
基于信息熵与迭代因子的复杂网络节点重要性评价方法
2023-03-05 00:06:16汪亭亭梁宗文张若曦
物理学报 2023年4期
汪亭亭 梁宗文 张若曦
(西南石油大计算机科学学院,成都 610500)
在复杂网络的研究中,如何有效地衡量节点的重要性一直都是学者们关心的问题.在节点重要性研究领域,基于拓扑学信息来判断节点重要性的方法被大量提出,如K-shell 方法.K-shell 是一种寻找可能具有重要影响力节点的有效方法,在大量的研究工作中被广泛引用.但是,K-shell 过多地强调了中心节点的影响力,却忽视了处于网络外围节点作用力的影响.为了更好地衡量网络中各个节点对传播的促进作用,本文提出了一种基于迭代因子和节点信息熵的改进方法来评估各个层次节点的传播能力.为评价本文方法的性能,本文采用SIR 模型进行仿真实验来对各节点的传播效率进行评估,并在实验中将本文算法和其他算法进行了对比.实验结果表明,本文所提方法具有更好的性能,并且适合解决大规模复杂网络中的节点重要性评价问题.
1 引言
在网络科学领域中,研究节点重要性的排序算法一直都是学者们追随的热点话题,其目的是为了通过对节点的重要性排序寻找出对传播起关键性作用的节点.在病毒网络中通过对重要节点的及时控制可以抑制病毒大面积的扩散[1],在社交网络中,商家可以把新产品投放到重要客户中,通过重要客户的宣传实现投资效益最大化[2].由此可以看出研究网络中的重要节点不仅有重要的理论意义,更有重要的现实意义.
目前已经提出了各种方法来对节点的重要性进行排序.在网络结构拓扑基础上发展起来的经典算法有度中心性(DC)[3]、介数中心性(BC)[4]、接近中心性[5]和h指数[6]等,这些都是基于网络拓扑结构的经典算法[7].另外,pagerank[8]和leaderank[9]是基于随机游走的两个代表性方法.Kitsak 等[10]提出了K-shell 方法,该方法的算法实现非常简单,有研究显示该算法对识别影响力节点具有显著的度量作用[11].但是K-shell(ks)索引对网络拓扑全局信息要求较高且在单调性(排名列表中拥有相同排名节点的比例)上表现不佳[12],即在同一个Kshell(ks)值中的所有节点都拥有相同的排名,这样不利于唯一地区分节点的排名.之后研究者们在K-shell 基础上提出了很多改进的方法.Basaras 等[13]提出了基于混合度和K-shell 的算法,该方法提出了µ幂社区指数(µ-power community index,µ-PCI).它是K-shell 和中心度的混合,该算法以完全局部化的计算方式达到了适用于任何类型的网络.Wang 等[14]利用k-shell 的迭代信息来区分具有相同ks 值的节点,并同时考虑了节点度来综合量化节点的重要性,具有很好的准确性.网络中少量的节点具有大量的边,这些节点也被称为“富节点”,它们会出现倾向于彼此之间相互连接的现象,这种现象一般被称为富人俱乐部现象[15].如果通过排序方法选出来的重要节点作为种子节点,种子节点之间具有高度连接,就会受富人俱乐部现象的影响,造成大量的活跃节点在传播时出现交叉现象,传播仅在小范围内扩散.而这些以K-shell 为基础的排序方法,往往无法避免网络中富人俱乐部现象带来的影响.
有研究学者已经提出很多方法来规避富人俱乐部现象的带来的影响,使得基于拓扑排序的方法变得更可靠.针对富人俱乐部现象问题,Wang 等[16]提出一种改进的K-shell 方法(improved K-shell method,IKS),该方法通过迭代筛选出K-shell 各层中信息熵最高的节点,从而有效地避免富人俱乐部现象,实验表明其对网络中前K 个节点的传播影响力衡量更准确.但在同一shell 内有大量信息熵相等的节点时,该算法会随机选取其中之一并把其余节点投入到下次迭代当中,这就造成了本来排名靠前的节点因无限迭代而靠后.在Zareie 等[17]所提出的算法中考虑了节点及其邻域集的公共层次,将迭代因子(iteration,IT)应用于网络分层中,使得网络中节点更具有差异性,从而提出一种基于邻域相关系数的关键节点识别算法.
受Zareie 等[17]所提算法的启发,本文沿用迭代因子(iteration,IT)对网络进行分层;在改进的K-shell 方法(improved K-shell method,IKS)[18]的基础之上,利用迭代因子来对网络的结构进行分层,然后再分别计算每层中节点的信息熵,提出了基于迭代因子和信息熵相结合的方法(简称IE+)来衡量网络中的节点重要性,该方法对在迭代过程中因随机选择造成节点排序靠后的问题有所改进,同时在具有富人俱乐部现象的网络中进行节点重要性排序时也具有较好的表现.本文在八种常见网络数据中使用SIR 模型[18,19]来模拟病毒传播的过程,将所提出的算法与常见算法进行比较,实验结果表明,本文所提方法具有更好的性能,并且适合解决大规模复杂网络中的节点重要性评价问题.
