
融合BiGRU和记忆网络的会话推荐算法
2023-02-21 13:16曾亚竹孙静宇何倩倩
计算机工程与设计 2023年2期
曾亚竹,孙静宇,何倩倩
(太原理工大学 软件学院,山西 晋中 030600)
0 引 言
Massimo等[1]提出一种分层循环神经网络(recurrent neural network,RNN)向用户提供推荐。Hidasi等[2]通过改进排名损失函数提升了RNN的性能。Liu等[3]考虑用户的整体偏好和当前目的,在会话推荐中取得了较好的推荐效果。Wu等[4]将图神经网络应用于会话推荐。Li等[5]使用了一种注意力机制来获取用户的主要会话目的。Sun等[6]采用深层的双向自注意力对用户行为会话进行建模。Li等[7]提出一种BiLSTM(bidirectional long short-term memory)结构,处理当前会话和历史会话的交互,但这样可能会引入噪声。由于基于RNN推荐算法存在短期记忆问题,Chen等[8]首先引入用户记忆网络来利用用户的历史记录以提高性能,并显式地捕获项和特征级序列模式,从而改进了序列推荐。Wang等[9]在Li等的基础上加入了邻域信息辅助建模用户会话意图,并证明邻域会话有助于改善当前会话推荐算法,但未充分获取短期会话反映的用户兴趣。Wu等[10]构建了一个个性化图神经网络,但忽略了历史会话中的交互。
为解决以上问题,本文综合考虑历史会话的交互和邻域会话的信息并构建模型。融合缩放点积自注意力和BiGRU(bidirectional gated recurrent unit)提取用户行为特征。使用图卷积网络获取邻域信息以改进记忆网络并判断用户当前会话的辅助信息。最后对两个编码器的会话表示进行特征融合,获得用户的当前偏好并预测下一个交互。
1 相关技术
1.1 门限循环单元
门限循环单元(gated recurrent unit,GRU)是一种特殊的RNN,它优化了传统的RNN,使得网络更加简单,模型参数更少。它包含两个门,更新门的表达式ht如式(1)
(1)
其中,更新门zt是由式(2)确定
zt=σ(Wzxt+Uzht-1)
(2)
(3)
重置门中rt的计算如式(4)
rt=σ(Wrxt+Urht-1)
(4)
Wr、Ur是权重矩阵,⊙表示点乘,σ表示使用Sigmoid激活。
1.2 缩放点积自注意力
