
基于污染种类判别特征的作物Pb、Cu污染种类判别
2023-03-06 08:01尚相春金倩杨可明高伟吴兵
农业环境科学学报 2023年1期
尚相春,金倩,杨可明,高伟,吴兵
(1.淮北矿业股份有限公司孙疃煤矿,安徽 淮北 235000;2.河北省矿产资源与生态环境监测重点实验室,河北 保定 071051;3.中国矿业大学(北京)地球科学与测绘工程学院,北京 100083)
近百年来,随着人类文明的发展和工业化进程的加速,矿山无序开采、矿石违规冶炼、超标废水废气排放、农药化肥过量使用等现象屡见不鲜,导致大量重金属流入到水土环境中,影响了重金属的全球循环[1-3]。超过安全限值的重金属会破坏生态系统的正常功能,它们难以被生物降解,会通过根部及叶面气孔进入植物阻碍其生长[4],且极有可能沿食物链向农作物与动物传导,进而在人类体内富集,从多方面对人体造成损害[5-6]。由此可见,重金属污染严重威胁着全球粮食安全与人类健康,已经成为当今世界面临的重大生态环境问题之一。Pb 和Cu 是常见的重金属元素,但它们对于生命体的作用与危害差异极大。Pb 属于生命体的非必需金属元素,较低含量便会对生物体表现出严重毒性[7],环境中Pb超标轻则影响植物生长、产量和品质,重则导致植物死亡;而适量Cu对植物的生长有促进作用,只有过量Cu 才会对生命体产生有害影响[8];此外,Pb 和Cu 诱发的疾病也不尽相同,Pb 中毒会造成正常红细胞性贫血等[9-10]疾病,Cu 中毒则会造成多种神经系统退行性疾病[11-13]。由此可见,不同种类、不同程度的重金属污染产生的危害存在差异,而作物是环境中重金属沿食物链向人体转移的重要环节,因此鉴别作物的重金属污染种类尤为重要。
高光谱遥感技术是一种新兴的科学观测手段,相较于传统的化验分析方法,其获取的数据更加丰富多样,监测能力与效率更强,同时也更加绿色环保[14]。近年来,高光谱数据凭借其独特优势,在土壤成分监测、植物要素监测、水土环境监测等方面发挥了重要作用。在作物重金属污染监测中,较多研究聚焦于重金属含量的反演预测,如RATHOD等[15]在研究过程中使用了水分胁迫指数,计算其与叶片砷含量之间的相关系数,探讨植物生长状态,建立回归模型,为监测植物健康状况提供了一种新思路。HEDE 等[16]探究了植被受重金属污染的影响程度,通过与常规方法进行比较,结果表明所提出的植被指数对重金属胁迫的灵敏度更高。