
中文命名实体识别研究综述
2023-02-18 07:16王颖洁张程烨白凤波汪祖民季长清
计算机与生活 2023年2期
王颖洁,张程烨,白凤波,汪祖民+,季长清,2
1.大连大学 信息工程学院,辽宁 大连116622
2.大连大学 物理科学与技术学院,辽宁 大连116622
3.中国政法大学 证据科学研究院,北京100088
命名实体识别(named entity recognition,NER)是自然语言处理中的一项基础任务,主要用于识别文本中实体的类别和边界。该任务最初是在信息理解会议(message understanding conference,MUC)任务[1]上作为实体关系分类的一个子任务被提出,其中关注的实体类型主要包括组织名、人名、地名等。命名实体识别的主要思想是先将待识别文本转换为嵌入向量的形式,然后将嵌入向量输入到识别模型中,最终将模型的输出通过分类器得到实体分类的结果。将文本中的实体进行准确的划分和分类,可以有效地为接下来关系抽取、情感分析和文本分类等下游任务提供可靠的支撑,因此,如何有效提高命名实体识别的效果,成为当前工业界关注和研究的焦点。
本文从当前中文命名实体识别的研究成果出发,首先对命名实体识别各个阶段的研究成果进行了概述,同时从汉字和单词两个角度,对当前中文NER 热门的字词特征融合方法进行了论述和总结。然后,针对当前中文NER 的研究成果,在模型方法优化和模型预处理两个优化方向上进行了总结。最后,对中文NER 任务中常用的数据集和评价指标进行了归纳和整理,并对中文NER 任务未来的研究方向和研究重点进行了展望。
1 命名实体识别方法
命名实体识别的主要任务是从海量的文本数据中识别不同类型的实体。这不仅是构建知识图谱或智能问答系统的基础技术环节,而且也是进行文本信息挖掘的第一步。命名实体识别的方法按照发展历程可以分为基于规则的方法、基于统计模型的方法和基于深度学习的方法三类。
1.1 基于规则的方法
基于规则的方法由于易于实现且无需训练的特点,在早期的实体抽取任务中取得了很好的效果。基于规则的方法在已有知识库和词典的基础上,通过特定领域的专家手工制定规则模板,以标点符号、指示词、位置词、方向词、关键字、中心词等特征作为抽取的依据。常见的基于规则的实体抽取方式包括基于实体词典的最大匹配算法和基于正则表达式的规则模板设计。基于规则的方法的优点是在特定领域内的准确率高,且召回率很低,适用于数据集较小且更新不频繁的领域。Feng 等人[2]针对在数据集实例较少时,单一基于条件随机场(conditional random field,CRF)的提取器准确率和召回率效果不好的情况,将CRF、规则模板和中文实体词典结合使用,实现了良好的性能。Pan[3]通过将识别规则引入统计方法,减少了对大规模语料库的依赖。Yan[4]从实体内部组成和上下文语境入手,针对姓名构建了相应的识别规则,极大地提高了中文人名识别的准确率。但同时基于规则的方法也存在着泛化能力差、词典构造成本高的问题。因此在面向海量文本数据的今天,基于规则的方法大多情况下与选用的训练模型结合使用,以提高模型的准确率。
1.2 基于统计模型的方法
基于统计模型的方法的核心在于针对特定的研究背景来选择合适的训练模型。与基于规则的方法相比,这种方法省略了诸多繁琐的规则设计,可以花费更短的时间训练人工标注的语料库,提高了训练效率。同时,面对特定领域规则不同的问题,基于统计模型的方法只需要针对特定领域的训练集,重新对模型进行训练即可。因此这种方法的可移植性很高,使用方便。目前常用的模型有隐马尔可夫模型(hidden Markov model,HMM)、条件随机场模型、支持向量机(support vector machine。SVM)和最大熵模型(maximum entropy,ME)等。而HMM 和CRF 在序列标注领域效果突出,因此被广泛应用于实体抽取领域。以下对HMM 模型进行简要的介绍。
隐马尔可夫模型是一种针对序列标注的概率模型,能够通过观测序列来预测隐含的状态序列。它的基本思想是根据观测序列找到隐藏的状态序列,同时服从于齐次马尔可夫假设和观测独立假设。按照所研究的基本问题可以将其分为三类,即概率计算问题、参数学习问题和解码计算问题。
(1)概率计算,即给定模型参数λ=(A,B,π)和观测序列Z=(z1,z2,…,zN),计算观测序列Z的条件概率P(Z|λ)。其中A为状态转移矩阵,B为观测矩阵。以前向算法为例,其流程描述如图1 所示。
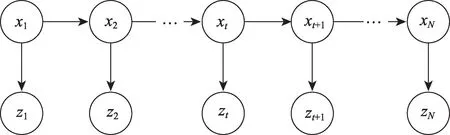
图1 序列标注问题流程描述Fig.1 Description of sequence labeling problem process
设有T个序列,定义前向概率αt(i)表示t时刻的状态以及第1,2,…,t时刻的观测在给定参数下的联合概率;bi(x)表示由状态xi生成给定观测数据的概率。经推导后可得第t+1 时刻的前向概率为:
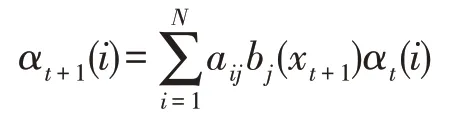
其中,aij表示在当前时刻处于状态xi的条件下,下一时刻转移到状态xj的状态转移概率。则观测序列Z的条件概率为:
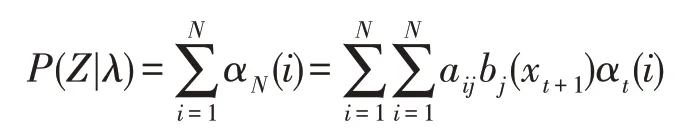
(2)参数学习,即在给定观测序列Z=(z1,z2,…,zN)的情况下,求模型中的最优参数λ*:
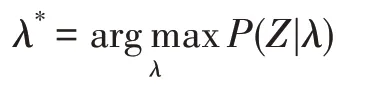
其实质上就是对模型进行训练并调参的过程,一般通过最大期望算法进行求解,具体的数学推导这里不做赘述,可以参考Rabiner[5]的文章或者其他相关书籍。
