
基于忆阻循环神经网络的层次化状态正则变分自编码器
2023-03-01 08:19胡小方
电子与信息学报 2023年2期
胡小方 杨 涛
(西南大学人工智能学院 重庆 400715)
(类脑计算与智能控制重庆市重点实验室 重庆 400715)
1 引言
变分自编码器(Variational AutoEncoder,VAE[1])和其他深度生成模型,如生成对抗网络[2]和自回归模型[3]等,都可以从复杂且高维的未标记数据中学习到相应的信息。其中VAE广泛应用于图像处理[4,5]和自然语言处理任务[6–9]。
然而,VAE在优化过程中常常会出现后验崩溃,又称为KL散度(Kullback–Leibler Divergence,KLD)消失[10],即在生成过程中,模型忽略变分自编码器的潜在变量信息,退化为一个自编码模型。由于循环神经网络(Recurrent Neural Network,RNN)自身的强自回归性,使得基于循环神经网络的变分自编码器更容易出现这种现象。针对这一问题,研究人员陆续提出多种解决方案[10–12]。在最近的研究中,Shen等人[13]利用多层卷积神经网络替代编码器并用循环网络作为解码器;Hao等人[14]使用循环模拟退火方法来缓解KL散度消失;He等人[15]提出一个滞后推理网络,在解码器更新之前多次更新编码器,从动力学的角度避免该问题;Zhu等人[16]将批量归一化(Batch Normalization, BN)正则应用于VAE的近似后验概率的参数中,确保KL值为正值;Li等人[17]对编码器中的隐变量施加KL正则,缓解后验崩溃的问题;Pang等人[18]提出一种新的推理方法,在VAE模型的后验分布的指导下运行一定次数的朗之万动力学(Langevin dynamics)算法,从而有效避免模型崩溃的问题。然而,这些模型大多集中于缓解VAE后验崩溃的问题,而忽略了模型预测性能。
RNN是一种广泛研究的具有信息反馈的神经网络模型,与前馈神经网络相比,RNN融合了时间序列的概念,保持了对时间序列的长期依赖性,并且对时间序列场景具有良好的建模能力,然而,在文本生成过程中,当文本序列过长时,RNN模型会发生梯度消失的现象。为解决这个问题,提出长短期记忆神经网络(Long Short-Term Memory,LSTM),LSTM通过控制模型内部的遗忘门在一定程度上抑制RNN模型的梯度消失的问题,并在较长时间内保持了信息依赖性。随着LSTM模型的发展,其显著增加的复杂度和不断增长的参数量,使得基于互补金属氧化物半导体(Complementary Metal Oxide Semiconductor, CMOS)器件实现的LSTM网络,在计算方面表现出一些不足之处。