本文的其余部分安排如下.第2 节简要叙述了现有的一些经典算法.第3 节中将详细阐述本文的算法思想.数据集将在第4 节中介绍.第5 节将简要介绍评价指标.实验设置、结果和讨论在第6 节中提及.最后,在第7 节中给出结论.
2 相关工作
一个无向未加权网络通常表示为G=(V,E),其中V和E分别表示节点和边的集合.它也可以定义为一个邻接矩阵A=(aij)n×n,如果节点vi和vj有一条边相连接,则aij=1,否则aij=0.
大部分算法都是基于拓扑结构,关注节点的中心性.此前学者们提出了许多中心性度量方法,这些方法从不同的角度衡量了节点的重要性.在这里,简要回顾几个中心性指标的定义.
在度中心性算法中,DC 算法[3]主要考虑了节点度中心性,并得出节点邻居数量越大传播能力越强;接近中心性(CC)[5]算法则更关注节点和整个网络之间的关系,认为节点与网络中所有节点之间距离的平均值越小,节点越重要;学者们还提出了相对新颖的方法,例如基于重力的方法论上,取两个节点的ks 值作为质量,两个节点之间的最短路径作为距离[20,21],两个节点之间的相互作用关系随着他们的距离而减小,模仿重力公式将两个节点间的ks 值的乘积与两节点间的最短距离的比值作为衡量节点传播能力的度量,从而实现对节点重要性的排序.
Kitsak 等[10]提出了K-shell 方法,该方法认为节点的影响力是由它的位置决定的,而最有影响力的节点应该是网络的核心.K-shell 分解是一个迭代过程,第一步是删除所有度数为1 的节点,直到网络中没有度数为1 的节点,被移除节点ks=1.第二步是从网络中移除所有度数为2 的节点,直到网络中没有度数为2 的节点,被移除节点ks=2.迭代继续,直到所有节点都从网络中删除.图1 列出了一个包含26 个节点和32 条边的网络图.通过K-shell分解得到每个节点的ks 值.K-shell 算法认为ks值越大,传播影响越大.这意味着在图1 所示网络中,节点1,2,3,4,5 的影响力最大,而ks=1的节点传播影响力最小.在K-shell 的分解过程中,对度很大但位于网络边缘节点的影响力衡量不够准确,例如图1 中的节点21.研究人员基于K-shell提出了大量的扩展方法,如邻域核心中心性(Cnc)、扩展邻域核心中心性方法(Cnc+)[22]等算法认为,一个节点的影响不仅取决于它的自己的ks 值,也依赖于其邻居节点的ks 值.

图1 一个简单示例图Fig.1.A sample graph.
最近,一些混合的度量方法被陆续提出.这些方法充分利用节点的拓扑信息,利用混合的衡量指标从不同的角度来对节点的重要性进行评价.Bha 等[23]提出提高的混合排序方法,该方法结合了两个中心性—扩展的邻居中心性(Cnc+)和h指数中心性,该方法在排序准确性上具有很好的性能.阮逸润等[24]提出了基于结构洞引力模型的改进算法,综合考虑节点h指数、节点核数以及节点的结构洞位置.
除此之外,在动态网络中,网络拓扑随着时间的推移而不断变化,导致动态网络中关键节点的识别变成一项艰巨的任务.研究者们通过不同时间段的网络快照信息对节点进行排名[25-30],Qu 等[31]提出时态网络中的时态信息收集(TIG)过程,将TIG过程作为节点的重要性度量,可用于节点重要性排名.胡钢等[32]依托复杂网络的层间时序关联耦合关系、层内连接关系和层间逼近关系构建时序网络超邻接矩阵,提出了基于时序网络层间同构率动态演化的超邻接矩阵建模的重要节点辨识方法.
无论是静态网络还是动态网络,它们都遵循幂律网络中的一个重要性质就是少数几个节点连接数量较多,而连接数量较多的节点更愿意去连接比它连接数量更多或同等多的节点,这时就造成了富人俱乐部现象的出现.为了避免富人俱乐部现象对排序结果带来的影响,Liu 等[27]提出了一种基于每个节点的局部索引秩(local index rank,LIR)的算法,可以对具有富人俱乐部现象的网络中的节点实现快速排序;Namtirtha 等[28]提出了一种混合指标的度量方法,考虑了节点的度、节点间的联合影响率和节点间的最短距离,从网络中心到网络边缘来对节点进行排序;改进的K-shell 算法[16]采用K-shell 分层与节点信息熵相结合的方法来迭代地选取重要节点,考虑了不同shell 层中网络节点的重要性,但该算法会在具有相同信息熵的节点中随机选择一个并把其余节点投入到下次迭代当中,这就造成了本来排名靠前的节点因无限迭代而靠后.受IKS 算法的启发,本文提出了一种基于迭代因子和信息熵的算法来识别从网络外围到核心的每个网络级别的重要节点,将此方法简称为IE+.
