
基于互信息参数优化BP神经网络的生物质发电量预测研究*
2023-03-04 04:59佟敏史昌明马善为崔亚茹李凯
中国农机化学报 2023年2期
佟敏,史昌明,马善为,崔亚茹,李凯
(1. 国网内蒙古东部电力有限公司电力科学研究院,呼和浩特市,010020;2. 华北电力大学新能源发电国家工程研究中心,北京市,102206)
0 引言
二氧化碳排放引起环境污染、温室效应等问题日益严重,严格限制二氧化碳等温室气体排放受到世界各国的普遍重视[1]。化石能源发电是二氧化碳排放的重要来源。与化石能源相比,生物质能是唯一具有负碳属性的可再生能源。以生物质发电替代燃煤发电被视为一种行之有效的碳减排方法,受到学者们的普遍推崇[2-3]。据统计,我国生物质发电的装机容量处于持续增长阶段[4],截至2021年,生物质发电装机容量达 3 319 万千瓦,但遗憾的是,目前生物质的利用率仍不到其总可利用量的13%[5]。
生物质发电作为现有应用最广、规模最大的生物质能利用方式,在清洁电能替代方面具有极大潜力。与风能[6]、太阳能[7-8]等其它可再生能源发电相比,生物质发电受气候影响小,发电量稳定,而且可以参与电力调度、电网调荷,维持电网的稳定运行。然而,实现这一目标的前提是准确预测生物质发电量。相比燃煤发电[9-10],生物质发电发展较晚,目前生物质发电研究更多地关注于发电模式和发电机组优化,鲜有研究注重生物质发电量的预测。
现阶段,关于发电量预测的研究主要集中于传统化石能源发电或者风能和太阳能等不稳定可再生能源发电,学者们开发了众多的发电量预测方法,包括基于能量守恒的“以热定电”发电量计算[11]、BP神经网络[12-13]、支持向量机(SVM)[8]、长短期记忆人工神经网络(LSTM)[14]、Elman神经网络[9]、主成分分析(PCA)优化神经网络[15]等。其中,神经网络预测模型作为目前研究最广、发展最为迅速、智能化程度最高的模型算法,在发电量预测的准确性、精度、稳定性等方面都表现出较大优势。
