
用于多表连接优化的深度强化学习嵌入表示
2023-02-21 12:54王江晴王雪言
计算机工程与设计 2023年2期
王江晴,王雪言,孙 翀+,帖 军,尹 帆
(1.中南民族大学 计算机科学学院,湖北 武汉 430074;2.中南民族大学 湖北省制造企业智能管理工程技术研究中心,湖北 武汉 430074;3.中南民族大学农业区块链与智能管理湖北省工程研究中心,湖北 武汉 430074)
0 引 言
多表连接优化是查询优化的重要研究问题之一[1],其任务是在各种可能的候选序列找到一种最佳的连接顺序,使得执行计划的代价最小[2]。不同的连接顺序会生成不同大小的中间结果[3],因此对应消耗的资源也不同(CPU和I/O的消耗)。传统方法使用动态规划算法和贪心策略来解决多表连接优化问题,这些方法不能从之前的经验中学习,会重复选择不好的执行计划,导致查询的效率低下。目前,数据库领域出现强化学习相关技术的应用[4-6],将多表连接优化建模为强化学习问题[7],使用数据库中的参与查询的关系表示状态,关系之间的连接视为动作,最终的执行耗时作为奖励,模型的总目标是生成一个低延迟的执行计划。而查询语句的嵌入表示方法是影响使用强化学习生成连接顺序结果的关键,因此找到一种能捕获更多关于连接信息的嵌入表示方法至关重要。
针对上述问题,本文提出一种嵌入表示方法Smart-Encoder,能捕获到查询语句的选择谓词和连接谓词信息、连接树的左右关系及树的高度信息,并使用基于策略的强化学习算法[8]来解决多表连接优化的问题,将模型集成到PostgreSQL查询优化器中并同时从代价和延迟中学习,称本文的模型为SmartJOIN。在数据集(join order benchmark,JOB)上的实验结果表明,本文提出的嵌入表示方法SmartEncoder进行连接优化不仅可以减少生成执行计划的时间,还可以提高生成的查询计划的质量,从而提高数据库系统的查询性能。
1 相关工作
