
文字部件分割方法
2023-02-20 13:42蔺广逢刘廷金
实验室研究与探索 2023年11期
蔺广逢,刘廷金,杨 戬
(1.西安理工大学印刷包装与数字媒体学院,西安 710048;2.西安碑林博物馆,西安 710001)
0 引言
在“十四五”期间,为加快社会主义文化繁荣发展,明确要求加快数字化发展,加强对古籍碑文保护的研究。因此,准确、有效地检测和分割碑文文字,是对石刻碑文保护的有效途径。
目前对于石刻碑文检测和分割的研究相对较少。传统方法中,部分学者对较为成熟的计算机光学字符识别(OCR)进行改进。然而,由于石刻碑文背景杂乱、字体残损、字体风格多样、训练图像单一等原因,导致传统识别算法的效果较差。同时,传统识别算法的性能主要取决于特征的提取,而人工设计的提取器只适用于特定场景,因此所提取的特征信息区分度低。深度学习下的文字检测分割主要分为2 类:第1 类,借鉴语义分割方法,将文字识别问题转化为语义分割问题,对输入文字图像的每个像素点进行分类,实现像素级的预测分割;第2 类,利用目标定位、检测进行分割,包含两阶段的算法R-CNN[1](region-convolutional neural networks)、Fast R-CNN[2](fast regionconvolutional neural networks)、Faster R-CNN[3](faster region-convolutional neural networks)等以及一阶段的算法SSD[4](single shot multibox detector)、YOLO[5](you only look once)、SOLO[6](segmenting objects by locations)等。
现有算法都是对文字的整体进行检测和分割,但是文字种类繁多,常用文字就有2 500 多个,而且对于残损文字检测效果较差,因此提出了文字部件的检测和分割方法。文字部件相对较少,只有393 个,而且对于残损文字的判别和修复可提供有效支持。针对文字部件检测和分割的需求,基于深度学习的文字部件实例分割,探索现有实例分割框架对文字部件分割的有效性,然后采用SOLOv2 改进算法,将高层语义特征和底层细粒度特征进行充分融合,优化部件边界分割精度。最后,通过实例验证了所提算法的有效性。
