
乡村振兴背景下农民幸福感知路径与优化逻辑
——基于省域面板数据的组态研究
2023-02-22 14:35张新亮
乡村科技 2023年23期
张新亮
南昌大学公共政策与管理学院,江西 南昌 330031
0 引言
自2017 年乡村振兴战略实施以来,我国政府为了让人民过上幸福美好的生活,采取了一系列综合有效的措施,取得了令世界瞩目的成就。然而,全面推进乡村振兴最艰巨最繁重的任务仍然在农村[1],农民生活是否幸福美好是评价乡村振兴战略实施成效的关键指标[2-3]。如何实现农村地区高质量发展、促进农民幸福感提升,也是当下学界探讨的热点问题[4]。近年来,学界开始关注政府行为对公众幸福感知的影响。例如,陈刚等[5]使用O-Probit 回归模型考察了政府质量、办事效率对居民幸福感知的影响,结果发现良好的政府形象与工作绩效能够显著提升居民幸福感;祁玲玲等[6]认为,政府供给并不能直接影响居民幸福感知,而是先影响居民对政府的信任度,然后才会对居民的主观幸福感造成影响;董源等[7]研究表明,高水平的公共服务往往能够提高居民的主观幸福感知,并建议重点推进社会保障制度完善,以提升居民幸福感。总体来说,已有研究开始强调政府供给对居民幸福感知的重要作用,并根据各自研究提供了相应的政策建议。但既往文献大都从经验主义视角对农民幸福感知路径进行分析,其路径本身缺乏外部有效性的检验。鉴于此,笔者在前人研究的基础上,根据现有理论,利用2017—2021年河北、山西、内蒙古、辽宁、吉林、黑龙江、江苏、浙江、安徽、福建、江西、山东、河南、湖北、湖南、广东、广西、四川、贵州、云南、陕西、甘肃及青海等23个省(自治区)农村地区的面板数据,从组态视角着重探寻农村基础建设、经济质量、人居环境等方面与农民幸福感之间的多重并发关系,为政府开展治理工作提供参考。
1 研究设计
1.1 方法选择
相比传统实证研究方法,定性比较分析(Qualitative Comparative Analysis,QCA)方法在应对前因复杂性、降低现象复杂度、完整解读案例等方面具有显著优势[8]。目前,在公共管理领域,学术界将QCA 方法广泛应用于政策议程设置、政策执行、数字政府和地方政府治理等方面。但随着研究的深入,传统QCA 方法本身存在的局限性不断显露,如阿克塞尔·马克斯等[9]指出QCA 方法在样本选择方面缺乏纵深分析视角,无法生成稳健的组态路径等。为了拓展QCA 方法的纵深分析视角,有学者提出基于面板数据研究的动态QCA方法[10],在保留传统定性比较分析方法的布尔运算逻辑的同时,实现对面板数据的纵深研究。2022 年,张放[11]率先在国内将动态QCA 方法应用于政府信息公开水平影响因素探究。笔者在现有理论和前人研究的基础上,运用动态QCA 方法对省域面板数据中有关农民幸福感的数据进行纵深分析。