HAN 等[17]对作物叶片光谱进行了奇异值分解,而后将获得的能量值作为作物自适应模糊神经网络模型的输入层,进行了叶片Pb含量的反演。BANERJEE 等[18]通过构建植被健康指数,分析植被健康与其受重金属污染的关系。MIRZAEI 等[19]以采集的葡萄叶片光谱数据为研究对象,采用偏最小二乘法、多元线性回归以及支持向量机方法进行建模,预测叶片内的重金属含量并取得一定效果。
随着作物重金属污染种类鉴别意义的凸显,该问题引发了部分研究人员的关注,如LI等[20]将变分模态分解应用于光谱曲线分解,联合主成分分析算法构建二维分类平面,利用支持向量机中的超分类线对玉米Pb、Cu 污染进行了可视化分析,并取得了较好的效果。FU 等[21]绘制了重金属污染环境下作物叶片的功率谱密度曲线,进而依据曲线形态区分了重金属污染种类。LI等[22]构建了区分Pb、Cu 污染的光谱指数,通过朴素贝叶斯算法制定区分玉米叶片Pb、Cu 污染的判别规则。上述研究侧重于从视觉角度进行种类鉴别,虽然结果清晰,但不适用于海量数据,不能转换为计算机语言进行结果统计,考虑到作物重金属污染种类判别的最终目标是进行区域级的应用,故应探寻具备大面积应用潜力的作物重金属污染种类判别方法。
本研究拟依托于Pb、Cu 污染下玉米叶片光谱数据及对应的重金属污染种类信息,通过分数阶、整数阶的导数(Derivative,D)进行光谱处理,借助差值比光谱指数(Difference ratio spectral index,DRSI)结构生产指数参量,进而基于优势指数参量构建多维Pb、Cu 污染种类判别特征(DFLCPT),最终以DFLCPT 为驱动,结合随机森林分类(Random forest classification,RFC)、K-最邻近分类(K-nearest neighborhood classification,KNNC)、支持向量机分类(Support vector classification,SVC)、高斯过程分类(Gaussian process classification,GPC)原理,开展作物Pb、Cu 污染种类判别研究,以期为工业级的重金属污染种类判别实践提供技术支持或参考。
1 材料与方法
1.1 试验与数据
1.1.1 植株培育
