
强调信息传播和特征分布的说话人验证模型:EIPFD-ResNet
2023-03-06 09:58梁新彦钱宇华
小型微型计算机系统 2023年3期
张 霞,刘 乾,郭 倩,梁新彦,钱宇华,畅 江
1(山西大学 大数据科学与产业研究院,太原 030006) 2(山西省机器视觉与数据挖掘工程研究中心,太原 030006) 3(山西大学 计算机与信息技术学院,太原 030006)
1 引 言
说话人验证指的是根据待识别语音的声纹特征识别该段语音是否对应于指定说话人,它是一种自然而有效的生物特征身份认证方法,尤其是文本无关说话人验证[1](Text Independent Speaker Verification,TI-SV),能够极大的帮助检索目标说话人.目前,其已经被广泛应用在语音认证[2,3]、语音分离[4-6]以及语音合成[7-9]等领域.一般来说,说话人验证任务中最重要的工作是构造一个说话人特征提取器,该提取器应当尽可能地生成具有区分度的固定维说话人嵌入[10,11].近些年来,随着大量可供训练数据的出现,深度神经网络(Deep Neural Network,DNN)取代传统说话人识别方式[12-15]成为了文本无关说话人验证任务中最广泛使用的说话人表征提取模型.
目前,在端到端的深度学习说话人识别中,基于DNN方法的两种主流模型分别是基于时延神经网络[16-18](Time Delay Neural Network,TDNN)的x-vector结构和基于深度卷积神经网络(Convolutional Neural Network,CNN)的r-vector结构.x-vector采用一定空洞率的空洞卷积来提取帧级特征,接着使用池化层将所有帧级特征聚合为一个固定维的向量,最后通过全连接层来提取说话人嵌入.由于深度残差网络[18]对于识别深层信息非常有效,Li C[19,20]等人将其应用在说话人验证任务中,命名为r-vector.和x-vector不同,相比于基于TDNN的说话人验证模型,r-vector接受三维特征作为输入,并采用二维卷积来提取特征,在不同的说话人验证数据集上均取得了良好的效果[21-23].尽管在2020VoxSRC[23]挑战赛后,基于TDNN的ECAPA-TDNN[25]模型在说话人验证任务中取得了最优表现,但由于ResNet优越的推理速度和不俗的性能在说话人验证任务中仍占据主导地位[26-28].
由2021VoxSRC[29]挑战赛结果不难看出,随着不断对ResNet层数加深或者通道加宽,基于ResNet模型的性能仍可与当前最优说话人验证模型:ECAPA-TDNN性能持平.例如:2021VoxSRC竞赛中Wang J等人[30]使用ResNet101作为特征提取模型.然而为了追求良好的性能,一味的增加网络的深度与宽度,会导致网络优化与学习的难度增加,这对于模型之后部署、应用以及进一步改进带来了巨大的负担.为解决上述问题,本文深入分析了ResNet体系架构,通过对网络重新设计,促进信息在网络中的传播,提出了一个新的说话人验证模型EIPFD-ResNet,在仅使用7.486M参数量情况下,取得了目前说话人验证任务中的最优结果.
本文贡献主要包括以下3个方面:
1)提出了新的残差块结构与特征图下采样方式.本文提出的残差块允许训练初期的负权值信息通过网络以减少信息损失,重新设计的下采样方式保证了下采样过程中卷积核大小与卷积步长相同从而避免了引入无意义的特征图信息.新的残差块结构与特征图下采样方式显著改善了说话人信息在网络传播过程中的损失情况和噪声引入问题,从而提高了说话人信息在网络中的传播效率,使模型在性能提升的同时加速了收敛.
2)对生成的说话人嵌入特征规范化处理.通过改变说话人嵌入空间中的特征分布,使相同个体的特征更紧凑,不同个体之间的特征更分散,从而提升说话人分类任务的性能.
3)为文本无关说话人验证任务提供强大的基线模型.
