
分块压缩学习剪枝算法
2023-02-17 06:23:00刘会东余振华宋丽娟
小型微型计算机系统 2023年2期
刘会东,余振华,2,杜 方,2,宋丽娟,2
1(宁夏大学 信息工程学院,银川 750021)2(宁夏大数据与人工智能省部共建协同创新中心,银川 750021)
1 引 言
近年来,深度神经网络(Deep Neural Network,DNN)在文本处理[1]和计算机视觉任务[2]上进行广泛的应用,并取得了较优结果.然而,高性能的DNN具有较多的参数和更多的计算量,无法在资源有限的设备或移动设备上使用.目前,解决这一问题的可行方法是在不影响精度的情况下对网络模型进行压缩[3].而网络剪枝技术是模型压缩中常用的方法,并在处理复杂网络模型效率上展现显著优势[4].
网络剪枝技术是去除网络中冗余的参数和结构以得到稀疏的网络结构,可分为非结构化剪枝和结构化剪枝.非结构化剪枝通过去除每层不重要的权值以实现权重矩阵较高的稀疏度,Han等[5]提出基于阈值的剪枝方法去除网络中冗余的权值,删除权值绝对值低于阈值的权重参数.但非结构化剪枝的实现需要借助特定的软件[6]和硬件[7],将带来额外的计算成本.相比非结构化剪枝,结构化剪枝通过去除冗余的层、卷积核和通道减少网络参数和计算成本[8],其适用性更强.Ashok等[9]提出了一种两阶段压缩方法,去除网络中冗余的结构.He等[10]利用深度确定性策略算法逐层删除不重要的卷积核.这些工作均采用逐层的方式修剪网络,在剪枝过程中仅关注当前层的信息,无法全面考虑层与层之间的优化关系.
最近研究工作表示[11,12],相比继承基线网络重要的权重参数,剪枝网络的结构是决定剪枝网络模型性能的关键.网络剪枝技术可以看作网络架构搜索(Neural Architecture Search,NAS)问题,所有符合搜索条件的网络称为子网络或候选网络,而由所有子网络组成网络搜索空间,网络搜索的目标是在搜索空间中搜索较优的子网络.之前的NAS方法使用强化学习[13]或遗传算法[14],但由于网络巨大的搜索空间和对子网络结构复杂的性能评估,搜索最佳的子网络结构较困难.为了加快NAS的速度,Pham等提出自动化模型设计的方法[15],不需要全面训练每个候选网络,通过权重共享的方式同时训练不同的候选网络.但由于每个子网络无法得到充分的训练且共享同一网络参数的子网络太多,导致子网络无法完全训练收敛,无法准确评估候选网络的有效性.
为解决以上问题,本文提出了一种有效的结构化剪枝方法.首先,为避免网络巨大的搜索空间,本文在一个网络压缩目标空间中随机初始化剪枝网络所有层的压缩率.然后,借鉴知识蒸馏的思想,将基线网络作为教师网络,剪枝网络作为学生网络,将教师网络和学生网络按层划分多个并行的块网络.最后,将每个块网络的剪枝率看作种群,使用遗传算法搜索每个子网络最优的结构,通过最小化剪枝块网络与基线块网络输出特征之间的距离对剪枝网络结构进行优化.
综上所述,本文的主要贡献如下:
1)本文基于知识蒸馏和遗传算法提出了分块压缩学习算法;
2)本文所提方法通过对剪枝网络进行分块优化,减少网络搜索空间,提高了网络搜索的效率;
3)大量的实验表明,本文所提方法优于其它网络剪枝方法.
2 相关工作
2.1 遗传算法
遗传算法(Genetic Algorithm,GA)[16]是模拟达尔文生物进化论的自然选择和遗传学机理的生物计划过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法.遗传算法的本质是减少繁琐的数学推理,基于概率搜索全局最优解,在搜索过程中自动获取和积累搜索的经验,并自适应的调整搜索策略.
遗传算法的应用是通过将问题建模为种群进化的过程,通过重组、变异等步骤产生下一代的解,然后逐渐淘汰适应度较差的个体,保留适应度较高的个体.以此方式进化N代后,会进化出适应度较高的种群.遗传算法的求解问题如图1所示.