1 实验设计
1.1 算法设计
本实验拟以SOLOv2 模型为基准,实现对文字部件的实例分割。图1 为SOLOv2 改进算法流程及详细框架。图1(a)为所提出的SOLOv2 改进算法流程,对文字图像进行预处理,然后输入改进的SOLOv2 模型中,通过置信度筛选和非极大值抑制确定部件类别和部件掩码。图1(b)为SOLOv2 改进算法的详细框架,层级融合模块(HIM)和边界增强模块(BEM)为提出的改进模块。图像经过骨干网络(ResNet50[7])特征提取后得到不同深度的特征C2、C3、C4、C5、C6(Cn表示原图的1/2n大小特征),然后传入层级融合模块(HIM)得到融合后特征的P2、P3、P4、P5、P6。P2~P6充分融合细粒度特征和语义信息,特征大小依次为输入图像的1/4、1/8、1/16、1/32、1/64,再利用SOLOv2算法的原始共享头部进行类别预测和掩码预分割。最后,将预分割掩码和Sobel检测的边缘先验信息传入边界增强模块,通过注意力机制融合掩码特征和边缘先验信息,以增强预分割掩码的边界信息,提高掩码精度。
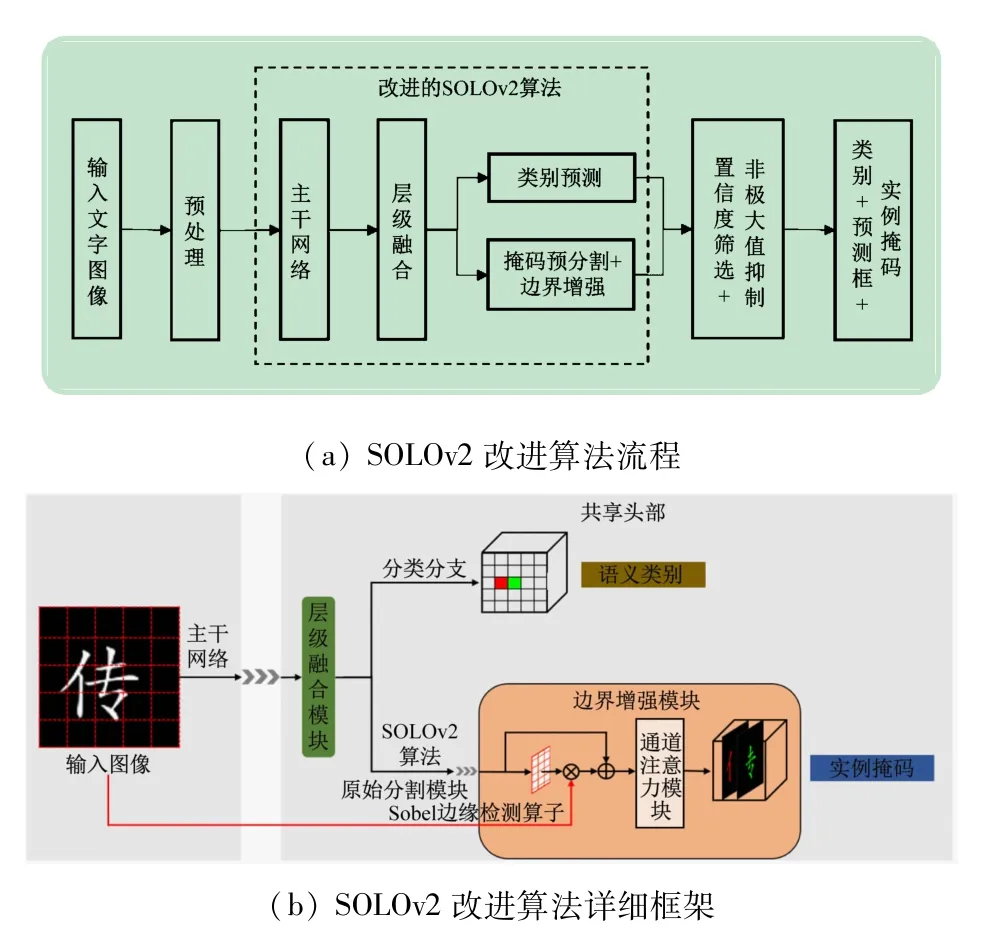
图1 SOLOv2改进算法流程及详细框架
1.2 层级融合模块
PANet[8](path aggregation network)和FPN[9](feature pyramid networks)仅传递了多尺度信息,没有对这些信息进行选择性融合。因此,借鉴文献[10]中提出的特征金字塔生成范式,提出层级融合模块。
层级融合模块如图2 所示。在FPN 之后,将FPN层不同尺度的特征P =(P2,P3,P4,P5,P6)作为输入,通过特征压缩复制(FCR)模块在通道上进行压缩复制,然后将特征进行分组、组合和融合。
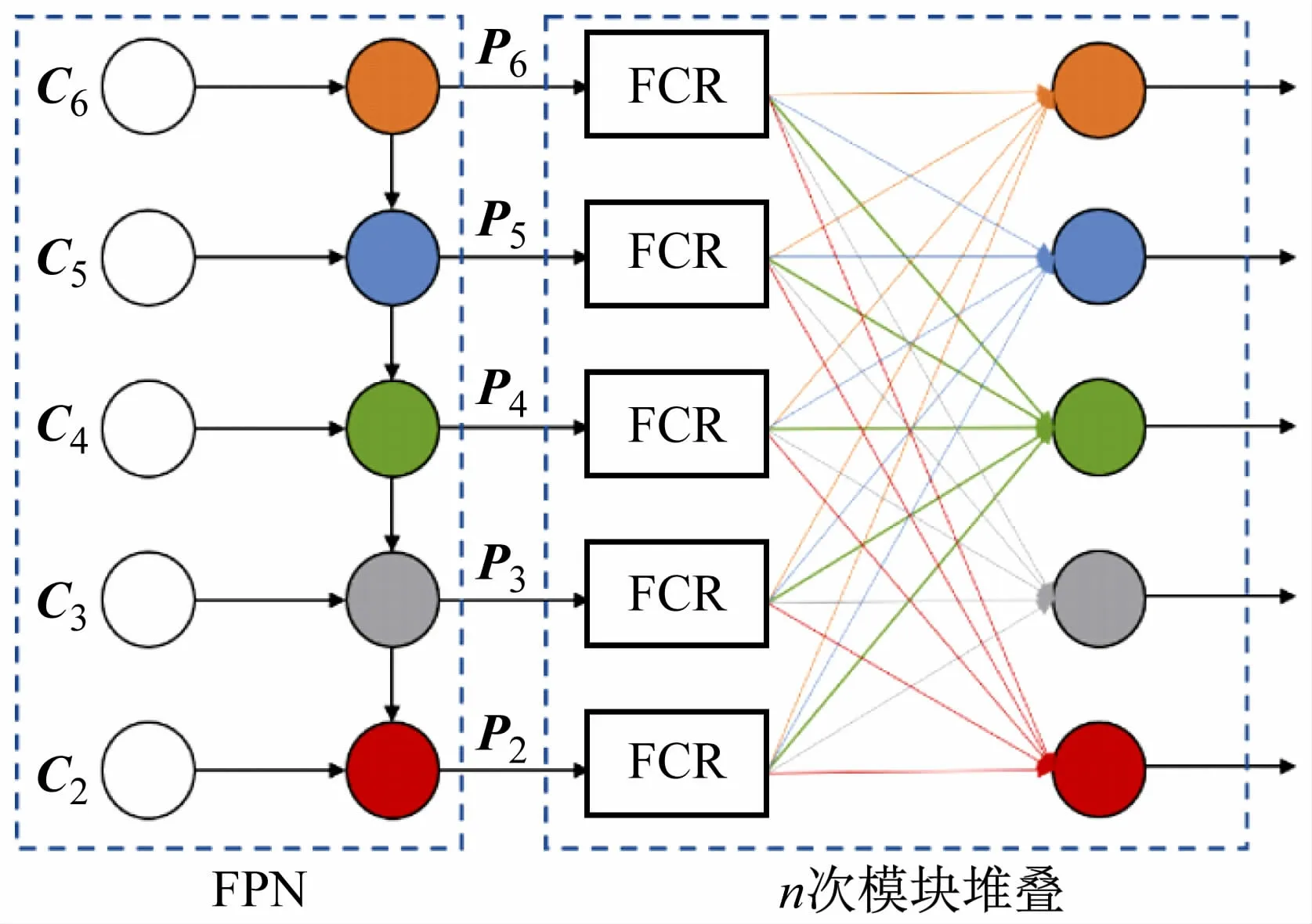
图2 层级融合模块网络结构
层级融合具体的步骤如下:以矩阵乘法的形式对特征P进行加权,并压缩特征维度,使其在通道上更加紧凑,同时进行复制,用于后续多尺度特征组合和融合。融合后特征Xk可表示为