2 残差网络结构
基于残差网络的说话人验证模型主要由说话人表征提取模块和分类模块两部分组成.说话人表征提取模块包含帧级特征提取和话语级特征聚合两个部分.帧级特征提取部分包含4个阶段,每个阶段包含若干残差块,各阶段中残差块分布比例/数量不同,通常来说,每个基本残差块(ResBlock)包含两个权重层(weight layer)并使用跳跃连接(shortcut)允许信息隔层相加来避免深层网络中的退化问题.话语聚合子模块使用特征聚合层将不同长度的帧级说话人特征编码为固定长度的话语级特征[31],通过模型输出头将固定长度说话人特征送入分类模块,以此训练模型对说话人嵌入的辨别能力,通常将模型输出头后的输出称为说话人嵌入(embedding).表1给出了基于ResNet说话人识别模型结构(T和F分别代表特征图的时间维度与频率维度,(3×3),32,1代表卷积核大小为3×3,通道数为32,卷积步长为1的卷积层;BN代表批归一化层;{ResBlock,32,1}×3代表该阶段由3个通道为32的步长为1的ResBlock叠加在一起,FC代表全连接层).
鉴于ResNet优越的推理速度和不俗的性能,本文以此为基线,展开了不同的改进架构.
3 说话人验证模型EIPFD-ResNet
为了促进信息在网络中传播,提升模型提取说话人嵌入能力.在本节中分别从基线模型中残差块比例、残差块结构、特征下采样方式以及最后的模型输出头4个方面对原始残差网络进行重新设计,分析由此对说话人验证任务的影响.出于计算量与参数量考虑,最后结合实验给出了基于深度残差网络Half-ResNet34(通道数为原始ResNet34的一半)的更适合于说话人验证任务的模型EIPFD-ResNet,其整体结构如图1所示,其中IPBlock、下采样层和输出头具体结构分别见图2(b)、图3和图4(b),表1中给出了EIPFD-ResNet网络结构.