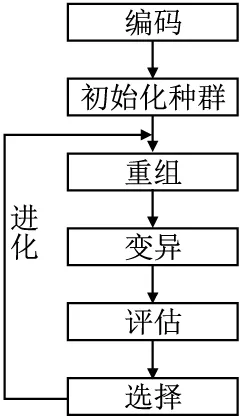
图1 遗传算法流程图Fig.1 Genetic algorithm flow chart
1)编码.需要对实际的求解问题进行编码,将问题数字化.
2)初始化种群.根据定义的问题编码方案,随机初始化种群,种群中的个体是数字化的编码.其中,种群的初始化方案和种群的大小需要根据实际问题进行设置.
3)重组.随机选择种群中的两个个体,将个体中位于相同位置的基因以一定的概率进行交换,产生新的个体.
4)变异.随机选择一个个体,然后将个体中的某个基因以一定的概率进行更改.
5)评估.评估种群中每个个体的适应度.
6)选择.首先判断种群是否达到设定的稳定条件,达到稳定条件则结束进化,没有达到稳定条件,从种群中挑选适应度较高的个体组成新的种群,然后,从3)开始继续执行.
2.2 网络剪枝
网络剪枝技术可分为非结构化网络剪枝和结构化网络剪枝.非结构化网络剪枝称为权重剪枝[5],通过移除不重要的权重参数以实现稀疏化的权重矩阵,是将不重要的权值参数更改为0,在实际意义上并不能实现网络运行的加速.相比之下,结构化剪枝通过修剪网络中冗余的卷积核、层和通道减少网络的参数和计算量,以实现真正意义上的网络“加速”.
结构化剪枝可以分为两个子任务:网络稀疏度的分配[8-10]和层内重要卷积核的选择[17,18].网络稀疏度的分配是通过在有限资源中确定每层网络结构对网络全局的重要性,以修剪网络.Lin等[8]使用软掩码更新的方式寻找网络模型中块、分支、通道的压缩率.层内重要卷积核的选择是通过对每层卷积核、神经元、层进行重要性排名,以去除不重要的单元.Lin等[17]通过特征图秩的大小对网络中的特征图进行重要性排序,并根据提剪枝率删除每层秩较低的特征图.Li等[18]通过L1范数计算每层卷积核的权重绝对值之和作为卷积核的重要性,以去除不重要的卷积核.
2.3 神经网络架构搜索
NAS是在大的网络空间中搜索较优的子网络结构,其由3个模块组成,分别是搜索空间、搜索策略和性能评估.搜索紧凑的神经网络体系结构最初是由领域专家根据经验完成的,但由于人为制定的策略无法搜索所有的稀疏网络结构,可能导致搜索次优的网络结构.最近工作结合遗传算法或强化学习算法[13,14],提高了搜索最优稀疏网络结构的可能性.然而,这些方法需要从零开始训练大量的子网络结构,导致搜索最优的网络结构需要消耗大量的计算时间.
为解决以上问题,最近研究提出通过权值共享加速搜索过程.Guo等[19]提出了“One-shot methods”,首先训练一个大的网络结构,然后通过搜索算法在大网络中搜索最佳的子网络结构.Cai等[20]提出“once-for-all network”,通过权重共享生成子网络结构,将网络模型训练和体系结构解耦,对子网络的评估不需要额外的训练.此外,还有研究者提出添加一些约束方法减少网络搜索空间[21,22],通过搜索更大的单元或块组建新的子网络结构.Li等[23]借鉴人脑的特性,将神经网络结构划分为n个不同的块结构(Block),同时利用知识蒸馏进行指导训练.
2.4 知识蒸馏
知识蒸馏[24]是首先训练一个大网络(教师网络),然后将大网络学到的知识作为监督信号指导小网络(学生网络)的训练.近年来,较多研究人员采用知识蒸馏和网络剪枝相结合的方式对网络进行加速.Lin等[8]通过将教师网络最后一层的输出特征直接复制给学生网络,学生网络可以自动学习如何修剪网络.对学生网络的指导不仅限于最后一层网络的输出,从教师网络中间层可提取更丰富的表征信息以指导学生网络.Li等人[25]通过让生成对抗网络的生成器网络的每一层输出特征以指导相应层的剪枝.