式中:⊙表示矩阵乘法;ReC×H×W(·)和ReC×HW(·)分别表示将输入张量重塑为三维C×H×W和二维C×HW,HW表示H和W的乘积,其中C是通道数,H是特征图的高,W是特征图的宽;Gk(·)表示特征压缩复制模块中特征变换部分。特征压缩复制模块结构如图3 所示。首先输入特征Pk进行全局池化(GAP),然后经过2 个卷积提升通道维度,最后重塑为C′×C,得到特征P′k,该特征与输入特征Pk进行矩阵乘法,以通道加权的方式对特征压缩复制。对于加权后的特征Xk,每C′/5 个通道为一组,以进行多尺度特征融合。图3 中,ReC′×C表示将输入张量重塑为C′×C大小,其他的张量重塑有类似的意义。实验中C为256,C′为320。
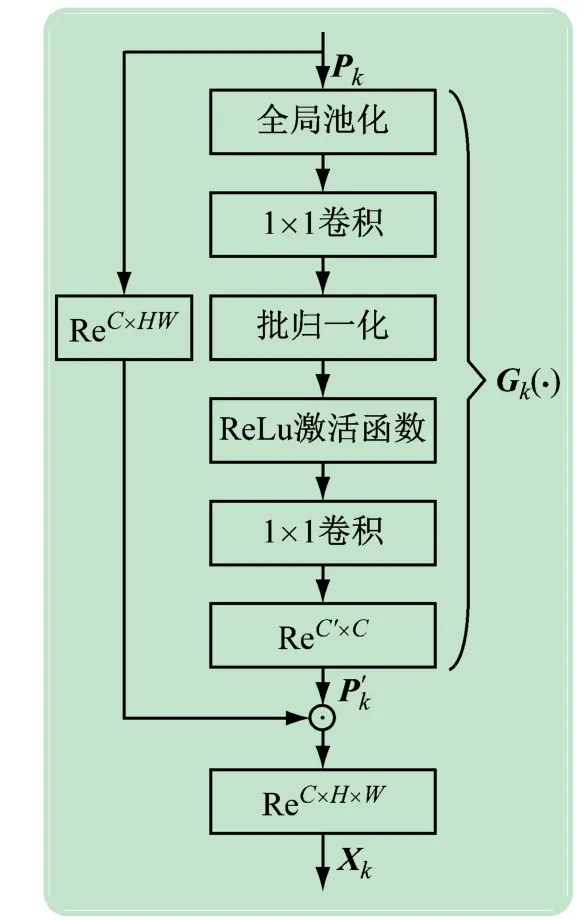
图3 特征压缩复制模块网络结构
将特征压缩复制模块的输出Xk在通道维度上划分成五部分:Xk=(X2k,X3k,X4k,X5k,X6k),2≤k≤6,然后将多尺度的特征进行组合并融合,表达式如下所示:
式中:concat(·)表示特征连接操作;Convs(·)表示2层卷积核为3 ×3 的卷积、批归一化(BN)层和ReLU激活函数操作。
1.3 边界增强模块
文字部件结构复杂多样,为了得到更好的分割效果,提出了边界增强模块,如图4 所示。图4 中通道注意力模块以特征s 每个通道为token。结合边缘检测算子,得到原图像的边缘先验信息,然后通过注意力机制增强预分割掩码的边缘特征,以提升掩码精度。

图4 边界增强模块
将原始图像x 和SOLOv2 算法预分割掩码特征fpre_mask作为输入。原始图像经过下采样、Sobel 边缘检测和卷积处理后得到原始图片的边缘先验信息fedge_prior,表达式如下所示:
式中:D(·)表示下采样操作;S(·)表示Sobel 边缘检测算子。预分割掩码特征具有高级语义信息,但是仍然存在大量实例内部的杂乱边缘信息,该信息会严重影响预测掩码的精度。将激活的边缘先验信息和预分割掩码特征在通道上进行连接,然后采用通道注意力模块(CAB)[11]在通道维度上屏蔽杂乱的边缘信息,表达式如下所示:
式中:σ(·)表示Sigmoid激活函数;⊕表示在通道上进行拼接;⊗表示对应元素相乘;CAB(·)表示通道注意力模块。经过Sigmoid激活函数得到通道之间的注意力得分,然后对输入特征在通道上进行加权,重新计算得到的特征,最后添加残差连接,将原始特征和加权后的特征对应像素相乘,表达式如下所示:
式中:T(·)表示矩阵维度转置(将H×W×C置换为C×H×W);aAtt表示注意力得分。
在通道注意力模块后,经过2 层卷积Convs(包含卷积核为3 ×3 的卷积层、BN 层、ReLU 激活函数层和卷积核为1 ×1 的卷积层)进行特征融合并降维,得到预测掩码。
边界增强模块中,原始图像通过Sobel 边缘检测算子处理得到原图的边缘先验信息,并在损失函数的指导下优化这些边缘,以引导模型将注意力集中在文字部件的边界上。
1.4 实例分割数据集的生成
文字不仅种类繁多(仅常用文字就有2 500 多个),而且结构复杂。在数据采集的过程中由于人为疏忽、自然环境的影响,可能存在破坏石碑的风险,因此难以采集足够的在碑文上每个字的训练样本。国家语言文字工作委员会发布的语言文字规范对常用的2 500 多个文字进行结构和部首的拆分,得到336个文字部件。模拟现实中石刻碑文图像是一个有效解决碑文训练样本少的方法。
通过旋转、缩放、拉伸、剪切、颜色模型空间色调变换等方式,在336 个文字部件中随机选取2~6 个不同的文字部件复制到石碑杂乱背景,同时加入椒盐噪声,随机生成白点或者黑点,模拟现实中的石刻碑文图像,如图5 所示。图5 的左上图中仅存在2 个部件,旋转角度较小;右上图中存在多个部件,旋转角度较大的;左下图中存在多个部件,并且相互重叠;右下图中背景噪声干扰严重。数据集详细信息如表1 所示。数据集下载地址为https:∥github.com/Liutingjin/Rad-ical-Instance-Segmentation/releases/download/datasets/radical2coco.zip。

表1 文字部件数据集

图5 部件数据集示例图片
1.5 损失函数设计
所提出模型的整体损失函数可以表示为
式中:Lcls、Lpre-mask分别表示SOLOv2 模型的原始类别损失和实例分割的掩码损失;LBEM-mask表示边界增强后实例分割的掩码损失;λ和μ为损失权重,在实验中设置为3,用来平衡Lcls、Lpre-mask和LBEM-mask。
Lcls为Focal损失,是在交叉熵损失的基础上加入α和γ 超参数平衡因子,平衡难以分类样本的损失贡献。Lcls的表达式如下所示:
式中:p为部件的真实标签值,为模型分类结果。Lpre-mask为Dice损失,用于计算预分割掩码与真实掩码的重叠区域,表达式如下所示:
式中:M为真实分割掩码;为预分割掩码分支预测掩码。LBEM-mask是在Dice损失的基础上添加交叉熵损失(BCE),表达式如下所示:
2 实验方法与分析
2.1 网络模型训练
在文字部件数据集上进行实验,使用平均精度(AP)作为实验的评估指标,分别评估了边界框检测和实例分割掩码的amAP(平均精度在不同IoU 阈值上平均)、aAP50(IoU阈值为0.50 时的平均精度)、aAP75(IoU阈值为0.75 时的平均精度)、aAPs和aAPm(不同尺度的平均精度,s表示实例面积小于322,m表示实例面积大于322且小于962),所有实验的主干网络均为ResNet50,并利用ImageNet数据集[12]上预训练的权重初始化网络参数。硬件设备为NVIDIA RTX 3090 24 G、CUDA v11.1 和Ubuntu 16.04。实验使用随机梯度下降(SGD)训练,进行1.8 ×105次迭代训练优化,初始学习率为0.005,每批量为8 张图像,在迭代1.2 ×105和1.6 ×105次时,学习率均降低10 倍。权重衰减系数和动量系数分别设置为1.0 ×10-4和0.9。基于Detectron2[13]开源库,在训练期间,输入图像大小被调整为短边在[640,800]范围内,而长边小于或等于1 333,也可使用左右翻转数据增强。训练得到的损失曲线如图6 所示,损失值在训练开始时急剧下降,随着训练的进行逐渐放缓,最终趋于稳定,模型收敛。测试时,不使用任何数据增强,按比例缩放图像的分辨率至少为800 × 800。这项工作的推理在单个RTX 3090GPU上测试,每批量为1 张图像。在相同的实验环境下,使用相同的训练方式,训练了Mask RCNN[14],CenterMask[15]、Transfiner[16]和CondInst[17]模型,用于对比分析。
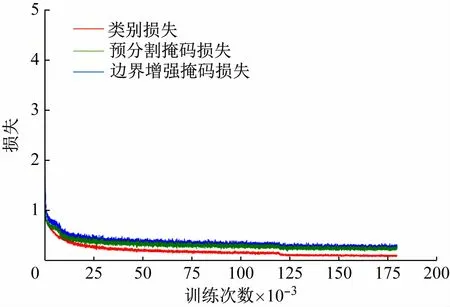
图6 训练过程的损失曲线
2.2 与其他模型对比