相比燃煤等化石能源发电,生物质发电发展仍不成熟,生物质发电的关键影响因素尚不清晰,包括物料参数、锅炉参数、汽机参数、烟气参数等众多参数均能影响发电过程。基于神经网络的生物质发电模型缺乏理论指导,如果参数选择不当,神经网络容易学习干扰信息,不仅会降低神经网络预测的准确性,而且会增加神经网络计算量。值得庆幸的是,在其它应用领域,众多学者们提出了大量的参数优化方法,包括Pearson相关分析[16]、Spearman相关分析[17]、平均影响值(MIV)分析[18]、互信息(MI)分析[19]、灰色关联度分析[20]等。其中,Pearson和Spearman是目前最为普遍的线性相关性分析方法,而互信息分析对于参数之间的非线性相关性具有较好的鉴别效果,MIV则可直接反应参数变化对神经网络预测结果的影响程度。基于此,本文提出采用了Pearson相关分析、Spearman相关分析、平均影响值(MIV)分析和互信息分析对生物质发电量关键影响参数进行优选,以期建立参数优化的BP神经网络模型,从而实现生物质发电量的准确预测。
1 BP神经网络模型介绍
BP神经网络作为目前应用最广泛的神经网络模型,是一种按照误差反向传播算法训练的多层前馈神经网络。通常而言,BP神经网络至少包括输入层、隐含层和输出层三种网络拓扑结构。隐含层也可设置为多层,每层神经网络设有数量不等的神经元,理论上只要隐含层设置足够多的神经元数,即可建立任意非线性映射模型。一般而言,神经网络输出层设置为目标变量,输入层设置为目标变量的影响因素,二者的神经元节点数由训练样本决定,隐含层节点数没有通用的设置方法,可以采用如下经验公式确定。
(1)
式中:l——隐含层节点数;
m——输出层节点数;
n——输入层节点数;
v——常数,一般取1≤v≤10。
2 样本参数优化方法
2.1 样本参数组成
本研究以某生物质直燃发电厂为研究对象,对电厂实际运行过程中的发电量进行建模预测。通常,影响生物质直燃发电量的因素主要包括燃料参数、锅炉参数、汽轮机参数、环境参数等。因此,本文从该电厂收集了发电量以及相关影响因素参数,包括变压器损耗X1(kW·h)、电厂用电量X2(kW·h)、秸秆消耗量X3(t)、锅炉蒸汽产量X4(t)、发电补水量X5(t)、秸秆热值X6(kJ/kg)、收到基水分X7(%)、收到基灰分X8(%)、锅炉主汽压力X9(MPa)、锅炉主汽温度X10(℃)、送风机入口温度X11(℃)、排烟温度X12(℃)、飞灰含碳量X13(%)、炉渣含碳量X14(%)、汽轮机主汽压力X15(MPa)、汽轮机主汽温度X16(℃)、给水温度X17(℃)、排汽温度X18(℃)、凝结水温度X19(℃)、真空度X20(kPa)、循环水入口温度X21(℃)、循环水出水温度X22(℃)、当地大气压X23(kPa)共计23个参数。