忆阻器是一种二端口“记忆电阻”,能够在存储信息的地方进行计算,这种存算一体化的特点减少了存储和计算之间传输数据的需求。与传统的基于CMOS器件的实现方案相比,基于忆阻器的人工神经网络具有体积小、功耗低、集成度高等特点。忆阻器已经被应用于许多人工神经网络硬件部署,包括单层或多层神经网络[19]、卷积神经网络(Convolutional Neural Networks, CNN)[20]和LSTM[21]等。其中,Adam等人[22]提出了一种用于时间序列预测的忆阻LSTM;Gokmen等人[23]将LSTM功能模块映射到忆阻交叉阵列中,并探索了器件缺陷对模型性能的影响;Li等人[24]展示了LSTM网络核心模块的忆阻器硬件实现,并采用两个1T1M的方式来表示正负权值;Liu等人[25]在LSTM的硬件实现上提出一种新的权值更新方案,实现在线训练,并对忆阻器的电导值实现并行更新。
本文针对VAE后验崩溃的问题,提出一种新的变分自编码器模型,称为层次化状态正则变分自编码器(Hierarchical Status Regularisation Variational AutoEncoder, HSR-VAE)。HSR-VAE不但可以有效缓解后验崩溃的问题,且较于基线模型,拥有更好的文本生成质量。与现有的变分自编码器仅在最后的时间步状态下施加KL正则[17],或者仅仅是通过分层的思想对隐藏状态矩阵进行细化处理[26]不同,HSR-VAE在层次化状态方法的基础上引入时间步状态正则的方法,通过层次化方法对隐藏状态矩阵进行细化处理,并且对各个时间步的隐藏细化状态值施加KL正则,两种方法的结合可以有效缓解VAE的后验崩溃问题,明显提升模型预测能力。同时,为提高HSR-VAE模型的计算效率,本文在忆阻循环网络的基础上,将HSR-VAE部署在忆阻交叉阵列中,提出HSR-VAE的硬件加速方案,即层次化变分自编码忆阻神经网络(Hierarchical Variational AutoEncoder Memristor Neural Networks, HVAE-MNN)。通过忆阻器存算一体的特性,明显提升HSR-VAE模型的计算效率。
