
基于用户行为序列的短视频用户多行为点击预测模型
2023-03-01 08:19顾亦然杨海根
电子与信息学报 2023年2期
顾亦然 王 雨 杨海根
①(南京邮电大学自动化学院、人工智能学院 南京 210023)
②(南京邮电大学智慧校园研究中心 南京 210023)
③(南京邮电大学宽带无线通信技术教育部工程研究中心 南京 210003)
1 引言
根据中国互联网络信息中心(China internet Network Information Center, CNNIC)发布的第47次《中国互联网络发展状况统计报告》,中国短视频用户规模达8.73亿人,人均单日刷视频时长达125 min,可见短视频受到了越来越多的人的喜欢。随着短视频的发展,短视频的数量越来越多,大量冗余的短视频信息远超用户的个人需求,导致了信息过载问题。为了解决信息过载的问题,推荐系统应运而生,点击率(Click Through Rate, CTR)预测就是推荐系统的一个关键性问题[1]。
CTR预测任务主要用于预测用户点击推荐物品的概率,目前主要的研究方法分为基于机器学习模型的方案[2–4]和基于深度学习的方案[5–9]。在传统的机器学习模型中,最早用于解决点击率预测问题的是文献[2]提出的逻辑回归模型。为了学习到特征间的非线性关系,文献[3]则提出了混合逻辑回归模型(Mixed Logistic Regression, MLR),它是对逻辑回归模型的改进,进一步提升了模型的精度。然而这类模型存在稀疏特征带来维度灾难的问题。为了解决现实场景中存在的数据稀疏性的问题,Rendle等人[4]提出了因子分解机模型(Factorization Machine, FM),该模型使用分解参数对所有特征变量交互进行建模,将2阶的组合特征的权重分解为两个隐含向量的点积,有效缓解了数据稀疏性的困扰。随着深度学习在计算机视觉、自然语言处理等领域取得巨大成功,越来越多的学者利用深度学习算法进行CTR预测。Cheng等人[5]提出了一种将线性模型和深度学习模型融合的模型Wide&Deep(Wide&Deep Learning for Recommender Systems),不仅考虑了低阶特征携带的信息,而且考虑了高阶特征的交互信息,然而Wide部分依赖人工交叉特征。Guo等人[6]在Wide&Deep模型的基础上,将线性模型换成FM模型,提出了DeepFM(DeepFM: A Factorization-Machine based Neural Network for CTR Prediction)模型,该模型解决了Wide&Deep模型需要手动交叉特征的缺点,可以自动学习到低阶和高阶特征的交互,但是该模型忽略了用户的行为本质上是一个动态序列的事实。文献[7]提出的循环神经网络(Recurrent Neural Network, RNN)及其文献[8]提出的变种长短期记忆网络(Long Short-Term Memory, LSTM)和文献[9]提出的门控循环单元(Gated Recurrent Unit, GRU)被广泛用于用户行为序列建模,捕获用户行为序列间的依赖关系。然而该类方法受限于循环结构,缺失低阶特征交互信息。