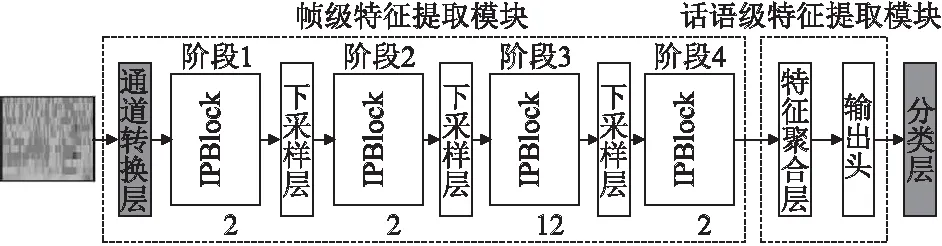
图1 EIPDF-ResNet模型整体结构图Fig.1 Architecture of the EIPDF-ResNet
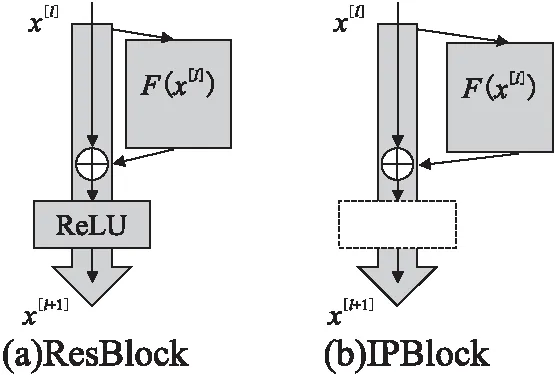
图2 原始ResBlock与IPBlock的区别Fig.2 Difference between the original ResBlock and the modified IPBlock
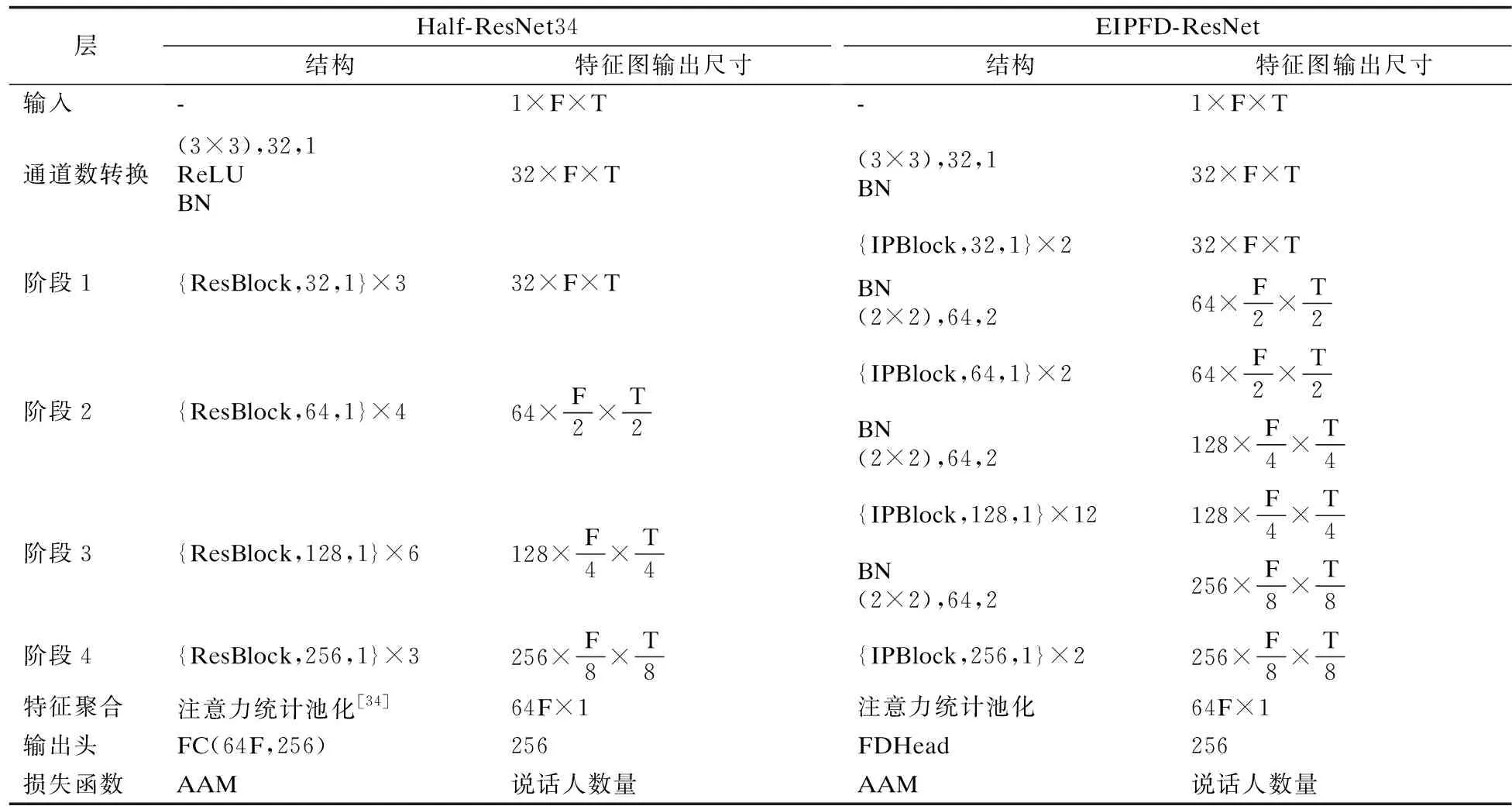
表1 Half-ResNet34结构与本文提出的EIPFD-ResNet结构对比Table 1 Structure difference between the Half-ResNet34 and the EIPFD-ResNet
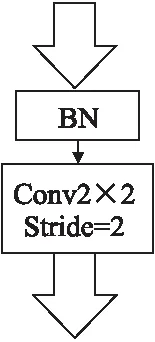
图3 下采样层结构Fig.3 Architecture of downsampling layer
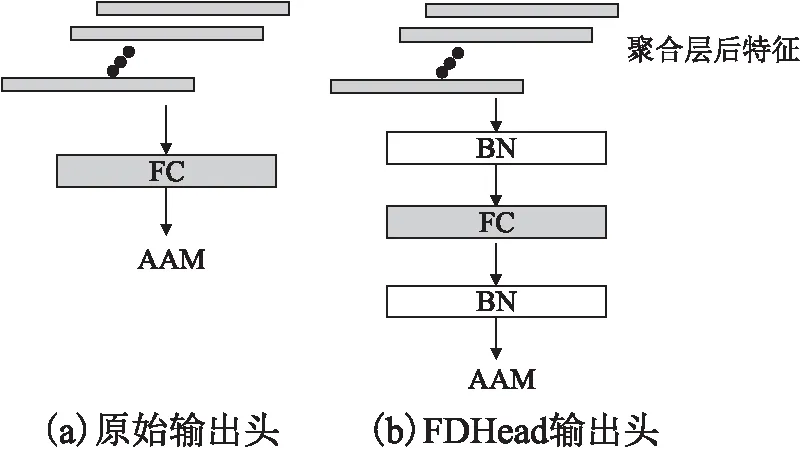
图4 原始输出头与FDHead的区别Fig.4 Difference between originalhead and FDHead
3.1 残差块比率
ResNet起源于图像领域,其残差块在模型各阶段分布比例主要是根据图像识别任务设计,可能对于说话人验证任务来说不是最优的.受ConvNext[32]启发,本节以更大第3阶段残差块分布比例修改原始网络中残差块分布,将每个阶段的残差块数量由Half-ResNet34中的(3,4,6,3)调整为(2,2,6,2)、(3,3,9,3)、(2,2,12,2)以及(2,2,15,2).探索残差块分布比例以及由此带来的模型深度与参数量改变对说话人验证任务的影响.
