
基于知识图谱的服装问答系统
2023-03-04 06:43赖佳扬张晓滨马瑛超
计算机技术与发展 2023年2期
赖佳扬,张晓滨,马瑛超
(西安工程大学 计算机科学学院,陕西 西安 710048)
0 引 言
随着社会的不断发展,消费者的购物方式发生了巨大的改变。服装作为生活中的必需品,已经成为网上购物的第一大商品。由于服装需求的差异性,消费者购物选择时需要频繁地与商家进行沟通。这不但对商家的知识提出了挑战,更重要的是人工服务需要大量的人力资源[1]。知识图谱作为一种结构化的知识库,通过实体关系相互连接,已经成为人工智能应用于知识问答中的重要基础。目前一些大型知识图谱(如CN-DBPedia)[2-3]已得到了较好的应用。服装作为传统行业,其领域内的智能化技术仍在发展。知识问答作为知识图谱下游应用的重要组成部分,问答方法旨在对用户的输入信息进行分析和挖掘,而后利用知识图谱进行答案的搜索,最后反馈给用户。基于知识问答构建智能客服系统能够很好地提高服装智能化水平并减少人力资源需求。
1 研究现状
基于知识图谱的问答方法大致可分为三类:基于语义解析的方法、基于信息检索的方法以及基于知识嵌入的方法。
基于语义解析的方法是利用直接映射或者神经网络方法将自然语言映射成为结构化的表达,而后通过对知识图谱的子图进行匹配完成答案的检索。早期Steedman等人[4]提出组合范畴语法,利用词汇表完成问句到结构化表达的转换。孟明明等人[5]提出了一种语义查询拓展方法解决从知识库中无法搜索到理想答案的问题,实现了对知识图谱内容的多语义拓展。上述直接映射的方法依赖于人工制定规则,因此该类方法的适应性很差。Dong等人[6]基于神经网络进行语义解析,他们通过将映射问题转换为翻译问题,通过一个基于注意力的编码器-解码器结构完成问句的映射。Zhu等人[7]提出了一种Tree2seq模型,该模型将句子映射到知识库的特征空间中以加强其映射的准确性。基于语义解析的方法在问答中是较为规范的流程,这类方法能够有效地减少问答的检索时间,但此类方法的误差对任务的后续影响较大,并影响到最终的结果。
基于知识嵌入的方法则起源于知识图谱推理的发展,包括TransE[8]、TransR以及ITMEA[9]等知识图谱嵌入模型的提出都为知识图谱问答提出了新的思路。Huang等人[10]提出一种基于嵌入的问答方法,该方法将问题作为输入,并对其进行知识图谱嵌入的映射,在知识图谱的表示中找到其相似度最高的表示,而后将实体作为答案进行输出。Niu等人[11]将路径和多关系问题间的语义关系引入问答任务,并基于此提出了PKEEQA方法,通过实验对比,该方法提高了多关系问答的性能。然而基于嵌入的方法由于需要将图谱和问句进行映射,从而降低了方法的可解释性,这在问答环境下是十分致命的。
基于信息检索的方法则是利用问句中的实体对知识库进行搜索,利用其相关子图进行搜索,进而构成答案集合。Yao等人[12]利用句法依存树对问句进行解析,分析其问题焦点,而后对知识图谱进行检索,最终通过对比问题焦点、问题核心动词等方法完成答案的确定。Dong等人[13]利用Freebase进行问答系统的构建,该模型利用多列卷积神经网络从答案的路径、背景等对问题进行理解,而后对检索出的答案也使用卷积神经网络进行编码最终比较二者的相似性。Xu等人[14]在图谱的基础上为实体引入描述信息,进而对描述信息进行编码最终完成答案和问题的匹配。虽然以上方法都取得了较好的结果,但并未考虑到问题涉及实体的多跳关系相互之间的语义联系对答案的影响。
基于此,该文在信息检索的基础上提出一种基于语义匹配的多跳检索问答生成方法。该方法通过在知识库中检索目标实体的多跳信息作为答案集合,而后将生成问题转换为匹配问题,并在模型中设计了以LSTM为结构的跳转路径学习层,将学习到的特征与问句进行匹配,然后利用深度学习网络进行匹配评分的计算,最终应用该方法完成了基于知识图谱的服装问答系统。
2 服装知识图谱构建
2.1 模式层构建
模式层又称为本体,其作为知识图谱的骨架,具体规定着知识图谱的实体定义和关系定语。该文采用自顶向下的方法构建服装领域知识图谱,数据以“中国服装网”、“服装网”等专业网站所提供的国家标准GB/T31007(纺织服装编码)、GB/T 15557-2008(服装术语)为源构建核心概念。实体概念与关系定义如表1所示,实体包含概念、设计细节、制造物、生产相关以及教育相关。关系包括上下位概念、组成构成、同义关系以及部分与整体的关系。
如表1所示,将服装实体概念进行了五类划分,并为每个分类进行了细分,在实体识别时,模型将按照表中所示的概念进行分类。