3 方 法
3.1 问题定义
为提高网络剪枝的效率,本方法借鉴知识蒸馏的思想,将基线网络作为教师网络,剪枝网络作为学生网络.然后将教师网络和学生网络按层划分多个块网络,利用教师网络逐块对学生网络进行监督,每个块网络均可以按照相同的方式进行修剪.如图2所示,第i个学生块网络和第i个教师块网络的输入特征向量是上一个教师块网络的输出特征向量.用fi(X,W)和gi(X,W′)分别表示第i个学生块网络和教师块网络的输出特征,其中X、W和W′分别表示块网络的输入特征向量、教师网络的权重张量和剪枝网络的权重张量.为减少模型的性能损失,教师块网络和学生块网络输出特征之间的差异应尽可能小,为此,使用均方误差(Mean Squared Error,MSE)损失表示它们之间的差异,如下:
(1)
其中n表示样本的数量.最小化MSE损失可有效减少网络模型的性能损失,基于MSE损失可定义类似准确率的度量指标来评估不同的网络结构:
(2)
为了进一步区别具有相似性能而计算效率不同的块网络,本方法使用块网络的FLOPs压缩率作为块网络的效率度量,剪枝块网络的FLOPs压缩率的计算公式表示为:
(3)

(4)
其中α是用来控制网络模型性能和效率的权值,较高的α值将减少更多的FLOPs.对于剪枝网络中的每个块网络,其目标是寻找较高度量分数R的稀疏块网络.在下面的章节中,通过遗传算法,为该优化问题提供了一个可行的解决方案.
3.2 模型框架
基于遗传算法的分块压缩学习算法(Chunking Compression Learning Algorithm,CCLA)网络架构图如图2所示.首先,将教师网络复制为学生网络,在预定义的压缩空间对学生网络进行随机初始化.其次,将教师网络和学生网络按层划分多个块网络,并使用教师网络的块网络对学生网络相应的块网络进行监督.最后,通过遗传算法搜索剪枝网络中较优的块网络结构,使学生网络和学生网络相应的块网络之间的差异最小化.网络框架可分为两部分,分别是网络架构搜索和剪枝算法.

图2 CCLA网络框架图.图中的分数代表模型性能和效率的度量指标Fig.2 CCLA network framework diagram.score is a measure of model performance and efficiency
CCLA算法具体流程如下:
1)初始化剪枝网络.将教师网络复制为学生网络,在指定的FLOPs范围内对剪枝网络进行初始化,如公式(5)所示:
(5)
其中r是剪枝网络的目标FLOPs压缩率,ε是指定FLOPs的搜索空间大小.
2)将网络划分多个块网络.如图2所示,将教师网络和学生网络按层划分多个块网络.
3)网络架构搜索.参考知识蒸馏的思想,将基线块网络对剪枝块网络进行监督,使用遗传算法搜索每个剪枝块网络较优的压缩率.
4)网络剪枝.首先使用基于权值绝对值大小来对每层的卷积核排序,然后根据每层的压缩率对网络进行剪枝.剪枝算法流程详见3.4节.
5)获取较优的剪枝网络.将搜索出的较优块网络模型依次序重新搭建,并微调网络模型,即为搜索的较优网络模型.
3.3 基于遗传算法的分块网络结构搜索
所有的剪枝块网络S均按照类似的方式进行独立修剪,设L是剪枝块网络S的层数,ri是剪枝块网络S第i层的剪枝率,本方法的目标是找到每个块网络中最优的剪枝率.此问题可以表述为如下优化问题:

(6)
其中S*表示修剪后较优的剪枝块网络,S表示剪枝块网络,S′表示剪枝块网络的候选空间.
本文使用遗传算法对每个剪枝块网络中的剪枝率进行搜索,以找到每个剪枝块网络较优的剪枝率.如本文2.1遗传算法中介绍所示,遗传算法是种群经过重组、变异等步骤迭代进化N次,然后选择适应度较高的种群.下面将对使用遗传算法剪枝网络进行介绍:
编码:本方法是将网络模型中每个块网络的剪枝率r作为个体的单个基因.将块网络中的剪枝率用一维向量S表示,作为遗传算法的个体.