多表连接优化作为查询优化中一个非常重要的问题,随着关系数量的线性增长,要枚举的连接序列会呈现出指数级增长[9],多表连接优化是NP-Hard的问题。现实应用中通常利用启发式方法来解决,当代价模型是线性的,关系的连接和连接产生的代价成线性关系,这种方式是可接受的,然而实际情况中连接的代价具有非线性特征[10]。例如,连接的中间结果超过可用内存可能会触发分区。在这种情况下,启发式的方法可能会呈现出次优的效果,就难以起到良好的作用。采用基于学习的方法而不是启发式方法来进行连接顺序选择优化,可以从过去的经验中学习,充分利用之前的连接策略进行多表连接优化[11]。
近年来,基于学习的多表连接优化方法被提出,利用深度强化学习的技术来解决连接优化的问题。Ryan等[12]提出基于策略的深度强化学习算法的连接优化器ReJoin,将连接优化问题抽象成强化学习问题,ReJoin将选择信息和连接信息向量化,将连接树的高度信息向量化为每个表所处连接树的深度的平方分之一来表示,输入当前状态的向量化信息,输出对应状态的连接动作的概率分布,然后选择相应的连接动作,但是这种向量化方法无法区分连接的左右关系,导致不同的连接顺序在编码后产生相同的向量。Krishnan等提出基于Deep Q-Learning算法[13]的优化器DQ,将多表连接优化问题建模为马尔可夫决策过程,每个状态都是一个查询图,两个关系之间的连接视为动作,对已经连接到一起的关系和待连接的关系进行编码,并将多表连接的物理操作符用独热向量表示。用两层深度神经网络近似Q函数,输入连接的状态,输出连接动作的Q值,选择Q值最小的连接动作,但是DQ使用简单的独热向量进行连接的状态表示,导致不能获得查询树的层次结构信息,且不同的连接顺序的连接树编码后产生同样的向量化信息。