为了证明本文方法的有效性,本文加入一些强基线模型进行对比,并基于4个公共数据集,分别在语言模型和对话响应生成任务上进行实验对比。语言模型任务中, HSR-VAE可有效缓解后验崩溃,且在定量分析负对数似然(Negative Log Likelihood, NLL)和困惑度(PerPlexity Loss, PPL)的平均实验结果表明,较于基线模型,NLL值降低6,PPL值降低5.9,KL值提高5.6;对话响应生成任务中,多样性评估指标Intra-dist1和Inter-dist1分别提升5.6%和20.4%。
综上所述,本文贡献如下:
(1) 提出一种新的变分自编码器模型HSR-VAE,有效缓解变分自编码器后验崩溃的问题。
(2) 提出一种层次化状态正则的方法。在层次化状态的基础之上引入时间步状态正则的方法,明显提升模型预测性能。
(3) 设计一种基于忆阻循环神经网络的变分自编码器硬件实现方案HVAE-MNN,为变分自编码器的硬件加速提供一种新的思考。
2 层次化状态正则变分自编码器
2.1 变分自编码器


2.2 结合层次化和时间步正则的变分自编码器
针对VAE后验崩溃, 时间步正则变分自编码器(Time step-Wise Regularisation Variational AutoEncoder, TWR-VAE)[17]对编码器的所有时间步的隐藏状态值施加标准正态分布K L 正则。TWR-VAE虽然有效缓解后验崩溃,但与批量归一化变分自编码器(Batch Normalization Variational AutoEncoder, BN-VAE)[16]相比,KL值相对较低,针对这一问题,本文提出层次化状态正则变分自编码器HSR-VAE。HSR-VAE通过层次化方法编码隐藏状态矩阵,并且对编码后的隐藏状态矩阵各个时间步的状态值施加KL正则。



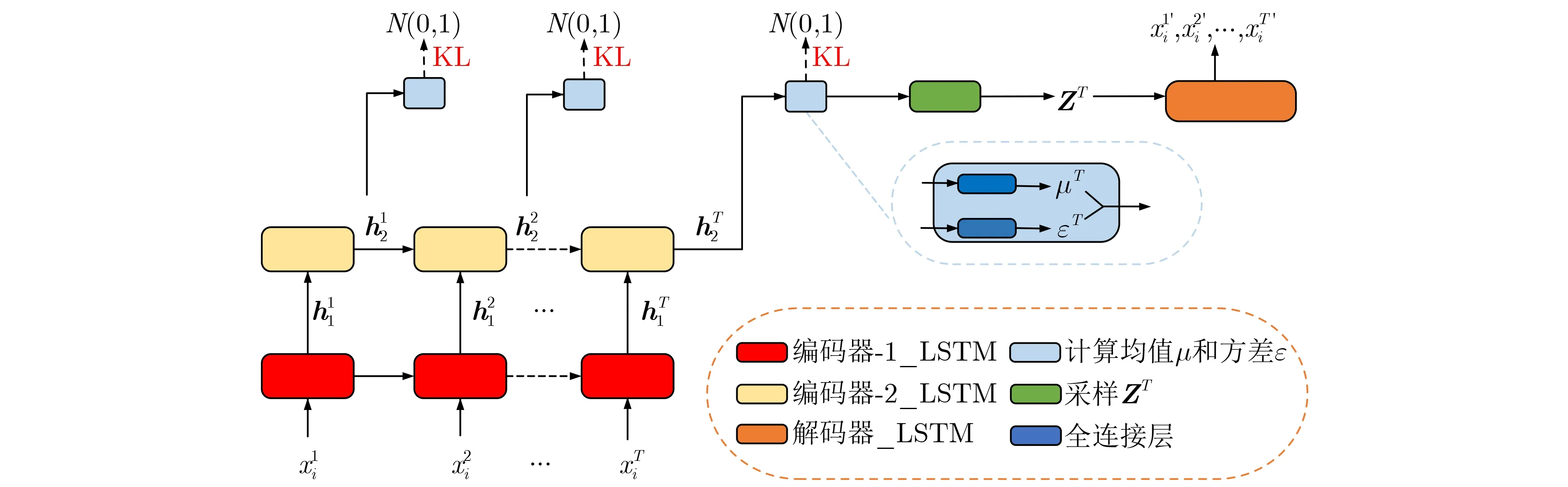
图1 HSR-VAE模型结构图

3 基于忆阻神经网络的层次化变分自编码器
3.1 忆阻器
1971年,文献[27]在研究电荷、电流、电压和磁通量之间的关系时,定义了磁通量和电荷之间的关系,提出忆阻器的概念。忆阻器是一种有记忆功能的非线性电阻,通电时可以通过改变流过它的电荷数量或磁通量来改变阻值,断电时保持当前阻值不变。2008年,惠普实验室设计出一个能工作的忆阻器物理模型,一个典型的惠普Pt/TiO2/Pt忆阻器数学模型[28]如式(8)所示