1.2 评价指标体系的构建及数据来源
1.2.1 评价指标体系的构建
缩小城乡差距,提升农村公共服务供给水平,是乡村振兴的要义之一。该研究认为,由公共部门所提供的客观福祉被宏观概念上的公共服务所涵盖,即客观福祉水平能够反映公共服务的供给水平。山东大学生活质量与公共政策研究中心课题组已经连续15 年对中国居民客观福祉进行统计、分析和评价,形成了比较全面的中国居民客观福祉评价指标体系。在此基础上,笔者根据罗必良等[12]最新研究成果、农民生活情况,构建了由7个维度、共27个条件变量组成的农民幸福感评价指标体系(见表1)。
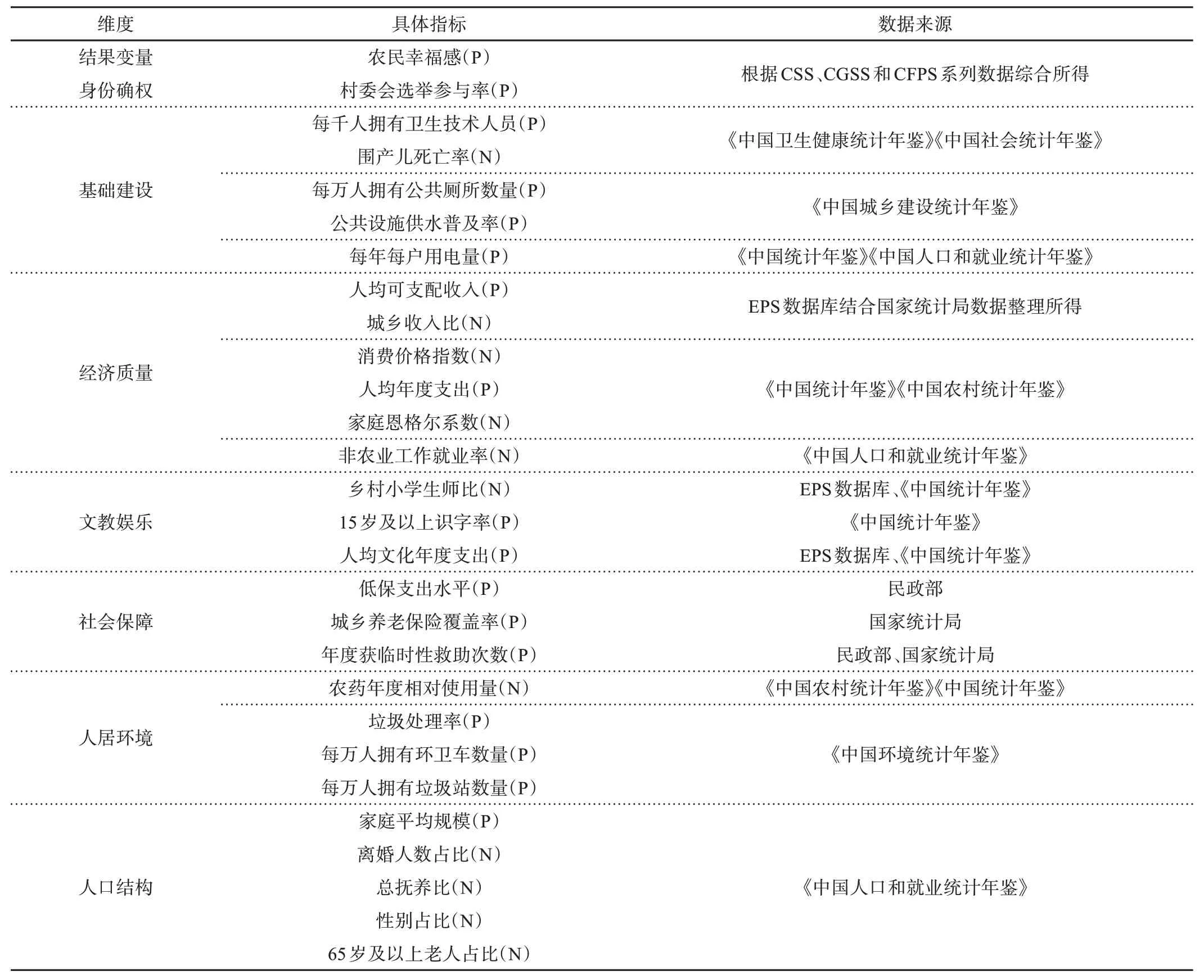
表1 公共服务与幸福感评价指标体系
1.2.2 数据来源及预处理
鉴于数据可得性及该研究重点,选取2017—2021年中国23 个省(自治区)的相关面板数据进行研究。在农民主观幸福感和身份确权方面,中国社会状况综合调查(Chinese Social Survey,CSS)、中国家庭追踪调查(个人库)(China Family Panel Studies,CFPS)和中国综合社会调查(Chinese General Social Survey,CGSS)系列数据库均包含有关农民主观幸福感和“是否参加上届村委会选举”的题项。考虑不同量表之间量程不统一的情况,笔者将每年度指标数据的最大、最小及中间值分别赋值1、5、10,并根据具体选项内容对其他得分逐一编码为不同变量,最终得到2017—2021 年中国23 个省(自治区)农民有关主观幸福和身份确权的省域面板数据。
其余变量数据来自各统计年鉴及官方公开资料,部分数据经过统一处理后所得。对于少量缺失数据,笔者根据其时间轴上的分布特征,视情况采用均值法或一次加权移动平均法(对最近2 年数据分别赋予0.6、0.4 权重值进行移动平均)进行补全操作,以保证数据的平衡性。由于各具体指标变量无法直接进行运算,笔者参照邢占军[4]的做法,通过max-min 方式对所有条件变量数据进行标准化处理,将指标体系中所包含的正、负向指标数据分别通过式(1)进行无量纲化处理。