对查询语句编码得到的不同嵌入表示方法会影响基于学习的多表连接优化方法的准确性[14],针对上述连接优化方法中编码方式存在的问题,本文提出一种改进的关于查询语句的嵌入表示方法SmartEncoder,能包含更多关于连接的信息,对查询语句的连接条件和选择信息进行编码,并采用改进的连接树结构,能区分连接的左右关系并得到连接树的层次结构,使得编码和相应的连接顺序之间有一致的一对一匹配关系,从而实现编码可计算。本文提出的嵌入表示方法能够得到更多关于查询语句的信息,使用深度强化学习来优化多表连接顺序选择,提高了网络的学习能力,进而提高查询的性能。
2 SmartJoin模型
在基于深度强化学习的多表连接优化方法中,将当前的子树作为状态,动作是连接两个子树的操作,对查询语句的连接方案和选择条件以及连接树的信息进行编码,得到关于查询语句的嵌入表示信息,作为神经网络的输入,可以由深度强化学习算法学习,每次操作将两个关系进行连接,当所有的关系被连接完成时,代表一个回合结束,模型会在多个回合中进行学习。
2.1 模型流程

多表连接优化的目标是找到一个每个状态下采取动作所构成的序列,使得累计代价最小。当前状态向量化以后作为输入被送入状态层,通过若干个隐藏层进行转换,每层通过激活函数转换其输入数据,将输出结果送至后续层,数据最终被传递到动作层。动作层的每个神经元代表一个潜在的行动,它们的输出被归一化后形成一个概率分布,策略πθ(St,At) 通过从这个概率分布中取样来选择动作。基于深度强化学习的多表连接优化方法SmartJOIN的整体框架如图1所示。
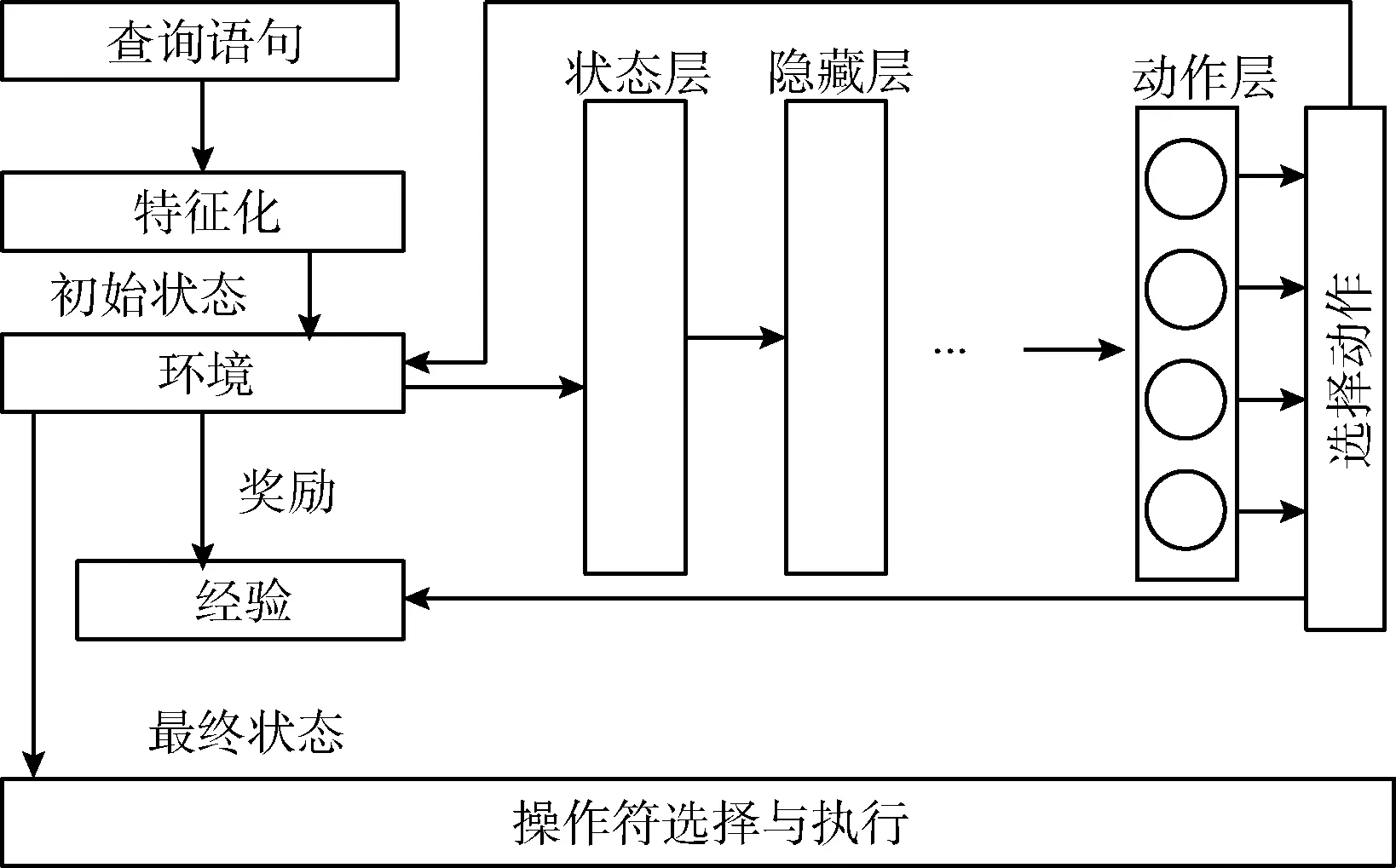
图1 SmartJOIN框架
本文使用基于策略梯度的强化学习方法——近端策略优化算法[8]来进行连接顺序决策,智能体根据一个参数化的策略πθ来选择最佳操作,其中θ代表一个代表策略参数,在近端策略优化算法中,用参数化神经网络表示策略πθ, 其中θ为网络的权重,策略依据环境的反馈来调整θ, 从而优化策略参数θ, 使得预期的奖励Rπ(θ) 最优。给定一个状态和一个动作的集合At, 策略πθ会为At中的每个动作输出一个概率(即连接两个表的概率),然后根据概率选择动作,最终的连接顺序结果发送到优化器进行后续操作和执行。
