
基于强化学习的D3QN拥塞控制算法
2023-03-04 06:37过萌竹
计算机技术与发展 2023年2期
过萌竹,孙 君
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
大规模机器类通信(massive Machine Type Communication,mMTC)是第五代移动通信技术的三大应用场景之一[1],在远程医疗、自动驾驶、智能交通等应用场景中发挥着关键作用[2]。在传统接入方法下,MTC设备总是会选择最佳信号质量的演进型Node(evolved Node B,eNB)进行接入,大量的MTC设备同时接入会引发碰撞,造成网络拥塞[3]。这最终将导致无线电接入网拥塞、超低的设备复杂性和有限的电池寿命[4-5]。
起初,专家学者提出ACB[6](Access Class Barring)以及扩展ACB方案[7-8]来解决拥塞问题。通过限制设备的接入数量,减少拥塞并提高接入成功率。这些方案的局限性在于大规模设备带来的高延迟以及不同到达率设备带来的前导码分配不均[9]。
因此,目前的研究倾向于机器学习辅助的接入控制方案。文献[10]提出了一种基于Q学习算法的设备接入控制方案,该方案利用Q学习来动态调整ACB因子的值,达到优化接入的目的。文献[11]使用吞吐量和延迟作为强化学习的奖励,MTC设备根据奖励选择基站,从而增加了设备的吞吐量并减少了延迟。文献[12]结合NOMA(Non-Orthgonal Multiple Access)技术和Q学习,通过地理位置分区复用前导码,从而提高接入成功率。文献[13]提出了一种协作分布式Q学习机制,这能够为MTC设备的传输找到唯一的RA(Random Access)时隙。文献[14]提出了一种基于强化学习的ACB方案, 调整了所有设备的禁止因子和延迟敏感设备的缩放因子,以保证大规模MTC设备的随机接入。文献[15]提出一种基于Q学习的随机接入算法,优先为H2H(Human to Human)设备提供服务并最大化M2M(Machine to Machine)设备接入数量,使M2M设备业务不影响H2H业务。
然而,随着MTC设备数量增多,上述方案的有效性大打折扣。因此,需要设计出一种能够适应大规模接入场景的方案。该文采用基于深度强化学习的方法,在考虑的场景中,基站可以知道冲突的设备数量,MTC设备通过探索或经验动态地选择基站。在开始时,因为不确定环境知识的原因会采取探索行动,随着训练次数越来越多,智能体会执行处于这一状态时能获得最大奖励的动作。该方案可以让MTC设备准确地选择较空闲的基站进行接入,减少了接入的延迟,也增加了接入的容量。
1 系统模型
如图1所示,该文考虑四个基站共同服务的区域,四个基站都有各自的前导码池。MTC设备可以向任意的基站发送信号,争夺前导码资源按照二步RA进行接入。二步RA是对四步RA的一种增强,其优点是通过简化现有的分别携带前导码和有效负载的四步RA来减少延迟,它可以用来检测发生冲突的前导码的数量,进而可以检测发生冲突设备的数量。
在RA过程开始之前,基站周期性地广播系统信息块,其中包括用于同步的多个关键参数、前导信息和为RA预先配置的资源。在二步RA的第一步中,MTC设备发送一个前导码和PUSCH(Physical Uplink Share CHannel)上的有效负载。利用接收到的标记前导码,基站可以检测每个前导码是否发生冲突,基站计算出当前发生冲突的设备总数K并通过下行链路传送到边缘侧。

图1 系统模型
多个MTC选择同一前导码会导致前导冲突,无法在当前RA时隙传输数据,这些设备不需要退避时间,可以在下一个RA时隙进行重新接入。该文考虑的情况为MTC设备最多重传1次。进行随机接入的MTC设备分为两类,一类是上一个RA时隙中冲突的设备,另一类是新激活的MTC设备。新激活的MTC设备服从速率参数为λ的泊松分布。

(1)
由于服从参数为λ的泊松分布,有:
(2)
因此,η可被改写成:
(3)