2.2 相关系数优化方法
相关系数是目前最常用的判断变量之间相关程度的统计指标,根据研究对象的不同,相关系数具有多种定义方式,最常用的相关系数主要有Pearson相关系数和Spearman相关系数。
Pearson相关系数又称线性相关系数,一般用于衡量参数之间的线性相关程度,其定义式如下
(2)
式中:μX——参数X的平均值;
μY——参数Y的平均值。
一般而言,Pearson相关系数的绝对值越接近1,表示参数之间的线性相关程度越高;绝对值越趋向于0,表示参数之间的相关程度越差。
Spearman相对系数又称秩相关系数,其不关注参数之间具体值大小,通过对参数值进行排序,进而统计数据排序之间的相关程度,定义式如式(3)所示。
(3)
式中:di——参数之间的排序差值。
与Pearson相关系数类似,Spearman相关系数的值域同样在-1和1之间,其绝对值的大小表示参数的相关程度。不同的是,Spearman相关系数不考虑参数的真实值的大小,也能在一定程度表示参数之间的非线性相关性。
2.3 互信息分析方法
互信息(MI)是信息论中提出的信息度量方法,它可以看成一个随机变量包含另一个随机变量的信息大小。当变量之间具有某种关联关系,变量之间的随机性越小,互信息就越大。互信息定义式如式(4)所示。
(4)
式中:p(x,y)——参数X、Y的联合密度分布函数;
p(x)、p(y)——X、Y的边缘密度分布函数。
一般而言,互信息满足对称性和正定性,即I(X,Y)=I(Y,X),I(X,Y)≥0;当且仅当X、Y独立,I(X,Y)=0。
2.4 MIV分析方法
平均影响值(MIV)被认为评价参数的最佳指标之一,其核心思想是利用神经网络模型测试参数变动对目标参数的影响。具体计算过程是:首先利用原始数据训练获得一个神经网络模型,然后利用所获得的神经网络依次对待评价变量变动±10%时,计算目标参数的差值,最后取平均值,即为MIV值。
3 工程实例分析
3.1 发电量影响参数优化分析
本文从国内某生物质电厂采集了35组不同时间段的生物质发电量及其影响因素的样本数据,部分数据如表1所示。