自注意机制通过强调某些特定行为,忽略其它行为来关注当前会话的意图。对相对更重要的项目赋予更高的权重。自注意机制能通过建模项目间更细粒度的关系学习到更加准确的用户行为模式。通过计算每个点击的权重减少高维数据的计算复杂度,使模型更快学习当前会话意图,并利用注意权重找出每个点击对会话意图的重要程度。输入由query、key和value组成,并且三者相等。缩放点积自注意力函数是自注意力函数的一种,其结构如图1所示。

图1 缩放点积自注意力模型
query和key经过矩阵乘积之后进行缩放,mask操作保证当前预测结果仅取决于之前的输出,将softmax归一化后的结果和value相乘获得加权输出。
2 融合BiGRU和记忆网络的会话推荐
提出一种融合BiGRU和记忆网络的会话推荐模型(SRGM)来生成基于会话的推荐。SRGM模型利用当前会话和邻域会话的信息来预测用户的下一个交互。如图2所示,SRGM由3个部分组成:会话网络编码器(session network encoder,SNE)、记忆网络编码器(memory network encoder,MNE)和推荐解码器。

图2 SRGM模型
将用户为序列S划分为会话I,其中Xt=[x1,x2,…xt,…,xn] 表示用户和项目交互中的时间戳t(t≥1) 处的会话,n表示在会话中交互项目的个数,其中每个xt是与用户交互的项目。基于会话的推荐系统的目标是预测用户的下一个交互。用户在不同的时间段内有明确独特的意图,将超过一定时间的用户行为分割为两个会话[5]。给定当前会话,目标是通过从用户交互的所有会话I中top-N个项目 (1≤N≤|I|) 来预测第xn+1个项目。
会话Xt进入输入层后分别经过全局编码器和局部编码器。BiGRU改进SNE中的全局编码器以更好地建模历史会话兴趣,使用另一个融合缩放点积自注意力的BiGRU改进局部编码器以消除会话中的噪声,提取用户的特定行为特征。
全局和局部编码器共同构造用户会话表示。使用图卷积网络改进MNE获得用户的邻域信息以加强对用户当前会话辅助信息的推断,并用改进的融合选通门结合SNE获得的用户短期意图和MNE获得的用户邻域长期兴趣以考虑用户的动态兴趣,最终获得用户的最终兴趣的向量表示并对用户进行推荐。
2.1 会话网络编码器
SNE对当前会话进行编码,它包括两个模块:全局编码器和局部编码器。前者用于总结并建模整个会话中用户的顺序行为并获取会话的总体特征。后者关注用户特定的行为,用于在会话包含意外单击或出于好奇而单击的项目时选择当前会话中相对重要的项目以捕捉用户的主要意图。本文使用BiGRU改进全局编码器,相比于LSTM(long short-term memory),BiGRU复杂度更低,而相较于GRU,更利于捕捉历史会话之间的顺序关系。
