
逆强化学习驱动的公共交通乘客路径选择建模
2023-02-23 08:24:24廖采盈
交通科技与管理 2023年2期
廖采盈,张 彤,黄 练
(1.武汉大学测绘遥感信息工程国家重点实验室,湖北 武汉 430079; 2.深圳市易景空间智能科技有限公司,广东 深圳 518052)
0 引言
路径选择建模,是通过最大化个人在出行中遵循的效用函数来估计可能选择的路径。传统的路径选择模型多采用离散选择模型(Discrete Choice Model,DCM),模型通常从连接起点和目的地(Origin and Destination,OD)的路径选择集里选择一条路径,模型简单但需要提前对OD间的路径进行采样形成一个有限的选择集,这在大型的城市公共交通网络中是一项困难的任务[1]。同时大多数DCM假设了线性参数的效用函数,无法揭示复杂的路径选择偏好[2]。
近年来,深度学习因其良好的预测性能已经成为经典DCM的有力替代[3]。其中,深度逆强化学习(Inverse Reinforcement Learning,IRL)很适合用于路径选择问题,因为它在结构上与动态DCM相似[4],可以解释选择行为,并且足够灵活,可以纳入深度架构和高维特征捕捉非线性的偏好信息。IRL将路径选择问题表述为顺序选择路径段的马尔科夫决策过程,并从观察到的真实路径中恢复奖励函数(类似于效用函数)。最近的几项工作证明了IRL在路径预测[5]和路径生成[6]方面的潜力。
该文将在智能公交卡数据的驱动下,建立用于城市公共交通乘客路径选择的逆强化学习模型,利用深度神经网络近似奖励函数来纳入更多高维特征以捕捉潜在的路径选择偏好(成本)。最后,以深圳市公共交通网络为案例,进行分析。
1 方法
1.1 问题定义