由于基数估计的不准确性会导致代价模型的估计不准确[15],但获取每条查询语句的执行延迟是十分困难的。因此,在本文的方法中首先使用代价模型的估计作为奖励来学习,这个阶段完成后,模型可以生成一个以代价为指标的连接计划。然后切换到基于真实延迟的数据中进行训练,对模型进行微调。从而实现从代价和延迟中进行学习。
2.2 嵌入表示方法SmartEncoder
将查询语句进行编码后得到嵌入表示信息,即对模型有用的向量,向量包含的特征应该足够丰富,可以获得更多关于查询的相关信息,这就需要得到此条查询语句所请求的内容,连接左侧的关系、连接右侧的关系和过滤条件以及关于连接树的信息。
查询编码:对查询信息进行编码,即对查询语句中关系和属性进行编码。与之前的工作类似[16],它包含了查询语句中连接操作和选择条件的信息两部分,一部分连接操作用邻接矩阵表示,矩阵中的“1”对应两个表之间存在连接关系,矩阵的大小为数据库中表的个数。如图2(a)(连接谓词)示例中,第一行第二列对应位置“1”表示A和B两表之间存在连接操作;第二行第四列对应的位置为“0”,表示B和D两表之间没有进行连接。由于这个矩阵是对称的,因此本文取上三角部分进行编码;另一部分选择操作用一维向量表示,用来标识查询语句中用于过滤元组的属性,向量的大小是数据库表中所有的属性个数。例如,在图2(b)(选择谓词)中,数据库中所有属性的集合为 (A.id,A.a1,A.a2,…,B.id,B.a1,B.a2,…), 其中属性B.a2作为查询语句的选择谓词,在对应向量的位置记为“1”。进一步扩展,对于查询中的每个选择条件,可以利用传统数据库管理系统中表的统计信息获得它的选择性。例如,如果选择条件B.a2<50被估计为有30%的概率,故将列谓词向量中其对应位置上的槽值改为0.3,用来表示查询语句中这个过滤条件得到的基数信息。