3 算法介绍
3.1 迭代因子
在IKS 方法中,网络使用K-shell 进行分层.从图1 可以看出,虽然节点7,8 和9 在同一个K-shell中,但是节点7,8 较节点9 更接近网络的核心,当网络中的节点被移除时,节点9 在节点7,8 之前被移除.与被感染的节点9 相比,被感染的节点7,8 可以达到更好的传播效果.鉴于K-shell 对节点重要性度量不够完善,本文提出迭代因子(iteration,IT)对节点进行分层,使得网络层次结构更加清晰.
以图1 为例,设置迭代因子的初始值IT=1,然后将度数最小的节点从网络中移除.这些被移除的节点属于图结构的第一层,然后在本次迭代中被删除节点的迭代因子IT=1.在下一阶段,IT 值增加1,并再次从图中删除度最小节点,并将在本次迭代中被删除节点的IT=2.这个过程会一直迭代,直到图中没有剩余节点.在每次迭代中,IT 的值都会加1 并分配给在此阶段中被删除的节点.从图1可以看出,节点7,8,9 不再处于同一结构层级,但节点7 和8 更靠近网络中心,因此比节点9 具有较大的IT 值.同理,对位于网络中心的节点(如节点1,2,3,4,5)的网络层次划分更细,节点5 被认为是网络的核心,节点1,2,3 和4 被认为是次要核心.
3.2 信息熵
在IKS 算法中,信息熵被定义为
其中j∈Γ(i) 是节点vi的邻居节点的集合,其中:
从(1)式和(2)式可以看出,节点信息熵的计算主要依赖于节点的本地邻居信息.节点17,18和19 都在网络的外围,如果仅依靠邻居的度信息来计算节点的信息熵,那么这三个节点的信息熵和ks 值均相同.但节点17 的邻居节点比其他两个节点的邻居节点更接近网络的中心,因而仅依靠邻居节点的度信息显然是不够的.因此,本文结合节点在网络中的位置,基于ks 提出一种计算节点信息熵的新方法:
其中 (i) 是节点vi的邻居集合;Ij的定义如(2)式所示;ksj表示节点j的ks 值.以节点17 为例计算其信息熵:
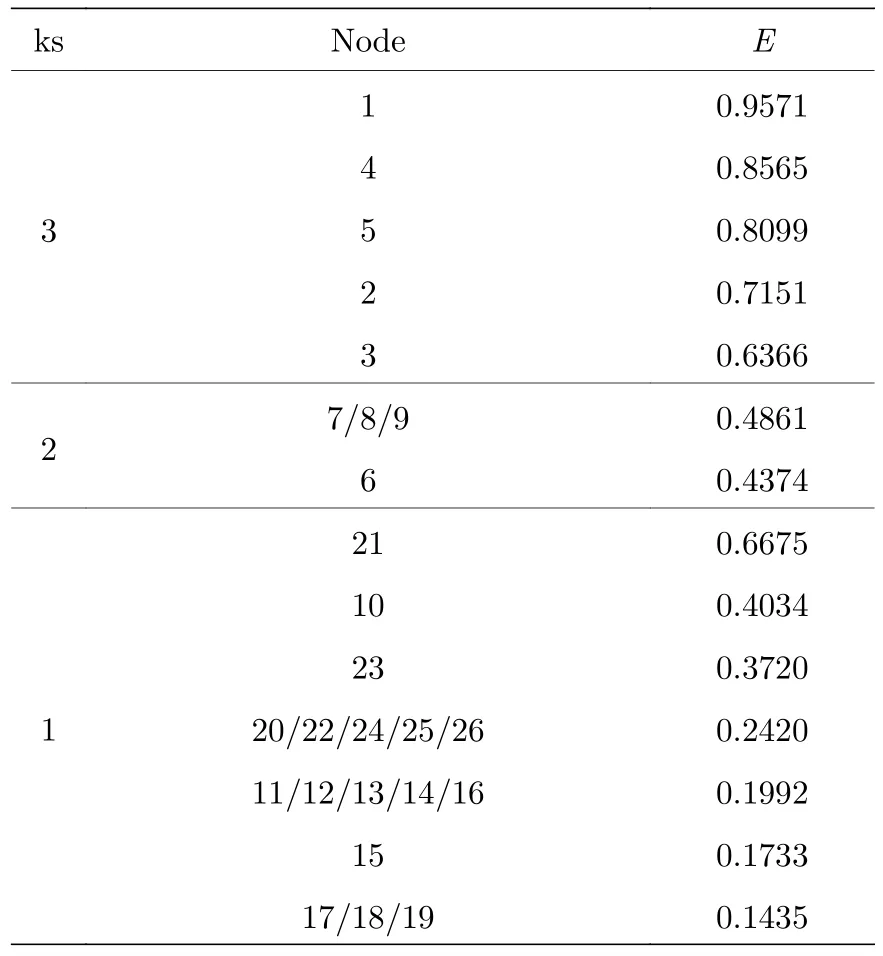
表1 节点在每个shell 中的信息熵Table 1.Information entropy of each node.