式(1)中:Zi表示无量纲化后的数据;xi为各具体指标;和分别表示以2011 年为基年,取其对应具体指标的最大、最小值对变量数据进行校准。
考虑具体指标在面板数据中存在调整或缺失的现象,笔者在基年指标缺失时根据实际情况将该具体指标基年数据自动平移至原基年最近的年份,并将其作为最终的基年数据进行无量纲化处理。根据经过上述处理后的数据熵值特征,分别对各具体指标赋予权重,具体变量数据来源如表1所示。
2 数据分析及实证结果
2.1 数据校准
在进行组态必要性和充分性分析之前,标准化的数据需要进行二次校准,以降低前因条件的复杂性。由于目前学界在该研究所涉及具体指标对结果变量产生的影响方面还存在较多分歧,为了尽可能消弭隐性矛盾,笔者选择95%、50%和5%作为二次校准锚点,以此对整体数据进行直接校准。为尽可能保留数据中所蕴含的信息及防止数据丢失,对二次校准后的数据采取放大处理,具体校准结果见表2。

表2 变量校准
2.2 农民幸福感知单个条件必要性分析
在定性比较分析方法中,单个条件必要性分析是探讨条件变量对结果变量是否存在必要影响的关键步骤,能够进一步降低条件变量的复杂度,提升研究结果的准确性。为了实现时间纵深分析的同时实现横向截面分析,笔者对各条件变量组间、组内的调整距离进行一并汇总,具体分析结果如表3 所示。在动态QCA 方法分析中,若某变量调整距离小于0.2,则代表该汇总结果准确,可以作为判定标准。在表3中,调整距离小于0.2 的单个条件变量的汇总一致性均小于0.9,说明这些变量不是结果变量的必要条件。其余条件变量的调整距离大于0.2,说明汇总结果不够准确,需要对其进行更深层次的探讨。分别对组间调整距离大于0.2条件变量的组间一致性和覆盖度进行分析,发现低水平的“身份确权”有可能是导致幸福感较低的必要条件。再加上相关研究普遍认为“身份确权”能够对农民的幸福产生显著的促进作用[13],因而认为该变量是实现高水平幸福感的核心条件。
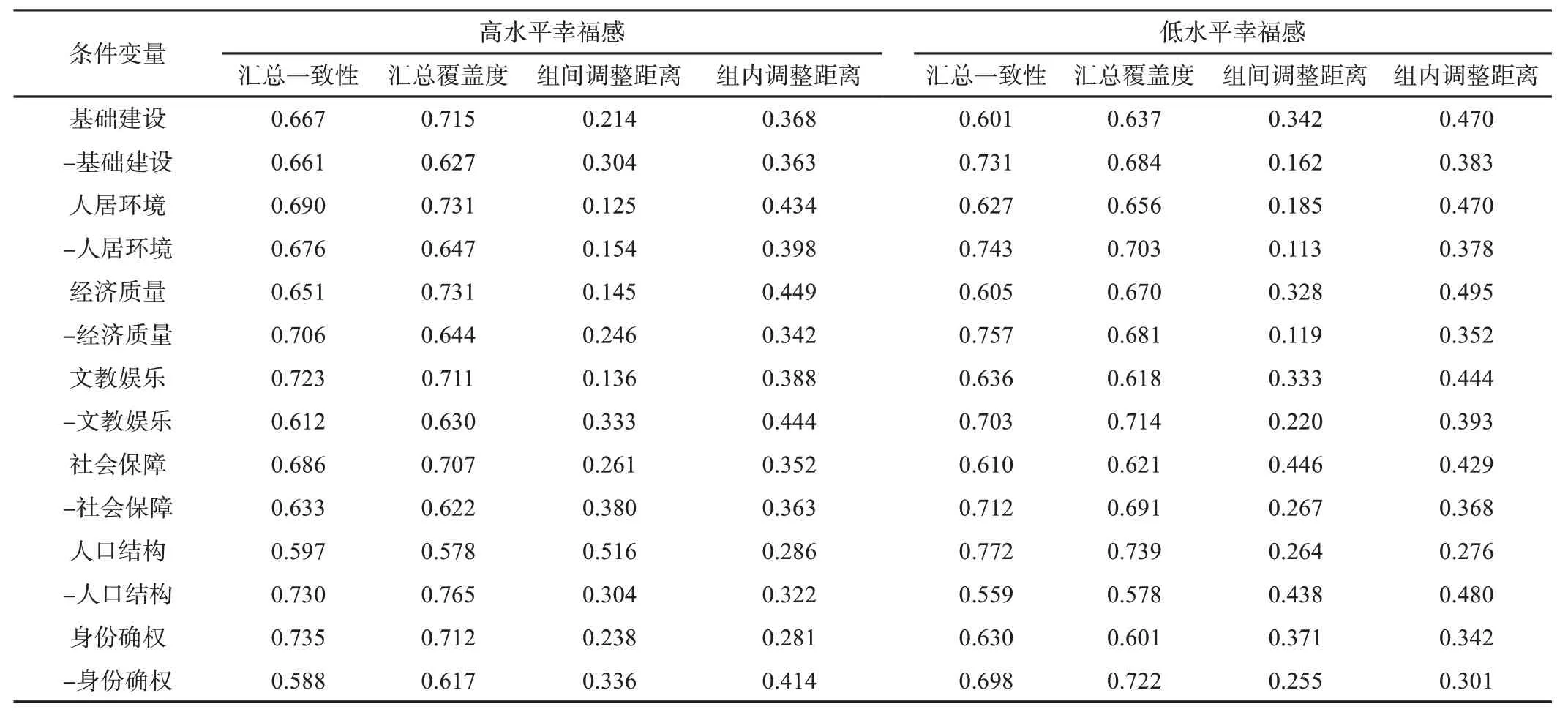
表3 单个条件必要性分析结果汇总
2.3 农民幸福感知路径充分性分析
为了探寻条件变量所构成的不同组态和结果变量存在的多重并发关系,笔者在现有理论和前人研究的基础上,根据数据特点,将一致性阈值设置为0.8,并指定PRI阈值为0.7,对所覆盖案例进行组态充分性分析。根据前文必要性的分析结果,认为身份确权有利于农民幸福感的提升,因此在进行组态充分性分析时将“身份确权”变量设置为正向。这样,采用动态QCA方法进行组态充分性分析时便会优先探索增加“身份确权”变量的取值。
