
融合CNN和二进制生成对抗网络的多元时间序列检索
2023-02-17 06:23汤丽君关东海汪子璇袁伟伟燕雪峰
小型微型计算机系统 2023年2期
汤丽君,关东海,汪子璇,袁伟伟,燕雪峰
(南京航空航天大学 计算机科学与技术学院/人工智能学院,南京 211106)
1 引 言
多元时间序列广泛存在于我们的日常生活及实际应用中,如可穿戴设备[1],磁盘监控[2,3],状态监控[4,5]等.随着计算机技术和传感器技术的不断发展,多元时间序列变得越来越容易收集,同时数据量也变得越来越庞大.因此,多元时间序列的相关研究也面临较大的挑战和发展.对于给定当前的时间片段,如何高效精确地从以往时间片段中找出相似片段是一个极为重要的研究方向,这对于后续各种应用提供了极大的帮助,如状态识别,异常检测等.
目前,针对时间序列检索已经有了较多的研究,但是这些研究主要集中在一元时间序列检索方面,对于多元时间序列检索涉及较少,并且这些研究所采用的方法主要是一些传统的方法.同时,这些表示方法大多是基于专业人员的先验知识获得的,且主要针对一元时间序列,对于多元时间序列检索没有较好的移植性.
已有的研究工作主要采用支持离散傅里叶变换(DCT)[6,7],离散小波变换(DWT)[8]等传统机器学习方法以及长短期记忆网络(LSTM)等基本的神经网络对时间序列进行表示,主要采用欧氏距离或动态时间规整(DTW)[9.10]等相似性度量方法计算特征空间中的成对距离.以上这些方法在实验中取得了一定的成果,但是面对越来越复杂的多元时间序列数据,这些方法的效果并不理想.具体原因可能有以下几点:首先,多元时间序列有较多属性,而一元时间序列只需要考虑一个属性,已有的研究不能学习到多个属性之间的相关性[11,12];其次,已有的研究在时间序列表示上较为复杂,需要依赖专业人员的先验知识;再者,已有的相似性度量方法的计算较为复杂,当时间序列片段较长时,需要花费很大的计算成本;最后,目前的研究对于时间序列的表示只停留在简单的特征表示上,不能提高时间序列的可鉴别性,即不能促使相似的时间列有相似的表示,不相似的时间序列有不同的表示.
为解决上述问题,并且基于卷积神经网络利用卷积层在提取多元特征方面的优越性以及生成对抗式网络在提高模型泛化的能力,本文针对多元时间序列检索提出了一种基于CNN和深度非监督二进制生成对抗网络结构,通过生成对抗网络强化非监督学习,同时通过对时间序列进行二进制编码,使用Hamming距离来进行相似性度量,进一步降低计算成本.相较于以往研究,本文的方法能有效提高多元时间序列检索的速度和准确率.
论文工作的主要贡献在于:
1)本文是第一个将基于CNN的生成对抗式网络使用在多元时间序列检索上的论文,通过共享鉴别器和编码器的参数,利用鉴别器学习到的内容进行编码,通过CNN强大的特征提取能力,获取多元之间的相关性,同时采用生成对抗训练模型,提高模型的泛化能力.
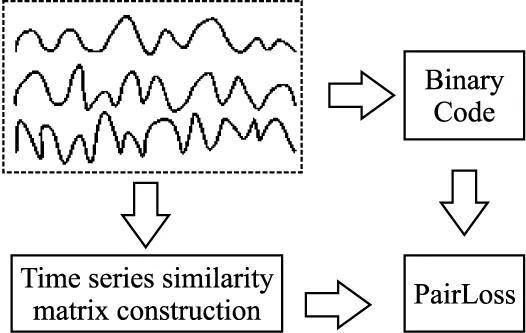
2)本文在模型中加入了时序相似矩阵,通过引入相似对损失,提高了时间序列特征表示的可鉴别性,促使相似的时间序列有相似的二进制表示,不相似的时间序列有不同的二进制表示.与此同时,通过计算时间序列二进制编码的Hamming距离,进一步降低了计算成本.