表2 节点在每个迭代层中的信息熵Table 2.Information entropy of each node.
3.3 算法步骤
本文基于迭代因子(IT),通过ks 值对节点信息熵的计算进行改进,提出了迭代因子和信息熵相结合的算法(简称IE+)来对节点的重要性程度进行度量,该算法的步骤如下:
1) 使用K-shell 算法计算网络中所有节点的ks 值,然后令IT=1;
2) 将当前网络中度最小的节点的迭代因子记为IT,并根据(4)式来计算这些节点的信息熵 ei+;
3) 从网络中删除这些度最小的节点;
4) 若网络中的节点个数为0,记录IT(max)=前迭代因子IT,跳转步骤5;否则,IT 加1,跳转步骤2;
5) 选择当前迭代因子IT 对应节点集合中信息熵最大的节点,按序放入节点重要性排序集合中.如果有多个节点信息熵值相等时,按照节点的序号从大到小将所有信息熵相等的节点全部放入重要性排序集合中;
当今,大部分高中学生在学习数学内容时都喜欢用单一的思维去审视和理解课本,而且都采用的是比较陈旧的方法来解答习题,在解题思维上显得比较呆板,缺乏变通.而习题又是教师对学生传达自己解题步骤和核心技巧的载体,所以提高学生的解题能力至关重要.
6) 如果IT=0,则跳转步骤7,否则IT 减1,跳转步骤5;
7) 如果网络中所有节点都已经被放入重要性节点排序集合中,则结束算法;否则,令前迭代因子IT=IT(max),跳转到步骤5.
算法伪代码如下所示:

计算出每个节点的ks 值和迭代因子IT 后,将迭代因子相同的节点按照信息熵值降序排列,如表2 所列.然后对节点进行排序,在最大迭代因子中选择最大信息熵的节点,显而易见应该选择节点5,然后在下一个迭代因子中选择节点1.在下一层中节点7 和8 具有相同的改进的信息熵值.按节点序号从大到小顺序放入,直到最小的迭代因子层次结构中选择信息熵最大的节点.此时,第一次迭代结束,下一次迭代继续从迭代因子最高中选择节点,直到所有节点都被选中.
在表3 中,使用了不同的方法对图1 中的网络进行排序.因为每种方法对节点重要性的识别原理不同,可以看出每种方法的排序结果略有不同.与IKS 算法相比,在迭代次数相同的情况下,本文算法识别出的重要节点在网络中的分布更广,这表明本文算法能更有效地避免在迭代次数相同时出现的富人俱乐部现象.

表3 由不同方法得出的排名: DC,CC,ks,Cnc,Cnc+,IKS,IE+Table 3.The ranking lists determined by different methonds: DC,CC,ks,Cnc,Cnc+,IKS,IE+.
4 数据集
选择了八种不同类型的网络,其详细信息见表4.1) NS 是一个由从事网络科学工作的科学家组成的合作网络[33].2) EEC 描述了一家大型欧洲研究机构成员之间的电子邮件交换[34].3) PB 是美国政治博客的网络[35].4) Facebook 描述了该网站的社交圈[36].5) WV 是一个维基百科网络,描述了投票记录[37].6) Sport 是从体育网络收集的有关Facebook 页面上的体育运动的信息(2017 年1 月)[38].7) Sex 是一个二分网络,其中节点是女性和男性.当男性写帖子表明与女性发生性接触时,他们之间的联系就会建立起来[39].8) CondMat 是一个协作网络,涵盖了凝聚态类别中作者论文之间的科学合作关系[40].
5 评价指标
5.1 SIR
在本文中,使用SIR 模型[18,19]来验证算法的表现能力.通过模拟SIR 模型的传播过程,可以得到每个节点的传播能力.在SIR 模型中,每个节点可以具有三种状态,即易感状态、感染状态和恢复状态.一开始,网络中的所有节点都处于易感状态,除了原始的受感染节点.在每个时间段中,每个被感染的节点都会以β的概率感染那些处于易感状态的邻居节点.同时,受感染节点将以λ的概率进入恢复状态并不会再次感染,当网络中没有受感染节点时,此传播过程结束.在选择传播值β时,它可以略大于网络流行阈值βth=〈k〉/〈k2〉,其中k是平均度,k2是二阶平均度[41].不同网络中的βth和βc值如表4 所列.当网络达到稳定状态时,记录恢复的节点总数,可以用来衡量节点的传播能力,对每个节点重复该过程来衡量它的传播效率.为了获得更准确的实验数据,SIR 模型传播过程的模拟次数由网络规模决定,在N<104的小型网络中模拟次数为1000 次,在N≥ 104大型网络中模拟次数为100 次.