本文提出了一种基于用户行为序列的短视频用户点击行为预测模型。用户的行为序列蕴含了用户的行为习惯、不同行为之间的顺序依赖关系以及用户兴趣偏好随时间推移而发生变化的内在模式等重要信息[10],因此本文对用户的历史行为进行分析,将用户的历史点击行为按照点击时间先后顺序进行排序,得到用户的历史行为序列,将用户的历史行为序列作为文本输入,利用词向量模型Word2Vec[11–13]进行特征提取,提取出一系列序列特征信息用来表征用户的动态兴趣偏好,通过FM模型和深度神经网络(Deep Neural Networks, DNN)模型分别学习到低阶和高阶特征交互信息,最终完成用户对短视频进行点击行为的预测。在一个真实的短视频平台数据集上的实验结果表明,本文提出的用户行为预测模型优于其他几个深度学习模型。
本文的主要工作总结如下:
(1)提出一种用于预测短视频用户对不同视频内容的发生点击行为的概率的模型,包含预测用户对视频的点赞、查看视频评论、点击头像及转发视频的概率。
(2)根据用户历史行为发生的时间先后顺序构建用户历史行为序列,利用词向量模型Word2Vec提取出一系列的序列特征用来表征用户的偏好;将融合视频文本、声音和图像的多模态特征向量通过主成分分析模型(Principal Component Analysis,PCA)进行数据降维处理得到低维稠密的视频特征。
(3)在一个真实的短视频平台进行实验,本文设计的模型性能相较于其他深度学习模型的性能都有着不同程度的提升。
2 基于用户行为序列的用户多行为点击预测模型
2.1 问题定义
假设有n个用户与视频的交互实例记作 (x,y),x包含与用户产生交互的视频特征,y表示用户与视频已产生的交互行为,包括查看视频评论、点赞、点击头像及转发行为,y∈{0,1}(y=1表明用户与视频产生该交互行为,否则y=0)。x可能包含与用户产生交互的视频ID、作者ID及视频时长等基础特征,也可能包含用户观看视频总和、停留视频时长平均值等交互特征及用户序列特征。短视频用户点击行为预测的任务就是建立一个预测模型yˆi=F(x){i=read_comment, like, click, forward}来预测用户对推送的视频产生点击行为的概率,其中read_comment, like, click, forward分别表示用户查看视频评论、点赞、点击头像和转发行为。
2.2 模型整体结构