3)本文面向3个不同的多元时间序列的数据集设计了多组对比实验,提出的模型在3个数据集上在速度和准确率上都表现出了较优异的效果.
2 相关工作
关于时间序列检索的研究已经展开了多项工作.这个问题常见的解决方案是基于欧氏距离(EU)或者动态时间规整(DTW)来进行相似性度量,通过计算原始空间中的成对距离来获取相似片段.然而,在时间序列的长度较长或者数据量太大的情况下,这些方法需要花费较大的计算成本,通常是不可行的.所以,在后续的研究中,开始通过提取特征,从而获取时间序列的紧凑表示,进一步降低计算成本.到目前为止,已经开发了许多方法来表示时间序列,如离散傅里叶变换(DCT),离散小波变换(DWT),分段聚合逼近(PAA)[13]等.然而,以上这些方法都要求对数据进行专业的特征选择等复杂的预处理过程,需要专业人员的先验知识,对于多元时间序列检索来说是不够好的.此外,即使获取了良好的特征表示,使用欧氏距离或者动态时间规整来进行相似性度量所花费计算成本仍然是昂贵的.先前的研究[4,14]表明散列技术,如局部敏感哈希(LSH)[15]、草图单一散列法(SSH)[14]等可用于进一步降低高维相似性检索的检索复杂度,然而这些方法主要用于单变量时间序列,且排名前列的准确度并不高.总之,传统的机器学习在时间序列的特征表示及相似性度量方法上都需要较多专业人员的先验知识和计算成本,不能满足我们高效的检索目标.
随着深度学习的迅速发展,研究学者们尝试使用神经网络来解决这一问题.Grabocka等[16]提出了NeuralWarp方法,这是一种在深度表示空间中对时间序列对齐进行建模的新方法.通过将扭曲函数建模为对时间序列进行深度编码.Franceschi等[17]提出了一种无监督的方法来学习多变量时间序列的通用表示,该方法符合所研究的时间序列长度较长的情况,可获得可变长度和多变量时间序列的通用表示.然而,这些方法仍然存在相似性计算成本较高的问题,且有些是针对一元时间序列,对于多元时间序列检索效果一般,没有考虑多元时间序列的多元相关性和动态性,并且没有使时间序列具备可区分性.
生成对抗式网络在时间序列上的应用给了我们一定的启发.Jiang等[18]提出了一种非监督生成对抗学习方法用于异常检测,其将长短期记忆神经网络与全连接层连接起来,设计出一种可进行二次编码的自编码器,通过减少样本重构误差和潜在向量之间的距离,提高模型的泛化能力.Akcay等[19]通过使用编码器-解码器-编码器网络使模型能够将输入图像映射到一个较低的维数矢量,然后用来重建生成的输出图像.研究表明,GAN网络能极大提高模型的泛化能力.
近期,在图像检索和视频检索方面有较大进展.Li等[20]提出了一个用于大规模遥感图像检索的量化深度学习哈希框架(QDLH),QDLH框架中的权重和激活函数被二值化为低位表示,从而很大程度上减少了存储空间和计算资源.Anuranji等[21]提出了一种基于卷积的双向LSTM学习模型的联合集成,该模型从视频中学习丰富的帧级和视觉级特征,以获取紧凑的二进制编码.Zhang等[22]提出了一种新的无监督视频哈希框架,称为自监督(SSTH),它能够以端到端的方式捕获视频的时间特性,为视频生成二进制编码.以上这些进展充分体现了二进制编码对于降低计算成本的有效性,这些研究给我们的课题带来很大启发.
由于多元时间序列很难获取历史的标签信息,我们将其定义为无监督的多元时间序列检索问题,本文设计了基于CNN和无监督二进制编码生成对抗网络来进行多元时间序列检索.
3 相关技术介绍
3.1 标准CNN连接结构
卷积神经网络(CNN)广泛地应用于图像领域,其核心思想是利用卷积层进行特征提取.越来越多的研究者尝试将卷积神经网络应用于时间序列进行相关实验[3],这启发我们将卷积神经网络用于多元时间序列检索.