BiGRU包含前向和后向GRU,用隐藏状态表示hn当前会话的顺序行为,隐藏状态hn的计算如下
(5)
(6)
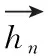
尽管全局编码器考虑了整个会话过程反映的兴趣,但受限于GRU本身的特性,仍会给模型引入噪声。为消除噪声项的干扰,准确捕捉当前会话的行为模式,使用一个融合项目级自注意力机制[11]的BiGRU改进局部编码器,如图3所示。
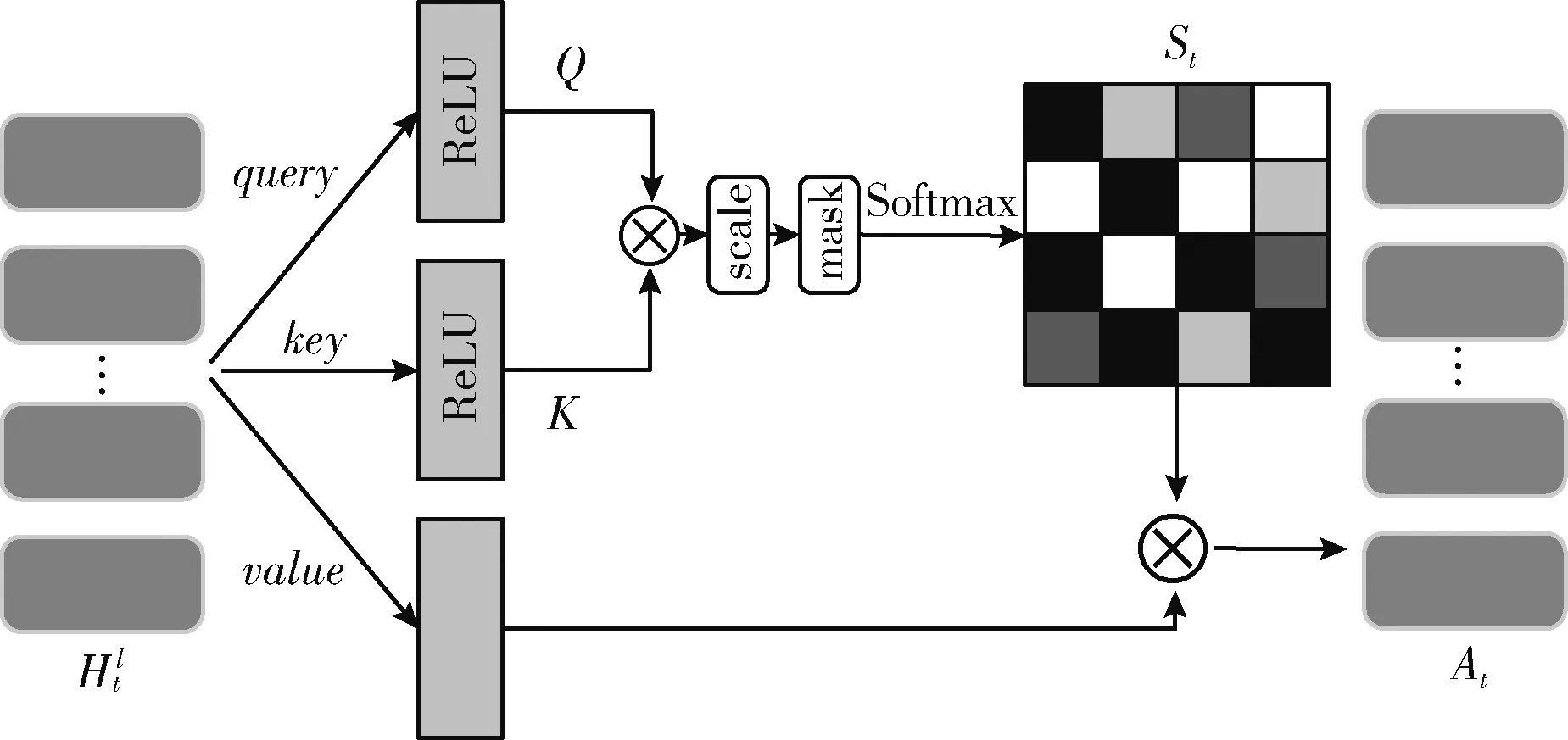
图3 项目级自注意力层结构
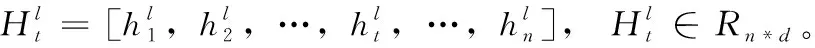
(7)
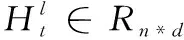
将Q和K相乘,再使用scale缩放以防止梯度过小,使用mask操作隐藏对角线元素避免Q和K中相同物品之间的高匹配分数。最后使用softmax做归一化处理,得到权重矩阵,并和局部编码器的存储器矩阵相乘,使用缩放点积计算最后的加权输出At
(8)
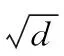
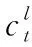
(9)
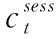
(10)
2.2 记忆网络编码器
SNE仅利用用户自身会话之中包含的行为信息,忽略了邻域会话中相似行为信息对推荐的重要性,并且对于长度较短的会话,SNE由于缺乏足够的历史信息而导致不能够准确捕捉用户行为模式。为解决这个问题,提出了记忆网络编码器MNE。MNE模块使用记忆网络矩阵M,存储最近一段时间内的m个用户会话并抽取当前会话的邻域会话,作为与当前会话有着相似兴趣模式的会话。这是一个基于会话的最近邻方法,对具有与当前会话相似的行为模式的会话赋予更高的权重。这些邻域会话可以加强对当前会话的辅助信息的推断。
(11)
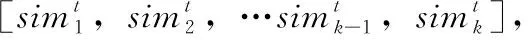
(12)
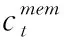
(13)