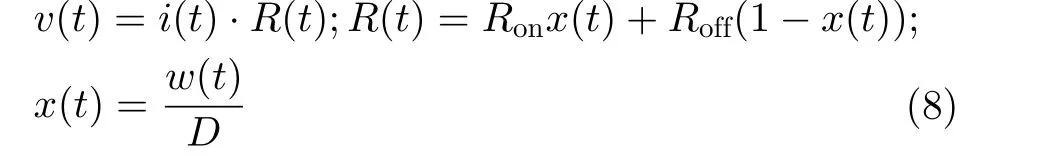
其中,R(t)表 示忆阻器的阻值,Ron和Roff分别表示忆阻器的最小和最大的阻值。w(t)表示掺杂层厚度,x(t)表 示内部状态变量,D表示为忆阻器的厚度。
本文采用Ag/AgInSbTe/Ta(AIST)忆阻器模型,其内部状态变量描述为


3.2 HSR-VAE硬件部署设计
本文模型HSR-VAE的硬件部署设计方案HVAEM N N 通过忆阻交叉阵列实现。本模型由3 层LSTM网络组成,所以重点介绍基于忆阻LSTM的HSR-VAE硬件实现方案。
LSTM网络的关键组成为3个门控单元,即输入门、输出门和遗忘门。LSTM利用独特的门控单元对序列数据进行学习和选择性记忆,保持长距离的时间序列信息相关性,实现高精度预测。其中,输入门主要处理输入数据,遗忘门决定当前神经元对历史信息的记忆程度,输出门代表神经元的输出结果。输入文本序列(x1,x2,...,xT), 则t时刻,LSTM网络迭代公式为

其中,it,ft和ot分别表示t时刻的输入门、输出门和遗忘门的输入;xt表示t时刻LSTM的输入序列,ht−1表 示t−1时 刻的隐藏层输出状态,bi,bf和bo分别是对应的偏移向量,wi,wf和wo表示对应的权重矩阵,ct表示t时刻LSTM网络记忆信息。S表示sigmoid激活函数。
对公式分析可知,在LSTM网络中,其核心计算模块为矩阵的乘累加计算。忆阻器具有可变电阻和记忆电阻状态的能力,是权值矩阵计算的理想器件。因此,在具体应用过程中,将LSTM网络中的权值计算过程映射到忆阻交叉阵列中,通过改变加载幅值相同的电压时间长短的方式完成输入向量与权值向量的乘累加计算,实现LSTM网络的硬件加速,提升计算效率。
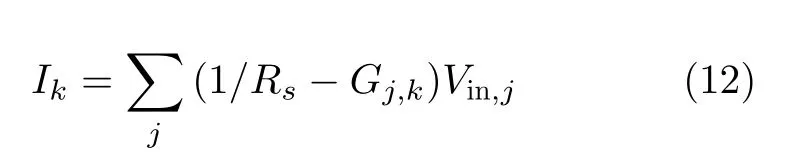
其中,Ik为忆阻交叉阵列中第k列总的输出电流,(1/Rs −Gj,k)表示模型映射到交叉阵列中的权值的大小。 1 /Rs表 示固定电阻的电导,Gj,k代表第j个输入数据在第K列上忆阻器的电导值。Vin,j表示第j个输入电压,in表示输入类型是X,H或b,其对应的j 的取值范围是 (0,T) , (T,T+M) ,(T+M,T+M+1), T和M分别是文本序列的长度和隐藏层的维度。