为满足作物Pb、Cu 污染高光谱甄别研究的数据需求,在温室大棚内开展重金属胁迫下的玉米培育实验。实验从重金属胁迫种类、重金属胁迫程度两个角度出发,进行玉米植株差异化培育。通过对穗期玉米叶片的测量、检验,获取不同种类、不同程度重金属胁迫下的玉米叶片高光谱数据及Pb、Cu含量数据,用于后续研究。其中,Pb、Cu污染源为Pb(NO3)2、CuSO4·5H2O,胁迫程度依据《土壤环境质量标准》(GB 15618—1995)设置为50、100、150、200、300、400、600、800 mg·kg-1,对应标记为Pb(50)、Cu(50)、Pb(100)、Cu(100)……Pb(800)、Cu(800)。同一污染种类下各胁迫程度的土壤均分为三盆,每盆中培育一组作物,对应标记为Pb(50)a、Pb(50)b、Pb(50)c、Cu(50)a、Cu(50)b、Cu(50)c……Cu(800)c,共计48 组。培育过程中各植株的水、气和养分条件适宜且一致。
1.1.2 数据获取
在密闭暗室中,以50 W 卤素灯为光源,利用ASD FieldSpec 4型光谱仪采集叶片光谱,光纤视场角为25°,采集时与叶片间距为5 cm。每盆植株均选择三枚不同位置的叶片用于光谱采集,且每枚叶片均重复测量三次光谱,以单一植株多个叶片多次光谱的均值表示该植株的叶片光谱。其中,各叶片对应标记为Pb(50)a1、Pb(50)a2、Pb(50)a3、Pb(50)b1、Pb(50)b2、Pb(50)b3……Cu(800)c1、Cu(800)c2、Cu(800)c3。
对叶片进行化学消解等预处理,而后利用电感耦合等离子发射光谱仪(ICP-OES)测定叶片中的Pb、Cu 含量。植物的生长培育环境除栽培土污染种类与程度不同外,其余条件均一致,故在重金属污染种类与程度相同的前提下,植株叶片同种重金属含量应在同一范围内。依据四分位距法,筛查异常叶片,基于Pb 含量的筛查结果如图1,基于Cu 含量的筛查结果见图2。依据异常值筛查结果,剔除异常叶片,更新用于研究的相关数据。不含异常叶片的48 组植株样本光谱见图3,不含异常叶片的叶片Pb、Cu 含量见表1,基于剔除异常叶片后的数据集开展后续研究。
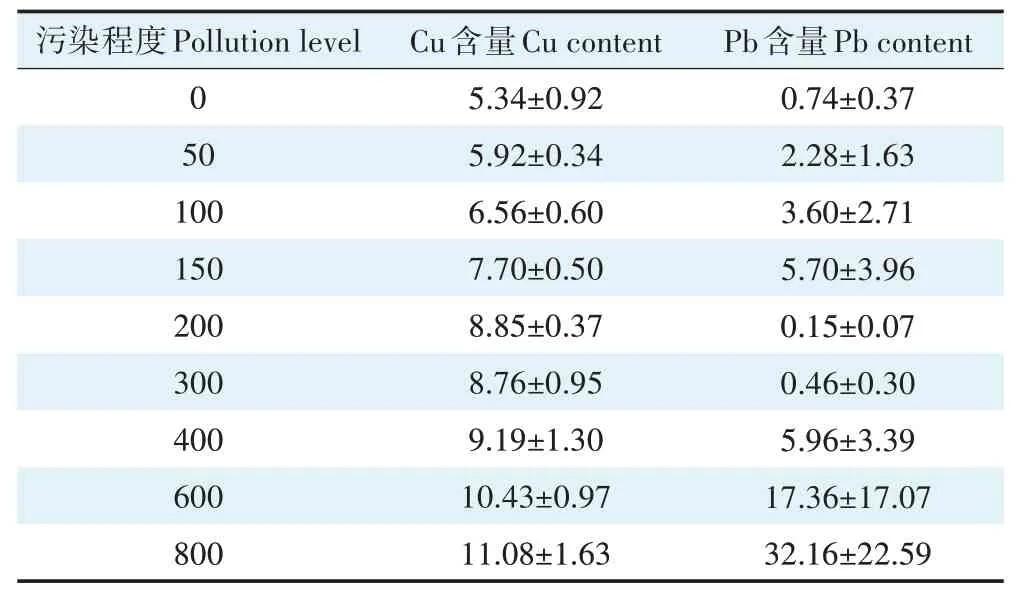