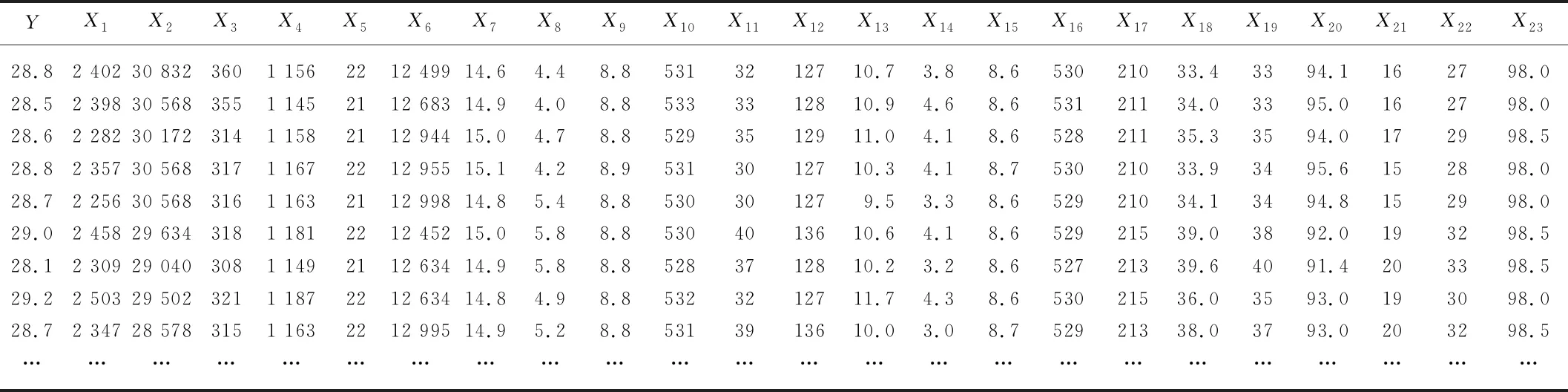
表1 电厂实际运行数据Tab. 1 Actual operation data of power plants
对原始数据进行直接分析,可以发现不同时间段生物质燃料特性、燃烧参数、锅炉参数、汽机参数等均存在一定的波动性且不同参数的波动情况差异较大,相应的生物质直燃发电量也存在一定波动性,很难直接看出参数之间的关联性。基于此,首先采用相关分析、互信息分析和MIV分析对发电量与其影响因素的关联性进行分析。需要指出的是,进行MIV分析时,需要先建立神经网络模型,再通过所建立的神经网络模型对影响因素一一测试。考虑到现阶段缺乏生物质发电量的关键影响因素的研究指导,因此本研究将全部采集参数均用于神经网络建模研究,分析结果如表2所示。

表2 发电量与影响参数的关联分析Tab. 2 Correlation analysis between power generation and influencing parameters
从表1、表2可以看出不同优化方法所得的结果差异较大,以相关性大于0.5为发电量关键影响因素判定标准。Pearson相关分析所得关键参数为锅炉蒸汽产量、发电补水量、锅炉主汽压力、汽轮机主汽压力;与Pearson相关分析相比,Spearman相关分析则仅仅多了变压器损耗一个关键参数,这可能是因为这两种相关系数的原理基本相同导致的分析结果较为相近;MI分析认为秸秆消耗量、锅炉蒸汽产量和汽轮机排气温度为影响发电量的关键因素;MIV分析则获得了8个关键影响因素,分别为电厂用电量、锅炉蒸汽产量、锅炉主汽压力、锅炉主汽温度、汽轮机主汽压力、汽轮机主汽温度、真空度和当地大气压。
3.2 不同方法优化神经网络预测分析
随机选取25组样本作为训练样本,分别利用上述优化参数建立并训练神经网络模型,同时利用未优化样本建立神经网络模型作为对比,利用所建立的神经网络模型对剩余10组样本进行分析测试,结果如图1所示。从图1中可以明显看出,未优化神经网络的预测误差明显大于优化样本建立的神经网络,不同优化方法的预测效果也相同,整体而言MI优化方法获得误差最小。对未优化神经网络、Pearson优化神经网络、Spearman优化神经网络、MI优化神经网络和MIV优化神经网络预测的平均相对误差进行计算,如表3所示,可以看出五种方法预测的平均相对误差分别为4.59%、2.07%、1.72%、0.66%和3.87%,这进一步证实了MI优化效果最佳。