本文模型在忆阻交叉阵列的基础上,提出HSRVAE硬件加速方案HVAE-MNN。HVAE-MNN忆阻电路由3层忆阻LSTM所组成,其中,两个忆阻LSTM组成模型编码器,单个忆阻LSTM组成模型解码器,每个LSTM硬件电路网络基于图2(a)所示的忆阻交叉阵列。在实际应用场景中,硬件加速计算流程包括:将训练好的模型权值矩阵映射到忆阻交叉阵列中,其输入数据转换为对应的电压信号,经过图2(a)所示的LSTM电路计算隐藏状态矩阵值,将该隐藏状态矩阵使用ADC信号转化器转换为数字信号;在软件层面上,计算该隐藏状态矩阵的均值和方差,重参数化构建zt隐变量矩阵,再将该隐变量矩阵通过DAC信号转换器转化为模拟信号,输入到解码器LSTM网络中,进行LSTM网络硬件加速计算,最后将输出转换为数字信号传给软件,计算预测值,并构建预测文本序列信息,最终,该文模型实现HSR-VAE模型的硬件加速。
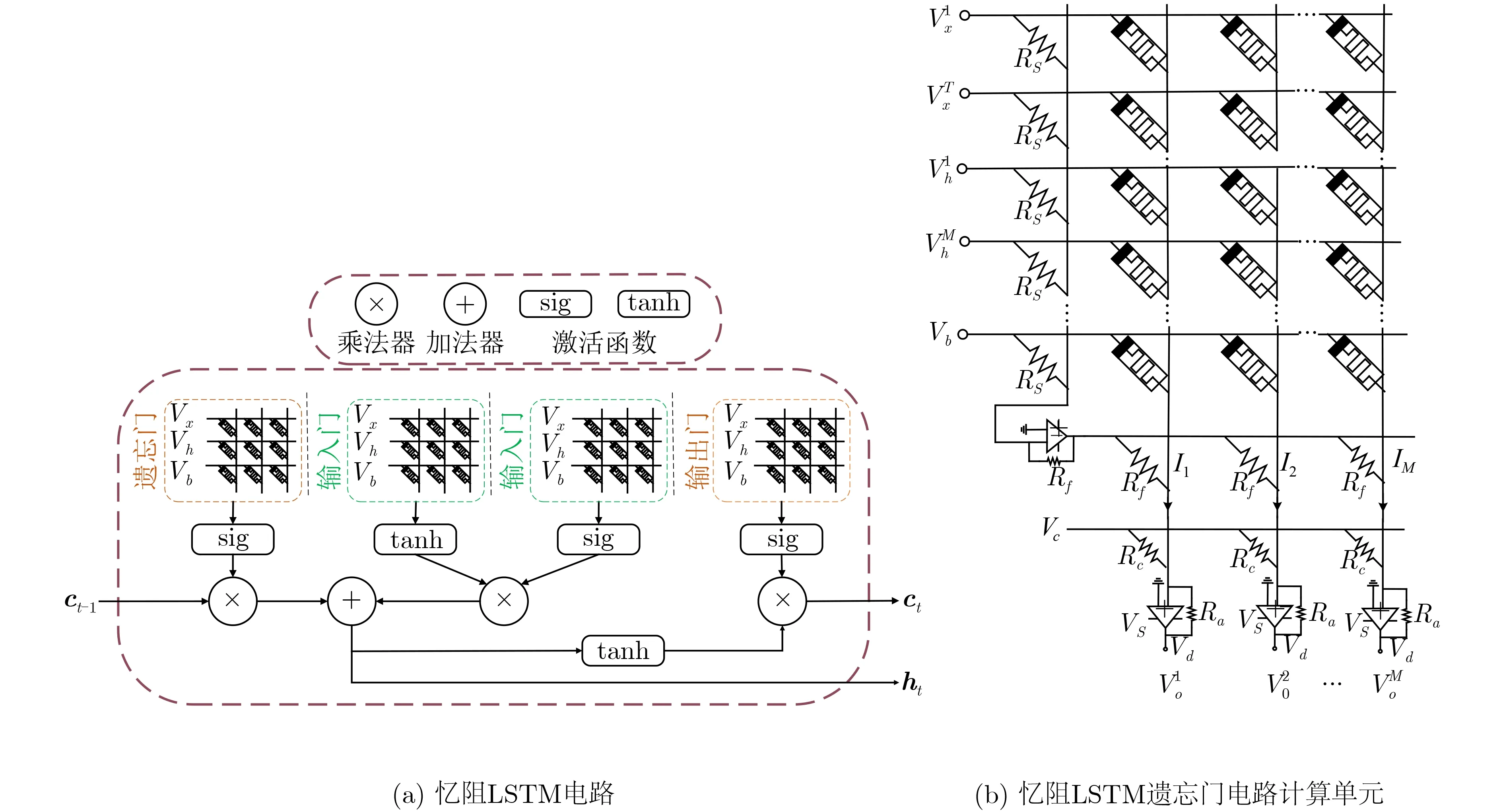
图2 忆阻LSTM
4 实验结果分析
本文采用4个公共数据集来评估HSR-VAE,包括PTB, Yelp, Yahoo和Dailydialog。表1总结了相应的数据集信息。其中,PTB,Yelp和Yahoo数据集应用于语言模型任务,Dailydialog数据集应用于对话响应生成任务。本文模型词向量的大小为512维,隐藏层的大小均为256维。
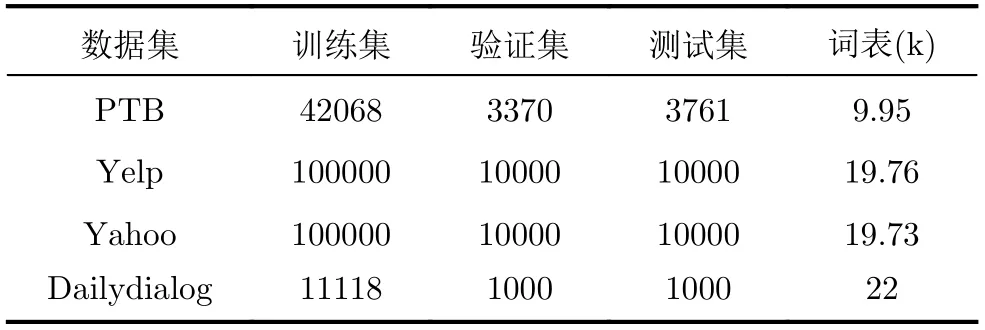
表1 数据集
4.1 语言模型
神经网络语言模型是在给定一个文本序列的前提下,预测下一个词出现的概率。本文采用两个评估指标,包括NLL和PPL来评价模型的预测性能,NLL和PPL值越低说明预测文本越合理;KL值来评估模型是否出现后验崩溃。通过实验,本文模型与强基线模型进行了对比分析。(1)VAE-LSTM[10]:基于LSTM网络的VAE模型,采用KL-annealing方法缓解后验崩溃;(2)半摊销变分自动编码器(Semi-Amortized Variational AutoEncoders, SA-VAE)[29]:采用随机变分推理初始化变分参数;(3)循环变分自动编码器(Cyclical Variational AutoEncoder,Cyc-VAE)[14]:采用周期性模拟退火方法缓解KL散度消失;(4)滞后变分自动编码器(Lagging Variational AutoEncoder, Lag-VAE)[15]:采用多次更新编码器而较少更新解码器;(5)批量归一化变分自动编码器(Batch Normalization Variational