表4 八个常见网络的基本拓扑特征,N 和|E|是节点和边的数量,〈d〉 和〈k〉 是平均距离和平均度,c 是聚类系数,βth 和βc 是流行阈值和传播值Table 4.The basic topological features of the eight real neworks,N and |E|,|E| are the number of nodes and edges,〈d〉and〈k〉 are the average distance and the average degree,c is the clustering coefficient,βth and βc are the epidemic threshold and the spread value.
5.2 相关系数
为了验证本文算法的性能,使用Kendall Tau[42]系数τ来衡量不同算法得到的节点重要性排名表与SIR 模型模拟的排名表之间的相关性,τ定义为
其中Nc和Nd分别是经过计算后相关性一致和不一致的数量.考虑具有N个节点的两个相关序列X和Y,X=(x1,x2,···,xn)和Y=(y1,y2,···,yn).任何一对二元组(xi,yi)和(xj,yj)(x≠y),当xi>xj和yi>yj或xi<xj和yi<yj这两个元素被认为是一致的,如果xi>xj和yi<yj或xi<xj和yi>yj它们是不一致的,如果xi=xj或yi=yj时不计入Nc和Nd.系数必须在—1 ≤τ≤ 1 的范围内,τ值越大,算法的排序结果越接近准确值.
5.3 单调关系
一个好的节点重要性排序算法应该是每个节点都被分配唯一的排名索引,如果在同一排名索引上出现多个节点,那么这样的算法被认为是存在缺陷的.为了定量测量不同指标的分辨率,使用了排名列表的单调性指标M(R)[22]:
其中Nr是具有相同索引值r的节点数.如果M(R)=1,表示该算法是完全单调的,并且每个节点被归类为不同的索引值,如果M(R)=0,则所有节点处于同一等级.单调性指标反映排序算法是否能很好地将节点区分开来.
5.4 平均最短路径长度
计算每对传播者之间的平均最短路径长度[43],这是一个基本指标.如果每个节点感染其他节点的概率相同,则初始感染节点越分散,传播范围越广.本文选择初始节点S作为度量,其定义为
其中|S|和S 分别表示选择的种子节点的数量和选择的初始节点集合;duv是从节点u到节点v的最短路径的长度.
6 实 验
6.1 相关系数
在表5 中显示了所提出的方法以及其他索引方法与SIR 模型模拟得出的排名R之间的Kendallτ秩相关系数,在表中加粗字体对应最优值.从表5可以看出经典DC 网络算法的性能并不太理想,在Sex 网络中,虽然IE+算法表现不是最佳,但与最优值对应的算法Cnc+相比相差不大,尽管本文提出的IE+算法并不是在所有网络中都表现最好,但在大多数网络中比其他算法更具有表现力.
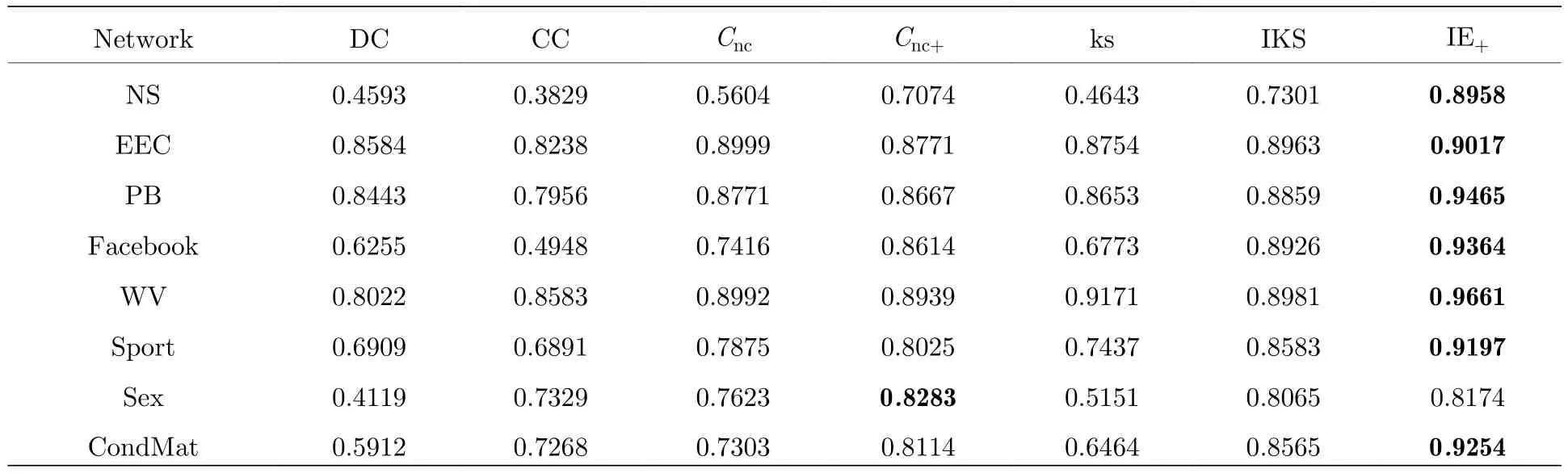
表5 SIR 模型中节点影响指数R 与五个中心性指数之间的Kendall TauTable 5.The Kendall Tau between the node influence index R of SIR model and five centrality indices.
