
基于特效合成数据增广的YOLO算法在烟雾检测中的应用
2023-02-28 09:13凌宇志徐家新杨昊坤
数字通信世界 2023年1期
凌宇志,徐家新,杨昊坤
(中海油信息科技有限公司,广东 深圳 518000)
1 研究背景和意义
海洋石油作业环境复杂多变,海上油气勘探、开采生产工作是一项高危险的工作,因此,安全一直是油气生产工业的重中之重,也是企业生产过程中亟须解决的问题[1]。有毒及易燃易爆气体泄漏、流程热液异常刺漏、火灾隐患等都是海洋石油作业中的安全隐患。为防止海上溢油、单点系泊、工人生产跌落、生产设备设施跑冒滴漏等事故的发生,中国海油公司制定了“五想五不干”等安全措施,同时针对海上油田平台、油轮等制定了一系列的安全防范规范,通过加强人工巡检等手段来预防事故发生。但由于油气行业作业,尤其是海上油气作业环境恶劣,以及受装备、设备老化等诸多因素影响,事故依然时有发生,造成人员伤亡以及财产重大损失,产生极大的社会负面影响。
本文主要针对跑冒滴漏中的烟雾检测问题进行研究,通过数据增广方法对有限的样本进行扩充,采用YOLO算法对视频图像样本进行训练,最终达成了烟雾检测的目标。这不仅解放了定期巡查的企业员工,为企业节约了人力成本,更重要的是减少了人员在有害或危险环境中暴露的风险,将更多安全隐患消灭在爆发之前[2]。
2 理论基础
2.1 YOLO算法
YOLO算法属于无候选框的目标检测算法,具有检测速度快、实用性强、依赖简单、易于移植等优点,是目前最通用的目标检测算法之一。经过这几年的发展,YOLO算法已然成为实时目标检测算法中的标杆。本文作者基于DarkNet开源框架,采用C语言对YOLO算法进行了编程运行,并将该程序应用于烟雾检测应用当中,取得了较为理想的实验结果。
2.2 数据增广
数据增广又名数据增强,是在数据训练样本不足或数据场景单一的情况下通过增加有限数据的多样性和数据量,从而实现在有限数据中提取出更多的有效信息,让有限数据产出更多价值的一种手段。数据增广通用方法主要集中在数据图像变换方面,常见的数据增广有图像亮度信息变换、图像反转、旋转、高斯模糊等。
充足的训练数据是保证深度学习网络模型稳定的前提,但由于烟雾检测技术起步较晚,不像人脸识别、口罩识别、安全帽识别等技术已经商业化并且建立了多个行业标准训练数据集。烟雾的发生通常代表危险,视频图像采集难度极高。另外,烟火的危险性非常大,我们也难以进行大型的烟火实验来采集烟雾数据。基于此,本文采用烟雾发生器结合后期特效模拟的手段对烟雾数据进行增广[3]。
2.2.1 基于合成的烟雾数据集增广
因为部分复杂场景,譬如高空场景、地底管廊管线等危险场景,无法部署烟雾发生器,所以我们考虑在这部分场景中使用特效软件进行模拟,同时验证模拟数据集能否代替部分真实数据。
电厂现场拥有百余枚监控摄像头,可以通过录制收集各类各点位的烟雾素材。为了保证素材不重复,本文采用间隔提取的方法,平均间隔2 s提取一张图片。
针对位置过高、环境复杂类特殊场景,本文采用后期特效软件进行素材合成。我们收集了180个不同种类的烟囱烟雾的真实素材,同时使用AfterEffects的Particular系统模拟了一系列烟雾效果。
2.2.2 特效合成
叠加模式是一种通过两幅图像的像素值的加权叠加来合成新图像的方式,如式(1)所示。

式中,g是目标图像;f0、f1是两幅进行叠加的图片;a是权重范围(0~1)。从式(1)可知,黑色色块通过叠加不影响底层图像像素信息,可以做到不破坏原有像素图像信息。
2.3 数据标注
本文所使用的训练数据都是单帧图像,所以需要将收集到的视频和特效合成后的视频进行单帧截取。我们对视频每秒提取5帧图像。由于YOLO第一层卷积层输入分辨率是608×608,而我们收集到的烟雾视频分辨率基本是1920×1080,对于网络训练分辨率太高,所以通过resize到608×608分辨率进行进一步训练。
本实验采用labelimage进行标定工作,具体方法是:通过修改classes.txt自定义标类别为smoke,使用python打开labelimage软件,在图片上用创建矩形框包围烟雾范围,软件生成对应PASCALVOC格式的xml标签文件,之后利用python编写的转换器将生成的xml文件转换为包含图片样版本路径、标签路径、标定位置等信息的文本格式文件,为接下来的调用YOLO训练做好准备[4]。
3 算法设计与实现
目标检测领域中IoU是用以描述精度的性能指标,是指预测框与实际框所重叠占比,IoU损失的计算公式如式(2)所示。