CNN是一类前馈神经网络,其特点是共享权重和平移不变性.如图1所示,与传统的人工神经网络相比,CNN通过滤波器使神经元只与输入数据的一个局部区域相连接,该连接的空间叫做神经元的感受野,CNN的神经元只在视野中被称为感受野的受限区域对刺激作出反应.不同神经元的感受野部分重叠,从而覆盖整个视野.采用共享权重的方案将局部神经元连通可以显著减少参数的数量,简化了网络模型,可防止神经网络出现过拟合的问题,同时这种非全连接的共享式深度神经网络更类似于生物神经网络.

图1 滤波器及感受野示意图Fig.1 Schematic diagram of filter and receptive field
3.2 生成对抗网络(Generative Adversarial Network,GAN)
生成对抗网络(Generative Adversarial Networks,GAN)[23]是一种生成式的对抗网络,即通过对抗的方式去学习数据分布的生成式模型.其中生成网络需要生成逼真的假样本来干扰鉴别网络,而鉴别网络则需要尽可能鉴别该样本是真实的样本还是生成的假样本,二者相互对抗从而达到一种平衡.
与其他生成式模型相比,GAN有两个优势:1)不依赖于任何先验假设.许多传统的方法会假设数据服从某一分布,然后使用极大似然去估计数据分布;2)生成假样本的方式非常简单.GAN生成假样本的方式通过生成器的前向传播,而传统的采样方式非常复杂.
GAN的模型结构如图2所示,隐变量z通过生成器生成Xfake,鉴别器负责鉴别输入的数据是生成的假样本Xfake还是真实样本Xreal.优化的目标函数如下:
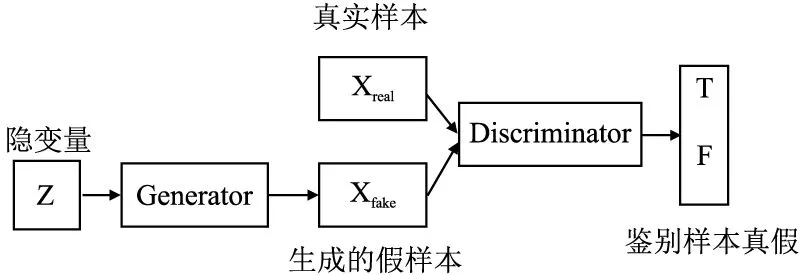
图2 GAN的模型结构Fig.2 Model structure of GAN
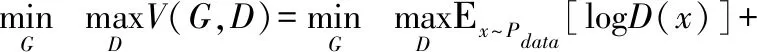
(1)
对于鉴别器D而言,这是一个简单的二分类问题,V(G,D)即为解决此类问题常用的交叉熵损失.对于生成器G而言,为了能更好地干扰鉴别器D,则需要最大化生成样本的鉴别概率D(G(z)),即最小化log(1-D(G(z))).
该目标函数是最小化两个分布的JS散度.事实上,还有很多种方法可以衡量两个分布距离,根据不同的距离度量方法,就可以得到不同的目标函数.许多改进GAN稳定性的方法,如EBGAN,LASGAN等定义了不同的距离度量方式.
3.3 二进制编码
二进制编码技术包含两大类:数据无关的二进制编码技术和数据相关(基于学习)的二进制编码技术,基于学习的二进制编码技术又可以进一步分为无监督方法和有监督方法.近期,深度二进制编码方法逐渐流行,其在图像检索任务中展现出优异的性能.受此启发,我们将二进制编码技术用于多元时间序列检索.本文使用sigmoid函数来近似地表示二进制编码.
与图像检索相比,我们必须同时考虑原始多元时间序列片段的时序动态性和不同特征之间的相关性.
4 多元时间序列检索模型
本节将对模型进行详细的介绍.其中,4.1节给出了一些基本的定义.4.2节详细描述了模型结构.