3.2 强调信息传播的残差块(IPBlock)
残差网络使用跳跃连接来解决深层网络产生的退化问题,但在Ionut C D等人[33]实验中,随着原始残差块的堆叠,模型深度增加,网络仍表现出优化的困难,这表明原始残差块的设计仍存在不足,过多的残差块仍会影响信息在网络中的传播.本文对原始残差块的结构重新设计,为方便描述,本文将原始残差块命名为ResBlock,修改后的残差块命名为IPBlock,图2(a)给出了原始残差块的例子:在F(x[l])中包含两个卷积层(conv),其卷积核大小均为3×3、两个批归一化层(BN)和一个激活层(ReLU),图中大箭头表示信息传播的最直接路径:主传播路径(在ResBlock主传播路径中包含跳跃连接过程),从公式上每个ResBlock可以定义为:
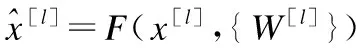
(1)
(2)
(3)
如同在公式(3)和图2(a)中看到的,负值信号在主传播路径上通过ReLU激活层后结果将归于0,但在初期训练时网络中存在很多负权值,这意味着原始的残差块设计会阻碍特征信息的传递,导致说话人相关信息损失.由此本文分别去掉残差块中残差连接后的激活层以及主干网络中通道转换层中的激活层.通道转换层中的修改在表1中体现,去掉激活层的残差块:IPBlock如图2(b)所示(虚线框代表去掉了主传播路径中的激活层).为防止这样设计的网络在特殊情况下(公式(1)结果为0)主传播路径完全不受约束,给学习带来困难,下文中提到的方式会将信号变得“标准化”,从而稳定学习过程.
3.3 独立的下采样过程
为解决上述问题,如图3所示,本文将下采样操作从残差块中剥离开,使用单独的下采样层来满足维度变换的需求.在第1、2和3阶段结束时采用步长为2,卷积核大小为2×2的卷积层来对时频维度和信道维度变换.通过使卷积核大小与步长大小一致来考虑x[l]中所有的信息,使元素间的过度更平滑,减少信息损失.批归一化层用来规范信号,减少模型学习困难,保持模型训练过程的稳定性[32].此外下采样层的作用还在于防止3.2中提到的去掉主传播路径上所有激活层后,信息在极端情况下不受任何约束的通过网络.在实验部分展示了单独使用下采样层与3.2中方法结合在性能上的好处.
3.4 强调特征分布的模型输出头(FDHead)
如图4(a)所示,许多最先进的说话人验证模型在模型输出头后使用AAM[35](Additive Angular Margin Softmax,AAM)来约束说话人嵌入.AAM如公式(4)所示:
(4)
其中n代表说话人个数,θyi是当前语句嵌入与其对应说话人类中心夹角,θj是当前语句嵌入与其他说话人类中心夹角,s和m是两个超参数,s代表尺度,该参数目的是将cos值增大s倍,方便AAM提高差异性,m为子空间角度间隔,间隔越大则表明不同说话人之间的分类间隔越大,越利于分类.