图2 查询编码
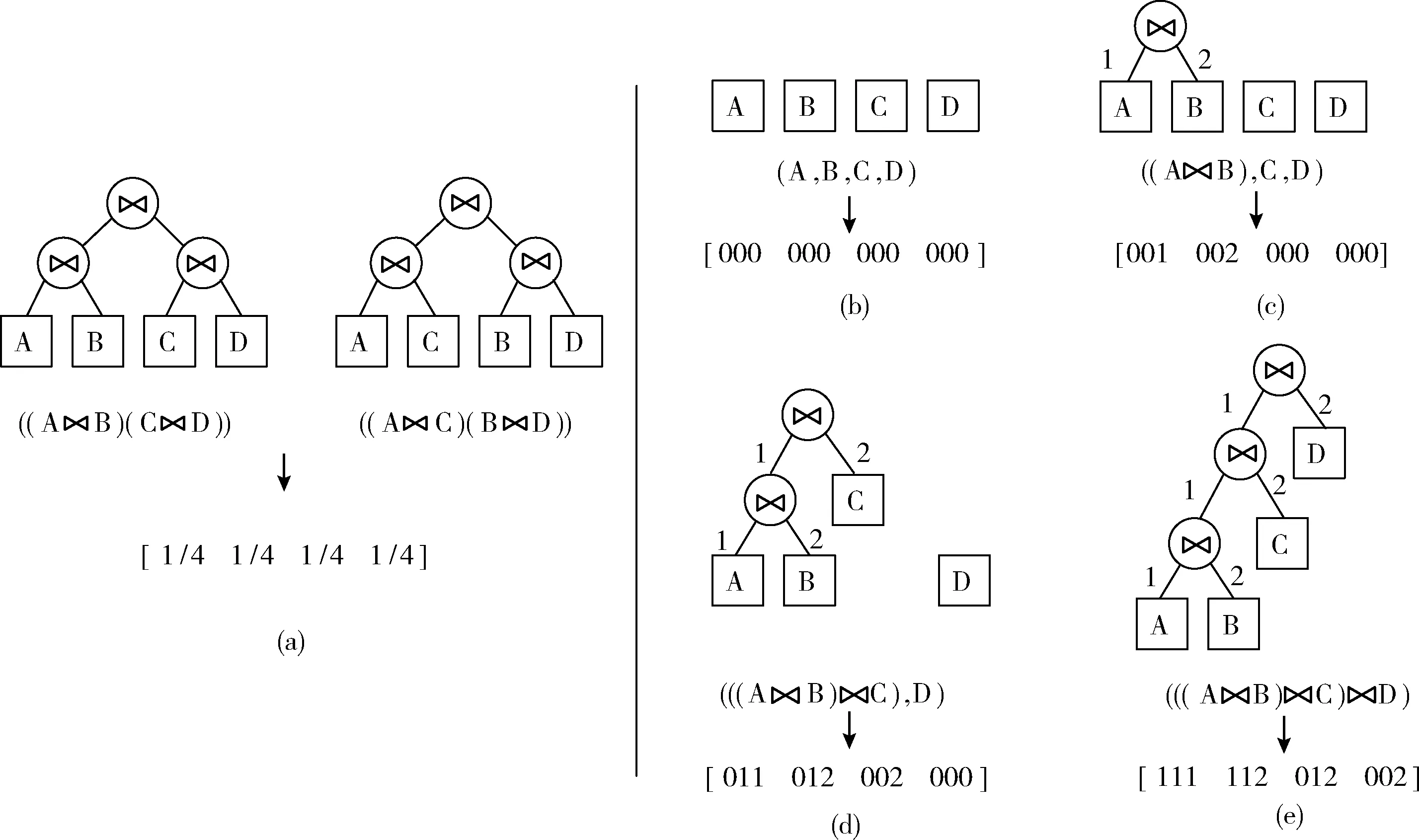
图3 计划编码
3 实验与分析
3.1 数据集与实验设置
实验数据集采用JOB,它从真实数据集IMDB派生出来,IMDB由21个表组成,有3.6 G大小,最大的表有3600万行,包含了关于电影、演员和导演等信息。在JOB中一共包含33个模板和113个查询,每个模板包含2到6个不同的变体,连接关系的数量从4到17个,每个查询平均有8个连接。在实验中对90个查询进行训练,训练集覆盖数据库的所有关系和连接条件,对23个查询进行测试,每个测试包含尽可能多的连接关系。
本实验在GPU服务器环境配备NVIDIA Tesla K80和Ubuntu 20上,使用Python3.6和深度学习开源框架Tensorflow实现。将PostgreSQL配置为执行SmartEncoder嵌入表示的多表连接顺序选择优化方案,且使用PostgreSQL作为查询执行引擎。为了得到在2.2节查询编码中的选择谓词返回的元组数量,在本文中使用根据PostgreSQL得到的基数估计量。本文中使用近端策略优化算法,并使用两个带有128个ReLUs单元的隐藏层。
3.2 实验结果及分析
为了评估本文嵌入表示方法SmartEncoder在多表连接优化中的有效性,本文对比PostgreSQL和ReJOIN的连接顺序生成执行计划的效率。表1~表3分别展示了关系数量为4、8、14的3a模板、7a模板、28c模板(包含自连接)中参与连接的最大表、最小表的大小以及参与连接表的平均的大小和元组数量。如图4~图6分别展示了在关系数量为4、8、14的查询模板中PostgreSQL和ReJOIN以及SmartEncoder生成执行计划对应的时间。如图4所示,执行模板3a的查询语句,在参与连接的关系数目较少时,连接产生的中间结果也较小,此时SmartEncoder还没有表现出明显的优势。