每轮实验开始时,记忆网络矩阵均设置为空。使用先进先出法更新记忆网络矩阵。当新会话被存入记忆网络矩阵时,起始会话被从记忆网络矩阵中删除,新会话被加进队列。记忆矩阵不为空时,会话会被直接写入矩阵,不删除矩阵中现有的早期会话。
2.3 推荐解码器
推荐解码器结合SNE和MNE的会话表示并进行特征融合,预测项目接下来被点击的概率。如图2所示,模型使用选通门机制结合SNE和MNE的信息并建模用户最终的会话表示,可以兼顾序列会话包含的信息和邻域会话间的权重。由于之前的模型大多未考虑到不同项目特性的部分,没有重视项目内部的丰富的特征信息,可能会使模型对用户兴趣失去精准的判断。根据Ma等[13]的研究,提出了一种改进的融合项目内部特征的选通门以选择项目特征并且建模用户的兴趣。融合选通门ft由下面的公式给出

(14)
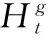
(15)
参考文献[5],为节省内存空间,不使用标准RNN中的全连接层对隐藏层状态解码,而使用双线性插值替代全连接层来计算推荐列表,减少模型参数的同时提升了预测的准确度。embi是待预测项目的特征表示,根据用户会话意图的最终表示ct计算待预测项目被推荐的概率值
(16)
其中,B∈Rd×D,d是每个嵌入项的维数,D是用户会话意图的最终表示ct的维数。
2.4 目标函数
模型的目的是使用当下的用户会话,尽可能预测下一个被点击的项目。所以采用交叉熵损失函数,计算为预测的项目得分和实际场景中用户的点击的项目的独热编码之间的交叉熵
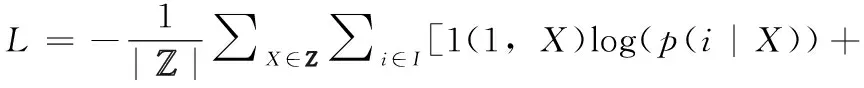
(17)
3 实验设置
3.1 数据集
使用YOOCHOOSE和LastFM两个公开的数据集并对其做以下预处理。将数据集里的所有会话序列按时间顺序重新排序,将只在测试集中出现的项目过滤掉并对项目进行数据增强。表1中展示了两个数据集的统计信息。
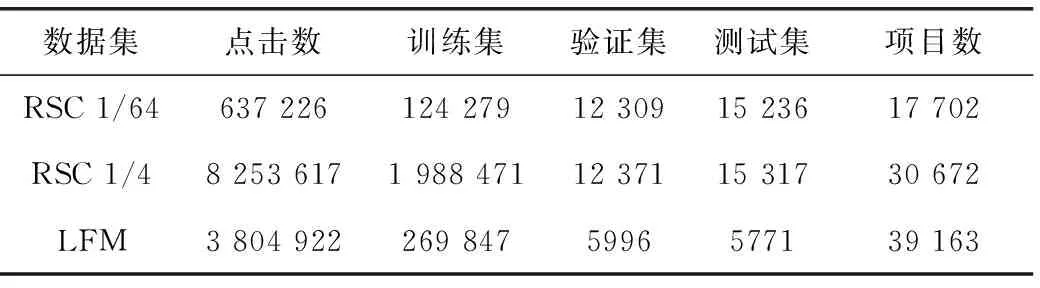
表1 实验数据集信息统计
YOOCHOOSE数据集是2015年RecSys竞赛的公开数据集,内容为电子商务网站的用户点击。将最后一天的点击流作为测试集,其它的数据则作为训练集。文献[14]证明了仅使用当前一段时间的会话就可以达成较好的推荐性能,故按照文献[14]的方法,移除长度为1的会话和交互少于5次的物品。使用最近一段时间的1/64和1/4的会话切片作为训练集并称之为RSC 1/64(RecSys 1/64)和RSC 1/4 (RecSys 1/4)。