考虑我国各省(自治区)农村地区的人口空间分布、年龄结构、资源禀赋等方面有着较大的差异,难以对条件变量的影响作用一一判别,因此不再对其他变量进行方向预设。此外,为提升分析结果的精准度和政策价值,笔者在进行低幸福感组态充分性分析之前将高水平“身份确权”设置为负向,辅以增强标准解对导致低幸福感的路径进行研究。最终共生成7 条组态,其中组态1、2、3为高水平幸福感提升路径组态,其余组态为导致低水平幸福感的路径组态,具体结果如表4所示。

表4 条件组态充分性分析汇总
各条件变量构成的组态对高幸福感解释的组间、组内调整距离均小于0.2 的同时,总体一致性、PRI分别达到了0.919、0.776,且各组态一致性、PRI值均大于0.9、0.7,表明上述组态能够对结果变量产生较好的解释。整体来看,“身份确权”贯穿高幸福感提升路径,在每个组态中均作为核心变量对结果变量产生影响。值得注意的是,“人口结构”在高幸福路径中出现了大面积缺失,却在导致低幸福感的路径组态中表现活跃。这种情况有悖于日常认知,需要对其进行深层次的探讨。
组态1 在良好“人口结构”明确确实状态下,以“基础建设”“文教娱乐”“社会保障”和“身份确权”作为核心条件变量,实现了高水平的幸福。作为在类型组态中核心条件最多的组态,组态1 分别在PRI、覆盖度及唯一覆盖度3 项指标上表现优异,远超同类型中的其他组态,说明组态1 拥有较广的案例覆盖范围,且对其覆盖案例拥有较为稳定、良好的解释。但是,在同类型组态中该组态的一致性最低,可能是该组态的实现难度较大,然而组态1 涵盖地区的农民很可能拥有较高水平的幸福感。
组态2、3 都是在多个条件变量明确缺席的情况下,选择不同的条件组态实现了对当地农民幸福感的提升。进一步分析发现,两条组态在“文教娱乐”“社会保障”是否应该作为提升幸福感的影响因素方面产生了较大分歧。在高水平幸福感的路径中,组态3 一致性达到了同类型组态最高,但其余关键指标均为同类型组态的最低值,说明组态3 实现难度较小,但质量较低。组态2 在一致性、PRI、覆盖度方面总体表现均优于组态3,表明农村地区幸福感提升路径对于精神文明等类型的公共服务供给有着更为迫切的需求。