表1 实体概念与关系定义
实体属性在本体中所定义的实体通用属性有中文名称、英文名称、描述信息等,并且参照结构化数据和半结构化数据中的信息为不同的实体类别和小类增加了新的属性信息。如服装面料增加了主要成分、适用衣物、特点、洗涤方式、编织方式、印染方式。
2.2 数据层构建
由于服装领域内网页知识的不规范性,该文使用包装器方式对获取的知识进行进一步的解析,最终获得包含实体和实体关系的三元组。与此同时,为进一步利用服装文本中的知识进行图谱构建,该文对文本信息利用深度学习模型进行知识抽取,这里主要包含对实体的实体识别和关系抽取。
2.2.1 实体识别
实体识别的目的是为了将文本中出现的实体识别出来并确定其类型,该文利用Bert+BiLSTM+CRF模型进行服装实体识别。具体的,文本通过Bert预训练层[15]将文本进行字符级的编码,而后将编码传入BiLSTM网络层进行文本上下文特征的学习,最终传入序列标注层CRF得到文本对应字符的识别结果。训练数据使用人工标注的服装实体抽取数据集进行,模型的准确率为0.94。
2.2.2 关系抽取
关系抽取利用基于输入控制长短期记忆网络模型[16]将实体识别模型识别出的实体进行配对后对其关系进行识别。关系抽取的模型首先通过编码层对文本进行编码,并依据句法依存树生成控制向量,而后利用输入控制长短期记忆网络进行上下文特征的学习,输入控制长短期记忆网络在传统LSTM网络上添加输入控制单元,单元结构如图1所示。

图1 输入控制单元结构
图中,门阀控制单元计算如下所示:
ct=σ(Wc•[ht-1,xt]+bc)
其中,ct为输入控制门的控制信息,xt为更新后的输入信息,x_ct为控制向量,Wc和bc为记忆门的权重及偏置值。
聚焦式注意力计算进行特征级别的注意力机制的计算,该文选择聚焦式注意力机制将经过门阀控制单元计算出的输入与实体信息进行注意力机制的计算,公式如下:
ai=softmax(s(xi,q))
其中,ai为第i个特征的注意力权重,s为注意力打分函数,xi为t时刻第i个输入特征,q为key的实体特征。
在特征级别的注意力计算中,输入为t时刻输入特征的值,q为实体信息的表示,文本在选择注意力打分函数时使用双线性模型,公式如下:
s(xi,q)=xiWTq
其中,W为可训练参数,维度与q相同。

而后从编码中根据实体位置提取实体特征,进而传入注意力层,将文本特征与实体特征进行注意力计算,最后通过分类网络得到关系抽取的结果。
基于输入控制长短期记忆网络能够对复杂的服装文本进行有效的关系抽取。
2.3 知识构建及存储
以“中国服装网”、“服装网”及百度百科等开源数据进行知识抽取,从中抽取了5 201个实体、3 140条实体关系。图谱囊括了服装材料、服装概念、服装教育相关、设计细节等实体信息。图谱实体分布见表2。