4.1 基本定义
基本符号的定义:首先,我们介绍论文中使用的符号.假设给定了一个多元时间序列片段:
Xt,w=(x1,…,xn)Τ=(xt-w+1,…,xt)∈Rn×w
(2)

多元时间序列检索问题描述:假设给出了一个多元时间序列片段Xq,w∈Rn×w,我们的目标是在历史的时间片段中(或数据库中)找到与其最相似的时间片段,用符号语言表示即我们希望获取:
(3)
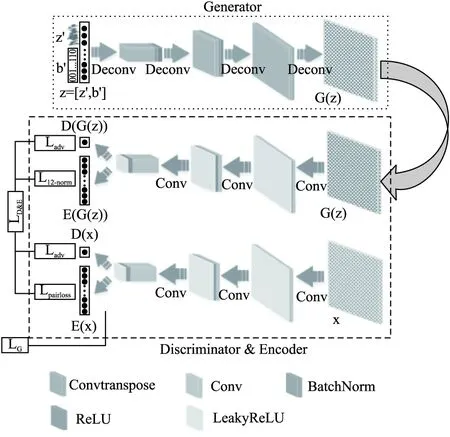
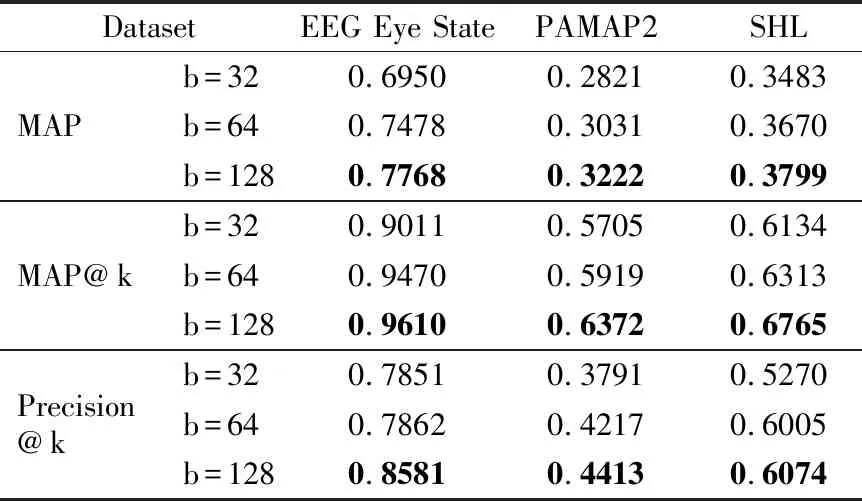
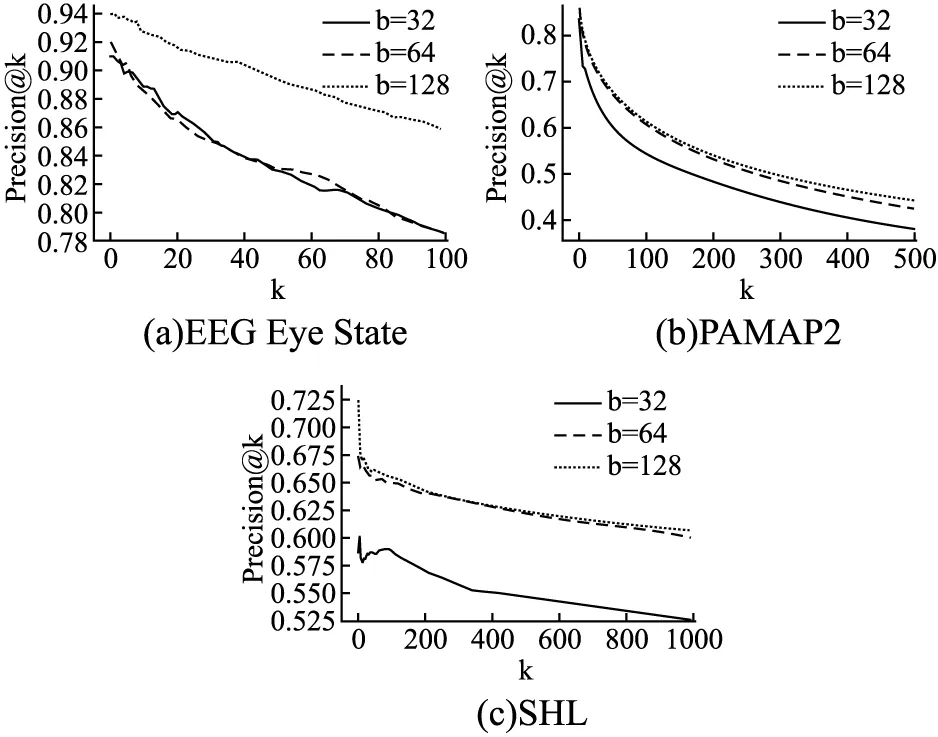
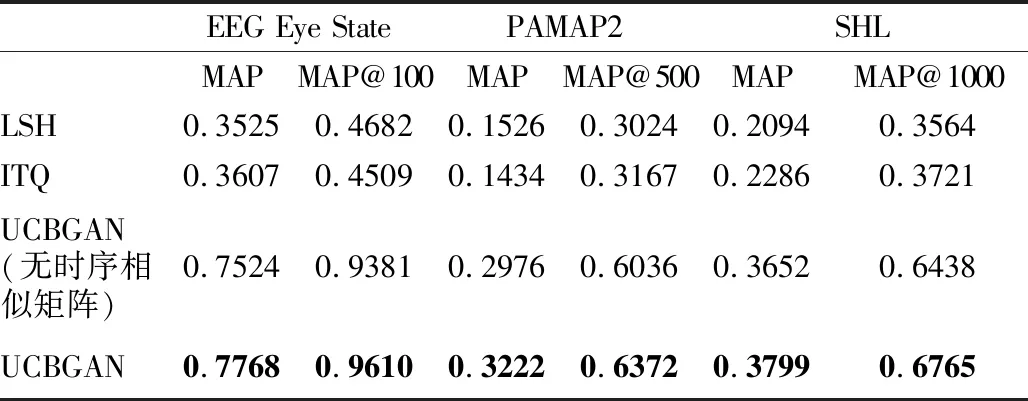
其中,D={Xp,w}表示一个时序数据集,p表示第p个时序片段的索引(∀w-1 在这一节中,我们首先展示模型UCBGAN的体系结构,并且解释模型背后的原理,其次,我们定义模型的损失函数,并解释每个损失函数在该模型中的作用. 我们提出的模型主要有3个部分组成,一个生成器,一个编码器和一个鉴别器.生成器主要是将随机分布映射到真实数据分布,从而使用合成数据来欺骗鉴别器,鉴别器主要用于区分真实数据和合成数据,编码器的作用是将时间序列映射为具有鉴别性的二进制编码,以进行后续的相似性度量.如图3所示,除了最后一层外,鉴别器和编码器共享权重参数.生成器的输入是随机二进制编码和均匀随机分布这两个随机分布数据的连接.由于我们模型的具体结构使用的是卷积神经网络,所以我们需将时序数据转化为类似图像的张量模式,所以我们首先详细介绍时序特征矩阵. 图3 UCBGM模型结构图Fig.3 UCBGM model structure diagram 4.2.1 时序特征矩阵 多元时间序列两个重要属性为时序属性和多元之间的相关性,所以我们应用滑动窗口来获取时间序列数据的滞后特征,并通过一种类似图像的张量模式来表示多元时间序列,以学习变量之间的相互作用,从而将其应用到卷积神经网络. (4) 其中κ为一个缩放因子(κ=w).所有时序对之间的时序特征即构成了时序特征矩阵Mt.时序特征矩阵不仅能捕捉时序对间的形状相似性和数值相关性,而且对于输入数据的噪声具有较强鲁棒性,因为特定时间节点的波动对于时序特征矩阵来说影响很小.在本实验中,我们将时间间隔设为10.构造完时序特征矩阵,我们对其进行归一化处理,将其范围控制在[0,1]的范围内. 4.2.2 具体结构 生成器的具体结构如图3所示,我们使用了1层全连接,后接3层反卷积网络,用于从随机分布中学习真实分布构造合成数据欺骗鉴别器,全连接层和反卷积层中间都使用了BatchNorm层和Relu激活函数优化中间层输出的分布,提高训练的效率.鉴别器和编码器除最后一层全连接层外,使用相同的结构并且共享权重参数,其结构为3层反卷积网络,后接一层全连接层,分别用于鉴别输入数据的真假和构造二进制编码. 为了训练鉴别器的参数,我们在GAN模型中使用了标准的对抗损失函数,而编码器的参数则是通过对合成数据二进制编码的L2-norm损失来训练的,通过该损失函数能强制约束编码器构造出与输入二进制编码相似的编码.