由公式(4)可知,AAM在特征空间内使用余弦角度构造一系列决策边界,把不同说话人的特征分配到角度间隔为m的不同子空间中,如图5(a)所示.最理想的情况是最小类间角度大于最大类内角度,即除AAM强制类间存在角度间隔外,希望类内特征分布尽可能紧凑,然而聚合层后的特征在欧式空间内,特征分布较为松散[36],这可能会给AAM优化带来困难.受Liu W等人启发[37],如图4(b)所示,本文在生成说话人嵌入的全连接层前后分别添加BN层来平滑嵌入空间的特征分布[36],减少特征分布的自由区域.对于AAM, Softmax使得特征倾向于仿射状分布时,导致靠近仿射中心的特征缺乏清晰的决策面并且难以区分,但BN层可以使特征保持紧凑分布[36]的同时,使得特征空间内话语特征更靠近其对应的说话人类中心(图5中虚线箭头),从而得到更清晰的分类决策面,帮助AAM更好的约束特征.同时BN也能起到正则化效果,预防过拟合,经过FDHead后的特征分布示意图如图5(b)所示.
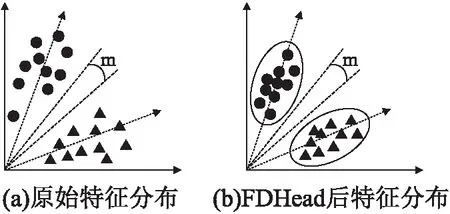
图5 说话人嵌入特征分布示意图Fig.5 Illustration of speaker embedding feature distribution
4 实验设置与细节
4.1 数据集与特征提取
1)数据集.为了评估本文所提出方法对说话人特征提取的有效性,本文在3个公开数据集CN-Celeb[38]、VoxCeleb1和VoxCeleb2数据集[39]进行了实验.
VoxCeleb:如表2所示,包含VoxCeleb1和VoxCeleb2两个数据集.这两个数据集均是从Youtube网站中提取的大规模文本独立数据集.VoxCeleb1开发集包含1221位名人的148642条访问语音,VoxCeleb2开发集包含5994位名人的1092009条访问语音.两个数据集之间没有重复.由于算力原因,本文绝大部分实验基于VoxCeleb1训练,使用VoxCeleb-O评估.为了与目前最优说话人验证模型对比,本文最后以VoxCeleb2为训练集,分别在VoxCeleb-O、VoxCeleb-E和VoxCeleb-H验证集上做了实验验证.VoxCeleb-O评估集包含40名说话人,VoxCeleb-E评估集包含了整个VoxCeleb1开发集与VoxCeleb-O中所有说话人,其测试语句更多,结果更具代表性.而VoxCeleb-H内则是包含VoxCeleb1中相同国籍,相同性别的说话人,对于说话人验证任务来说这个评估集相较于另外两个更困难.
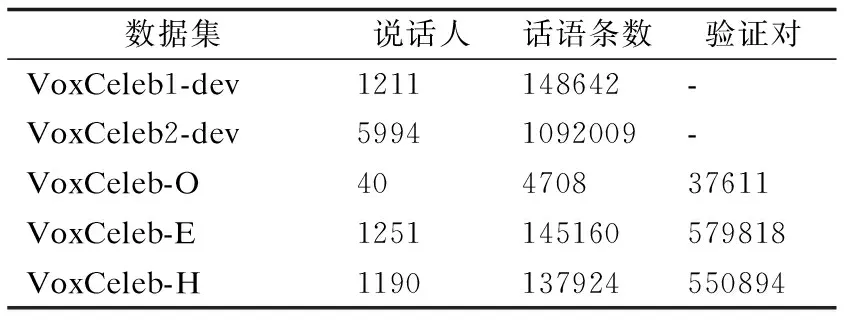
表2 VoxCeleb:训练集与评估集Table 2 VoxCeleb:training set and evaluation set
CN-Celeb:如表3所示,同样是CN-Celeb1和CN-Celeb2两个数据集,本文使用CN-Celeb2作为训练集,它是从哔哩哔哩、网易云、喜马拉雅、抖音以及唱吧等平台收集的包含娱乐、访问、唱歌、戏剧、电影、视频博客、现场直播等11个不同场景下的声音数据,涉及许多真实的噪音、信道失配和真实的讲话风格,包含1996人的超过500000条语音,相较于VoxCeleb中只包含访问类型的语音,CN-Celeb更具无约束条件的代表性.本文实验中使用来自CN-Celeb1中的CN-Celeb(E)作为评估集,包含200个说话人的18024条语音.此外该评估集的验证对中注册语句与测试语句的场景不匹配,以及数据集中包含的大量短语音数据使得该数据集在说话人验证任务中非常具有挑战性.