LFM(LastFM数据集)是用户听音乐序列的数据集,包含从2004年到2009年之间近1000名听众的音乐播放记录、时间、歌手和歌曲。为简化数据,将LFM用于歌手推荐。在实验中选择前40 000个最受欢迎的歌手作为数据集。将发生在8小时内的音乐点击流数据划分为一个会话,删除长度为1和长度大于50的会话。
3.2 基线算法
为验证SRGM模型效果,将模型和6种基于会话推荐的基线算法进行比较,分别是两种传统推荐算法、两种基于RNN的推荐算法和两种基于内存网络的推荐算法。
用于比较的传统推荐算法如下:
S-POP:推荐当前会话中最流行的物品。推荐的物品会跟随会话长度的增加而更改。
ItemKNN:基于社交的相似度计算法,物品的相似度定义为会话中两个物品的共同出现的次数除以其中一个项目出现的会话次数乘积的平方根。使用正则化避免很少被点击的项目之间巧合的高度相似性。
用于比较的基于RNN的推荐算法如下:
GRU4Rec:Hidasi等提出的模型。它使用会话并行以及小批量的方法训练模型,并且还使用基于排序的损失函数。
NARM[5]:引入了一种注意力模型和编码器结构结合历史行为以优化GRU4Rec的深度学习算法。
用于比较的基于内存网络的推荐算法:
RUM-I:RUM[8]的两个具体实现中的其中一个。将项目嵌入存储在内存矩阵中,应用于基于会话的推荐任务,通过基于RNN的算法表示一个新会话,另一个具体实现由于难以提取新会话对特定项目的偏好而不能应用于基于会话的推荐,故不在此处赘述。
CSRM[9]:一种基于会话的协同推荐机,在NARM算法上进行改进,增加基于邻域信息的记忆网络模块以更好预测当前会话的意图。
3.3 实验过程
编程语言为Python,使用TensorFlow编写代码,显卡使用RTX2080 GPU加速训练。为降低过拟合,使用两个dropout层。分别位于会话物品嵌入层和BiGRU层之间及用户意图表示层和Bilinear层之间,dropout设置为25%和50%。在整个模型训练中,使用基于时间的反向传播算法(back-propagation through time,BPTT)对模型进行训练。模型训练使用高斯分布参数随机初始化,使用Adam优化器,并根据验证集对超参数进行调整,验证集是训练数据大小的一部分。超参数统计见表2。
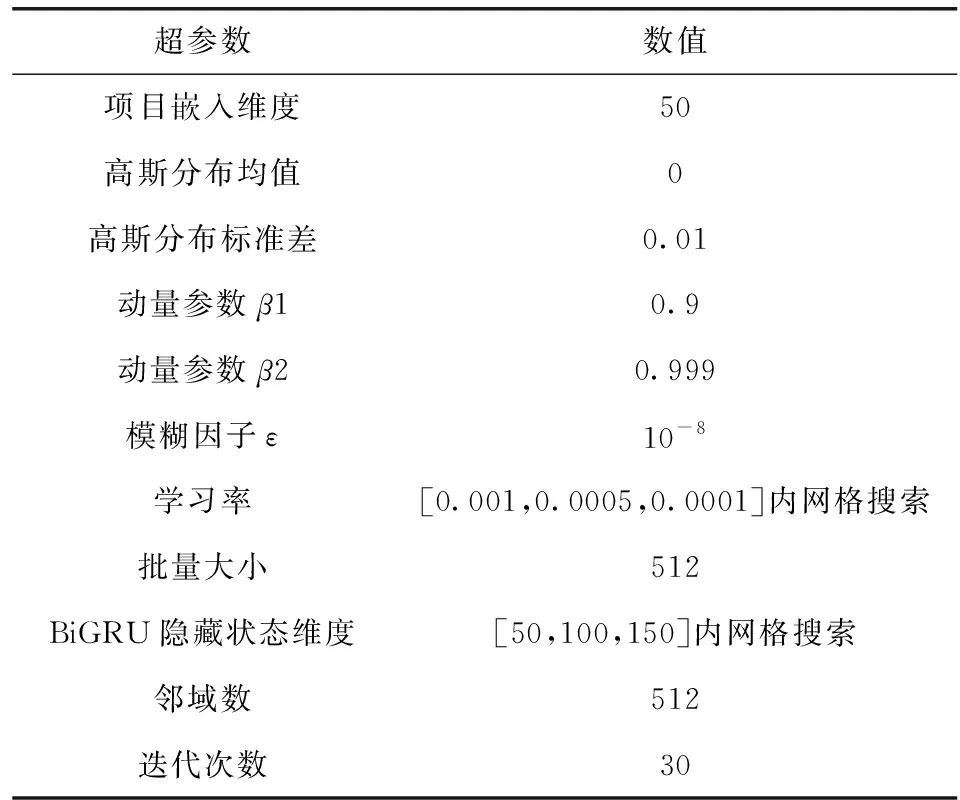
表2 超参数统计
3.4 评价指标