为了验证现有经典模型和所提出模型对碑文部件数据集的检测和分割能力,进行了实验和对比,结果如表2 所示。在实验中发现,在CenterMask 模型中,若全卷积一阶段目标检测效果较差,则裁剪得到的特征存在部件特征缺失,可能使部件退化为另一部件,导致掩码分支像素点分类错误。例如,部件特征缺失后,“甲”“申”“电”“由”可能会变成“田”。
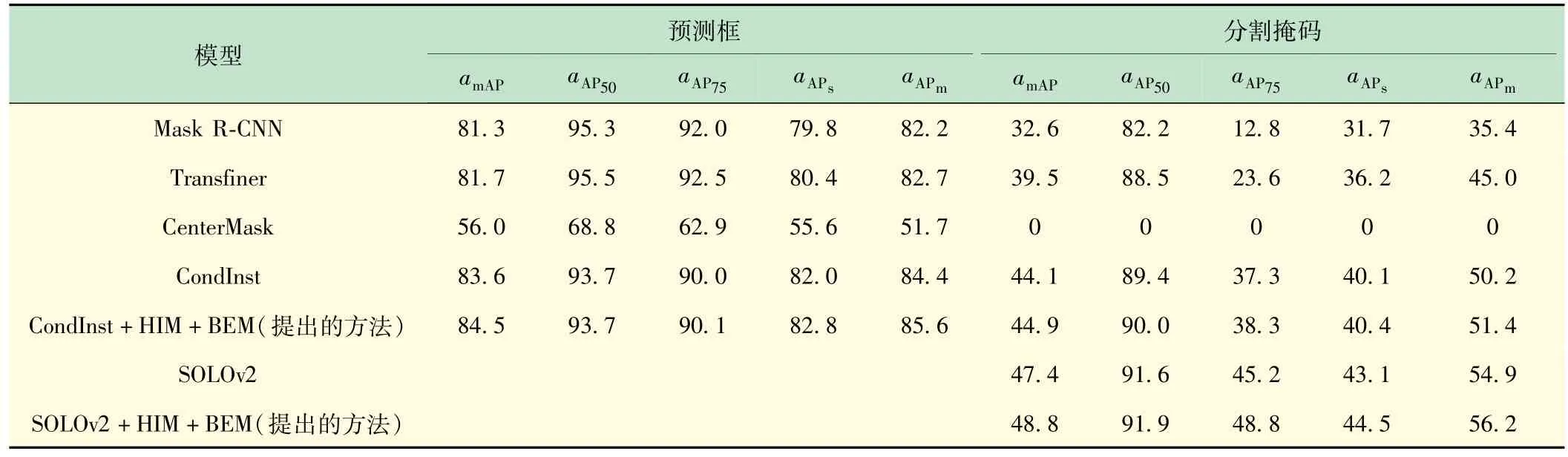
表2 不同模型的精度 单位:%
由表3 可以看出,Mask R-CNN 和Transfiner 模型的分割效果较差,但是没有出现CenterMask 模型那种失效的情况。SOLOv2 模型的amAP达到了47.4%,远远高于其他模型的分割效果,而且SOLOv2 模型只进行分类和分割,分割速度更快,具有良好的实时性。相对于SOLOv2 和CondInst 模型,SOLOv2 +HIM +BEM模型和CondInst +HIM +BEM模型的性能都有不同程度的提高,CondInst +HIM +BEM 模型的amAP提升0.8%,SOLOv2 +HIM +BEM 模型的amAP提升1.4%,验证了改进后文字部件分割方法的有效性。

表3 在CondInst模型上消融实验数据对比 单位:%
2.3 消融实验
为证明提出的层级融合模块和边界增强模块对模型的贡献,在SOLOv2 和CondInst 模型上进行消融实验。在消融实验中,分别将层级融合模块和边界增强模块单独添加到相应的模型,对文字部件进行检测和分割。实验中骨干网络都采用ResNet50 模型,实验结果如表3 和表4 所示。优后的模型在文字部件检测和分割任务中性能均得到了提升。在CondInst模型中加入层级融合模块后amAP、aAP50、aAP75、aAPs、aAPm分别提升0.7%、0.6%、0.9%、0.4%、0.8%;在SOLOv2 模型中加入层级融合模块后amAP、aAP50、aAP75、aAPs、aAPm分别提升0.5%、-0.1%、1.8%、0.4%、0.4%,尽管aAP50有0.1%的下降,但是对小物体和中等物体的分割精度得到了提升。
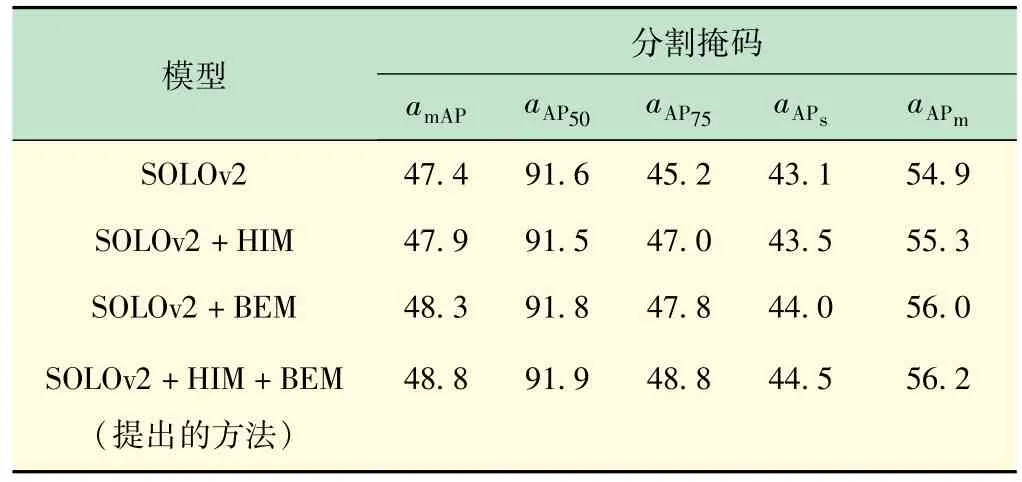
表4 在SOLOv2 模型上消融实验数据对比 单位:%