6.2 单调关系
本文对各算法单调性进行了度量.算法的单调性越高说明该方法在确定唯一排名的能力越强,在表中加粗字体对应最优值.从表6 可以看出,在大多数网络中,本文提出的IE+算法与IKS 方法相比单调性较强.虽然在一些网络(如NS,EEC 等网络)单调性上表现不是最佳的,但在较大网络上本文算法单调性要比其它算法单调性要高.

表6 不同排序方法的单调性 MTable 6.The monotonicity M of different ranking methods.
6.3 平均最短路径长度
为避免富人俱乐部现象带来的影响,将排序得到的重要节点作为初始感染节点,在传播中当节点的感染概率相等时,为得到更广的传播范围则需要更多的初始感染节点分散在网络中.本文进一步测试了不同算法下不同比例的初始感染节点之间的平均最短距离.如图2 所示,通过不同算法排序得出的节点集合,选取了前2%—20%的重要节点,发现,除了EEC 网络,随着初始感染节点的比例不断扩大,重要节点之间的平均距离也在相应扩大.这更进一步说明了本文提出的IE+算法在避免富人俱乐部现象方面具有较为优秀的表现.
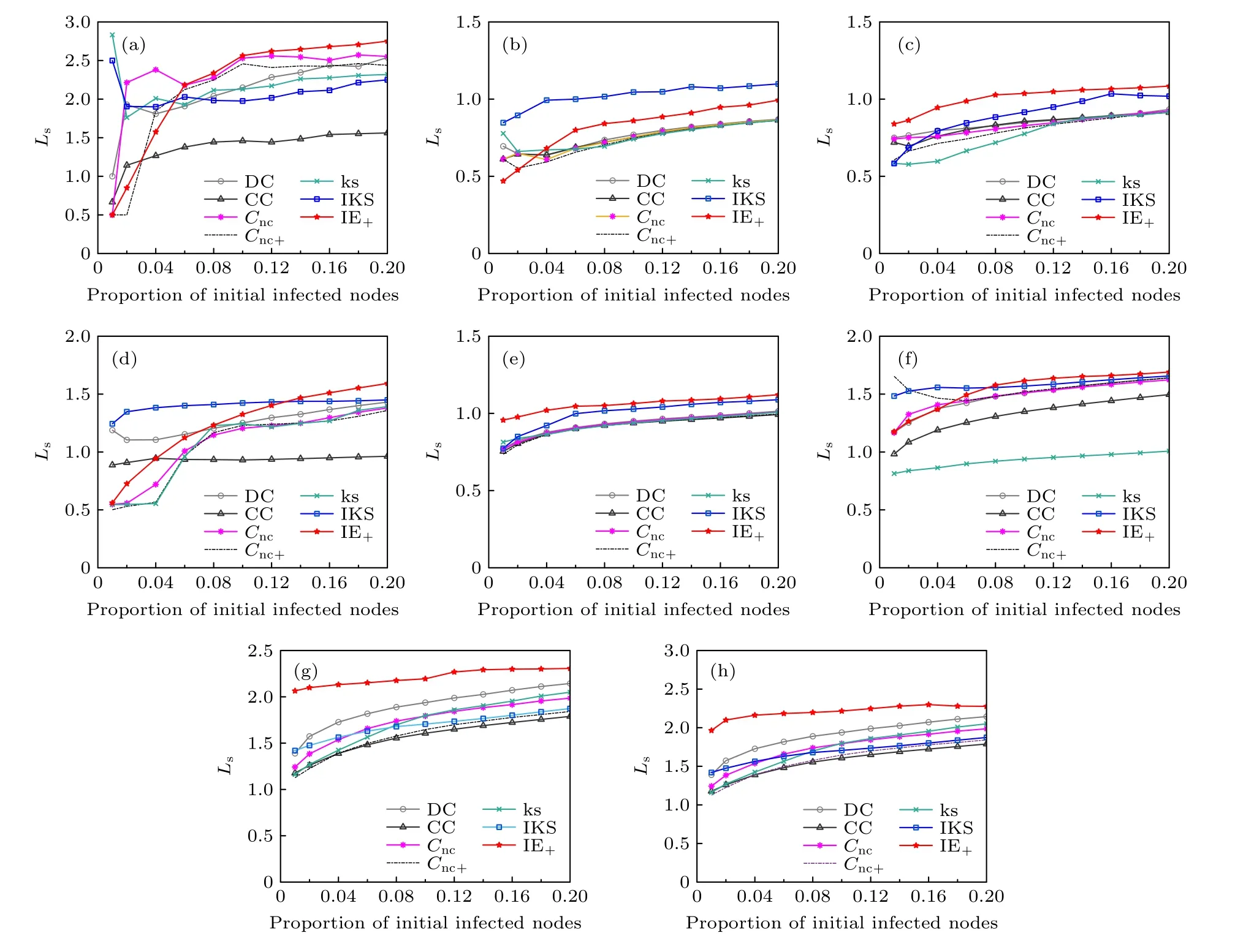
图2 不同方法下不同比例源扩散器的平均最短路径长度Ls (a) NS;(b) EEC;(c) PB;(d) Facebook;(e) WV;(f) Sport;(g)Sex;(h) CondMatFig.2.Average shortest path length Ls under different proportion of source spreaders by different methods: (a) NS;(b) EEC;(c) PB;(d) Facebook;(e) WV;(f) Sport;(g) Sex;(h) CondMat.
6.4 重要节点性能