整体上,导致低水平幸福感的路径中条件变量表现越单一,其对应组态的唯一覆盖度就越低,组态本身越不具备成为典型案例的潜质。比较有代表性的有组态4、5、7 条件变量缺失情况较为严重,其一致性、唯一覆盖度均处于较低水平,证明这3 个组态所覆盖案例较少,且不具备较明显的典型特征。此外,这3 个组态在对案例的覆盖度方面显现出较高的水平,表明其可以对多数的低水平幸福案例进行合理的解释。
相比组态4、5、7,组态6 的条件变量缺失最少,其唯一覆盖度达到了同类型路径中最高,表明高水平的“基础建设”“经济质量”“社会保障”和“人口结构”条件变量同时存在也不一定会为农民带来高水平的幸福感。实际上,单纯从组态特征来看,组态6 具有成为高幸福水平类型的路径的潜力,结合组态1、2、3 的条件变量缺失情况,发现有可能是“身份确权”条件变量缺失导致组态6成为低水平幸福感类型的组态。
2.4 农民幸福感知路径稳健性检验
虽然各组态的组件调整距离均小于0.2,组态并未出现明显的时间效应,但是无法明晰各组态在时间纵轴上的表现。为进一步考察单个组态的时间效应,检验其稳健性的优劣,将每个条件组态的一致性按照时间顺序进行可视化,具体结果如图1所示。
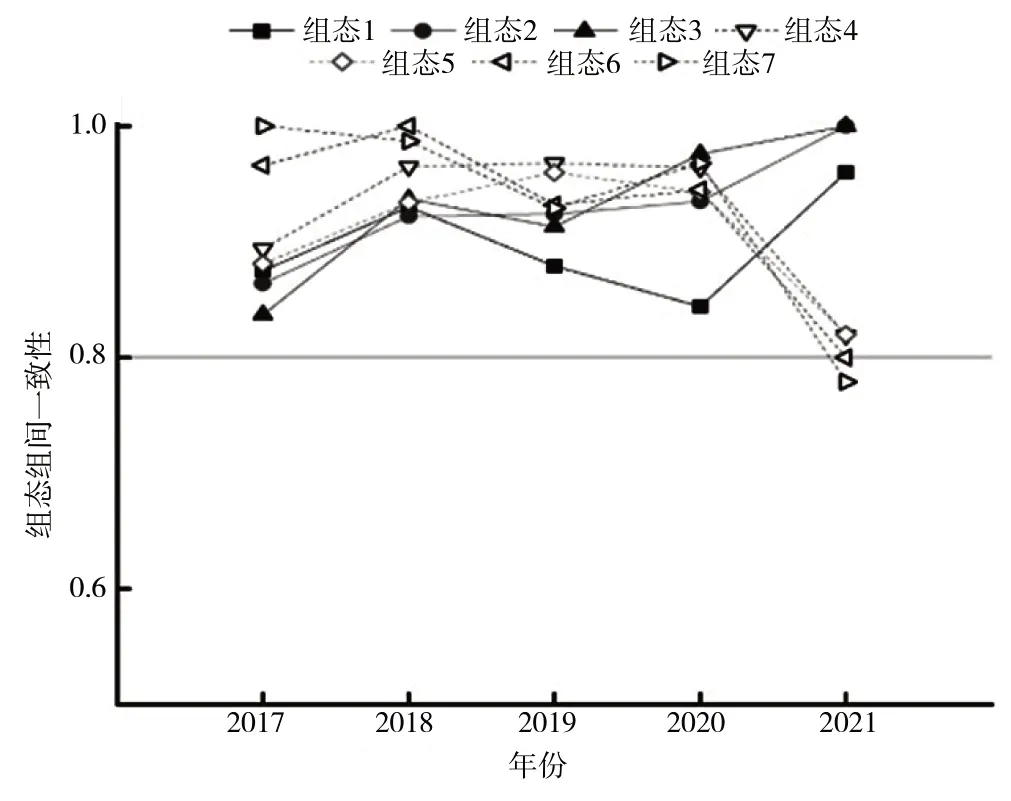
图1 条件组态组间一致性汇总
2017—2020 年的所有组态均达到该研究要求的一致性阈值,其中高水平幸福感类型路径整体一致性表现略逊于低水平幸福感类型路径。但这一形式在2021 年得到了扭转,导致低幸福感类型路径的一致性出现了断崖式下跌,该类型的所有组态一致性迅速降低到0.8 附近。结合2019 年年末出现的新型冠状病毒感染情况,一个可能的解释是常态化下农村地区公共服务供给对幸福感提升的稳定性略逊于致使低水平幸福感类型组态,但在紧急情况下由于政府工作扁平化水平、统一性等得到大幅提升,农村公共服务供给水平迅速提升,继而使得农民幸福感得到了大幅提升。而由于公共服务供给过程中不确定因素减少,低水平幸福的路径一致性出现下滑也在情理之中。
2.5 农民幸福感知路径异质性检验
同理,各组态组内调整距离小于0.2并不能解释在单个条件必要性检验时组内所产生的波动现象。通过组态组内一致性的检验能够从更加具体的角度来探讨组态与该现象之间的联系,找到影响组态组内解释力度的真正原因。为了能够从整体上把握组态组内一致性的特征,笔者对上述所有组态所覆盖的全部案例一致性进行散点图绘制,并认为组内一致性低于0.8水平的组态对其所涵盖地区不具备良好的解释,具体分析结果如图2所示。

图2 条件组态组内一致性汇总