2 基于强化学习的D3QN算法
2.1 强化学习框架设计
Q学习是强化学习中value-base的算法,Q即为Q(st,at),表示在状态st下,采取动作at能够获得的奖励的期望。Q学习算法的主要思想就是将状态和动作建立成一个Q表来存储Q值。根据这个表格来选取可获得最大奖励的动作。然而,当状态空间特别大时,在巨大的Q表中找到最优策略具有挑战性。因此,面对大规模MTC接入问题,该文采用深度强化学习(Deep Reinforcement Learning,DRL)来代替传统的Q学习。
DRL基本思想是用一个深度神经网络来近似表示估值函数。这个深度神经网络被称为深度Q网络(Deep Q-network,DQN)。DQN算法的目标是逼近真实的Q(st,at),输入是可能的状态,输出是该状态下所有动作的Q值。
大规模MTC设备的随机接入问题,实际上是一个决策问题。该文利用DQN来作一个最优决策。DQN的算法流程如图2所示。

图2 DQN算法流程
将每一个MTC设备定义为agent,agenti=MTCDi,1≤i≤MTCDmax。

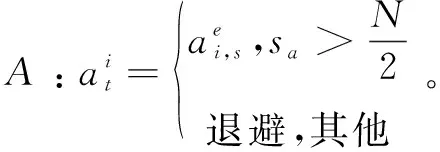
奖励R:奖励的定义为:
(4)
其中,K为发生冲突的设备数量。
算法的目标是最大化预期奖励,将RA时隙t时未来的累计奖励定义为Ut。
(5)
每个基站都有前导码池,每个MTC设备在M 2M帧中的每个前导码都有单独的Q值,并在每次接入尝试时进行更新。Q值的更新公式为:
(6)
其中,α是学习率,Rt+1是奖励或惩罚,取决于接入是否成功。采用贪婪策略,agent会选择Q值最大的动作。DQN利用一个目标网络和在线网络来稳定网络的整体性能。目标网络更新其权重,以最小化损失函数,定义为:
(7)

(8)

2.2 DQN算法改进
经典的DQN算法无法有效解决大规模场景中的连接问题,并且在决策能力以及收敛速度上有着很大的缺陷,因此需要对传统的DQN算法进行改进。该文所提的D3QN算法在经验回放采样、目标值计算、网络结构中都做出了改进,具体改进如下文所述。
2.2.1 优先经验回放
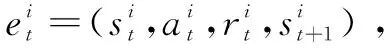
在D装满的时候,新的数据会覆盖旧的数据。在学习的时候,网络不仅学习当前的数据,还可以通过随机从D中采样小批量数据来进行训练,通过减少训练样本之间的相关性,经验回放的方法确保了模型的收敛,并且使得网络的训练更加高效。然而从经验中均匀采用并不是一个最佳的方法,因为从全局来看,刚开始的经验占总经验的比重很小,被采样到的概率是很小的。但这部分经验具有较大的时间差分误差,是值得关注并且学习的,因此需要根据优先级对经验库中经验进行采样。在回放缓存中,将经验按照时间差分误差从高到低进行排序,定义优先级为:
(9)
每个经验所对应的采样概率为:
(10)
其中,rank(i)是经验在回放缓存中的排名。通过优先经验回放,网络的训练速度将会更快。
2.2.2 Dueling Double DQN
如式(8)所示,传统DQN在计算目标Q值时,需要穷举所有的动作,把最高Q值加上奖励变成目标Q值。网络误差会导致得到的目标Q值是被高估的。对于目标Q值被高估的问题,在D3QN中,使用在线网络去选择动作,目标网络去计算Q值,通过在线网络和目标网络的交互,有效避免了DQN算法的目标值估计过高问题。如下所示:
(11)
除了目标值计算方式不同之外,D3QN与DQN还存在网络结构上的不同。如图3所示,传统的DQN直接输出Q值,D3QN将Q网络分成两部分,第一部分仅与状态s有关,与具体采用的动作a无关,记为V(s)。第二部分同时与状态s和动作a都有关,记为A(s,a),那么最终输出的Q值可以表示为:
Q(s,a)=A(s,a)+V(s)
(12)
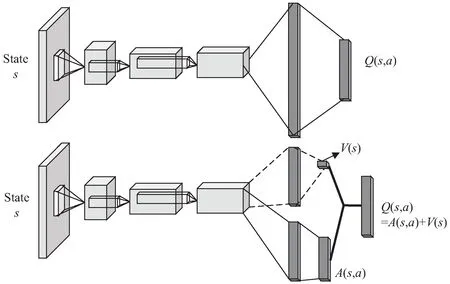
图3 传统DQN与D3QN网络结构对比
在传统DQN中,当需要更新某个动作a的Q值,会采用直接更新Q网络的方法让这个动作a的Q值提升。在D3QN中,更新某个状态s的值时,不是简单地更新某个动作的值,而是把所以动作的Q值都更新了一次。因为这个区别,D3QN算法在更新网络的时候,可以用更少的次数让更多的值进行更新,网络的训练速度会更快。根据以上改进,给出了基于强化学习的D3QN算法详细过程,如算法1所示。
算法1:基于强化学习的D3QN算法。
1.初始化replay memory D,初始化DQN网络参数θ,初始化目标网络替换频率M。
2.初始化在线网络Q(s,a;θ)。
4.通过消息传递初始化网络的状态st。