表1 剔除异常样本后的叶片Pb、Cu含量(mg·kg-1)Table 1 Pb and Cu contents in leaves after the removal of abnormal samples(mg·kg-1)
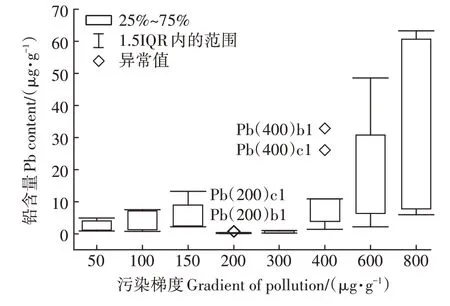
图1 基于Pb含量的异常叶片筛查结果Figure 1 Abnormal leaf screening results based on Pb content
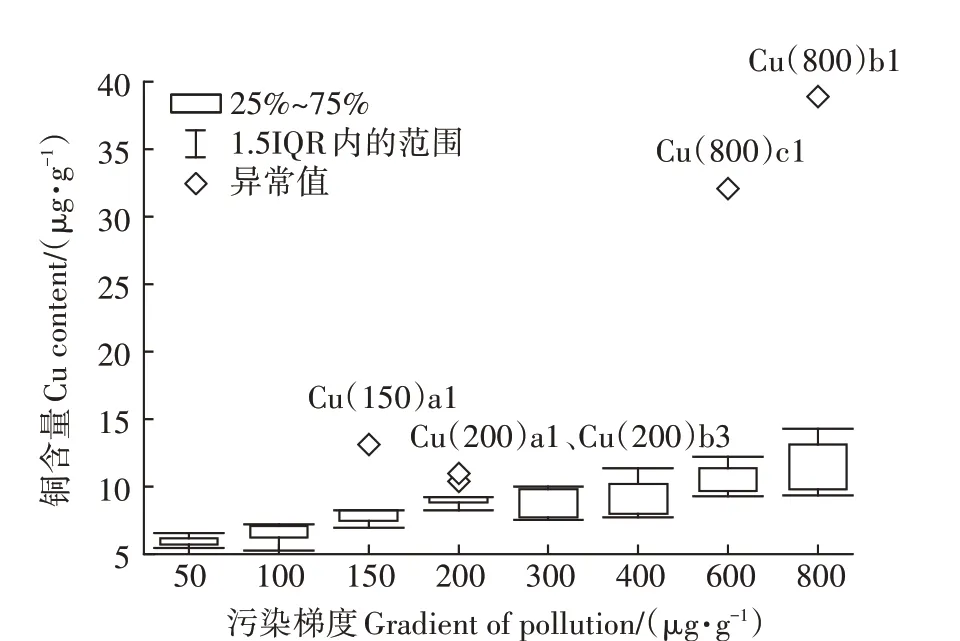
图2 基于Cu含量的异常叶片筛查结果Figure 2 Abnormal leaf screening results based on Cu content
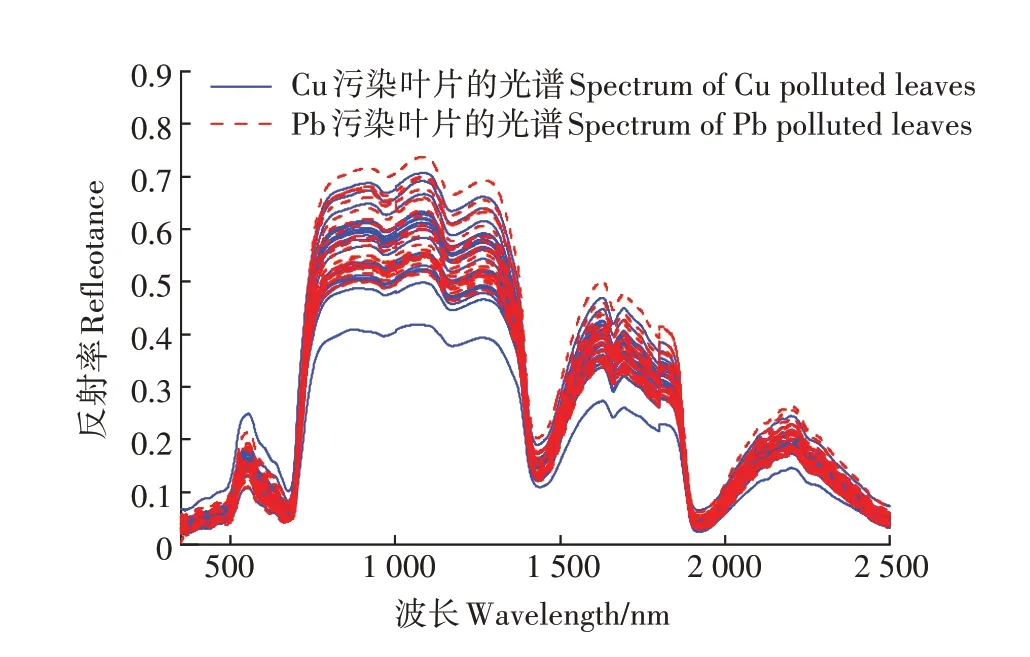
图3 剔除异常样本后的叶片光谱Figure 3 Leaf spectra after the removal of abnormal samples
1.2 理论与方法
1.2.1 导数
导数变换是一项应用广泛的光谱处理技术,在消除噪声、获取隐藏信息等方面发挥着重要作用[23]。传统导数的阶次一般为整数,而分数阶导数是传统导数的拓展,其在光谱信号中常依据Grünwald-Letnikov(G-L)法[24-25]实现。由G-L 法可知,光谱f(x)在波长[bstart,bend]间的v阶导数为:
式中:v为阶次,且大于0;bstart为光谱的起始波长;bend为光谱的终止波长;INT()为取整运算;Γ为Gamma函数;x为指定波段的光谱值;h为光谱的采样间隔;z为自变量;u为积分变量。
故而,式(1)可以表示为:
1.2.2 Pb、Cu污染种类判别特征(DFLCPT)
为开展Pb、Cu污染种类判别,设计了一种多个要素(E)构成的特征集以表征样本的种类属性,即DFLCPT。依据包含要素的数量,可分为不同维度的DFLCPT。
n维尺度的DFLCPT(DFLCPTnD)可表示为:
式中:E1,E2……En为DFLCPTnD构成要素。
适宜的光谱指数能够有效利用多波段信息,进一步提升对目标的表征能力,故以光谱指数作为DFLCPTnD的构成要素。差值和比值是两种常见的光谱指数形式,相关性分析能够实现面向属性的信息提取,故结合两种指数的结构优势,加入相关性最优波,构建了差值比光谱指数(DRSI)结构。DRSI的具体参数受基准光谱(Basic spectrum,BS)、构成波段的影响,因此将DRSI 记作DRSI[b1,b2,br]BS,DRSI[b1,b2,br]BS的计算方法为:
式中:br为相关性最强波段波长,Rbr为波长br处的光谱值。
1.2.3 判别模型原理
(1)随机森林分类(RFC)
随机森林是一种机器学习技术,决策树是其基分类器,该算法将随机因素引入到决策树的训练中,其主要思路:首先将预测空间分为多个样本空间,然后再从各个决策树中选取最优特征分割点,选取时从每一子空间随机选取部分特征,构建一个特征数据集,最终汇总获取结果。由于决策树的训练集及候选集均为独立选取,因此其预测结果具有独立性。随机森林的分类结果是由所有决策树联合表决确定的,与单一决策树相比,其具有不过度拟合、所需参数少、泛化能力较强等特点,因此随机森林的性能更佳。
(2)K-最邻近分类(KNNC)
最邻近分类算法是基于样本的一种分类算法,其主要研究重心为提高模型的分类精度,其主要操作过程:确定待分类的对象,首先寻找训练样本与待分类对象距离较近的样本,然后计算相似度,并将相似度进行排名,在排列结果中,选择最相似的K个样本,K的取值在很大程度上依赖于训练样本的大小,然后计算出K个样本的所属类别,从而决定出该测试样本的类别。
(3)支持向量机分类(SVC)
支持向量机算法可应用于样本分类及回归等问题处理方面,是一种按照监督分类方式进行分类的机器学习方法,其基本原理是首先选定训练集与测试集,并确定核函数,然后选取样本的特征信息,映射到高维空间,在该空间寻找一个最优超平面,从而在数据特征之间创建边界,最终达到分类的目的。SVM算法的优点是可以应对样本较少的情况,具有对样本数据敏感的特点。
(4)高斯过程分类(GPC)
高斯过程分类与SVM 分类操作过程类似,同样是基于核函数确立的算法模型,其属于贝叶斯机器算法模型,被用来解决二分类等问题研究,GPC 的基本建立过程:首先依托训练样本,划分分类级次;其次进行训练学习,确定似然函数,求解最优参数;而后基于高斯理论及贝叶斯规则,综合先验知识,调整预测分布;最终得到分类结果。
2.4 随机搜索优化(RSO)
网格搜索是机器学习与深度学习领域重要的超参数优化方法,但其在非关键参数维度消耗了大量的算力。RSO是一种设计更加便捷的参数搜索方法,其将原参数空间划分为规则的网格,而后从中均匀且独立地抽取,以生产新的参数训练集。RSO 具备GS 的所有优势(原理简单、易于实现、并行性小),并以低维搜索空间中效率的小幅降低换取了高维搜索空间中效率的大幅提高。