(3)解码计算,即在给定模型参数λ=(A,B,π)和观测序列Z=(z1,z2,…,zN)的情况下,求最可能出现的状态序列X=(x1,x2,…,xN)。常用的解决方法是将其看作一个最短路径问题,采用Viterbi 算法的思想,首先寻找概率最大的路径,其次在得到概率最大路径之后,从最优路径终点开始,回溯地寻找最优路径上当前点的上一个点,直到找到最优路径的起点。因此解码计算问题也可以认为是一个模型预测问题。
HMM 模型训练速度快,复杂度低,但容易在训练过程中陷入局部最优解。为了解决标注偏置问题,得到序列标注问题的全局最优解,Lafferty 等人[6]提出使用CRF 来解决序列标注问题。现阶段存在海量的文本数据,因此基于统计模型的实体抽取方法由于可以面向大规模语料而占据了一定的研究地位。Wang 等人[7]提出了一种带有回路的条件随机场(conditional random field with loop,L-CRF)来研究句子级别的序列特征,能够对上下文之间的关联进行更精准的推断,得到更为合理的序列。Yang 等人[8]提出了一种基于注意力机制的Attention-BiLSTM-CRF模型,发现在BiLSTM(bi-directional long short-term memory)层中单独的词特征要比单独的字符特征好,且二者同时运用能进一步提高性能。Li 等人[9]将HMM 与Transformer 模型结合,增加了模型的稳定性和鲁棒性。Alnabki 等人[10]通过使用局部近邻算法寻找语义上与模糊术语相似的标记,与BiLSTM-CRF相结合后,F1 值在特定实体类型上有明显提高。
但是基于统计模型的实体抽取方法也存在一定的局限性,所使用的模型只与当前时刻的状态和所观察的对象有关。在模型的实际训练过程中,序列的标注不仅和单独的某个词相关,而且和这个词所在的位置和序列总长度都有关联。因此为了与上下文进行语境的结合,提出了基于深度学习的实体抽取方法。
1.3 基于深度学习的方法
深度学习的概念由Hinton 等人于2006 年提出,起源于对人工神经网络的研究。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。深度学习覆盖领域多,涉及到的知识面广,可以解决以往的机器学习难以解决的大量问题,但其实质仍然是机器学习的一个子集。常见的深度学习模型包括卷积神经网络(convolutional neural network,CNN)、循环神经网络(recurrent neural network,RNN)、图神经网络(graph neural network,GNN)、深度神经网络(deep neural network,DNN)、生成对抗网络(generative adversarial network,GAN)、长短时记忆网络(long short-term memory,LSTM)、Transformer 和BERT(bi-directional encoder representation from transformers)等。
神经网络的基本结构由输入层、隐藏层、输出层三部分组成,其中输入层的每个神经元(neuron)可以看作待研究对象的一个特征;隐藏层用于将输入层传递的数据通过内部的函数进行处理后传递给输出层,具体的实现细节对用户透明;输出层将隐藏层的计算结果进行处理后输出。其中隐藏层的层数应当适中,过少的层数会导致需要增加更多的训练集,而过多的层数会产生过拟合的现象。
1.3.1 长短时记忆网络
长短时记忆网络(LSTM)隶属于一种循环神经网络,在时序数据预测、语音识别、文本翻译等领域均表现出不错的效果。在命名实体识别领域,LSTM可以有效提取上下文的语义信息,从而能够更好地理解文本内容。LSTM 的单元结构如图2 所示。
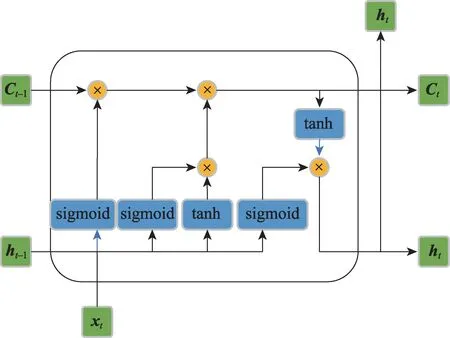
图2 LSTM 单元结构Fig.2 Unit structure of LSTM model
可以看出,相较于RNN 而言,LSTM 的每个单元结构增加了图2 所示的遗忘门、更新门和输出门三种门控制结构,从而解决了对上文长期依赖的问题。因此LSTM 可以具有较长的短期记忆,与RNN 相比具有更好的效果。
LSTM 遗忘门的结构如图3(a)所示,其作用是决定上一时刻的单元状态有多少会保留到当前时刻。设输入数据为i维列向量xt,上一时刻的隐藏状态为j维列向量ht-1,则参数矩阵Wif和Whf的维度分别为j×i和j×j,偏置矩阵bif和bhf的维度均为j×1。最终,遗忘门的输出ft的计算公式如下:

LSTM 更新门的结构如图3(b)所示,其作用是决定当前时刻网络的输入有多少会更新到单元状态中。更新门首先对输入数据xt和上一时刻的隐藏状态ht-1进行计算,其中参数矩阵Wii和Wig的维度为j×i、Whi和Whg的维度为j×j,偏置矩阵bii、bhi、big、bhg的维度均为j×1。最终,更新门的输出it和gt计算公式如下:
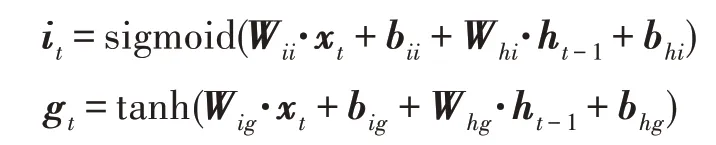
计算出it和gt后,即可和遗忘门的输出ft与前一时刻的状态Ct-1进行计算,得到更新的单元状态Ct,其计算公式如下:
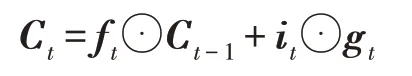
其中⊙表示哈达玛乘积运算。
LSTM 输出门的结构如图3(c)所示,其作用是决定从更新后的单元状态中输出的信息。输出门根据输入数据xt和上一时刻的隐藏状态ht-1计算得到输出门的输出ot,其计算公式如下:
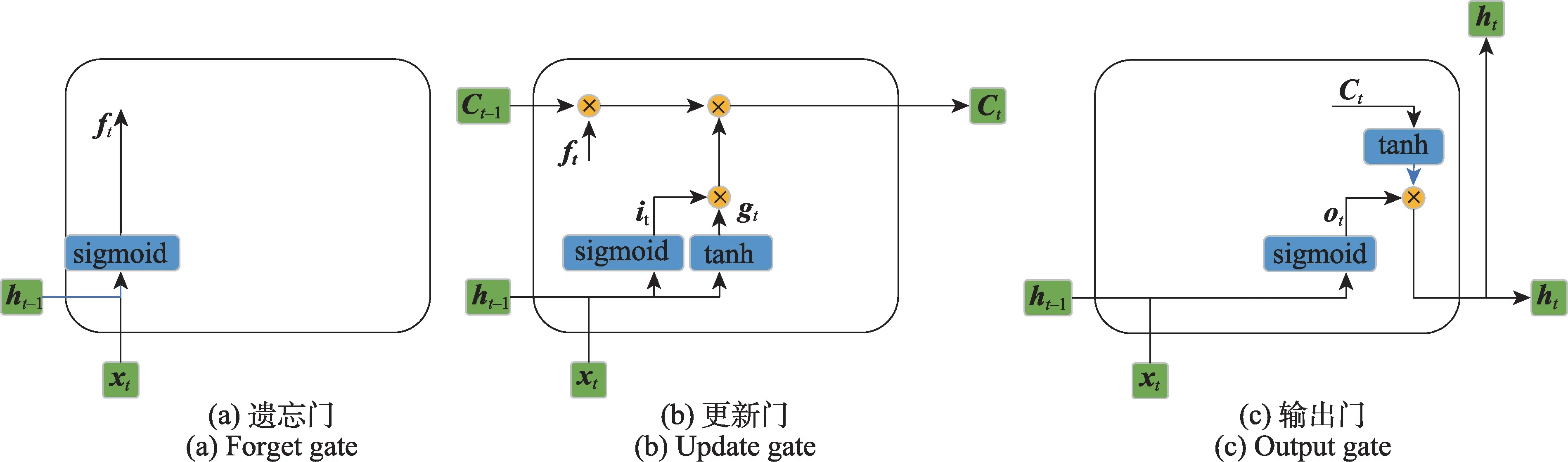
图3 LSTM 门控结构Fig.3 Gate control structure of LSTM model

其中参数矩阵Wio和Who的维度分别为j×i和j×j,偏置矩阵bio和bho的维度均为j×1。
最后,根据ot和更新后的单元状态Ct,得到该时刻的输出ht,并传递到下一个LSTM 单元中,ht的计算公式如下:

LSTM 相较于RNN 而言,在一定程度上解决了梯度消失和梯度爆炸问题。但是为了更好地捕捉双向的语义依赖,通常会在NER 任务中选择使用由前项LSTM 和后项LSTM 组合而成的双向Bi-LSTM,并与CRF 结合使用以提高识别准确率。
1.3.2 中英文NER 相互借鉴关系
相对于中文命名实体识别而言,英文文本的NER 技术由于文本分词界限清晰,相关研究起步较早,对应的成果和产品均已经处于成熟期。中文文本和英文文本同时具有相似的词性类型和语法结构,因此国内外的学者近年来逐步尝试将英文命名实体识别的相关技术应用到中文命名实体识别中。并且中文命名实体识别面临的问题在英文文本中也有类似的体现。例如,对于原始数据的标注大多停留在原始的手工标注阶段,需要一种相对稳定且可靠的标注手段。同时,随着大数据时代的到来,每天都会出现大量的互联网新词,需要寻找一种能够使词典不断更新的方式,以避免出现OOV(out of vocabulary)问题。因此,从已有的英文命名实体识别研究中寻找思路是极有必要的。
Zhao 等人[11]提出了一种多标签CNN 方法,将实体识别任务作为分类任务处理,在原有的输出层上加入多标签机制,用于捕获相邻标签之间的相关信息,在疾病名和化合物识别任务中取得了更好的效果。Wang 等人[12]提出了一种基于生成对抗网络的数据增强算法,可以在不使用外部资源的情况下,生成更加多样化的训练数据扩大数据集,同时可以自动生成标注。为了解决文本数据中噪声的干扰,Aguilar 等人[13]提出了一种多任务神经网络,将CNN和BiLSTM 并行使用,能够从字词序列、语法信息和地名词典信息中学习到更高阶的特征。但该方法对于实体边界的处理效果仍然不太理想。为了解决这个问题,Guo 等人[14]在模型中加入了注意力机制,同时针对中文语料,将部首嵌入集成到字符嵌入中作为输入,以丰富语义信息。
在某些专业领域中,文本类型的语料库规模较小,训练的效果明显降低。针对文本数据集较少的问题,Zhang 等人[15]提出使用GAN 模型所生成的注释数据作为训练数据,同时采用光滑近似逼近思想处理离散类型的文本数据,解决了标注数据缺乏和同一实体标注不一致的问题。通常在处理不同领域的数据集时,需要对模型进行重新训练,在模型比较复杂且语料库规模较大时会花费大量成本。Das等人[16]基于图聚类算法,采用无监督方法提取语料库中的实体关系,可以有效地将实体进行分类,并且适用于一般数据集。由于实体抽取的效果依赖于前期对文档分词的效果,有学者提出在文档级别对文本进行实体抽取。Zhao 等人[17]使用基于文档级的注意力机制,采用连续词袋模型(continuous bag of words,CBOW)对输入字向量进行预训练,保证了实体标签的一致性。Yang 等人[18]将双向RNN 与胶囊网络结合,提出了文档级的BSRU-ATTCapsNet(bi-directional simple recurrent unit-attention-based capsule network)模型,不仅可以提取文档中复杂结构的远距离依赖信息,而且可以从多个维度学习实体对的更深层次的关系。
相较于传统的深度学习模型,预训练模型训练的时间较短,同时训练结果也通常优于传统模型。预训练模型是指已经用数据集训练好的模型,在遇到相似的问题时,可以在调整模型中的参数后直接使用,大大缩短了模型训练的时间。目前应用较多的主流预训练模型有ELMo(embedding from language model)、BERT、GPT-2(generative pretrained transformer)、ALBERT 和Transformer 等。然而,预训练模型的参数量并非越大越好,过多的参数量会产生推理速度慢、内存空间占用大的问题,从而增加了不必要的训练时间。常见的预训练模型参数量如图4所示。
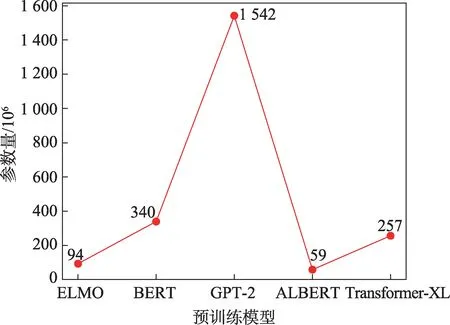
图4 预训练模型参数量对比Fig.4 Comparison of parameters of pre-training model
Guo 等人[19]提出了一种字级别的中文NER 方法,将BiLSTM 和Transformer-XL(Transformer-extra long)模型结合使用,解决了Transformer 位置和方向信息缺失的问题,大大提高了实体边界识别的准确率。Cai[20]使用多准则融合方法构建BERT-DNN-CRF 模型以挖掘语料库间的共有信息,从而提高中文命名实体识别的准确率和召回率。Liu 等人[21]将两个BiLSTM 网络以点对点的方式合并后与ALBERT 结合使用,提高了中文实体识别任务的细粒度,可以实现高精度的序列标注,在CLUENER 2020 数据集上可以达到91.56%的准确率。针对在命名实体识别时概念不够明确或实体数量较少,导致F 值下降的问题,Chen 等人[22]提出了一种融合BERT 的多层次司法文书实体识别模型,使用掩码语言模型(Masked LM)在BERT 层进行无监督预训练,在中国裁判文书网上公开的裁判文书训练中,F1 值达到了89.12%,明显优于对照模型。
2 文本预处理
2.1 序列标注方法
序列标注(sequence tagging)是自然语言处理领域的基础任务,其目标是对句子中每个单词的实体或词性进行标注,并在此基础上预测给定的文本序列中的标签类型。对于中文文本而言,序列标注任务即是对文本中每一个汉字给出一个对应的标签。在命名实体识别任务中,常用的序列标注方法有三种,分别为三位序列标注的BIO 方法、四位序列标注的BMES 和BIOES 方法。表1 列出了标注的标签类型所表示的含义。
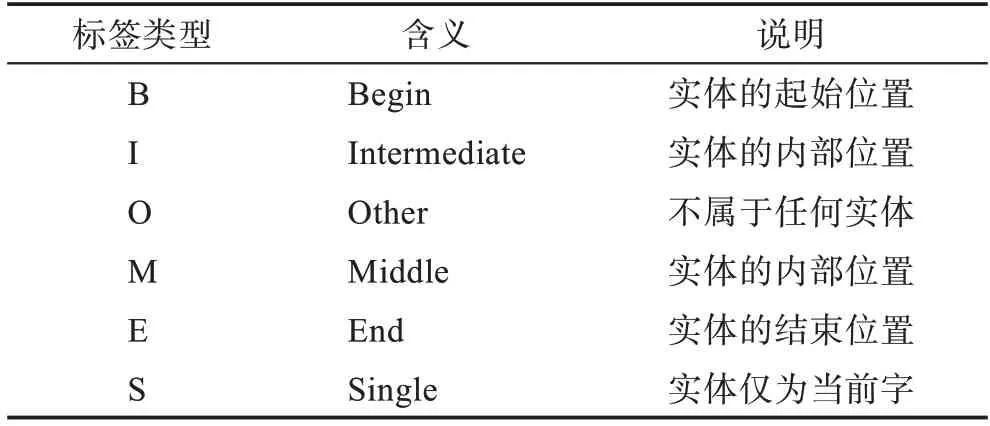