该文将乘客的路径选择过程看作是一个马尔可夫决策过程(Markov Decision Process,MDP),此时乘客路径选择的概率和出行行为的成本可以通过策略网络、奖励(成本)函数得到解释。一个MDP通常可以描述为:智能体从某一个状态sS出发,根据策略π(a|s)在aA选取动作执行后,环境将会以pa(s,s')的状态转移概率转换到下一个状态s',同时将给予智能体一个确定的奖励r(s,s'),该过程将不断进行直到终止状态。逆强化学习的目标是要学习出一个奖励函数rθ(s,a),再使用它来学习最优策略π*(a|s),其中θ是参数。
1.2 模型构建
1.2.1 环境描述
该文基于OpenAI的Gym库[7]构建了城市公共交通网络的模拟环境,将公交站点、地铁站点定义为图节点,节点的连接边定义为交通线路和步行可达边,从而抽象表达出城市的交通网络结构,如图1所示。
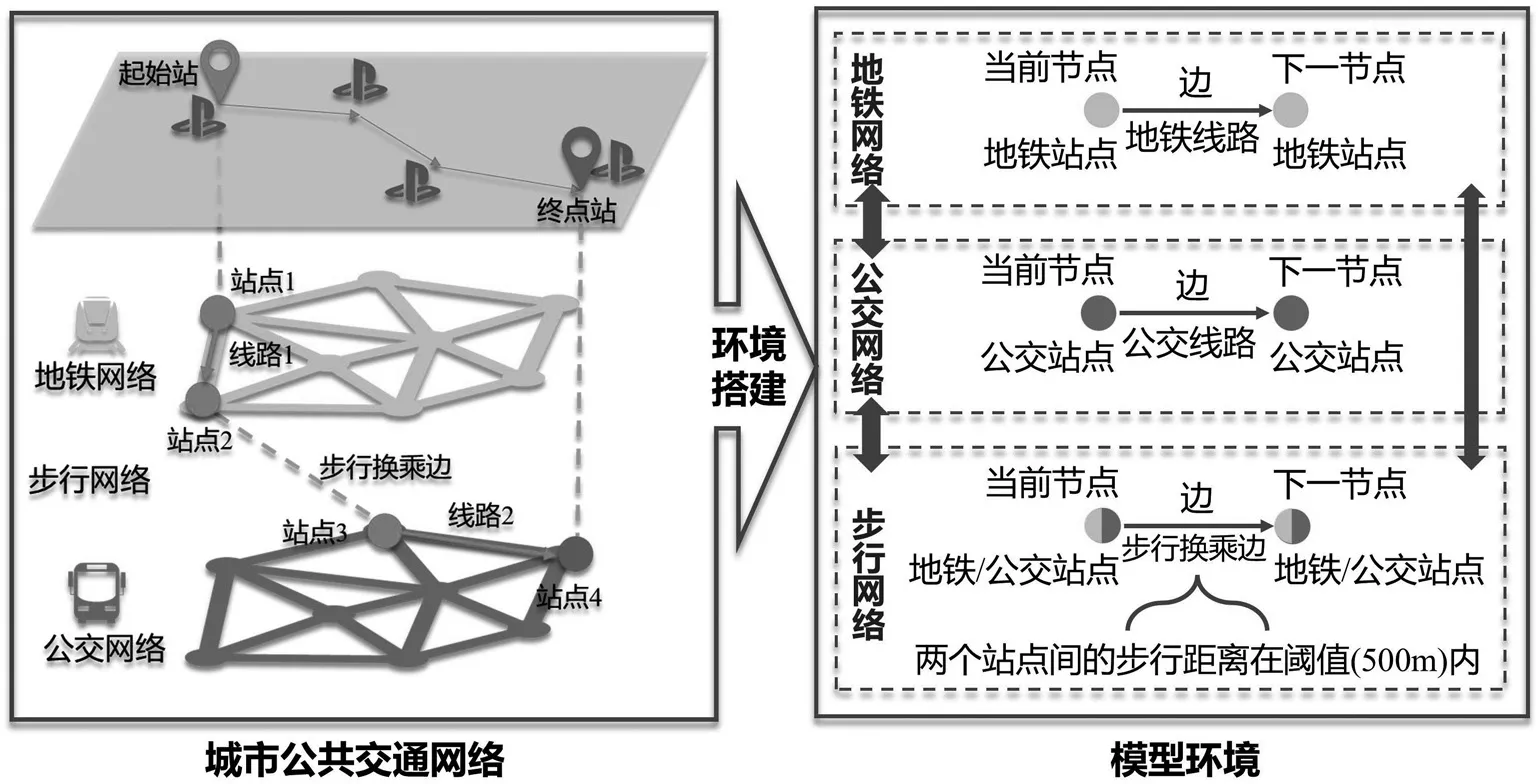
图1 环境交互下的出行过程表达
1.2.2 状态表达
状态来自对智能体的描述,即对乘客的位置、行程完成度和出行意图的特征表达。因此,该文设计了如图2所示的状态表达网络结构来提取乘客的出行条件,希望具有相同行为序列的乘客被映射到相似的向量空间之中,以此区分不同出行的乘客状态。
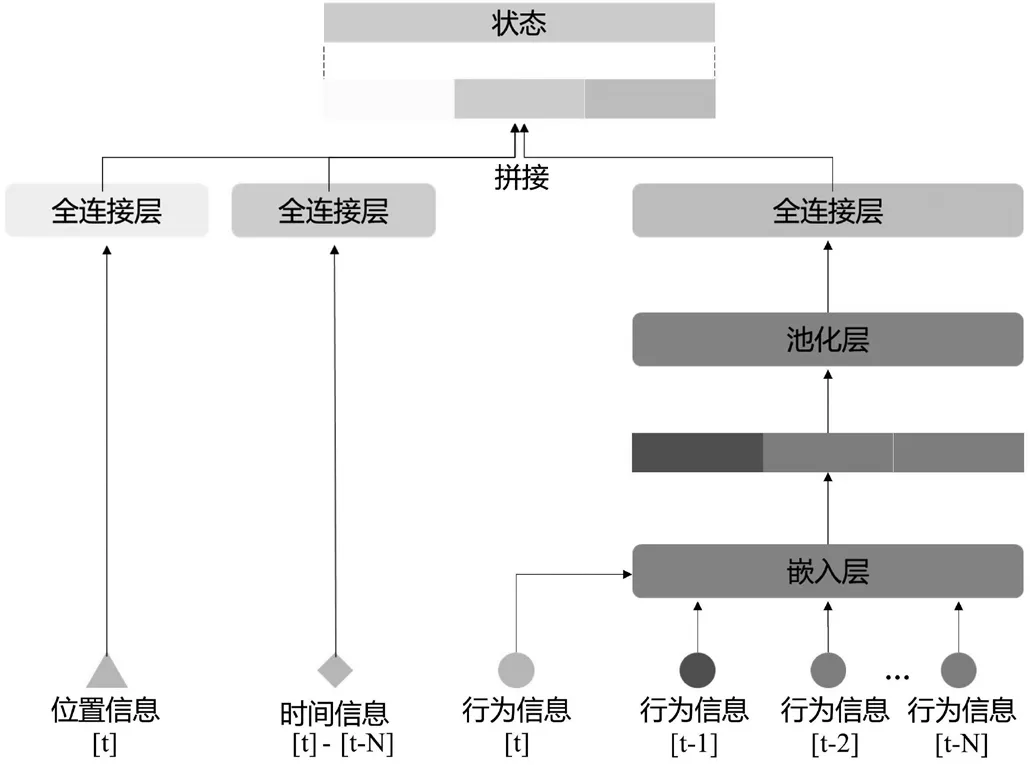
图2 状态特征表达网络
1.2.3 行为设计
模型的动作空间由公共交通网络环境中的路径组成,考虑到路径选择与出行行为的对应关系,可将乘客的路径选择抽象为三个可解释的出行行为:
(1)本站乘车:不下车,继续乘坐本线路到下一站。
(2)本站换乘:在本站下车,乘坐本站其他线路到下一站。