为了训练生成器的参数,我们使用特征匹配损失函数促使生成器学习真实样本的分布,选择编码器最后一层隐含层的输出用来训练. 4.2.3 时序相似矩阵 我们认为,仅仅通过对抗损失和对输入的重构不足以使二进制编码具备较为精确的检索能力.所以,在本模型中,为了提高时间片段的可鉴别性,促使相似的时间序列有相似的二进制编码,不同的时间序列有不同的编码,我们引入了时序相似矩阵,通过训练促使二进制编码保持这种相似矩阵的结构.大量的研究表明,从预先训练的深层架构可提取丰富的特征信息.为了更好得利用这些信息,我们从预先训练的深层架构中提取深层特征,基于这些特征来构建时序相似矩阵. (5) 对于每个时间序列,找出其K1-NN并且保存它们的索引P∈RN×K1,其中N表示所有训练样本的数量.如果将K1设置为较小的数,就不能得到足够的时序相似信息,如果只是简单地增加K1的值,检索的精确率将会减小.因此,我们使用一种新的策略来获取足够的时序相似信息.对于每个时序数据前K1个相似索引中,我们分别计算与其交集最多的前K2个索引,然后分别将这前K2个时序数据中相似集合合并到该时序数据的相似集合中,作为该时序数据的相似集合.例如,我们得到索引为i的时序数据的K1-NN为{1,2,4,6,9},索引为j的时序数据的K1-NN为{1,3,4,7,9},若这两个集合的交集数量在索引为i的时序数据的前K2-NN中,则将两个集合合并,则时序数据i的时序相似集合为{1,2,3,4,6,7,9}.因此,我们构建一个时序相似矩阵S∈RN×N,即: (6) 若si,j=1,时序片段i和时序片段j即为邻居,si,j=-1,时序片段i和时序片段j不为邻居. 时序相似矩阵构建完成后,我们利用相似矩阵来获取相似对损失,以此进行训练,促使相似的二进制编码有相似的二进表示,提高二进制编码的可鉴别性,其流程逻辑图如图4所示. 图4 利用时序相似矩阵进行训练流程逻辑图Fig.4 Train process logic graph by using temporal similarity matrix 为了训练生成器网络,我们使用特征匹配损失,而不是使用常规的生成对抗式网络的判别损失函数.特征匹配损失促使合成数据与真实数据能有相似的分布,为了提高鲁棒性,我们使用鉴别器的最后一个隐藏层来计算,用F表示.同时F也是编码器网络的最后一个隐藏层,它影响着二进制编码,同时也能提高真实时间片段二进制编码的可鉴别性.生成器的损失函数LG定义如下: (7) 其中z为生成器的输入,它是由随机二进制编码和均匀随机分布这两个随机分布数据这两部分拼接而成,即z=[z′,b′]. 