种群:在本算法定义的种群大小是100,然后在指定的FLOPs压缩范围内对种群进行初始化.
重组:随机选择种群中2个个体,任意选择个体中某一个相同的位置以较大的概率值进行交换.
变异:随机选择1个个体,任意选择个体中某一位置的剪枝率,以较小的概率值用0-1之间的随机值进行替换.
选择:本方法种群选择策略采用轮盘赌选择策略,该策略中个体被选中的概率与个体的适应度函数成正比.需计算每个个体的适应度函数,对种群中所有个体的适应度值进行累加,然后进行归一化处理,最后对种群中的个体进行随机选择.每个个体被选中概率如下:
(7)
其中Q(ai)是表示种群第i个个体的适应值,本方法的适应度函数的计算如公式(4)所示.
3.4 网络剪枝算法
网络剪枝是通过剪枝率,对网络模型中不重要的权重、卷积核、通道或层进行剪枝.本方法是对卷积核中不重要的卷积核进行修剪,使用的剪枝算法是L1权重范数的剪枝算法.L1权重剪枝算法是将权重绝对值之和的大小作为卷积核或神经元重要性的判断指标,根据层剪枝率修剪掉层中不重要的卷积核,其剪枝步骤如下:
1)对卷积核的重要性进行排序.计算每层卷积核或神经元的L1权重值,并根据重要性分数按从小到大的方式对卷积核或神经元进行排序.
2)删除卷积核.根据每层的剪枝率,删除网络中不重要的卷积核.
4 实验结果与分析
为了验证本文所提方法的有效性,本文使用VGGNet[26]和ResNet[27]网络模型在CIFAR-10和CIFAR-100[28]数据集上进行压缩实验.
CIFAR-10和CIFAR-100数据集各有50000张训练图像样本和10000张测试样本.将CIFAR-10和CIFAR-100数据集以9∶1将训练集随机划分为训练集和验证集,在剪枝过程中使用验证集对剪枝网络的性能进行评估,而不对剪枝网络进行微调.
块网络的划分:VGGNet网络使用的是VGG-16网络,对于VGG-16网络,将整个教师网络作为一个块网络进行搜索.ResNet网络使用的是ResNet-20网络、ResNet-56网络和Resnet-110网络,为保持ResNet网络每个块结构的输出通道不变,CCLA只修剪每个块结构中除最后一层以外的卷积层.对于ResNet-20网络,将3个Block作为一个块网络,ResNet-56网络和ResNet-110网络,均采用9个Block作为一个块网络.
4.1 实验参数设置
基线模型训练过程中的参数设置如下:迭代次数(Epoch)设为300;批量大小(Batchsize)大小为256;学习率大小初始化为0.1,在迭代120次、180次和240次时分别递减10倍;优化器采用随机梯下降算法,动量大小为0.9,权重衰减大小为5×10-4.剪枝网络的微调参数设置如下:学习率率初始化为0.01,其它参数和基线网络模型的训练参数一致.
本文遗传算法中的参数设置如下:种群大小设置为100,进化次数设置为300,重组的概率值设置为0.8,变异的概率值设置为0.05.
4.2 VGGNet网络的实验结果与分析
为验证本文所提方法的有效性,本文首先在CIFAR-10数据集上对VGG-16网络进行压缩实验.CCLA在不同的压缩目标下修剪了两次,然后选用SSS(Sparse Structure Selection)[29]、GAL(Generative Adversarial Learning)[8]和HRank(High Rank)[17]进行比较,剪枝结果如表1所示.