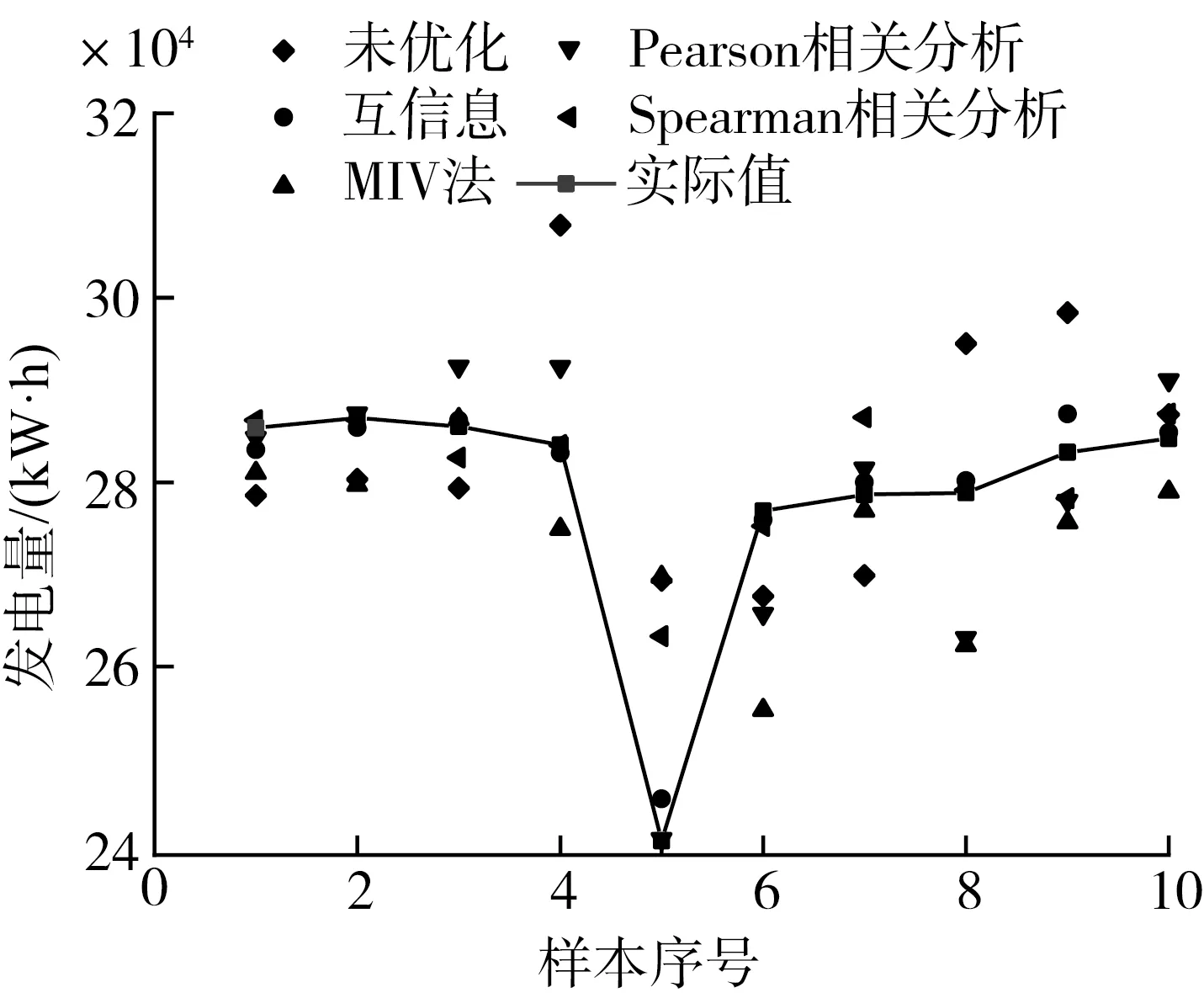
图1 不同方法建立神经网络模型的发电量预测测试
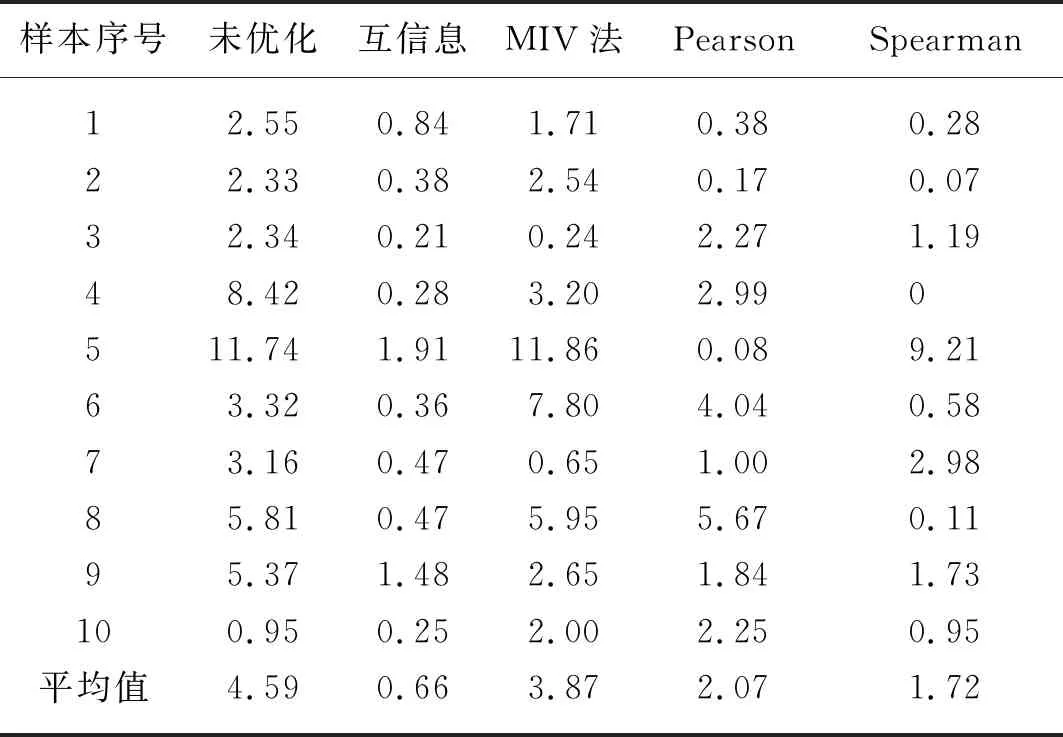
表3 不同方法建立神经网络预测发电量的相对误差Tab. 3 Relative error of power generation by neural networks with different methods %
从样本优化分析上看,Pearson和Spearman相关分析主要认为锅炉蒸汽产量、锅炉主汽压力、汽轮机主汽压力对发电量影响较大,即发电量主要取决于锅炉参数和汽轮机参数;MI分析则认为秸秆消耗量、锅炉蒸汽产量和汽轮机排气温度对发电量影响最大,即MI充分考虑到了原料因素、锅炉因素和汽轮机因素对发电量的影响,这也和实际情况较为相符,因此MI获得优化效果最佳。相比而言,MIV被认为是参数评价的最佳指标之一,但其优化效果最差,这是因为本研究中MIV计算采用的神经网络选择了全部参数作为输入变量,而实际上这些参数存在一定的干扰因素,使得神经网络建模效果较差。这也证实神经网络过多学习干扰信息,会降低其预测准确度。
3.3 互信息参数优化的神经网络模型发电量预测
基于MI样本优化结果,重新构建并优化训练神经网络,探究隐含层节点数对预测误差的影响。随机选取25组样本作为训练样本,其余10组样本作为测试样本,结果如图2所示。
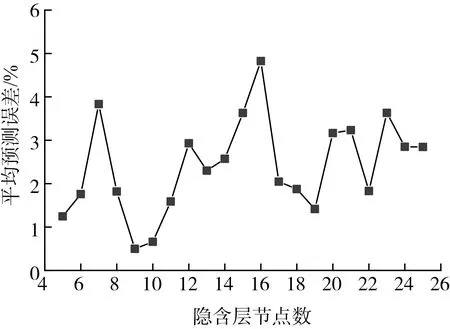
图2 优化样本的BP神经网络预测
从图2可以看出,对神经网络拓扑结构,即隐含层节点数进行优化设置,对神经网络平均预测误差在5%以内波动变化,当隐含层节点数为9时,神经网络模型预测误差可以进一步降低至为0.50%。
基于上述神经网络,进一步对神经网络预测效果进行测试,分别探究秸秆消耗量、蒸汽产量和排气温度对发电量的影响特性。测试方法如下:探究秸秆消耗量对发电量影响时,控制蒸汽产量和排气温度为定值,秸秆消耗量在实际运行的最小值与最大值之间变化,对发电量进行预测;其它两个参数也同样采用相同的测试方法,测试结果如图3~图5所示。可以看出,秸秆消耗量、蒸汽产量与发电量基本呈非线性正相关关系,排气温度与发电量呈非线性负相关关系,这与电厂实际运行结果基本一致。

