
跨境电商新品榜数据自动跟踪研究与实现
2023-02-22 09:14叶文全
电大理工 2023年4期
叶文全
(闽北职业技术学院,福建南平 353000)
0 引言
选品是跨境电商运营的一个痛点,采集跨境电商新品榜数据能够获取市场趋势和竞争情况,为选品提供数据依据,但使用人工跟踪新品榜数据难度大、效率低。本文通过对Scrapy框架技术在电子商务中的应用分析[1-4],同时,深入研究Scrapy框架、网页数据解析、Selenium自动化操作和数据批量存储等技术,得出了使用程序化实现新品榜数据自动跟踪的技术可行性,提出一种基于Python、Selenium 和Scrapy框架技术的A站新品榜数据自动跟踪解决方案。方案使用模拟浏览器、代理IP、Cookie、错误重试等方法应对A 站的反爬虫机制,合理创建爬虫和爬虫调度机制,实现爬虫工作自动化。使用CSS 选择器和Xpath[5]技术获取商品数据,针对存储在JavaScript 中的ASIN 相关数据使用JSON 解析[6]获取。对商品数据的存储进行了数据库连接优化和批量存储优化,批量存储使用存储过程和表值参数[7]实现,进一步提高数据存储效率。使用Python 和Selenium 实现商品商标的自动化查询,将R 标的商品从选品库中删除,有效规避侵权的发生,为跨境电商选品提供符合市场需求且侵权概率低的数据依据。
1 反爬虫应对方法与爬虫设计
1.1 反爬虫应对方法
A 站作为一个大型电商平台,采取了多种反爬虫机制来保护其数据和资源,包括User-Agent检测、IP封锁和限制、人机验证、动态页面和JavaScript 渲染、访问频率限制、Cookie 和Session 跟踪等,大大提高了数据采集的难度。通过使用Scrapy 框架的下载中间件,支持程序在爬虫发送请求之前和接收到响应之后进行预处理和后处理操作,为应对反爬虫机制提供了策略和实现方法。下载中间件类的主要方法如表1所示。

表1 下载中间件类的主要方法
通过对Scrapy 框架下载中间件和爬虫工作流程的研究,本方案针对A 站反爬虫机制的主要应对方法如下:
第一,设置User-Agent 和Cookie,模拟真实浏览器发出的请求。通过自定义下载中间件类,并在process_request 方法中指定request.headers['User-Agent']和request.cookies。
第二,使用代理IP,降低被检测和限制的概率。本方案通过搭建代理IP 管理系统,使用端口号调用不同的代理IP,使用IP 白名单实现代理IP 使用的授权,提高代理IP 使用灵活性的同时,也保证了代理IP 使用的安全性。代理IP的指定在自定义下载中间件类的process_request方法中实现,主要代码如下:
request.meta['proxy'] = "代理IP 接口?port=%d" % port