表2 图谱实体分布
通常知识图谱保存的方式有三元组和图数据库,该文的服装知识图谱使用Neo4j图数据库进行保存。图2展示了部分知识图谱。
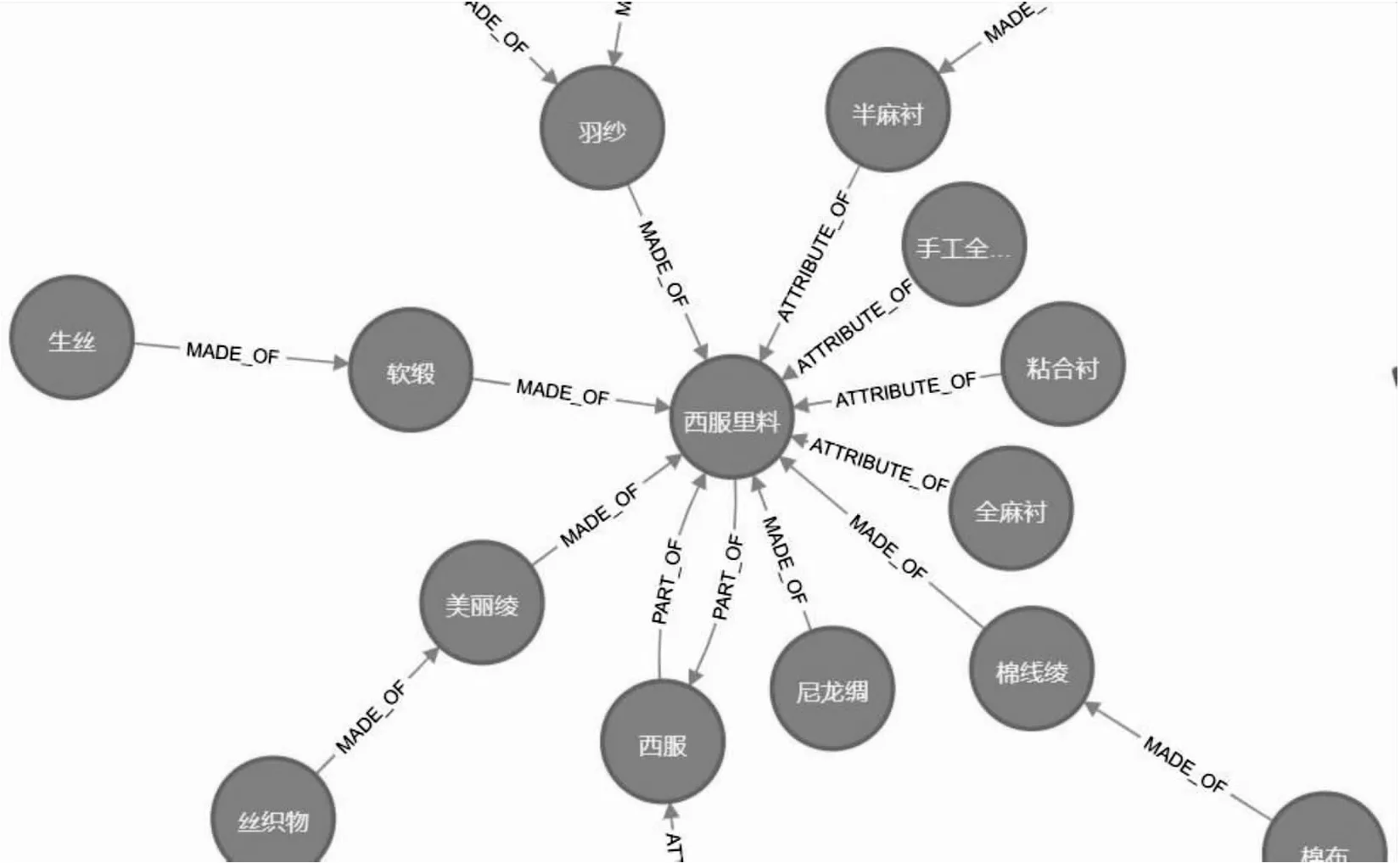
图2 部分知识图谱
3 基于服装知识图谱的问答系统
3.1 问答系统处理流程
问答系统处理流程包括:输入问题;实体识别;知识库查询;答案匹配;答案回复。
3.2 问答系统的设计实现
3.2.1 服装实体识别
在得到用户的输入后,该文通过命名实体识别模型对问句进行实体识别,采用知识抽取中命名识别模型的Bert+BiLSTM+CRF模型,模型结构如图3所示。