2 结果与讨论
2.1 光谱导数变换结果及分析
对叶片原始光谱(OS)进行不同阶次导数(D)处理,阶次分为整数阶与分数阶,使用的整数阶次为1~10,使用的分数阶次为0.1~0.9、1.1~1.9。不同阶次背景下生成的28 种导数光谱,在本研究中记作“vD”光谱,v表示D的阶次。
分析28 种导数光谱及OS 与样本Pb、Cu 污染种类的相关性,统计光谱各波段与样本Pb、Cu污染种类相关系数绝对值(| |r)的均值(rmean)与最大值(rmax),以及rmax对应的波长(br),见表2。从与样本Pb、Cu 污染种类的rmean来看,分数阶导数变换与整数阶导数变换均达到了预期效果,相较于OS 凸显了更有价值的信息,整体上增强了数据与研究目标的相关程度;从与样本重金属污染种类的rmax来看,分数阶导数变换与整数阶导数变换同样均达到了预期效果,提取的最有价值信息相对于OS 更具潜力,增强了最优数据与研究目标的相关程度,但随着导数阶次的增长,光谱对应的rmax并未一直增加。
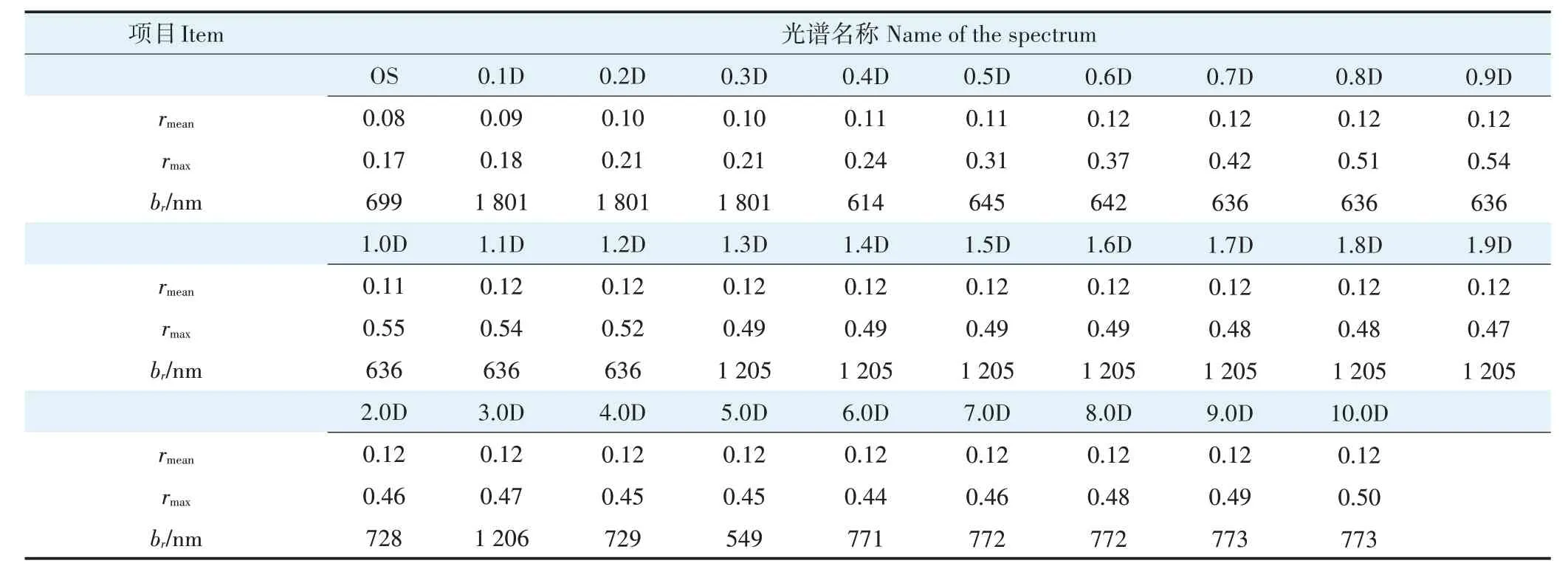
表2 不同类型光谱与样本Pb、Cu污染种类的相关程度表Table 2 Correlation between multiple types of spectra and types of Pb and Cu pollution in samples
2.2 DFLCPT构建结果
基于不同阶次的导数光谱与对应的br信息构建DRSI,共得到28 类BS 不同的DRSI,同一BS 下,共有4 624 650种组成波段不同的DRSI,即生产了129 490 200种DRSI。分析每种DRSI 与样本Pb、Cu 污染种类的相关性,以DRSI 中b1、b2 波长值为自变量,以对应的|r|为因变量进行制图,见图4。可见,相较于其他阶次导数光谱,0.5~1.2D 光谱生产的DRSI 与样本Pb、Cu 污染种类相关系数整体上更高,对污染种类的表征能力更强。
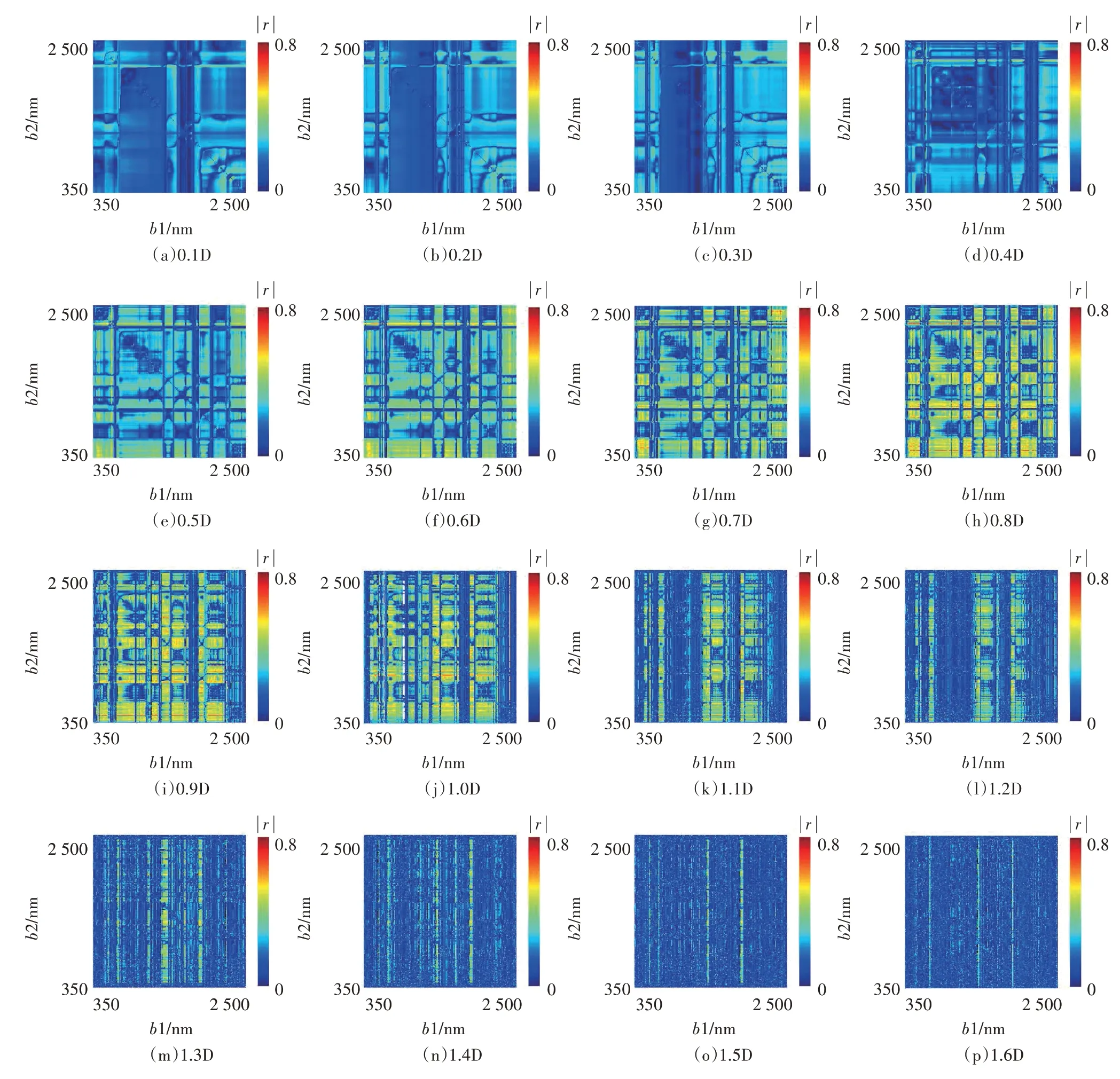