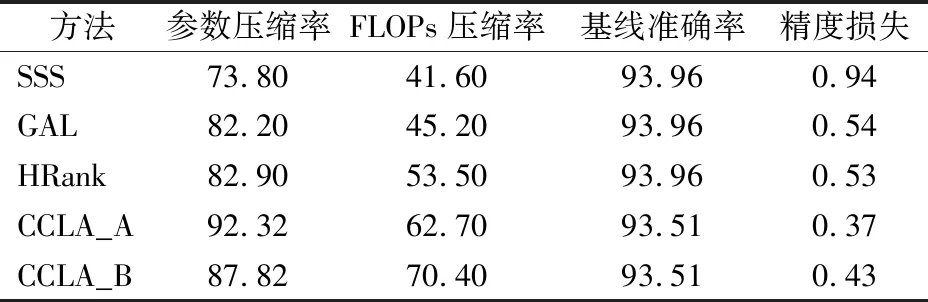
表1 在CIFAR-10数据集上VGG-16网络的剪枝结果CCLA_A和CCLA_B是不同FLOPs压缩目标下CCLA方法的剪枝结果Table 1 Pruning results of VGG-16 on CIFAR-10 CCLA_A and CCLA_B are pruning results of CCLA for different FLOPs compression targets
与现有方法相比,本文所提方法在网络精度和计算成本之间可以实现较好的权衡.例如,SSS压缩掉73.80%的参数和41.60%的FLOPs,精度下降0.94%.GAL压缩掉82.20%的参数和45.20%的FLOPs,精度下降0.54%.HRank压缩掉82.90%的参数和53.50%的FLOPs,精度损失为0.53%.而本文所提出的方法CCLA压缩掉92.32%的参数和62.70%的FLOPs,精度损失仅为0.37%.此外,CCLA在0.43%的精度损失下,可压缩掉87.82%的参数和70.40%的FLOPs,这是因为本文方法将FLOPs压缩率作为优化的目标,在更大的精度损失下,可以压缩掉较多的FLOPs.以上实验结果表明,通过知识蒸馏的方式对剪枝网络进行监督,使用遗传方法可以有效地修剪掉网络的冗余结构.
4.3 ResNet网络的实验结果与分析
为验证本文所提方法的有效性,本文在CIFAR-10数据集上对ResNet-20网络、ResNet-56网络和ResNet-110网络进行压缩实验,在CIFAR-100数据集上对ResNet-56网络行压缩实验.
如图3所示,为验证公式(4)中超参数α对网络剪枝的影响,本文选择多个不同数值的α在CIFAR-10数据集上对ResNet-20网络进行剪枝实验.设超参数α初始值为0.1,增量大小为0.1,取7个不同的数值,每个α值重复测试3次,并取3次的中值大小.随着α值的增大,CCLA会倾向于修剪较多的FLOPs和参数,而网络精度逐渐下降.例如,在α=0.2时,ResNet-20网络可以压缩掉44.65%的参数和39.36%的FLOPs.在α=0.3时,ResNet-20网络可以压缩掉33.54%的参数和41.95%的FLOPs.但α=0.3时参数压缩率低于α=0.2,这是由于本方法是以FLOPs压缩率为搜索目标.以上实验结果表明,使用本方法在对网络模型进行剪枝过程中,可以通过设置适当的α值以得到不同稀疏度的网络模型.
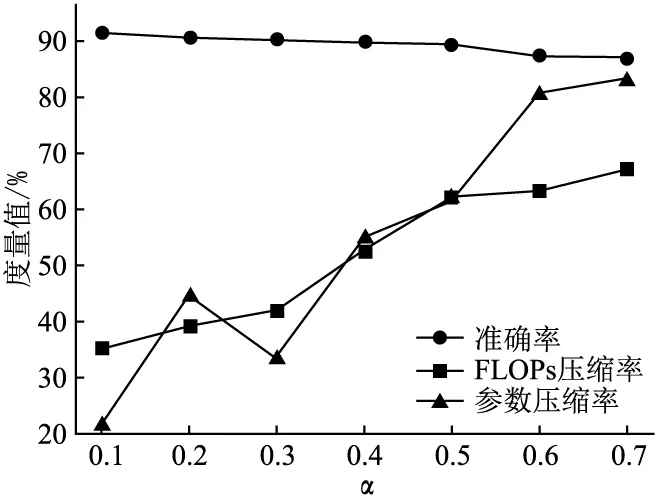
图3 不同的α对网络剪枝的影响Fig.3 Effect of different α on network pruning
ResNet-56网络在CIFAR-10数据集上测试准确率为93.32%,在0.53%的精度损失下,CCLA可修剪掉ResNet-56网络58.67%的FLOPs和54.48%的参数,各层的剪枝结果如图4(a)所示.在第1、11、12、16、26个Block中,CCLA的修剪力度最大,说明在该层中存在较多的冗余,而在第13、第22个Block中,CCLA没有修剪,说明这些Block对网络结构较重要.ResNet-56网络在CIFAR-100数据集上测试准确率为70.53%,在1.26%的精度损失下,CCLA可以修剪掉29.39%的参数和48.86%的FLOPs,各层的剪枝结果如图4(b)所示,CCLA可有效寻找网络的冗余结构并进行修剪.实验结果表明,本文所提方法在简单分类任务和复杂分类任务上,均可对网络进行有效的剪枝.