第三,根据所需采集的数据量,设置合理的请求并发数,并设置随机间隔请求时间,提高请求成功概率。通过指定项目CONCURRENT_REQUESTS 的值,控制爬虫在同一时间内发送的请求数量,实现对爬取速度的调节。通过指定项目DOWNLOAD_DELAY 的值,控制爬虫发送请求之间的延迟时间,其默认延迟时间是固定的,需要将项目RANDOMIZE_DOWNLOAD_DELAY 的值设置为True,才会实现随机延迟,随机延迟时间的取值范围:
[0.5 * DOWNLOAD_DELAY,1.5 *DOWNLOAD_DELAY ]
第四,HTML 解析无法直接获取的数据,可通过处理JavaScript 代码构建JSON 字符串,使用json.loads( )函数将其转换为Python 字典对象并获取数据。
第五,当商品采集失败且失败次数小于设置的重试次数时,进行采集重试,提高商品采集成功率。通过RetryMiddleware 中间件处理请求出现的异常并进行重试,RETRY_ENABLED指定是否启用重试,RETRY_TIMES 指定最大重试次数,RETRY_HTTP_CODES 指定需要重试的HTTP 状态码。由于A 站会将怀疑是爬虫的请求重定向到人机验证页面,因此,针对发生重定向的请求也要进行请求重试。请求重试时,使用新的代理IP,提高请求成功率。本方案还对数据库商品表进行轮询,针对采集状态失败的商品在间隔一定的时间后,再次启动爬虫任务。
1.2 爬虫设计
本方案将新品榜列表页和商品详情页的数据采集分为两个爬虫实现,分别是:新品榜列表页爬虫(crawl_list) 和商品详情页爬虫(crawl_detail)。同时,创建爬虫调度程序,通过从数据库中读取需要采集的新品榜类目和需要采集的商品ASIN,自动执行相关爬虫。以商品详情页爬虫调度为例,主要流程如下:
第一,从数据库中读取需要采集的商品ASIN:select top 1 asin from tb_asin where isCrawl=0 and errorTime<3 and datediff(s,lastCrawlDetail-Date,getdate())>300 order by NEWID()。
第二,使用线程(threading.Thread)启动商品详情页爬虫,并将对应的ASIN使用自定义参数传入:os.system("scrapy crawl crawl_detail-a asin=%s " % asin)。
第三,通过threading.enumerate( )控制线程并发数,当没有商品需要采集时,暂停调度。
2 商品数据获取与商标查询
2.1 商品数据获取
本方案需要采集的商品数据项包括ASIN、商品标题、销售价格、主图、商品属性(颜色、尺码等)、所属品牌、物流方式、销售商、供货国家、上架时间、最新评论时间、评论数、店铺编号等。通过对A 站相关页面源码的分析与多种呈现方式的总结,得出商品数据项获取方法如表2所示。
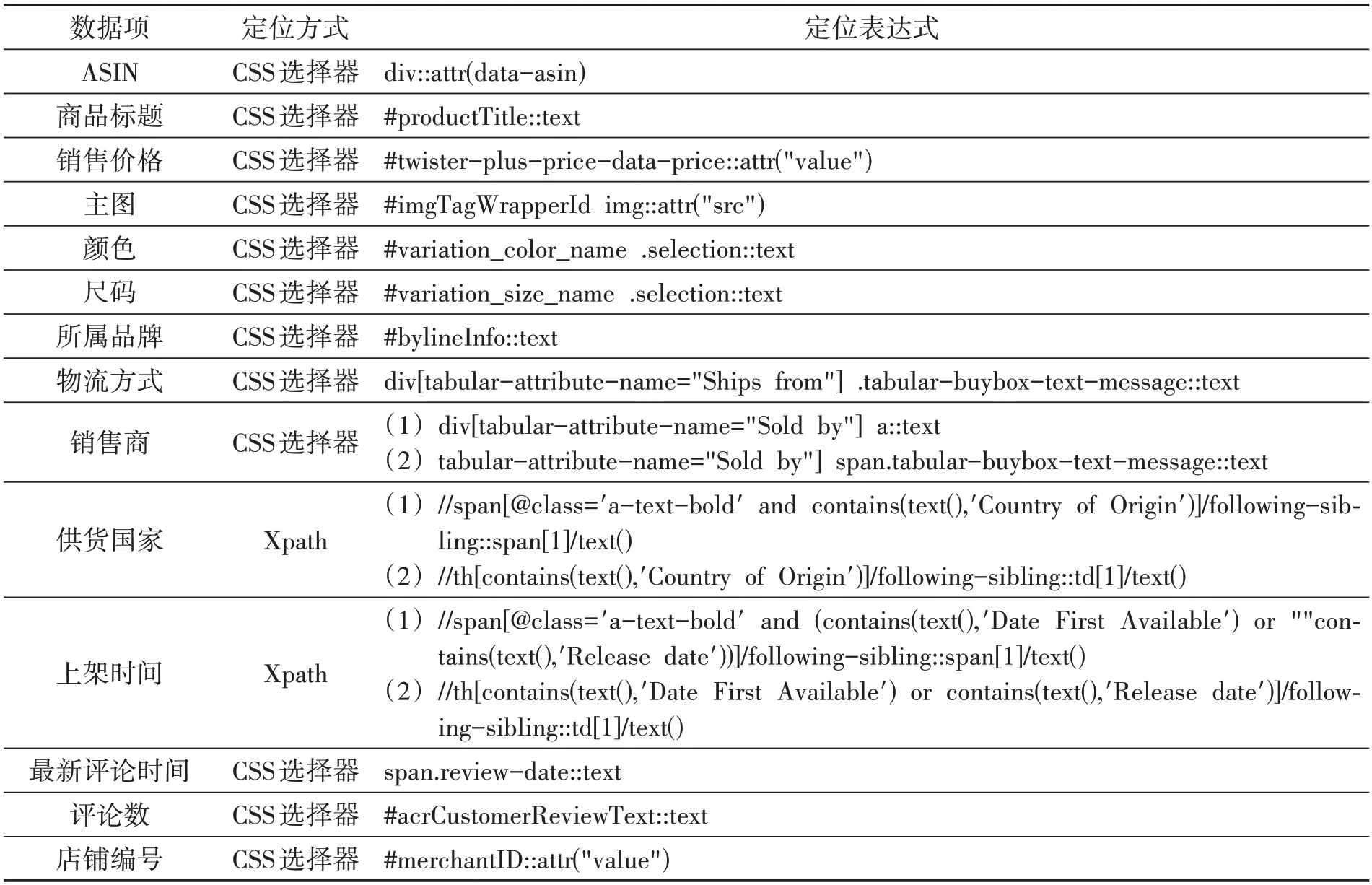
表2 商品数据项获取方法