对节点进行排序的最终目的是为了挖掘出对传播过程起关键作用的节点,换句话说,如果通过排序算法得到的重要节点对传播过程起不到很好的作用,那么这样的排序算法是不可靠的.本小节中从不同角度来评判IE+算法识别的重要节点的在网络传播中的表现情况.因在此部分讨论的是前k个重要节点在网络中的传播规模,本文引入一些个经典的影响力最大化算法(CI[44],CELF++[45],IRIE[46])作为比较算法.
在图3 中,选择网络中排名靠前的2%—20%个节点,计算在感染值为βc=2βth,λ=1,t=20 时感染的节点总数(不包括初始感染节点)与网络节点总数的百分比.我们惊讶地发现在大多数网络中,在CC,Cnc+,ks,IKS 算法下,随着种子节点数的增加,感染的节点总数反而在减少,这种现象是因为随着种子节点越来越紧密地聚集在一起,它们开始重叠,无法再有效地传播.而在NS,Facebook,Sex 和CondMat 网络中,IE+算法随着初始感染节点总数的增加相应的感染节点总数也在增加,在其余网络中虽然IE+算法随着初始感染节点的增加而略有下降,但下降趋势相对缓慢.除EEC的其余网络中,IE+算法优于经典的影响力最大化算法(CI,CELF++,IRIE),或与其表现出相同的优势.

图3 比较在相同时间内感染节点总数的百分比 (a) NS;(b) EEC;(c) PB;(d) Facebook;(e) WV;(f) Sport;(g) Sex;(h) CondMatFig.3.Compare the percentage of the total number of infected nodes over the same time period: (a) NS;(b) EEC;(c) PB;(d) Facebook;(e) WV;(f) Sport;(g) Sex;(h) CondMat.
在六个网络中,通过各排序算法计算后,选择排在前 10%的节点作为初始感染节点.在上述相同的感染概率和恢复率下,记录不同传播时间感染节点数与总节点数的百分比.从图4 可以看出,随着时间的增加,感染节点的数量先增加后趋于稳定,该现象是因为随着传播时间达到一定的时长时,网络处于稳定状态.在NS,Facebook,WV,Sport和CondMat 网络中,本文提出的IE+算法具有最广泛的传播范围.