6.基站向基站e发送接入请求,根据接入的成功与否以及式(4)获得相应的奖励或惩罚。
7.通过消息传递控制器得到下一个状态st+1。

9.从D中按照式(10)采样小批量的N个样本。
11.通过梯度下降最小化损失函数(7)。
12.经过M次,将在线网络的参数θ复制给目标网络的参数θ-,θ-=θ。
13.结束循环。
3 仿真结果
本节对所提拥塞控制方案进行仿真。网络由4个基站和若干设备组成。设置用户数为50个,基站的半径为500米,可用前导码为32个,由4个基站平分。D3QN网络的超参数设置如表1所示。

表1 D3QN仿真参数
在其他超参数都固定的情况下,设置参数λ为10,分别测试了不同学习率α对算法收敛性能的影响,结果如图4所示。从图中可以看出,在训练初期,样本数不多,过高的α训练效果是很好的,但图中α为0.1时发生了过拟合现象。随着样本数的增加,学习任务越来越复杂,过高的α导致收敛不理想,并且还降低了接入成功率。因此选择学习率0.000 1。
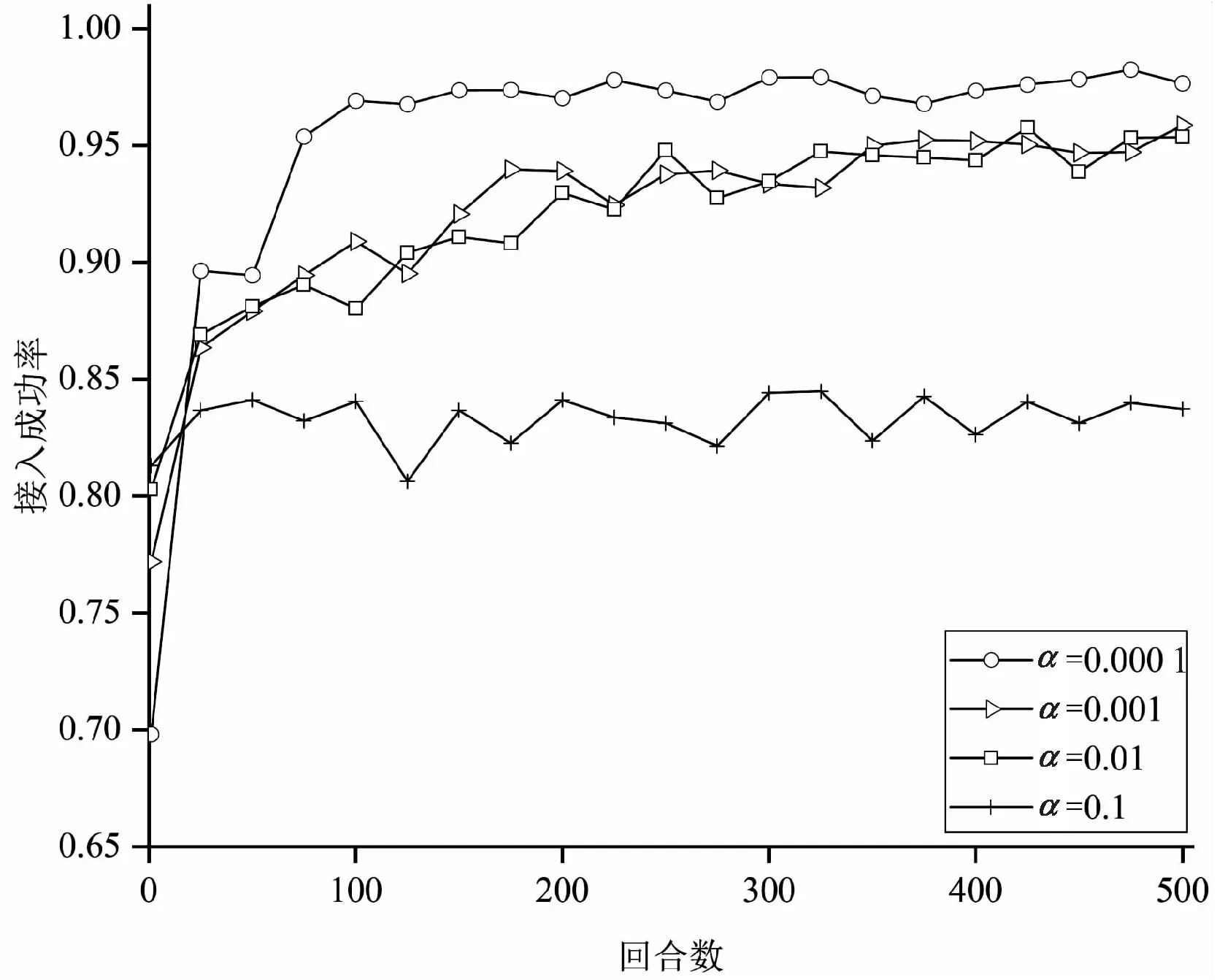
图4 不同学习率α下的训练收敛性
在其他超参数都固定的情况下,设置参数λ为10,分别测试了不同折扣率γ对算法收敛性能的影响,结果如图5所示。从图中可以看出,不同折扣率γ都能够使网络收敛到同样好。γ为0.90时,约100个回合就收敛了。γ为0.95时,前500个回合依旧有明显震荡。而γ为0.99时,需要更多的回合才能收敛。折扣率γ越高,表示希望agent越多关注未来的情况,这比关注当前要难得多,导致训练变得缓慢和困难。因此选择折扣率为0.90。

