的准确率,一定程度上扩充了老挝语用于下游NLP任务的语料规模.在未来的工作中,将进一步研究OCR后较长的及文本中存在较多错误(3个错误以上)的老挝文本的纠正,并对老挝文本进行句法、语义搭配等分析,结合语法、语义等知识进一步提升老挝语文字识别后文本的准确率.
猜你喜欢
中国石油石化(2022年12期)2022-07-16
电脑爱好者(2022年15期)2022-05-30
今日农业(2021年10期)2021-11-27
云南画报(2021年12期)2021-03-08
小学生学习指导(低年级)(2019年12期)2019-12-04
中国外汇(2019年19期)2019-11-26
电子制作(2019年19期)2019-11-23
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
少儿美术(快乐历史地理)(2018年7期)2018-11-16