表1 常用标注标签类型含义Tabel 1 Meaning of common label annotation types
相较于BIO 方法,BIOES 方法额外提供了实体结束位置的信息,并给出了针对单字实体的标签,因此可以提供更多的信息;但它需要预测的标签更多,效果也可能因此而受到影响。在BIOES 的基础上,衍生了针对于特定领域数据集的标注方法BILOU 和BMEWO,其表示含义如表2 所示。
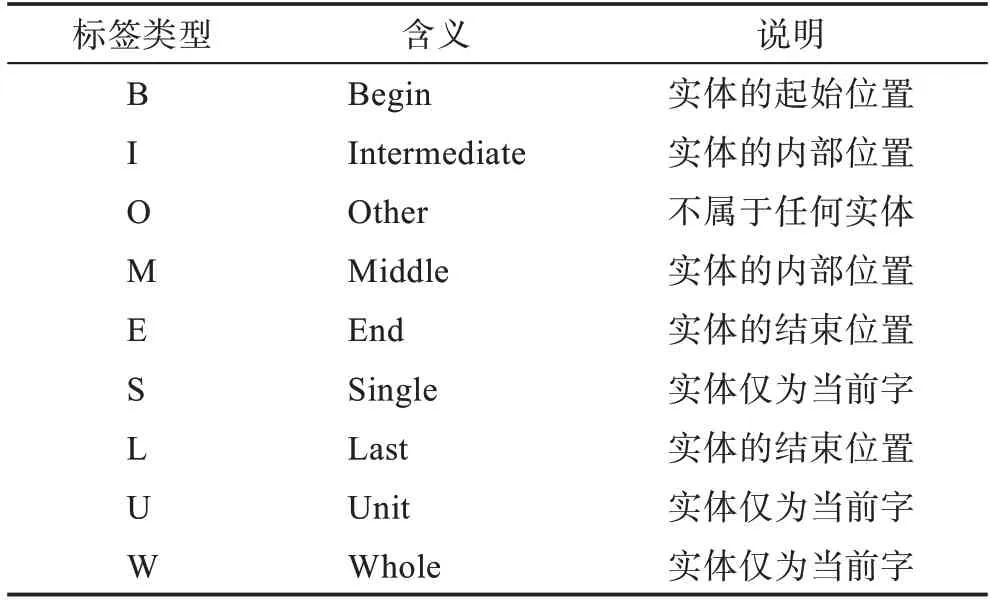
表2 BILOU 和BMEWO 标签类型Tabel 2 Annotation label types of BILOU and BMEWO
2.2 中文文本词汇分割
在执行自然语言处理任务中,对于整段的文本,首先需要以字或词为单位进行分割。分词的准确率会对下游任务产生直接影响,分词产生的误差也将在接下来的过程中逐级传递。因此,作为自然语言处理的基础,分词是文本预处理环节的关键技术。
在以英语为代表的印欧语系语言中,每个单词之间都以空格进行分割,因此可以相对简单和准确地提取单词,极大地降低了文本分词的难度。然而,中文文本将汉字作为基本单位,使用连续的字符序列进行书写,文本中的短语和词组无法直接通过文本的外在属性进行切分,在一定程度上影响了分词的准确率。因此,近年来对于中文分词(Chinese word segmentation,CWS)的研究受到了极大的关注。在国际计算语言协会(ACL)下属的中文特殊兴趣研究小组SIGHAN 举办的国际中文分词比赛中[23-24],所使用的SIGHAN Bakeoff 2005/2008 依然是当前中文分词研究的主要数据集。目前对于中文分词任务,主要采用开源的中文分词系统进行处理。图5 列出了主要采用的中文分词系统及其特性,并通过四类数据测试了不同分词系统的分词准确度。
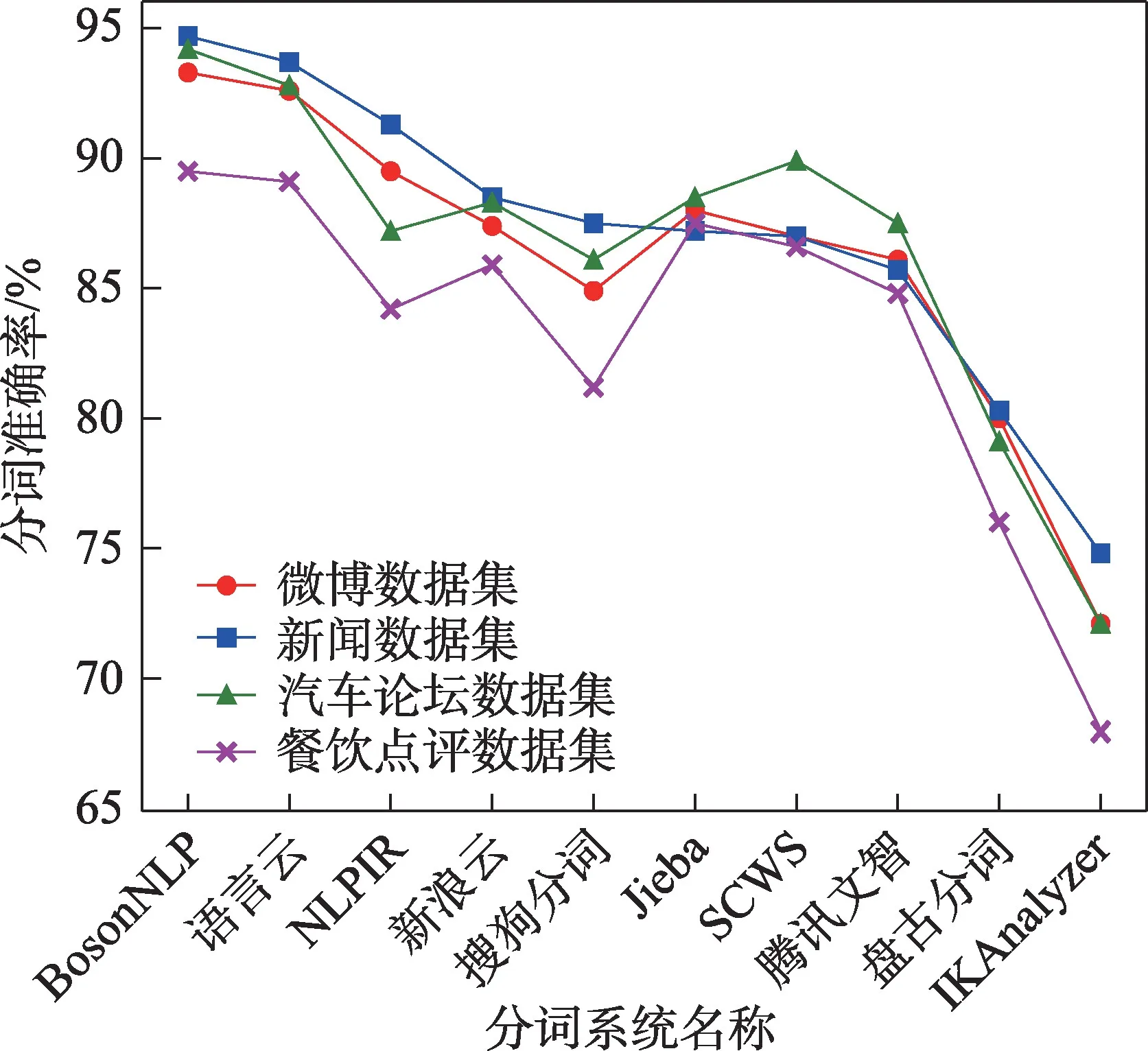
图5 不同分词系统对比Fig.5 Comparison of different word segmentation systems
CWS 方法分为两类:基于词典的方法[25],根据预先定义的分词规则,从字符串中切出单词,然后与词典中的单词匹配以完成分词。基于词典的方法简单有效,但这种方法无法处理不在词汇表中的单词,同时对于多义词的切分效果不佳。基于统计的方法,依赖于从语料库中学习的统计模型或特征[26-27],本质是将分词视为一个概率最大化问题。统计方法在表外词识别和多义词分割方面有了很大的改进,但其分词性能依赖于训练语料库的质量。并且基于统计的方法对于一些共现频率高的单字符词的识别精度较差,大多情况下有较高的时间复杂度。近年来,基于神经网络的连续小波分解方法,由于其非线性映射能力、自学习能力以及有效减少特征工程工作量的优势,多次被用于解决CWS 问题[28-30]。
中文分词相较于英文分词,存在着以下四个难点:第一,在汉语中,同一个汉字在不同的语境中可能有不同的语义;第二,汉语中的词不仅可以是一个字符,也可以由两个或多个字符组成;第三,汉语句子中的每个字之间处于紧密连接的状态,词组之间没有明显的切分特点和词性变化;第四,许多新词汇的出现和中英文混合词汇的加入给分词带来了挑战。针对上述问题,国内外的学者展开了深入研究。
Wang 等人[31]和Li 等人[32]利用深度神经网络的优势,自动学习和提取CWS 深度特征,极大地降低了传统机器学习序列标记模型中,稀疏特征向量和维数过大导致内存和计算资源的浪费。对于跨域CWS,Zhang 等人[33]提出了一种用于联合CWS 和词性标记的监督域自适应方法。Qiu 等人[34]基于连续小波分解方法,提出了一种使用双传播算法自动挖掘小说名词实体的方法。Zhang 等人[35]将外部字典集成到CWS 模型中,提高了跨域CWS 的准确率。
作为一种替代表示学习模型,自注意力网络(self-attention network,SAN)[36]已被证明对一系列自然语言处理任务非常有效,例如机器翻译[37]、选区解析[38]、语义角色标记[39]和语言建模[40-42]。Gan 等人[43]首次使用SAN 模型处理CWS 任务,不仅可以实现高度并行化,而且在域内和跨域中文分词数据集上都能够实现良好的效果。然而,现有的中文自动分词研究成果还不能完全满足实际应用的需要。在一些专业领域中,对于分词规范化、分词歧义、非语料库词识别、分词顺序等问题,仍然需要进一步研究。
2.3 中文NER 任务常用数据集
为了准确地评估中文NER 模型识别的效果,研究人员尝试采用一种可以通过理论证明的模型评价方法。在通常情况下,同一模型在不同环境下的效果存在较大的差异,因此需要提供一个基准评估数据集,从而客观地评价当前模型的实体识别效果,进而开展下一步模型分析和改进的研究。
对于中文命名实体识别任务而言,数据集中标签的标注准确率可以对模型的识别效果产生很大的影响。图6 列出了近年来在中文命名实体识别任务中常用的数据集,并列举了其年份、来源和实体类型数量。
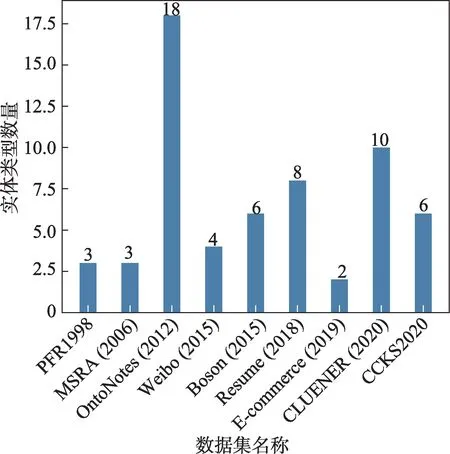
图6 中文NER 常用数据集Fig.6 Commonly used Chinese NER datasets
2.4 模型评价指标
模型在构建完成后,需要对其执行结果进行评估。模型评估不仅为了确认该模型是否符合实际的需求,而且在评估的同时,模型的参数和特征值都需要根据评估结果进行相应的修正,从而对模型进一步优化。对于同一个模型,需要从各个角度进行评估,而非从某个单一的角度判断其性能优劣。当多种模型进行横向对比时,使用不同的评价方法往往会导致不一样的测试结论。因此,在评估具体模型时,评估结果的好坏通常是相对的。总体而言,模型的好坏不仅取决于测试数据的质量和使用算法的性能,还决定于所完成任务的具体需求。