AutoEncoder, BN-VAE)[16]:在KL分布中采用BN正则避免后验崩溃;(6)TWR-VAE[17]:对每个时间步的隐藏状态值进行KL正则;(7)短程推理变分自动编码器(Short Run Inference Variational AutoEncoder, Sri-VAE)[18]:将VAE与Langevin Dynamics算法结合避免后验崩溃。
语言模型实验结果如表2所示,HSR-VAE的预测性能(NLL, PPL)优于所有基线模型。对两个数据集的评估结果进行平均,与基线模型TWR-VAE相比,本文模型在NLL值降低6,PPL值降低5.9,KL值提高5.6;与强基线模型BN-VAE相比,KL值提升1.1;与最新模型Sri-VAE相比,NLL和PPL分别降低29.2和42.6。实验结果表明HSR-VAE在语言建模任务中优异的性能。语言模型生成文本如表3所示,原始文本序列与生成文本序列越相似,说明模型的预测性能越好。
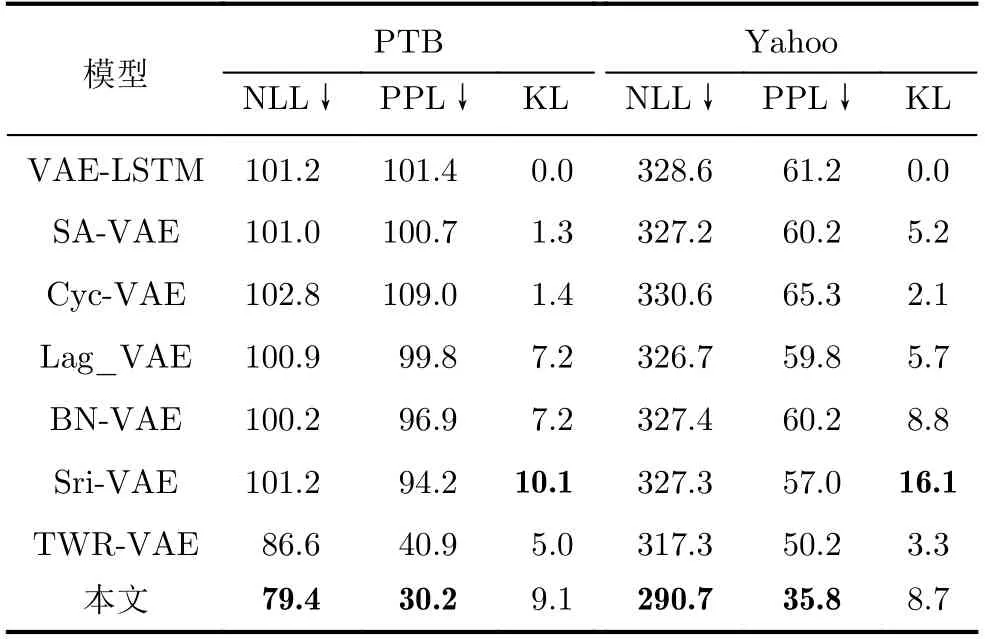
表2 语言模型实验对比

表3 语言模型生成文本示例
消融研究测试TWR-VAE与HSR-VAE模型在RNN, LSTM和GRU等不同循环结构的实验结果。同时,为测量隐变量zt采样输入数据信息量,即测量输入数据与隐变量之间的互信息,增加一个互信息评估(Mutual Information, MI)。其中,MI的计算方法如式(13)所示
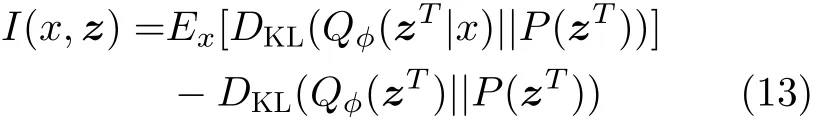
消融实验结果如表4所示,与TWR-VAE相比,HSR-VAE的评估指标NLL和PPL值有明显降低,表明HSR-VAE预测文本更加合理。同时,本文还探究不同循环网络结构组合的实验效果,HSR-VAE的KL值表明,相比于单层循环网络结构,双层循环网络结构可更加有效地避免VAE后验崩溃;互信息MI值表明,双层循环网络架构会减少解码器获得的信息量。低MI值和高KL值表明,弱化编码器采样性能有助于避免VAE后验崩溃。
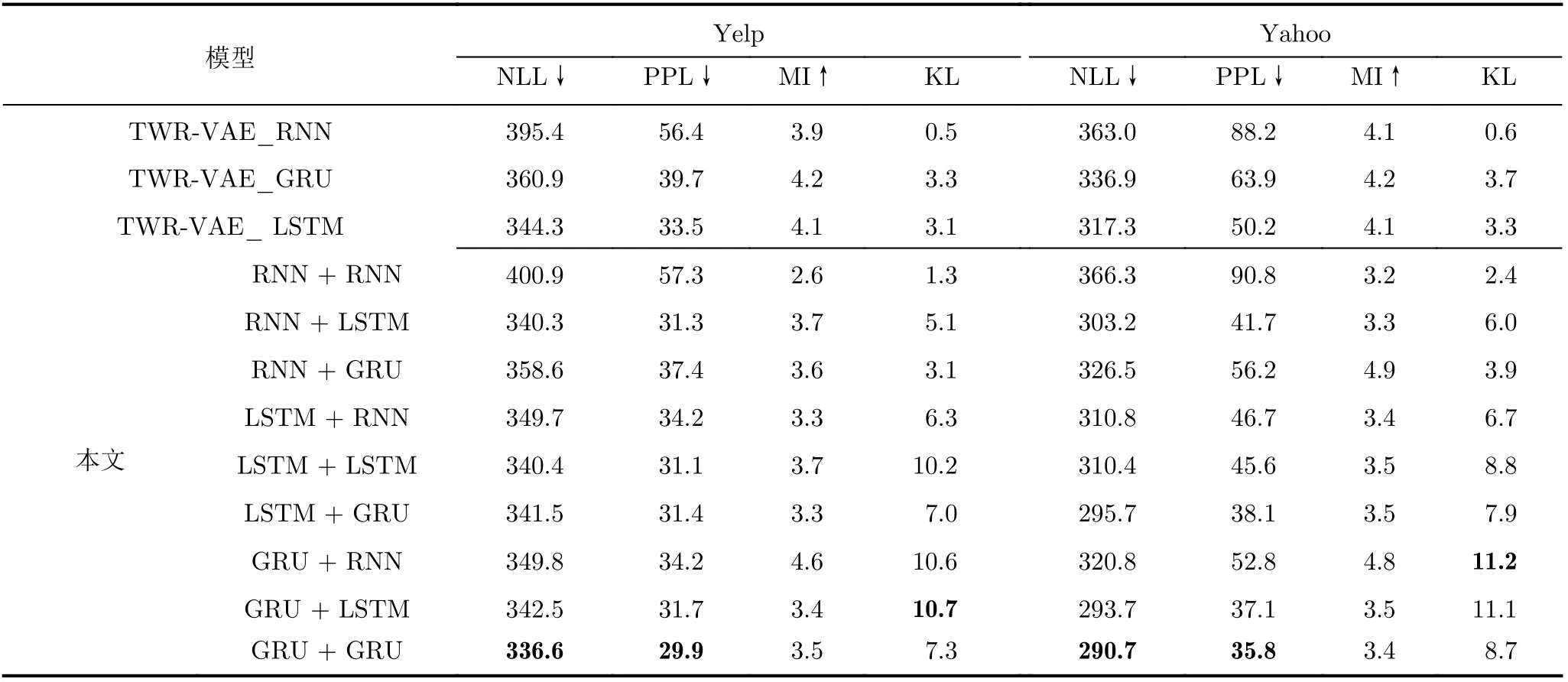
表4 消融研究实验对比
4.2 对话响应生成