表3 CN-Celeb2:训练集与评估集Table 3 CN-Celeb2:training set and evaluation set
2)特征提取.本文所有基于ResNet的模型使用64维对数梅尔滤波器能量(F-bank)作为输入特征.使用长度为25ms,窗口长度为10ms的汉明窗从输入音频中提取F-bank.每段音频使用200帧的随机块作为网络输入,并且不应用语音活动检测(Voice Activity Detection,VAD).输入特征是在帧级别上的均值.所有实验在特征提取阶段均结合噪音数据集[40](气泡音,噪音,混响)做数据增强[41].最后对提取出的F-bank应用频谱增强[42].
4.2 训练设置
实验是基于 Pytorch 深度学习框架下完成的,本文使用说话人验证任务中常用的模型Half-ResNet34作为基线模型,采用注意力统计池化[33](Attention Statistics Pooling,ASP)对模型提取出的帧级特征聚合,中间通道维度设置为128.使用AAM作为模型的监督损失.
在训练阶段,每次迭代批大小设置为256,学习率初始值设置为1e-3并以每个周期0.02的衰减率衰减,选用Adam优化器并将其权重衰减设置为2e-5.AAM的超参数尺度和间隔分别设置为30和0.2.在评估阶段应用了测试时间增强(Test Time Augment,TTA)方法[43],通过重叠裁剪从单个话语中提取10个说话人嵌入,将10个嵌入的平均值作为最终的说话人嵌入.本文使用余弦相似度作为评判标准.EER和最小检测代价函数[44](Minimum Detection Cost Function,minDCF)作为性能指标,Ptarget=0.01,Cmiss=Ca=1,参数量用来衡量模型大小,下文中EER,minDCF,参数量3个评价指标越小均代表模型越具优越性.
5 结果与讨论
为了彻底评估本文所提出的方法,在本节中首先在VoxCeleb1上实验,证明了第3节中提出的4种方法的有效性.接着在3个不同数据集上分别实验与其余说话人验证模型对比,进一步证明EIPFD-ResNet的优越性.
表4内容展示的是在原始Half-ResNet模型基础上逐步增加第3节中提出的残差块分布比例、IPBlock、单独下采样层以及FDHead模块,并给出了实验结果.
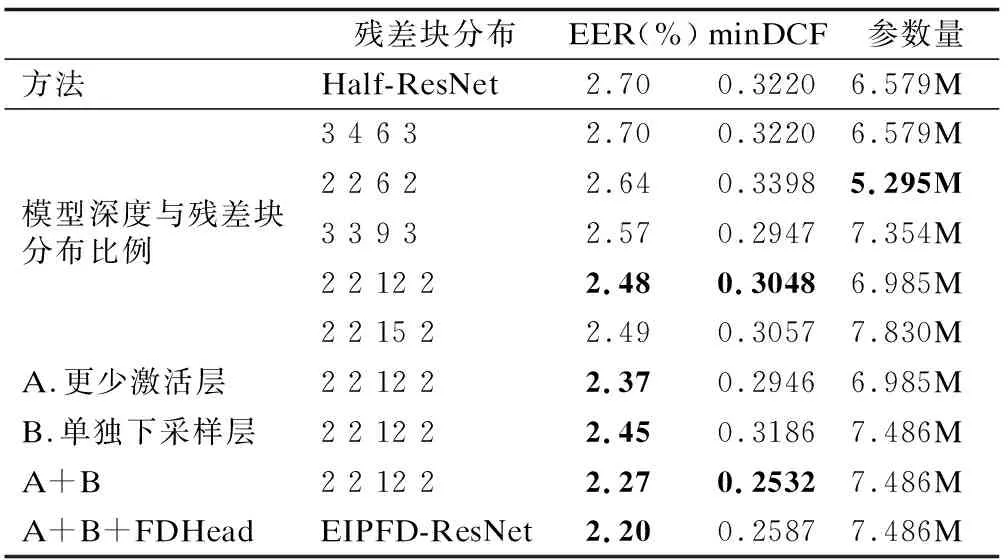
表4 本文中提出方法在VoxCeleb1数据集上的实验结果Table 4 Experimental results of the method proposed in this paper on VoxCeleb1 dataset