在训练鉴别器和编码器的过程中,我们使用了3个损失函数——传统的生成对抗式网络损失函数ladv,用于保持时序相似矩阵结构的相似对损失函数lpairloss,用于促使编码器输出和生成器输入之间距离最小化的损失函数lL2-norm,即鉴别器和编码器的总损失函数为ladv: LD&E=w1ladv+w2lpairloss+w3lL2-norm (8) 其中,ladv即为二分类交叉熵损失函数,它通过更新鉴别器的参数,促使鉴别器能够更加正确地区分出真实数据和合成数据: ladv=bce_loss(D(x),1)+bce_loss(D(G(x)),0) (9) 为了提高二进制编码的可鉴别性,促使相似的时序数据有相似的二进制编码,不相似的时序数据有不同的二进制编码,我们使用相似对损失进行编码器的训练: (10) 其中bi和bj为时间序列的二进制编码,si,j为时序数据i和j在时序相似矩阵S中的相似状态,L为二进制编码的位数.二进制编码bi=sgn(hi),hi是没有进行二进制编码前的隐藏状态.由于sgn(·)是不可微的,所以我们对此损失函数进行改进,使用hi和hj来进行相关运算: (11) 我们还利用合成数据的二进制编码和生成器输入的二进制编码b′计算L2-norm损失函数,通过该损失函数,促使编码器网络为合成数据生成与输入二进制编码b′相似的二进制编码,该损失函数与特征匹配损失配合使用,进一步提高了二进制编码的可鉴别性,提高检索的准确率.该损失函数如下: (12) 其中ε(·)表示编码器网络. 模型训练完之后,我们在验证集上进行评估.验证阶段只使用网络结构中的编码器网络,在编码器网络中,我们使用sigmoid函数近似二进制编码,在评估阶段通过sgn(·)生成二进制编码.生成二进制编码后,我们通过Hamming距离来进行相似性度量.并通过MAP,MAP@k,precision@k,recall@k这3个指标来评估我们的模型.在测试阶段,采用和验证阶段相同的方法来计算测试样本的3个指标. 在本节中,我们首先介绍所使用的3个数据集,其次,我们将具体阐述参数设置和评估标准,最后,我们将所提出的模型进行对比试验,从而阐述其高效性和精确性. 我们选择了现实生活中的3个多元时间序列数据集——EEG Eye State数据集,PAMAP2 Physical Activity Monitoring数据集,SHL(Sussex-Huawei Locomotion)数据集.如表1所示,对于每个数据集的采集片段,我们选取50%作为训练集,10%作为验证集,40%作为测试集. 表1 数据集Table 1 Dataset EEG Eye State数据集是由情绪脑电图耳机的连续脑电图测量得到,在脑电图的测量过程中,通过摄像头检测眼睛的状态,“1”表示闭眼,“0”表示睁眼.在我们的实验中,我们均匀采集了1460个片段,其中每个时间片段长度为10. PAMAP2 Physical Activity Monitoring数据集是一个身体活动监测数据集,其包含各种不同身体活动的数据,如步行,骑自行车,踢足球等.该数据集由佩戴3个惯性测量单元(IMU)和心率监测器的9名受试者执行,惯性测量单元的采样频率为100赫兹,心率监测器的采样频率为9赫兹.在我们的实验中,我们使用了来自Subject101的原始数据,它包含376416个时间点,每个时间点由52个属性组成,该数据集共包含13个类别标签.