图3 命名实体识别模型
模型训练采用标注的服装实体识别数据集,训练使用SGD优化算法进行参数的调优。
3.2.2 基于Neo4j的数据库查询
该文使用Cypher语句对Neo4j图数据库进行查询,查询语句为:Math(a)-[关系]-(b) where b.name=“实体”return a.name。在得到文本中的实体指称后,对实体和查询语句进行拼接后再查询,并且对查询到的实体进行再次搜索,以实现对知识的多跳搜索。实体搜索的范围考虑到问答的一般形式,设置两跳为最大跳转数。最终通过搜索可以得到指称实体围绕两跳范围的所有对象。
3.2.3 答案匹配
在得到实体的多跳数据后,对数据和问句文本进行语义匹配,该文通过建立一个基于Bert的语义匹配模型对数据进行匹配,模型结构如图4所示。
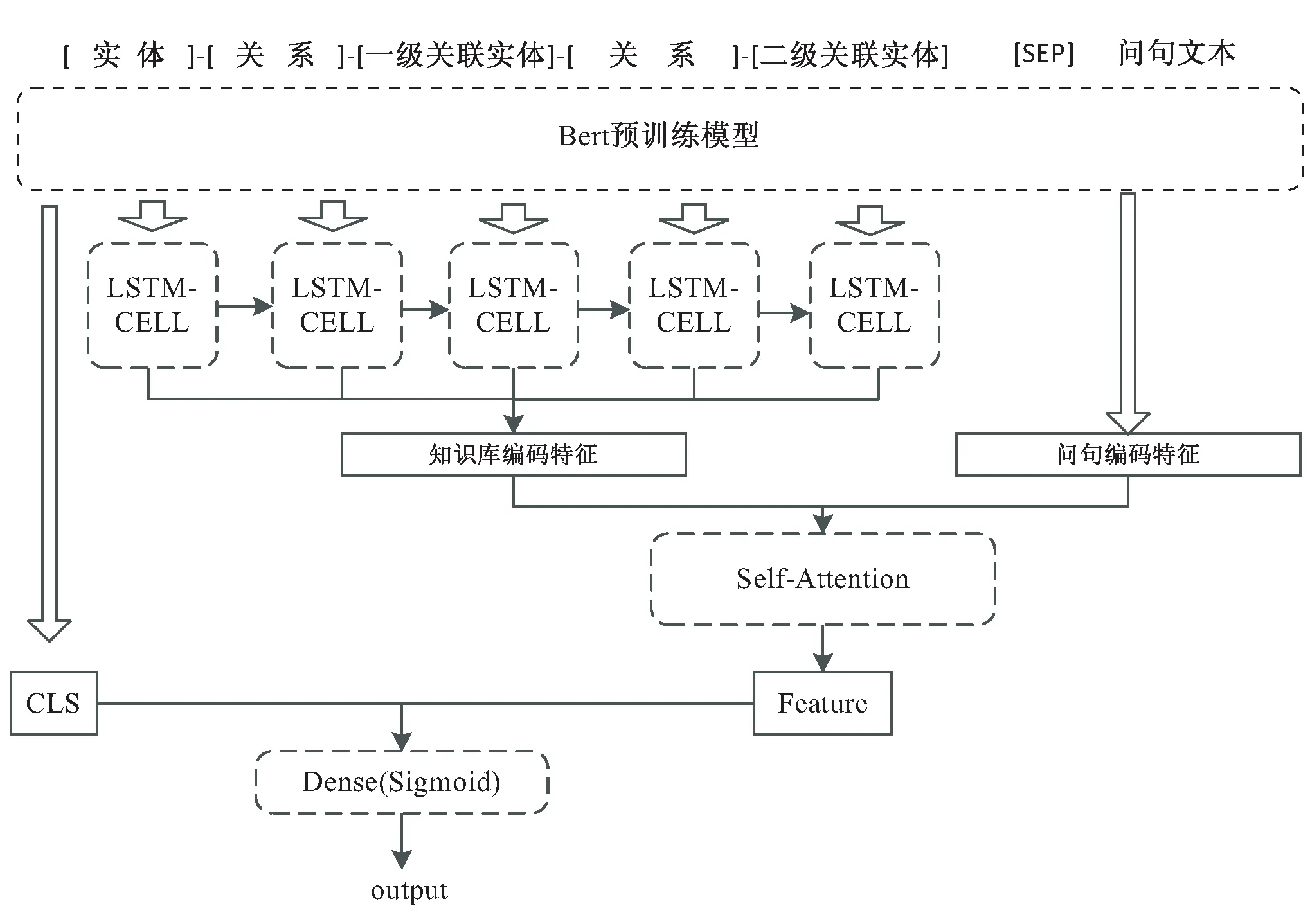
图4 答案匹配模型结构
模型通过Bert编码层对路径和文本进行编码,编码时实体和关系表示均占用十个字符,其余以空格补全。模型利用Bert对于拼接文本中用[SEP]拼接后进行编码。利用LSTM对搜索到的实体路径进行再次编码,而后与问句编码进行拼接后传入自注意力层,最后使用Bert编码层中[CLS]位置的编码与自注意力层拼接后传入以Sigmoid为激活函数的全连接层为模型的输出。
模型的优化目标如下:

模型的输出结果为对于当前搜索和问句的匹配度,最终对匹配度进行排序,选择评分大于阈值的搜索结果作为答案传递给用户。
4 实验结果与分析
为验证该知识问答方法的有效性,并测试基于该知识图谱的服装问答系统的性能,该文对系统答复的准确性和系统的响应时间进行了评测。
4.1 评分阈值选取实验
模型在对文本进行匹配后,系统将评分大于阈值的答案推送给用户,而阈值的选取将直接关系到系统的性能。为选择效果最优的参数,以[0.5,0.9]为值域、以0.01为间隔进行了阈值选取实验,实验结果如图5所示。

图5 评分阈值选取实验结果
由图5可见,在阈值设置过低时,问答系统会将很多错误的答句反馈给用户,进而导致准确率下降,而当阈值设置过高时,则会过滤掉一些正确答案,因此,系统选择0.7作为评分的阈值。
4.2 实验数据及实验环境
该文以自建的服装电商领域服装知识和服装搭配推荐问答语料集进行模型训练和验证。数据来源为“中国服装网”中的问答栏目内容和与学校合作电商的问答数据记录,将6 325条数据作为训练数据,2 000条作为验证数据。
模型训练硬件环境为RTX3060及Intel(R) Core(TM) i7-10750H 。软件环境为python3.6,tensorflow1.14.0,keras2.2.4,Bert版本为Bert-chinese-base。系统部署于阿里云服务器,后端框架为SSM。
4.3 答案准确性实验
4.3.1 实验评测指标
实验评价指标选用精确率P。给定输入问答集Q,对于Q中每条问句q由N个答案组成。则问答精确率的评价指标定义如下:

4.3.2 实验结果
为验证该问答系统的有效性,以自建的服装电商领域服装知识和服装搭配推荐问答语料集进行实验。将传统的模板匹配方法(Template Match)、图谱嵌入方法(TransE、TransR)和语义解析方法(NER+RE、Tree2seq)和文中方法进行对比,实验结果如表3所示。

表3 问答方法准确性实验
由表3可见,基于模板匹配的方法相对于文中方法在准确率上有所不足,原因是模板匹配方法依赖于模板的制定,而模板的制定需要付出巨大的代价以适应各个问答语句。而基于知识图谱推断的方法相对传统方法取得了很好的效果,但基于知识图谱推断的方法缺乏可解释性且在稀疏图谱中效果不佳。而文中方法通过准确率较高的实体识别方法将两跳以内的实体进行搜索,而后通过语义匹配方法进行答案生成,这相对于使用实体识别和关系抽取先判别意图和实体而后搜索的方法具有更高的准确性。
4.4 系统响应时间实验
为验证系统的适用性,该文使用无答案、一跳查找以及两跳查找的问句进行测试,测试结果如表4所示。
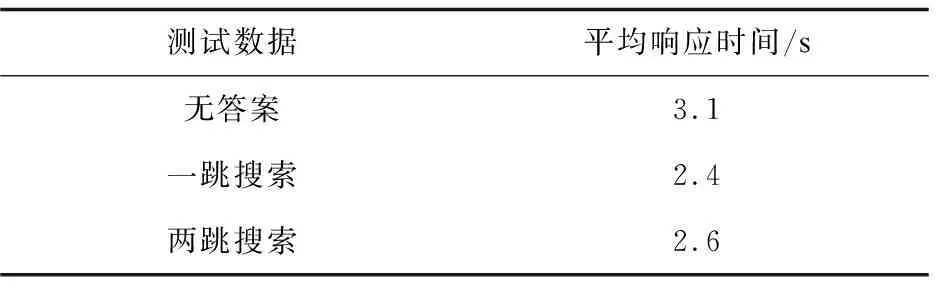
表4 系统响应时间实验结果
文中方法由于存在命名实体识别和匹配两个阶段,且使用了Bert预训练模型,因此系统的响应速度相对较慢,但响应时间总体符合系统的应用环境。
5 结束语
为了满足服装电商领域智能客服问答的需求,设计实现了以服装知识图谱为基础的服装知识问答系统。该系统基于信息检索的方式进行答句生成,提出的答句生成方法通过在知识库中检索目标实体的多跳信息作为答案集合,而后将生成问题转换为匹配问题,并设计了以LSTM为结构的学习跳转路径。最后的实验验证了该问答系统的有效性,可满足服装领域智能客服环境中服装知识和服装搭配推荐问答的需求。
猜你喜欢
少先队活动(2020年12期)2021-01-14
开放教育研究(2020年2期)2020-03-31
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
领导科学论坛(2016年9期)2016-06-05
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