1)从模型深度与残差块分布比例结果可以看出原始ResNet中残差块的分布相对于更改后的残差块分布在说话人验证任务中表现并不出色;从(2,2,6,2)分布与(3,3,9,3)分布结果对比可知,尽管增加模型深度对模型会有一定增益,但这部分增益可能是由于参数量增加带来的;通过观察残差块按照(3,3,9,3)分布与(2,2,12,2)分布结果可以发现,在参数量相对一定时,更大的第3阶段残差块比例对与说话人验证任务来说更有益,这是由于该阶段可以保留特征结构信息前提下使其推理能力达到最强;在(2,2,12,2)分布基础上进一步扩展第3阶段残差块数量后,EER没有进一步改善,原因如本文3.2中描述的使用原始残差块构建网络时,主路径上激活层数量与网络的深度呈正比关系,在网络堆叠过深时会妨碍信息传输,导致网络优化困难.因此本文基于(2,2,12,2)分布完成后续实验.
2)减少激活层数量后,即使用IPBlock替代ResBlock并去掉通道数转换层中的激活层,EER进一步达到了2.37,相对于修改残差块分布后的模型降低了4.4%,证明主传播路径中没有激活层对语音特征在模型中的传递更有益.
3)尽管在使用单独下采样层来缩放模型特征图后EER改善不明显,但同时使用单独下采样层和减少激活层数量后,EER相对降低了8.5%,大于两者对于模型提升之和,证明了3.3中所描述的下采样层可以对主路径信息起到约束作用,从而与IPBlock和去掉激活层的通道转换层达到互补效果.此外使用下采样层后,模型可以更好的收敛并加快收敛过程,图6展示了使用单独下采样层策略后相对于原始下采样方式收敛情况对比,为了表示更清晰,图中没有展示前10轮迭代的收敛过程.图中横轴代表迭代轮数,纵轴代表训练损失,实线是使用原始下采样方式结果,虚线是使用下采样层的结果.
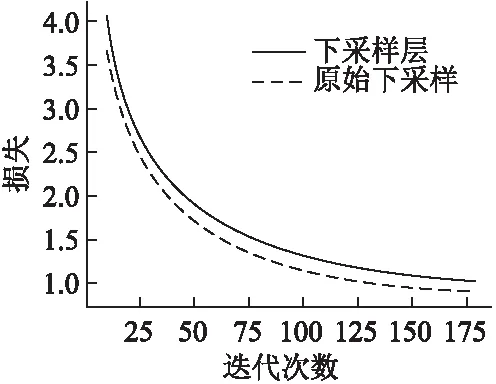
图6 原始下采样方式与下采样层收敛情况对比Fig.6 Difference of convergence between original down sampling method and down sampling layer
4)表4的最后在上述结果基础上使用本文提出的输出头来生成说话人嵌入,EER进一步下降了0.07,这表明FC层前后的批归一化层对模型提取特征有效,增强了损失函数对模型的约束.为了更好表现模型提取出的特征分布,本节对模型输出特征作了可视化处理,但由于语音基线数据集中人物数量多,每个人对应的话语很少且分布不均匀,可视化过程中会产生很大的噪音.参考Hao Luo等人解决方式[35],本节使用MNIST数据集训练模型来可视化特征空间内的特征分布,原因是相比于语音基线数据集,MNIST数据集仅有10个类别且每个类由平均600个样本组成,可使特征分布清晰稳健.图7展示了在MINIST数据集上特征可视化后的结果,可以看出,经过FDHead输出头后的特征分布相对于改进前特征分布更紧凑,决策面相对更清晰.