评价指标的目的是预测用户在当前会话的下一步将单击什么项目。推荐系统将生成一个候选列表,该列表通常包含N个项目,这N个项目将根据预测分数的高低进行排序。用户接下来点击的实际项目应该包含在推荐列表中。因此,使用以下指标来评估top-N的表现:
Recall@20(召回率):期望项目在前20个推荐列表中的比例。不考虑实际项目在推荐列表中的排名。
MRR@20(平均倒序排名):期望项目在推荐列表中排名的倒数平均值,排序大于20则置为0。MRR考虑到了实际推荐场景下项目列表中的真实排序情况。
3.5 性能比较
3.5.1 和基线算法的比较
比较了SRGM和6种基线算法的性能。表3中说明在实验使用的两种指标下,SRGM相较于基线算法在实验数据集上都实现了较好的提升。
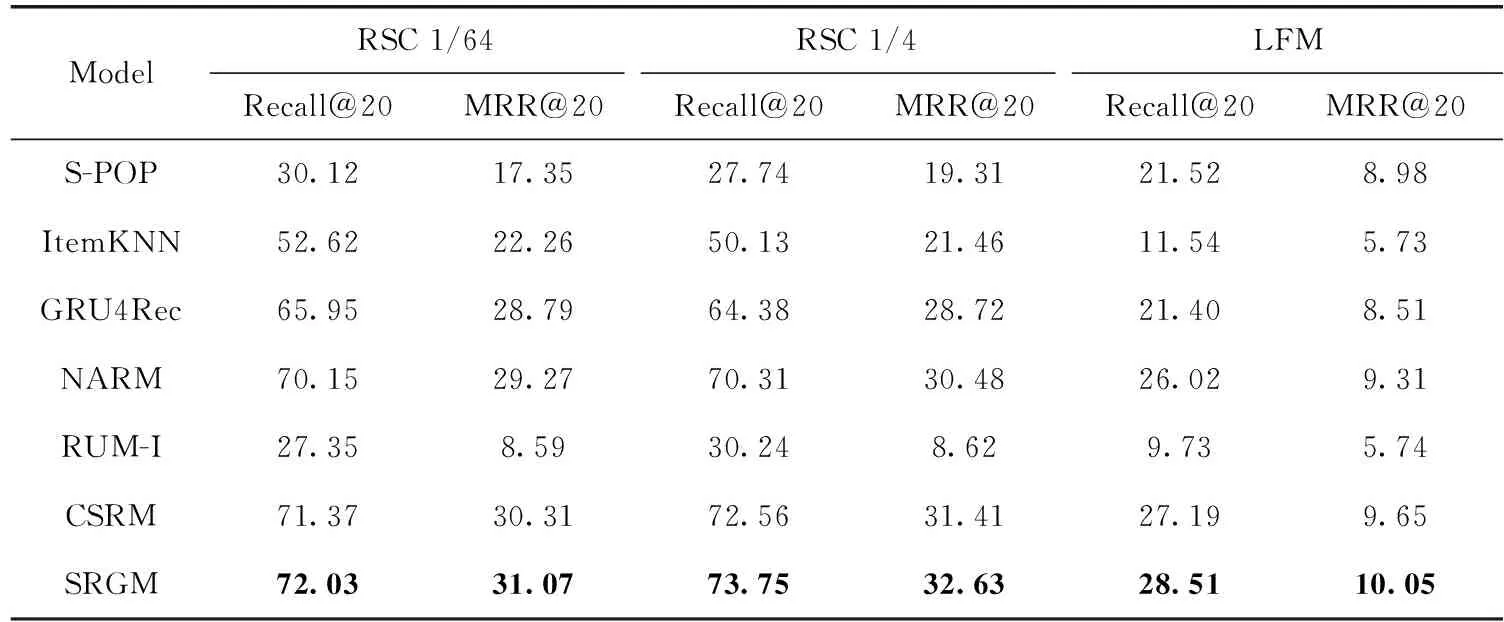
表3 SRGM与基线算法的性能比较/%
表3可看出,基于RNN的模型相对于传统的模型性能提升明显,这说明基于RNN的模型能够很好处理会话中的序列信息并且解决基于会话的推荐问题。NARM相对于GRU4rec推荐性能的明显提升也说明注意力机制的加入对于会话推荐性能会产生积极影响。而SRGM明显优于两种基于RNN的基线算法。对于基于内存网络的基线算法,实验结果发现SRGM明显优于RUM,这可能是基于会话的推荐中由于用户是匿名的原因,并没有可供使用的用户信息。
相较于最优基线算法CSRM,SRGM在3个数据集(RSC 1/64,RSC 1/4和LFM)的Recall@20指标上的提升为0.92%、1.64%和4.85%,对于MRR@20指标上的提升为2.51%、3.88%和4.14%。算法在LFM数据集上的提升较RSC 1/64、RSC 1/4更高可能是由于LFM是音乐数据集,相比于电商数据集更容易捕获短期的会话意图,而电商数据集的短期会话意图不确定性更强。经过20轮训练之后,模型性能基本趋于稳定。
3.5.2 不同会话长度的比较
不同会话的会话长度,即一段时间内用户和项目的交互数量也不尽相同。而在会话中,当前会话最近的几个点击项目对用户的兴趣偏好有重要的影响,故本文希望比较不同会话长度的性能以分析本文的两个编码器对模型性能的影响。如图4所示。
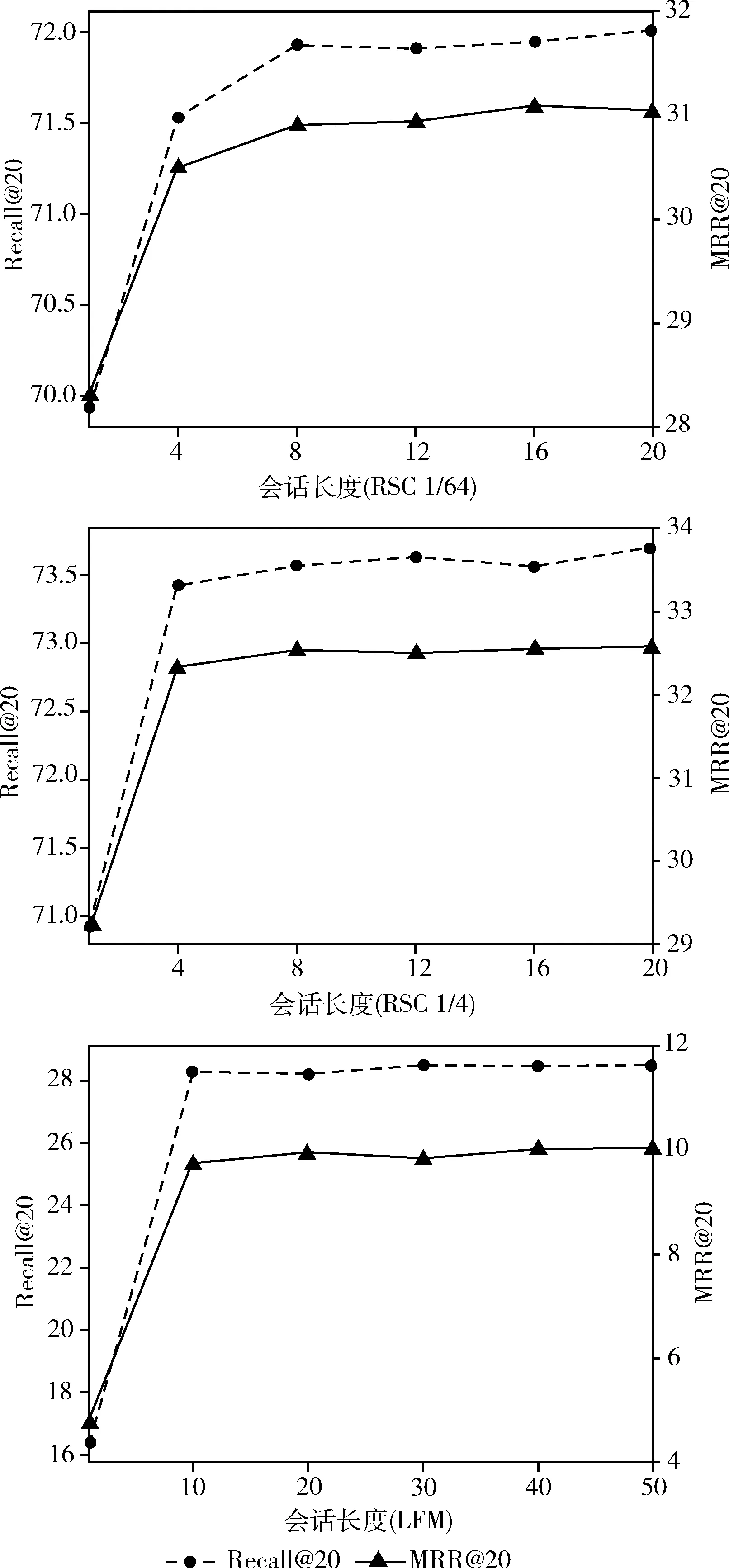
图4 不同会话长度性能对比