边界增强模块主要作用为掩码分支,由表3 和表4 可以看出,其对检测并无促进效果,但是对掩码精度的提升有一定的效果。CondInst模型在添加边界增强模块后amAP、aAP75、aAPs、aAPm分别提升0.3%、0.6%、0.1%、0.5%;在SOLOv2 模型中加入边界增强模块后amAP、aAP50、aAP75、aAPs、aAPm分别提升0.9%、0.2%、2.6%、0.9%、1.1%。
层级融合模块和边界增强模块分别作用于网络的不同模块中,层级融合模块可以为后续分割提供更好的特征。由实验结果可以看出,这2 个模块并不会产生冲突,能够促进检测和分割效果。CondInst 模型在添加层级融合模块和边界增强模块后amAP、aAP50、aAP75、aAPs、aAPm分别提升0.8%、0.6%、1.0%、0.3%、1.2%;在SOLOv2 模型中加入层级融合模块和边界增强模块后amAP、aAP50、aAP75、aAPs、aAPm分别提升1.4%、0.3%、3.6%、1.4%、1.3%。图7 为SOLOv2 模型上的可视化结果。由图7 可见,SOLOv2 原始模型能够很好地检测和分割文字部件,但是在一些边界细节上处理得并不精细,而改进后的模型从特征融合和边缘增强方面促进掩码分支分割精度的提高。

图7 可视化分割结果
3 结语
对文字部件的检测和分割进行了初次探索,达到了较好的效果。首先,基于文字部件,利用数据增强方式模拟杂乱碑文背景,生成了大量文字部件实例分割数据集;其次,探索了现有实例分割模型对文字部件数据集的分割效果,基于感兴趣区域对齐、池化操作的实例分割框架会使检测部件退化为另一部件,导致像素点分类错误,分割效果较差甚至不起作用;最后,将所提出的层级融合模块和边界增强模块对SOLOv2 和CondInst模型进行改进。
猜你喜欢
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
通信学报(2019年5期)2019-06-11
制造技术与机床(2018年9期)2018-09-19
通信技术(2018年3期)2018-03-21
海外华文教育(2017年6期)2017-08-07
系统工程与电子技术(2016年2期)2016-04-16
水电站机电技术(2016年1期)2016-02-28
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