由图2 可知,没有一条高水平幸福类型路径能对江西、福建两省的农村地区产生令人信服的解释。笔者通过Kmeans聚类寻找相似案例,并在此基础上找寻导致同因异果现象的真正原因。笔者对各案例进行多次聚类分析,以便对其进行比较分析。最终聚类结果显示,江西省、河南省具有较高的相似度,但是高水平幸福感类型路径却能够对后者产生良好的解释。与此同时,江苏、浙江和福建3 省的农村地区在公共服务供给方面具备较高的相似度,但是两种类型的组态都能够对江苏、浙江两省农民幸福感产生良好的解释。通过对以上案例所有指标的逐一比对发现,相比其他省份地区,江西、福建两省农民身份确权出现了明显下滑趋势,再次印证了身份确权在农民幸福感提升方面具有关键作用。
3 结论与启示
笔者采用动态QCA 方法,对2017—2021 年我国23 个省(自治区)农村地区的面板数据进行了分析,探寻了3 条较为稳健且能够促进农民幸福感提升的路径组态,可为政府开展治理工作提供参考。该研究主要得出以下几点结论与启示。
第一,身份确权变量对农民高水平幸福感提供着基础性的保障作用。结合低水平幸福路径组态特征,可以发现身份确权变量基本上不具备可替换的属性。因此,各地应通过制度规约等方式健全村委选举流程,以确保农民正常政治诉求的表达。
第二,除身份确权外,单个条件变量不会对公共服务满意度产生较为明显的影响,说明公共服务供给与农民幸福感之间的作用大都通过组态路径实现。
第三,我国农村地区的良好人口结构出现了大面积缺失,在城乡二元结构带来的影响下,拥有良好人口结构的农村地区却很有可能步入低水平的幸福生活中。该现象一方面说明农村幸福感提升中的表象指标并不能够为政府治理提供正确的方向,另一方面则喻示着当下我国农村青年群体普遍缺乏对村集体的认同。对此,各地在着重产业振兴、经济建设的同时应加强当地农村文化建设,通过修建青年文化站、交流中心等,提升农村青年群体在村集体中的话语权。
猜你喜欢
公民与法治(2022年5期)2022-07-29
好日子(2022年3期)2022-06-01
教学考试(高考物理)(2021年5期)2021-11-08
中医眼耳鼻喉杂志(2021年1期)2021-07-22
河北农机(2020年10期)2020-12-14
英语文摘(2020年11期)2020-02-06
中国生殖健康(2019年7期)2019-01-06
凿岩机械气动工具(2017年2期)2017-07-19
工业设计(2016年11期)2016-04-16
燕山大学学报(2015年4期)2015-12-25