(3)异站换乘:在本站下车,步行至其他站点,乘坐某一线路到下一站。
1.2.4 成本估计
成本具体体现为乘客每一次选择路径后进行状态转移所应花费的相应成本,在求解对不同出行行为的乘客偏好时,难以用一个统一的成本函数形式来参数化乘客对不同行为成本的衡量标准,因此我们通过构建一个对抗逆强化学习模型来优化由深度神经网络近似的成本函数。
Finn[8]指出,逆强化学习目标函数公式(1)与生成式对抗网络的目标函数公式(2)有着极其相似的性质,并证明了生成式对抗网络优化的正是最大熵逆强化学习的目标函数:
因此将生成式对抗网络的思想应用到逆强化学习问题,其中,判别器的目标函数D(s,a)由公式(3)给出,其中由状态价值函数和状态动作价值函数的优势差由公式(4)得到。
1.3 用于路径选择的对抗逆强化学习模型
综上,该文提出基于生成式对抗网络的逆强化学习模型,迭代求解最优策略下的最优奖励函数。模型流程如图3所示。
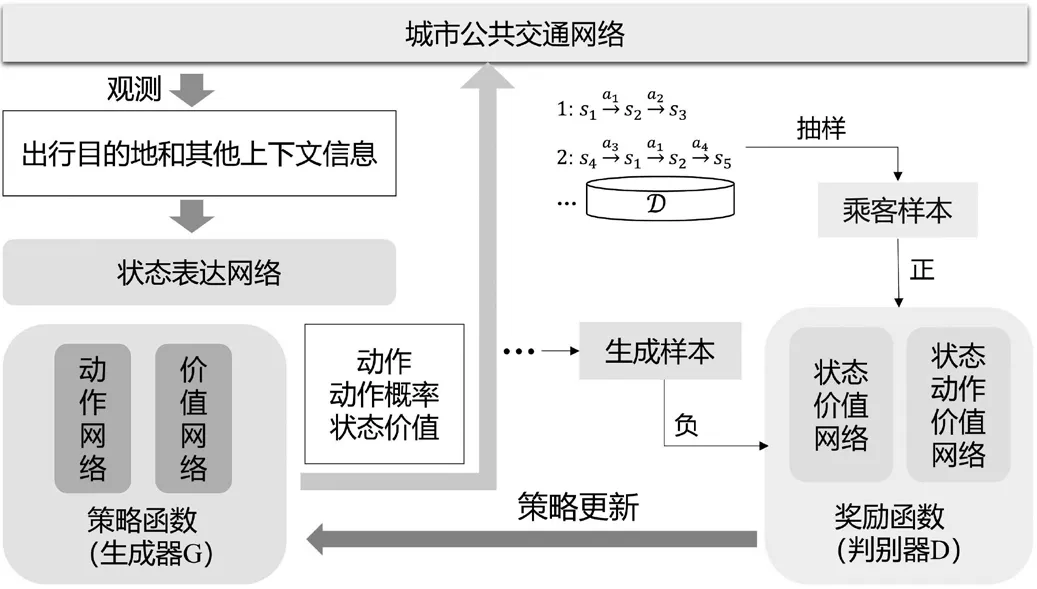
图3 模型流程图
2 实验
2.1 数据准备
该文以深圳市公共交通系统作为实例研究,使用的数据包括城市交通网络数据和公共交通乘客出行数据如下所述:
(1)城市交通网络数据:2017年深圳市公交站点、地铁站点、公交线路、地铁线路组成的交通路网,包括816条公交线路,8条地铁线路。
(2)公共交通出行数据:基于深圳市2017年4月20日星期四的公共交通出行链数据,数量约为372万,进行模型的训练与测试。
2.2 结果分析
选取某一OD对,将起始站出行路径的真实乘客样本的起点状态输入模型,应用生成器进行模拟样本的生成,再通过判别器输出对真实样本和生成样本中各出行选择行为的预测,结果如图4所示。可以看出,生成样本不同行为的成本与真实样本能很好地匹配,在一些成本比较小的行为上也能达到良好的预测效果。因此除了应用判别器网络来估计乘客出行行为成本外,模型还可为公共交通规划模拟乘客出行、预测客流量提供一些决策数据支撑。