本实验采用正确率(Precision)、召回率(Recall)、平均精度(AP)、平均精度均值(mAP)作为模型的评判指标。正确率是所有预测为正样本的结果中所有预测正确的比率,在本实验中,TP代表正确检测到烟雾的次数,FP表示错误检测烟雾的次数,FN代表漏检烟雾的次数。正确率Precision与召回率Recall的定义如式(4)、式(5)所示。

在本实验中,由YOLO算法来实现目标检测。YOLO算法基于dark net网络进行编写,实验是在Win10系统上进行的,每次迭代训练样本数为64,学习率为0.005。当迭代次数分别为10 000和15 000时,学习率衰减至0.003和0.0005。
本方法设计两组对照实验,用于探讨使用后期特效模拟的烟雾数据对真实拍摄数据的影响,以及使用模拟数据替代真实烟雾数据对模型性能的影响,多少百分比的模拟数据可以使模型达到一个最优值。
第一组实验用于对比特效模拟的烟雾训练集和真实烟雾训练集。测试数据集:选取2 000张真实拍摄的烟雾素材作为测试数据集。真实数据集:选取2 000张真实录制烟雾照片作为真实数据训练集。如图1所示。

图1 真实数据集
模拟数据集:选取2 000张后期特效模拟照片作为模拟数据训练集,模拟效果如图2所示。
图2 模拟数据集示例
检测结果对比如表1所示。

表1 检测结果对比
实验结果表明,拍摄烟雾素材和使用后期模拟烟雾素材所构建的模型性能相差并不大,说明在样本数据不足的情况下,使用特效模拟的数据可以替代部分真实拍摄数据。为了进一步探讨在真实数据量不足的情况下,后期模拟素材对实际模型精准度有多大的影响,我们设计了第二组实验。第二组对照实验用于讨论需要使用多少比例的后期模拟素材能够让模型精度达到一个比较好的状态。我们分别设计了1∶1、5∶1、1∶5的比例训练数据进行训练,详细数据如下。
(1)1∶1数据集:3 000张真实拍摄素材和3 000张后期特效模拟素材。
(2)5∶1数据集:5 000张真实拍摄素材和1 000张后期特效模拟素材。
(3)1∶5数据集:1 000张真实拍摄素材和5 000张后期特效模拟素材。
(4)真实数据集:6 000张真实拍摄素材。
不同比例训练集训练得出的模型对烟雾检测的测试结果如表2所示。
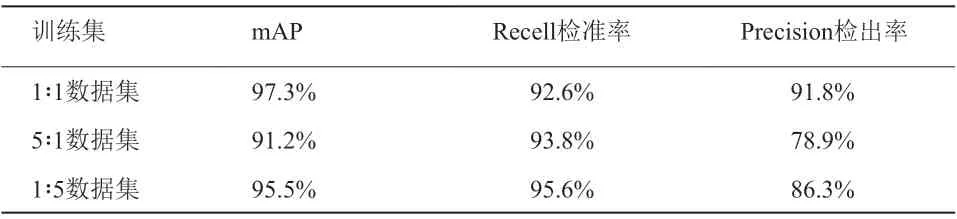
表2 不同比例训练集下测试结果
通过对比可以明显看出,在各个比例下的真实拍摄素材和后期模拟素材中,1∶1的比例能让模型拥有更好的性能,验证了前面提出的猜想。
4 结束语
本文通过使用后期特效软件制作上万张烟雾场景图片,结合现场实际拍摄的烟雾图片,能够让模型更好地识别烟雾。通过两组对比试验可以看出,以1∶1比例将实际图片和特效图片混合,可以让模型达到最佳性能,使用模拟素材提高了模型对烟雾识别的目标精准度。该算法及数据增广方法同样适用于其他目标检测应用,譬如使用YOLO算法识别水滴滴漏。漏水检测的素材同样难以收集,通常做法是在需要漏水部位进行模拟漏水拍摄或是使用吊瓶一类工具进行滴漏模拟。我们可以考虑使用黑色幕布拍摄一系列漏水、溅射一类的画面。如图3所示。

图3 液体滴漏示意
使用后期软件进行二次合成加工,可以得到相对拟真的图像。使用这类图片结合实际拍摄素材,以1:1进行混合加入模型训练,可以得到模型精准度超越单纯只有实际拍摄素材训练的模型,在样本数量不足或现场条件有限而无法获得大量训练样本的情况下很实用。■
猜你喜欢
小学阅读指南·低年级版(2021年3期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
作文小学中年级(2020年6期)2020-07-24
华人时刊(2019年13期)2019-11-26
成都信息工程大学学报(2019年4期)2019-11-04
阅读与作文(英语初中版)(2019年8期)2019-08-27
小学生学习指导(低年级)(2018年11期)2018-12-03
当代陕西(2017年12期)2018-01-19
现代防御技术(2016年1期)2016-06-01
科学启蒙(2014年12期)2014-12-09