图5 不同折扣率γ下的训练收敛性
如图6所示。对于不同的λ,接入成功率首先随着训练回合数的增加而增加,然后逐渐稳定,这证明了所提出的基于深度强化学习的方案是可以收敛的。稳定时的接入成功率随着λ的增加而下降,这是由于新激活的MTC设备增加,网络中竞争前导码资源的设备增多,增加了碰撞概率。

图6 不同λ下的接入成功率
图7给出了所提方案与其他方案(文献[13])以及传统方案的比较结果。在相同条件下,所提方案明显优于传统方案和其他论文中的方案。例如,当λ=10时,基于深度强化学习的方案对比其他方案,接入失败率可以从5×10-2降低到1.41×10-2。所提方案将接入失败率下降了71.8%,与传统方案作比较,所提方案将接入失败率下降了85.7%。这是因为DRL追求的是最大化的累计奖励,因此在每一次选择基站的时候,会选择从长远出发来看最不容易发生冲突的那个基站。从图中可以看出,所提方案在新接入设备增多时有更好的效果,接入成功率随λ的增加下降的幅度明显小于其他方案,这说明此方案可以提供更佳的接入性能。

图7 不同方案对比
4 结束语
该文提出了一种基于DRL的前导码分配方案,用于MTC设备在二步随机接入中选择合适的前导码。通过基站的冲突设备数量来调整RL中奖励的大小,设备将选择较空闲的基站进行接入,减少了可能发生的冲突。采用D3QN以及优先经验回放来改善网络的训练,网络将会快速收敛。与其他方法和传统方法对比表明,该方案能够获得更高的接入成功率。
猜你喜欢
党课参考(2021年20期)2021-11-04
福建基础教育研究(2020年1期)2020-05-28
小哥白尼(军事科学)(2019年6期)2019-03-14
党课参考(2018年20期)2018-11-09
网络安全与数据管理(2018年8期)2018-08-27
电子制作(2017年8期)2017-06-05
探索科学(2017年4期)2017-05-04
广东通信技术(2016年9期)2016-10-25
中国交通信息化(2016年8期)2016-06-06
移动通信(2015年17期)2015-08-24