在知识抽取任务中,常见的评价指标有准确率(precision)、召回率(recall)和F 值(F-score),这三个指标常被用来衡量所采用的知识抽取系统的性能。由于在二元分类任务中,预测结果和真实情况之间存在四种不同的组合,即预测为正例的正样本TP、预测为正例的负样本FP、预测为负例的正样本FN 和预测为负例的负样本TN,这四者组成了二元分类任务的混淆矩阵(confusion matrix)。
准确率:指在所有预测为正例的样本中,真实值也为正例的概率。
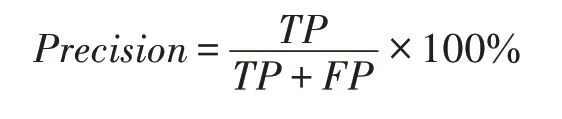
召回率:指在真实值的所有正样本中预测为正例的概率。
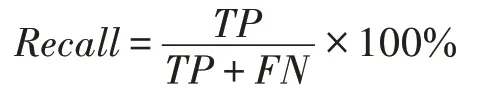
F 值:用来衡量二分类模型精确度的一种指标,当准确率和召回率发生相互矛盾的情况时,可以同时兼顾分类模型的精确率和召回率两个评价指标。

当准确率和召回率都很重要时,可以认为二者有相同的权重,即β=1,则称此时的F 值为F1 值。
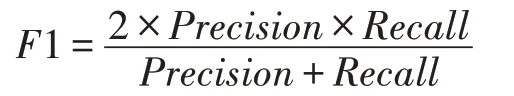
模型的评估检验方式众多,以下对其中常用的三种检验方式进行介绍。
(1)Holdout检验
Holdout检验是一种最为简单也最为直接的验证方法。它将原始的数据集随机划分成训练集和验证集两个互斥的集合。这种方式的缺点也很明显,计算出来的评估指标与划分方式有很大的关系,并且当数据集中数据不平衡时,无法进行划分。为了消除这种随机性,引入了交叉检验的方式。
(2)交叉检验
交叉验证的核心思想是在已有数据集规模较小的情况下重复使用数据。首先对数据集进行切分,并将切分后的子集归为训练集和测试集两类,最终基于训练集和测试集反复进行模型的训练和优化,从而对模型进行检验。从数据切分的方式上看,交叉检验分为简单交叉验证和K-fold交叉验证两种方式。
简单交叉验证首先将给定的数据划分为训练集与测试集两部分,接着用训练集在不同的条件下对模型进行n次训练,从而得到n个不同的模型;最后在测试集上对当前n个模型进行测试,计算其测试误差,并选取误差最小的模型作为最优训练模型。
K-fold 交叉验证首先将全部样本划分成k个大小相等的样本子集;接着依次遍历这k个子集,每次遍历利用k-1 个子集的数据作为训练集,余下的子集作为测试集,进行模型的调参和优化;最后把k次评估指标的平均值作为最终的评估指标。
(3)自助检验法
不管是Holdout 检验还是交叉检验,其原理都是基于划分训练集和测试集的方法来进行模型评估。然而在实际情况中,训练数据集的规模通常较小,因此无论如何进行划分都会减少训练集的规模,从而影响模型的训练效果。此时基于自主采样的自助法成为了目前针对小规模样本模型评估的主流选择。
自助法首先对总数为N的样本集合进行N次有放回的随机抽样,根据抽样结果得到大小为N的训练集。由于采样过程随机,必定会存在从未被抽取的样本。自助法将这些没有被抽取过的样本作为验证集,进行模型验证。
当采用自助法进行模型评估时,训练数据集越大,其训练集和验证集的比例越会趋近于一个稳定值。其证明过程如下:
由于在一次抽样过程中,某一样本未被抽中的概率Pval为:
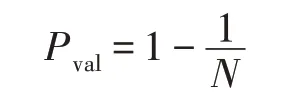
则N次抽样均未被抽中的概率为:
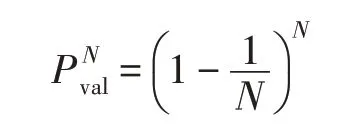
当训练集较大时,N可以视作趋近于无穷大,则当样本数较大时有:
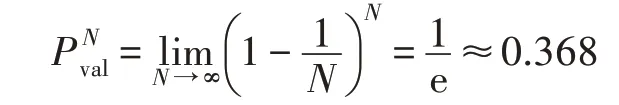
也即当样本数很大时,样本中约有36.8%的数据会作为验证集使用。
3 中文字词特征融合
传统的中文命名实体识别方法根据固定的转换编码,将每个汉字转换为特征向量输入到网络模型中。然而,这种方法存在着较为严重的局限性。首先,该类方法仅利用了汉字自身的特征,并没有结合字在词中的位置信息,会导致出现上下文语义缺失的问题。同时,与英文单词不同,汉字自身具有丰富的象形特征,而这种固有的特征信息并没有被充分利用。为了解决上述问题,在中文特征融合这一方面有超过百篇的文章来讨论如何解决语义缺失问题。根据所融合的特征对象进行划分,大体上可以分为两类特征融合:词语特征融合和汉字特征融合。
3.1 词语特征融合
在中文文本中,分词的错误引起的错误传播会导致命名实体识别的效果变差,使用常规的通用分词方法甚至会导致基于词语的NER 方法的准确率低于基于字符的方法[44]。因此,为了有效利用单词序列信息,可以采用一种格结构[45]进行处理,通过词开始和结束的字符来确定所在的位置。该方法的主要缺点在于只适用于LSTM 模型,存在一定的信息损失且无法使用GPU 进行并行化计算。
为了解决这些问题,Sui 等人[46]构建了三种不同的字词连接图网络,并使用生成式对抗网络提取三种图网络中的前n个字符节点的特征,证明了该方法可以有效避免词级别特征融合时的信息损失。为了避免信息损失而导致的词冲突问题,Gui 等人[47]将中文NER 视为一个图节点分类任务,通过图结构实现局部信息的聚合,并增加全局节点进行全局信息融入。Ma 等人[48]将特定长度的单词放在特定的层中,并加入整个句子的语境信息和更高维度的信息,不仅减少了单词之间的冲突,而且实现了模型的并行计算。Kong 等人[49]将每个字能够对应的标签汇成一个分词标签嵌入向量,在融合词典的嵌入向量与字向量直接连接,可以极大地提高训练速度。
为了捕捉长距离的依赖,Transformer 模型采用了自注意力机制以保持位置信息。由于自注意力机制具有无偏性,可以使用位置向量来提取位置信息。Li 等人[50]根据自注意力机制的无偏性,对文献[45]的结构进行了重构。具体而言,该方法对于所有汉字和词都提供了一个位置向量,以包含其开始和结束位置。因此,所提出的FLAT(flat lattice transformer)模型可以直接实现字符与所匹配的全部词汇的交互。