如图5中所示执行7a模板中的查询语句,可以看出随着关系数量的增加,这时会导致连接得到的中间结果增大,SmartEncoder的优势逐渐显现,计划时间在一定程度上低于其它两种方法的计划时间。如图6中所示执行28c模板的查询时在关系数量的增多的同时SmartEncoder的计划时间相较于其它两种方法有了明显的改善。从上述对比中可以看出,随着关系数量的增加,尤其是参与连接关系数量较多时,使用SmartEncoder进行连接优化相对于其它两种连接顺序选择优化方法的有效性。

表1 3a模板信息

表2 7a模板信息

表3 28c模板信息

图4 3a模板执行时间
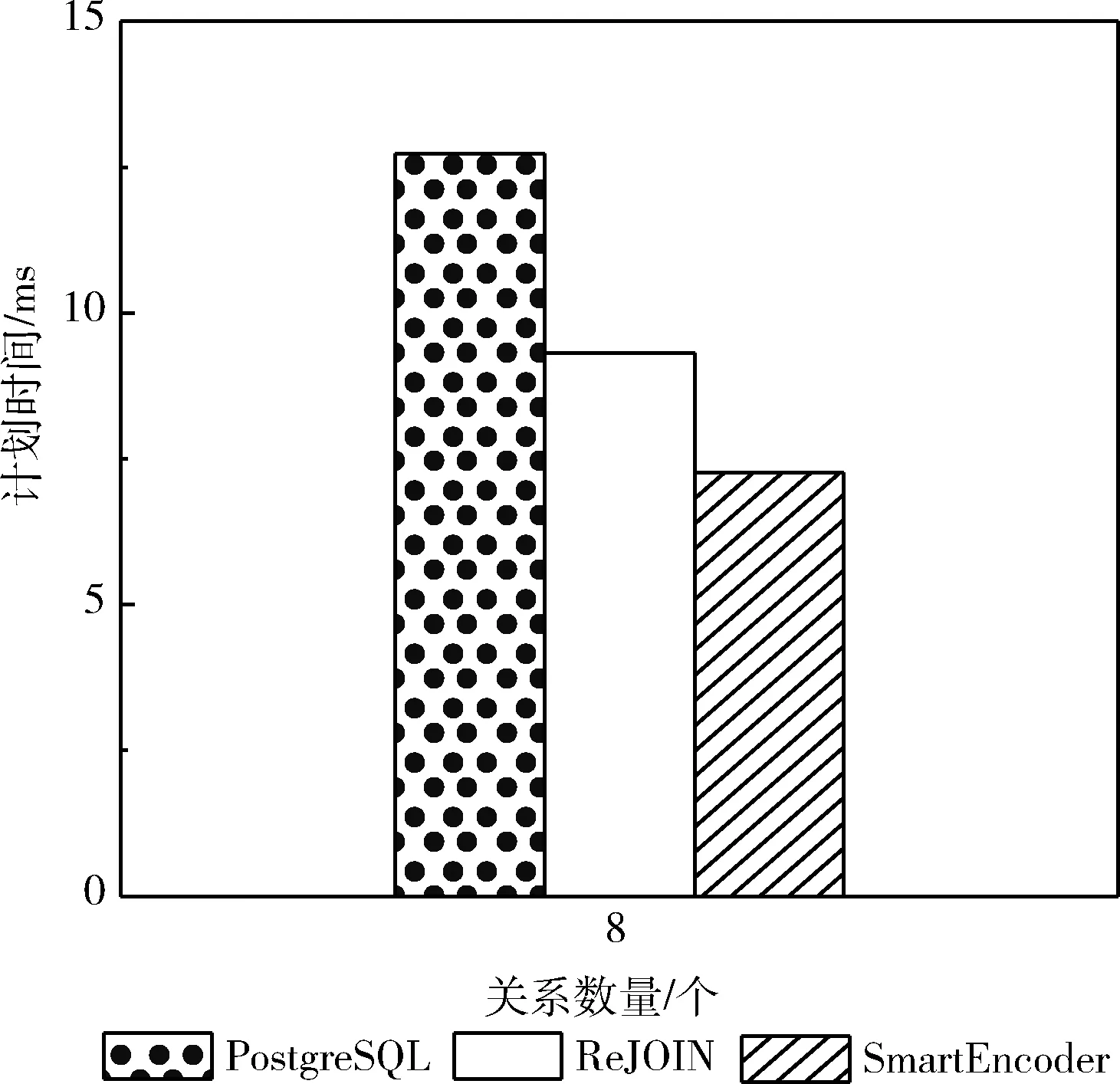
图5 7a模板执行时间
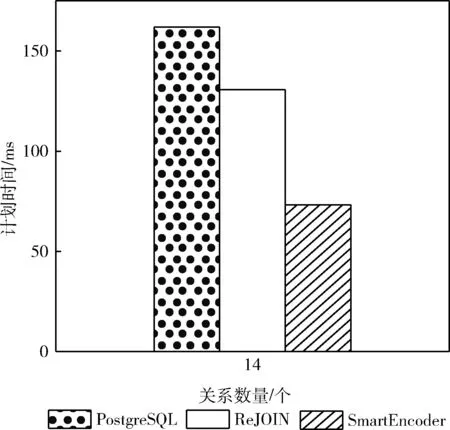
图6 28c模板执行时间
计划时间:SmartEncoder对比了PostgreSQL和ReJOIN制定执行计划的时间,根据要参与连接的关系数分组,如图7所示,随着查询中关系数量的增加,PostgreSQL制定执行计划的时间快速增长,ReJOIN和SmartEncoder都是基于学习的方法,计划时间并没有随着关系数量增加而呈指数级增长。在刚开始SmartEncoder没有表现出明显的优势,但同样随着关系数量的增加,SmartEnco-der制定执行计划的时间逐渐有了改善。例如,在关系数量为9时,SmartEncoder的执行时间较PostgreSQL相比降低了29%,比ReJOIN降低了23%。在关系数量为12时,SmartEncoder较PostgreSQL的执行时间相比降低了22%,较ReJOIN降低了12%。
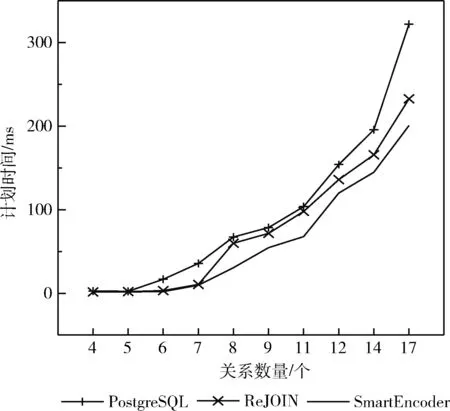
图7 计划时间