对话响应生成的任务目标是根据用户的话语生成有意义的响应,然而,建立在序列对序列模型基础上的对话响应生成往往会产生例如“好”“嗯”“谢谢”等一般性的回答。针对该问题,一种有效的解决方案是采用条件变分自编码器(Conditional Variational AutoEncoder, CVAE)[30],该模型采样编码器中的句子级别多样性,通过隐变量来学习潜在会话意图的分布,有效改善响应的多样性问题。本文以CVAE的结构基础对HSR-VAE进行扩展,进一步评估模型在对话响应生成任务中的效果。扩展模型损失计算如式(14)所示

其中,c表示上下文内容编码,J表示对话窗口的大小,j表示第几个对话窗口。Pθ(xi|zJ,c)表示重构损失,DKL(Qϕ(zj|xi,c)||Pθ(zj|c))表示KL散度,即通过Qϕ(zj|xi,c)来 拟合真实后验分布Pθ(zj|c)。
对话响应生成任务中,本文基于Dailydialog[31]数据集进行对比实验。训练过程中,对话窗口的大小J设置为10,最大对话长度为40,采用贪婪解码来抽样响应,使得对话随机性完全取决于隐变量。所有基线模型采用的超参数相同,编码器和解码器都采用GRU模型,模型的隐藏状态值维度设置为300,隐变量维度大小为200。
在对比实验中,本文模型除了与基线模型TWRVAE[17]、 Wasserstein自动编码器(Wasserstein AutoEncoder, WAE)[8]、CVAE、独立变分自动编码器(Independent Variational AutoEncoder,IVAE)[32]进行对比,还与层次化基线模型RNN(Variational Hierarchical Conversation RNNs,VHCR)[26]、可变分层循环编码器(Variable Hierarchical Recurrent Encoder-Decoder, VHRED)[33]、基于强化学习方法的Seq2Seq生成性对抗网络(Seq2Seq Generative Adversarial Networks, SeqGAN)[34]进行对比。对话响应生成任务评估指标采用先前已有工作所采用的评价方法。(1)双语评估替补(BiLingual Evaluation Understudy, BLEU)。该评估指标展示了生成对话与参考序列的匹配程度。对于每个测试情境,计算每个响应的BLEU分数,并将n元语法查准率和n元语法召回率分别定义为平均分和最高分;(2)BOW。该评估展示了模型生成的回答和参考序列之间的词袋嵌入余弦相似度。本文采用3种度量方式计算单词嵌入的相似度:BOW-G(BOWGreedy)是通过贪婪匹配的两个对话单词之间的平均余弦相似度,BOW-A(BOW-Average)是单词嵌入之间的平均余弦相似度,BOW-E(BOW-Extreme)是两个对话的单词嵌入的最大极值之间的余弦相似度。