用户序列特征就是根据用户的历史交互行为产生的,因此对用户序列特征的表示就是对用户的偏好进行了表征。为了提取出用户对视频的偏好,本文提出一种基于用户行为序列的短视频用户多行为点击预测模型(USer multi behavior Click Prediction model, USCP),模型结构自下而上主要由输入层、因子分解机层、深度神经网络层和输出层4部分组成。模型结构如图1所示。
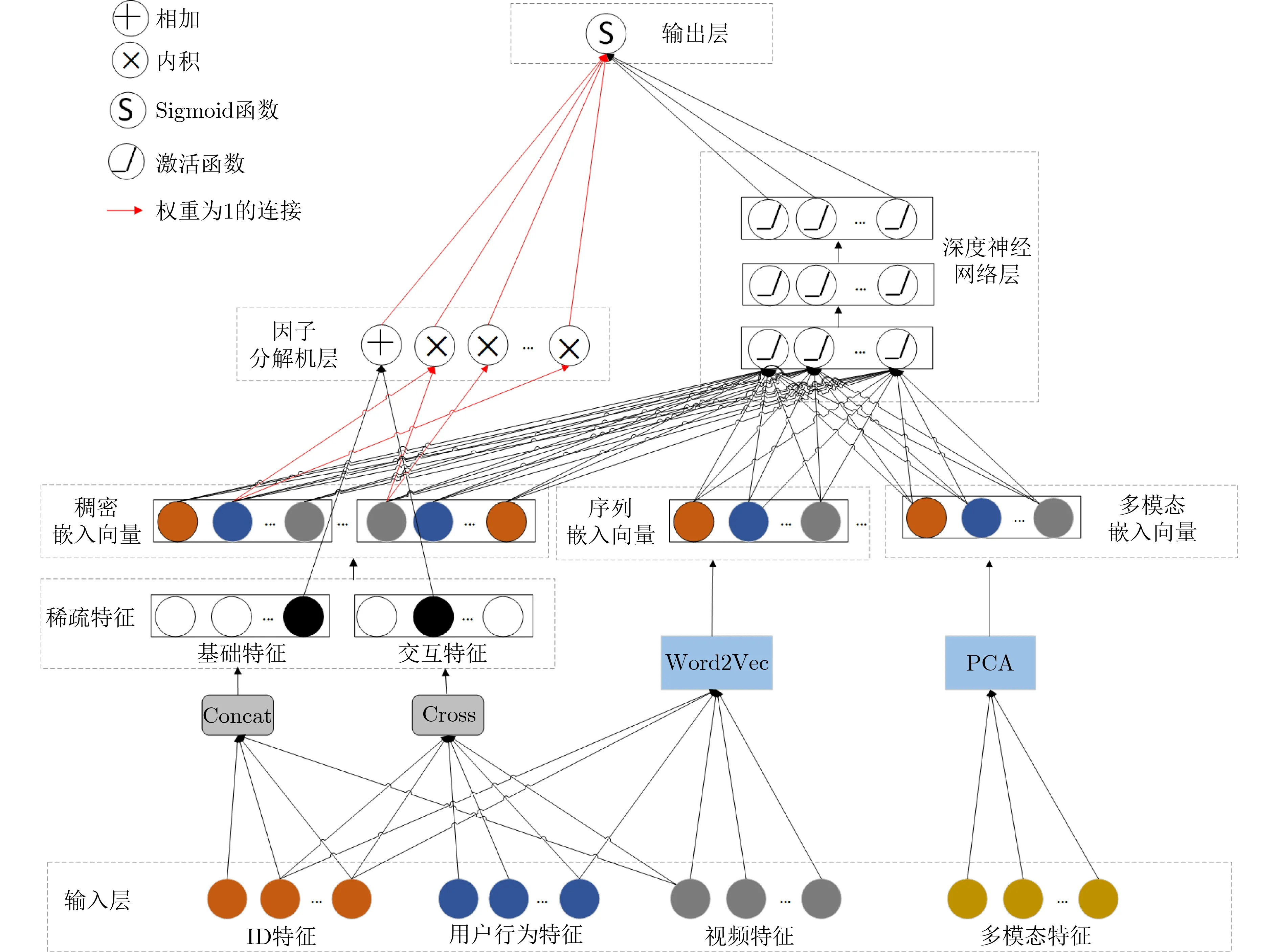
图1 模型结构图
2.2.1 输入层
输入层主要由ID特征、用户历史行为特征、视频特征及融合视频文本、图像、声音等信息的多模态特征4部分组成。其中ID类特征包括用户ID、视频ID、视频作者ID、背景音乐歌手ID和背景音乐ID等5个ID类特征;用户历史行为特征包括用户播放视频时长、停留视频时长和用户点赞、转发、查看评论、点击头像等4种历史行为;视频特征包括视频时长、视频关键字、视频标签等特征;视频多模态特征包含视频图像、声音、文本的多模态特征信息。
首先将ID类特征和视频特征进行合并后组成基础特征;为了进一步挖掘出用户对视频不同特征如视频作者、视频背景音乐、视频标签等的偏好,本文对N天内用户对视频的不同特征之间的交互进行交叉统计,得到交互特征。最后将经过处理后的特征送至因子分解机层和深度神经网络层来分别学习低阶和高阶特征交互。
2.2.2 因子分解机层
为了捕获基础特征和交互特征间1阶和2阶的特征交互信息,本文利用因子分解机FM模型进行低阶特征交互。首先,考虑到现实场景中很多特征都是互相关联,彼此联系的,如“高跟鞋”和“女性”、“冬天”和“羽绒服”等,因此在线性模型的基础上引入2阶特征组合项xi和xj,得到2阶多项式模型


2.2.3 深度神经网络层
仅通过FM模型得到1阶和2阶的特征交互信息显然是不够的,生活中还存在很多需要深入分析才能得到特征间的相关性的场景,比如啤酒和尿布的关系[14],从表面上看两者的属性似乎没有任何关系,但是商家通过对1年多的交易记录进行分析发现了这对神奇的组合,因此需要更加深入地挖掘特征间的关系。
2.2.3.1 用户动态兴趣偏好表征
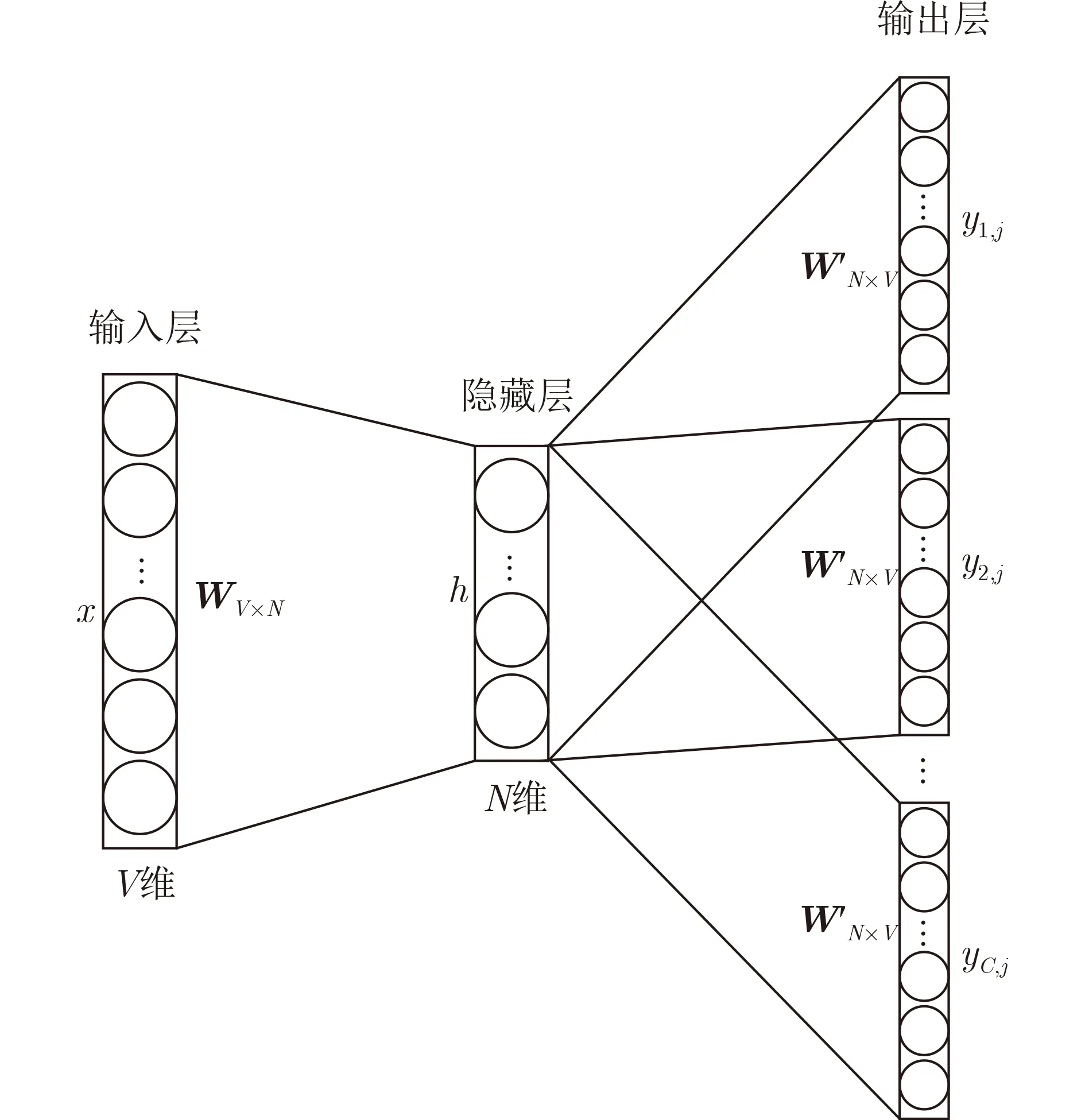
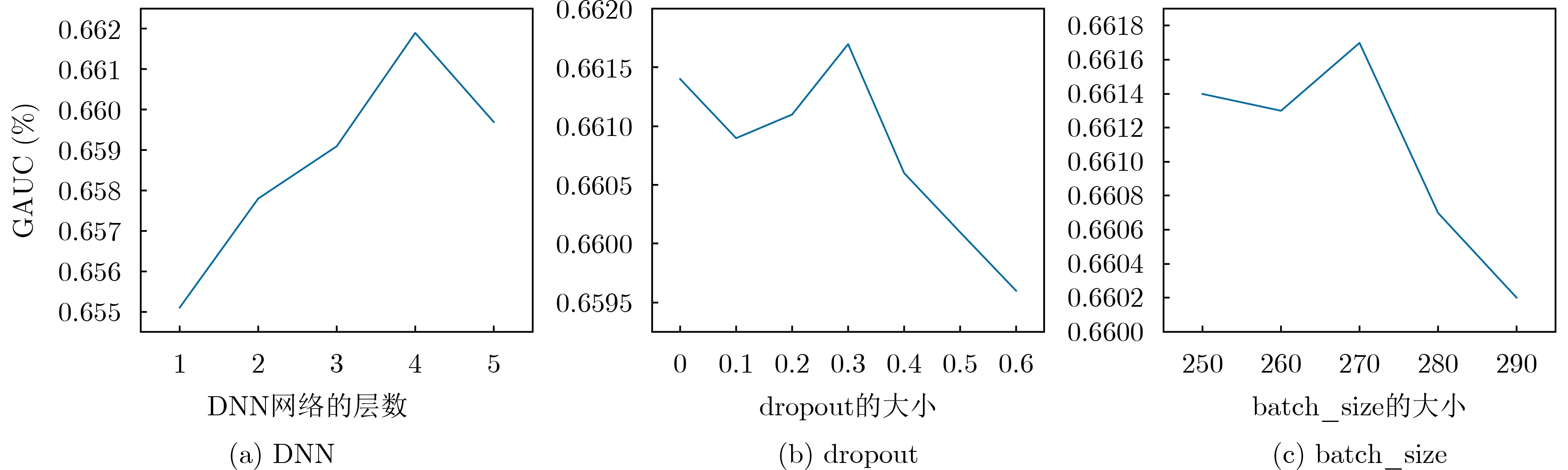
在现实生活中,用户的交互行为通常可以看成一个序列,并且前后不同的交互行为通常存在着一定的依赖关系,如:一位用户观看了吉他弹唱视频,并且点赞了该视频,显然用户此时表达了对音乐类视频有着一定的兴趣,本文猜测接下来用户想观看歌曲演唱视频的概率应该是大于美食视频的,因为歌曲演唱视频和吉他弹唱视频都属于音乐类视频,彼此之间存在一定的关联性。