图3 秸秆消耗量对发电量影响的预测曲线
对发电量预测值进行曲线拟合,发现秸秆消耗量和蒸汽产量与发电量的关系符合BidoseResp函数模型,排气温度与发电量的关系符合指数下降模型,三者的拟合度均在0.95以上。对生物质直燃发电过程分析发现,秸秆消耗量决定了系统的总输入能量,蒸汽产量反映了系统的有效吸收能量,这两个参数间接反映了生物质的燃烧效率和锅炉效率;而排气温度表征了乏汽能量损失,一定可以表征蒸汽轮机的发电效率。因此,这三个因素共同决定了最终的发电效率。
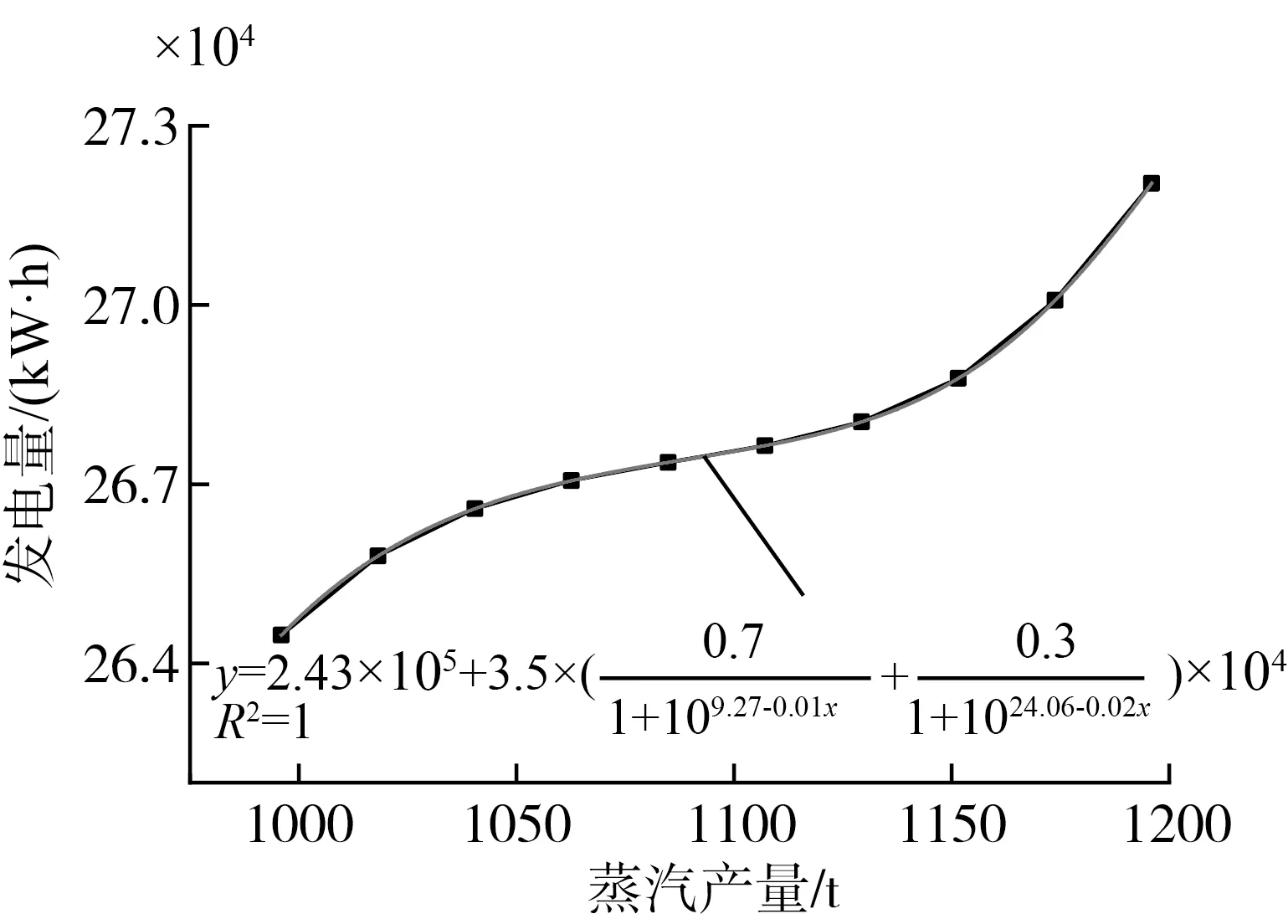
图4 蒸汽产量对发电量影响的预测曲线

图5 排气温度对发电量影响的预测曲线
4 结论
本文提出了一种基于互信息参数优化BP神经网络的生物质发电量预测方法。生物质直燃发电量影响因素众多且关键影响因素尚不清晰,通过相关系数分析、MI分析和MIV分析对影响因素进行优选分析发现,虽然不同方法获得的特征关键参数均不相同,但基于优化样本建立的神经网络模型预测误差均有所降低,其中MI分析优化效果最佳,可使神经网络预测相对误差从4.59%降至0.66%;通过进一步优化神经网络参数,预测相对误差可降低至0.50%。基于优化神经网络模型分析了所筛选关键参数对发电量的影响规律,结果表明,秸秆消耗量和蒸汽产量与发电量呈非线性正相关关系,排气温度与发电量呈非线性负相关关系,这与实际发电结果一致。
猜你喜欢
能源工程(2021年5期)2021-11-20
水泵技术(2021年6期)2021-01-26
生物质化学工程(2021年1期)2021-01-26
中国造纸(2020年9期)2020-10-20
中国煤炭(2020年2期)2020-01-21
水电站设计(2018年3期)2018-03-26
电站辅机(2016年4期)2016-05-17
当代化工研究(2016年2期)2016-03-20
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西北工业大学学报(2015年4期)2016-01-19