当前商品ASIN 相关数据存储在商品详情页的JavaScript 代码中,HTML 解析无法直接获取,需要按JSON 格式截取、拼接的方式构建JSON字符串,并使用json.loads( )函数将其转化为Python字典对象,从而实现所需数据的获取。商品ASIN 相关数据包括当前ASIN、父ASIN、商品属性维度、各商品属性维度包含的属性值、映射商品属性维度和对应的ASIN 等,如表3所示。
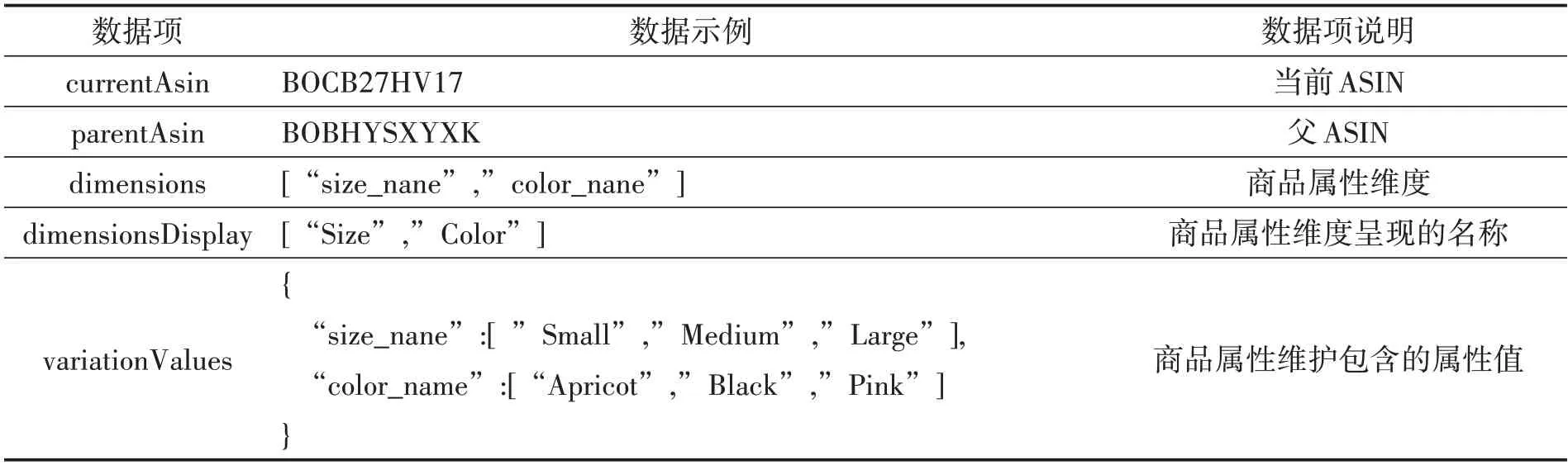
表3 商品ASIN相关数据
获取商品ASIN相关数据的主要代码如下:
script_list = sel.css('script::text').extract()
for script in script_list:
flag = script.find('"currentAsin"')
if flag != -1:
# 构建json字符串
script = '{' + script[script.find('"currentAsin'):]
script = script[0:script.find('};')] + '}'
# 使用json.loads 方法,将构建的JSON 格式的字符串解析为Python对象
json_data= json.loads(script)
# 读取dimensionToAsinMap 属性,该属性映射了商品属性维度和对应的ASIN
dimensionToAsinMap = json_data['dimensionToAsinMap']
2.2 商品商标查询
A 站对商品侵权的处理非常严格,一旦检测到卖家的商品侵权,直接下架涉嫌侵权的商品,严重的会冻结账号,资金无法提现。因此,在选品时不能选择会造成侵权的商品。商品商标包含R(REGISTER)标、TM(TradeMark)标和无商标。R 标具有排他性、独占性、唯一性等特点,未经商标所有权人许可或授权不能使用,否则将涉及侵权;TM标若商标未经商标局核准注册,其受法律保护的力度不大。因此,在选品时要严格规避选用R 标商品。在美国商标局网站(tmsearch.uspto.gov)上可以查询商标,但使用人工查询的方式效率太低,难以满足大量商标的查询和TM 标后期的跟进查询。本方案使用Python+Selenium 操作Chrome 浏览器,实现商品商标自动查询,验证商品商标类型(R 标、TM 标、无商标),如果商标是TM标,在间隔一定时间(默认为半个月,系统可配置)后,重新检测,验证TM标是否转为R标。2.2.1 Selenium自动化技术研究
Selenium 使用ChromeDriver 驱动Chrome 浏览器,所下载的ChromeDriver 版本需要和运行环境的Chrome 浏览器版本及操作系统匹配。在使用Python+Selenium 实现商品商标的自动化查询时,可能遇到的问题及解决方法如下:
第一,遇到网站证书错误的问题,导致页面无法正常打开,可以通过添加ignore-certificate-errors 参数,忽略网站证书验证,主要代码如下:
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--ignore-certificate-errors')
第二,被目标网站识别为自动化工具,导致拒绝访问,可以通过配置浏览器的行为,绕过自动化工具检测,主要代码如下:
chrome_options.add_experimental_option('excludeSwitches', ['enable-automation'])
chrome_options.add_experimental_option('useAutomationExtension', False)
browser=webdriver.Chrome(options=chrome_options)
browser.execute_cdp_cmd(
'Page.addScriptToEvaluateOnNewDocument',
{
'source': 'Object.defineProperty(navigator,"webdriver", {get: ()=>undefined})'
}
)
2.2.2 商标自动化查询实现
本方案通过在美国商标局网站查询商标,来确定相应的商品是否侵权。经测试,必须通过点击主页的商标查询链接进入商标查询页,才能正常使用商标查询功能,否则会报错,报错信息如图1所示。
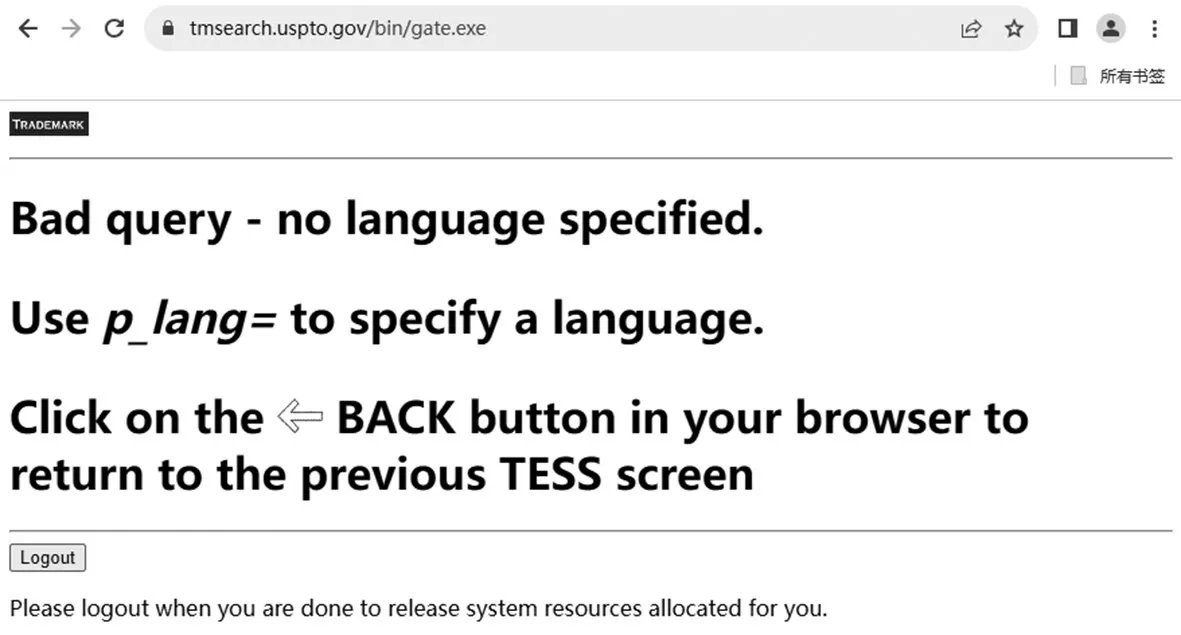
图1 直接访问商标查询页的报错信息
使用Python 和Selenium 技术实现商品商标自动化查询的主要步骤及核心代码,如表4所示。

表4 商标自动化查询实现
3 商品数据存储优化
3.1 数据库连接优化
完成一次爬虫任务往往要执行多次数据存储,以新品榜列表页爬虫为例,执行一次爬虫任务需要存储200 多个商品基本信息,如果每次存储都要单独创建数据库连接,则需要创建200 多次数据库连接,不仅更加消耗时间、影响性能,还可能导致数据库连接池不足,无法及时处理新的连接请求,甚至因为数据库服务器负载过重而崩溃。Scrapy 的ITEM_PIPELINES配置项用于指定处理数据的管道,可以对爬虫爬取到的数据做进一步处理和存储。本方案中的数据存储集中在数据管道类的process_item 方法中实现,不同的爬虫通过爬虫名称(spider.name)加以区分,实现不同数据的存储。同时,在open_spider 方法中创建数据库连接,在close_spider 方法中关闭数据库连接,一个爬虫任务不管要存储多少次数据,只需要创建一次数据库连接,爬虫任务执行完毕后,自动关闭数据库连接。
3.2 数据批量存储优化