首先本文对用户的历史行为进行序列建模,由于用户的历史行为发生的时间点都是不同的,将用户的历史行为按照时间先后顺序排成一个序列,用Su=(bu1,bu2,...,bun)表示用户u的行为序列,1 本文选用Word2Vec模型中的Skip-Gram模型进行训练,输入用户u的行为序列Su,以用户当前行为bui为中心词,最终预测出用户u当前行为bui窗口两侧的行为的概率分布,Skip-Gram的模型结构图如图2所示。 图2 Skip-Gram 模型图 2.2.3.2 DNN网络 DNN网络是由3层结构组成的一个多层感知机,分为输入层、隐藏层和输出层,每层结构中包含多个神经元节点[15]。本文利用DNN网络来学习用户与视频之间的高阶特征交互信息,使模型具有较强的泛化能力[16]。 DNN网络部分的输入包含3部分:稠密嵌入向量、序列嵌入向量和多模态嵌入向量。由于稀疏特征里包含高维稀疏的one-hot向量,需经过稠密嵌入层转化为低维稠密嵌入向量,送入DNN网络中进行训练。此外,本文将经过Word2Vec提取到的6种序列嵌入向量和经过降维后的视频多模态嵌入向量输入至DNN网络中学习高阶特征交互。 假设DNN网络的输入为a(0)=[e0,e1,...,ed](d为输入的个数),则DNN网络第l层的输出为 其中,yi为样本i的 真实标签,p(yi)是预测出样本i的概率。 本文采用的优化算法是自适应梯度算法(Adaptive Gradient, AdaGrad),该优化算法记录了历史梯度的逐元素累积平方和,并使用该累积和的平方根的逆作为学习率权重,解决了不同参数应该使用不同的更新速率的问题,自适应地为各个参数分配不同的学习率,具体如式(10)、式(11)所示 本文的数据集来源于某短视频平台官方公开的数据集,通过脱敏和采样处理后,该数据集包含20000个真实用户和106444个视频产生的7317882条历史数据,这些数据包括14天内用户查看评论、点赞、点击头像和转发视频等历史行为数据表和含视频作者、背景音乐、视频简介、关键字、标签和多模态内容等视频信息表。本文选取前13天的数据作为训练集,第14天的数据作为测试集。 本文的实验代码是利用Python3基于深度学习框架Pytorch1.5和Tensorflow2.5进行开发,所用操作系统为Windows10,实验所用服务器为4核32 GB显存的Tesla V100。 (1)Wide&Deep[5]。Wide&Deep模型是由谷歌研究人员提出的,该模型巧妙地将线性模型和深度学习模型进行融合,不仅考虑了低阶特征携带的信息,也考虑了高阶特征的交互信息。 (2)MMOE[17]。多任务学习模型(Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts, MMOE)也是由谷歌研究员提出的,主要是解决传统的多任务网络在任务相关性不强的情况下效果不佳的情况,常被用于推荐系统任务中。 (3)DeepFM[6]。模型在Wide&Deep的基础上,将线性模型替换为FM模型,无需手动交叉特征且可以同时学习到低阶和高阶特征的交互信息。 在CTR预测任务中,A UC(Area Under Curve)是最常用的评价指标,它反映的是整体样本间的排序能力,但实际上有时这并不能真正反映模型的好坏,这是因为A UC并没有考虑到不同用户或不同场景下的情况。为此,阿里团队提出了G AUC[18]用来衡量不同用户对不同广告之间的排序能力。针对复杂的短视频应用场景,不同的用户对于推送的视频进行点赞、转发等行为的情况是错综复杂的,因此,本文采用G AUC作为评价指标。本文首先计算不同用户下的A UC 的平均值uAUC 其中,n为测试集中用户的个数。 A UCi为第i个用户预测结果的AUC。 为了区分不同行为的重要性,本文统计用户过去13天内点击视频的次数用来表征用户的活跃度,本文对筛选出来的活跃度高的用户的历史行为进行分析,发现用户查看评论、点赞、点击头像和转发行为在用户历史行为序列的占比依次降低,因此本文对将要预测的用户查看评论、点赞、点击头像、转发行为这4个行为的u AUC分配不同的权重,进行加权平均,最后得到最终的G AUC值。计算如式(14)所示。 其中,ωi={4,3,2,1}表示权重值,i=1,2,3,4依次代表了用户查看评论、点赞、点击头像和转发视频4个点击行为。 本文通过调用genism函数库来使用Word2Vec模型,将用户的历史行为序列输入至Word2Vec模型,进而提取用户的序列特征。向量维数为16表示生成16维的用户序列特征向量,sg=1表示采用Skip-Gram算法,具体参数设置如表1所示。 表1 Word2Vec模型参数 多模态视频特征数据包含经过脱敏后的视频描述的文本识别信息、视频图像的图像识别信息和视频背景音乐的语音识别信息,为了利用PCA算法将512维多模态视频特征向量降维成32维稠密的向量,本文通过调用scikit-learn的decomposition模块进行PCA降维,将n_components设置为32,表示降维至32维,其余参数为默认值。 对于DNN网络的参数设置,本文采用4层全连接层,每层的节点数为(256, 256, 256, 128);每个field的稠密嵌入维数为16;batch_size的大小为256;激活函数为ReLU;优化器为Adagrad;dropout为0.3。 本文将基线模型和本模型进行了对比实验,实验结果如表2所示。 从表2可以看出,Wide&Deep模型的效果最差,远远差于DeepFM的效果。MMOE多任务模型对于用户的多行为点击预测任务有着一定的优势,相较于Wide&Deep模型GAUC提升了2.2%。