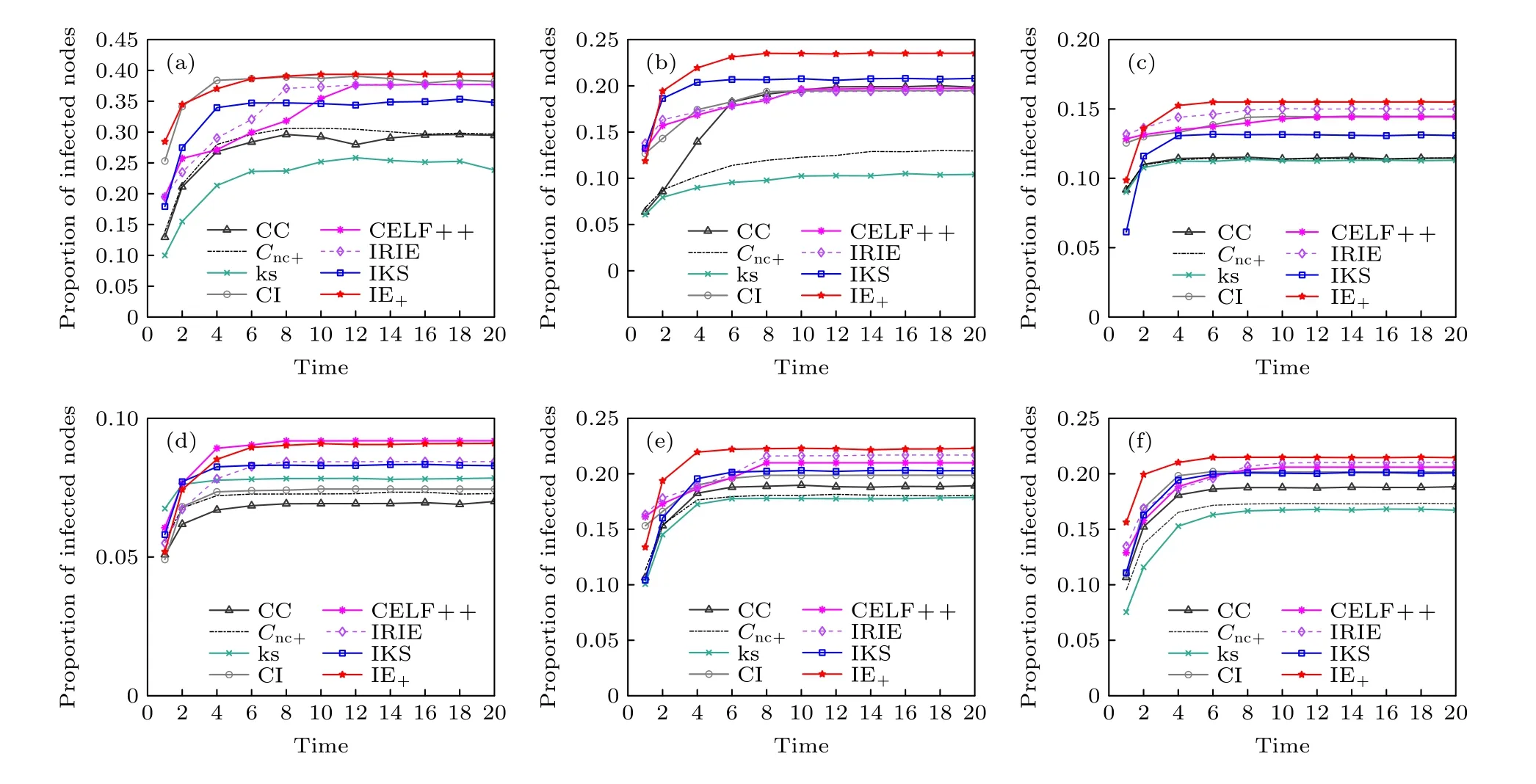
图4 比较不同传播时间 t 中前 10% 种子节点感染节点的百分比 (a) NS;(b) Facebook;(c) WV;(d) Sex;(f) Sport;(f) CondMatFig.4.Compare the percentage of nodes infected by the top 10% of seed nodes in different propagation time t: (a) NS;(b) Facebook;(c) WV;(d) Sex;(f) Sport;(f) CondMat.
6.5 时间复杂度
在时间复杂度方面,由于需要节点的ks 值来计算节点的信息熵,所以本文所提出的IE+算法的时间复杂度主要体现在迭代因子IT 和ks 值的计算上.计算节点迭代因子IT 和节点的ks 值的时间复杂度都是O(n),即本文算法的时间复杂度是O(n),IKS,Cnc,Cnc+,DC,ks 的时间复杂度都是O(n),CC 的时间复杂度为O(mn).因此,就时间复杂度而言,我们的算法并不比其他算法具有更高的时间复杂度.在相同的时间复杂度下,IE+算法在几个考察指标上都具有良好的表现.
7 结论
在复杂网络分析中,对节点的影响力进行识别和排序是一个基础性工作.本文的研究目的是将信息熵与迭代因子相结合,提出一种新的节点影响力评价指标,通过排序算法得到的重要节点即使在受到富人俱乐部现象的影响下也依然具有很好的传播效果,基于该指标,利用迭代因子和改进的信息熵,提出了衡量节点重要性方法IE+.通过在Kendall Tau 相关系数、单调性、平均最短距离以及节点性能上的对比实验,表明本文提出的算法能有效对节点的重要性进行评估,并能很好地规避富俱乐部现象,对复杂网络中的重要节点识别工作具有较强的借鉴意义.
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:02
中国生殖健康(2020年4期)2021-01-18 02:58:26
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
甘肃教育(2020年21期)2020-04-13 08:09:24
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
电子测试(2017年12期)2017-12-18 06:35:48
雷达学报(2017年6期)2017-03-26 07:52:58