我们均匀采集了35720个片段,其中每个时间片段的长度为10. SHL数据集全称为苏塞克斯华为移动数据集(Sussex-Huawei Locomotion Dataset),它是一个移动用户移动和运输模式的多功能注释数据集.该数据集由在身体典型部位携带的一台相机和4部智能手机所收集,它是一个多模态数据集.在我们的实验中,我们选择了一个受试者的运动数据(以100赫兹采样),该数据集共包含8个类别标签,分别为“空”,“静止”,“步行”,“自行车”,“火车”和“地铁”等.我们均匀采样了981745个片段,其中每个时间片段的长度为10. 为了全面衡量多元时间序列检索的有效性,我们综合考虑了3个评价指标——平均精度的均值(MAP),前k个检索精度(precision@k),前k个检索召回率(recall@k). 本文提出的模型有6个超参数,其分别为学习率,编码位数,损失函数的3个权重,batch大小,其中学习率为{1e-6,1e-5,1e-4,1e-3},编码位数为{32,64,128},损失函数权重为{1,1,0.001},Batch大小100,对于这6个超参数,我们进行了较为全面的实验以获取最优结果. 对于多元时间序列检索,我们更关注相似的多元时间序列是否排在检索结果的前列,而不只是正确地检索出相似序列,所以在考虑前k个检索精度(precision@k)和前k个检索召回率(recall@k)的同时,我们还需考虑MAP和MAP@k,并用MAP作为一个综合评价指标.对于二进制编码的位数,不同的编码位数会对多元时间序列检索产生不同的检索效果,为获取最优的检索效果,我们分别将二进制编码位数取32位,64位和128位进行实验,我们比较了其在3个数据集上的MAP、MAP@k两个指标,如表2所示. 表2的结果表明,本文提出的方法在3个数据集上都有较好的效果,相较于EEG Eye State,本文模型在PAMAP2和SHL数据集上效果稍微差一点.由表2还可看出当二进制编码的位数分别为32、64和128时,多元时间序列检索的效果,在二进制编码位数为128位时,检索效果相较于其他位数效果更优,由此可表明我们所提出算法的有效性. 表2 不同位数的二进制编码下3个数据集的MAP和MAP@k指标,其中EEG Eye State(k=100),PAMAP2(k=500),SHL(k=1000),b表示二进制编码位数Table 2 Map and MAP@k indicators of three data sets encoded with different bits of binary 为了进一步研究所提出的UCBGAN模型的有效性,我们还比较了前k个检索精度(precision@k)和前k个检索召回率(recall@k),当b变化时,其在3个数据集上的实验结果分别如图5和图6所示. 