相较于改进前的模型Half-ResNet,第3节提出的4个方法改进后的模型:EIPDF-ResNet在VoxCeleb1数据集上EER达到了2.20,总体获得了17.3%的提升.
为进一步展示EIPDF-ResNet的优越性,本节根据数据集大小及数据复杂程度,分别在VoxCeleb1(规模小)、VoxCeleb2(规模大)、CnCeleb2(复杂场景)3个数据集上进行模型评估.
1)表5给出了EIPFD-ResNet在大数据集下的实验结果,可以发现本文提出的EIPFD-ResNet尽管仅使用了7.486M的参数量,但仍表现出强大的表征能力,取得了最优结果.相对于该数据集中最广泛使用的说话人验证模型:ResNet34-SE[30],EIPFD-ResNet的EER/minDCF在VoxCeleb-O、VoxCeleb-E和VoxCeleb-H评估集上分别相对降低了19.1%/6.1%、43.5%/46.7%和38.8%/34.1%,并且显著优于当前最优说话人验证基线模型ECAPA-TDNN,在3个评估集上,EER/minDCF分别相对降低了9.7%/33.3%、8.5%/13.0%和13.2%/14.3%.

表5 在VoxCeleb2数据集上实验结果Table 5 Experimental results on VoxCeleb2 dataset
2)表6给出了EIPFD-ResNet在小数据集上与常用的基于残差网络结构的话人验证模型对比.可以发现本文所提出的EIPFD-ResNet在性能上显著优于其余基于残差网络的说话人验证模型.相较于传统ResNet34模型,EER/minDCF相对改善了16.4%/18.4%.
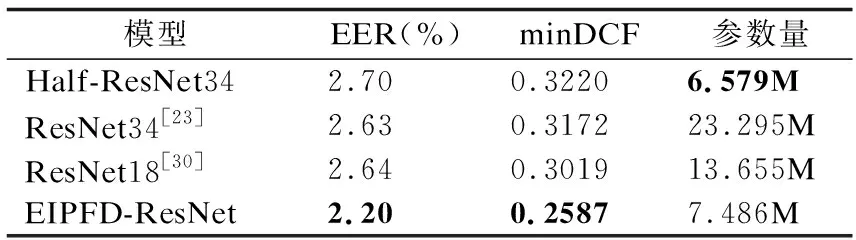
表6 在VoxCeleb1数据集上实验结果Table 6 Experimental results on VoxCeleb1 dataset
3)表7给出了EIPFD-ResNet在复杂场景下的性能表现.EIPFD-ResNet在CN-Celeb2上的EER/minDCF结果达到了9.02/0.5233,相比于ResNet-34模型与ECAPA-TDNN模型,EER /minDCF分别相对降低了6.0%/7.8%和9.0%/8.4%.
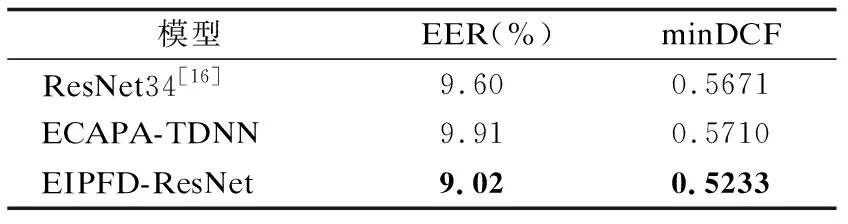
表7 在CN-Celeb2数据集上实验结果Table 7 Experimental results on CN-Celeb2 dataset
6 结 语
残差网络被广泛应用于说话人验证任务中.本文对残差中的信息流及输出特征进行分析,针对其存在的信息传播受限,容易引入噪声信息,提取出的特征难以分类等问题,对残差块分布、残差块结构、特征下采样以及模型输出头进行了更合理的设计,提出了基于残差网络的说话人特征提取模型EIPFD-ResNet.在保持优越推理速度的同时提高了捕捉说话人本质特征的能力,并在多个数据集上均取得了显著效果,为说话人验证任务提供了一个强有力的基线模型.未来计划从语音信息中特有的时间与频率信息出发对全局信息建模,从而进一步提升模型性能.
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
自动化学报(2019年6期)2019-07-23
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
数学物理学报(2017年5期)2017-11-23