当数据实时性要求较高时,为了确保数据立即被存储至数据库,一般使用单条存储。单条存储需要多次与数据库进行交互,每次插入操作都会引起一次网络通信和磁盘写入开销,对于大量并发的单条插入操作,可能引发数据库的高负载情况,导致资源竞争和性能下降。批量存储减少了数据库交互、网络通信和磁盘写入的次数,从而提高存储性能,但数据的存储存在一定的滞后性。本方案中的商品数据存储实时性要求不高,使用批量存储提高存储性能。本方案采集到的商品数据通过数据管道进行临时存储,当商品数据达到一定数量或采集结束时进行批量存储。
SQL 字符串拼接批量存储和存储过程批量存储是两种常见的批量存储方式。使用SQL 字符串拼接批量存储简单易用,但存在以下不足之处:
第一,一次性执行大量SQL 语句,需要注意SQL 语句的长度限制,避免超出数据库的限制。
第二,每次执行SQL 语句,数据库系统需要解析、编译和优化该语句,并生成执行计划,需要消耗较多的时间和系统资源,对于复杂的查询和操作,效率更加不如存储过程。
第三,直接使用SQL 语句容易暴露数据库的敏感信息,同时,存在SQL注入的安全风险,攻击者可以通过构造特殊的SQL 语句绕过身份验证,进而提取、修改或删除重要数据,甚至更严重的攻击,安全性差[8,9]。
第四,将SQL 语句直接写在爬虫代码中,一旦需要修改或优化SQL 语句,则需要修改爬虫代码,可维护性差。
本方案使用存储过程实现批量存储,相比SQL 字符串拼接批量存储,安全性和存储效率都更高[10]。使用表值参数传递批量数据,相比XML 参数性能更高,适用频繁使用的批量数据传递场景。在MS SQL 中,使用表值参数,需要自定义表类型(User-Defined Table Type),用于定义表值参数的结构,包括列名、数据类型和其他约束。在Python 中使用pymssql 的Table 方法创建表值参数,使用游标的register_table方法注册表值参数的类型。
4 结束语
文章以A 站为例,阐述了一种基于Scrapy的跨境电商新品榜数据采集方案。该方案在反爬虫机制应对、爬虫调度上做了优化,提高了数据采集的稳定性,构建JSON字符串并解析获取存储在JavaScript 中的ASIN 相关数据,提高了数据获取的完整性,使用存储过程和表值参数实现商品数据批量存储,提高了数据存储效率和安全性,降低数据库负载,完整的实现了新品榜的商品数据自动跟踪。该方案已投入实际使用,目前实现了A 站20 多个类目新品榜数据的自动跟踪,性能稳定、数据完整,运营人员选品难度大大降低,选品效率提高10 倍左右。下一步将继续优化选品算法,完善智能选品推荐和一键找货源功能。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
农家参谋(2021年6期)2021-08-03
现代信息科技(2021年21期)2021-05-07
科学家(2021年24期)2021-04-25
智富时代(2019年8期)2019-09-24
智富时代(2019年8期)2019-09-24
商场现代化(2019年12期)2019-09-05
电子测试(2018年1期)2018-04-18
电子制作(2017年9期)2017-04-17
农家参谋(2017年8期)2017-03-25