(3)Distinct。该方法通过计算生成的对话响应中的唯一n元语法(n=1,2)与所有n元语法的比率来衡量生成的对话响应的多样性。Intra-dist表示单次情境中单个响应内部的多样性;Inter-dist表示单次情境中多个响应之间的多样性。
对话响应生成实验结果如表5所示。HSR-VAE在各个评估指标均优于层次化基线模型VHRED和VHCR,表明在层次化的基础上进行时间步状态正则可提升生成对话的质量;与基线模型TWR-VAE相比,HSR-VAE在一些评估指标上有一定的优化,特别是在多样性评估指标Intra-dist和Inter-dist,表明层次化优化方法可有效提升对话响应生成任务的多样性。表6展示了对话响应生成任务中生成的可能的响应文本。

表5 对话响应生成任务实验对比

表6 对话响应生成文本示例
5 结束语
本文提出层次化状态正则变分自编码器HSRVAE,本文模型通过层次化方法编码隐藏状态矩阵,并且对编码后的隐藏状态矩阵各个时间步的状态值施加KL正则。同时,基于忆阻交叉阵列完成LSTM网络核心模块的权值矩阵计算,通过线上线下混合训练及实时推理,实现HSR-VAE模型的硬件加速。计算机仿真结果实验表明,在语言建模任务中,HSR-VAE不仅可以有效避免后验崩溃,且拥有比所有强基线模型更好的性能;消融实验研究表明,层次化编码和时间步状态正则的有效结合可应用于不同循环结构的VAE,并有效提升模型性能;在对话响应生成任务中,HSR-VAE可有效提升对话响应生成序列的多样性。上述实验结果都表现出本文模型的有效性,进一步研究可以将HSRVAE应用在其他任务,如机器翻译等。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
数学杂志(2020年3期)2020-07-25
数学物理学报(2019年6期)2020-01-13
数学物理学报(2019年6期)2020-01-13
电子制作(2017年24期)2017-02-02
铁道通信信号(2016年1期)2016-06-01
中国市场(2016年45期)2016-05-17
中国舰船研究(2015年2期)2015-02-10
航天返回与遥感(2014年5期)2014-07-31
郑州大学学报(理学版)(2014年2期)2014-03-01