图4 各DRSI与样本Pb、Cu污染种类的相关性Figure 4 Correlation between each DRSI and the Pb and Cu pollution types in the sample
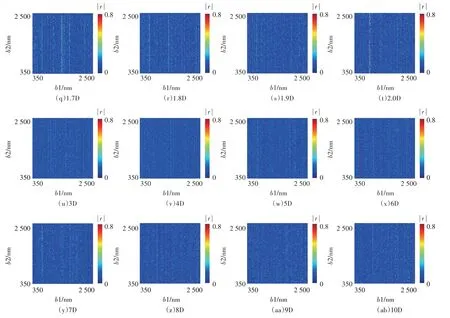
续图4 各DRSI与样本Pb、Cu污染种类的相关性Continued figure 4 Correlation between each DRSI and the Pb and Cu pollution types in the sample
为准确获取能力最强的DRSI,统计多种DRSI 与样本Pb、Cu 污染种类的 |r|,最大的10 个 |r|及对应的DRSI 构成参数见表3。对Pb、Cu 污染种类的表征效果而言,基于分数阶导数光谱的DRSI 相较于基于整数阶导数光谱的DRSI 更好,说明导数阶次并非越高越好,阶次的分数化在适当的环境中能获得更好的效果。
统筹分析表3中相关数据,依据对研究目标表征能力的强弱,依两种指数构型下各指数对研究目标表征能力的强弱顺序,逐个纳为DFLCPTnD的构成要素。
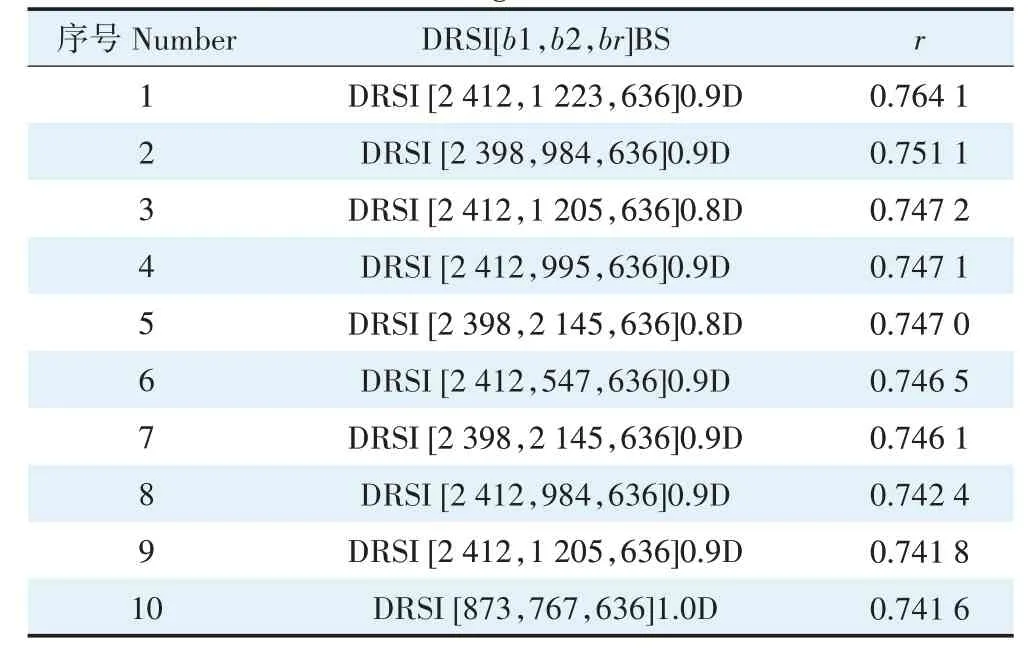
表3 优势DRSI的性能及构成参数Table 3 Performance and composition parameters of advantageous DRSI
2.3 基于DFLCPTnD甄别模型的建立与检验
以DFLCPTnD数据为驱动,结合SVC、RFC、KNNC、GPC 理论分别构建Pb、Cu 污染甄别模型。DFLCPTnD可细化为多种不同维度的特征数据,也意味驱动甄别模型的数据维度可能是不同的。随着DFLCPTnD维度的上升,其各要素中有益信息的占比存在升高或降低的可能,进而对甄别模型的性能产生影响。因此,分析不同维度DFLCPTnD数据驱动下的甄别模型性能是必要的,故分别选取多个维度的DFLCPTnD为驱动数据,进行甄别模型构建,其中选取的DFLCPTnD数据维度为DFLCPT1D、DFLCPT11D、DFLCPT21D、DFLCPT31D、DFL-CPT41D、DFLCPT51D、DFLCPT61D、DFLCPT71D、DFLCPT81D、DFLCPT91D。部分建模算法中的参数对性能影响较大,同时考虑驱动数据维度的影响,故利用RSO算法求取各模型参数的动态最优解。