3.2 汉字特征融合
作为世界上最古老的文字之一,汉字由于其浓缩性和联想性的特点,使得单一汉字可以包含极大数量的隐含信息。与其他语言相同,汉字的语义会随着说话者的语气、说话的时间和场合以及上下文语境的不同而变化。同时,汉字作为一种象形文字,文字本身也蕴含着大量的特征信息,例如汉字的笔画、笔顺、偏旁部首以及语调。这些特征信息交融在一起,共同构成了汉字丰富的语义信息。在Zhang 等人[51]的研究中已经证明,笔画、结构和拼音相似的汉语单词具有相似的语义。因此,对汉字的固有字形特征进行提取是很有必要的。在现有的研究中,主流方法包括融合汉字字形特征、汉字笔画特征、汉字偏旁特征和汉字读音特征等。
3.2.1 汉字字形特征
基于传统的命名实体识别方法,Li等人[52]结合汉字的词性特征,对中文文本进行命名实体识别,并证明了词性特征可以有效提高中文命名实体识别的准确率。作为一种象形文字,汉字自身固有的形态也可以视作一种特征。因此有学者尝试将汉字视为图像进行处理[53]。
Su 等人[54]对汉字的位图进行处理,通过自动编码器直接从字符的位图中学习,并依据汉字图向量进行语义增强。Meng 等人[55]使用了一种改进的CNN 处理汉字位图,有效提高了模型的泛化性。
3.2.2 汉字笔画特征
为了得到单词和字符是如何构造的先验假设,以自动获取与汉语单词相关的有意义的潜在表示,有学者提出利用汉语单词所传达的笔画信息,来捕捉单词的形态和语义信息。Cao 等人[56]首次提出了使用汉字的笔画特征信息进行语义增强的思想,将汉字笔画分为五种不同的类型,并为每个笔画分配一个整数类型的ID 值作为特征标识。实验证明引入笔画特征后可以得到更好的中文实体识别效果。Zhang 等人[57]对中文和日文的笔画特征进行特征提取和比对,并应用在机器翻译中,识别率得到了显著提高。
3.2.3 汉字偏旁特征
在中文文本中,汉字的偏旁是由笔画所组成,因此可以包含笔画特征的一部分特征信息。同时,汉字的偏旁在一定程度上可以反映汉字所属的类别。由此可见,对汉字的偏旁特征进行提取可以实现更好的识别效果。
Sun 等人[58]通过使用汉字的词根特征,在中文命名实体识别任务中的识别率得到了显著提高。同时,Shao 等人[59]也通过实验证明,在中文自然语言的理解任务中,对词根和偏旁这类汉字的固有特征进行提取可以起到良好的改进作用。
在文献[55-56]的基础上,Chen 等人[60]对汉字的偏旁特征进行提取,并结合GRU-GatedConv(gated recurrent unit with gated convolution)网络,在公开数据集上进行了测试,实验结果表明提取偏旁特征对中文命名实体识别起到了积极的作用。在中医领域,Yang 等人[61]将笔画特征和偏旁特征结合使用进行命名实体识别,其F1 值高于单独使用笔画特征或偏旁特征。
3.2.4 汉字读音特征
在中文文本中,即使是同样的汉字,在不同的语境下所代表的含义也有所差异,有的时候甚至代表了完全相反的含义。其中,汉字的读音在一定程度上可以反映说话人的情感或所处语境的类型。同时,从语言学的角度来看,口语是一种更直接的语义表达,文本只有作为口语的记录时才具有实际意义。因此,汉字的读音也作为汉字的固有特征之一,得到了广泛的研究。
Zhang 等人[51]在Cao 等人[56]研究的基础上,将汉字的拼音特征嵌入到汉字的特征向量中,并通过实验证明了融合拼音特征、字形特征和偏旁特征的识别准确率高于仅使用字形特征和偏旁特征。Zhu 等人[62]在汉语文本中引入汉字的读音特征向量,并采用相同的模型进行比对,结果表明读音特征的引入对文本的识别可以起到良好的改进效果。Chaudhary等人[63]同样将汉字的拼音特征融入网络模型中,使模型的识别效果得到显著的提升。Zhang 等人[64]结合上述特征,将汉字的结构、偏旁、笔画和拼音特征融合到汉字的字符向量中,并通过设计特征子序列来学习这些特征之间的相关性。该方法在融合了四种汉字固有特征后,在中文命名实体识别任务和文本分类任务中的结果均优于目前最先进的方法。
4 中文命名实体识别方法改进
中文命名实体识别相较于英文而言,首先面临的问题就是如何对文本中的词语进行正确的分割。同时中文的词语数量庞大,且更新速度快,时效性较强,因此基于词典的模型往往会出现无法识别新词的问题。并且一词多义和多音字的问题在中文文本中广泛存在,需要进行特殊的标记处理。最后,对于识别性能较好的模型,需要对其中的算法进行优化,以缩短模型的训练时间和模型泛化性。
4.1 模型结构优化
近年来,基于深度学习的模型逐渐成为命名实体识别主流的解决方案。与基于特征的方法[65]相比,基于深度学习的模型有助于发现文本中隐含的深层特征。根据单词在句子中的形式,可以把基于深度学习的模型分为处理字和处理词两类。
对于处理字的模型,输入的句子被视为一个字符序列,该序列通过相应模型结构,输出各个字符对应的预测标签。Peters等人[66]提出了ELMO 模型对中文文本进行处理,该模型在具有字符卷积的两层双向语言模型的基础上计算,具有较高的准确率。对于处理词的模型,输入的每个单词都由其单词嵌入表示。Yadav 等人[67]提出了一个词级别LSTM 结构,并使用CRF 层处理预测的标签向量以提高模型性能,在CoNLL 2003 数据集上获得了84.26%的F1 分数。在实际的应用环境中,需要减少模型的训练时间,针对这个问题,Yohannes 等人[68]使用CNN 进行语义信息的降维,极大地减少了模型的参数量。
在医学命名实体识别领域,Xie 等人[69]使用skipgram 编码引入汉字词汇特征,在CCKS 2019 公开数据集中取得了较好的医学实体识别效果。Lee 等人[70]基于一种改进的图神经网络,并结合多特征融合方法,在保证模型识别效果的情况下提高了模型的识别效率。华为诺亚方舟实验室首创了一种预训练语言模型哪吒NEZHA[71],该模型首次使用了函数式相对位置编码。通过对比实验可发现,采用了函数式相对位置编码的方式明显优于其他位置的编码方式。