执行时间:如图8的示例中对比了不同关系数量下PostgreSQL、ReJOIN和SmartEncoder的执行时间,可以看出,SmartEncoder的执行时间明显低于PostgreSQL,较ReJOIN相比也有显著的优势。例如,在关系数量为9时,SmartEncoder的执行查询语句所需要的时间较PostgreSQL相比降低了35%,较ReJOIN相比降低了20%。这得益于在本文中采用了能够区别关于连接左右关系以及连接树的层次结构的嵌入表示信息,且不会限制查询树的形态,能够捕获到更多关于查询语句中关系的连接信息,也使得连接过程中有合适的中间结果,进而提高了查询的性能。
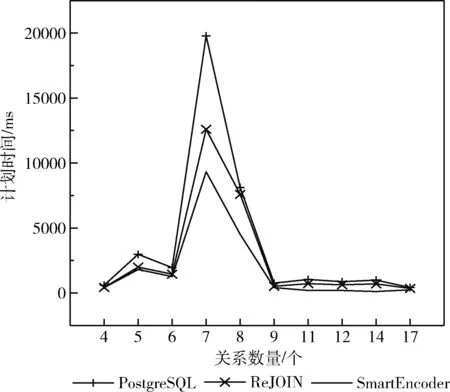
图8 执行时间
4 结束语
针对现有多表连接优化问题中查询语句的嵌入表示方法对连接关系信息的关注程序不同,提出改进的嵌入表示方法SmartEncoder,能得到查询语句的选择谓词和连接谓词信息、能够区分连接的左右关系和连接的高度信息,从而使得查询编码与查询树有一致的匹配,实现编码可计算,能包含更多关于查询语句的信息并将深度强化学习应用于多表连接优化问题。在模型训练过程中,使用代价模型产生的代价进行训练,再使用执行查询语句的真实延迟调整。在PostgreSQL上的实验结果表明了SmartEncoder在多表连接顺序选择优化方法的有效性。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
——论胡好对逻辑谓词的误读
现代哲学(2020年5期)2020-11-30
新世纪智能(语文备考)(2020年4期)2020-07-25
西夏研究(2020年2期)2020-06-01
高中生学习·高三版(2016年9期)2016-05-14
外语学刊(2016年4期)2016-01-23
新高考·高二数学(2015年11期)2015-12-23
语文知识(2014年4期)2014-02-28
小雪花·初中高分作文(2009年8期)2009-11-16