随着会话长度的增加,评价指标逐步增长并逐步趋于稳定,这说明大部分会话长度很短,增加会话长度对模型精度影响不大,增加的会话可能多为用户多次点击的项目。基于图4可以得出下列结论:在会话长度较短时(如1-10),由于缺乏中长期点击流,不利于会话编码器对用户的偏好进行准确预测。此时用户的意图主要依赖于邻域会话进行辅助推断,在会话长度较长时(10-),历史项目信息在邻域会话的帮助下将更有利于模型捕捉用户的兴趣。因此,本文模型对长短会话均有较为准确的预测。
3.5.3 不同模型深度的比较
为评估不同深度的模型对于算法性能的提升,使用消融实验基于本模型的不同网络类型和深度与最佳基线CSRM进行比对。消融实验见表4。
模型1:SNE中使用BiGRU作为全局和局部编码器,融合MNE学习项目的特征。
模型2:SNE的局部编码器中融合缩放点积自注意力,融合MNE学习项目的特征。
模型3:解码器中使用改进的融合选通门进行项目特征的选择。
模型4:使用图卷积网络改进MNE,增强会话注意,获取用户邻域会话的兴趣。
模型5:融合以上4个模型,并建模用户兴趣。
表4模型1可以看出,BiGRU对算法性能可以产生积极影响,模型2可以看出加入了自注意力的神经网络可以获取用户更细粒度的行为,而消融实验的结果可以看出加入了缩放点击自注意力的模型。相比于其它模型提升更大,在Recall@20和MRR@20两个指标上相较于基线分别提升达2.17%、1.31%、2.94%和3.20%、3.41%,3.11%。这说明用户当前会话的兴趣对于用户的下一次点击影响更大,这说明短期兴趣对用户整体会话意图的建模更加具有帮助性。模型3在MRR@20上提升明显,同时也反映了改进的融合选通门能够放大项目特征用以帮助模型提取用户兴趣。模型4说明使用图卷积网络可以增强邻域信息对当前会话兴趣的推断以帮助模型找到与当前会话最相似的项目,但提升效果相较于其它模型较小。模型5说明本文模型的综合改进对处理会话推荐的有效性。
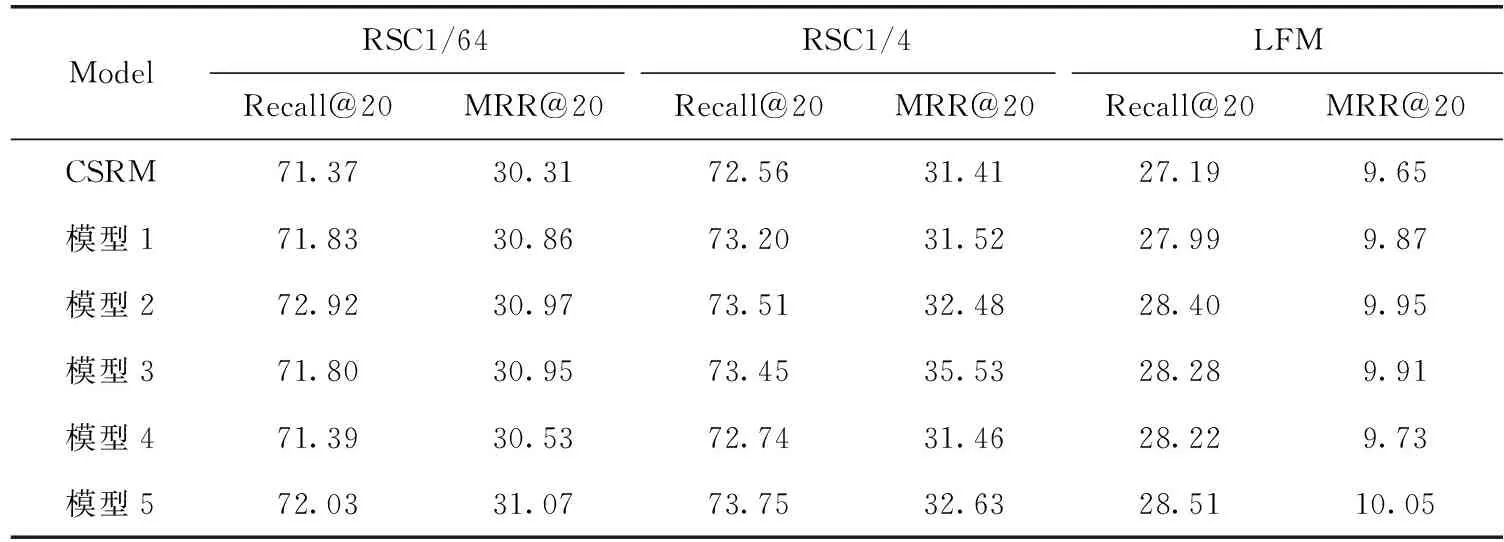
表4 SRGM消融实验性能比较/%
3.5.4 不同邻域的比较
为探究邻域信息对于算法捕获用户会话意图的贡献,根据经验分别取k为128、256、512和1024,比较了不同邻居数对于SRGM的影响。根据表5发现,对于RSC 1/64和RSC 1/4数据集,随着k的提高,算法在Recall@20的性能逐渐增加并在k=512附近时达到最佳,在MRR@20的性能在k=256附近时基本达到最佳。对于LFM数据集,Recall@20的性能在k=512和256时较为接近,在MRR@20上k=512附近性能最佳。但k超过512时算法在3个数据集上性能均有不同程度的下降,这可能是由于邻居数在256-512左右时邻域信息整合程度较高,能够较好提升模型的性能,但过大时引入了与会话意图无关的噪声会话导致推荐性能降低。实验结果表明,邻域信息的整合程度能够影响模型对于用户会话意图的准确预测。