4.2 基于BERT 的预处理方法
BERT 是在2018 年由谷歌公司的Devlin 等人[40]提出的一种基于深度学习的语言表示模型,其主要的模型结构是Transformer 编码器。BERT 模型使用掩词模型和相邻句预测两个方法完成文本字词特征的预训练。其中,掩词模型通过将单词掩盖,从而学习其上下文内容特征,来预测被掩盖的单词;相邻句预测通过学习句子间关系特征,预测两个句子的位置是否是相邻的。由于BERT 在做文本处理类任务时,不需要对模型做过多修改,在中文命名实体识别的研究中受到了广泛的关注。谷歌公司在2018 年发布了用于处理中文文本的BERT 模型,该模型仅含有1.1×108的参数量,并可以识别简体中文和繁体中文。该模型一经问世,便有众多学者尝试将它用于中文命名实体识别任务中。
Li 等人[72]将外部词典知识直接集成到BERT 层中,实现词典增强型BERT 做预训练。直接使用BERT 虽然可以提升识别的准确率,但是由于BERT内部参数过多,会导致内存不足和训练时间过长等问题。因此,Lan 等人[73]提出了一种简化的BERT 模型ALBERT,该模型使用跨层参数共享方法,在略微牺牲模型性能的情况下极大地减少了模型的参数量和训练时间。Xiong等人[74]将ALBERT 和双向长短期记忆神经网络相结合,并用于中国政府公文的处理,在各类政府文书实体上均实现了良好的识别效果。
在医学领域,同样开展了一系列关于医学中文实体识别的研究。Wen 等人[75]使用BERT 对中医文本进行了实体识别,根据比对识别效果,证明了预训练的语言模型在中医命名实体识别任务中的有效性。Xiao 等人[76]对多源词典信息进行了融合,不仅提高了中医实体识别的效果,而且模型具有良好的领域迁移性。Zhang 等人[77]将字符与所对应的词汇相结合,在CCKS 2019数据集中实现了84.98%的F1值。
对于临床医疗诊断文本,Zhu 等人[78]将多个Bi-LSTM 模型与BERT 结合,并通过实验证明以交错的方式堆叠Bi-LSTM 模型相对于直接堆叠可以实现更好的识别效果,并可以花费更少的训练时间。针对临床医疗诊断文本标注量少的问题,Chen 等人[79]结合BERT 模型,采用半监督方法进行训练,减少了对大量标记数据的依赖。同时,对比研究表明,在已有模型的基础上,使用BERT 模型作为编码器进行预训练,可以在医学实体的识别任务中取得良好的效果。表3 列出了在CCKS 2020 数据集上表现良好的几种模型,其相应的实现效果使用F1 值作为评价指标[80-83]。
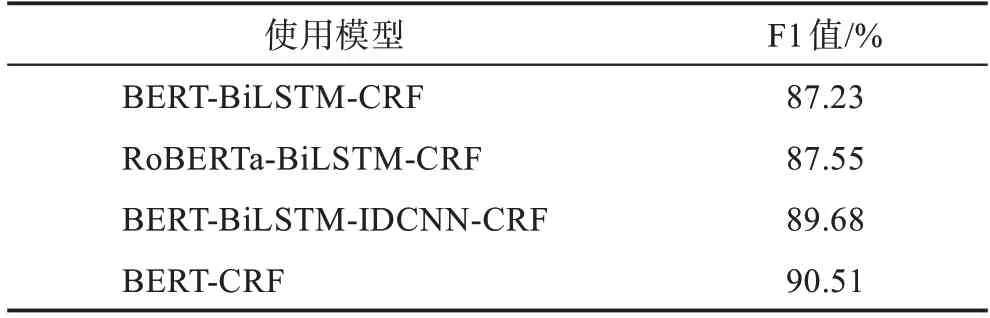
表3 基于BERT 的模型在CCKS 2020 上的效果Tabel 3 Effect of BERT-based models on CCKS 2020
4.3 实际应用优化
相对于实验环境中的理想情况,实际工程应用中的因果结构常常会存在各种伪相关的路径。由于预训练数据和所使用测试集之间的伪相关性,预训练模型会对特定标签有一定的预测偏好。一旦对预训练数据或测试集进行很小的干预,性能就会迅速下降,极大地影响命名实体识别的准确率。同时,同一概念可以存在多种表达方式,这也导致了预训练模型在不同测试集上的效果极不稳定。目前主流的方法是在文本中引入更多的信息,主要分为加入示例的类比信息[84]和加入上下文推理信息[85]两类。
加入上下文推理信息是指在原有基础上,增加通过检索得到的相关上下文[86]。上下文推理信息分为显式和隐式两种推理方式。显式推理指上下文中已经包含了答案的词语;隐式推理指上下文中虽然没有明确给出具体的答案,但是同样可以根据词性等方式预测答案。这种方式可以对文本的各种表述有更高的适应能力,在一定程度上提高模型的预测稳定性。加入示例的类比信息是指在原有基础上,增加一些示范性的样例[87]。这种方式可以借助示例的类比,帮助模型更好地识别实体类别,同时也提升了答案的类别准确率,从而提升了NER的准确率[88]。这种方式也存在着不足之处。所加入的示例只能帮助预训练模型更好地识别实体的类别,对于某一个类别内部的实体识别效果,并没有实质性的提升。并且,预测偏好的问题在示例类比过程中同样存在。预训练模型同样倾向于选择示例中的标签,导致预测存在整体的偏差[89]。同时,错误的示例标签对模型的性能影响并不明显。Min 等人[89]在12 个不同的主流模型上进行了测试,发现即使仅有格式正确的输入或输出时,模型的识别效果依然可以达到95%以上。因此,加入示例的类比信息导致的模型性能提高,主要是因为模型学习了输出的大致分布,而并非输入和输出的对应关系。
目前,命名实体识别在大型网商平台的应用包括搜索召回、情感分析等。在网商平台的O2O(online to offline)搜索中,对商家的描述是商家名称、地址等多个互相之间相关性并不高的文本域,如果采用简单取交集的方式,必然会产生大量的误召回。国内的某电商技术团队采用实体词典匹配和模型预测相结合的框架,使模型预测具备泛化能力,同时解决了词典匹配的歧义问题。整体识别架构如图7 所示。
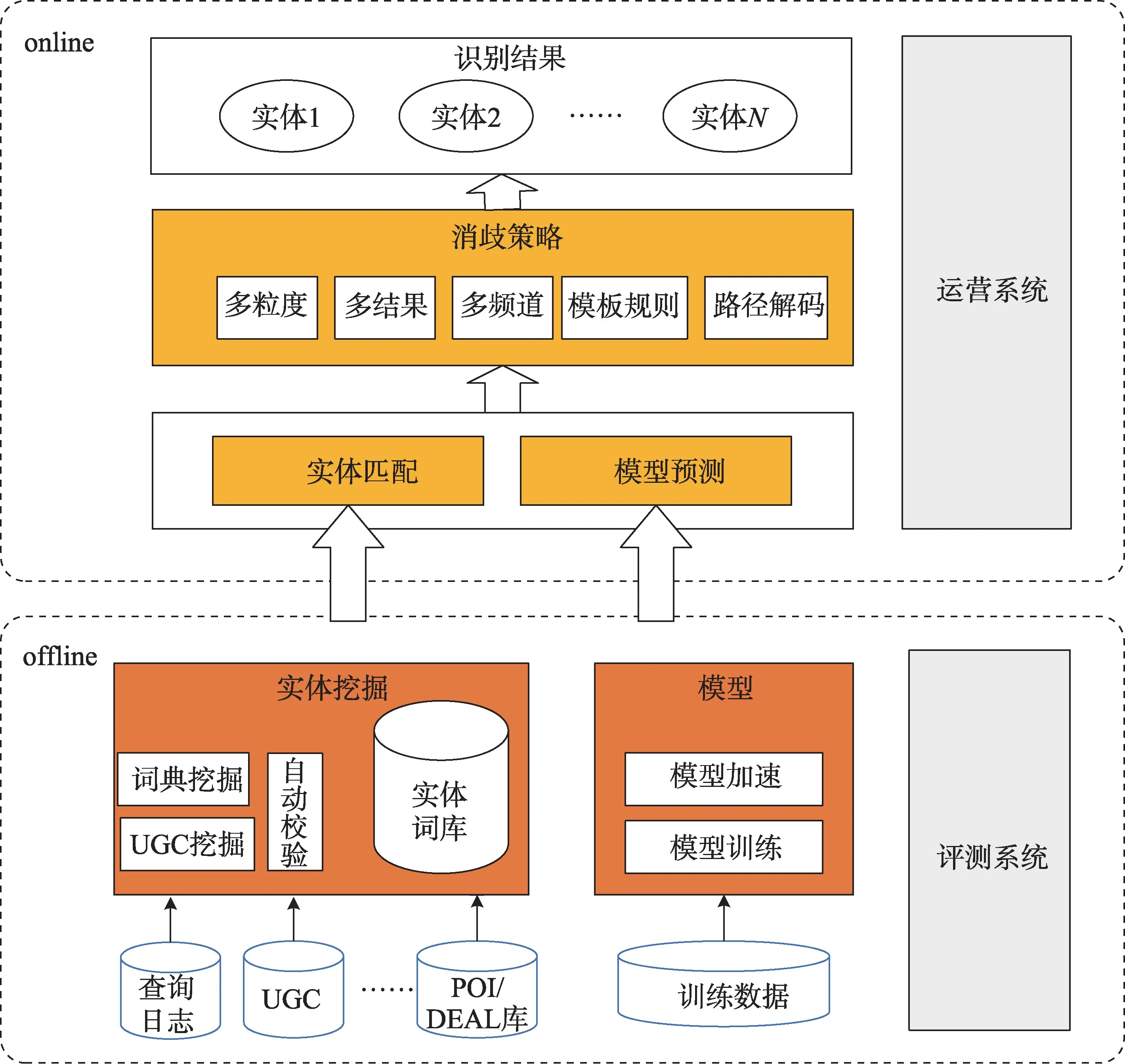
图7 实体识别整体架构Fig.7 Entity recognition overall architecture
同时,用户数据的吞吐量极大,因此存在搜索性能和训练数据质量的要求。针对以上问题,该电商技术团队采用模型蒸馏、算子融合、混合精度和批处理推理的方式,在不影响效果的基础上,极大提升了模型训练和预测的速度。同时,通过弱监督标注数据生成的方法,解决了标注数据难以获取的问题,在搜索召回的实际应用中取得了良好的效果。