以训练集样本对应的数据为自变量,训练不同维度DFLCPTnD数据为驱动下的甄别模型,获得模型在训练集中的正确率;而后结合验证集数据进行检验,获得模型在验证集中的正确率。由表4可知,RFC模型效果最优时,对应的训练集与验证集正确率均为100%,SVC模型效果最优时,对应的训练集、验证集正确率均分别为89%、100%。GPC 模型效果最优时,训练集和验证集正确率分别为92%、100%;KNNC 模型效果最优时,训练集和验证集正确率为100%、90%或89%、100%。综上所述,基于DFLCPTnD数据的RFC模型在Pb、Cu污染甄别中精度较好,且稳定性较强。
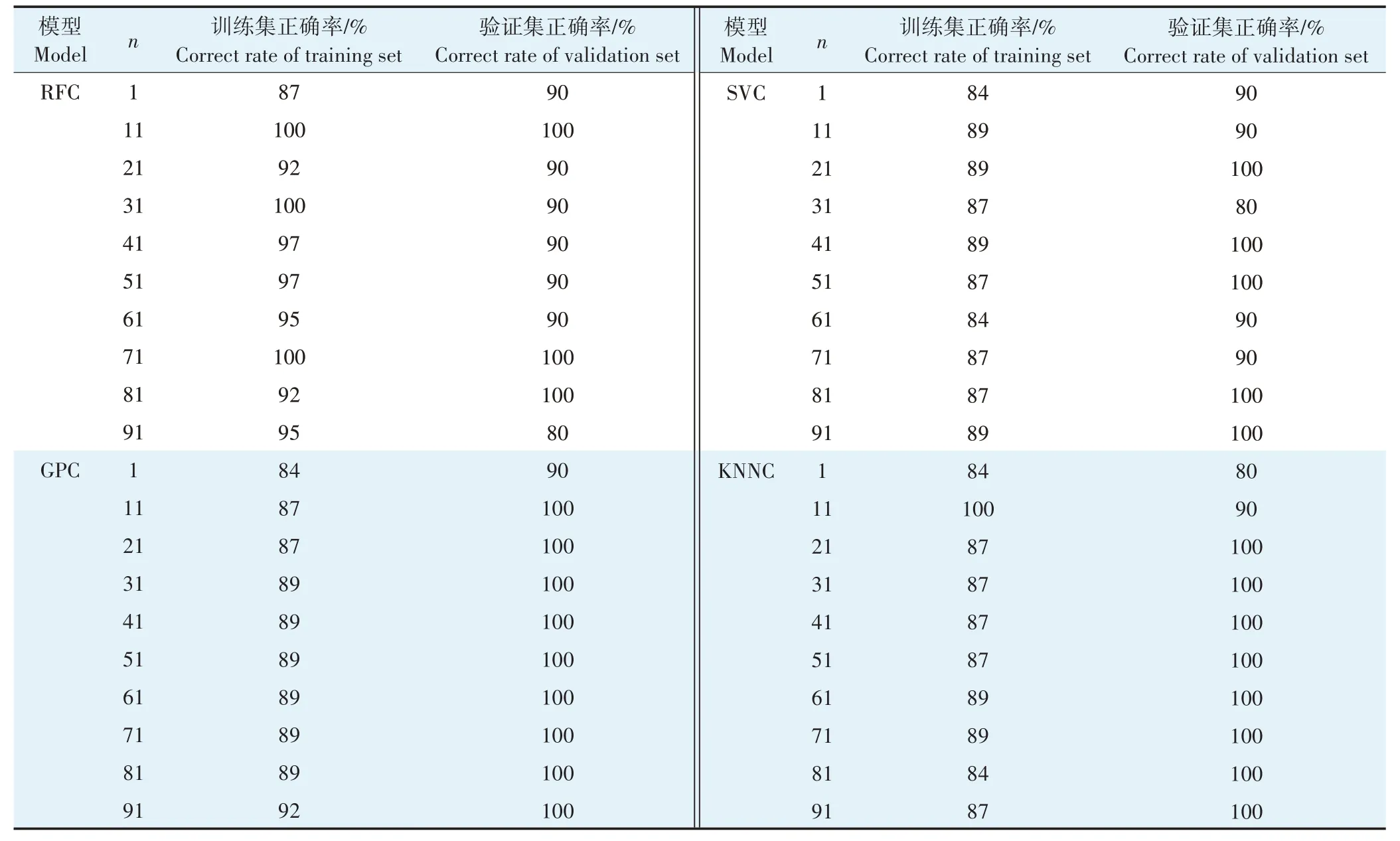
表4 各判别模型在训练集和验证集中的正确率Table 4 Correct rate of each discrimination model in the training set and verification set
3 结论
(1)叶片光谱的分数阶导数变换、整数阶导数变换均增强了其与Pb、Cu污染种类的相关程度,但相关程度的峰值并未随着阶次的增长而增长。
(2)在构建的DRSI 中,DRSI[2 412,1 223,636]0.9D 与样本Pb、Cu 污染种类的|r|最大,为0.764 1;以分数阶导数光谱为基准光谱的指数对Pb、Cu 污染种类的表征能力更强。
(3)基于DFLCPTnD的RFC 污染判别模型的效果优于SVC、KNNC、GPC 模型,其在训练集与验证集中取得的最高正确率均为100%,精度较好,稳定性较强。
猜你喜欢
中学生数理化(高中版.高二数学)(2021年4期)2021-07-20
汽车实用技术(2019年24期)2019-12-27
组合机床与自动化加工技术(2019年7期)2019-08-06
收藏界(2018年1期)2018-10-10
创新作文(小学版)(2018年31期)2018-05-16
价值工程(2017年28期)2018-01-23
摄影之友(影像视觉)(2017年1期)2017-07-18
数学大世界·中旬刊(2017年3期)2017-05-14
小学阅读指南·低年级版(2016年6期)2016-05-14
高中生学习·高三版(2016年9期)2016-05-14