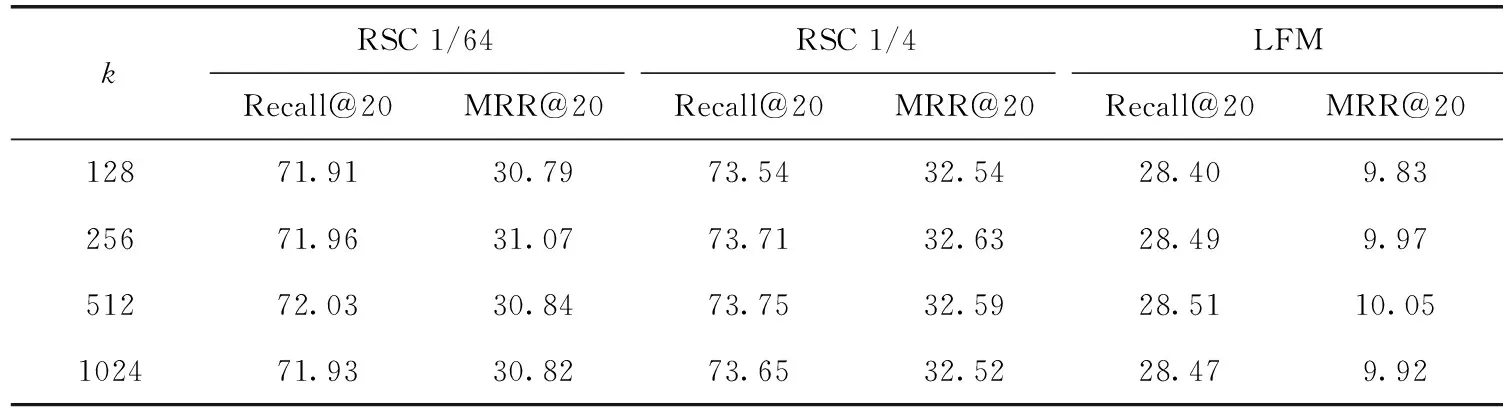
表5 SRGM的不同邻居数(k)性能比较/%
3.6 时间复杂度分析
SRGM的模型时间复杂度[15]的计算力主要集中于图卷积网络和BiGRU部分。假设设会话长度为n,项目嵌入维度为d,层数为K,则通过出入度矩阵初始节点表示的时间复杂度为O(nd2), 通过BiGRU单元为O(nd2), 整个图卷积过程的时间复杂度为O(Knd2+nd2)。
SRGM在GRU基础上增加双向结构,在时间复杂度少量增加的同时带来了性能的巨大提升。有助于实现模型对会话意图的预测。CSRM的时间复杂度为O(Kn2d+nd2), 在层数K接近的情况下,会话长度越长,SRGM相比于CSRM的时间复杂度越低。整体来看,本文提出的SRGM模型更加高效,具有一定的实用性。
4 结束语
本文提出一种融合BiGRU注意力机制和记忆网络的模型SRGM来解决推荐系统中会话推荐的问题。使用BiGRU获得用户的历史会话兴趣,并用另一个融合缩放点击自注意力的BiGRU捕捉用户当前行为特征并将两者融合作为SNE的会话表示,使用卷图积网络改进MNE以作为用户邻域会话表示,最后融合选通门将两个编码器会话表示特征融合的结果作为用户最终会话兴趣以预测下一个点击。
3个数据集上的实验结果表明,在不同的评估指标上本文模型相对于基线算法有了明显改进,验证了本模型在基于会话推荐上的有效性。在未来的工作中,还希望引入用户评论等有关项目的信息来对模型进行改进。
猜你喜欢
长江丛刊(2020年17期)2020-11-19
吉林大学学报(理学版)(2020年3期)2020-05-29
成都信息工程大学学报(2018年3期)2018-08-29
自动化学报(2018年7期)2018-08-20
制造技术与机床(2017年7期)2018-01-19
海外华文教育(2016年3期)2017-01-20
周口师范学院学报(2016年5期)2016-10-17
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