5 中文命名实体识别实际应用
5.1 中文命名实体识别在医疗领域的应用
电子病历作为一种重要的医学信息资源,是卫生健康领域信息化的重要组成部分之一。研究者通过利用其中蕴含的大量关于疾病症状、诊断和治疗信息,使用自然语言处理和人工智能技术来挖掘和发现电子病历中的有效知识,可以有效优化就医流程和降低医疗成本。近年来,随着“互联网+医疗”概念的引入,电子病历系统广泛应用于各级医院,电子病历文本的数量也随之呈爆炸式的增长。然而,当前对于医疗领域的命名实体识别仍然存在着许多问题。首先,现阶段暂时没有系统化的中文医学语料库,对医疗领域命名实体识别的研究造成了许多困难;同时,在医疗领域内传统使用的RNN 模型在文本序列较长时,容易损失大量的有价值信息;并且,现有方法大多仅将一个文本序列映射为单一的向量表示,无法从多个维度分析文本序列的特征;最后,当前医疗领域命名实体识别的研究对标注训练数据集的数量和质量依赖极大。但是,医疗领域数据集中大量的医学专有名词、非标准化的名词缩写、大量专业名词的英文缩写和书写或表达错误产生的噪声,都对当前的研究带来了巨大的挑战。
针对医学语料库较少的问题,美国国家集成生物与临床信息研究中心针对不同疾病危险因素,在2006 年建立了较为完善的生物疾病信息语料库。我国的知识图谱与语义计算大会从2017 年开始,组织了多次面向中文电子病历的命名实体识别评测任务,并构建了中文电子病历的语料库。Su 等人[90]所在的研究团队在国内外电子病历标注规则的基础上,提出了一套相对完整的中文电子病历命名实体标注方案。
同时,国内外的学者对所使用的模型也进行了相应的优化。Luo 等人[91]将领域词典和多头注意力机制相结合,不仅捕获了语境、语义等潜在特征,而且减少了数据不均衡导致的精确度降低问题。Wang等人[92]采用了RNN-CNN 的混合式结构,并使用RoBERTa(robustly optimized BERT pretraining approach)进行向量嵌入表示,在处理长短交替的序列文本时实现了更高的准确率和更短的训练时间。Tian等人[93]使用泛化的通用语料库对当前基于Transformer 的衍生模型和基于BiLSTM-CRF 的衍生模型进行了评估,证明了基于Transformer 的衍生模型拥有更为优秀的泛化性。Li等人[81]采取了特征融合的思路,使用BiLSTM 和IDCNN(iterated dilated CNN)分别提取文本的上下文特征和局部特征,F1 值在CCKS 2020 的数据集中达到了89.68%。
针对中文电子病历数据集质量存在的问题,Zhang等人[94]采用RoBERTa 与WWM(whole word masking)方法结合的方式进行预训练,有效减少了数据集中文本噪声的影响。Jing 等人[95]针对小样本电子病历数据集,采取了半监督的方式,显著降低了人工标注的工作量,对相关项目的实际应用开发有较大的指导意义。
5.2 中文命名实体识别在政法领域的应用
近年来,随着国家司法和政务改革的持续开展,政法领域智能化平台的建设受到了广泛的关注,对海量的政法类文书进行智能分析和处理已成为当前研究的重要内容。在目前政法领域命名实体识别的研究中,主要存在以下两点问题:首先,现有的政法命名实体识别大多倾向于识别实体的固有属性,而并没有落实到政法属性,限制了诸如政法知识图谱下游任务的展开。同时,相对于通用领域的NER 任务,政法领域要求实体识别的细粒度更高。例如,对于地理实体的识别,通用领域的NER 只要求提取出大体的行政区即可。然而政法领域所需要提取的地理实体常常需要精确到街道和楼宇一级,因此使用现有的方法会导致准确率降低,并产生很大的误差。
针对上述问题,国内外的学者近年来对此展开了一系列的研究。Li 等人[96]通过手工的方式构建法律文本语料库,在司法领域中取得了86.09%的F1值。Liu 等人[97]采取自监督的方式,在迭代过程中扩展标注词典,只需要手工标注小部分数据即可达到良好的效果。针对政法领域实体的高细粒度要求,Ding 等人[98]使用ELECTRA 模型对电信网络诈骗案件文本进行处理,可以得到细粒度较高的识别实体。然而,噪声和一词多义的问题仍然没有得到有效解决。Roegiest等人[99]提出使用句子的逻辑倾向进行标记,从而缩小实体识别的范围。在文献[99]的基础上,Donnelly 等人[100]提出了一种双层结构的筛选器,其中一层对可能包含实体的句子进行筛选,另一层对句子中实体的位置进行筛选。这种方式不仅缓解了数据不均衡的问题,而且提高了实体识别的细粒度。
6 结束语
对于中文命名实体识别任务而言,目前所提出的模型和方法基本可以满足实际生产环境的需要,并且在特定领域中能够达到令人满意的识别准确率。但是,当前中文NER 的研究仍然受到诸多因素的制约,主要存在以下四点的不足:第一,现有的中文NER 模型参数量十分庞大,模型的训练需要消耗大量的时间,因此需要一种轻量化的模型来弥补这一不足之处。第二,当前的研究大多集中在特定领域,也即所提出的模型大多具有领域专一性,在迁移领域数据集后,模型的效果可能会明显降低,因此需要提出一种具有良好泛化性的模型。第三,当前大多神经网络模型对于训练词表外的词的识别效果不佳。第四,目前所使用的网络模型大多是基于人工神经网络的结构,因此可以尝试与生物神经学相结合,使用基于脉冲神经网络的方法开展进一步研究。
猜你喜欢
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
校园英语·月末(2021年13期)2021-03-15
中国外汇(2019年18期)2019-11-25
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