Deep-FM模型是在Wide&Deep的基础上,将线性模型部分换成了FM,可以同时自动低阶和高阶的特征交互,效果有着明显的提升,相较于MMOE模型,DeepFM模型的GAUC提高了0.5%。本文提出的模型在DeepFM的基础上加入用户行为序列信息,学习用户的动态兴趣偏好,相较于DeepFM模型,本模型的GAUC提高了1.4%。 表2 模型性能比较 在模型的训练过程中,本文发现某些超参数的大小对模型性能影响较大。因此,本文选择了以下几个超参数进行研究。 3.7.1 DNN网络的层数 随着DNN网络的层数的增加能在一定程度上增强模型的学习能力和泛化性能,但如果网络的层数过大会出现模型过拟合的问题,影响模型的性能。具体如图3(a)所示。 3.7.2 dropout的大小 dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。dropout可以比较有效地缓解模型过拟合的问题,在一定程度上达到正则化的效果。本文将dropout从0增加到0.6,可以看出模型在dropout为0.3时,性能达到最好。如图3(b)所示。 图3 USCP模型的超参数研究 3.7.3 batch_size的大小 batch_size即1次训练所抓取的数据样本数量,适当的batch_size能使模型更快地收敛到全局最优值。本文通过不断地调整batch_size的大小从而使模型更好的收敛,发现模型在batch_size为270时达到最优的性能。具体如图3(c)所示。 在推荐系统领域,用户的兴趣偏好是一个动态变化的过程,根据用户的行为的变化学习出用户的兴趣变化,可以提高推荐质量。本文提出了基于用户行为序列的多行为点击预测模型,该模型可以同时学习到用户与视频的低阶和高阶特征信息,并且对用户的历史行为进行序列化建模,构造用户的序列特征,进而表征出用户的兴趣变化。最后,本文在某短视频平台上公开的数据集进行了实验,比较了不同的方案,结果证明本文提出的模型的性能都优于其他几个模型。后续,本文会将用户的兴趣进行细粒划分,进一步探究用户的兴趣表示。





3 实验
3.1 数据集
3.2 实验环境
3.3 基线模型
3.4 评价指标


3.5 参数设置

3.6 实验分析

3.7 超参数研究
4 结束语
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
矿产勘查(2020年11期)2020-12-25
数学物理学报(2019年3期)2019-07-23
数学物理学报(2018年3期)2018-07-17
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
高中生学习·高三版(2016年9期)2016-05-14