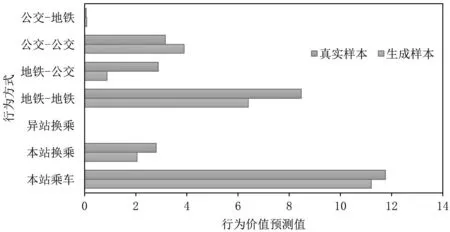
图4 判别器对乘客样本和生成样本的行为成本估计
3 总结与展望
该文基于马尔可夫决策过程,将乘客的路径选择表示为在环境中路网路径的选择,再基于站点-线路的组合抽象出出行行为;乘客的状态集成了乘客当前的出行情况,定义为乘客当前位置、乘客的累积时间花费、乘客的出行行为序列。通过基于生成式对抗网络的逆强化学习模型训练出衡量乘客路径选择的成本函数,然后基于这一成本函数可从出行成本角度对乘客不同出行行为进行分析。该文提出的路径选择模型如何应用到公共交通运营规划和资源配置中将是下一步的研究重点。
猜你喜欢
环球时报(2022-10-10)2022-10-10 13:49:24
中学生数理化·八年级物理人教版(2022年3期)2022-03-16 05:55:10
城市公共交通(2021年3期)2021-04-15 06:39:16
绿色科技(2021年2期)2021-03-11 00:37:38
今日农业(2019年16期)2019-01-03 11:39:20
安徽农业科学(2017年14期)2017-07-05 03:16:36
自动化学报(2017年1期)2017-03-11 17:31:10
数学小灵通(1-2年级)(2016年3期)2016-11-15 08:56:16
中国交通信息化(2016年3期)2016-06-05 02:21:43
公民与法治(2016年2期)2016-05-17 04:08:24