图4 ResNet-56网络修剪前后各层卷积核的对比Fig.4 Comparison of the convolutional kernels of each layer of the ResNet-56 before and after pruning
为了进一步验证本文所提方法对复杂网络修剪的有效性,本文在CIFAR-10数据集上对复杂网络ResNet-110进行压缩实验.然后选用GAL、SFP(Soft Filter Pruning)[30]、FPGM(Filter Pruning via Geometric Median)[31]、LFPC(Learning Filter Pruning Criteria)[32]和HRank进行了比较,ResNet-110网络的剪枝结果如表2所示.
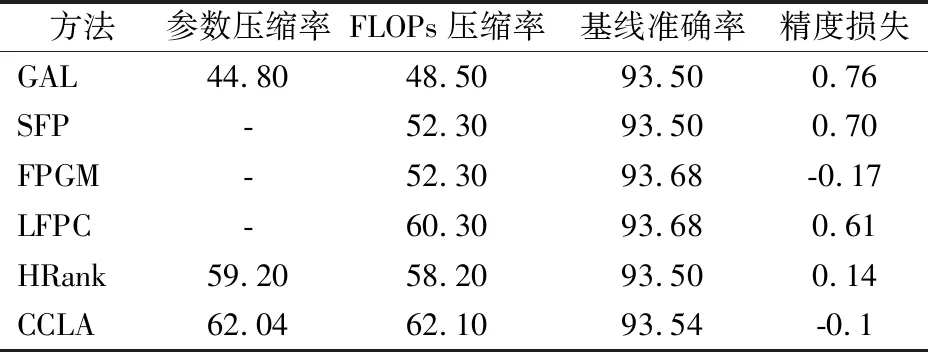
表2 在CIFAR-10数据集上ResNet-110网络的剪枝结果Table 2 Pruning results of ResNet-110 on CIFAR-10
在表2中,GAL修剪44.80%的参数和48.50%的FLOPs会导致0.76%的精度损失,而CCLA修剪62.04%的参数和62.10%的FLOPs,精度提升0.1%,结果表明使用知识蒸馏对网络剪枝过程中,使用遗传算法对网络进行分块剪枝可更有效地找到网络模型的最优剪枝率.相比FPGM,FPGM修剪52.3%的FLOPs,精度可以提升0.17%,而CCLA在相近的精度提升下,可修剪较多的FLOPs.此外,与SFP、LFPC和HRank相比,CCLA对稀疏网络的搜索都更加有效,可在无精度损失下,找到更加稀疏的网络结构.以上实验结果表明,CCLA适用于复杂网络的修剪,将复杂网络进行分块之后,使用遗传算法可准确找到层内和层间的冗余结构.
5 结束语
为减少网络剪枝过程中,子网络搜索空间较大的问题,本文提出基于遗传算法的分块压缩学习算法(CCLA).不同于现有的剪枝方法,CCLA在剪枝过程中不是直接对大网络进行剪枝,而是将大的网络分为多个块网络,然后对每个块网络进行剪枝,因此其效率更高.实验结果表明,在常规和更复杂的网络模型上,CCLA可以准确找到每层网络的冗余结构.进一步的工作,将在更大的数据集和具体的应用场景中进行测试,以验证CCLA的有效性和实用性.
猜你喜欢
保健医苑(2022年5期)2022-06-10 07:47:22
成都信息工程大学学报(2021年6期)2021-02-12 03:00:54
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
中央民族大学学报(自然科学版)(2017年1期)2017-06-11 07:13:32
统计与决策(2017年2期)2017-03-20 15:25:24
天津诗人(2017年2期)2017-03-16 03:09:39
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:38:39