图5 3个数据集分别在b=32、b=64和b=128下的Precision@kFig.5 Precision@kof three datasets with b=32,b=64 and b=128 图6 3个数据集分别在b=32、b=64和b=128下的Recall@kFig.6 Recall@kof three datasets with b=32,b=64 and b=128 为了表明本文提出模型中所使用的时序相似矩阵的有效性,体现时序相似矩阵对于检索效果的提升,我们将未使用时序相似矩阵的网络进行训练所获取的实验结果和使用了时序相似矩阵的实验结果进行了对比,同时与另外两种算法局部敏感哈希(LSH)[15]和迭代量化方法(ITQ)[24]进行了比较,实验结果主要比较这4种算法的MAP等指标,如表3所示.比较了4种算法在3个数据集上的效果,在一定程度上反映了本文所提出模型的性能. 由表3可看出,相对于LSH和ITQ,本文提出的算法在3个数据集上都显著优于这两种方法,体现了UCBGAN模型在多元时间序列检索上的有效性,该模型能同时获取多元时间序列的时序性和多元相关性,提高检索精度.我们还发现,ITQ的效果总体上是优于LSH的,这表明利用底层的数据结构可为多元时间序列生成更有效的二进制编码.通过比较未加入时序相似矩阵和加入时序相似矩阵的两种模型的检索效果,实验结果表明,加入时序相似矩阵模型的检索效果总体优于未加入时序相似矩阵模型的检索效果,由此可见,在模型中加入特征相似矩阵能促使相似的时间序列有相似的二进制表示,不相似的多元时间序列有不相似的二进制表示.提高多元时间序列表示的可鉴别性,从而进一步提高多元时间序列的检索精度. 表3 UCBGAN与其他3种算法的MAP和MAP@k指标比较结果,其中EEG Eye State(k=100),PAMAP2(k=500),SHL(k=1000)Table 3 UCBGAN compared the results with the other three algorithms 我们提出了一种基于CNN和深度非监督二进制编码生成对抗网络进行多元时间序列检索.首先我们考虑多元时间序列时序属性,将其构造为时序特征矩阵,使其转化成类似图像的数据并使用UCBGAN模型进行训练;其次卷积神经网络可很好地学习多元相关性,我们对多元时间序列进行二进制编码,进一步降低了计算成本;最后我们使用时序相似矩阵来提高二进制编码的可鉴别性,提高检索精度.3个公开真实数据集的实验结果验证了本文所提出的UCBGAN模型的有效性.将来,我们会进一步研究如何对网络结构进行优化设计以提高其检索精度,以及如何将多元时间序列检索模型应用到一些实际应用中.4.2 模型结构

5 训练模型


6 实验与分析
6.1 数据集

6.2 评估指标和参数设置
6.3 实验结果对比

7 结 论
猜你喜欢
通信学报(2022年10期)2023-01-09
小猕猴智力画刊(2022年3期)2022-03-28
中等数学(2021年8期)2021-11-22
铁道建筑技术(2020年11期)2020-05-22
数学大王·低年级(2019年10期)2019-11-25
中等数学(2019年4期)2019-08-30
国防科技大学学报(2019年4期)2019-07-29
电子制作(2017年13期)2017-12-15
系统工程与电子技术(2016年5期)2016-11-02
自动化学报(2016年5期)2016-04-16
